Day 3:逻辑回归与分类预测
逻辑回归,虽然名字里带有"回归",但它却是解决分类问题最基础、最重要的算法之一。
📋 目录
- 逻辑回归基础原理
- Sigmoid函数详解
- 决策边界与分类
- 交叉熵损失函数
- 优化算法
- 多分类扩展
- 评估指标回顾
第一部分:逻辑回归基础原理(1.5小时理论)
1.1 为什么需要逻辑回归?
典型的分类问题,我们的目标不是预测一个连续的数值(比如房价),而是预测一个离散的类别标签。
如果我们强行使用之前学过的线性回归来解决这个问题,会遇到什么麻烦呢?
- 输出值范围不对 :线性回归的输出是任意实数,范围是 (−∞,+∞)(-\infty, +\infty)(−∞,+∞)。但分类问题,特别是二分类,我们希望得到的是"是"或"否"(通常用1和0表示)。
- 对异常值敏感:假设我们用0表示"否",1表示"是"。线性回归的拟合直线可能会被极端的异常值轻易地拉偏,导致分类阈值(比如0.5)的判断完全失效。
因此,我们需要一种新的模型,它能将线性模型的输出"压缩"到一个固定的范围内,比如(0, 1),并将其解释为概率。这就是逻辑回归诞生的原因。
逻辑回归的优势:
- 输出可以解释为概率 P(y=1∣x)P(y=1|x)P(y=1∣x)
- 自然处理二分类问题
- 计算效率高,可解释性强
- 是许多量化策略的基准模型
1.2 从线性回归到逻辑回归
逻辑回归的本质,可以看作是"线性回归 + 一个特殊的函数"。逻辑回归先通过线性模型计算一个得分,再用Sigmoid函数把这个得分转换成概率。
第一步:线性组合
z=β0+β1x1+β2x2+⋯+βnxn=xTβ z = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_n x_n = \boldsymbol{x}^T \boldsymbol{\beta} z=β0+β1x1+β2x2+⋯+βnxn=xTβ
第二步:通过Sigmoid函数转换为概率
p=P(y=1∣x)=σ(z)=11+e−z p = P(y=1|\boldsymbol{x}) = \sigma(z) = \frac{1}{1+e^{-z}} p=P(y=1∣x)=σ(z)=1+e−z1
第三步:决策规则
y^={1if p≥0.50if p<0.5 \hat{y} = \begin{cases} 1 & \text{if } p \geq 0.5 \\ 0 & \text{if } p < 0.5 \end{cases} y^={10if p≥0.5if p<0.5
1.3 逻辑回归的假设
| 假设 | 说明 | 金融数据中的处理 |
|---|---|---|
| 二分类输出 | 因变量是0/1 | 涨跌、买卖信号 |
| 独立性 | 样本相互独立 | 时间序列需谨慎 |
| 线性决策边界 | 特征线性组合 | 可添加多项式特征 |
| 无多重共线性 | 特征相关性低 | 使用正则化 |
第二部分:Sigmoid函数详解
2.1 Sigmoid函数公式与性质
数学表达式 :
σ(z)=11+e−z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1
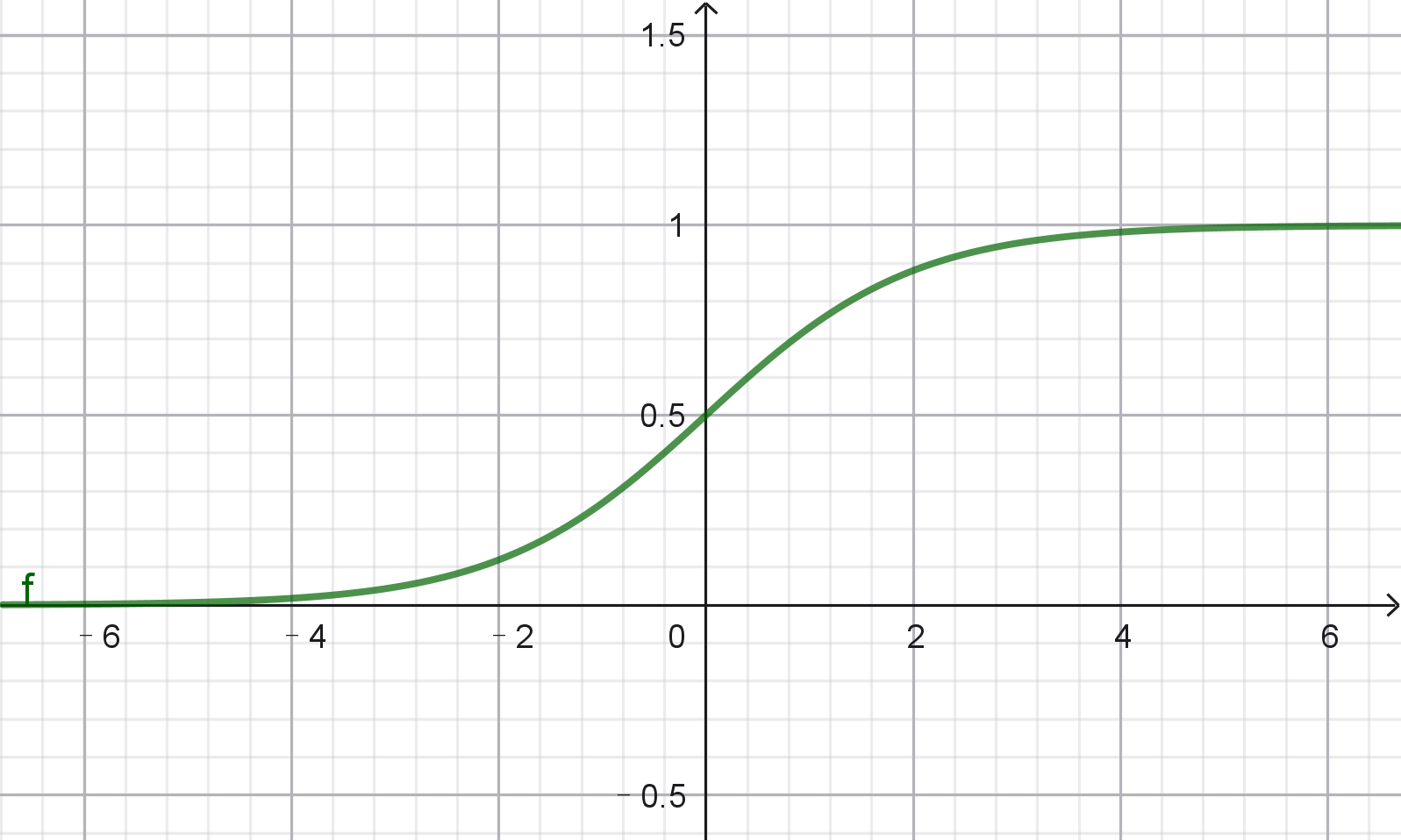
重要性质:
- 值域 :(0,1)(0, 1)(0,1)
- 对称性 :σ(−z)=1−σ(z)\sigma(-z) = 1 - \sigma(z)σ(−z)=1−σ(z)
- 单调递增 :zzz越大,σ(z)\sigma(z)σ(z)越接近1
- 可导性 :σ′(z)=σ(z)(1−σ(z))\sigma'(z) = \sigma(z)(1 - \sigma(z))σ′(z)=σ(z)(1−σ(z))
