论文题目:Low-Light Salient Object Detection by Learning to Highlight the Foreground Objects(通过学习突出显示前景对象的低光显著目标检测)
期刊:IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY
摘要:以往的显著物体检测方法主要集中在有利光照条件下,而忽略了低光照条件下的性能,严重阻碍了相关下游任务的开展。在这项工作中,考虑到在此任务中标注大规模标签是不切实际的,我们提出了一个框架(HDNet)来使用合成图像检测低光图像中的显著目标。我们的HDNet由前景突出子网络(HNet)和外观感知检测子网络(DNet)组成,两者都可以以端到端方式共同学习。具体来说,为了突出前景目标,我们设计了HNet来估计参数,自适应调整每个像素的动态范围,并通过突出目标标签的弱监督信号进行训练。此外,我们设计了一个简单的检测网络(DNet),其中包含上下文特征融合模块和多尺度特征提炼模块,用于细节特征融合和提炼。此外,我们还贡献了第一个用于弱光图像显著性物体检测的标注数据集(SOD-LL),包括6,000张标记合成图像(SOD-LLS)和2,000张标记真实图像(SOD-LLR)。在SOD-LL等野外弱光视频上的实验结果证明了该方法的有效性和泛化能力。
我们的数据集和代码可在https://github.com/Ylinyuan/HDNet上获得。

在黑暗中寻找目标:HDNet如何突破低光照显著性检测的困境
引言:当AI在黑暗中"失明"
想象一下:一个训练有素的AI视觉系统在白天能够准确识别和分割出图像中的显著目标,但一到夜晚或光线不足的环境,就像突然"失明"一样,性能急剧下降。这不是科幻场景,而是当前计算机视觉领域面临的真实挑战。
显著性目标检测(Salient Object Detection, SOD)是计算机视觉中的一项基础任务,旨在自动识别和分割图像中最吸引人注意力的目标。这项技术在视频监控、自动驾驶、图像编辑等领域有着广泛应用。然而,几乎所有现有的SOD方法都有一个共同的"软肋"------它们在光照充足的理想条件下训练,一旦遇到低光照场景就会失效。
来自湖南师范大学和西安大略大学的研究团队在IEEE TCSVT 2024上发表了一篇开创性论文,提出了HDNet框架,专门解决低光照条件下的显著性目标检测问题。更令人兴奋的是,他们还构建了首个针对这一任务的大规模数据集SOD-LL。
问题的本质:为什么低光照如此棘手?
不仅仅是"看不清"
低光照SOD的难度远超我们的直觉想象。研究团队发现,低光照场景带来了三大核心挑战:
1. 目标-背景融合问题 在低光照下,前景目标的部分或全部区域会与背景完全融合,即使对人眼来说也难以区分边界。这不是简单的"模糊",而是信息的实质性丢失。
2. 极端对比度差异 同一场景中可能存在极亮和极暗的区域,造成前景和背景之间的强烈对比。这种对比度失衡会严重干扰特征提取。
3. 多样化的光照退化 低光照不是单一问题,而是包括:
- 极低照明(几乎全黑)
- 彩色光照(如霓虹灯环境)
- 背光场景(目标被光源背后)
- 昏暗照明(整体亮度不足但有微弱光源)
现有方案为何失效?
