Note:强化学习(一)
2026 | ming

本系列文章并非我以往的入门教程风格,不追求面面俱到、循序渐进地带新手走进强化学习。相反,它是我个人在学习强化学习过程中所整理笔记的一次重新梳理与分享。
如果你已经学过强化学习的基础知识,但因为时间久远而遗忘了大部分细节,希望快速重温核心概念与典型算法,那么这份笔记将非常适合你。它默认你已有一定的理论背景(例如知道什么是状态、动作、奖励、策略、价值函数等),因此不会从零解释基本术语,而是着重帮你把零散的记忆"串"起来。
笔记中附带的所有代码均可直接复制执行,且每一行代码都配有详细的注释,清晰说明核心逻辑、参数含义及实现思路。这些代码的可扩展性很高,你可以直接以这些代码为模板,根据特定的任务场景、数据特点,灵活调整参数设置、优化模型结构,快速适配不同的强化学习任务,无需从零搭建代码框架,大大节省开发和调试时间。
本系列所有代码和笔记都会以jupyter笔记的形式开源,本系列末尾会附上Github链接。
参考文献
1 斋藤康毅. 深度学习入门4:强化学习. 北京: 人民邮电出版社, 2024.
2 赵世钰. 强化学习的数学原理. BiliBili, 2022. www.bilibili.com/video/BV1sd...
3 肖智清. 强化学习:原理与Python实现. 北京: 机械工业出版社, 2019.
4 王树森. 深度强化学习(DRL). BiliBili, 2021. www.bilibili.com/video/BV12o...
5 李理的博客. 强化学习相关笔记. fancyerii.github.io/
6 东川路第一可爱猫猫虫. 个人哔哩哔哩主页. BiliBili. space.bilibili.com/675505667
requirements
text
Python 3.10+
numpy
matplotlib
tqdm
gymnasium[box2d]
torch
array-api-compat一. 基础概念
在任何涉及数学推导的领域里,先统一符号约定是最基本的一步。强化学习(Reinforcement Learning, RL)的文献虽然众多,但核心符号体系其实高度一致------这也意味着,只要我们把这些符号"认全了",后续阅读强化学习相关论文都会顺畅很多。
下面我们把强化学习中最核心的一组符号做一个集中梳理,后面推导时会频繁用到。
1.1 符号约定
- vπ(s) :状态价值函数------在状态 s 下,遵循策略 π 的长期期望奖励
- π(a∣s) :策略------在状态 s 下,选择动作 a 的概率
- p(s′∣s,a) :状态转移概率------在状态 s 执行动作 a ,转移到下一个状态 s′ 的概率
- r(s,a,s′) :即时奖励------在状态 s 执行动作 a 、转移到 s′ 后获得的奖励
- r(s,a) :即时奖励 ------在状态 s 执行动作 a 时获得的奖励,这两种写法取决于具体问题的建模方式。
- qπ(s,a) :动作状态价值函数(Q函数)------在状态 s 遵循策略 π 、执行动作 a 后的长期期望奖励
- γ :折扣因子------控制未来奖励的权重,一般取0.9(值越接近1,越重视长期奖励;越接近0,越重视即时奖励)
- v∗(s) 、 q∗(s,a) :最优价值函数------遵循最优策略时,对应的状态/动作状态价值
- μ∗(s) :最优策略------在状态 s 下,能获得最大价值的动作(本质是对Q函数取 argmax)
1.2 状态价值函数
状态价值函数衡量的是"处于状态 s ,遵循策略 π ,未来能拿到的平均奖励"。它的核心公式有两种等价形式,本质是对"所有可能动作、所有可能转移状态"的期望求和:
vπ(s)=a,s′∑π(a∣s)p(s′∣s,a){r(s,a,s′)+γvπ(s′)}
也可以拆分成"先对动作求和,再对转移状态求和",逻辑更清晰:
vπ(s)=a∑π(a∣s)s′∑p(s′∣s,a){r(s,a,s′)+γvπ(s′)}
直观解释:在状态 s 下,先按策略 π(a∣s) 选择动作 a ,再按转移概率 p(s′∣s,a) 转移到 s′ ,此时能拿到即时奖励 r(s,a,s′) ,再加上未来状态 s′ 的价值(乘以折扣因子 γ ),把所有这些情况的期望加起来,就是状态 s 的价值。
1.3 动作状态价值函数
Q函数比状态价值函数更"具体"------它固定了"状态 s + 动作 a ",衡量的是"在状态 s 做动作 a ,之后遵循策略 π 的长期期望奖励"。公式如下:
qπ(s,a)=s′∑p(s′∣s,a){r(s,a,s′)+γa′∑π(a′∣s′)qπ(s′,a′)}
直观解释:固定动作 a 后,我们只需要考虑所有可能的转移状态 s′ ,拿到即时奖励后,后续按照策略 π 选择下一个动作 a′ ,对应的Q函数是 qπ(s′,a′) ,求和后就是当前" s,a "对的价值。
补充关联:状态价值函数其实是Q函数对动作的期望------ vπ(s)=∑aπ(a∣s)qπ(s,a) ,因为状态价值是"所有可能动作的Q值,按策略概率加权求和"。
1.4 贝尔曼最优状态价值函数
做强化学习的最终目标,是找到最优策略 μ∗ ,而最优策略的前提是找到最优价值函数 v∗(s) 和 q∗(s,a) ------贝尔曼最优方程,就是定义"最优价值"的核心方程,重点在于"最大化"(区别于普通贝尔曼方程的"期望")。
