一、设计模式基础概念
1. 核心定义
设计模式不是固定的代码模板,而是一套经过长期实践验证的设计思想与最佳实践。它针对软件开发中反复出现的"对象创建、结构组合、交互通信"三类核心问题,给出了成熟的、可灵活落地的解决方案。
2. 核心价值
-
解耦:拆分强依赖的模块,让代码变更的影响范围最小化;
-
复用:避免重复造轮子,大幅提升开发效率,减少重复代码;
-
可维护:结构清晰分层,符合通用规范,便于团队协作与后期迭代;
-
可扩展:遵循开闭原则,新增功能无需修改原有核心代码,降低迭代风险。
3. 六大设计原则
所有设计模式都严格遵循六大设计原则,其中开闭原则是核心中的核心,是衡量设计是否合理的核心标准
单一职责原则: 一个类/接口/方法只负责一个核心职责,杜绝臃肿的"万能类" 拆分职责边界模糊的类,避免一个类承担多个变化维度的逻辑
开闭原则: 对扩展开放,对修改关闭 封装不变的核心逻辑,隔离可变的扩展点,通过新增代码实现功能迭代,而非修改原有代码
里氏替换原则 :子类可以完全替换父类,且不会破坏程序原有正确性 子类可以扩展父类功能,但不能重写父类的非抽象方法,不能改变父类的输入输出约定
依赖倒置原则: 面向抽象编程,依赖抽象接口而非具体实现 高层模块不依赖低层模块,二者都依赖抽象;细节依赖抽象,而非抽象依赖细节
接口隔离原则 :建立细粒度的专用接口,避免强制实现无用方法的"胖接口" 拆分臃肿的大接口,客户端只需要依赖它需要的接口,不依赖无关的方法
迪米特法则(最少知道原则): 一个类对其他类的了解越少越好,只和直接的朋友通信 降低类之间的耦合度,避免跨层级的依赖调用,通过中间类封装复杂交互
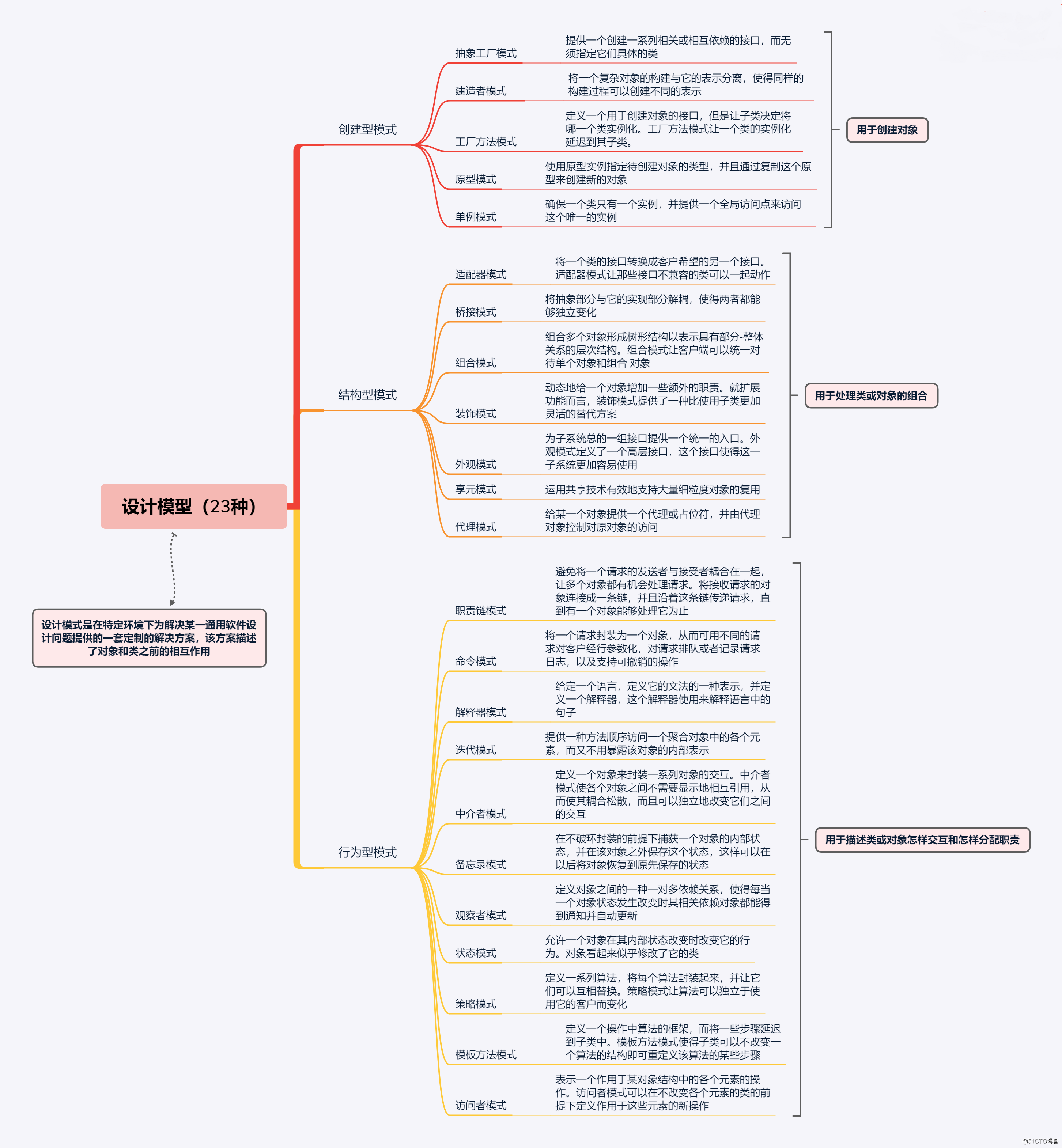
二、23种设计模式三大分类
创建型模式(5种): 聚焦对象的创建过程,封装对象创建逻辑,精细化控制实例化,将对象创建与使用分离 。(单例模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式)
结构型模式(7种): 聚焦类与对象的组合结构,通过继承、组合构建灵活的结构,在不修改原有代码的前提下扩展功能 。(适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式、代理模式 )
行为型模式(11种): 聚焦类与对象之间的交互通信、职责分配,优化复杂流程控制,让对象之间的协作更清晰、耦合度更低。( 责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式、访问者模式)
三、23种设计模式
(一)创建型模式(5种)
创建型模式的核心是封装对象的创建逻辑,解决硬编码实例化带来的耦合问题,精细化控制对象的实例化时机、方式与数量
1. 单例模式
核心原理
保证一个类在整个应用的运行周期中,有且只有一个唯一实例,并对外提供一个全局统一的访问点,避免频繁创建销毁对象带来的性能开销,保证全局状态的一致性。
详细使用场景
-
全局唯一资源管理:数据库连接池、线程池、配置管理类、全局日志对象;
-
状态一致性场景:Spring容器中的单例Bean、分布式ID生成器、计数器;
-
资源占用高的对象:大对象、初始化耗时久的对象,避免重复创建。
完整Java代码示例(全实现方式)
单例模式的实现核心是:私有化构造方法,禁止外部通过new实例化,以下是6种常见实现,覆盖面试所有考点:
(1)饿汉式单例(类加载时初始化,天然线程安全)
javascript
public class HungrySingleton {
// 类加载时就初始化实例,天然线程安全
private static final HungrySingleton INSTANCE = new HungrySingleton();
// 私有化构造方法,禁止外部实例化
private HungrySingleton() {
// 全局唯一访问点
public static HungrySingleton getInstance() {
return INSTANCE;
}
}-
优点:实现简单,类加载时完成初始化,无线程安全问题,调用效率极高;
-
缺点:类加载时就创建实例,不管是否使用都会占用内存,可能造成内存浪费;
-
适用场景:单例对象占用内存小、启动时确定会使用,无懒加载需求。
(2)懒汉式单例(线程不安全,面试反面案例)
javascript
public class LazySingletonUnsafe {
private static LazySingletonUnsafe instance;
private LazySingletonUnsafe() {}
// 调用时才初始化,懒加载
public static LazySingletonUnsafe getInstance() {
// 多线程下,多个线程同时进入if判断,会创建多个实例,破坏单例
if (instance == null) {
instance = new LazySingletonUnsafe();
}
return instance;
}
}-
优点:懒加载,只有使用时才创建实例,节省内存;
-
缺点:多线程环境下完全线程不安全,生产环境绝对禁止使用;
-
适用场景:仅单线程环境,面试常考线程安全问题分析。
(3)懒汉式单例(线程安全,方法加锁)
javascript
public class LazySingletonSafe {
private static LazySingletonSafe instance;
private LazySingletonSafe() {}
// 方法加synchronized锁,保证同一时间只有一个线程进入
public static synchronized LazySingletonSafe getInstance() {
if (instance == null) {
instance = new LazySingletonSafe();
}
return instance;
}
}-
优点:懒加载,线程安全;
-
缺点:每次调用getInstance都要加锁释放锁,性能极差,并发场景下效率极低;
-
适用场景:并发量极低、对性能无要求的场景,生产环境不推荐。
(4)双重检查锁DCL单例(面试高频,懒加载+高性能+线程安全)
javascript
public class DCLSingleton {
// volatile禁止指令重排,解决多线程下空指针问题
private static volatile DCLSingleton instance;
private DCLSingleton() {}
public static DCLSingleton getInstance() {
// 第一次检查:无锁,实例已创建直接返回,提升性能
if (instance == null) {
// 加类锁,保证同一时间只有一个线程进入
synchronized (DCLSingleton.class) {
// 第二次检查:避免多线程并发重复创建实例
if (instance == null) {
instance = new DCLSingleton();
}
}
}
return instance;
}
}-
优点:懒加载,线程安全,只有第一次初始化时加锁,后续调用无锁,性能极高;
-
缺点:实现相对复杂,必须加volatile关键字,否则会有指令重排问题;
-
适用场景:高并发场景,对性能和懒加载都有要求的生产环境。
(5)静态内部类单例(推荐使用,懒加载+高性能+线程安全)
javascript
public class StaticInnerSingleton {
private StaticInnerSingleton() {}
// 静态内部类,只有被调用时才会加载,实现懒加载
private static class SingletonHolder {
// 类加载的初始化锁,天然保证线程安全
private static final StaticInnerSingleton INSTANCE = new StaticInnerSingleton();
}
public static StaticInnerSingleton getInstance() {
return SingletonHolder.INSTANCE;
}
}-
优点:懒加载,利用JVM类加载机制天然保证线程安全,无锁,调用性能极高,实现简单;
-
缺点:无法防止反射和序列化破坏单例;
-
适用场景:绝大多数生产环境,是除枚举单例外最推荐的实现方式。
(6)枚举单例(《Effective Java》官方推荐,最安全的单例)
javascript
public enum EnumSingleton {
// 唯一实例,天然单例
INSTANCE;
// 业务方法
public void doBusiness() {
System.out.println("枚举单例执行业务逻辑");
}
}-
优点:实现最简单,天然线程安全,绝对防止反射和序列化破坏单例,无任何漏洞;
-
缺点:非懒加载,枚举类加载时就初始化实例;
-
适用场景:无特殊懒加载需求的所有生产环境,是官方推荐的单例实现方式。
单例模式高频面试题
面试题1:双重检查锁DCL单例中,volatile关键字的作用是什么?能不能去掉?