研究者们尝试过的直接解决方案包括:
方案1: 使用通用图像增强 问题:传统图像增强方法(如Zero-DCE)会同时增强背景和前景,甚至放大噪声,反而模糊了显著目标的特征。
方案2: 在正常图像上训练的模型直接应用 问题:存在严重的域偏移------模型从未见过低光照场景,泛化能力极差。
方案3: 收集真实低光照数据进行标注 问题:在低光照图像上进行像素级精确标注极其困难,甚至人类标注者也难以准确判断目标边界。
HDNet的创新解决方案
核心理念:"先高亮,再检测"
HDNet的设计哲学非常直观但巧妙:不是增强整张图像,而是选择性地高亮前景目标。这一看似简单的思路转变,解决了传统方法的根本问题。
架构解析
HDNet由两个紧密耦合的子网络组成:
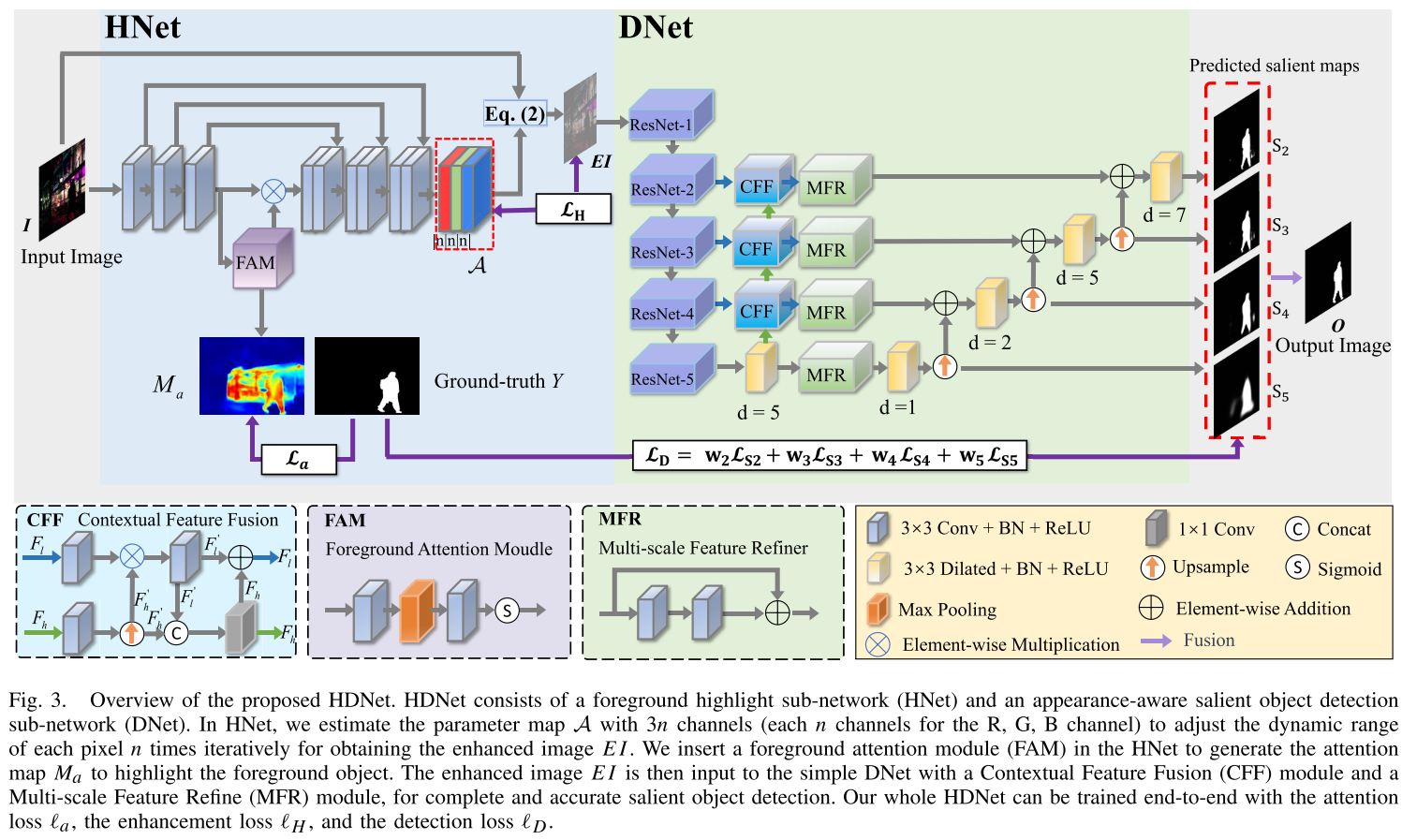
1. 前景高亮子网络(HNet)
核心创新:前景注意力模块(FAM)
传统的图像增强是"一视同仁"的,而HNet通过FAM学会了"区别对待":
- 对前景目标区域:大幅提升亮度,增强细节
- 对背景区域:适度调整或保持原样
技术实现细节:
增强公式:
EI(x) = I(x) + A(x)·I(x)·(1 - I(x))其中A(x)是网络学习的像素级参数,范围在-1,1。通过迭代n次,可以实现更大的动态范围调整。
关键特性:
- 弱监督学习:仅使用显著目标的标注(不需要增强图像的ground truth)
- 端到端训练:与检测网络联合优化
- 自适应调整:每个像素的增强程度由网络根据任务需求自动学习
2. 外观感知检测子网络(DNet)
在获得前景高亮的图像后,DNet负责精确检测和分割。它包含两个关键模块:
上下文特征融合模块(CFF)
- 融合高层语义特征和低层细节特征
- 采用选择性融合策略:用高层特征对低层特征进行"筛选"
- 通过元素级乘法和拼接实现互补
多尺度特征精炼模块(MFR)
- 使用不同膨胀率的卷积捕获多尺度信息
- 自顶向下逐步精炼特征
- 采用残差结构保持特征完整性
损失函数设计
HDNet使用三个损失函数联合训练:
L_total = η_a·L_a + η_h·L_H + η_d·L_D- L_a (注意力损失): 监督FAM学习前景区域
- L_H (增强损失): 包含空间一致性、曝光控制、色彩恒常性等约束
- L_D (检测损失): 像素位置感知损失,监督多尺度预测
开创性贡献:SOD-LL数据集

为什么需要新数据集?
