一、为什么需要位置编码?
1.1 卷积 vs 自注意力的天然差异
bash
卷积神经网络(CNN):
┌─────────────────────────────────┐
│ [我] [爱] [吃] [烤] [鸭] │
│ ↑ ↑ ↑ ↑ ↑ │
│ 卷积核每次只看相邻的几个元素 │
│ 天然感知"谁在谁旁边" │
│ → 自动捕获相对位置关系 ✓ │
└─────────────────────────────────┘
自注意力机制(Transformer):
┌─────────────────────────────────┐
│ [我] [爱] [吃] [烤] [鸭] │
│ ↕ ↕ ↕ ↕ ↕ │
│ 每个词和所有词同时交互 │
│ 不知道谁在第几位! │
│ → 完全感知不到位置 ✗ │
└─────────────────────────────────┘1.2 位置不敏感的严重后果
bash
句子A:"猫追老鼠"
句子B:"老鼠追猫"
Self-Attention看到的(没有位置编码):
两句话都含有 {猫, 追, 老鼠}
→ 模型认为两句话完全一样!😱
加入位置编码后:
句子A:猫(位置1) 追(位置2) 老鼠(位置3)
句子B:老鼠(位置1) 追(位置2) 猫(位置3)
→ 模型正确区分两句话!✓二、绝对位置编码
2.1 绝对位置编码的两种类型
2.1.1 可学习的绝对位置编码
基本思路:
bash
直接为每个位置准备一个"可学习的向量":
位置1 → e₁ = [?, ?, ?, ...] ← 随机初始化,通过训练更新
位置2 → e₂ = [?, ?, ?, ...] ← 随机初始化,通过训练更新
位置3 → e₃ = [?, ?, ?, ...] ← 随机初始化,通过训练更新
...
最终输入 = 词向量 + 位置向量优缺点:
bash
优点:
✅ 灵活,模型自己学出最优的位置表示
✅ 实现极其简单(就是个Embedding层)
缺点:
❌ 引入大量参数(每个位置都有一个d_model维向量)
例:max_length=512, d_model=768
→ 512 × 768 = 393,216个额外参数!
❌ 需要大量数据才能训练好这些参数
❌ 超出训练长度的位置,没有对应的位置向量
训练时最长512个词
测试时输入600个词 → 位置513~600没有向量!❌
代表模型:BERT、GPT-2(早期大模型主流方案)2.1.2 固定的绝对位置编码:三角位置编码
来自《Attention Is All You Need》
位置pos对应的位置向量在偶数位和奇数位的值分别为:

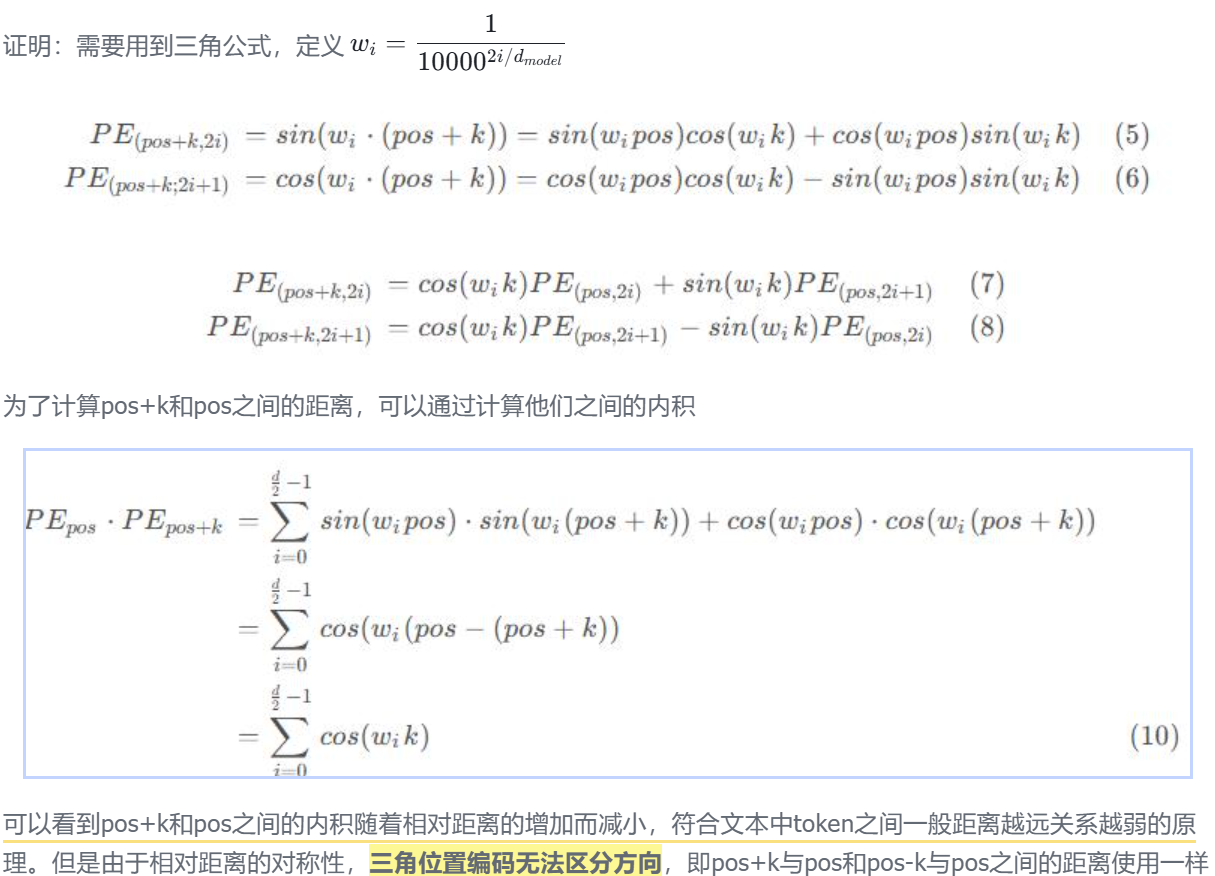
为什么用 100002i/dmodel10000^{2i/d_{model}}100002i/dmodel 作为分母?
bash
当 i=0(低维度):
w₀ = 1/10000⁰ = 1
→ 频率最高的正弦波:sin(pos × 1)
→ 变化很快,能区分相邻位置
当 i=d_model/2(高维度):
w_{max} = 1/10000¹ = 1/10000
→ 频率最低的正弦波:sin(pos × 0.0001)
→ 变化极慢,能体现长距离的全局位置关系
可视化:
i=0: ∿∿∿∿∿∿∿∿∿∿ (高频,快速振荡)
i=1: 〜〜〜〜〜〜 (中频)
i=2: ~~~~ (低频)
i=max: ────────── (极低频,近似直线)🌰 时钟类比:
就像时钟用三根指针共同表示时间:
秒针(高频):每60秒转一圈,精确到秒
分针(中频):每60分钟转一圈
时针(低频):每12小时转一圈
三根指针组合,唯一确定任意时刻!
三角编码用多个频率的波,唯一确定任意位置!