最优状态价值,是"在状态 s 下,选择最优动作后,未来能拿到的最大长期期望奖励"。公式中用 maxa 替代了普通贝尔曼方程中的"对动作求和",因为最优策略会直接选择能最大化价值的动作,而不是按概率选择:
v∗(s)=amaxs′∑p(s′∣s,a){r(s,a,s′)+γv∗(s′)}
1.5 贝尔曼最优Q函数
最优Q函数,是"在状态 s 做动作 a 后,后续都遵循最优策略的最大长期期望奖励"。公式中,后续的价值不再是"按策略求和",而是对下一个状态的最优Q函数取最大值:
q∗(s,a)=s′∑p(s′∣s,a){r(s,a,s′)+γa′maxq∗(s′,a′)}
1.6 贝尔曼最优策略
有了最优Q函数,最优策略就很简单了------在每个状态 s ,选择能让 q∗(s,a) 最大的动作即可,公式如下:
μ∗(s)=aargmax q∗(s,a)=aargmaxs′∑p(s′∣s,a){r(s,a,s′)+γv∗(s′)}
直观解释:argmax的作用就是"找到能让后面表达式最大的动作 a ",所以最优策略本质上就是"贪心选择"------每个状态下,选当前看起来最好的动作。
二. 简单策略评估与改进
2.1 求解给定策略下的价值函数
当我们确定一个策略 π 后,需要知道这个策略的"好坏"(即每个状态的价值),这就是策略评估,最常用的是迭代法,逻辑很简单:初始化价值→不断迭代更新,直到收敛。
具体步骤:
- 初始化所有状态的价值函数 Vπ(s)=0 (初始值可以任意设,常用0,不影响最终收敛结果);
- 迭代更新(直到价值函数变化量小于阈值,认为收敛):
for k=1,2,...,n do:for s in every_state do:Vk+1(s)=a∑π(a∣s)s′∑p(s′∣s,a){r(s,a,s′)+γVk(s′)}
说明: Vk(s) 表示第 k 次迭代后的状态价值, Vk+1(s) 是更新后的价值,每次更新都用前一次的价值来计算当前状态的价值。
简化情况:如果状态迁移是确定的(即 p(s′∣s,a)=1 ,在状态 s 做动作 a ,只会转移到唯一的 s′ ),公式可以简化为:
Vk+1(s)=a∑π(a∣s){r(s,a,s′)+γVk(s′)}
2.2 从价值函数到最优策略
当我们得到某个策略的价值函数后,就可以通过"贪心改进"得到更优的策略,重复"评估→改进"的过程,最终就能得到最优策略。
具体步骤:
for s in every_state do:μ(s)=aargmaxs′∑p(s′∣s,a){r(s,a,s′)+γv(s′)}
简化情况:同样,若状态迁移确定( p(s′∣s,a)=1 ),公式简化为:
μ(s)=aargmax{r(s,a,s′)+γv(s′)}
直观解释:对每个状态,遍历所有可能的动作,计算每个动作对应的"即时奖励+未来状态价值",选择最大值对应的动作,就是当前状态下的最优动作,所有状态的最优动作组合起来,就是最优策略。
三. 价值迭代法
3.1 数学理论
在已知环境模型(状态转移概率和奖励函数)的前提下,求解最优策略有两类经典途径:策略迭代和价值迭代。这一节我们聚焦后者------价值迭代。价值迭代的思路非常"暴力":既然最优价值函数满足 Bellman 最优方程,那我们就直接把这个方程当作更新规则,反复迭代直到收敛。不需要显式地维护策略,也不需要交替进行策略评估与改进。
价值迭代法也有它的局限性:由于需要遍历环境的所有状态、所有动作进行计算,当状态空间过大时,它的计算成本会急剧上升,所以实际中更多用于处理状态数较少的小规模问题,这也是我们在使用时需要注意的点。但在理论学习和简单环境中,价值迭代依然是最直观的入门方法之一。
和大多数迭代方法一样,我们先给所有状态的价值函数赋一个初始值,最常用的就是全部初始化为0,即:
V0(s)=0,∀s∈S
这里的 V0(s) 表示初始时刻(第0轮迭代)状态s的价值, S 是所有状态的集合。这个初始化很简单,本质上是"先假设所有状态暂时没有价值",后续通过迭代逐步修正。
迭代的核心是利用贝尔曼最优方程,对每个状态 s 的价值进行更新。对于第 k 轮迭代,我们通过第k轮的价值函数 Vk(s′) ,计算第 k+1 轮的价值函数 Vk+1(s) ,公式如下:
Vk+1(s)=amaxs′∑p(s′∣s,a){r(s,a,s′)+γVk(s′)}
如果环境是确定性的(此时 p(s′∣s,a)=1 ,其他 s′′的转移概率为0),那么上面的公式可以简化为:
Vk+1(s)=amax{r(s,a,s′)+γVk(s′)}
我们不断重复上述更新步骤,直到价值函数收敛------也就是当两次迭代之间的价值变化量小于一个预设的极小值 ϵ (比如 maxs∣Vk+1(s)−Vk(s)∣<ϵ )时,就可以停止迭代了。
从理论上来说,价值迭代法经过无限次迭代后,一定会收敛到最优价值函数 V∗(s) 。此时,我们只需要基于这个最优价值函数,采用2.2节所示公式,就能得到最优策略 π∗ 。
3.2 网格世界环境搭建
在开始上手价值迭代法代码之前,我们首先需要一个能够直观理解、便于调试的环境。强化学习领域中,网格世界(GridWorld) 是一个经典的入门环境,它非常简单易懂。
如下的GridWorld代码是一个二维平面,智能体可以在格子间上下左右移动。我们的目标很简单:从起点出发,走到终点(绿色格子),途中尽可能避开黑色障碍物和红色陷阱从而得到更多的奖励。
- 状态 :每个格子坐标
(y, x)就是一个状态。 - 动作:4 个离散动作------上、下、左、右。