现有的SOD数据集(如DUTS、HKU-IS)都是在良好光照下采集的。缺乏低光照数据严重制约了该领域的研究发展。
SOD-LL的构成
训练集:SOD-LLS (6,000张合成图像)
研究团队采用两种策略生成逼真的低光照图像:
-
CycleGAN风格转换 (2,601张)
- 在DUTS-TR和ExDark之间训练无配对图像转换模型
- 保留语义内容,转换光照风格
- 平均亮度:15.98 nit
-
Photoshop动态范围调整 (3,399张)
- 四步操作:降低亮度(-50) → 应用"NightFromDay"滤镜(70%透明度) → 添加"Foggy"效果(50%透明度) → 提升对比度(+30)
- 模拟真实低光照退化过程
测试集:SOD-LLR (2,000张真实图像)
- 从ExDark精选并人工标注
- 三位标注者协作确保质量
- 涵盖12种低光照场景类型
- 平均亮度:21.99 nit
数据集统计

| 特性 | SOD-LLS | SOD-LLR |
|---|---|---|
| 图像数量 | 6,000 | 2,000 |
| 类别数 | 40个子类 | 12种场景 |
| 平均亮度 | 15.98 nit | 21.99 nit |
| 目标实例数 | 5,260 | 1,834 |
| 场景类型 | 室内/室外 | 室内/室外 |

实验结果:全面超越现有方法
定量性能