具体数值示例
bash
d_model = 4,所以 i ∈ {0, 1}
维度0(偶数,i=0):sin(pos/10000^(0/4)) = sin(pos)
维度1(奇数,i=0):cos(pos/10000^(0/4)) = cos(pos)
维度2(偶数,i=1):sin(pos/10000^(2/4)) = sin(pos/100)
维度3(奇数,i=1):cos(pos/10000^(2/4)) = cos(pos/100)
各位置的编码向量:
pos=0:[sin(0), cos(0), sin(0), cos(0) ]
=[0, 1, 0, 1 ]
pos=1:[sin(1), cos(1), sin(0.01), cos(0.01) ]
=[0.841, 0.540, 0.010, 0.9999 ]
pos=2:[sin(2), cos(2), sin(0.02), cos(0.02) ]
=[0.909, -0.416, 0.020, 0.9998 ]
每个位置都有唯一的编码向量!✓
python
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super().__init__()
self.dropout=nn.Dropout(p=dropout)
pe=torch.zeros(max_len, d_model)
position=torch.arange(0,max_len).unsqueeze(1)
div_term=torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0)/d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe=pe.unsqueeze(0)
self.register_buffer('pe', pe)
self.pe = pe
def forward(self, x):
x = x+self.pe[:,:x.size(1)] 绝对位置编码实现简单,存在以下缺点:
- 尽管能包含一定的相对位置信息,但是这种信息仅仅保存在位置编码内部,在计算自注意力时,这种位置信息就被破坏了
- 一个token的位置编码是什么由其在句子中的绝对位置决定,但是真正重要的往往不是绝对位置,而是它与其他token之间的关系
- 对输入的长度敏感,一旦输入变化则需要重新调整
三、相对位置编码
相对位置编码将两个token的相对位置信息添加到对应的attention值中
bash
绝对位置编码:告诉模型"我在第几个位置"
相对位置编码:告诉模型"我和你之间相距几个位置"
绝对位置(像门牌号): 相对位置(像导航):
张三住 → 北京路第5号 张三住 → 李四家旁边第3户
李四住 → 北京路第8号
→ 换一条街就失效了!❌ → 无论在哪条街都有效!✓3.1 ALiBi
Attention with linear biases enables input length extrapolation
带有线性偏置的注意力机制能够实现输入长度的外推
3.1.1 ALiBi是什么?
ALiBi的全名和核心思想:
bash
ALiBi = Attention with Linear Biases
= 带有线性偏置的注意力机制
核心思想:
不给每个词额外加一个位置向量,
而是在计算注意力分数时,
直接对"距离较远的词对"施加惩罚!
惩罚方式:距离越远,惩罚越重(线性增长)3.1.2 ALiBi的计算过程
传统注意力 vs ALiBi注意力
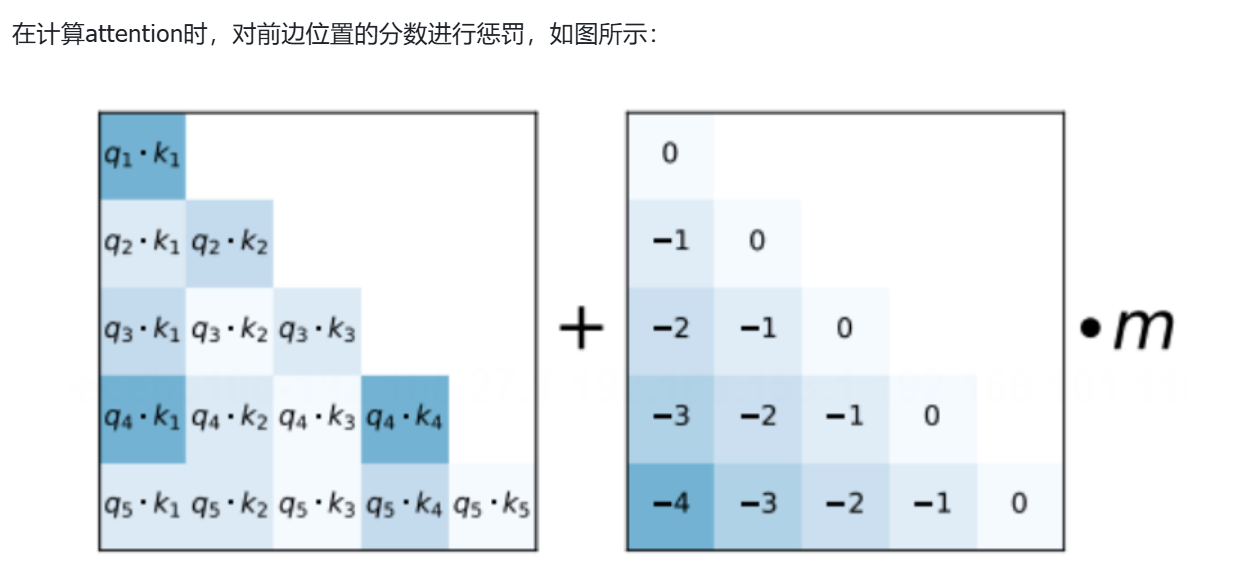
具体数值示例
以句子 "我 爱 吃 烤 鸭" 为例,计算"鸭"(位置4)对其他词的注意力分数:
bash
传统注意力分数(只有语义信息):
我 爱 吃 烤 鸭
原始分数:[3.2, 2.1, 4.5, 3.8, 5.0]
ALiBi惩罚项(m=1,距离位置4的距离):
我 爱 吃 烤 鸭
距离: [4, 3, 2, 1, 0]
惩罚: [-4, -3, -2, -1, -0]
ALiBi最终分数 = 原始分数 + 惩罚:
我 爱 吃 烤 鸭
分数: [3.2-4, 2.1-3, 4.5-2, 3.8-1, 5.0-0]
= [-0.8, -0.9, 2.5, 2.8, 5.0]
Softmax后:
"鸭"主要关注近处的"烤"和"吃",
远处的"我"和"爱"被大幅压制!直观图示:
bash
注意力分数
↑
5.0| ★ 鸭(自己)
| ★ 烤
| ★ 吃
|
|
| ★ 我 ★ 爱
──┼────────────────────────→ 位置
0 1 2 3 4
规律:距离越近,注意力分数越高!不同注意力头有不同的惩罚斜率m
bash
ALiBi为每个注意力头设置不同的m值:
头1(m=1): 惩罚强 → 主要关注很近的词
头2(m=0.5): 惩罚中 → 兼顾近处和中等距离
头3(m=0.25):惩罚弱 → 也能关注较远的词
头4(m=0.1): 惩罚很弱→ 可以关注较远的全局信息
可视化:
距离 头1(m=1) 头2(m=0.5) 头3(m=0.25) 头4(m=0.1)
1 -1 -0.5 -0.25 -0.1
2 -2 -1.0 -0.50 -0.2
5 -5 -2.5 -1.25 -0.5
10 -10 -5.0 -2.50 -1.0
20 -20 -10.0 -5.00 -2.0
多个头的组合:
既有关注局部的头,也有关注全局的头
→ 模型可以同时学习局部和全局依赖!✓3.1.3 ALiBi的四大核心优势
- 优势一:更好的长度外推能力
问题背景:
bash
传统绝对位置编码(如BERT):
训练时:见过位置1~512
模型学习了"第512个位置"的编码
测试时:遇到位置513
从没见过这个位置!
→ 模型不知道该怎么处理 ❌
就像一个只去过上海的人,
突然被放到北京,完全迷失了方向!ALiBi的解决方案:
bash
ALiBi训练时:处理长度=512的序列
学习的是"距离1惩罚多少,距离2惩罚多少..."
ALiBi测试时:遇到长度=1000的序列
只需要继续延伸惩罚规则:
"距离513?那就惩罚513×m就好了!"
线性规律天然外推:
训练范围: 外推范围:
距离1→惩罚1 距离513→惩罚513
距离2→惩罚2 → 距离514→惩罚514
距离3→惩罚3 ...(规律不变!)
...