- 奖励 :
- 到达目标格子 →
+100(终止) - 踩到陷阱 → 负奖励(
-1, -2, -3, -5,颜色越深惩罚越大) - 撞墙或撞障碍物 → 停在原地,获得当前格子的奖励(通常是
0) - 普通地面 →
0
- 到达目标格子 →
GridWorld 类提供了标准的强化学习环境接口:
reset():把智能体放回起点,开始新的一局。step(action):执行一个动作,返回(next_state, reward, done)。如果碰到目标,done=True表示回合结束。render():可视化当前网格------用不同颜色区分起点、目标、陷阱、障碍物,还能额外绘制价值函数或策略箭头。
如下GridWorld类代码带有详细注释,除了render方法不需要掌握理解外,其它部分都非常简单易懂,相信你完全可以看懂。
python
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
class GridWorld:
"""
一个简单的网格世界环境。
属性:
height (int): 网格高度(行数)
width (int): 网格宽度(列数)
start_state (tuple): 起始坐标
goal_state (tuple): 目标坐标
action_space (list): 可用的动作列表
reward_map (np.array): 存储每个位置奖励的矩阵
"""
# 定义动作常量
ACTION_UP = 0
ACTION_DOWN = 1
ACTION_LEFT = 2
ACTION_RIGHT = 3
# 动作对应的坐标增量
ACTIONS = {
ACTION_UP: (-1, 0),
ACTION_DOWN: (1, 0),
ACTION_LEFT: (0, -1),
ACTION_RIGHT: (0, 1),
}
ACTION_NAMES = {0: "↑", 1: "↓", 2: "←", 3: "→"}
# 定义陷阱等级和对应的颜色(颜色越深代表惩罚越大)
TRAP_LEVELS = [-1, -2, -3, -5]
# 颜色映射:Hex颜色码
TRAP_COLORS = {
-1: "#ffcccc", # 极浅红
-2: "#ff9999", # 浅红
-3: "#ff5555", # 中红
-5: "#880000", # 深红
}
def __init__(
self,
height,
width,
goal_state,
start_state=(0, 0),
obstacle_ratio=0.1,
trap_ratio=0.15,
random_seed=None,
):
"""
初始化网格世界
Args:
height (int): 高度
width (int): 宽度
goal_state (tuple): 目标位置
start_state (tuple): 起始位置
obstacle_ratio (float): 障碍物(不可通行)生成的概率
trap_ratio (float): 陷阱(负奖励)生成的概率
random_seed (int): 随机种子
"""
if random_seed is not None:
np.random.seed(random_seed)
self.height = height
self.width = width
self.start_state = start_state
self.goal_state = goal_state
self.now_state = start_state
# 初始化奖励地图
self.reward_map = self._generate_grid_world(obstacle_ratio, trap_ratio)
# 确保目标点的奖励是最大的
self.target_reward = 100
self.reward_map[self.goal_state] = self.target_reward
# 确保起点不是障碍物或陷阱
self.reward_map[self.start_state] = 0
def _generate_grid_world(self, obstacle_ratio, trap_ratio):
"""
生成基础网格,包含普通地块、多等级陷阱和障碍物
"""
# 1. 生成随机数矩阵
rand_grid = np.random.rand(self.height, self.width)
# 2. 初始化网格,dtype=object 允许存储 None 和 负数
grid = np.zeros((self.height, self.width), dtype=object)
# 3. 设置障碍物 (None)
# 概率范围:[0, obstacle_ratio)
obstacle_mask = rand_grid < obstacle_ratio
grid[obstacle_mask] = None
# 4. 设置陷阱
# 概率范围:[obstacle_ratio, obstacle_ratio + trap_ratio)
trap_mask = (rand_grid >= obstacle_ratio) & (
rand_grid < (obstacle_ratio + trap_ratio)
)
# 统计陷阱数量
num_traps = np.sum(trap_mask)