详细解答:
volatile关键字绝对不能去掉,它有两个核心作用:
- 禁止指令重排: new DCLSingleton() 创建对象分为3个步骤:
① 分配内存空间;
② 初始化对象;
③ 将instance引用指向分配的内存地址。
JVM可能会对这3个步骤进行指令重排,变成①→③→②。如果没有volatile,多线程场景下,线程A执行了①和③,此时instance不为null,但对象还未初始化完成;线程B调用getInstance,会直接拿到这个半初始化的对象,调用时触发空指针异常。volatile通过内存屏障禁止指令重排,保证对象初始化完成后,才会将引用赋值给instance。
- 保证内存可见性:保证一个线程修改了instance的值,其他线程能立即看到最新的值,避免线程从本地缓存中读取到过期的null值。
面试题2:反射会破坏单例吗?如何防止?
详细解答:
除枚举单例外,其他所有单例实现都会被反射破坏。因为反射可以通过 setAccessible(true) 强行调用私有的构造方法,创建新的实例,破坏单例特性。
-
防止方式1:使用枚举单例。JVM天然禁止通过反射创建枚举实例,当尝试反射调用枚举的构造方法时,会直接抛出 IllegalArgumentException 异常,这是最安全的方式。
-
防止方式2:在私有构造方法中添加实例校验。当第二次调用构造方法时,直接抛出异常,代码如下:
javascript
private DCLSingleton() {
if (instance != null) {
throw new RuntimeException("禁止通过反射创建单例实例");
}
}面试题3:序列化和反序列化会破坏单例吗?如何解决?
详细解答:
会破坏。当单例类实现了 Serializable 接口,反序列化时会创建一个新的对象,即使构造方法是私有的,也会破坏单例特性。
- 解决方式:在单例类中添加 readResolve() 方法,反序列化时会自动调用这个方法,返回我们指定的单例实例,避免创建新对象,代码如下:
javascript
private Object readResolve() {
return SingletonHolder.INSTANCE;
}- 枚举单例天然不会被序列化破坏,因为JVM对枚举的序列化有特殊处理,反序列化时只会返回枚举类中定义的同名枚举常量,不会创建新的实例。
面试题4:饿汉式和懒汉式单例的核心区别是什么?
详细解答:
核心区别在于实例初始化的时机,延伸出线程安全、性能、内存占用的差异:
-
初始化时机:饿汉式在类加载时就初始化实例;懒汉式只有第一次调用getInstance方法时才初始化实例,实现懒加载。
-
线程安全:饿汉式利用JVM类加载机制,天然线程安全;懒汉式默认线程不安全,需要通过加锁、静态内部类等方式保证线程安全。
-
内存占用:饿汉式不管实例是否使用,都会占用内存;懒汉式只有使用时才创建,节省内存。
-
性能:饿汉式调用时直接返回实例,无任何额外开销,性能最高;懒汉式需要处理线程安全问题,可能会有加锁开销,性能略低。
面试题5:Spring中的单例Bean和Java单例模式是一回事吗?
详细解答:
不是一回事,核心区别在于作用域范围不同:
-
Java单例模式:单例的范围是ClassLoader,同一个类加载器下,只会有一个实例,不同类加载器会创建不同的实例。
-
Spring单例Bean:单例的范围是Spring IoC容器(ApplicationContext),同一个容器中,一个Bean定义只会创建一个实例,不同容器会创建不同的实例。
-
补充:Spring的单例Bean默认是饿汉式初始化,容器启动时就创建实例,也可以通过 lazy-init=true 配置为懒加载;Spring通过三级缓存解决单例Bean的循环依赖问题,和Java单例模式的实现原理完全不同。
2. 简单工厂模式(静态工厂模式)
注:简单工厂不属于23种经典设计模式,但它是工厂模式的基础,面试高频考察,因此优先讲解。
核心原理
定义一个统一的工厂类,根据传入的参数,动态创建对应的产品实例,所有产品都实现同一个抽象接口。核心是封装对象创建逻辑,客户端无需关心对象的创建细节,只需要传入参数即可获取对应的实例。
详细使用场景
-
产品种类少、变化不频繁的场景,比如日志记录器创建、简单的对象实例化;
-
客户端只需要使用产品,不需要关心产品的创建逻辑,隔离对象创建与使用;
-
封装第三方SDK的对象创建,对外提供简单的调用入口。
完整Java代码示例
javascript
// 产品抽象接口
public interface Logger {
void log(String message);
}
// 具体产品:控制台日志
public class ConsoleLogger implements Logger {
@Override
public void log(String message) {
System.out.println("控制台日志:" + message);
}
}
// 具体产品:文件日志
public class FileLogger implements Logger {
@Override
public void log(String message) {
System.out.println("文件日志:" + message + ",已写入日志文件");
}
}
// 具体产品:数据库日志
public class DatabaseLogger implements Logger {
@Override
public void log(String message) {
System.out.println("数据库日志:" + message + ",已写入数据库");
}
}
// 工厂类:静态工厂,统一创建产品实例
public class LoggerFactory {
// 私有化构造方法,禁止实例化工厂类
private LoggerFactory() {}
// 静态工厂方法,根据类型创建对应的日志实例
public static Logger getLogger(String type) {
if (type == null) {
return new ConsoleLogger();
}
switch (type) {
case "file":
return new FileLogger();
case "db":
return new DatabaseLogger();
default:
return new ConsoleLogger();
}
}
}
// 测试类
public class SimpleFactoryTest {
public static void main(String[] args) {
Logger consoleLogger = LoggerFactory.getLogger("console");
consoleLogger.log("这是一条控制台日志");
Logger fileLogger = LoggerFactory.getLogger("file");
fileLogger.log("这是一条文件日志");
Logger dbLogger = LoggerFactory.getLogger("db");
dbLogger.log("这是一条数据库日志");
}
}简单工厂模式高频面试题+详细解答
面试题1:简单工厂模式的优缺点是什么?
详细解答:
- 优点:1. 封装了对象创建逻辑,客户端无需关心对象创建细节,只需要传入参数即可获取实例,降低耦合度;
- 统一管理对象创建,便于后期维护,修改产品实现时,只需要修改工厂类,不需要修改所有客户端代码。
- 缺点:1. 违背开闭原则,新增产品时,必须修改工厂类的switch逻辑,扩展不友好;
-
工厂类职责过重,所有产品的创建逻辑都集中在一个工厂类中,产品种类过多时,工厂类会变得臃肿,维护难度提升;
-
静态方法无法被继承和重写,工厂类无法形成层级结构。
面试题2:简单工厂模式和工厂方法模式的核心区别是什么?