距离512→惩罚512
类比:
学会了"1步=1分钟路程"的规律
即使走1000步,也知道需要1000分钟
不需要专门学习"1000步"的情况!- 优势二:不依赖复杂的周期性结构
bash
三角位置编码(Sinusoidal):
用sin/cos的组合来表示位置
→ 模型需要学习复杂的周期性规律 ❌
→ 计算复杂,理解困难
ALiBi:
直接用线性关系:距离k → 惩罚 m×k
→ 规律极其简单 ✓
→ 不需要学习任何复杂结构
对比:
Sinusoidal:PE(pos+k) = M_k × PE(pos) ← 旋转矩阵,复杂
ALiBi: Score(i,j) = Score(i,j) - m×|i-j| ← 减法,简单!- 优势三:理论上支持任意长度序列
bash
绝对位置编码的瓶颈:
┌─────────────────────────────┐
│ 位置编码矩阵 │
│ 形状:[max_len × d_model] │
│ max_len=512 → 只有512行 │
│ 超出512 → 没有对应的编码! ❌│
└─────────────────────────────┘
固定大小的矩阵 → 固定长度的限制
ALiBi没有编码矩阵:
┌─────────────────────────────┐
│ 只有一个公式: │
│ 惩罚 = m × 距离 │
│ 距离可以是任意正整数! │
│ → 天然支持任意长度 ✓ │
└─────────────────────────────┘
公式没有大小限制 → 长度无上限!
实际效果(论文数据):
训练长度: 1024 个词
外推测试: 2048 个词 → 性能几乎不下降!✓
4096 个词 → 性能轻微下降,但可接受
传统方法: 超出1024就显著下降 ❌- 优势四:平衡局部和全局依赖
bash
语言中的两种依赖关系:
局部依赖(短距离):
"我 正在 吃 烤鸭"
"吃"和"烤鸭"相邻 → 局部语法关系
需要高度关注 ✓
全局依赖(长距离):
"虽然今天天气不好,但是我还是决定出门"
"虽然"和"但是"相距很远 → 全局逻辑关系
也需要关注 ✓
ALiBi的平衡策略:
不同斜率m的作用:
大m(强惩罚头): 小m(弱惩罚头):
注意力分数 注意力分数
↑ ↑
|█ |█
| ██ | █
| ████ | ██
| ████████ | █████████████
└────────────→ 距离 └──────────────→ 距离
专注于局部关系 兼顾全局关系
多个头的组合 = 同时学习局部+全局!✓
类比:
一个团队里:
有人负责盯紧眼前的事(大m头)
有人负责把握整体方向(小m头)
分工合作,效果最好!
python
import torch
import math
def alibi_attention(q, k, v, m=1.0):
"""
ALiBi注意力机制(单头简化版)
参数:
q: Query矩阵 [seq_len, d_k]
k: Key矩阵 [seq_len, d_k]
v: Value矩阵 [seq_len, d_v]
m: 惩罚斜率(每个头不同)
"""
seq_len, d_k = q.shape
# ① 计算传统注意力分数
# 形状:[seq_len, seq_len]
scores = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k)
# ② 构建ALiBi惩罚矩阵
# 生成位置索引
positions = torch.arange(seq_len)
# 计算每对位置之间的距离(绝对值)
# distance[i,j] = |i - j|
distance = torch.abs(
positions.unsqueeze(0) - positions.unsqueeze(1)
).float()
# distance矩阵(seq_len=5时):
# [[0, 1, 2, 3, 4],
# [1, 0, 1, 2, 3],
# [2, 1, 0, 1, 2],
# [3, 2, 1, 0, 1],
# [4, 3, 2, 1, 0]]
# ALiBi惩罚 = -m × 距离
alibi_bias = -m * distance
# alibi_bias矩阵(m=1时):
# [[ 0, -1, -2, -3, -4],
# [-1, 0, -1, -2, -3],
# [-2, -1, 0, -1, -2],
# [-3, -2, -1, 0, -1],
# [-4, -3, -2, -1, 0]]
# ③ 传统分数 + ALiBi惩罚
scores = scores + alibi_bias
# ④ Softmax归一化
attention_weights = torch.softmax(scores, dim=-1)
# ⑤ 加权求和Value
output = torch.matmul(attention_weights, v)
return attention_weights, output
# ─── 演示ALiBi效果 ─────────────────────────
seq_len = 5
d_k = 4
# 模拟Q、K、V
torch.manual_seed(42)
q = torch.randn(seq_len, d_k)
k = torch.randn(seq_len, d_k)
v = torch.randn(seq_len, d_k)
# 对比不同m值的效果
for m in [0.0, 0.5, 1.0, 2.0]:
weights, _ = alibi_attention(q, k, v, m=m)
print(f"\nm={m}时,最后一个词的注意力权重:")
print([f"{w:.3f}" for w in weights[-1]])
# m=0.0(无惩罚): 各位置权重相对均衡
# m=0.5(弱惩罚): 近处权重略高
# m=1.0(中等惩罚):近处权重明显更高
# m=2.0(强惩罚): 远处权重被强烈压制3.2 XLNet
3.2.1 先回顾:绝对位置编码的问题
三角位置编码在计算attention时的表示如下:
bash
(a) E_xi × E_xj:纯语义交互
"我"和"烤鸭"在语义上有多相关?
(b) E_xi × p_j:词i的语义 vs 词j的绝对位置
"我"的语义,和"烤鸭在第4位"有多相关?
(c) p_i × E_xj:词i的绝对位置 vs 词j的语义
"我在第1位",和"烤鸭"的语义有多相关?
(d) p_i × p_j:纯位置交互
"位置1"和"位置4"之间有多相关?绝对位置编码的核心问题
bash
问题:(b)(c)(d)三项都用了绝对位置 p_i 或 p_j
绝对位置的缺陷:
句子A:"猫[位置1] 追 老鼠[位置3]"
句子B:"我[位置1] 看 老鼠[位置3] 跑"
"老鼠"在两句中的绝对位置都是3
但它们的语法角色完全不同!
模型被误导:
p_j(位置3的向量)在两句中完全一样
→ 模型觉得两个"老鼠"处于相同的位置语境
→ 这显然是错的!❌
真正重要的:
"老鼠"和"追"之间相距多远?
"老鼠"和"看"之间相距多远?
这才是相对位置信息!3.2.2 XLNet的核心改进思想
XLNet对绝对位置编码公式做了三处关键修改:

bash
修改前(绝对位置编码):
A_{i,j} = (E_xi)Wq · Wk(E_xj) ← (a)语义×语义
+ (E_xi)Wq · Wk(p_j) ← (b)语义×绝对位置j
+ (p_i)Wq · Wk(E_xj) ← (c)绝对位置i×语义
+ (p_i)Wq · Wk(p_j) ← (d)绝对位置i×绝对位置j
修改后(XLNet相对位置编码):
A_{i,j} = (E_xi)Wq · Wk(E_xj) ← (a)不变!语义×语义
+ (E_xi)Wq · Wk(R_{i-j}) ← (b')语义×相对位置
+ u · Wk(E_xj) ← (c')固定向量×语义
+ v · Wk(R_{i-j}) ← (d')固定向量×相对位置三处改动:
bash
改动1:p_j → R_{i-j}
绝对位置j → 相对位置(i到j的距离)
改动2:p_i → u(可训练的固定向量)
绝对位置i → 与位置无关的全局向量u
改动3:p_i → v(另一个可训练的固定向量)
绝对位置i → 与位置无关的全局向量v3.2.3 逐项深度解析XLNet公式
todo:补充公式
项(a):纯语义交互----不变!
bash
含义:词i和词j纯粹基于语义内容的相关性
例子:"我 爱 吃 烤鸭"
当i="吃",j="烤鸭"时:
(a) = "吃"的语义向量 × "烤鸭"的语义向量
→ 动词"吃"和宾语"烤鸭"在语义上高度相关 ✓
这项与位置无关,原封不动保留!项(b'):语义 * 相对位置----关键改动!
bash
R_{i-j} = 位置i和位置j之间相对距离(i-j)对应的编码向量
用三角函数生成(和原版Transformer类似):
R_0 → 距离为0(同一位置)的编码
R_1 → 距离为1(相邻位置)的编码
R_2 → 距离为2(间隔一个词)的编码
R_{-1} → 距离为-1(前一个位置)的编码
...