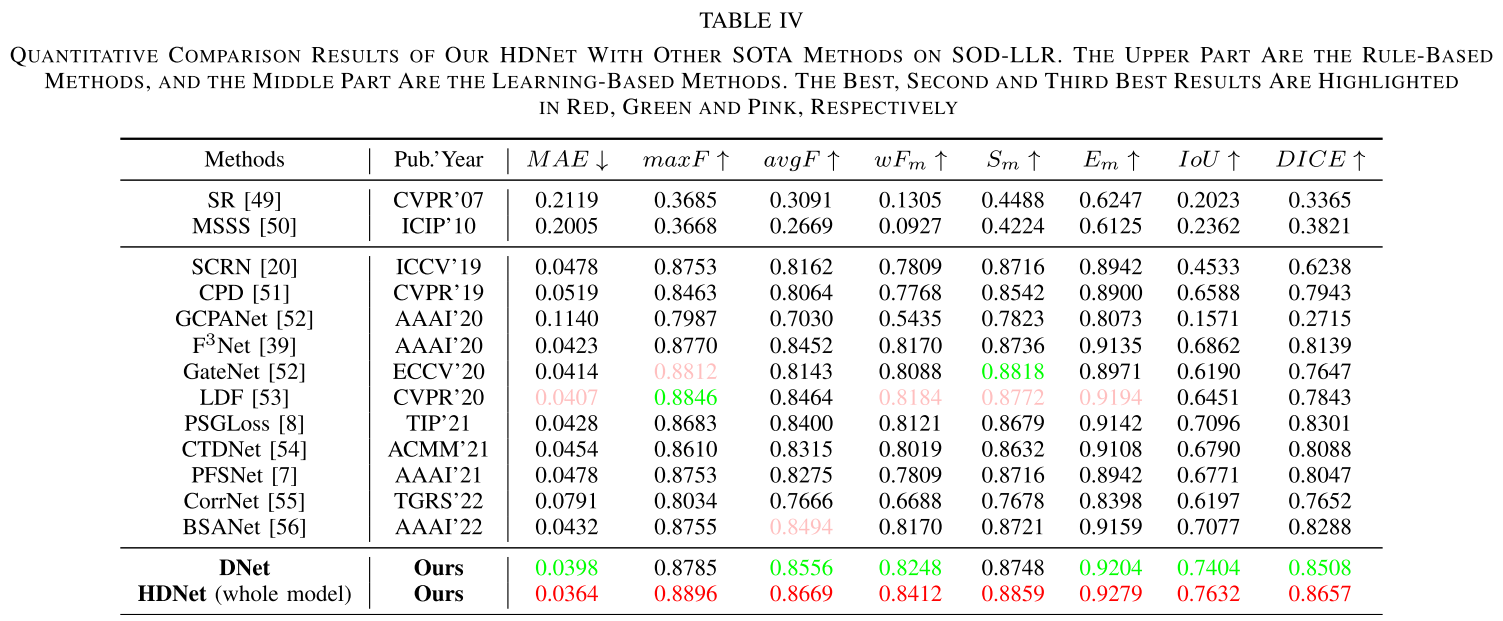
在SOD-LLR测试集上,HDNet在所有评价指标上都取得了最佳性能:
核心指标对比:
- MAE (越低越好): 0.0364 vs 次优0.0398 (提升10.57%)
- IoU (越高越好): 0.7632 vs 次优0.7258 (提升5.23%)
- avgF (越高越好): 0.8669 vs 次优0.8460 (提升2.06%)
与使用Zero-DCE增强后的最佳方法相比,HDNet的MAE降低了21.6%,充分证明了端到端联合训练的优势。
消融研究的启示
研究团队进行了细致的消融实验,得出了几个重要发现:
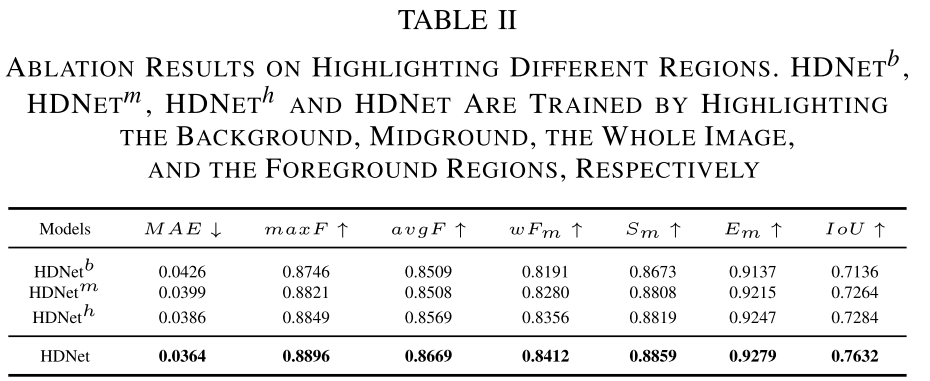
1. 高亮前景的必要性
- 高亮前景区域: MAE = 0.0364 ✓
- 高亮背景区域: MAE = 0.0426 (最差)
- 高亮全图: MAE = 0.0390
- 高亮随机区域: MAE = 0.0386
这证明了选择性增强前景是关键,而不是简单的全局增强。
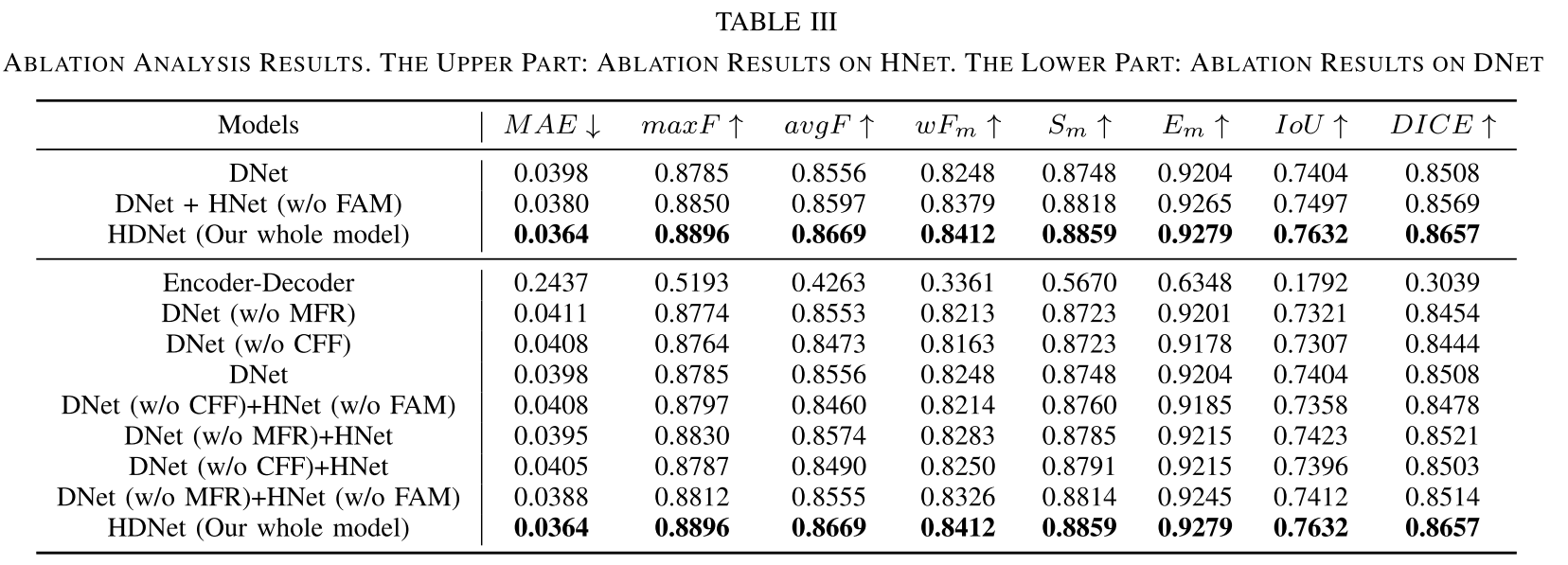
2. 每个模块的贡献 去除任何一个关键模块都会导致性能下降:
- 去掉HNet: MAE ↑ 9.3%
- 去掉FAM: MAE ↑ 4.4%
- 去掉CFF: MAE ↑ 6.6%
- 去掉MFR: MAE ↑ 8.5%
3. 不同增强方法的对比