2.2 Sigmoid的导数推导
ddzσ(z)=ddz(11+e−z)=e−z(1+e−z)2=σ(z)(1−σ(z)) \frac{d}{dz}\sigma(z) = \frac{d}{dz}\left( \frac{1}{1+e^{-z}} \right) = \frac{e^{-z}}{\left(1+e^{-z}\right)^2} = \sigma(z)\bigl(1 - \sigma(z)\bigr) dzdσ(z)=dzd(1+e−z1)=(1+e−z)2e−z=σ(z)(1−σ(z))
重要性:导数可以用函数值本身表示,简化梯度计算。
2.3 Sigmoid的饱和问题
从图像上我们可以看到,当 z 的值非常大(比如 > 5)或非常小(比如 < -5)时,函数曲线变得非常平缓,几乎是一条水平线。这个区域被称为饱和区。
在饱和区,函数的导数 σ′(z)\sigma'(z)σ′(z) 趋近于0。这在梯度下降优化时会导致梯度消失 问题,使得参数 β\boldsymbol{\beta}β 的更新变得极其缓慢,从而影响模型的训练效率。这是Sigmoid函数的一个主要缺点。
第三部分:决策边界与分类
3.1 决策边界的概念
决策边界 :决策边界是特征空间中的一个超平面,它将不同类别的样本分隔开。对于逻辑回归,我们通常以0.5作为阈值:
σ(xTβ)=0.5 ⟹ xTβ=0 \sigma(\boldsymbol{x}^T\boldsymbol{\beta}) = 0.5 \implies \boldsymbol{x}^T\boldsymbol{\beta} = 0 σ(xTβ)=0.5⟹xTβ=0
这是一个线性决策边界(超平面)。
3.2 线性与非线性决策边界
标准的逻辑回归模型产生的是线性决策边界。这意味着它只能解决线性可分的问题。
但是,我们可以通过特征工程 来创造非线性边界。例如,我们可以增加多项式特征。
例如:原始特征是 x1x_1x1,我们可以构造新特征 x12x_1^2x12。这样,决策边界 β0+β1x1+β2x2+β3x12=0\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1^2 = 0β0+β1x1+β2x2+β3x12=0 在原始特征空间中就变成了一条曲线。
| 特征形式 | 决策边界 | 例子 |
|---|---|---|
| 原始特征 | 线性 | β0+β1x1+β2x2=0\beta_0 + \beta_1 x_1 + \beta_2 x_2 = 0β0+β1x1+β2x2=0 |
| 多项式特征 | 非线性(曲线) | β0+β1x1+β2x2+β3x12=0\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1^2 = 0β0+β1x1+β2x2+β3x12=0 |
| 交互特征 | 非线性 | β0+β1x1+β2x2+β3x1x2=0\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_1 x_2 = 0β0+β1x1+β2x2+β3x1x2=0 |
3.3 概率输出的解释
逻辑回归的强大之处在于它不仅给出分类结果,还给出了置信度(即概率)。
- p=0.9p = 0.9p=0.9:模型有90%的把握认为这个样本是正类。
- p=0.51p = 0.51p=0.51:模型只是略微倾向于正类,把握不大。
应用场景:
- 阈值调整:根据风险偏好调整决策阈值
- 置信度评估:高概率信号更可靠
- 仓位管理:概率越高,仓位可以越大
第四部分:交叉熵损失函数
现在我们知道如何预测了,接下来要解决的核心问题是:如何衡量预测的好坏,并据此优化模型参数?这就需要一个损失函数。