关键区别:
绝对编码:p_j = "j在第几位"
相对编码:R_{i-j} = "i和j相距多远"
例子(i=3, j=1):
绝对编码:用p_1("第1位"的向量)
相对编码:用R_{3-1}=R_2("相距2位"的向量)
为什么更好?
不管这两个词在句子里的绝对位置是什么,
只要它们相距2位,就用同一个R_2
→ 位置关系的理解更稳定!✓
bash
(b') = 词i的语义向量 × 相对位置编码R_{i-j}
通俗理解:
"词i的语义内容" 与 "词i和词j之间的距离关系" 的交互
例子:
i="吃"(动词),j="烤鸭"(紧跟其后,距离=1)
(b') = "吃"的语义 × R_1(近距离的编码)
→ 告诉模型:"动词'吃'特别关注它紧邻的宾语" ✓
i="的"(助词),j="烤鸭"(距离=1)
(b') = "的"的语义 × R_1
→ "的"这个词对相邻词的关注程度(不同于"吃")项(c'):全局查询偏置---重要创新!
bash
原来的项(c):p_i × Wk × E_xj
问题:p_i 是词i的绝对位置,
每个词有不同的p_i,
意味着同一个词在不同位置,
对其他词的"基础关注偏好"不同。
但实际上:
"的"这个助词,不管它在句子的第1位还是第10位,
它对周围词的语义关注偏好应该是相同的!
XLNet的解决方案:
用一个与位置无关的固定向量 u 替代 p_i
u 是全局共享的,对所有位置都一样
u = 可训练参数(通过数据学习)
= "词i查询其他词语义时的固定偏好"
= "我这类查询者,天然对什么样的语义感兴趣?"
bash
直觉理解:
u ≈ 模型在查询时的"固定偏好/先验"
类比:
一位语言学教授(u),
不管坐在教室哪个位置,
他对"名词"和"动词"的关注偏好是固定的
不会因为今天坐在第1排就更喜欢名词,
明天坐在第5排就改喜欢动词!项(d'):全局位置偏置
bash
含义:固定向量v 与 相对位置编码 的交互
v = 另一个可训练的全局向量
= "词i在考虑距离关系时的固定偏好"
通俗理解:
v ≈ "不管我(词i)是谁,
我对'距离远近'的基础偏好是固定的"
例子:
(d') = v × R_1(距离为1)= 较大值(倾向关注近邻)
(d') = v × R_5(距离为5)= 较小值(不太关注远处)
v是全局学习的,反映了模型对距离关系的整体偏好!
bash
A_{i,j}^rel = (a) + (b') + (c') + (d')
语义×语义 语义×相对位置 固定偏好×语义 固定偏好×相对位置
"吃"→"烤鸭"的注意力分数来自四个角度:
(a):吃和烤鸭在语义上有多相关?(高,因为动宾关系)
(b'):吃的语义×它们相距1位的编码?(高,动词关注近邻宾语)
(c'):全局查询偏好×烤鸭的语义?(中,通用的语义关注)
(d'):全局偏好×相距1位的编码?(高,倾向关注近邻)
四项相加 → 最终注意力分数!3.2.4 XLNet的完整算法:不只是位置编码
XLNet的背景----从BERT说起:
bash
BERT的训练方式:
原始文本:"我 爱 吃 烤 鸭"
随机遮盖:["我", [MASK], "吃", [MASK], "鸭"]
预测任务:预测[MASK]位置的词
BERT的优点:
✅ 可以同时看左边和右边的上下文(双向)
✅ 理解能力强
BERT的缺点:
❌ 引入了[MASK]这个假token,预训练和微调不一致
❌ 假设被遮盖的词之间互相独立(实际上不独立)
❌ 每次只能预测15%的词,训练效率低XLNet的核心创新:排列语言模型
bash
XLNet的训练方式:
不用[MASK],而是用"排列"的方式!
原始文本:"我 爱 吃 烤 鸭"
位置编号: 1 2 3 4 5
随机生成一种排列顺序,例如:[3, 5, 1, 4, 2]
按这个顺序预测:
步骤1:预测位置3的词"吃"(此时没有任何上下文)
步骤2:预测位置5的词"鸭"(已知"吃")
步骤3:预测位置1的词"我"(已知"吃","鸭")
步骤4:预测位置4的词"烤"(已知"吃","鸭","我")
步骤5:预测位置2的词"爱"(已知所有其他词)
关键:虽然按排列顺序预测,
但位置编码仍然保持原始顺序!
("吃"的位置编码永远是位置3)类比:就像玩填字游戏:方格的位置是固定的(位置编码不变),但你可以按任意顺序来填写这些方格!这样模型既能学到双向上下文,又不需要使用MASK这个假token!
双流注意力机制
XLNet为了实现排列语言模型,引入了两种注意力流:
内容流(Content Stream)
bash
内容流 h_i:
含义:词i"知道自己内容"时的表示
可以看到:自己的词向量 + 之前所有词的内容
例子:预测"鸭"时,h_鸭 可以看到:
→ "鸭"本身的词向量
→ 已经预测过的词:"吃"的内容
(这是标准的Self-Attention)查询流(Query Stream)
bash
查询流 g_i:
含义:词i"不知道自己内容,只知道自己位置"时的表示
可以看到:自己的位置编码(但不能看自己的词向量!)
+ 之前所有词的内容
例子:预测"鸭"时,g_鸭 可以看到:
→ "鸭"的位置信息(位置5)
→ 已经预测过的词:"吃"的内容
→ 但不能看"鸭"本身是什么词!
为什么不能看自己?
如果预测"鸭"时,模型能看到"鸭"的词向量,
那就相当于直接告诉答案了,没有学习意义!两流的交互:
bash
双流注意力的计算:
内容流(h流):标准Self-Attention
看自己 + 看之前所有词的内容
查询流(g流):特殊Self-Attention
不看自己内容,只用位置信息
看之前所有词的内容
训练时: 推理时:
h和g同时更新 只用h流(内容流)
就像普通的语言模型
可视化:
排列顺序 [3,5,1,4,2],预测位置2的词"爱":
查询流 g_2: ← 需要预测的目标
可见:位置2的编码(知道自己在哪)
可见:位置3,5,1,4的内容(之前预测过的词)
不可见:位置2的词向量(不能作弊!)
内容流 h_2: ← 辅助其他词的预测
可见:位置2的词向量(知道自己是"爱")
可见:位置3,5,1,4的内容3.3 T5
3.3.1 T5的核心思想:大胆删减!
关键洞察:输入和位置应该解耦
bash
什么叫"解耦"(独立)?
解耦 = 两件事互不影响,分开处理
类比:
你买了一件衣服:
- 衣服的款式(语义信息)= 输入
- 衣服的标签编号(位置信息)= 位置
正常情况:
款式和标签编号是独立的!
同一款式可以有不同编号
同一编号可以有不同款式
如果款式和编号互相影响(不解耦):
"这件衣服是第5件,所以一定是红色的"
→ 这显然不合理!❌
T5的观点:
输入的语义内容,不应该和位置信息过度交互!
它们应该保持独立。** T5删掉了哪两项?为什么?**
bash
删掉项(b):输入-位置交互
原公式:E_xi × R_{i-j}
含义:词i的语义内容 × 相对位置编码
删掉理由:
"吃"这个词的语义,不应该因为它离别的词远近不同而改变!