详细解答:
核心区别在于工厂的职责与扩展方式不同,是否符合开闭原则:
-
工厂数量:简单工厂只有一个全局的工厂类,负责所有产品的创建;工厂方法模式是一个产品对应一个工厂,每个工厂只负责创建一类产品。
-
开闭原则:简单工厂新增产品时,必须修改工厂类的代码,违背开闭原则;工厂方法模式新增产品时,只需要新增对应的产品类和工厂类,无需修改原有代码,完全符合开闭原则。
-
复杂度:简单工厂实现简单,适合产品种类少、变化不频繁的场景;工厂方法模式结构更复杂,引入了更多的类,适合产品种类多、扩展频繁的场景。
3. 工厂方法模式
核心原理
定义一个工厂抽象接口,为每一个产品定义一个专属的工厂实现类,一个工厂只负责创建一类产品,将产品的实例化延迟到工厂子类中。核心是一对一的产品-工厂对应,完全符合开闭原则。
详细使用场景
-
产品种类扩展频繁,需要保证新增产品不修改原有代码;
-
客户端不需要知道产品的创建细节,只需要知道对应的工厂;
-
一个类需要由它的子类来指定创建哪个对象,实现创建逻辑的灵活扩展;
-
实际业务:不同支付渠道的创建、不同消息推送方式的创建、不同缓存类型的创建。
完整Java代码示例
javascript
// 产品抽象接口
public interface PayService {
// 支付方法
void pay(double amount);
}
// 具体产品:微信支付
public class WechatPayService implements PayService {
@Override
public void pay(double amount) {
System.out.println("微信支付:成功支付" + amount + "元,已从微信钱包扣款");
}
}
// 具体产品:支付宝支付
public class AlipayService implements PayService {
@Override
public void pay(double amount) {
System.out.println("支付宝支付:成功支付" + amount + "元,已从余额宝扣款");
}
}
// 具体产品:银行卡支付
public class BankCardPayService implements PayService {
@Override
public void pay(double amount) {
System.out.println("银行卡支付:成功支付" + amount + "元,已从储蓄卡扣款");
}
}
// 工厂抽象接口
public interface PayFactory {
PayService createPayService();
}
// 具体工厂:微信支付工厂
public class WechatPayFactory implements PayFactory {
@Override
public PayService createPayService() {
// 封装微信支付的初始化、参数配置等创建逻辑
return new WechatPayService();
}
}
// 具体工厂:支付宝支付工厂
public class AlipayFactory implements PayFactory {
@Override
public PayService createPayService() {
// 封装支付宝支付的初始化、参数配置等创建逻辑
return new AlipayService();
}
}
// 具体工厂:银行卡支付工厂
public class BankCardPayFactory implements PayFactory {
@Override
public PayService createPayService() {
// 封装银行卡支付的初始化、参数配置等创建逻辑
return new BankCardPayService();
}
}
// 测试类
public class FactoryMethodTest {
public static void main(String[] args) {
// 客户端只需要依赖工厂接口,不需要关心产品创建细节
PayFactory factory = new WechatPayFactory();
PayService payService = factory.createPayService();
payService.pay(199.0);
// 切换支付方式,只需要更换工厂实现类,无需修改原有代码
factory = new AlipayFactory();
payService = factory.createPayService();
payService.pay(299.0);
}
}工厂方法模式高频面试题+详细解答
面试题1:工厂方法模式的优缺点是什么?
详细解答:
- 优点:1. 完全符合开闭原则,新增产品时,只需要新增对应的产品类和工厂类,无需修改原有代码,扩展性极强;
-
符合单一职责原则,每个工厂只负责创建对应的产品,职责清晰,不会出现臃肿的工厂类;
-
面向抽象编程,客户端只依赖工厂和产品的抽象接口,不依赖具体实现,降低耦合度;
-
隐藏了产品的创建细节,产品的创建逻辑封装在对应的工厂类中,修改创建逻辑时,只需要修改对应工厂,不影响客户端。
- 缺点:1. 类的数量成倍增加,一个产品对应一个工厂,产品种类过多时,会出现大量的类,增加代码复杂度和理解成本;
- 增加了系统的抽象性和理解难度,引入了多层抽象结构,对于简单的场景,会过度设计。
面试题2:工厂方法模式的核心设计思想是什么?
详细解答:
工厂方法模式的核心设计思想是**"定义创建对象的接口,让子类决定实例化哪一个类,将类的实例化延迟到子类"**。
它完全遵循依赖倒置原则,面向抽象编程,客户端只依赖抽象的工厂接口和产品接口,不依赖具体的实现;同时通过拆分工厂职责,解决了简单工厂模式违背开闭原则的问题,让系统的扩展性更强,新增产品时无需修改原有代码,只需要扩展新的实现类即可。
4. 抽象工厂模式
核心原理
提供一个创建一系列相关或相互依赖的产品(产品族)的接口,而无需指定它们具体的实现类。核心是产品族的概念,一个工厂可以创建同一品牌/同一体系下的多个不同产品,解决工厂方法模式只能创建单一产品的问题。
核心概念区分:
-
产品等级:同一个产品的不同实现,比如手机产品,有小米手机、苹果手机,属于同一个产品等级;
-
产品族:同一个品牌下的多个相关产品,比如小米手机、小米电脑、小米平板,属于同一个产品族。
详细使用场景
-
系统需要创建一系列相关联的产品,产品族固定,比如跨平台的UI组件(Windows、Mac、Linux下的按钮、输入框、弹窗);
-
不同品牌的全系列产品创建,比如小米、苹果的手机、电脑、平板全系列产品;
-
数据库访问的多数据源适配,比如MySQL、Oracle的连接创建、语句执行、事务管理一整套适配;
-
微服务中不同环境的配置、服务调用、缓存一整套适配。
完整Java代码示例
javascript
// 产品1:手机接口
public interface Phone {
void makePhone();
}
// 产品1具体实现:小米手机
public class XiaomiPhone implements Phone {
@Override
public void makePhone() {
System.out.println("生产小米旗舰手机");
}
}
// 产品1具体实现:苹果手机
public class ApplePhone implements Phone {
@Override
public void makePhone() {
System.out.println("生产苹果iPhone手机");
}
}
// 产品2:电脑接口
public interface Computer {
void makeComputer();
}
// 产品2具体实现:小米电脑
public class XiaomiComputer implements Computer {
@Override
public void makeComputer() {
System.out.println("生产小米笔记本电脑");
}
}
// 产品2具体实现:苹果电脑
public class AppleComputer implements Computer {
@Override
public void makeComputer() {
System.out.println("生产苹果MacBook电脑");
}
}
// 产品3:平板接口
public interface Tablet {
void makeTablet();
}
// 产品3具体实现:小米平板
public class XiaomiTablet implements Tablet {
@Override
public void makeTablet() {
System.out.println("生产小米平板");
}
}
// 产品3具体实现:苹果平板
public class AppleTablet implements Tablet {
@Override
public void makeTablet() {
System.out.println("生产苹果iPad平板");
}
}
// 抽象工厂接口:定义产品族的创建规范,一个工厂创建同一品牌的所有产品
public interface ElectronicFactory {
Phone createPhone();
Computer createComputer();
Tablet createTablet();
}
// 具体工厂:小米工厂,创建小米全系列产品(产品族)
public class XiaomiFactory implements ElectronicFactory {
@Override
public Phone createPhone() {
return new XiaomiPhone();
}
@Override
public Computer createComputer() {
return new XiaomiComputer();
}
@Override
public Tablet createTablet() {
return new XiaomiTablet();
}
}
// 具体工厂:苹果工厂,创建苹果全系列产品(产品族)
public class AppleFactory implements ElectronicFactory {
@Override
public Phone createPhone() {
return new ApplePhone();
}
@Override
public Computer createComputer() {
return new AppleComputer();
}
@Override
public Tablet createTablet() {
return new AppleTablet();
}
}
// 测试类
public class AbstractFactoryTest {
public static void main(String[] args) {
// 创建小米产品族,只需要切换工厂,无需修改其他代码
ElectronicFactory xiaomiFactory = new XiaomiFactory();
xiaomiFactory.createPhone().makePhone();
xiaomiFactory.createComputer().makeComputer();
xiaomiFactory.createTablet().makeTablet();
System.out.println("--- 品牌分割线 ---");
// 创建苹果产品族,只需要更换工厂,所有产品统一切换
ElectronicFactory appleFactory = new AppleFactory();
appleFactory.createPhone().makePhone();
appleFactory.createComputer().makeComputer();
appleFactory.createTablet().makeTablet();
}
}抽象工厂模式高频面试题+详细解答
面试题1:抽象工厂模式和工厂方法模式的核心区别是什么?