if num_traps > 0:
# 从预定义的陷阱等级中随机选择
traps = np.random.choice(self.TRAP_LEVELS, size=num_traps)
grid[trap_mask] = traps
return grid
def step(self, action):
"""
执行动作一步
Args:
action (int): 动作索引
Returns:
next_state (tuple): 下一时刻的状态
reward (float): 获得的奖励
done (bool): 是否结束
"""
# 1. 获取下一状态
move = self.ACTIONS[action]
dy, dx = move
next_y = self.now_state[0] + dy
next_x = self.now_state[1] + dx
next_state = (next_y, next_x)
# 2. 检查边界和障碍物
# 如果超出边界或是障碍物(值为None),则状态不改变
if not (0 <= next_y < self.height and 0 <= next_x < self.width):
next_state = self.now_state # 撞墙
elif self.reward_map[next_state] is None:
next_state = self.now_state # 撞障碍物
# 3. 计算奖励
# 奖励由到达的位置决定
# 注意:如果是"撞墙"情况,next_state == now_state,reward 就是当前格子的奖励(通常是0)
reward = self.reward_map[next_state]
# 判断是否结束
done = next_state == self.goal_state
# 更新当前状态
self.now_state = next_state
return next_state, reward, done
def reset(self):
"""重置环境"""
self.now_state = self.start_state
return self.now_state
def render(self, value_map=None, policy_map=None):
"""
可视化当前网格世界
Args:
value_map (np.array): 价值函数矩阵,形状与网格相同
policy_map (np.array): 策略矩阵,里面是0,1,2,3,形状与网格相同
"""
fig, ax = plt.subplots(figsize=(self.width + 1, self.height + 1))
ax.set_xlim(0, self.width)
ax.set_ylim(self.height, 0)
ax.set_xticks(np.arange(self.width))
ax.set_yticks(np.arange(self.height))
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.grid(which="major", axis="both", linestyle="-", color="gray", linewidth=1)
for y in range(self.height):
for x in range(self.width):
is_goal = x == self.goal_state[1] and y == self.goal_state[0]
color = "white" # 默认普通地面
if self.reward_map[y, x] is None:
color = "black" # 障碍物
elif (y, x) == self.goal_state:
color = "lightgreen" # 目标
elif (y, x) == self.start_state:
color = "lightblue" # 起点
elif self.reward_map[y, x] < 0:
color = self.TRAP_COLORS[self.reward_map[y, x]]
rect = patches.Rectangle(
(x, y), 1, 1, linewidth=0, edgecolor="none", facecolor=color
)
ax.add_patch(rect)
if value_map is not None:
val = value_map[y, x]
ax.text(
x + 0.5,y + 0.5,f"{val:.1f}",ha="center",va="center",color="blue",fontsize=10,fontweight="bold",
)
elif policy_map is not None:
action = policy_map[y, x]
if self.reward_map[y, x] is not None and not is_goal:
arrow_str = self.ACTION_NAMES[action]
ax.text(x + 0.5,y + 0.5,arrow_str,ha="center",va="center",color="black",fontsize=20,alpha=0.5,
