前言
前言
"全球校园人工智能算法精英大赛"是江苏省人工智能学会举办的面向全球具有正式学籍的全日制高等院校及以上在校学生举办的算法竞赛。其中的算法巅峰赛属于产业命题赛道,这是第3赛季,这次优化题的主题是 "碳中和"。

回顾
第七届全球校园人工智能算法精英大赛-算法巅峰赛产业命题赛第3赛季优化题--碳中和
该文章是对上文的补充,之前对模拟退火版本有所"遗憾",一直在找寻更好的操作因子。
之前的操作因子
- 随机任务重选择
python
# 随机一个tasks下标
idx = random.randint(0, N - 1)
# 挑选策略,挑选某个空闲服务器/放弃,重置赋值
assigns[idx] = selectorStrategy.select(servers)- 如果该 task 从未分配到分配,那这个操作因子,显然正收益
- 如果该 task 从分配到分配(不同服务器间切换),那这个操作因子,收益为 0
- 如果该 task 从分配到非分配,显然负收益
该因子只能结合模拟退火框架,1 属于贪心策略,2/3 属于跳出局部最优的尝试,但整体低效,收敛太慢。
Deepseek推荐的模拟退火版本也采用了这个因子,但是它的挑选策略是 带随机概率的最优位子。
但为什么,我觉得这种因子效果不好呢?
直觉上来说,能优化结果的,一定是多个操作的组合,单个操作太过流离。
思路
题目参见:碳中和
前几天,AI 推荐了一版强化学习解法,但实测效果并不佳,但它的核心思想,探索和利用,给了我一点小小的启发。
给定一个合法解:
a 0 , a 1 , . . . , a n − 1 {a_0, a_1, ..., a_{n-1}} a0,a1,...,an−1
a i a_i ai的值表示第 i i i 个 task分配到具体服务器编号(也可能不分配)
定义如下操作
- 按序重选择
- 挑选过程引入随机扰动
这里想了 2 种思路
- 保留前 k 个tasks 的选择,后面的 tasks 引入随机概率挑选其他服务器或弃选(k 也随机生成)
- 每一个 task,都有一定概率 p选择有别于之前 选择结果
这两种思路,都契合了
- 利用(Exploitation)
- 探索(Exploration)
和强化学习相比,没有学习过程。更像一个启发式的、随机的、贪婪的搜索操作。
该因子操作之后,能快速直接判定是否有收益。
因此无论采用爬山法,还是模拟退火(接受一定的劣质解)的启发式算法框架,可行有收益。
效果评估
采用统一的算法框架(模拟退火), 采用不同的因子进化
- 随机任务重选择(随机)
- 随机任务重选择(最优)
- 按序重选择(保留前 k 项,后面扰动)
- 按序重选择(每个都有概率扰动)
没有初始解,全靠因子迭代进化