详细解答:
核心区别在于创建产品的数量与维度不同,适用场景不同:
-
产品维度:工厂方法模式是一对一,一个工厂只负责创建一个产品等级的单一产品;抽象工厂模式是一对多,一个工厂负责创建一个产品族的多个相关产品,覆盖多个产品等级。
-
适用场景:工厂方法模式适合产品结构单一,只有一个产品等级的场景;抽象工厂模式适合产品结构复杂,存在多个相关联的产品等级,需要创建产品族的场景。
-
开闭原则的适配:工厂方法模式完全符合开闭原则,新增产品时只需要新增产品类和工厂类;抽象工厂模式在新增产品族时符合开闭原则(新增品牌只需要新增工厂和产品类),但在新增产品等级时违背开闭原则(比如新增手表产品,需要修改抽象工厂接口和所有的工厂实现类)。
-
抽象层级:抽象工厂模式的抽象层级更高,封装的是一整套产品的创建规范,比工厂方法模式更适合复杂的业务场景。
面试题2:抽象工厂模式的优缺点是什么?
详细解答:
- 优点:1. 保证了产品族的一致性,同一个工厂创建的产品属于同一个体系,不会出现混用的情况;
-
隔离了具体产品的创建,客户端只依赖抽象工厂和产品接口,不需要关心具体实现,降低耦合度;
-
新增产品族时,完全符合开闭原则,只需要新增对应的工厂和产品类,无需修改原有代码,扩展性强;
-
将一系列相关产品的创建逻辑集中管理,避免了多个工厂方法的分散管理,结构更清晰。
- 缺点:1. 违背开闭原则,新增产品等级时,需要修改抽象工厂接口和所有的工厂实现类,扩展难度大;
-
系统抽象性更高,结构更复杂,理解和维护成本更高;
-
产品族固定后,产品等级的变更成本极高,只适合产品族固定、产品等级变化少的场景
5. 建造者模式
核心原理
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。核心是分步构建复杂对象,链式调用设置参数,将对象的构建过程和最终的表示分离,解决多参数对象构建的痛点。
详细使用场景
-
对象的属性很多,存在大量可选参数,构造方法参数列表过长,可读性差;
-
对象的构建过程复杂,需要分步设置参数,参数之间有依赖关系或校验逻辑;
-
需要创建不可变对象,构建完成后无法修改属性,保证线程安全;
-
实际业务:Lombok的@Builder注解、MyBatis的SqlSessionFactoryBuilder、订单对象、用户信息对象、HTTP请求构建、SQL语句构建。
完整Java代码示例
javascript
// 复杂对象:用户信息,包含必填参数和大量可选参数
public class User {
// 必填参数
private final Long userId;
private final String username;
// 可选参数
private final Integer age;
private final String phone;
private final String email;
private final String address;
private final String avatar;
// 私有化构造方法,只能通过Builder构建
private User(UserBuilder builder) {
this.userId = builder.userId;
this.username = builder.username;
this.age = builder.age;
this.phone = builder.phone;
this.email = builder.email;
this.address = builder.address;
this.avatar = builder.avatar;
}
// Getter方法,无Setter,保证对象不可变
public Long getUserId() {
return userId;
}
public String getUsername() {
return username;
}
public Integer getAge() {
return age;
}
public String getPhone() {
return phone;
}
public String getEmail() {
return email;
}
public String getAddress() {
return address;
}
public String getAvatar() {
return avatar;
}
// 重写toString,方便打印
@Override
public String toString() {
return "User{" +
"userId=" + userId +
", username='" + username + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", email='" + email + '\'' +
", address='" + address + '\'' +
", avatar='" + avatar + '\'' +
'}';
}
// 建造者静态内部类
public static class UserBuilder {
// 必填参数,通过构造方法传入,保证必填
private final Long userId;
private final String username;
// 可选参数,默认值
private Integer age;
private String phone;
private String email;
private String address;
private String avatar;
// 构造方法传入必填参数,强制保证必填项
public UserBuilder(Long userId, String username) {
this.userId = userId;
this.username = username;
}
// 链式设置可选参数,返回Builder本身
public UserBuilder age(Integer age) {
this.age = age;
return this;
}
public UserBuilder phone(String phone) {
this.phone = phone;
return this;
}
public UserBuilder email(String email) {
this.email = email;
return this;
}
public UserBuilder address(String address) {
this.address = address;
return this;
}
public UserBuilder avatar(String avatar) {
this.avatar = avatar;
return this;
}
// 构建方法,最终创建User对象,可添加参数校验逻辑
public User build() {
// 可添加参数校验,比如年龄不能为负数
if (age != null && age < 0) {
throw new IllegalArgumentException("年龄不能为负数");
}
return new User(this);
}
}
}
// 测试类
public class BuilderTest {
public static void main(String[] args) {
// 链式调用构建对象,只需要设置需要的参数,可读性极强
User user = new User.UserBuilder(1L, "张三")
.age(25)
.phone("13800138000")
.email("zhangsan@163.com")
.address("北京市朝阳区")
.build();
System.out.println(user);
// 只设置必填参数和部分可选参数,灵活便捷
User user2 = new User.UserBuilder(2L, "李四")
.age(30)
.phone("13900139000")
.build();
System.out.println(user2);
}
}建造者模式高频面试题+详细解答
面试题1:建造者模式和工厂模式的核心区别是什么?
详细解答:
两者都是创建型模式,核心区别在于创建对象的复杂度、关注点不同:
-
关注点不同:工厂模式关注的是对象的创建,封装对象的实例化逻辑,不关心对象的属性如何设置;建造者模式关注的是复杂对象的分步构建过程,不仅创建对象,还精细化控制对象的属性设置、构建步骤,甚至构建顺序。
-
创建对象的复杂度不同:工厂模式创建的对象结构简单,通常是直接new一个实例即可;建造者模式创建的对象结构复杂,属性多、可选参数多,构建过程有固定的步骤,甚至有参数依赖和校验。
-
使用场景不同:工厂模式适合创建同一类型的不同实现对象,重点是"创建哪个对象";建造者模式适合创建同一个类型的复杂对象,重点是"如何分步构建对象"。
-
举例:工厂模式就像奶茶店,你点奶茶,工厂直接给你做好的奶茶,不管制作过程;建造者模式就像DIY奶茶,你可以分步选择茶底、糖度、配料、温度,一步步构建出你想要的奶茶。
面试题2:建造者模式的优缺点是什么?Lombok的@Builder注解原理是什么?