| 增强方法 + SOD | MAE | avgF |
|---|---|---|
| Zero-DCE + DNet | 0.0464 | 0.8607 |
| EnlightenGAN + DNet | 0.0503 | 0.8581 |
| URetinex-Net + DNet | 0.0504 | 0.8346 |
| HDNet (端到端) | 0.0364 | 0.8669 |
定性分析:视觉效果对比

论文展示了几个极具挑战性的案例:
案例1: 小尺度目标(第1行)
- 其他方法:完全遗漏或仅检测到部分
- HDNet:准确定位并完整分割
案例2: 强对比度场景(第2行)
- 其他方法:误将高亮背景标记为前景
- HDNet:准确区分前景和强光背景
案例3: 极低光照+复杂场景(第3行)
- 其他方法:目标边界模糊,背景干扰严重
- HDNet:清晰的目标轮廓,背景抑制良好
泛化能力验证

令人惊喜的是,HDNet不仅在低光照场景表现出色,在其他场景也展现了强大的泛化能力:
正常光照数据集:
- PASCAL-S: Sm = 0.8758 (第1名)
- HKU-IS: Sm = 0.9358 (第1名)
- DUTS-TE: MAE = 0.0364 (最优)
低光照视频:
- 比专门的视频SOD方法(DCFNet, STVS, RCRNet)表现更好
- 时空一致性更强,减少闪烁
技术深入:为什么HDNet如此有效?