| method | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | score |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 按序重分配(每个都概率扰动+最优挑选) | 13.00 | 27.11 | 25.83 | 39.53 | 38.00 | 41.47 | 53.89 | 66.74 | 69.70 | 95.53 | 470.80 |
| 按序重分配(每个都概率扰动+随机挑选) | 13.00 | 27.11 | 25.86 | 39.32 | 37.78 | 41.04 | 52.56 | 65.56 | 67.94 | 92.78 | 462.95 |
| 多策略混合(赛时440+) | 13.00 | 26.98 | 25.68 | 38.65 | 37.18 | 40.54 | 52.46 | 64.65 | 68.73 | 91.65 | 459.52 |
| AI(赛时430+) | 13.00 | 24.00 | 25.00 | 36.00 | 37.00 | 38.00 | 49.00 | 56.00 | 68.00 | 84.00 | 430.00 |
| 按序重分配(前k项保留后续扰动+随机挑选) | 13.00 | 26.80 | 24.50 | 37.99 | 32.28 | 37.41 | 33.39 | 42.90 | 54.81 | 86.47 | 389.55 |
| 随机任务重选择(挑选最优) | 11.74 | 25.77 | 25.36 | 35.30 | 33.18 | 34.10 | 43.48 | 50.58 | 58.40 | 63.24 | 381.15 |
| 贪心(赛时405) | 13.00 | 23.32 | 24.48 | 33.65 | 35.12 | 33.79 | 42.87 | 44.89 | 64.68 | 65.32 | 381.12 |
| 按序重分配(前k项保留后续扰动+最优挑选) | 13.00 | 25.33 | 24.73 | 28.44 | 28.09 | 34.38 | 50.86 | 39.63 | 65.28 | 61.30 | 371.04 |
| 随机任务重选择(随机挑选) | 10.10 | 24.67 | 23.92 | 28.15 | 30.82 | 28.21 | 34.80 | 36.14 | 51.38 | 52.85 | 321.04 |
| 单纯2个循环 | 11.28 | 23.71 | 21.27 | 24.57 | 24.93 | 23.73 | 29.28 | 31.00 | 47.05 | 42.36 | 279.18 |
| 全输出0(赛时80分) | 3.00 | 4.00 | 5.00 | 6.00 | 7.00 | 8.00 | 9.00 | 11.00 | 13.00 | 14.00 | 80.00 |
按分数线,都属于 巅峰赛的国一级别。
其中,按序重选择(每个都有概率扰动) 该因子结合模拟退火/爬山法,可以冲击赛时 第一。