详细解答:
- 建造者模式的优点:1. 链式调用,可读性极强,解决了多参数构造方法参数列表过长、参数顺序容易出错的问题;
-
保证了对象的不可变性,构建完成后没有Setter方法,无法修改属性,天然线程安全;
-
分离了对象的构建和表示,构建过程封装在Builder类中,可灵活控制构建步骤,添加参数校验逻辑,保证对象的合法性;
-
可以分步构建对象,处理参数之间的依赖关系,比构造方法更灵活。
- 缺点:1. 增加了代码复杂度,需要额外创建Builder类,类的数量增加;
- 对于属性很少的简单对象,会过度设计,增加不必要的代码量。
- Lombok的@Builder注解原理:
Lombok的@Builder注解就是基于建造者模式实现的,编译期会自动生成静态内部Builder类,以及对应的链式Setter方法、build方法,和我们手动实现的建造者模式逻辑完全一致。它会自动处理所有属性,生成对应的链式调用方法,简化了手动编写建造者模式的代码量,本质上还是建造者模式的落地实现。
6. 原型模式
核心原理
用原型实例指定创建对象的种类,并且通过拷贝这个原型实例来创建新的对象,也就是克隆。核心是避免重复初始化对象,通过拷贝已有实例快速创建新对象,提升创建效率,降低性能开销。分为浅克隆和深克隆两种实现方式。
详细使用场景
-
对象创建成本极高,比如初始化需要读取数据库、调用远程接口、加载大量资源,重复创建会造成性能浪费;
-
需要创建大量相同或相似的对象,比如批量生成报表、批量创建订单、游戏中的大量相同角色/道具;
-
需要保存对象的状态快照,实现对象的备份和回滚;
-
实际业务:Spring中Bean的原型作用域、Java的Cloneable接口、大对象的复制、原型设计工具的组件复用。
完整Java代码示例
javascript
import java.io.*;
import java.util.List;
// 原型类,实现Cloneable接口,标记可克隆
public class Order implements Cloneable, Serializable {
private static final long serialVersionUID = 1L;
// 基础属性
private Long orderId;
private String orderNo;
private Double amount;
// 引用类型属性
private List<String> productList;
private UserInfo userInfo;
// 构造方法:模拟初始化耗时操作,比如查询数据库
public Order() {
System.out.println("Order对象初始化,执行耗时操作...");
try {
Thread.sleep(1000); // 模拟1秒耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// Getter和Setter方法
public Long getOrderId() {
return orderId;
}
public void setOrderId(Long orderId) {
this.orderId = orderId;
}
public String getOrderNo() {
return orderNo;
}
public void setOrderNo(String orderNo) {
this.orderNo = orderNo;
}
public Double getAmount() {
return amount;
}
public void setAmount(Double amount) {
this.amount = amount;
}
public List<String> getProductList() {
return productList;
}
public void setProductList(List<String> productList) {
this.productList = productList;
}
public UserInfo getUserInfo() {
return userInfo;
}
public void setUserInfo(UserInfo userInfo) {
this.userInfo = userInfo;
}
// 浅克隆:重写Object的clone方法
@Override
public Order clone() {
try {
// 调用父类的clone方法,实现浅克隆
return (Order) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException("克隆对象失败", e);
}
}
// 深克隆:通过序列化实现,完全复制所有引用类型的属性
public Order deepClone() {
try {
// 字节数组输出流,写入对象
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 字节数组输入流,读取对象,创建新的实例
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Order) ois.readObject();
} catch (Exception e) {
throw new RuntimeException("深克隆对象失败", e);
}
}
@Override
public String toString() {
return "Order{" +
"orderId=" + orderId +
", orderNo='" + orderNo + '\'' +
", amount=" + amount +
", productList=" + productList +
", userInfo=" + userInfo +
'}';
}
}
// 引用类型用户信息类,实现序列化,支持深克隆
class UserInfo implements Serializable {
private static final long serialVersionUID = 1L;
private Long userId;
private String username;
public UserInfo() {}
public UserInfo(Long userId, String username) {
this.userId = userId;
this.username = username;
}
// Getter和Setter
public Long getUserId() {
return userId;
}
public void setUserId(Long userId) {
this.userId = userId;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
@Override
public String toString() {
return "UserInfo{" +
"userId=" + userId +
", username='" + username + '\'' +
'}';
}
}
// 测试类
public class PrototypeTest {
public static void main(String[] args) {
// 1. 创建原型对象,执行初始化耗时操作
System.out.println("=== 创建原型对象 ===");
Order prototypeOrder = new Order();
prototypeOrder.setOrderId(1L);
prototypeOrder.setOrderNo("ORDER_20240501_001");
prototypeOrder.setAmount(199.0);
prototypeOrder.setProductList(List.of("商品1", "商品2", "商品3"));
prototypeOrder.setUserInfo(new UserInfo(1001L, "张三"));
System.out.println("原型对象:" + prototypeOrder);
// 2. 浅克隆:快速创建对象,无需执行初始化耗时操作
System.out.println("\n=== 浅克隆对象 ===");
long start1 = System.currentTimeMillis();
Order shallowCloneOrder = prototypeOrder.clone();
long end1 = System.currentTimeMillis();
System.out.println("浅克隆耗时:" + (end1 - start1) + "ms");
System.out.println("浅克隆对象:" + shallowCloneOrder);
System.out.println("原型对象和浅克隆对象是否是同一个实例:" + (prototypeOrder == shallowCloneOrder));
System.out.println("浅克隆对象的引用类型属性和原型是否是同一个实例:" + (prototypeOrder.getUserInfo() == shallowCloneOrder.getUserInfo()));
// 3. 深克隆:完全复制所有属性,包括引用类型
System.out.println("\n=== 深克隆对象 ===");
long start2 = System.currentTimeMillis();
Order deepCloneOrder = prototypeOrder.deepClone();
long end2 = System.currentTimeMillis();
System.out.println("深克隆耗时:" + (end2 - start2) + "ms");
System.out.println("深克隆对象:" + deepCloneOrder);
System.out.println("原型对象和深克隆对象是否是同一个实例:" + (prototypeOrder == deepCloneOrder));
System.out.println("深克隆对象的引用类型属性和原型是否是同一个实例:" + (prototypeOrder.getUserInfo() == deepCloneOrder.getUserInfo()));
}
}原型模式高频面试题+详细解答
面试题1:浅克隆和深克隆的核心区别是什么?Java中如何实现深克隆?
详细解答:
核心区别在于引用类型属性的复制方式不同,是否创建新的引用类型实例:
-
浅克隆:只复制对象本身,对于对象中的引用类型属性,只复制引用地址,不创建新的实例。也就是说,原型对象和克隆对象的引用类型属性指向同一个实例,修改其中一个的引用类型属性,另一个也会跟着变化,存在线程安全问题。
-
深克隆:完全复制对象本身,以及对象中所有的引用类型属性,所有引用类型都会创建新的实例。原型对象和克隆对象完全独立,修改任何一个的属性,都不会影响另一个,完全隔离。
Java中实现深克隆的两种常用方式:
-
序列化方式:让所有需要克隆的类实现Serializable接口,将对象写入字节数组,再从字节数组中读取出来,创建新的对象实例。这种方式实现简单,无需手动处理多层引用,适合复杂对象的深克隆,也是示例中使用的方式。
-
重写clone方法手动复制:重写clone方法,不仅克隆对象本身,还要手动克隆所有的引用类型属性,逐层实现克隆。这种方式性能更高,但实现复杂,多层引用时需要逐层处理,容易遗漏。
面试题2:原型模式的优缺点是什么?和直接new对象相比,优势在哪里?
详细解答:
- 原型模式的优点:1. 性能极高,通过克隆创建对象,避免了执行构造方法中的耗时初始化操作,尤其是大对象、初始化成本高的对象,性能提升非常明显;
-
简化对象创建过程,无需关心对象的初始化细节,直接克隆已有实例,比new对象更灵活;
-
可以保存对象的状态快照,快速创建对象的备份,实现回滚功能;
-
符合开闭原则,新增产品类型时,只需要修改原型对象,无需修改原有代码。
- 缺点:1. 深克隆实现复杂,尤其是对象存在多层嵌套引用时,需要所有引用类型都支持克隆,处理难度大;
-
克隆对象时,不会执行构造方法,可能会绕过一些初始化校验逻辑,存在一定的风险;
-
对于没有实现Cloneable或Serializable接口的类,无法使用原型模式。
和直接new对象相比的核心优势:
-
性能优势:当对象初始化需要执行耗时操作(查询数据库、调用接口、加载资源)时,new对象每次都要执行这些操作,而原型模式只需要执行一次,后续克隆直接复制内存,性能提升几个数量级;
-
灵活性优势:可以基于已有对象的状态,快速创建新的对象,无需重新设置所有属性,适合创建大量相似对象的场景;
-
隔离初始化逻辑:new对象需要知道构造方法的参数和初始化逻辑,而原型模式只需要克隆,无需关心初始化细节,降低耦合度。
(二)结构型模式(7种)
结构型模式的核心是通过类的继承、对象的组合,构建灵活的结构,在不修改原有代码的前提下,实现功能扩展、接口适配、结构优化,解决类与对象之间的组合、依赖问题。
1. 适配器模式
核心原理
将一个类的接口转换成客户端期望的另一个接口,使得原本因为接口不兼容而无法一起工作的类可以协同工作。核心是兼容转换,充当两个不兼容接口之间的"转换器",分为类适配器、对象适配器、接口适配器三种实现方式。
详细使用场景
-
兼容旧系统的接口,旧系统的接口无法修改,但需要适配新的业务需求;
-
第三方SDK的适配,封装第三方SDK的接口,对外提供统一的业务接口,避免强依赖第三方SDK;
-
不同接口之间的转换,比如Java IO中的InputStreamReader(字节流转字符流)、OutputStreamWriter;
-
日志框架适配,比如SLF4J日志门面,适配logback、log4j等不同的日志实现框架;
-
SpringMVC中的HandlerAdapter,适配不同类型的处理器接口。
完整Java代码示例
(1)对象适配器(推荐使用,组合优于继承,适用范围广)
javascript
// 客户端期望的目标接口:5V充电接口
public interface ChargeTarget {
// 输出5V电压
int output5V();
}
// 被适配的类:家用220V交流电,接口不兼容,无法直接给手机充电
public class AC220V {
public int output220V() {
System.out.println("输出家用220V交流电");
return 220;
}
}
// 对象适配器:实现目标接口,持有被适配对象的实例,完成适配转换
public class VoltageAdapter implements ChargeTarget {
// 持有被适配对象的实例,通过组合实现适配
private final AC220V ac220V;
public VoltageAdapter(AC220V ac220V) {
this.ac220V = ac220V;
}
@Override
public int output5V() {
// 获取220V电压
int srcVoltage = ac220V.output220V();
// 适配转换:220V转5V
int targetVoltage = srcVoltage / 44;
System.out.println("适配转换,输出" + targetVoltage + "V直流电");
return targetVoltage;
}
}
// 客户端:手机,只支持5V充电接口
public class Phone {
public void charge(ChargeTarget chargeTarget) {
int voltage = chargeTarget.output5V();
if (voltage == 5) {
System.out.println("电压正常,手机开始充电");
} else {
System.out.println("电压异常,无法充电");
}
}
}
// 测试类
public class ObjectAdapterTest {
public static void main(String[] args) {
// 被适配对象:220V交流电
AC220V ac220V = new AC220V();
// 适配器:转换为5V充电接口
ChargeTarget adapter = new VoltageAdapter(ac220V);
// 客户端:手机充电
Phone phone = new Phone();
phone.charge(adapter);
}
}(2)类适配器(通过继承实现,有局限性,不推荐)
javascript
// 类适配器:继承被适配类,实现目标接口
public class ClassVoltageAdapter extends AC220V implements ChargeTarget {
@Override
public int output5V() {
// 继承父类的220V输出方法
int srcVoltage = output220V();
// 适配转换
int targetVoltage = srcVoltage / 44;
System.out.println("类适配器转换,输出" + targetVoltage + "V直流电");
return targetVoltage;
}
}
// 测试类
public class ClassAdapterTest {
public static void main(String[] args) {
ChargeTarget adapter = new ClassVoltageAdapter();
Phone phone = new Phone();
phone.charge(adapter);
}
}(3)接口适配器(缺省适配器,适配接口的部分方法)
javascript
import java.util.function.Consumer;
// 复杂的大接口,有多个方法
public interface ComplexFunction {
void function1();
void function2();
void function3();
void function4();
void function5();
}
// 接口适配器:抽象类,空实现接口的所有方法
public abstract class FunctionAdapter implements ComplexFunction {
@Override
public void function1() {}
@Override
public void function2() {}
@Override
public void function3() {}
@Override
public void function4() {
@Override
public void function5() {}
}
// 客户端:只需要实现需要的方法,无需实现所有方法
public class FunctionClient {
public static void main(String[] args) {
// 只需要重写function1方法,其他方法使用默认空实现
ComplexFunction function = new FunctionAdapter() {
@Override
public void function1() {
System.out.println("只执行function1方法");
}
};
function.function1();
}
}适配器模式高频面试题+详细解答
面试题1:类适配器和对象适配器的核心区别是什么?为什么推荐使用对象适配器?
