系列导读
这是**《12课拆解Claude Code架构》**系列的第 1 课。
整个系列用 12 个递进式 Python 课程,从最小 Agent 循环出发,逐步叠加工具注册、计划系统、子 Agent、技能加载、上下文压缩、任务持久化、后台执行、多 Agent 团队、自治协作,一直到 Worktree 隔离执行------覆盖一个生产级 Agent Harness 的全部核心机制。
第 1 课的格言:
"One loop & Bash is all you need" ------ 一个工具 + 一个循环 = 一个 Agent。
后面 11 个课程,循环本身一行不改。所有新机制都在循环之外叠加。所以这一课,是地基中的地基。
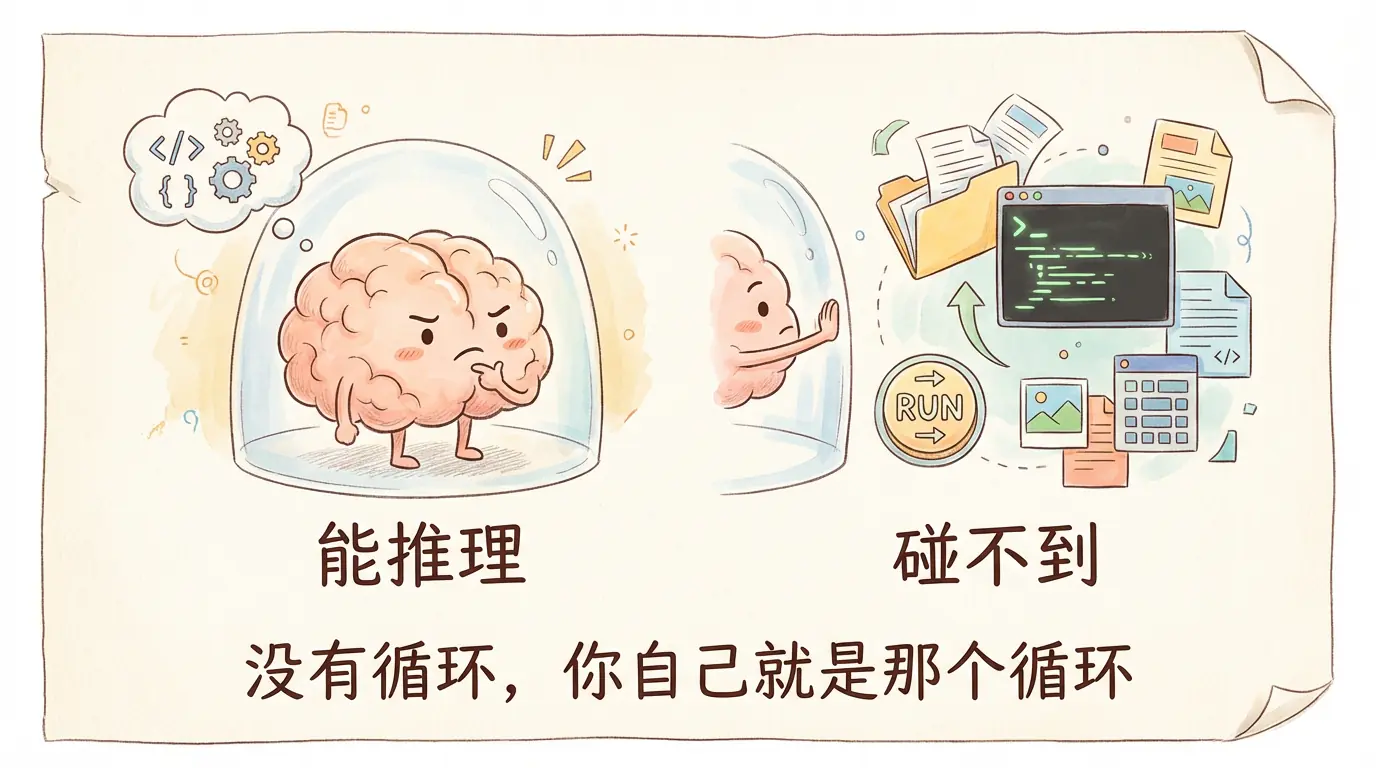
大模型的致命缺陷
Claude、GPT、Gemini,这些大模型能写代码、能分析 bug、能设计架构。但它们有一个致命缺陷:
碰不到真实世界。
不能读文件。不能跑测试。不能看报错。不能创建目录。不能执行任何命令。