按序重选择(每个都有概率扰动) 操作因子对下列因素敏感
- 排序策略(主)
- 服务器挑选策略(次)
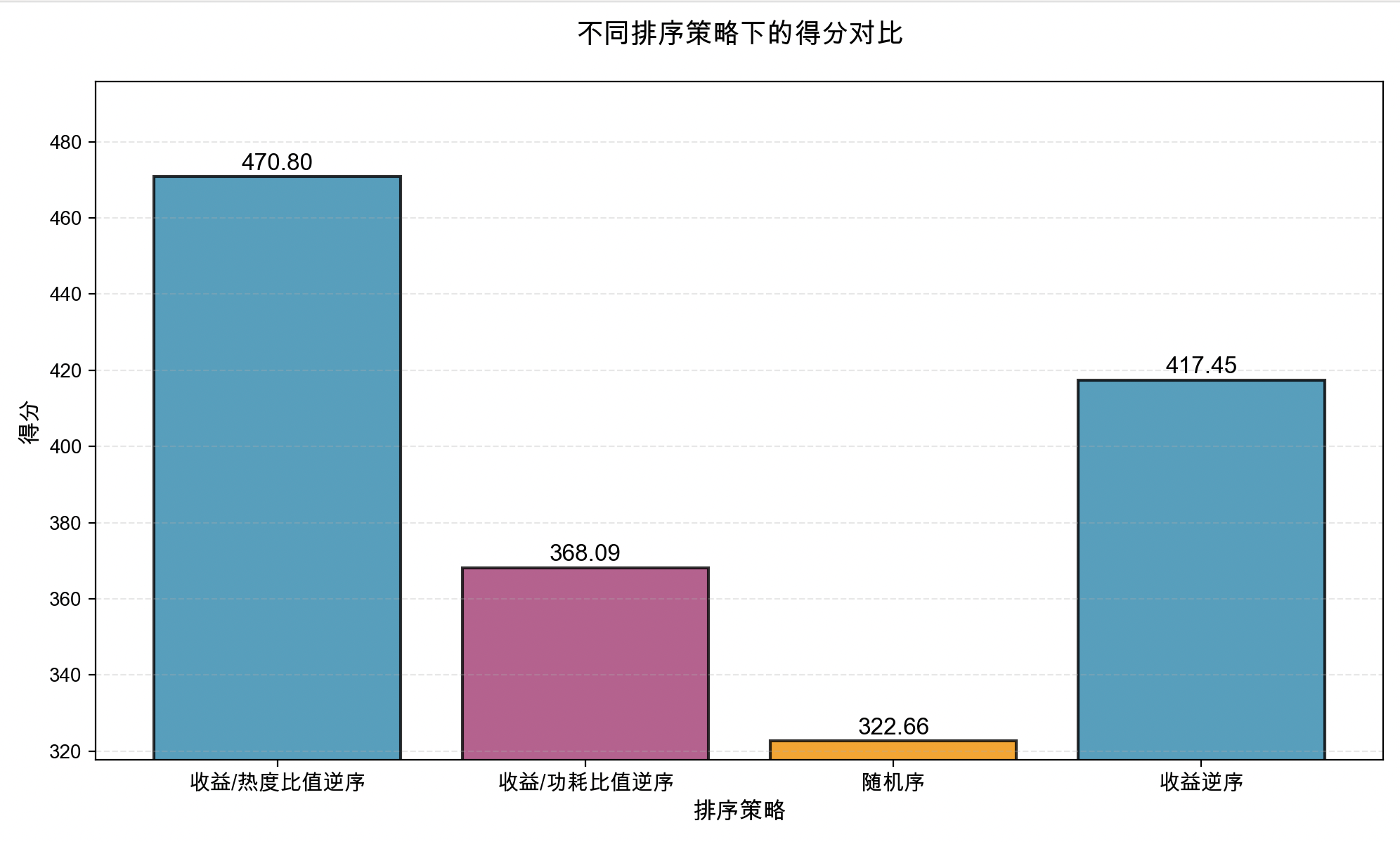
固定 带概率的最优服务器挑选策略,采用不同的排序策略,效果对比如下:
| 排序策略 | 收益/热度比值逆序 | 收益/功耗比值逆序 | 随机序 | 收益逆序 |
|---|---|---|---|---|
| 得分 | 470.80 | 368.09 | 322.66 | 417.45 |
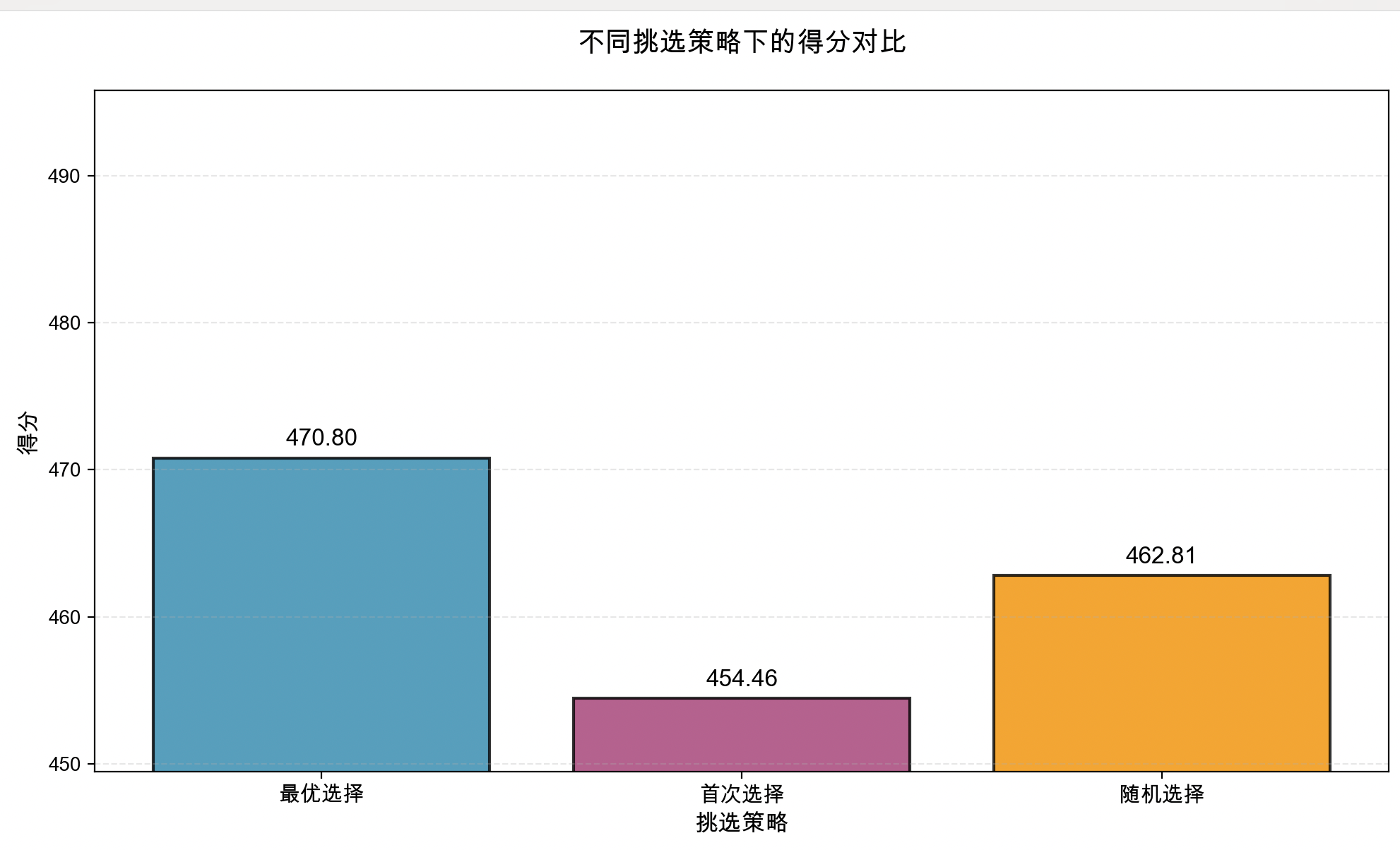
固定 按收益/热度比值逆序 排序,采用不同的服务器挑选策略,效果对比如下:
| 服务器挑选策略 | 最优选择 | 首次选择 | 随机选择 |
|---|---|---|---|
| 得分 | 470.80 | 454.46 | 462.81 |
代码
爬山法
cpp
#include <bits/stdc++.h>
using namespace std;
struct Task {
double gain;
double power;
double heat;
};
struct Server {
double power_limit;
double heat_limit;
};
class HeatChecker {
private:
const vector<Server>& servers;
double k;
int m;
public:
HeatChecker(const vector<Server>& servers, double k)
: servers(servers), k(k), m(servers.size()) {}
bool canPlace(const vector<double>& powers, const vector<double>& heats,
int pos, const Task& task) const {
if (task.power + powers[pos] > servers[pos].power_limit + 1e-9) return false;
double self_heat = heats[pos] + task.heat;
double lh = (pos > 0) ? heats[pos - 1] * k : 0.0;
double rh = (pos < m - 1) ? heats[pos + 1] * k : 0.0;
if (self_heat + lh + rh > servers[pos].heat_limit + 1e-9) return false;
if (pos > 0) {
double left_self = heats[pos - 1];