详细解答:
核心区别在于适配的实现方式不同,对被适配类的耦合度不同:
-
实现方式:类适配器通过继承被适配类,实现目标接口完成适配;对象适配器通过组合持有被适配类的实例,实现目标接口完成适配。
-
耦合度:类适配器继承被适配类,耦合度高,Java是单继承,类适配器只能适配一个被适配类,无法适配多个;对象适配器通过组合持有被适配对象,耦合度低,可以适配一个被适配类的所有子类,甚至可以同时适配多个被适配对象,灵活性极强。
-
局限性:类适配器会继承被适配类的所有方法,暴露了不必要的方法,增加了客户端的使用成本;对象适配器封装了被适配对象,只暴露目标接口的方法,符合迪米特法则。
-
扩展性:类适配器如果被适配类有子类,无法适配子类的扩展;对象适配器可以传入被适配类的任意子类,支持扩展,符合开闭原则。
推荐使用对象适配器的原因:
对象适配器遵循组合优于继承的设计原则,耦合度更低,灵活性更强,没有单继承的局限性,扩展性更好,不会暴露被适配类的内部细节,符合面向对象的设计规范,适用范围更广。
面试题2:适配器模式和装饰器模式的核心区别是什么?
详细解答:
两者都实现了目标接口,都持有被处理对象的实例,结构相似,但核心设计目的、使用场景完全不同:
-
核心目的不同:适配器模式的核心是接口转换,解决两个接口不兼容的问题,让原本无法一起工作的类可以协同工作;装饰器模式的核心是功能增强,在不修改原有对象的前提下,动态给对象添加额外的功能,不改变原有接口。
-
接口关系不同:适配器模式会将被适配对象的接口转换成完全不同的另一个接口,客户端使用的是新的目标接口;装饰器模式实现的是和被装饰对象相同的接口,客户端使用方式和原有对象完全一致,甚至感知不到装饰器的存在。
-
与被处理对象的关系不同:适配器模式是"适配"被适配对象,两者没有必然的层级关系,只是做接口转换;装饰器模式和被装饰对象属于同一个类型体系,是"is-a"的关系,可以多层嵌套装饰。
-
使用场景不同:适配器模式用于兼容旧接口、第三方SDK适配、接口转换;装饰器模式用于动态扩展对象功能,替代继承,比如Java IO流的装饰器实现。
面试题3:SpringMVC中的HandlerAdapter是如何使用适配器模式的?为什么要使用适配器模式?
详细解答:
SpringMVC中的HandlerAdapter是适配器模式的经典落地实现,核心作用是适配不同类型的处理器(Handler),让DispatcherServlet可以统一处理所有类型的处理器。
- 实现原理:- SpringMVC中有多种类型的处理器,比如实现了Controller接口的处理器、实现了HttpRequestHandler接口的处理器、加了@RequestMapping注解的方法处理器,它们的处理方法完全不同,接口不兼容。
-
SpringMVC定义了HandlerAdapter目标接口,为每一种处理器类型提供了对应的适配器实现类(比如RequestMappingHandlerAdapter、SimpleControllerHandlerAdapter),每个适配器负责适配一种处理器类型,封装处理器的调用逻辑。
-
DispatcherServlet接收到请求后,找到对应的处理器,再找到适配该处理器的HandlerAdapter,通过适配器统一调用处理器的处理方法,无需关心处理器的具体类型和调用方式。
- 为什么要使用适配器模式:- 解决接口不兼容的问题,让DispatcherServlet可以用统一的方式调用所有类型的处理器,无需为每一种处理器类型写单独的处理逻辑,避免了大量的if-else判断;
-
符合开闭原则,新增处理器类型时,只需要新增对应的HandlerAdapter实现类,无需修改DispatcherServlet的原有代码,扩展性极强;
-
隔离了处理器的调用细节,DispatcherServlet只依赖HandlerAdapter接口,不依赖具体的处理器实现,降低耦合度。
2. 桥接模式
核心原理
将抽象部分与实现部分分离,使它们都可以独立地变化,用组合代替继承,解决多层继承导致的"类爆炸"问题。核心是拆分多个独立变化的维度,让每个维度都可以独立扩展,而不是通过继承叠加所有变化。
详细使用场景
-
一个类存在多个独立变化的维度,且每个维度都需要独立扩展,比如:- 消息发送:消息类型(短信、邮件、微信)+ 消息紧急程度(普通、紧急、加急);
-
图形绘制:形状(圆形、矩形、三角形)+ 颜色(红、绿、蓝、黑);
-
跨平台开发:操作系统(Windows、Mac、Linux)+ 硬件类型(电脑、平板、手机);
-
多层继承导致类数量爆炸,继承体系过于臃肿,无法灵活扩展;
-
希望通过组合代替继承,降低类之间的耦合度,提升系统的灵活性。
完整Java代码示例
javascript
// 实现维度接口:消息发送方式,独立变化维度1
public interface MessageSender {
// 发送消息
void send(String message, String receiver);
}
// 实现维度具体实现:短信发送
public class SmsSender implements MessageSender {
@Override
public void send(String message, String receiver) {
System.out.println("【短信发送】给" + receiver + "发送短信:" + message);
}
}
// 实现维度具体实现:邮件发送
public class EmailSender implements MessageSender {
@Override
public void send(String message, String receiver) {
System.out.println("【邮件发送】给" + receiver + "发送邮件:" + message);
}
// 实现维度具体实现:微信发送
public class WechatSender implements MessageSender {
@Override
public void send(String message, String receiver) {
System.out.println("【微信发送】给" + receiver + "发送微信消息:" + message);
}
}
// 抽象维度:消息,独立变化维度2,桥接实现维度
public abstract class Message {
// 桥接:持有实现维度的引用,组合代替继承
protected MessageSender messageSender;
public Message(MessageSender messageSender) {
this.messageSender = messageSender;
}
// 抽象发送方法
public abstract void sendMessage(String message, String receiver);
}
// 抽象维度扩展:普通消息
public class NormalMessage extends Message {
public NormalMessage(MessageSender messageSender) {
super(messageSender);
}
@Override
public void sendMessage(String message, String receiver) {
System.out.println("【普通消息】");
messageSender.send(message, receiver);
}
}
// 抽象维度扩展:紧急消息
public class UrgentMessage extends Message {
public UrgentMessage(MessageSender messageSender) {
super(messageSender);
}
@Override
public void sendMessage(String message, String receiver) {
System.out.println("【紧急消息】");
messageSender.send("【紧急】" + message, receiver);
}
}
// 抽象维度扩展:特急消息
public class SpecialUrgentMessage extends Message {
public SpecialUrgentMessage(MessageSender messageSender) {
super(messageSender);
}
@Override
public void sendMessage(String message, String receiver) {
System.out.println("【特急消息】");
messageSender.send("【特急!请立即处理】" + message, receiver);
// 额外功能:特急消息抄送管理员
System.out.println("已抄送管理员:" + message);
}
}
// 测试类
public class BridgeTest {
public static void main(String[] args) {
// 1. 普通短信消息
Message normalSms = new NormalMessage(new SmsSender());
normalSms.sendMessage("明天上午10点开会", "张三");
System.out.println("--- 分割线 ---");
// 2. 紧急邮件消息
Message urgentEmail = new UrgentMessage(new EmailSender());
urgentEmail.sendMessage("服务器出现异常,请尽快排查", "运维组");
System.out.println("--- 分割线 ---");
// 3. 特急微信消息
Message specialWechat = new SpecialUrgentMessage(new WechatSender());
specialWechat.sendMessage("线上出现严重BUG,用户无法下单", "技术负责人");
// 扩展:新增消息类型/发送方式,只需要新增对应的类,无需修改原有代码
}
}桥接模式高频面试题+详细解答
面试题1:桥接模式的核心思想是什么?解决了什么问题?