你问它 "帮我创建一个 hello.py",它只能回复一段代码文本让你自己去复制粘贴。你问它 "这个测试为什么失败",它只能猜,因为它看不到实际的报错信息。
没有循环的时候,你自己就是那个循环------手动把模型的输出粘贴到终端,把终端的结果粘贴回模型,来来回回,直到任务完成。
Agent Loop 解决的就是这个问题:让模型自己完成这个循环。
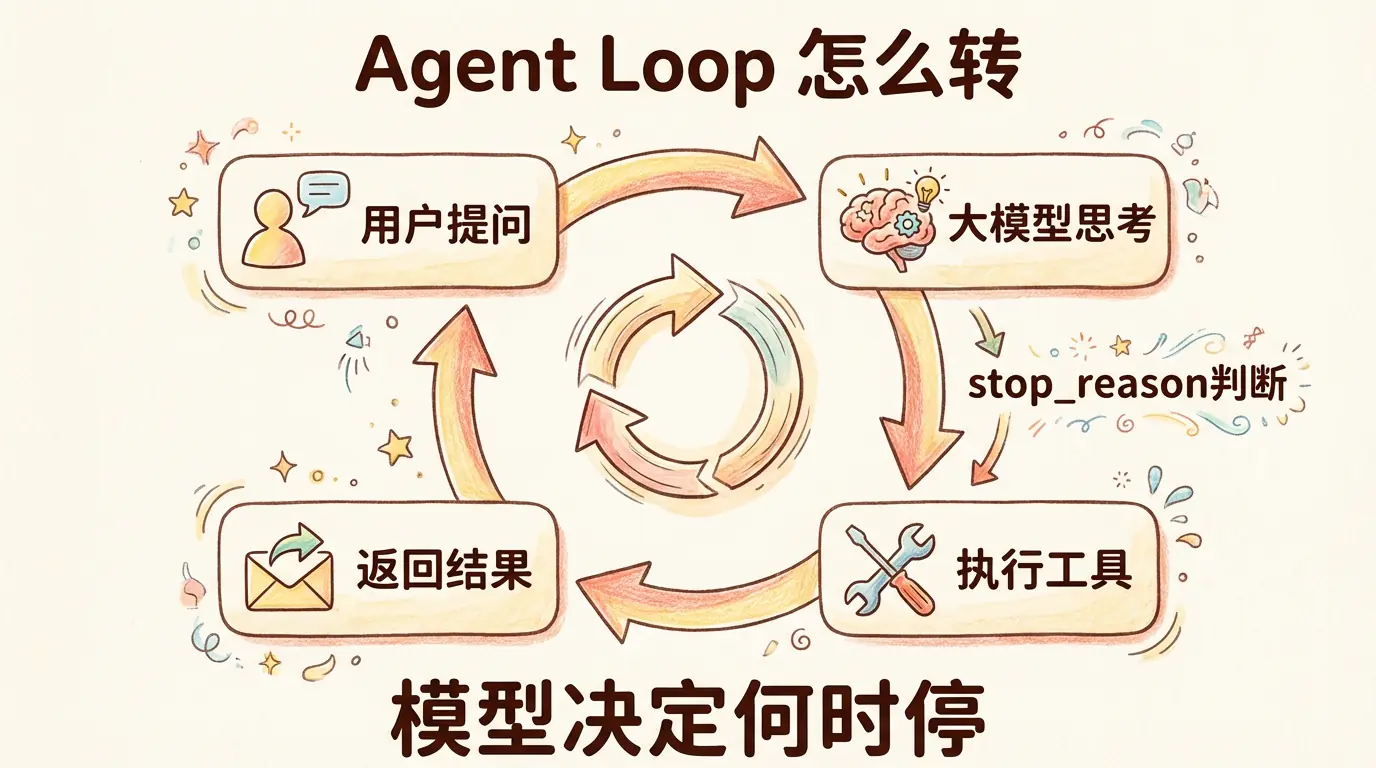
核心架构:一张图说清楚
sql
+--------+ +-------+ +---------+
| User | ---> | LLM | ---> | Tool |
| prompt | | | | execute |
+--------+ +---+---+ +----+----+
^ |
| tool_result |
+----------------+
(循环,直到模型不再调用工具)整个 Agent 的运转逻辑就这一张图:
markdown
1. 用户给一个任务 → 发送给大模型
2. 大模型思考后决定 :要不要调用工具?