语义是语义,位置是位置,不该混在一起。
举例:
"吃[位置3] 烤鸭[位置4]" 相对距离=1
"吃[位置1] 烤鸭[位置2]" 相对距离=1
两个"吃烤鸭",无论绝对位置在哪,
"吃"和"烤鸭"的语义交互应该是一样的!
位置信息不应该干扰语义判断 ✓
─────────────────────────────────
删掉项(c):位置-输入交互
原公式:u × W_k × E_xj
含义:位置偏置 × 词j的语义内容
删掉理由:
"我在某个位置"这个信息,
不应该去影响对其他词语义的判断。
举例:
不管"烤鸭"在第4位还是第8位,
它作为一道美食的语义是固定的!
位置不应该改变对语义内容的评判 ✓T5保留了哪两项?
bash
保留项(a):输入-输入(语义×语义)✓
最核心的交互!词和词之间的语义相关性
这是注意力机制最本质的功能,必须保留。
保留项(d):位置-位置(位置×位置)✓
但T5对这项做了大幅简化!
原来:v^T × Wk × R_{i-j} (复杂的向量运算)
T5改为:一个标量偏置 r_{b(t-s)} (简单的加法!)
T5的最终公式:
A_{t,s} = E_xt × E_xs (语义交互)
+ r_{b(t-s)} (位置偏置标量)3.3.2 T5简化后的完整公式
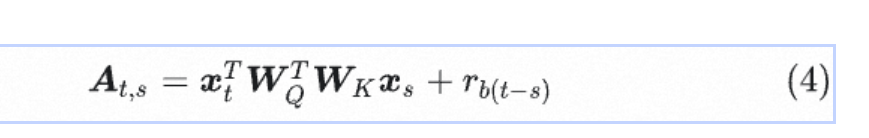
bash
传统注意力(无位置):
分数 = 语义相关性
绝对位置编码注意力:
分数 = 语义相关性 + 复杂的位置向量交互
T5注意力:
分数 = 语义相关性 + 一个简单的数字(位置偏置)
↑
就是加一个标量!极其简单!
类比:
普通考试打分:
分数 = 答题质量分(100分制)
T5式考试打分:
分数 = 答题质量分 + 座位加成分
(坐得近的同学加2分,
坐得远的同学减1分)
位置信息以"加减分"的形式直接叠加,
不影响原有的语义评分机制!✓3.3.3 桶函数b(t-s):把距离压缩到桶里
为什么需要桶函数?
bash
问题:相对距离 t-s 的范围可以非常大!
一篇512词的文章:
最大相对距离 = 511(第1个词和最后一个词)
最小相对距离 = -511
如果每个距离都训练一个单独的偏置:
需要学习 1023 个偏置参数!
而且:
远距离的词对(距离=100 vs 距离=101)
它们的位置偏置应该差不多,没必要分开训练!
解决方案:桶(Bucket)
把相近的距离归为同一个桶,共用一个偏置!桶函数的设计原理:
bash
核心思想:
近距离:每个距离单独一个桶(精细区分)
远距离:多个距离共用一个桶(粗略处理)
为什么这样设计?
语言学规律:
"我 爱 烤鸭"
距离1("我"和"爱")和距离2("我"和"烤鸭")
→ 差别很大,需要精细区分!
"我...(100个词)...那道烤鸭"
距离100和距离101
→ 对模型来说几乎没有区别,可以共用一个桶T5桶函数的具体实现:T5将范围-128, 128 的相对距离压缩到0, 31共32个桶:
bash
总共32个桶(0~31):
前16个桶:精细区分近距离(每个距离一个桶)
后16个桶:粗略区分远距离(对数分桶)
具体分配(简化说明):
距离0: → 桶15(中间,代表自身)
距离1: → 桶16
距离2: → 桶17
距离3: → 桶18
...
距离15: → 桶30
距离16~20: → 桶31(合并!)
距离21~27: → 桶31(继续合并!)
...
距离>128: → 桶31(最大桶)
负距离(i在j左边):
距离-1: → 桶14
距离-2: → 桶13
...
距离<-128: → 桶0(最小桶)对数分桶的数学定义:
todo:补充公式
bash
相对距离 → 桶编号的映射关系:
←── 负距离 ──────────────── 正距离 ──→
距离: -128 -64 -16 -8 -1 0 1 8 16 64 128
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
桶号: 0 1 7 8 14 15 16 22 23 30 31
可视化:
桶0 ████████████████ 覆盖 (-∞, -128]
桶1 ████████ 覆盖 (-128, -64]
桶2 ████
...(对数压缩,越远越粗糙)
桶7 ██ 覆盖 (-16, -8]
桶8 █ 覆盖 (-8, -7]
...
桶14 █ 覆盖 (-2, -1]
桶15 █ 覆盖 (-1, 0)
─────── 中心位置(自身)───────
桶16 █ 覆盖 (0, 1]
桶17 █ 覆盖 (1, 2]
...(近距离精细,一一对应)
桶22 █ 覆盖 (7, 8]
桶23 ██ 覆盖 (8, 16]
...(远距离粗糙,对数压缩)
桶30 ████████ 覆盖 (64, 128]
桶31 ████████████████ 覆盖 (128, +∞)
规律:近距离精细,远距离粗糙!3.3.4 可训练偏置
偏置是什么?
bash
T5为每个桶编号训练一个标量偏置:
桶0的偏置: r₀ = -2.3 (极远的负距离,注意力惩罚大)
桶1的偏置: r₁ = -1.8
...
桶15的偏置: r₁₅ = +0.5 (距离-1,近邻,适度提升注意力)
桶16的偏置: r₁₆ = +0.8 (距离+1,近邻,适度提升注意力)
...
桶31的偏置: r₃₁ = -1.5 (极远的正距离,注意力惩罚大)
这32个偏置值是可训练参数,
通过大量数据学习得到!偏置的作用
bash
最终注意力分数:
score(t, s) = 语义相关性得分 + r_{b(t-s)}
例子(假设训练后的偏置值):
"我 爱 吃 烤 鸭"
1 2 3 4 5 ← 位置
计算"吃"(位置3)对其他词的注意力:
目标词 "我"(位置1):
相对距离 = 3-1 = 2
桶编号 = b(2) = 18
偏置 = r₁₈ = +0.1
目标词 "爱"(位置2):
相对距离 = 3-2 = 1
桶编号 = b(1) = 17
偏置 = r₁₇ = +0.5 ← 近邻,偏置较大
目标词 "吃"自身(位置3):
相对距离 = 3-3 = 0
桶编号 = b(0) = 16
偏置 = r₁₆ = +1.0 ← 自身,偏置最大
目标词 "烤"(位置4):
相对距离 = 3-4 = -1
桶编号 = b(-1) = 14
偏置 = r₁₄ = +0.4 ← 近邻,偏置也较大
目标词 "鸭"(位置5):
相对距离 = 3-5 = -2
桶编号 = b(-2) = 13
偏置 = r₁₃ = +0.2
最终分数 = 语义分 + 对应偏置
→ 近处的词("爱"、"烤")得到更多注意力 ✓3.3.5 T5位置编码的完整算法流程
bash
输入:序列 ["我", "爱", "吃", "烤", "鸭"]
位置: 1 2 3 4 5
第一步:计算所有词对的相对距离矩阵
"我" "爱" "吃" "烤" "鸭"
"我" [ 0, -1, -2, -3, -4]
"爱" [ 1, 0, -1, -2, -3]
"吃" [ 2, 1, 0, -1, -2]
"烤" [ 3, 2, 1, 0, -1]
"鸭" [ 4, 3, 2, 1, 0]
第二步:通过桶函数,把相对距离映射到桶编号
"我" "爱" "吃" "烤" "鸭"
"我" [16, 14, 13, 12, 11]
"爱" [17, 16, 14, 13, 12]
"吃" [18, 17, 16, 14, 13]
"烤" [19, 18, 17, 16, 14]
"鸭" [20, 19, 18, 17, 16]
第三步:查表,得到每个桶对应的标量偏置
"我" "爱" "吃" "烤" "鸭"
"我" [1.0, 0.4, 0.2, 0.1, 0.0]
"爱" [0.5, 1.0, 0.4, 0.2, 0.1]
"吃" [0.1, 0.5, 1.0, 0.4, 0.2] ← 对角线(自身)最大
"烤" [0.0, 0.1, 0.5, 1.0, 0.4]
"鸭" [0.0, 0.0, 0.1, 0.5, 1.0]
第四步:加到注意力分数上
最终注意力矩阵 = 语义相关矩阵 + 位置偏置矩阵
= QK^T/√d_k + R(偏置矩阵)
第五步:Softmax归一化 → 加权求和V3.4 DeBERTa
去掉位置-位置交互
bash
含义:纯粹的位置之间的交互,
与任何词的语义内容无关
为什么可以删掉?