详细解答:
桥接模式的核心思想是**"拆分变化维度,用组合代替继承,让抽象和实现可以独立扩展"**。它将系统中多个独立变化的维度拆分开,通过组合的方式建立关联,而不是通过继承将多个维度的变化叠加在一起,让每个维度都可以独立地扩展和变化,互不影响。
桥接模式主要解决了两个核心问题:
-
解决多层继承导致的"类爆炸"问题:当一个类有多个变化维度时,如果用继承实现,每个维度的扩展都会导致子类数量成倍增加。比如示例中,3种发送方式+3种消息类型,用继承需要9个子类,新增1种发送方式需要新增3个子类;用桥接模式只需要6个类,新增1种发送方式只需要新增1个类,大幅减少了类的数量。
-
解决继承带来的强耦合问题:继承是静态的强耦合,父类的变化会影响所有子类,无法灵活调整;桥接模式通过组合关联两个维度,耦合度极低,两个维度可以独立扩展,互不影响,完全符合开闭原则。
-
提升系统的灵活性:可以在运行时动态切换两个维度的实现,比如示例中,同一个消息类型可以动态切换发送方式,同一个发送方式也可以动态切换消息类型,灵活性极强
面试题2:桥接模式和适配器模式的区别是什么?
详细解答:
两者都是结构型模式,都通过组合降低耦合度,但核心设计目的、使用场景、结构完全不同:
-
核心目的不同:桥接模式的核心是拆分变化维度,将多个独立变化的维度拆分开,让它们可以独立扩展,解决的是系统设计初期的结构问题;适配器模式的核心是接口转换,让原本不兼容的接口可以一起工作,解决的是系统运行期的兼容问题,通常是后期补救使用。
-
结构不同:桥接模式是双向的,两个独立的维度都可以独立扩展,通过桥接建立关联,是多对多的关系;适配器模式是单向的,只是将被适配对象的接口转换成目标接口,是一对一的适配关系。
-
使用场景不同:桥接模式用于系统设计初期,当一个类有多个独立变化的维度,需要灵活扩展时使用,是前期的架构设计模式;适配器模式用于系统后期维护,需要兼容旧接口、第三方SDK,适配不兼容的接口时使用,是后期的兼容补救模式。
-
抽象层级不同:桥接模式有两个独立的抽象层级,抽象和实现都可以独立扩展,抽象层级更高;适配器模式没有独立的抽象层级,只是做接口的转换,结构更简单。
3. 组合模式
核心原理
将对象组合成树形结构以表示"部分-整体"的层次结构,使得客户端对单个对象(叶子节点)和组合对象(分支节点)的使用具有一致性。核心是统一处理叶子节点和分支节点,客户端无需区分是单个对象还是组合对象,简化树形结构的处理。
详细使用场景
-
处理树形结构的数据,比如文件系统(文件+文件夹)、组织架构(部门+员工)、菜单系统(菜单+子菜单);
-
XML/JSON的节点解析、HTML的DOM树处理;
-
电商的商品分类(一级分类+二级分类+三级分类);
-
权限系统的菜单权限、角色权限的树形结构处理;
-
办公系统的审批流程、组织架构的层级处理。
完整Java代码示例
javascript
java
import java.util.ArrayList;
import java.util.List;
// 抽象组件:统一的文件系统节点接口,叶子节点和分支节点统一实现
public interface FileSystemNode {
// 获取节点名称
String getName();
// 获取节点大小
long getSize();
// 打印节点信息
void print(String prefix);
// 添加子节点(分支节点实现,叶子节点抛出异常)
default void add(FileSystemNode node) {
throw new UnsupportedOperationException("叶子节点不支持添加子节点");
}
// 移除子节点
default void remove(FileSystemNode node) {
throw new UnsupportedOperationException("叶子节点不支持移除子节点");
}
// 获取子节点
default List<FileSystemNode> getChildren() {
throw new UnsupportedOperationException("叶子节点不支持获取子节点");
}
}
// 叶子节点:文件,没有子节点
public class FileNode implements FileSystemNode {
private final String name;
private final long size;
public FileNode(String name, long size) {
this.name = name;
this.size = size;
}
@Override
public String getName() {
return name;
}
@Override
public long getSize() {
return size;
}
@Override
public void print(String prefix) {
System.out.println(prefix + "├─ 文件:" + name + " (" + size + "KB)");
}
}
// 组合节点(分支节点):文件夹,包含子节点(文件/子文件夹)
public class DirectoryNode implements FileSystemNode {
private final String name;
private final List<FileSystemNode> children = new ArrayList<>();
public DirectoryNode(String name) {
this.name = name;
}
@Override
public String getName() {
return name;
}
@Override
public long getSize() {
// 递归计算所有子节点的大小总和
long totalSize = 0;
for (FileSystemNode child : children) {
totalSize += child.getSize();
}
return totalSize;
}
@Override
public void print(String prefix) {
System.out.println(prefix + "└─ 文件夹:" + name + " (" + getSize() + "KB)");
// 递归打印所有子节点
for (FileSystemNode child : children) {
child.print(prefix + " ");
}
}
@Override
public void add(FileSystemNode node) {
children.add(node);
}
@Override
public void remove(FileSystemNode node) {
children.remove(node);
}
@Override
public List<FileSystemNode> getChildren() {
return children;
}
}
// 测试类
public class CompositeTest {
public static void main(String[] args) {
// 1. 创建根文件夹
DirectoryNode root = new DirectoryNode("根目录");
// 2. 创建文件
FileNode readme = new FileNode("README.md", 10);
FileNode license = new FileNode("LICENSE", 5);
root.add(readme);
root.add(license);
// 3. 创建src文件夹
DirectoryNode srcDir = new DirectoryNode("src");
FileNode mainJava = new FileNode("Main.java", 20);
FileNode utilsJava = new FileNode("Utils.java", 30);
srcDir.add(mainJava);
srcDir.add(utilsJava);
root.add(srcDir);
// 4. 创建resources文件夹
DirectoryNode resourcesDir = new DirectoryNode("resources");
FileNode configYml = new FileNode("application.yml", 15);
resourcesDir.add(configYml);
// 子文件夹
DirectoryNode staticDir = new DirectoryNode("static");
FileNode indexHtml = new FileNode("index.html", 50);
staticDir.add(indexHtml);
resourcesDir.add(staticDir);
root.add(resourcesDir);
// 5. 统一处理:打印整个树形结构,无需区分文件和文件夹
System.out.println("文件系统树形结构:");
root.print("");
// 6. 统一处理:获取根目录总大小,无需区分文件和文件夹
System.out.println("\n根目录总大小:" + root.getSize() + "KB");
}
}组合模式高频面试题+详细解答
面试题1:组合模式的透明式和安全式有什么区别?
详细解答:
组合模式分为透明式和安全式两种实现方式,核心区别在于是否将子节点的管理方法暴露在抽象组件中,客户端是否需要区分叶子节点和分支节点:
- 透明式组合模式:- 实现方式:将添加、移除、获取子节点的管理方法,全部定义在抽象组件接口中,叶子节点和分支节点都实现这些方法。叶子节点不支持这些方法,会抛出UnsupportedOperationException异常。
-
优点:完全透明,客户端无需区分叶子节点和分支节点,统一使用抽象组件接口处理所有节点,使用方式完全一致,符合组合模式的核心设计思想。
-
缺点:不安全,叶子节点不支持子节点管理方法,调用时会抛出运行时异常,编译期无法发现。
-
示例:本文中的代码就是透明式实现,抽象接口中定义了add、remove等方法,叶子节点默认抛出异常。
- 安全式组合模式:- 实现方式:抽象组件接口中只定义叶子节点和分支节点共有的方法(比如getName、getSize),将添加、移除、获取子节点的管理方法,只定义在分支节点的实现类中。
-
优点:安全,叶子节点没有子节点管理方法,不会出现误调用的情况,编译期就能校验,不会出现运行时异常。
-
缺点:不透明,客户端需要区分叶子节点和分支节点,必须将分支节点强制转换为具体实现类,才能调用子节点管理方法,失去了组合模式的一致性优势,增加了客户端的使用成本。
- 选型建议:- 优先使用透明式组合模式,符合组合模式的核心设计思想,客户端使用更简单,绝大多数业务场景都适用;
- 只有在对安全性要求极高,绝对不允许出现运行时异常的场景,才使用安全式组合模式。
面试题2:组合模式的优缺点是什么?