3. 如果要调用 → 执行工具,把结果喂回给模型 → 回到第 2 步
4. 如果不调用 → 任务完成,返回最终回复
退出条件只有一个:模型自己决定不再调用工具。这就是所有 AI Agent 的骨架。Claude Code 是这样,Cursor 是这样,Windsurf 也是这样。不同的只是循环之外叠加的 Harness 机制------工具多少、有无计划系统、能不能多 Agent 协作------但核心循环永远是这一个。
四步拆解:从空白到 Agent
第一步:用户输入变成消息
python
messages = [{"role": "user", "content": query}]Anthropic Messages API 用一个列表管理对话。用户的输入是第一条消息。后面所有的助手回复、工具调用结果,都会追加到这个列表里。
这个列表就是 Agent 的全部记忆。
第二步:把消息和工具定义一起发给 LLM
python
response = client.messages.create(
model=MODEL,
system=SYSTEM,
messages=messages,
tools=TOOLS,
max_tokens=8000,
)关键参数是 tools。你告诉模型 "你有一个叫 bash 的工具,可以执行 shell 命令",模型就知道自己有了一双手。
工具定义长这样:
python
TOOLS = [{
"name": "bash",
"description": "Run a shell command.",
"input_schema": {
"type": "object",
"properties": {"command": {"type": "string"}},
"required": ["command"],
},
}]一个名字,一段描述,一个参数定义。这就是给模型的 "工具说明书"。模型读懂之后,就知道怎么调用这个工具了。
第三步:检查模型要不要调工具
python
messages.append({"role": "assistant", "content": response.content})
if response.stop_reason != "tool_use":
return # 模型决定不调工具了,任务完成Anthropic API 返回的 stop_reason 有两种关键值:
"tool_use"→ 模型想调用工具"end_turn"→ 模型觉得说完了
这一个判断就是整个循环的退出条件。模型自己决定什么时候停。
第四步:执行工具,把结果喂回去