)
else:
if (y, x) == self.start_state:
ax.text(x + 0.5,y + 0.5,"S",ha="center",va="center",fontsize=15,fontweight="bold",
)
elif (y, x) == self.goal_state:
ax.text(x + 0.5,y + 0.5,"G",ha="center",va="center",fontsize=15,fontweight="bold",
)
elif self.reward_map[y, x] is None:
pass
elif self.reward_map[y, x] < 0:
ax.text(x + 0.5,y + 0.5,f"{self.reward_map[y, x]}",ha="center",va="center",color="black",fontsize=10,
)
if (y, x) == self.now_state:
# 在当前状态画一个黄色的圆圈
circle = patches.Circle((x + 0.5, y + 0.5),0.3,linewidth=2,edgecolor="gold",facecolor="none",
)
ax.add_patch(circle)
plt.title("GridWorld Visualization")
plt.show()我们可以尝试来使用一下这个环境,如下代码所示,每次执行,都会随机生成不同的网格世界环境。
python
# 创建环境
env = GridWorld(
height=5, # 网格世界的高
width=5, # 网格世界的宽
goal_state=(4, 4), # 终点坐标
start_state=(0, 0), # 起点坐标
obstacle_ratio=0.15, # 障碍物(墙)生成的概率
trap_ratio=0.3, # 陷阱生成的概率
)
env.render() # 可视化当前环境3次不同的可视化结果如图3.1所示:
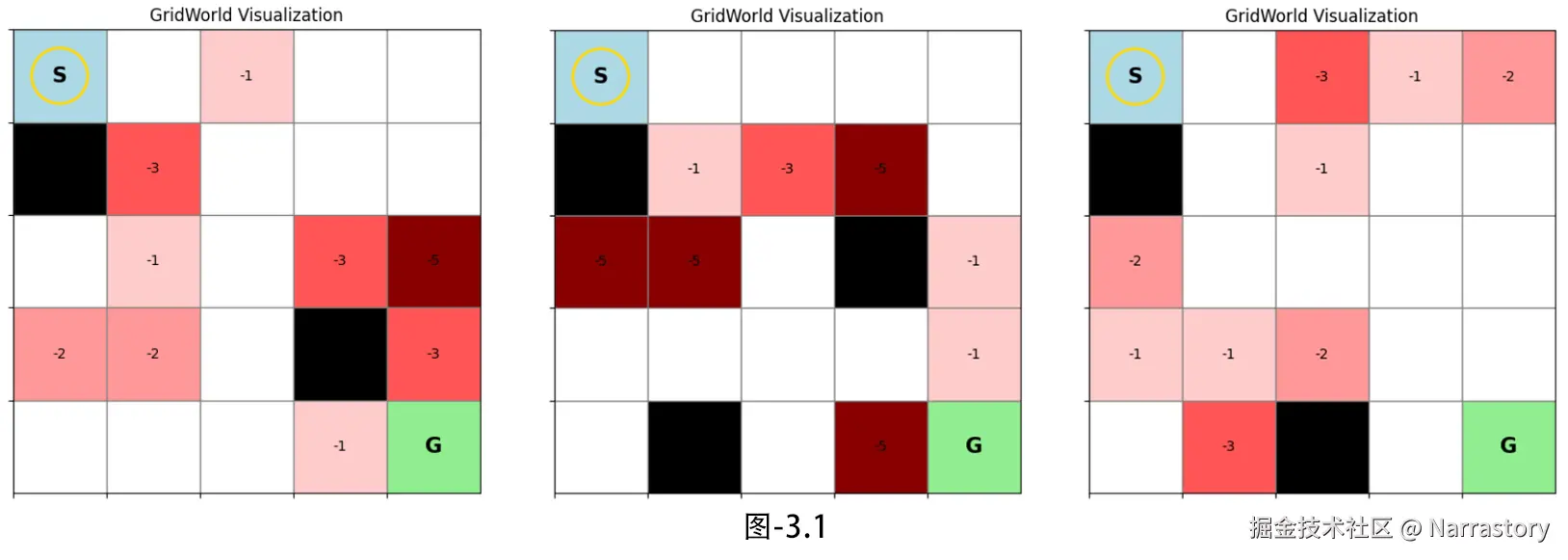
render方法不传入额外参数时,显示基础地图:起点(蓝色 S)、终点(绿色 G)、陷阱(从浅红到深红,并标有负奖励值)、障碍物(黑色)。- 传入
value_map时,在每个格子中央显示该状态的价值估计值(例如迭代过程中的价值函数)。 - 传入
policy_map时,在每个可通行的格子中画出动作箭头(↑↓←→),直观展示当前策略。
此外,render 还会用一个金色的圆圈高亮智能体的当前位置。
3.3 价值迭代与最优策略
如下的value_iteration函数就是价值迭代算法,这份代码主要做了如下的这些事:
- 初始化 :将所有状态的价值函数 V(s) 设为 0。障碍物位置会始终被标记为
np.nan,不参与更新;目标状态的价值也保持为 0(因为到达目标后任务结束,不再有后续奖励)。 - 迭代更新 :在指定的
num_iterations轮中,每一轮都扫描整个网格世界(除了障碍物和目标)。- 对每个状态 s,枚举所有可能的动作(上、下、左、右)。
- 模拟执行该动作后的下一状态 s′(如果撞墙或撞障碍物则停留在原地)。
- 从环境中取出即时奖励
reward(通常到达目标为正奖励,其他为负或零)。 - 计算该动作的 Q 值 : Q(s,a)=r+γ⋅V(s′)。
- 记录所有动作中最大的 Q 值,作为 s 的新价值 Vnew(s)。
- 收敛 :迭代结束后,价值函数 V 已经非常接近最优价值函数 V∗。
- 输出 :返回最终的价值矩阵,存储了每个格子的价值,障碍物位置为
np.nan,把这个价值矩阵作为参数输入到网格环境的render方法中就可以可视化每一个格子的价值。
python
def value_iteration(env, num_iterations, gamma):
"""
对给定网格世界执行价值迭代算法。
Args:
env (GridWorld): 网格世界环境实例
num_iterations (int): 迭代次数
gamma (float): 折扣因子
Returns:
np.ndarray: 形状 (height, width) 的价值地图,障碍物位置为 np.nan
"""
height, width = env.height, env.width
# 初始化价值函数,全部为 0
V = np.zeros((height, width), dtype=float)
# 找出障碍物位置,后续跳过不更新
obstacle_mask = env.reward_map == None
# 目标状态坐标
goal_y, goal_x = env.goal_state
for _ in range(num_iterations):
V_new = V.copy()
# 遍历所有格子
for y in range(height):
for x in range(width):
# 跳过障碍物和目标状态
if obstacle_mask[y, x] or (y == goal_y and x == goal_x):
continue
# 计算当前状态下所有可能动作的 Q 值,取最大值
best_q = -np.inf
for action in env.ACTIONS.keys():
