HarmonyOS 6 自定义人脸识别模型10:基于MindSpore Lite框架的自定义人脸识别功能实现
1. 引言与背景
通过前面几篇文章的摸爬滚打,我们已经学会了 MindSpore Lite 的基本套路 ,也搞定了 第三方 TFLite 模型转 .ms 的绝活。光说不练假把式,今天这篇就是系列的**"终局之战"**!
我们要把前面学到的东西全部串起来,基于真实的业务项目 RealTimeFaceDetection,实现一个实时运行的人脸检测相机应用。前置摄像头一开,我们的脸走到哪,红色的追踪框就跟到哪,完全不依赖系统自带的 Vision Kit,用咱们自己的模型硬刚!
2. 整体打通:相机画面内容流转流程图
在发车看代码之前,我们先得理清整个应用架构的"血液"是怎么流动的。因为涉及到相机硬件捕捉和底层 AI 高强度计算,我们不能把活全推给 ArkTS,必须是 C++ 扛起算力大旗,ArkTS 负责貌美如花(UI展示)。
下面这个流程图,清晰地展示了从你打开相机到屏幕画出红框的完整生命周期:
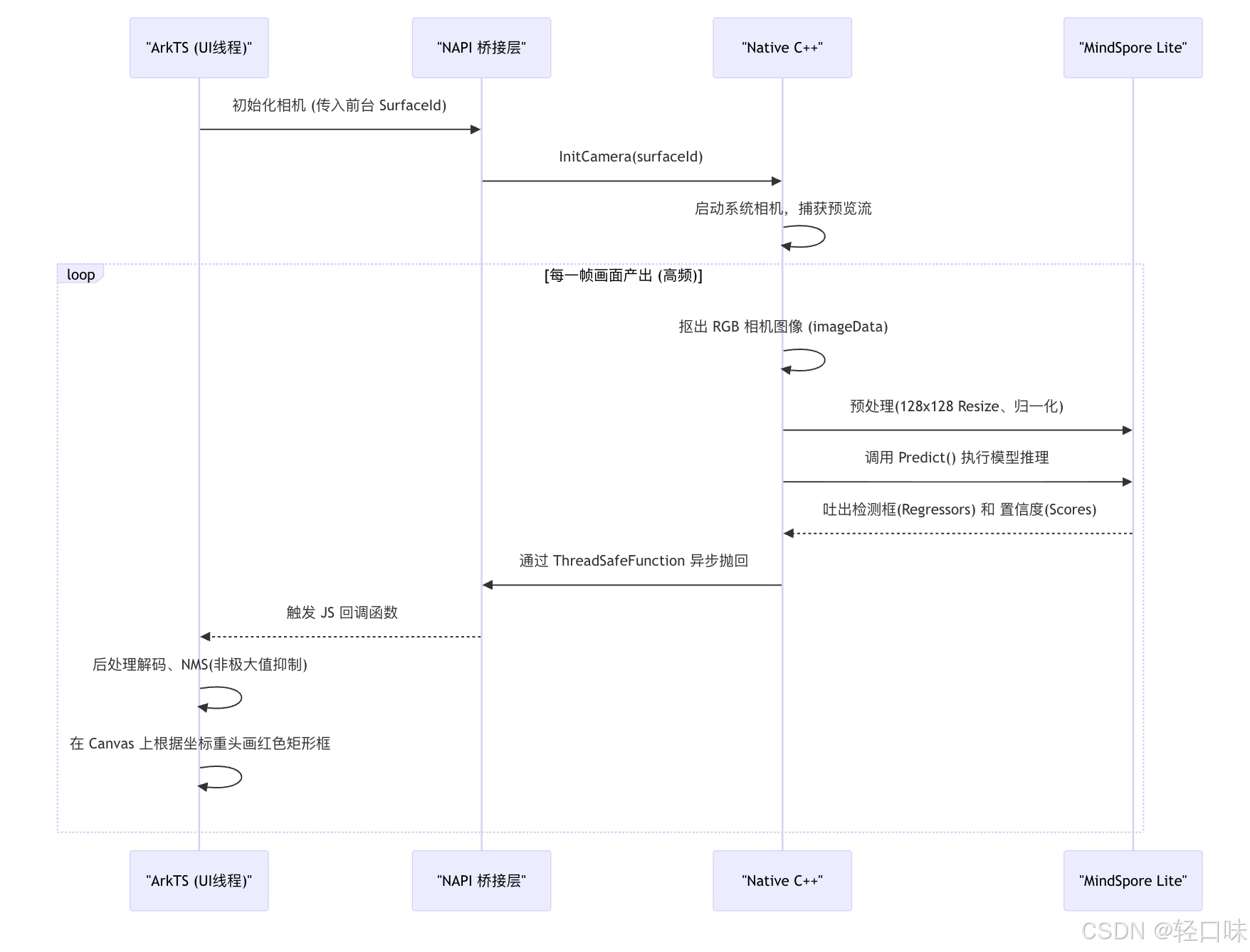
大白话总结一下:C++ 在后台拼命截图算数据,算出结果后"咻"的一下通过 NAPI 扔到前台,ArkTS 接住数据飞速地在屏幕上画个框。
3. Native 核心一:初始化模型与大起底输入输出
任何深度学习模型都是个"娇贵"的黑盒,你不按它的口味喂数据,它分分钟死机崩溃给你看。我们先来看 C++ 侧怎么在应用启动时把它唤醒。
模型加载与上下文配置代码
这一段位于 FaceDetector.cpp,负责从我们打包进来的资源文件中读取 .ms 模型包。
cpp
int FaceDetector::Init(NativeResourceManager* resourceManager, const std::string& modelPath) {
size_t modelSize;
// 1. 从 RawFile 里把编译好的 .ms 文件读进内存大 Buffer
void* modelBuffer = ReadModelFile(resourceManager, modelPath, &modelSize);
if (modelBuffer == nullptr) return -1;
// 2. 创建上下文,重点:开启 FP16 半精度加速!
context_ = OH_AI_ContextCreate();
auto cpu_device_info = OH_AI_DeviceInfoCreate(OH_AI_DEVICETYPE_CPU);
// 大白话:这句代码能让模型在 ARM 芯片上跑得飞快,且几乎不掉精度
OH_AI_DeviceInfoSetEnableFP16(cpu_device_info, true);
OH_AI_ContextAddDeviceInfo(context_, cpu_device_info);
// 3. 构建模型对象,然后释放临时的文件 Buffer
model_ = OH_AI_ModelCreate();
auto ret = OH_AI_ModelBuild(model_, modelBuffer, modelSize, OH_AI_MODELTYPE_MINDIR, context_);
free(modelBuffer);
// 4. 重头戏:探查模型需要的 Input 长宽