详细解答
- 优点:1. 统一处理树形结构,客户端无需区分叶子节点和组合对象,使用方式完全一致,简化了客户端的代码,降低了使用成本;
-
符合开闭原则,新增叶子节点类型或组合节点类型时,无需修改原有代码,扩展性极强;
-
可以灵活构建复杂的树形结构,通过递归组合,可以轻松构建任意层级的树形结构,结构清晰,便于维护;
-
简化了树形结构的遍历和处理,通过递归可以轻松实现整个树形结构的遍历、计算、操作,无需复杂的分支判断。
- 缺点:1. 透明式实现存在安全性问题,叶子节点调用子节点管理方法会抛出运行时异常;
-
当树形结构层级过深时,递归处理可能会出现栈溢出问题,需要优化递归逻辑;
-
对于叶子节点和组合节点差异过大的场景,使用组合模式会导致抽象接口的设计过于臃肿,不符合接口隔离原则。
4. 装饰器模式
核心原理
动态地给一个对象添加额外的功能,相比继承的静态扩展,装饰器模式支持灵活的多层动态扩展,完全遵循开闭原则。核心是对原有对象无侵入的功能增强,不改变原有对象的接口,客户端使用装饰后的对象和原有对象的方式完全一致。
详细使用场景
-
需要动态给对象添加功能,且功能可以灵活添加、移除、多层叠加;
-
继承无法实现灵活扩展,或者继承体系过于臃肿,子类数量过多;
-
Java IO流体系,比如BufferedReader、BufferedInputStream、DataInputStream等,都是装饰器模式的经典实现;
-
缓存功能增强,给数据查询接口添加缓存装饰,无需修改原有查询逻辑;
-
权限校验、日志记录、性能监控等非业务功能的增强,和核心业务逻辑解耦;
-
营销系统的优惠叠加,比如满减、折扣、优惠券的灵活叠加。
完整Java代码示例
// 抽象组件:咖啡接口,装饰器和被装饰对象都实现这个接口
javascript
public interface Coffee {
// 获取咖啡描述
String getDescription();
// 获取咖啡价格
double getPrice();
}
// 具体组件(被装饰对象):基础美式咖啡
public class Americano implements Coffee {
@Override
public String getDescription() {
return "标准美式咖啡";
}
@Override
public double getPrice() {
return 22.0;
}
}
// 具体组件(被装饰对象):基础拿铁咖啡
public class Latte implements Coffee {
@Override
public String getDescription() {
return "标准拿铁咖啡";
}
@Override
public double getPrice() {
return 28.0;
}
}
// 抽象装饰器:实现咖啡接口,持有被装饰对象的引用
public abstract class CoffeeDecorator implements Coffee {
// 持有被装饰的咖啡对象
protected Coffee decoratedCoffee;
public CoffeeDecorator(Coffee coffee) {
this.decoratedCoffee = coffee;
}
// 默认委托给被装饰对象,子类重写实现功能增强
@Override
public String getDescription() {
return decoratedCoffee.getDescription();
}
@Override
public double getPrice() {
return decoratedCoffee.getPrice();
}
}
// 具体装饰器:添加牛奶
public class MilkDecorator extends CoffeeDecorator {
public MilkDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return super.getDescription() + " + 全脂牛奶";
}
@Override
public double getPrice() {
return super.getPrice() + 6.0;
}
}
// 具体装饰器:添加焦糖糖浆
public class CaramelDecorator extends CoffeeDecorator {
public CaramelDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return super.getDescription() + " + 焦糖糖浆";
}
@Override
public double getPrice() {
return super.getPrice() + 4.0;
}
}
// 具体装饰器:添加奶油顶
public class CreamDecorator extends CoffeeDecorator {
public CreamDecorator(Coffee coffee) {
super(coffee);
}
@Override
public String getDescription() {
return super.getDescription() + " + 奶油顶";
}
@Override
public double getPrice() {
return super.getPrice() + 5.0;
}
}
// 测试类
public class DecoratorTest {
public static void main(String[] args) {
// 1. 基础美式咖啡
Coffee coffee = new Americano();
System.out.println(coffee.getDescription() + " | 价格:" + coffee.getPrice() + "元");
// 2. 动态添加牛奶
coffee = new MilkDecorator(coffee);
System.out.println(coffee.getDescription() + " | 价格:" + coffee.getPrice() + "元");
// 3. 动态添加焦糖糖浆
coffee = new CaramelDecorator(coffee);
System.out.println(coffee.getDescription() + " | 价格:" + coffee.getPrice() + "元");
// 4. 动态添加奶油顶
coffee = new CreamDecorator(coffee);
System.out.println(coffee.getDescription() + " | 价格:" + coffee.getPrice() + "元");
System.out.println("--- 分割线 ---");
// 灵活组合:拿铁+奶油顶+焦糖,无需创建大量子类
Coffee latte = new CreamDecorator(new CaramelDecorator(new Latte()));
System.out.println(latte.getDescription() + " | 价格:" + latte.getPrice() + "元");
}
}装饰器模式高频面试题+详细解答
面试题1:装饰器模式和继承的核心区别是什么?为什么推荐使用装饰器模式?
详细解答:
两者都可以实现类的功能扩展,但核心扩展方式、灵活性、耦合度完全不同:
-
扩展方式:继承是静态扩展,编译期就确定了扩展的功能,子类一旦编译完成,就无法动态改变扩展的功能;装饰器模式是动态扩展,运行期可以灵活地给对象添加、移除、叠加扩展功能,甚至可以动态调整叠加顺序,灵活性极强。
-
类数量:继承实现多个功能的叠加,会导致子类数量爆炸。比如示例中,3种配料+2种基础咖啡,用继承需要2*(2^3)=16个子类;用装饰器模式只需要6个类,新增配料只需要新增1个装饰器类,大幅减少了类的数量。
-
耦合度:继承是强耦合,子类依赖父类的实现,父类的修改会影响所有子类,不符合开闭原则;装饰器模式是弱耦合,装饰器和被装饰对象都依赖抽象接口,互不依赖具体实现,新增装饰器无需修改原有代码,完全符合开闭原则。
-
功能叠加:继承无法灵活调整功能的叠加顺序,每个子类的功能是固定的;装饰器模式可以灵活调整装饰器的叠加顺序,实现不同的功能组合,比如先加牛奶再加焦糖,和先加焦糖再加牛奶,都可以灵活实现。
推荐使用装饰器模式的原因:
装饰器模式遵循组合优于继承的设计原则,耦合度更低,灵活性更强,支持动态扩展,不会导致类爆炸,完全符合开闭原则,是比继承更优秀的扩展方式,尤其是在需要多个功能灵活叠加的场景,优势极其明显。
面试题2:Java IO流中是如何使用装饰器模式的?举例说明
详细解答:
Java IO流体系是装饰器模式最经典的落地实现,整个IO流的设计完全基于装饰器模式,分为字节流和字符流两大体系,核心结构和我们的示例完全一致:
- 核心结构对应:- 抽象组件:InputStream/OutputStream(字节流)、Reader/Writer(字符流),对应示例中的Coffee接口,定义了统一的读写方法。
-
具体组件(被装饰对象):FileInputStream、ByteArrayInputStream、FileReader等基础流,对应示例中的Americano、Latte,实现了基础的读写功能,是被装饰的原始对象。
-
抽象装饰器:FilterInputStream/FilterOutputStream、FilterReader/FilterWriter,对应示例中的CoffeeDecorator,实现了抽象组件接口,持有被装饰流的引用,默认委托给被装饰流处理。
-
具体装饰器:BufferedInputStream(缓冲增强)、DataInputStream(数据类型读写增强)、LineNumberReader(行号增强)、BufferedReader等,对应示例中的MilkDecorator等,给基础流动态添加额外的功能,不改变原有流的接口。
- 具体使用示例:
java
// 基础组件:文件字节输入流,实现基础的文件读取功能
InputStream fis = new FileInputStream("test.txt");
// 装饰器1:缓冲流,给基础流添加缓冲功能,提升读取性能
InputStream bis = new BufferedInputStream(fis);
// 装饰器2:数据流,给流添加基本数据类型的读取功能
DataInputStream dis = new DataInputStream(bis);
和咖啡示例完全一致,可以多层装饰,动态给基础流添加功能,客户端使用装饰后的流和基础流的方式完全一致,都实现了InputStream接口,无需区分。
- 设计优势:
通过装饰器模式,Java IO流实现了功能的灵活扩展,新增功能只需要新增对应的装饰器类,无需修改原有流的代码,完全符合开闭原则;同时可以灵活组合不同的装饰器,实现不同的功能组合,避免了继承导致的类爆炸问题。