4.1 为什么不使用MSE?
均方误差(MSE)是线性回归的损失函数。如果我们把它直接用在逻辑回归上,会有以下问题:
- 非凸性:容易陷入局部最优
- 梯度消失:预测错误时梯度小,学习慢
- 概率解释差:惩罚方式不合理
4.2 交叉熵损失推导
为了得到一个凸的损失函数,我们使用交叉熵损失(也称为对数损失)。它的思想来源于最大似然估计。
单个样本的损失 :
L(y,p)={−log(p)if y=1−log(1−p)if y=0 L(y, p) = \begin{cases} -\log(p) & \text{if } y = 1 \\ -\log(1 - p) & \text{if } y = 0 \end{cases} L(y,p)={−log(p)−log(1−p)if y=1if y=0
统一形式 :
L(y,p)=−ylog(p)+(1−y)log(1−p) L(y, p) = -\left y \\log(p) + (1 - y) \\log(1 - p) \\right L(y,p)=−ylog(p)+(1−y)log(1−p)
直觉理解:
- 当 y=1y=1y=1 时:ppp 越接近1,损失越小
- 当 y=0y=0y=0 时:ppp 越接近0,损失越小
4.3 批量交叉熵损失
J(β)=−1m∑i=1my(i)log(p(i))+(1−y(i))log(1−p(i)) J(\boldsymbol{\beta}) = -\frac{1}{m} \sum_{i=1}^{m} \left y\^{(i)} \\log\\left(p\^{(i)}\\right) + \\left(1 - y\^{(i)}\\right) \\log\\left(1 - p\^{(i)}\\right) \\right J(β)=−m1i=1∑my(i)log(p(i))+(1−y(i))log(1−p(i))
其中 p(i)=σ(x(i)β)p^{(i)} = \sigma(\boldsymbol{x}^{(i)}\boldsymbol{\beta})p(i)=σ(x(i)β)
4.4 梯度计算
对参数的偏导 :
∂J∂βj=1m∑i=1m(p(i)−y(i))xj(i) \frac{\partial J}{\partial \beta_j} = \frac 1m \sum_{i=1}^{m}(p^{(i)} - y^{(i)})x_j^{(i)} ∂βj∂J=m1i=1∑m(p(i)−y(i))xj(i)
观察 :与线性回归的梯度形式相同!只是预测值 ppp 不同。
第五部分:优化算法
5.1 梯度下降更新规则
βj:=βj−α1m∑i=1m(p(i)−y(i))xj(i) \beta_j := \beta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( p^{(i)} - y^{(i)} \right) x_j^{(i)} βj:=βj−αm1i=1∑m(p(i)−y(i))xj(i)
5.2 与线性回归的对比
| 方面 | 线性回归 | 逻辑回归 |
|---|---|---|
| 输出范围 | (−∞,∞)(-\infty, \infty)(−∞,∞) | (0,1)(0, 1)(0,1) |
| 激活函数 | 线性 | Sigmoid |
| 损失函数 | MSE | 交叉熵 |
| 梯度形式 | (h−y)x(h-y)x(h−y)x | (h−y)x(h-y)x(h−y)x |
| 优化目标 | 预测连续值 | 预测类别概率 |
5.3 优化技巧
1. 特征缩放(必需)
和线性回归一样,对特征进行标准化或归一化可以大大加速梯度下降的收敛。