(d)项的问题:
位置1 和 位置3 之间的关系 = 固定的数值
位置5 和 位置7 之间的关系 = 相同的数值(都相距2)
→ 不管这些位置上是什么词,
纯位置之间的关系都是固定的!
这种固定的关系,包含的信息量极低!
而且这种信息已经包含在(b)和(c)中了:
(b) 词的语义 × 相对距离 → 已经包含了距离信息
(c) 相对距离 × 词的语义 → 也包含了距离信息
删掉(d):去掉冗余信息,减少噪声
保留(b)(c):保留有实质意义的位置-语义交互 ✓3.4.1 DeBERTa的完整公式
DeBERTa的注意力公式:
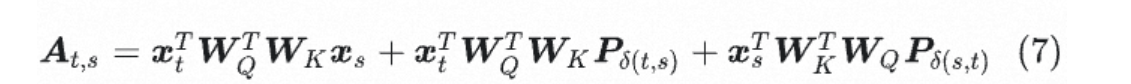
bash
含义:把相对距离 t-s 截断在区间 (-k, k] 内
为什么要截断?
相对距离可以从 -(n-1) 到 (n-1)
对于512词的句子:-511 到 511
如果每个距离都对应一个位置编码:
需要 1023 个位置向量!太多了!❌
截断的策略:
超过k的距离,都用同一个编码向量代表
(认为超过k的距离,关系已经足够弱,可以统一处理)
具体例子(k=128):
距离100 → δ = 100 (在范围内,精确表示)
距离200 → δ = 128 (超出范围,截断为128)
距离500 → δ = 128 (同样截断为128)
距离-100 → δ = -100 (在范围内,精确表示)
距离-200 → δ = -127 (截断为-127,因为区间是(-k,k])
最终只需要 2k 个位置向量!(通常k=512)
参数可控 ✓
bash
原始相对距离:
←────────────────────────────────────────→
-511 -k=-128 0 k=128 511
截断后:
-128 ←────────┤ 精确区域 ├────────→ 128
(-128, 128]
超出范围的距离统一映射到边界值:
距离<-128 → 都映射到 -128(同一个位置编码)
距离>128 → 都映射到 128(同一个位置编码)
效果:
把无限多种距离,压缩到有限的2k种!位置编码矩阵的构建
bash
DeBERTa维护一个位置编码矩阵 P:
形状:[2k, d_model](共2k个位置编码向量)
索引映射:
δ = -k → 第0行 (最远的负距离)
δ = -k+1 → 第1行
...
δ = 0 → 第k行 (同一位置)
...
δ = k-1 → 第2k-1行(最远的正距离)
使用时:
R_{δ(i,j)} = P[δ(i,j) + k] (+k使索引非负)3.4.2 缩放系数的改进
为什么要改变缩放系数?
bash
传统注意力缩放(单项):
score = QK^T / √d
只有一项的方差为 d(d个独立分量相加)
除以 √d,使方差恢复到1
→ 防止softmax饱和 ✓
DeBERTa有三项(a)(b)(c):
三项相加后的总方差 ≈ 3d
如果还用 √d 缩放:
score = (a + b + c) / √d
方差 = 3d / d = 3 ← 还是太大!
应该用 √(3d) 缩放:
score = (a + b + c) / √(3d)
方差 = 3d / (3d) = 1 ← 恢复正常!✓3.4.3 DeBERTa最重要的创新:绝对位置的引入方式
EMD(Enhanced Mask Decoder):分层引入绝对位置
bash
DeBERTa-Base(共13层)的架构:
前11层:Encoder(只用相对位置编码)
┌─────────────────────────────────────┐
│ Layer 1:相对位置注意力 │
│ Layer 2:相对位置注意力 │
│ ... │
│ Layer 11:相对位置注意力 │
│ │
│ 只用 R_{δ(i,j)} 作为位置信息 │
│ 不知道任何绝对位置! │
└─────────────────────────────────────┘
↓ 输出:富含语义和相对位置的表示
后2层:Decoder(加入绝对位置信息)
┌─────────────────────────────────────┐
│ Layer 12:相对位置 + 绝对位置 │
│ Layer 13:相对位置 + 绝对位置 │
│ │
│ 输入 = Encoder输出 + 绝对位置编码 │
│ 在最后阶段融合绝对位置信息! │
└─────────────────────────────────────┘
↓ 输出:融合了所有位置信息的最终表示为什么这样设计?
bash
直觉理解:先理解语义,再定位绝对坐标
类比------先看地图,再确认你在哪:
Encoder阶段(11层):
就像你在阅读一份地图,
理解各地点之间的相对关系:
"公园在学校右边500米"(相对位置)
"超市在公园斜对面"(相对位置)
Decoder阶段(2层):
然后你站在某个具体的位置,
结合你的绝对坐标:
"哦,我现在在北纬39.9°"(绝对位置)
把之前理解的相对关系,
映射到真实的绝对坐标系中!
效果:
11层打下了扎实的相对位置理解基础
最后2层用绝对位置"校准"最终输出
比一开始就用绝对位置效果更好!✓下游任务的微调策略:
bash
预训练模型(13层):
前11层 Encoder(相对位置)
后 2层 Decoder(相对+绝对位置)
下游任务微调时使用(12层):
前11层 Encoder(相对位置) ← 全部保留
后 1层 Decoder(相对+绝对位置) ← 只用1层
为什么减少1层?