python
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})模型说 "我要执行 cat hello.py",你就在本地跑这个命令,把输出结果以 tool_result 的格式追加到消息列表里。然后回到第二步,让模型看到结果后决定下一步。
组装:完整的 Agent Loop
把四步拼在一起,就是整个 Agent:
python
def agent_loop(messages: list):
while True:
# 发给模型
response = client.messages.create(
model=MODEL, system=SYSTEM,
messages=messages, tools=TOOLS,
max_tokens=8000,
)
# 记录助手回复
messages.append({"role": "assistant", "content": response.content})
# 退出条件:模型不再调工具
if response.stop_reason != "tool_use":
return
# 执行工具,收集结果
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
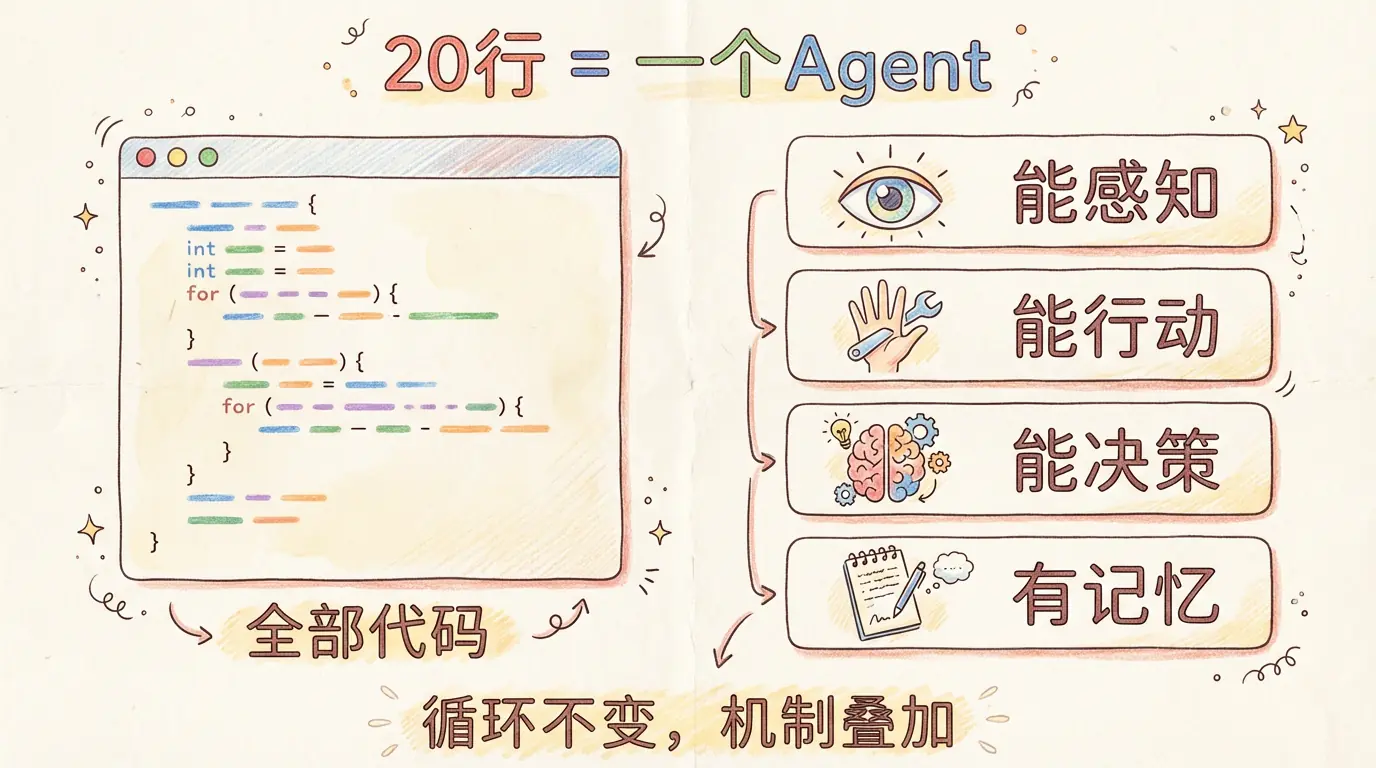
messages.append({"role": "user", "content": results})不到 20 行。这就是一个能操作真实世界的 AI Agent。
后面 11 个课程------工具注册、计划系统、子 Agent、上下文压缩、任务持久化、多 Agent 团队------全部都在这个循环之外叠加。循环本身,从第 1 课到第 12 课,一行不改。
实际运行:Agent 是怎么思考的
让我们看一个真实的执行过程。你给 Agent 一个任务:
"创建一个 hello.py,打印 Hello, World!"
Agent 的思考和行动链路:
makefile
用户: "创建一个 hello.py,打印 Hello, World!"
↓
模型思考: 我需要创建一个文件,用 bash 工具
↓
工具调用: bash → echo 'print("Hello, World!")' > hello.py
↓
工具结果: (空输出,表示成功)
↓
模型思考: 文件创建了,我验证一下
↓
工具调用: bash → cat hello.py
↓
工具结果: print("Hello, World!")