double left_influence = left_self + (heats[pos] + task.heat) * k;
if (pos - 1 > 0) left_influence += heats[pos - 2] * k;
if (left_influence > servers[pos - 1].heat_limit + 1e-9) return false;
}
if (pos < m - 1) {
double right_self = heats[pos + 1];
double right_influence = right_self + (heats[pos] + task.heat) * k;
if (pos + 1 < m - 1) right_influence += heats[pos + 2] * k;
if (right_influence > servers[pos + 1].heat_limit + 1e-9) return false;
}
return true;
}
};
class ServerScorer {
private:
const vector<Server>& servers;
double k;
public:
ServerScorer(const vector<Server>& servers, double k) : servers(servers), k(k) {}
double calculateScore(const vector<double>& powers, const vector<double>& heats,
int pos, const Task& task) {
double power_ratio = (powers[pos] + task.power) / servers[pos].power_limit;
double heat_ratio = (heats[pos] + task.heat) / servers[pos].heat_limit;
double heat_spread = heats[pos] + task.heat;
if (pos > 0) heat_spread += heats[pos - 1] * k;
if (pos < (int)servers.size() - 1) heat_spread += heats[pos + 1] * k;
double heat_ratio_with_spread = heat_spread / servers[pos].heat_limit;
double score = max(power_ratio, max(heat_ratio, heat_ratio_with_spread));
double remaining = min(servers[pos].power_limit - powers[pos] - task.power,