预训练用2层Decoder是为了MLM任务的精确预测
下游任务(分类、NER等)不需要那么精细的绝对位置
1层Decoder就足够把绝对位置信息融入 ✓
减少参数,降低过拟合风险 ✓四、旋转位置编码RoPE
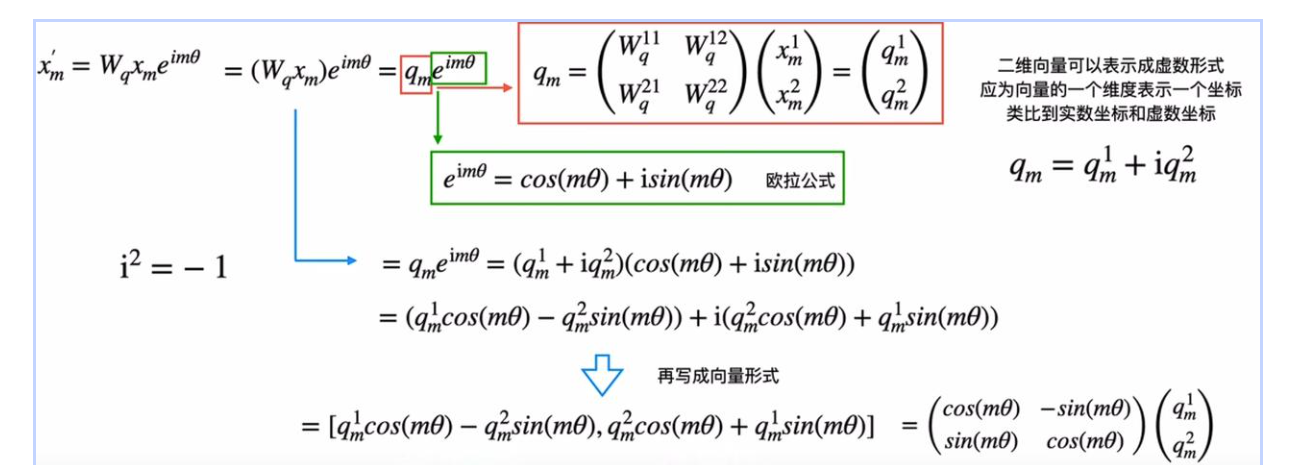

4.1 理解"旋转"----RoPE的核心操作
用时针来理解旋转:
bash
想象每个词的向量是一根时钟指针:
原始词向量:指针指向某个方向(由词的语义决定)
加入RoPE后:
位置0的词:指针保持原方向(旋转0°)
位置1的词:指针旋转θ度
位置2的词:指针旋转2θ度
位置3的词:指针旋转3θ度
...
位置m的词:指针旋转mθ度
每个位置旋转不同的角度 → 位置不同,方向不同!
bash
原始向量(所有词都指向同一方向):
词A 词B 词C 词D 词E
↑ ↑ ↑ ↑ ↑
(只有语义,没有位置区分)
RoPE之后(不同位置旋转不同角度):
词A 词B 词C 词D 词E
↑ ↗ → ↘ ↓
0° 45° 90° 135° 180°
每个词指向不同的方向!位置信息被编码进去了!✓旋转操作的直觉
bash
旋转的核心特性:
① 旋转不改变向量的"长度"(语义强度不变)
② 旋转改变向量的"方向"(位置信息体现在方向上)
③ 旋转是可逆的(可以还原)
类比:
给每个人换一套不同颜色的衣服(位置标记)
但他们的身高体重(语义内容)没有变化!为什么用"旋转"而不是"加法"?
bash
传统绝对位置编码(加法):
词向量 = 语义向量 + 位置向量
问题:语义和位置混在一起,互相干扰 ❌
RoPE(旋转):
词向量 = 旋转(语义向量, 位置角度)
语义信息体现在向量的"大小"
位置信息体现在向量的"方向"
两者正交,互不干扰!✓
就像:
加法:把盐(语义)和糖(位置)混在水里,分不清了
旋转:把水(语义)装进不同颜色的杯子(位置方向)
水还是原来的水,只是容器不同!4.2 RoPE如何实现相对位置
bash
关键洞察:
当两个旋转过的向量做内积时,
结果取决于它们的"夹角"!
词m旋转了:mθ 度
词n旋转了:nθ 度
两者的夹角:mθ - nθ = (m-n)θ
注意看:夹角只与(m-n)有关!
→ 只与相对距离有关!
→ 与绝对位置m和n无关!距离越远,关联越弱
bash
RoPE的另一个好性质:
两个词距离越远,内积值整体趋向减小
为什么?
距离远 → 旋转角度差大 → 向量方向差异大
→ 内积(点积)趋向减小
就像两根指针:
夹角很小(距离近)→ 指针方向接近 → 内积大 ✓
夹角很大(距离远)→ 指针方向相反 → 内积小 ✓
符合语言学直觉:
相邻的词关系最密切,
越远的词关系越弱!
bash
处理句子"我爱吃烤鸭":
Step1:计算Q和K矩阵(普通的线性变换)
Q = ["我"的query, "爱"的query, "吃"的query, ...]
K = ["我"的key, "爱"的key, "吃"的key, ...]
Step2:对Q和K施加RoPE旋转
Q_rope[0] = 旋转(Q[0], 0×θ) ← 位置0,旋转0度
Q_rope[1] = 旋转(Q[1], 1×θ) ← 位置1,旋转θ度
Q_rope[2] = 旋转(Q[2], 2×θ) ← 位置2,旋转2θ度
...(K同理)
Step3:计算内积(注意力分数)
score("吃"问"烤") = Q_rope[2] · K_rope[3]
= 包含了相对距离(3-2)=1的信息 ✓
score("吃"问"我") = Q_rope[2] · K_rope[0]
= 包含了相对距离(0-2)=-2的信息 ✓
Step4:V矩阵不需要旋转!
只有Q和K参与相对位置的计算
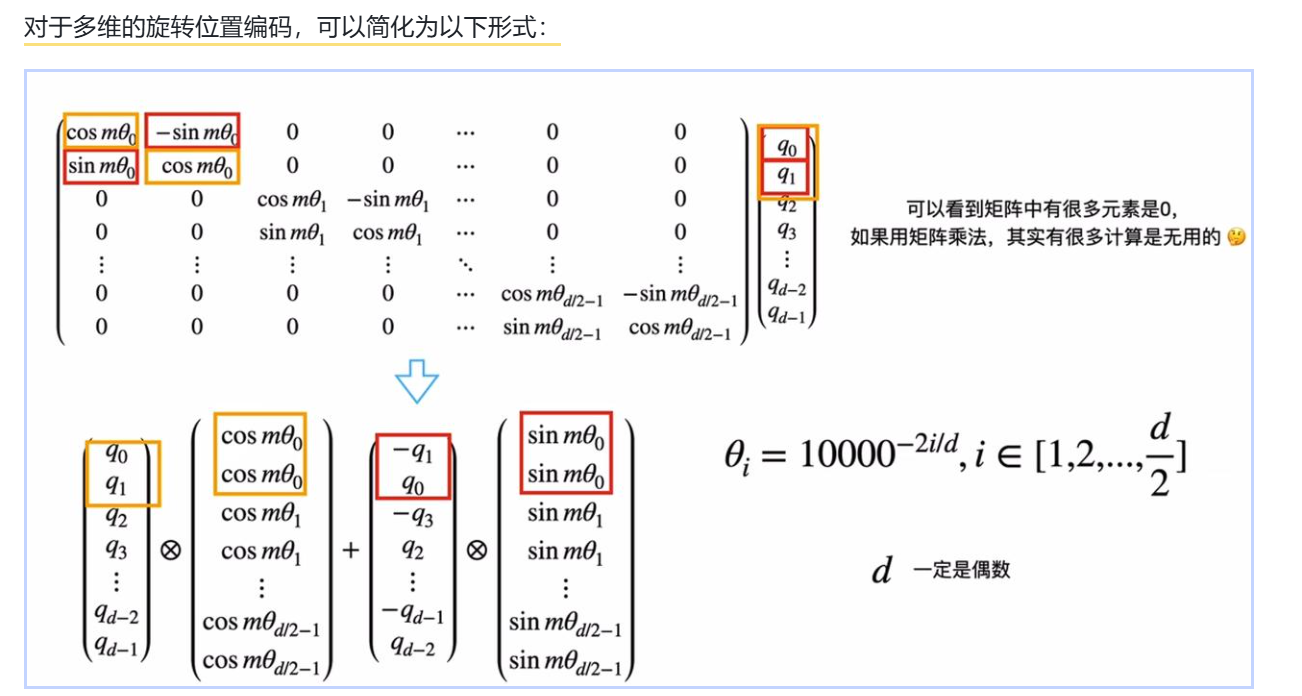
V只是存储"实际内容",位置信息已经通过注意力权重体现了4.3 多维度的设计哲学
为什么需要多个旋转速度?
bash
问题:只用一个旋转速度θ,够吗?