dy, dx = env.ACTIONS[action]
next_y = y + dy
next_x = x + dx
# 处理边界和障碍物碰撞(与 env.step 逻辑一致)
if not (0 <= next_y < height and 0 <= next_x < width):
next_y, next_x = y, x # 撞墙留在原地
elif env.reward_map[next_y, next_x] is None:
next_y, next_x = y, x # 撞障碍物留在原地
# 获取奖励(下一状态的即时奖励)
reward = env.reward_map[next_y, next_x]
# 计算动作价值
q = reward + gamma * V[next_y, next_x]
if q > best_q:
best_q = q
V_new[y, x] = best_q
V = V_new
# 将障碍物位置设为 np.nan,便于观察和处理
V[obstacle_mask] = np.nan
return V光有最优价值 V∗ 还不够------我们真正想要的是一个可执行的策略:在每个状态下,智能体应该往哪个方向走。这时候就需要参考第2.2节,从最优价值函数推导出最优策略。
extract_policy 函数就是完成这个"最后一公里"的工具:给定 V∗ ,求出最优策略 π∗。
- 输入 :价值迭代得到的
value_map(最优价值函数 V∗),以及环境模型。 - 输出:一个与网格等大的策略矩阵,每个元素是动作索引(0=上,1=下,2=左,3=右),障碍物和目标位置标记为 -1。将这个策略矩阵作为参数输入到网格环境的render方法中就可以可视化每一个格子的策略。
python
def extract_policy(env, value_map, gamma):
"""
根据价值地图提取最优确定性策略。
Args:
env (GridWorld): 网格世界环境实例
value_map (np.ndarray): 价值迭代得到的价值矩阵,障碍物位置为 np.nan
gamma (float): 折扣因子(与价值迭代时相同)
Returns:
np.ndarray: 形状 (height, width) 的策略矩阵,元素为动作索引 0(上) 1(下) 2(左) 3(右),
障碍物和目标位置标记为 -1
"""
height, width = env.height, env.width
policy = np.full((height, width), -1, dtype=int) # 默认 -1 表示无需策略
# 障碍物掩码
obstacle_mask = env.reward_map == None
goal_y, goal_x = env.goal_state
for y in range(height):
for x in range(width):
# 跳过障碍物和目标状态(目标无需动作)
if obstacle_mask[y, x] or (y == goal_y and x == goal_x):
continue
best_action = -1
best_q = -np.inf
# 遍历所有动作
for action in env.ACTIONS.keys():
dy, dx = env.ACTIONS[action]
next_y = y + dy
next_x = x + dx
# 碰撞检测(与 value_iteration 中完全一致)
if not (0 <= next_y < height and 0 <= next_x < width):
next_y, next_x = y, x
elif env.reward_map[next_y, next_x] is None:
next_y, next_x = y, x
# 奖励:进入下一状态的即时奖励
reward = env.reward_map[next_y, next_x]
# 下一状态的价值(注意 value_map 中障碍物是 nan,但此处下一状态不会是障碍物)
next_value = value_map[next_y, next_x]
q = reward + gamma * next_value
if q > best_q:
best_q = q
best_action = action
policy[y, x] = best_action
return policy3.4 结果展示
python
# 创建环境
env = GridWorld(
height=5,
width=5,
goal_state=(4, 4),
start_state=(0, 0),
obstacle_ratio=0.15,
trap_ratio=0.3,
)
env.render() # 可视化后如图3.2
# 运行价值迭代
gamma = 0.9 # 折扣因子
iterations = 100 # 迭代次数
value_map = value_iteration(env, iterations, gamma)
policy_map = extract_policy(env, value_map, gamma)
env.render(value_map=value_map) # 可视化后如图3.3
env.render(policy_map=policy_map) # 可视化后如图3.4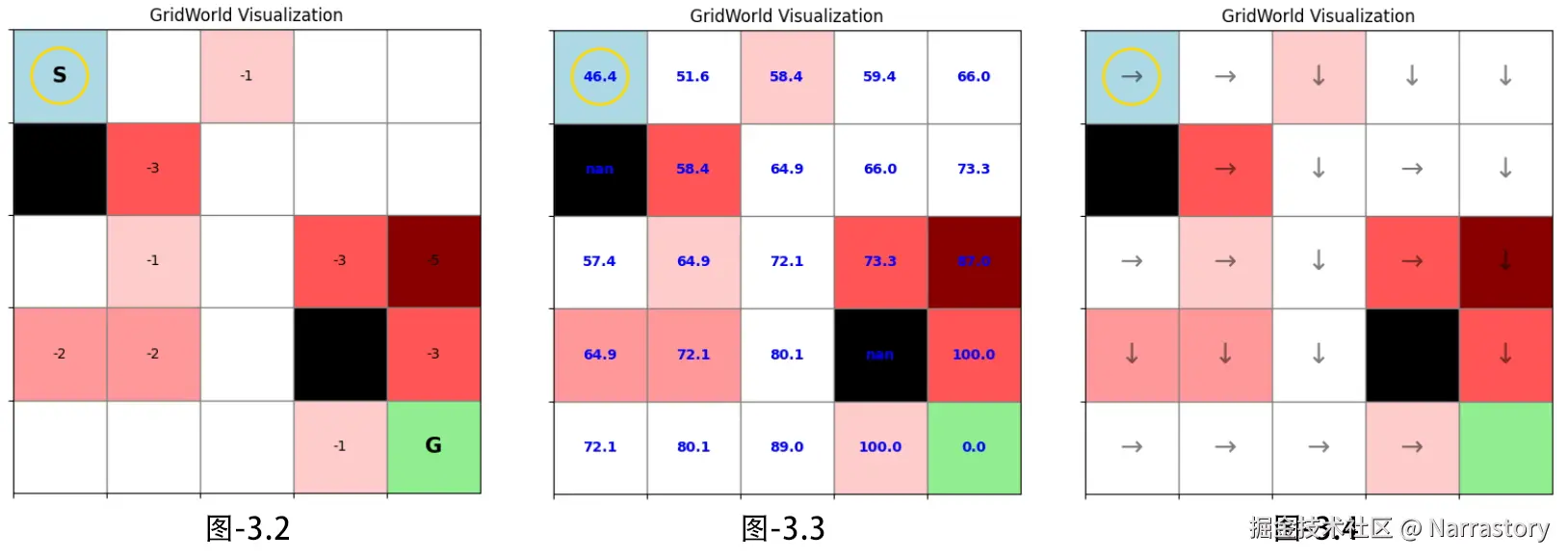