↓
模型思考: 内容正确,任务完成,不需要再调工具了
↓
stop_reason = "end_turn" → 循环退出
↓
最终回复: "已创建 hello.py,可以用 python hello.py 运行。"注意两个关键点:
- 模型自己决定要验证 ------没有人告诉它要
cat文件检查,它自己觉得应该验证。这就是 Agent 的自主性。 - 模型自己决定停止------确认文件正确后,它判断任务完成,不再调用工具。循环自然退出。
三个架构决策:为什么这样设计
决策一:为什么只用 Bash 一个工具
Bash 能读文件、写文件、执行程序、管理目录、安装依赖、跑测试、查看日志......几乎能做一切。
任何专门的工具------read_file、write_file、http_request------都只是 Bash 已有能力的子集。在第 1 课加更多工具,不会解锁新能力,只会增加模型需要理解的接口数量。
最小可行 Agent:一个工具,一个循环。
这也让一个核心洞见变得显而易见:一个 LLM + 一个 Shell,就已经是一个通用 Agent。后面的课程(s02)会加更多工具,但那是为了效率和安全,不是为了能力。
决策二:为什么没有规划框架
没有 Planner,没有 Task Queue,没有状态机。系统提示词告诉模型如何处理问题,模型根据对话历史自己决定下一步做什么。
这是有意为之的。在这个阶段,加规划层属于过早抽象。 模型的思维链本身就是计划。Agent Loop 只是不断问模型 "下一步做什么",直到模型说 "做完了"。
到第 3 课(TodoWrite),我们才会引入显式的规划系统。但第 1 课证明了:很多任务,隐式的模型推理就够了。
决策三:为什么退出条件这么简单
整个循环只看一个值:stop_reason != "tool_use"。
没有超时。没有最大轮次。没有错误计数器。
因为在教学场景下,简单就是正确。生产环境会加安全阈值(超过 N 轮强制停止、检测到危险命令拒绝执行),但核心退出逻辑永远是同一个:模型决定不再调用工具。
这个退出机制的优雅之处在于------你永远不需要预定义任务有几步。 简单任务一步完成,复杂任务十步完成,都是同一个循环。模型自己判断。
安全:最小但必要的防护
即使是教学代码,也不能裸奔。run_bash 函数做了最基本的防护:
python
def run_bash(command: str) -> str:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
try:
r = subprocess.run(
command, shell=True, cwd=os.getcwd(),
capture_output=True, text=True, timeout=120
)
out = (r.stdout + r.stderr).strip()
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
return "Error: Timeout (120s)"三层防护:
- 黑名单过滤 :拦截
rm -rf /、sudo等危险命令 - 超时控制:120 秒没跑完强制终止
- 输出截断:最多返回 50000 字符,防止上下文爆炸
生产环境需要更完善的沙箱(Docker 容器、文件系统权限隔离),但原则是一样的:让 Agent 能动手,但不能乱来。
五分钟跑起来
bash
# 克隆仓库
git clone https://github.com/shareAI-lab/learn-claude-code
cd learn-claude-code
# 安装依赖
pip install -r requirements.txt
# 配置 API Key
cp .env.example .env
# 编辑 .env,填入你的 ANTHROPIC_API_KEY 和 MODEL_ID
# 启动第一课
python agents/s01_agent_loop.py启动后你会看到一个交互式终端提示符 s01 >>,可以直接输入任务。以下是真实的运行记录:
任务 1:创建文件
perl
s01 >> Create a file called hello.py that prints "Hello, World!"
$ cat > hello.py << 'EOF'
print("Hello, World!")
EOF
(no output)
$ python3 hello.py
Hello, World!