1. 任务导向的增强策略
关键洞察:图像增强应该服务于下游任务,而非追求视觉质量。
传统增强方法优化目标:
min ||Enhanced_Image - Ground_Truth||HDNet的优化目标:
min L_detection(Segmentation, GT_Mask) + λ·L_enhancement这意味着增强的好坏不是由人眼判断,而是由检测性能决定。这种设计让HNet学会了"忽略背景,突出目标"。
2. 弱监督学习的威力
FAM模块仅使用显著目标的二值掩码作为监督信号,却能学会复杂的前景-背景区分。这得益于:
- 梯度反向传播:检测损失的梯度会传到FAM,告诉它哪些区域的增强有助于检测
- 注意力机制:通过sigmoid函数产生0,1的权重,实现软性选择
- 端到端优化:增强和检测联合训练,自动找到最优平衡
3. 多尺度特征的充分利用
DNet通过CFF和MFR模块实现了有效的多尺度信息融合:
- CFF:确保低层细节不被高层语义淹没
- MFR:使用膨胀卷积扩大感受野,不增加参数
- 深度监督:在多个尺度输出预测,每个尺度都有监督信号
4. 数据增强策略
使用两种风格的合成数据训练,提高了模型的鲁棒性:
- CycleGAN风格:保留了真实低光照的统计特性
- PS风格:提供了更多样化的退化模式
局限性与未来方向
尽管HDNet取得了显著成果,研究团队也诚实地指出了一些局限:
1. 高分辨率图像的挑战
在1024×1024或更高分辨率的图像上,性能有所下降。原因:
- 模型的感受野相对于图像尺寸变小
- 需要更多的下采样层来捕获全局上下文
- 计算资源限制
可能的解决方向:
- 金字塔式的多尺度输入
- 更高效的注意力机制(如Swin Transformer)
- 分块处理+全局一致性约束
2. 视频的时间一致性
虽然在视频上有良好表现,但缺乏显式的时间建模:
- 相邻帧之间可能有轻微闪烁
- 没有利用运动信息
未来改进:
- 引入光流或可变形卷积
- 添加时间一致性约束
- 探索视频Transformer架构
3. 极端场景的鲁棒性
在以下场景仍有提升空间:
- 动态光照(如闪烁的灯光)
- 强烈的镜头光晕
- 运动模糊+低光照
4. 计算效率
虽然已经相对高效,但对于实时应用(如自动驾驶)仍需优化:
- 当前:15ms/帧 (≈67 FPS)
- 目标:< 10ms/帧 (>100 FPS)
优化方向:
- 知识蒸馏到轻量级模型
- 量化和剪枝
- 神经架构搜索(NAS)
实践启示与应用前景
HDNet的成功为其他视觉任务提供了宝贵经验:
设计原则
- 任务导向的预处理: 预处理应该针对具体任务优化,而非通用的质量提升
- 端到端学习: 让模型自动学习最优的预处理策略
- 弱监督的力量: 巧妙的架构设计可以从少量监督信号中学到复杂模式
- 数据合成的价值: 精心设计的合成数据可以有效弥补真实数据的不足
应用场景
1. 夜间视频监控
- 自动识别和跟踪关注对象
- 在极低光照下保持高准确率
- 减少误报和漏报
2. 自动驾驶
- 夜间行人和车辆检测
- 隧道等低光照环境的目标识别
- 提高夜间驾驶安全性
3. 低光照图像编辑
- 自动抠图和背景替换
- 智能曝光调整
- 夜间摄影后期处理
4. 医学影像
- 低剂量CT/X光图像中的病灶检测
- 内窥镜图像中的组织分割
- 减少辐射暴露同时保持诊断准确性
5. 水下/雾天视觉
- 类似的低可见度场景
- 可以迁移HDNet的设计思想
- 针对性地调整增强策略
结论:迈向全天候视觉AI
HDNet的工作标志着计算机视觉向"全天候"能力迈出了重要一步。通过巧妙的架构设计和任务导向的优化,它证明了AI系统可以在极端光照条件下保持可靠的性能。
更重要的是,这项研究提供了一个可供借鉴的范式:
- 识别现有方法在特定条件下的失效模式
- 构建针对性的数据集和评测基准
- 设计任务导向的解决方案而非通用方法
- 通过端到端学习自动优化各个模块
随着SOD-LL数据集的发布和HDNet代码的开源,我们期待看到更多研究者在此基础上进行创新,推动低光照视觉理解走向成熟。
思考题
- HDNet的"先高亮再检测"范式是否可以推广到其他低质量图像任务(如去模糊、去噪等)?
- 如何设计更高效的注意力机制来处理高分辨率图像?
- 能否用生成式模型(如Diffusion Models)进一步改进图像增强效果?
- 如何将HDNet扩展到3D目标检测(如点云、RGB-D)?
如果您觉得这篇分析有帮助,欢迎分享并关注更多AI前沿研究解读!