四. 蒙特卡洛方法
4.1 数学理论
蒙特卡洛(Monte Carlo, MC)方法不需要我们知道环境模型(比如状态转移概率和奖励函数),仅靠智能体与环境的实际互动数据,就能完成价值函数估计和策略优化。
我们都知道,状态价值函数 vπ(s) 的本质,是智能体在状态 s 下遵循策略 π 所能获得的长期收益的期望值,即:
vπ(s)=EπGt∣St=s
这里的 Gt 是从状态 s 出发,遵循策略 π 所能获得的回报(return)。当模型已知时,我们可以通过贝尔曼方程递归地解这个期望。但在模型未知时,这个期望分布是隐式的------我们没法写出它的概率密度函数。
蒙特卡洛方法的处理方式很直接:不进行解析计算,而是从经验中采样 。我们让智能体在环境中实际运行(称为一个 episode),记录从某个状态出发后续获得的真实回报 G ,然后通过多次采样的平均值来逼近真实的价值。
具体来说,如果我们在第 i 个 episode 中观察到从状态 s 出发的回报为 G(i) ,那么经过 n 次独立采样后,状态价值的估计为:
Vn(s)=nG(1)+G(2)+...+G(n)
这种"观测-平均"的思路,就是蒙特卡洛方法的核心。
在实际操作中,一个 episode 通常包含多个状态。有意思的是,一次完整的采样可以更新路径上所有状态的价值估计,而不只是最终状态。
假设智能体从起点出发,依次经过状态 A→B→C ,最终到达终点。在每个时间步获得的奖励分别为 R0,R1,R2。由于回报 Gt 定义为未来折扣奖励之和,我们可以从后向前递推计算,如图4.1:
GC=R2GB=R1+γGCGA=R0+γGB
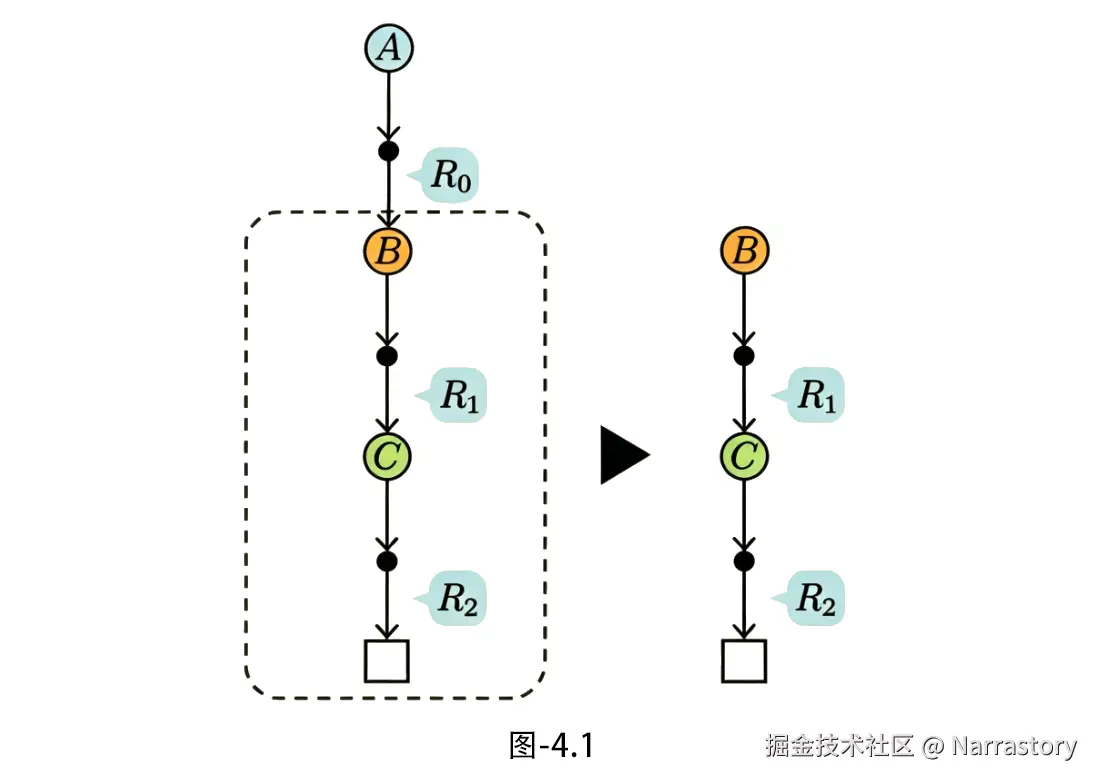
这种反向计算非常高效------一次完整的 episode 结束,我们就能得到这条轨迹上所有访问过的状态的真实回报值。这也是为什么蒙特卡洛方法需要等到 episode 结束才能进行更新。
在实际进行策略控制(control)时,我们不用 Vπ(s) 而是用 Qπ(s,a) 。如果我们只有 Vπ(s),在改进策略时会遇到一个根本性问题:我们不知道选择哪个动作更好 。因为 vπ(s) 已经隐含了对动作 a 的期望(即按照 π 选择动作),它无法告诉你"如果此刻我选择动作 a 会怎样"。
而动作价值函数 Qπ(s,a) 估计的是"在状态 s 下具体执行动作 a ,然后遵循策略 π 的期望回报":
Qπ(s,a)=EπGt∣St=s,At=a
有了 Q 函数,策略改进变得异常简单:直接在每个状态下选择 Q 值最大的动作即可 。更重要的是,基于 Q 的更新天然兼容 ϵ-greedy 等探索策略------我们可以持续地评估那些当前策略不会选择的动作,从而保证探索。
因此,MC 控制的流程通常是这样的循环:
采样 episode→更新 Q(s,a)→改进 π→采样 episode→⋯
在实际实现中,如果我们每次都用 Qn(s,a)=n1∑G(i) 来计算,就需要存储所有的历史回报。这在内存上是不经济的。好在,我们可以推导出增量式更新 的形式。通过简单的代数变形,第 n 次估计可以表示为第 n−1 次估计加上一个修正项:
Qn(s,a)=Qn−1(s,a)+n1G(n)−Qn−1(s,a)
这个形式非常优美:新的估计等于旧的估计,朝着新观测到的回报 G(n) 迈出一小步(步长为 n1)。这种写法非常省内存,实际上我们可以把 n1 替换为一个定值 α (这个值也叫指数移动平均),指数移动平均为较新的数据赋予了更大的权重,使得训练的更加稳定,效果更好。
Qn(s,a)←Qn−1(s,a)+αG(n)−Qn−1(s,a)
虽然蒙特卡洛方法概念简单、实现直接,但它有两个明显的痛点:
第一,高方差 。由于 G 是一系列随机奖励的折扣和,它的方差会随着轨迹长度指数级增长。这意味着 MC 估计的波动可能很大,收敛速度较慢,尤其是在长轨迹场景中。
第二,必须等待 episode 结束。这限制了 MC 方法在连续任务(non-episodic tasks)中的应用,也让它在实时性要求高的场景中显得笨拙。如果环境是一个超长的棋局,或者根本没有明确的终止状态,MC 就无法直接应用。
4.2 代码实现
如下是蒙特卡洛算法的具体实现:
python
import numpy as np
from collections import defaultdict
def train_monte_carlo(env, episodes=2000, gamma=0.95, eps=0.2, alpha=0.05):
"""
使用蒙特卡洛方法训练智能体,返回一个表示每个格子最佳动作的二维矩阵。
参数:
env: GridWorld 环境对象,需要提供 reset() 和 step(action) 方法。
episodes: 训练的 episode 总数,每个 episode 从起点走到终点(或掉入陷阱)结束。
gamma: 折扣因子,表示未来奖励在当前时刻的价值衰减程度(0~1)。
eps: epsilon-贪心策略中的探索概率,以一定概率随机选择动作,避免陷入局部最优。
alpha: 学习率,控制每次更新 Q 值时对新样本的采纳程度(0~1)。
返回:
policy_map: 二维 numpy 数组,形状为 (height, width),每个元素为 0,1,2,3 分别代表
上、下、左、右动作;若为 -1 则表示该格子为障碍物(不可通行)。