auto inputs = OH_AI_ModelGetInputs(model_);
auto tensor = inputs.handle_list[0];
size_t shape_num = 0;
auto shape = OH_AI_TensorGetShape(tensor, &shape_num);
// 拿到模型的输入宽高(例如 128x128)
inputHeight_ = (int)shape[1];
inputWidth_ = (int)shape[2];
LOGI("Model initialized. Input size: %dx%d", inputWidth_, inputHeight_);
return 0;
}深入理解输入(Input)与输出(Output)参数
上面代码在打印 Input size。以我们移植的 BlazeFace 人脸模型为例:
- 关于 Input 参数 :
- 尺寸与通道 :要求输入的分辨率非常袖珍,通常是
128 x 128,通道是RGB。也就是说不管原生相机给了你多大多高清的 4K 画面,我们统统要缩小。 - 值范围 (归一化) :模型是不认识
0~255的颜色值的。它需要被"压扁"到[-1.0, 1.0]的区间。具体的数学公式就是(像素值 / 127.5) - 1.0。
- 尺寸与通道 :要求输入的分辨率非常袖珍,通常是
- 关于 Output 参数 :
- 模型计算完,并不会直接给你
(x, y, w, h)的坐标!它吐出的是两个张量 (Tensor) 矩阵数组: - Scores (得分) :对应
896个预设锚点框(Anchor)有人脸的概率。 - Regressors (回归框偏移量) :也是长度极长的一串数据(
896 * 16 = 14336)。它告诉你如果这地方有脸,脸的大小和人脸关键点的微调量是多少。
- 模型计算完,并不会直接给你
4. Native 核心二:推理与 NAPI 跨线程异步回调
相机拿到画面后,立刻进行推断,并通过一个神奇的桥梁把结果发给 ArkTS。
推理与图像预处理逻辑
来看看底层 C++ 捕获到一帧图片 imageData 后是怎么操作的:
cpp
std::vector<std::vector<float>> FaceDetector::Detect(const unsigned char* imageData, int width, int height) {
auto inputs = OH_AI_ModelGetInputs(model_);
float* data = static_cast<float*>(OH_AI_TensorGetMutableData(inputs.handle_list[0]));
// 核心大缩水阶段:把源相机的高清水灵大图,缩并抽出变成 128x128 的小块
for (int y = 0; y < inputHeight_; ++y) {
for (int x = 0; x < inputWidth_; ++x) {
// 粗暴简单的最邻近插值法算原图坐标
int src_x = x * width / inputWidth_;
int src_y = y * height / inputHeight_;
int idx = (src_y * width + src_x) * 4; // 假设原图是 RGBA 的 4 通道
// 下面就是标准模型预处理:RGBA 抠出 RGB,同时从 0~255 变成 -1~1 的浮点数