servers[pos].heat_limit - heats[pos] - task.heat);
score -= remaining / (servers[pos].power_limit + servers[pos].heat_limit) * 0.1;
return score;
}
};
class IntelligentSelector {
private:
const vector<Task>& tasks;
const vector<Server>& servers;
HeatChecker checker;
ServerScorer scorer;
mt19937 rng;
public:
IntelligentSelector(const vector<Task>& tasks, const vector<Server>& servers, double k)
: tasks(tasks), servers(servers),
checker(servers, k),
scorer(servers, k),
rng(random_device{}()) {}
int selectBestServer(int task_id, const vector<double>& powers,
const vector<double>& heats) {
const Task& task = tasks[task_id];
int best_pos = -1;
double best_score = 1e9;
for (int j = 0; j < (int)servers.size(); ++j) {
if (checker.canPlace(powers, heats, j, task)) {
double score = scorer.calculateScore(powers, heats, j, task);
if (score < best_score) {
best_score = score;
best_pos = j;
}
}
}
return best_pos;
}
int selectWithExploration(int task_id, const vector<double>& powers,
const vector<double>& heats, double epsilon = 0.05) {
uniform_real_distribution<double> dist(0, 1);
if (dist(rng) < epsilon) {
vector<int> valid;
for (int j = 0; j < (int)servers.size(); ++j) {
if (checker.canPlace(powers, heats, j, tasks[task_id])) {
valid.push_back(j);
}
}