"""
# Q 值表:字典,键为 (state, action) 元组,值为该状态-动作对的估计价值。
# 使用 defaultdict(float) 使得未出现过的键默认值为 0.0,无需手动初始化。
Q = defaultdict(float)
# 策略表:字典,键为 state,值为该状态下每个动作被选中的概率分布。
# 初始化为等概率(每个动作 0.25),即完全随机策略。
policy = defaultdict(lambda: {a: 0.25 for a in range(4)})
# 主训练循环,重复 episodes 次
for _ in range(episodes):
# 重置环境,获取起始状态,并清空本轮的轨迹记忆列表
state = env.reset()
memory = [] # 存储本轮轨迹:每个元素为 (state, action, reward)
done = False # 是否到达终止状态(目标或陷阱)
# ---------- 采样阶段:与环境交互,收集一条完整的 episode ----------
while not done:
# 根据当前策略 policy 获取状态 state 下各动作的概率
probs = policy[state]
# 按概率随机选择一个动作
action = np.random.choice(list(probs.keys()), p=list(probs.values()))
# 执行动作,得到下一个状态、即时奖励和是否终止的标志
next_state, reward, done = env.step(action)
# 将本次转移记录到 memory 中(用于后续学习)
memory.append((state, action, reward))
# 更新当前状态,准备下一步
state = next_state
# ---------- 学习阶段:利用收集到的轨迹更新 Q 值和策略 ----------
G = 0 # 累积回报,从终止状态向前累加(蒙特卡洛的核心)
# 反向遍历轨迹,从最后一步回到第一步
for state, action, reward in reversed(memory):
# 计算当前时刻的回报 G:立即奖励 + 折扣后的未来回报
G = reward + gamma * G
# 状态-动作对的键
key = (state, action)
# 增量式更新 Q 值:新估计 = 旧估计 + alpha * (目标值 - 旧估计)
# 目标值 G 就是本次 episode 中从该步开始的实际折扣累积奖励
Q[key] += alpha * (G - Q[key])
# 根据更新后的 Q 值,重新计算该状态的 epsilon-贪心策略
# 1. 获取当前状态下所有动作的 Q 值
q_vals = [Q[(state, a)] for a in range(4)]
# 2. 找出最大 Q 值对应的动作(如果有多个,np.argmax 返回第一个)
best = np.argmax(q_vals)
# 3. 计算基础概率:每个动作至少获得 eps/4 的概率
base = eps / 4
# 4. 生成新的策略概率分布字典:
# - 非最优动作:仅获得基础概率 base
# - 最优动作:额外获得 (1 - eps) 的概率
policy[state] = {a: base + (1 - eps if a == best else 0) for a in range(4)}
# ---------- 训练结束,生成最终的确定性策略地图 ----------
# 识别障碍物格子:env.reward_map 中值为 None 的位置即为障碍物
obstacle = np.vectorize(lambda x: x is None)(env.reward_map)
# 初始化策略地图,默认所有格子为 0
policy_map = np.zeros((env.height, env.width), dtype=int)
# 遍历每一个格子
for r in range(env.height):
for c in range(env.width):
# 如果是障碍物,标记为 -1
if obstacle[r, c]:
policy_map[r, c] = -1
else:
# 否则,计算该状态下所有动作的 Q 值,选择最大 Q 值对应的动作
q_vals = [Q[((r, c), a)] for a in range(4)]
policy_map[r, c] = np.argmax(q_vals)
return policy_map4.3 结果展示
还是使用3.2小节搭建的网格世界环境来测试蒙特卡洛算法,测试代码如下:
python
env = GridWorld(
height=6,
width=6,
goal_state=(5, 5),
start_state=(0,0),
obstacle_ratio=0.1,
trap_ratio=0.3,
)
env.render() # 如图4.2
policy_map = train_monte_carlo(env, episodes=2000)
env.render(policy_map=policy_map) # 如图4.3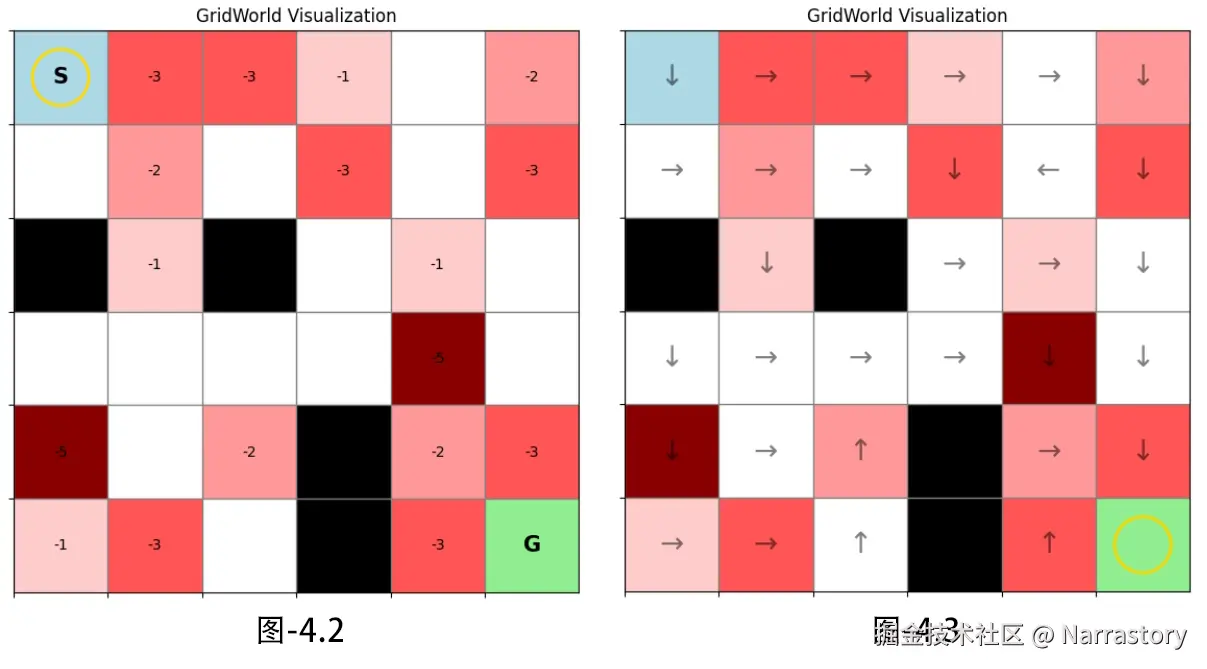
END~