int offset = (y * inputWidth_ + x) * 3;
if (data) {
// (数值 / 127.5) - 1.0 完美归一化
data[offset] = (static_cast<float>(imageData[idx]) / 127.5f) - 1.0f;
data[offset + 1] = (static_cast<float>(imageData[idx + 1]) / 127.5f) - 1.0f;
data[offset + 2] = (static_cast<float>(imageData[idx + 2]) / 127.5f) - 1.0f;
}
}
}
// "脑力劳动"开始:真正调用底层引擎执行推理
auto outputs = OH_AI_ModelGetOutputs(model_);
OH_AI_ModelPredict(model_, inputs, &outputs, nullptr, nullptr);
// 把算出来的结果 (Scores 和 Regressors) 捞出来装进 std::vector 里返回
std::vector<std::vector<float>> results;
for (size_t i = 0; i < outputs.handle_num; i++) {
float* outData = static_cast<float*>(OH_AI_TensorGetMutableData(outputs.handle_list[i]));
size_t num = OH_AI_TensorGetElementNum(outputs.handle_list[i]);
results.push_back(std::vector<float>(outData, outData + num));
}
return results;
}跨线程数据"偷渡"者:ThreadSafeFunction
大坑预警 :C++ 的那一套相机帧回调是在独立的子线程发生的。如果你在这个线程直接去调 JS 的函数,应用 100% 会 Crash!
正确的破局之道是利用鸿蒙提供的 NAPI 特性:napi_create_threadsafe_function(线程安全函数)。它就像一个异步快递员。
cpp
// 位于 napi_init.cpp
void HandleFacesDetected(std::vector<std::vector<float>> faces, void* context) {
if (!g_tsfn) return; // 检查快递员是否注册
// 把得到的人脸数据 new 一份在堆里扔包裹
auto data = new std::vector<std::vector<float>>(faces);
// 把数据扔给快递通道,底层的 JS 线程排队之后会安全收到!
napi_call_threadsafe_function(g_tsfn, data, napi_tsfn_blocking);
}5. ArkTS 核心三:XComponent 与 Canvas 画框逻辑
经过 C++ 的一番折腾,我们的 JS 层终于收到了回传的置信度得分和矩阵。
这里的难点有两处:
- 怎么画:底下一层铺满相机预览,上面盖一层透明玻璃(Canvas)用来拿画笔画画。
- 画在哪里:前置摄像头的逻辑都是镜像的,坐标一定要反过来算!