if (valid.empty()) return -1;
uniform_int_distribution<int> idx_dist(0, valid.size() - 1);
return valid[idx_dist(rng)];
} else {
return selectBestServer(task_id, powers, heats);
}
}
};
int main() {
int n, m;
double k;
cin >> n >> m >> k;
vector<Task> tasks(n);
for (int i = 0; i < n; i++) {
Task &task = tasks[i];
cin >> task.gain >> task.power >> task.heat;
}
vector<Server> servers(m);
for (int i = 0; i < m; i++) {
Server &svr = servers[i];
cin >> svr.power_limit >> svr.heat_limit;
}
vector<int> ans(n, -1);
double tot_gain = 0;
vector<int> ids(n);
iota(ids.begin(), ids.end(), 0);
// 根据收益值排序
sort(ids.begin(), ids.end(), [&](const auto &a, const auto &b) {
return tasks[a].gain / tasks[a].heat > tasks[b].gain / tasks[b].heat;
});
HeatChecker heatChecker(servers, k);
mt19937 rng(random_device{}());
uniform_real_distribution<double> dist(0, 1);
IntelligentSelector selector(tasks, servers, k);
// 爬山法调参
double retentionRate = 0.75; // 保留率
double giveUpRate = 0.05; // 不选择任何服务器的概率
double selectorEpsilon = 0.1; // 挑选随机率
// 时间限制
time_t time_limit = 7;
time_t start_time = time(nullptr);
// 单纯的爬山
while (true) {
time_t end_time = time(nullptr);
if (end_time - start_time > time_limit) break;
double tmp_gain = 0;
vector<int> tmp_ans(n, -1);
vector<double> tmp_power(m, 0);