`hello.py` has been created and works correctly --- it prints `Hello, World!`.注意 Agent 不仅创建了文件,还主动运行了一次验证------没有人让它这么做。
任务 2:探索环境
bash
s01 >> List all Python files in this directory
$ find . -name "*.py" -type f
./hello.py
./tests/test_agents_smoke.py
./agents/s01_agent_loop.py
...
A total of 21 Python files were found.任务 3:获取系统信息
css
s01 >> What is the current git branch?
$ git branch --show-current
main
The current git branch is main.一轮调用就结束------Agent 判断信息已经足够,不需要再调工具。
任务 4:多步操作
bash
s01 >> Create a directory called test_output and write 3 files in it
$ mkdir -p test_output
(no output)
$ cat > test_output/output1.txt << 'EOF'
This is the first test output file.
EOF
cat > test_output/output2.json << 'EOF'
{"name": "test_output", "file_number": 2, "status": "success"}
EOF
cat > test_output/output3.csv << 'EOF'
id,name,value
1,alpha,100
2,beta,200
EOF
(no output)
$ ls -l test_output/
output1.txt output2.json output3.csv
Done! Created the test_output directory with 3 files.Agent 自主决定了文件格式(txt、json、csv),自主验证了创建结果。你只给了目标,没给步骤。
每一个任务,Agent 都会自主决定执行什么命令、要不要验证结果、什么时候停下来。你不需要告诉它步骤,只需要告诉它目标。
总结:你刚造了什么
| 组件 | 之前 | 之后 |
|---|---|---|
| Agent 循环 | 无 | while True + stop_reason |
| 工具 | 无 | bash(单一工具) |
| 消息管理 | 无 | 累积式消息列表 |
| 退出机制 | 无 | stop_reason != "tool_use" |
| 代码量 | 0 | ~120 行(含安全防护和交互界面) |
核心代码不到 20 行,但它已经是一个功能完整的 AI Agent:
- 能感知环境(通过 bash 读取文件、查看状态)
- 能行动(通过 bash 执行命令、创建文件)
- 能自主决策(模型决定下一步、何时停止)
- 有记忆(累积式消息列表保存完整上下文)
这四个能力------感知、行动、决策、记忆------就是 Agent 的定义。
下一课预告
第 1 课只有一个工具 bash。虽然 bash 什么都能做,但让模型每次都拼 shell 命令效率不高,也不够安全。
第 2 课:Tool Use ------ 从 1 个工具扩展到多个。核心模式是一个 dispatch map:工具名映射到处理函数。新增工具只需注册,循环不用碰。
python
# 预告:s02 的 dispatch map
TOOL_HANDLERS = {
"bash": run_bash,
"read": read_file,
"write": write_file,
"edit": edit_file,
}
output = TOOL_HANDLERS[tool_name](**tool_input)加一个工具,只加一个 handler。循环一行不改。
这是《12课拆解Claude Code架构:从零掌握Agent Harness工程》系列的第 1 课。关注Claw开发者,不错过后续更新。
完整代码和交互式学习平台:github.com/shareAI-lab...
如果这篇文章对你有帮助,欢迎转发给你的技术团队。
系列目录
- 第1课:用20行Python造出你的第一个AI Agent(本文)
- 第2课:给Agent加工具 ------ dispatch map模式详解
- 第3课:TodoWrite ------ 让Agent先想后做:规划系统
- 第4课:Subagent ------ 拆解大任务,上下文隔离
- 第5课:按需加载领域知识------Skill机制
- 第6课:无限对话------上下文压缩三层策略
- 第7课:任务持久化------文件级DAG任务图
- 第8课:后台执行------异步任务与通知队列
- 第9课:Agent Teams------多Agent协作:团队与邮箱系统
- 第10课:团队协议------状态机驱动的协商
- 第11课:自治Agent------自组织任务认领
- 第12课:终极隔离------Worktree并行执行
📌 本文原始链接 :第1课:用20行Python造出你的第一个AI Agent
🔗 更多 AI Agent 开发实战教程,访问 HuanCode
💻 完整代码仓库:github.com/shareAI-lab...