看 Index.ets 的精华结构:
typescript
@Entry
@Component
struct Index {
@State faces: Face[] = [];
// ... 初始化定义
// 画框的核心函数
drawFaces() {
this.canvasContext.clearRect(0, 0, this.canvasWidth, this.canvasHeight); // 清空上一帧
this.canvasContext.strokeStyle = '#FF0000'; // 设定画笔是骚气的红色
this.canvasContext.lineWidth = 3;
// 细节填坑: 我们的模型只吃了一个正方形(1:1),屏幕是细长的,所以要算居中的 Offset 偏移量
const isPortrait = this.canvasHeight > this.canvasWidth;
const size = isPortrait ? this.canvasWidth : this.canvasHeight;
const offsetX = isPortrait ? 0 : (this.canvasWidth - size) / 2;
const offsetY = isPortrait ? (this.canvasHeight - size) / 2 : 0;
this.faces.forEach((face) => {
// 史诗级填坑:如果是前置摄像头抓脸,屏幕看到的是镜像,X 轴必须反转!
const mirroredX = 1 - face.x2;
// 把 AI 给的 [0~1] 的比例系数值,用屏幕 size 映射回来
const x = mirroredX * size + offsetX;
const y = face.y1 * size + offsetY;
const w = (face.x2 - face.x1) * size;
const h = (face.y2 - face.y1) * size;
this.canvasContext.strokeRect(x, y, w, h); // 最终画出红色矩形
});
}
build() {
Stack() {
// 1. 底层:Camera Preview 相机预览
XComponent({
id: 'cameraPreview',
type: 'surface',
controller: this.xComponentController
}).onLoad(() => {
// 初始化时把这个画布的 ID 传给 C++ 绑卡相机去
entry.initCamera(this.xComponentController.getXComponentSurfaceId());
})
.width('100%')
.height('100%')
// 2. 顶层:Drawing Overlay 在玻璃上画红框
Canvas(this.canvasContext)
.width('100%')
.height('100%')
.onReady(() => { this.drawFaces(); })
}
}
}!NOTE
收到 C++ 回传那大量的
regressors和scores时,我们在 ArkTS 层还需要执行decodeBlazeFace(按 Anchor 解码出绝对坐标)和nonMaxSuppression(非极大值抑制 NMS,把脸上重叠十几个框剃成唯一的一个最佳框),这里因为偏向纯前端算法处理,暂不在此篇堆砌太多 JS 代码。
6. 运行效果展示
打通所有的任督二脉之后,把应用安装到真机上跑起来。
首先系统会弹框让你授予相机权限。点同意以后,瞬间唤起 XComponent 呈现顺滑的镜头预览流。
与此同时,C++ 开始在黑暗的高速通道狂奔,你只要一露脸就可以看到下图的惊艳效果:一层又厚又红的边框立刻将你的整个人脸锁定,不管你是摇头还是移动,这个红色追分框仿佛长了眼睛跟得死死的!
下面是我自己用摄像头进行的效果,人脸遮挡一下:

下面是实时预览过程中的日志:
总结
从模型格式转换到今天的高压实战。在这场硬仗中,我们通过 C++ 高效截取底层视频流并完成像素映射转换,驱动 MindSpore Lite 获取极致的推理性能;再从多线程通信中化险为夷,最后加上灵活的 ArkTS UI 和逆映射策略。
这就打通了鸿蒙边缘侧 AI 推理的全链路闭环 。有了这套骨架,你完全可以把 face_detection_front.ms 剥掉,换成自己训练的 宠物识别、红绿灯判定,直接开启你在鸿蒙生态的"超级视觉大门"吧!也可以基于检测模型得到的输出结果上传云端对人脸校验,实现真正的人脸识别功能。