vector<double> tmp_heat(m, 0);
for (int i = 0; i < n; i++) {
int id = ids[i];
Task &task = tasks[id];
// 利用
double p = dist(rng);
if (p <= retentionRate) {
if (ans[id] == -1) {
tmp_ans[id] = -1;
continue;
} else if (heatChecker.canPlace(tmp_power, tmp_heat, ans[id], task)) {
tmp_ans[id] = ans[id];
tmp_power[ans[id]] += task.power;
tmp_heat[ans[id]] += task.heat;
tmp_gain += task.gain;
continue;
}
}
// 探索
p = dist(rng);
if (p < giveUpRate) {
continue;
}
int target = selector.selectWithExploration(id, tmp_power, tmp_heat, selectorEpsilon);
if (target != -1) {
tmp_ans[id] = target;
tmp_power[target] += task.power;
tmp_heat[target] += task.heat;
tmp_gain += task.gain;
}
}
if (tmp_gain > tot_gain) {
tot_gain = tmp_gain;
ans = tmp_ans;
}
}
for (int i = 0; i < n; i++) {
cout << (ans[i] + 1) << " \n"[i == n - 1];
}
return 0;
}从迭代进化的速度来看,初期非常陡峭
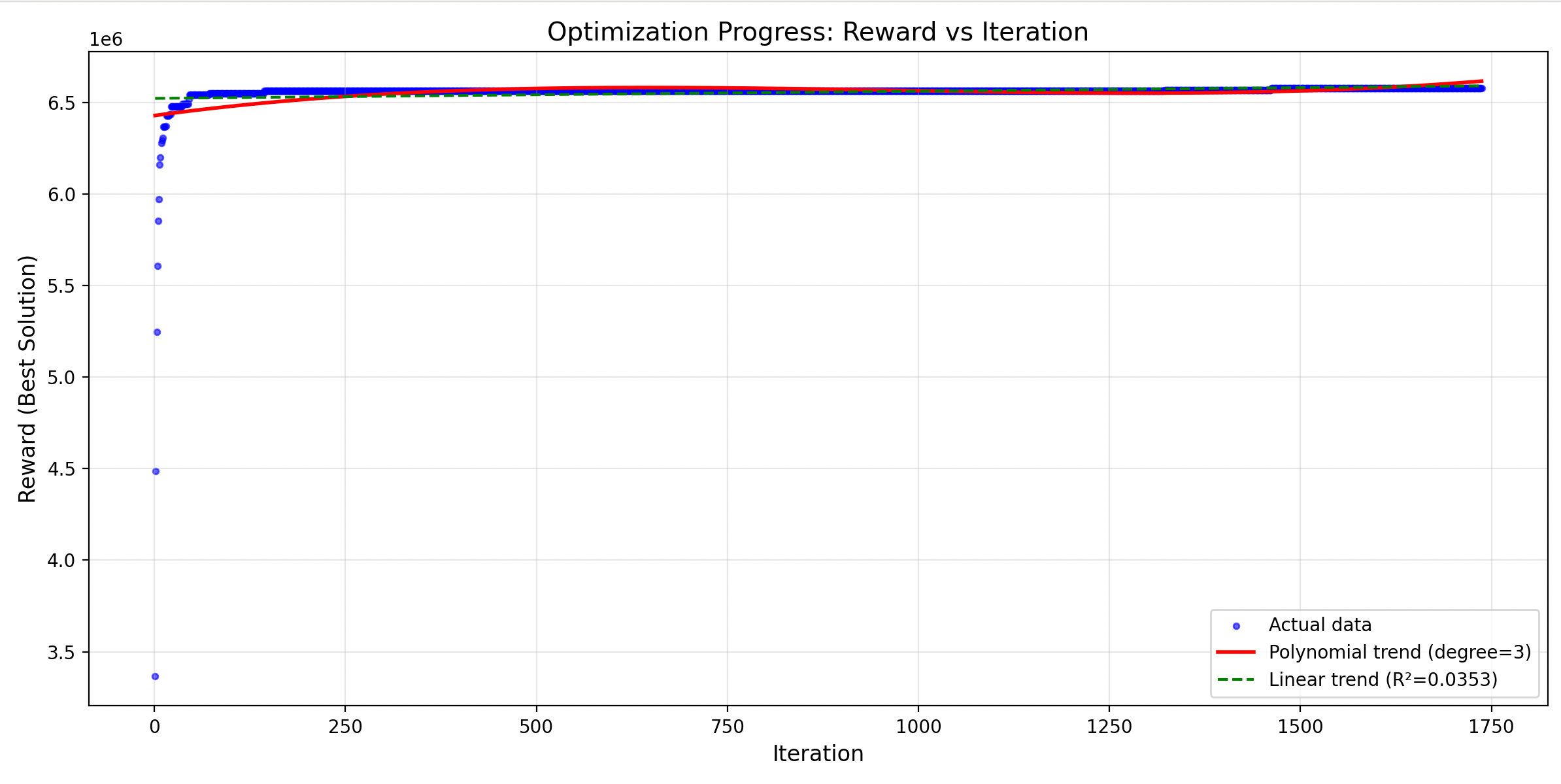
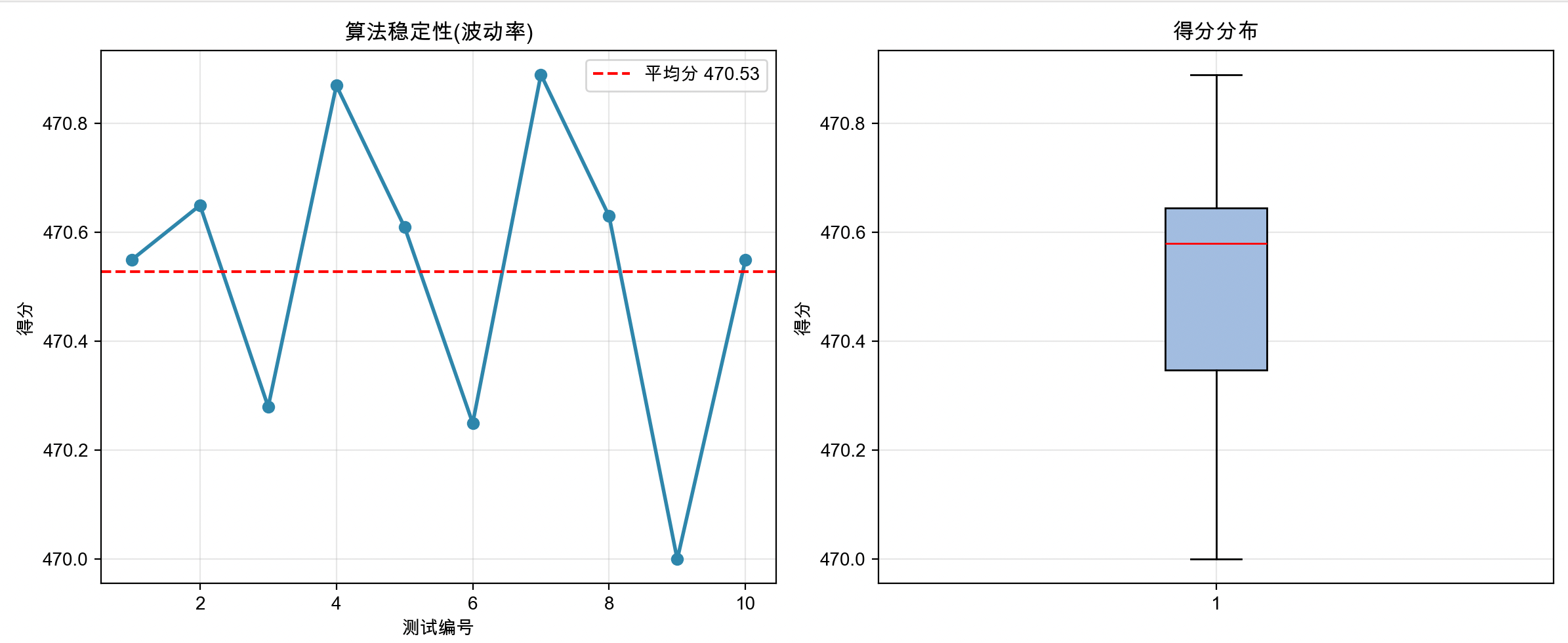
然后来看一下算法稳定性
| 测试 | 第1次 | 第2次 | 第3次 | 第4次 | 第5次 | 第6次 | 第7次 | 第8次 | 第9次 | 第10次 | 平均值 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 得分 | 470.55 | 470.65 | 470.28 | 470.87 | 470.61 | 470.25 | 470.89 | 470.63 | 470.00 | 470.55 | 470.528 |
借鉴意义
NPC(NP-Complete)难题中,如果涉及背包,任务分配/调度等问题,可以采用该因子,结合启发式算法,可以取得一个不错的结果。
写在最后