python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)2. 学习率调度
- 使用自适应优化器(Adam, RMSprop)
- 学习率衰减
3. 正则化(L1/L2)
为了防止过拟合,我们可以在损失函数中加入正则化项。
- L2正则化 (Ridge) :它会倾向于让参数 βj\beta_jβj 的值变小,但不会变为0。
LogisticRegression中的C参数就是正则化强度的倒数。 - L1正则化 (Lasso) :它倾向于让一些不重要的特征参数 βj\beta_jβj 变为0,从而实现特征选择。
python
from sklearn.linear_model import LogisticRegression
# L2正则化
lr_l2 = LogisticRegression(penalty='l2', C=1.0)
# L1正则化(特征选择)
lr_l1 = LogisticRegression(penalty='l1', solver='saga', C=1.0)第六部分:多分类扩展
6.1 One-vs-Rest (OvR)
策略 :假设有 K 个类别。我们为每个类别 k (k=1, 2, ..., K) 训练一个二分类逻辑回归模型。
- 在训练第
k个模型时,我们将所有属于类别k的样本作为正例(y=1),其余所有类别的样本作为负例(y=0)。 - 这样我们就得到了
K个模型。
预测 :对于一个新的样本 x,我们让它通过这 K 个模型,得到 K 个概率值。我们选择概率值最高的那个模型所对应的类别作为最终的预测结果。
python
# sklearn默认使用OvR
lr_multi = LogisticRegression(multi_class='ovr')6.2 Softmax回归(Multinomial)
Softmax回归是逻辑回归在多分类问题上的直接推广,也称为多项逻辑回归。
策略 :它不再训练 K 个独立的分类器,而是直接输出一个 K 维的概率向量。
对于一个样本 x\boldsymbol{x}x,模型会计算它属于每个类别 k 的得分 xTβ(k)\boldsymbol{x}^T \boldsymbol{\beta^{(k)}}xTβ(k)。然后通过 Softmax函数 将这些得分转换为概率:
p(y=k∣x)=exTβ(k)∑j=1KexTβ(j) p(y=k∣\boldsymbol{x}) = \cfrac{e^{\boldsymbol{x}^T \boldsymbol{\beta^{(k)}}}}{\sum_{j=1}^K e^{\boldsymbol{x}^T \boldsymbol{\beta^{(j)}}}} p(y=k∣x)=∑j=1KexTβ(j)exTβ(k)
特点:
- 直接输出多类概率
- 参数更多,但更优雅
python
# 使用softmax
lr_softmax = LogisticRegression(multi_class='multinomial', solver='lbfgs')第七部分:评估指标回顾
7.1 核心指标
| 指标 | 公式 | 适用场景 |
|---|---|---|
| 准确率 | (TP+TN)/总数 | 类别平衡 |
| 精确率 | TP/(TP+FP) | 减少误报 |
| 召回率 | TP/(TP+FN) | 减少漏报 |
| F1 | 2PR/(P+R) | 平衡指标 |
| AUC | ROC曲线下面积 | 类别不平衡 |
7.2 为什么AUC适合量化?
优点:
- 不受类别不平衡影响
- 评价排序能力(概率输出的质量)
- 单一指标,易于比较
量化应用:
- 涨跌预测的排序能力比绝对准确率更重要
- AUC越高,说明模型能更好地区分上涨和下跌股票