不够!原因:
一个θ只能提供一种"粒度"的位置信息
就像只有秒针的时钟:
1秒和61秒 → 指针方向相同!
模型分不清这两个时刻!
需要多个旋转速度(像时钟的多根指针):
快速旋转(大θ):区分近距离(秒针)
中速旋转(中θ):区分中等距离(分针)
慢速旋转(小θ):区分远距离(时针)
组合起来,可以唯一表示任意位置!✓不同维度对应不同旋转速度
bash
d_model = 8(8维向量,分成4组):
维度组 旋转速度 擅长区分
[0,1] 高频(快) 近距离(1,2,3步)
[2,3] 中高频 中近距离
[4,5] 中低频 中远距离
[6,7] 低频(慢) 远距离(几十上百步)
可视化:
近距离 远距离
↓ ↓
维度0,1: ∿∿∿∿∿∿∿∿∿∿ (高频,快速变化)
维度2,3: ~~~~~~ (中频)
维度4,5: ───~~──── (低频)
维度6,7: ────────── (极低频,几乎不变)
每个维度组:专注于自己"擅长"的距离范围
全部组合:覆盖所有距离范围!✓频率公式的直接理解:
bash
RoPE的频率设计:
θᵢ = 1 / 10000^(2i/d_model)
i从0到d_model/2-1,θᵢ越来越小
举例(d_model=8):
θ₀ = 1/10000⁰ = 1.000 ← 最快,高频
θ₁ = 1/10000^(0.25) = 0.178
θ₂ = 1/10000^(0.5) = 0.01 ← 中等
θ₃ = 1/10000^(0.75) = 0.00178 ← 最慢,低频
直觉:
10000这个基数确保了:
从最高频到最低频,覆盖了足够宽的范围
可以精确编码从1步到几千步的相对距离!
为什么选10000?
经验值,实践证明效果好
实际上这个值可以调整(称为RoPE的base)4.4 RoPE的优势与局限
4.4.1 四大核心优势
优势一:零额外参数
bash
传统绝对位置编码(BERT):
需要学习 max_length × d_model 个参数
512 × 768 = 393,216 个参数!
RoPE:
完全由公式决定,不需要任何额外参数!
节省参数 = 节省内存 + 不怕过拟合 ✓优势二:天然的相对位置感知
bash
传统编码:位置信息是"加进去"的(加法)
→ 和语义信息混合在一起
→ 模型需要额外学习如何分离它们
RoPE:位置信息是"旋转进去"的
→ 内积运算天然提取相对位置信息
→ 不需要模型额外学习!✓优势三:序列长度灵活
bash
传统方法:
训练了512词 → 位置矩阵只有512行
遇到600词 → 第513~600行不存在!❌
RoPE:
任何位置m → 直接计算旋转角度mθ
位置600 → 旋转600θ,直接计算,无需查表!✓
就像:
传统方法:背了一本512页的字典
RoPE:学会了一个公式,无限推导!优势四:距离衰减特性
bash
随着词之间距离增大,
RoPE的内积整体呈减小趋势
这意味着:
近邻词 → 高注意力 ✓
远处词 → 低注意力 ✓
符合语言规律:
"我昨天在北京吃了烤鸭"
"吃"和"烤鸭"相邻 → 高度关联 ✓
"我"和"鸭"距离较远 → 关联较弱 ✓4.4.2 RoPE的局限性
bash
局限:外推性能下降
什么意思?
训练时:序列长度 ≤ 2048词
测试时:遇到 4096词
虽然RoPE在数学上可以计算任何位置的旋转角度,
但模型在训练时从未见过这么大的旋转角度组合!
类比:
你练习走路(2048步以内)
突然让你跑马拉松(4096步)
步伐方法是对的,但体力(泛化能力)跟不上!
具体表现:
训练2048词时,困惑度(perplexity)很低 ✓
测试4096词时,困惑度明显上升 ❌
这就是RoPE的最大痛点,也是后续改进(xPOS、YaRN等)的动机!4.5 xPOS改进方案
xPOS解决了什么问题?
bash
RoPE的问题:
超出训练长度时,模型遇到"陌生的旋转角度"
→ 不知道如何处理这么远的距离关系
xPOS的解决思路:
与其让模型"硬撑"处理远距离关系,
不如让远距离的注意力自然趋近于零!
这样即使遇到超长序列:
近距离词:正常处理 ✓
远距离词:注意力接近0,相当于忽略 ✓
→ 不会被陌生的远距离搞乱!✓指数衰减因子:让远距离安静下来
bash
RoPE(原版):
旋转角度 = m × θᵢ
内积 ≈ 某个值(不保证随距离单调减小)
xPOS(改进版):
在旋转的基础上,加入衰减因子 γᵢ
内积 ≈ γ^(m-n) × 某个值
关键:γ < 1
所以 γ^(m-n) 随距离(m-n)增大而减小!
当距离=1时:γ¹ ≈ 0.99 (几乎不衰减)
当距离=10时:γ¹⁰ ≈ 0.9 (稍微衰减)
当距离=100时:γ¹⁰⁰ ≈ 0.37 (明显衰减)
当距离=1000时:γ¹⁰⁰⁰ ≈ 0.00 (趋近于0)
效果:
就像声音随距离的衰减------
近处:清晰可闻 ✓
远处:逐渐减弱 ✓
极远:几乎听不到(自然忽略)✓不同维度有不同衰减速度
bash
高频维度(快速旋转的那些):
→ 衰减也快
→ 主要关注近距离关系(1~10步)
低频维度(慢速旋转的那些):
→ 衰减也慢
→ 可以关注中远距离(10~100步)
示意图:
高频维度的注意力: 低频维度的注意力:
↑ ↑
1|█ 1|████████
| ██ | ████
| █████ | ████████
| ████████ | ████████████
└──────────→距离 └────────────────────────────→距离
专注近距离 兼顾远距离
多维度组合:
既关注近邻,也兼顾远端,分工协作!✓Blockwise Causal Attention
bash
xPOS还引入了"分块注意力":
普通Decoder注意力:
每个词看所有之前的词
计算量:O(n²) ← 序列越长越贵!
分块注意力:
把序列分成固定大小的"块"(比如每块256词)
[块1][块2][块3][块4][块5]
↑我在这
可以看到: ✓ ✓ ✓ ✓ ✓
详细程度: 少 少 中 多 全
超出一定范围的块 → 直接忽略!
好处:
✅ 计算量大幅降低
✅ 强制模型聚焦有效范围
✅ 与指数衰减配合,忽略极远距离
→ 外推性能显著提升!五、综合对比:一张图看懂所有位置编码
bash
位置编码家族谱:
绝对位置编码(门牌号时代):
BERT → 可学习的固定编码(每个位置一个向量)
Transformer → 三角函数固定编码
相对位置编码(距离时代):
XLNet → 四项分解,保留所有交互
T5 → 简化到两项(语义+标量偏置)
ALiBi → 最简单(线性惩罚)
DeBERTa → 三项分解,删除纯位置交互
旋转位置编码(旋转时代):
RoPE → 用旋转统一绝对和相对位置 ← 当前主流
xPOS → RoPE + 指数衰减,更好的外推性
YaRN → 调整旋转频率,支持超长上下文
代表模型:
LLaMA 1/2/3 → RoPE ← 当前最流行
ChatGLM → RoPE变体
GPT-NeoX → RoPE
Mistral → RoPE