seq2seq(Sequence to Sequence)架构翻译任务:
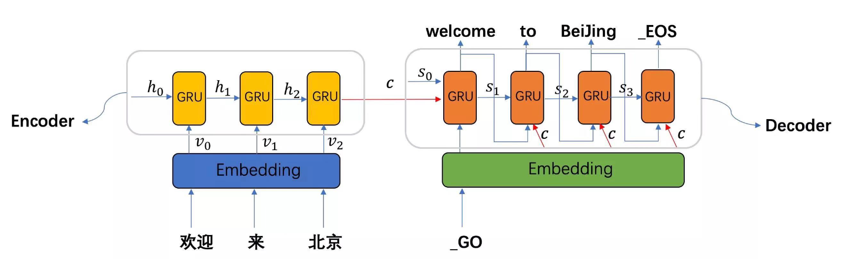
seq2seq模型架构包括三部分:encoder(编码器)、decoder(解码器)、中间语义张量c。图中表示的是一个中文到英文的翻译:欢迎来北京 - -> welcome to BeiJing。编码器首先处理中文输入"欢迎来北京",通过 GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量 c以及每一个时间步的隐层张量,逐个生成对应的翻译语言。
早期在解决机器翻译这一类 seq2seq问题时,通常采用的做法是利用一个编码器 (Encoder)和一个解码器 (Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
(解释:先把这3个词转成Embedding即词嵌入,一个向量,每个时间步通过 GRU也叫 RNN循环神经网络,本身是通过循环神经网络,每个时间步都会得到一个隐藏层张量的输出:'欢迎' 送到GRU得到 h1、'来' 送到GRU得到 h2、'北京' 送到GRU得到 h3、这些h1 h2 h3是每个时间步的输出张量;即将 3个单词进行 GRU进行转换:当前只有一个样本即一个句子 batch_size=1,3个单词即 seq_len=3:input=1, 3,5,GRU(5,10,1),则 output=1, 3, 10,此 output就是中间语义张量 C,它承接了所有编码信息,即原始的中文语义信息,拿到 C之后 再一个时间步一个时间步解码(或者说翻译);也可以将 output中 3个张量:1、3、10相加再平均来充当 C。hn=1, 1, 10 也可以充当 C,因为它代表了最后一个单词输出的词向量维度,它已经具备了上下文所有的语义;三种说法:① 可以用 output结果充当 C,因为它具备了上下文整个编码所有信息;② 可以把这 3个张量相加再平均来充当 C;③ 可以拿最后一个单词词向量维度当做 C;因为三者都包含了原始语义的所有信息。拿到 C之后,编码器部分和中间语义张量 C结束。)(每一步在翻译出新单词时都要用到中间语义张量 C,因为翻译成英文时必须要知道原始中文。如:解码预测时根据拿到的中间语义张量 C如何预测出 'welcome'?:首先要有一个 GO表示翻译的开始字符(对应有一个翻译的结束字符 EOS-End of Sentence),'GO'这个单词变成 Embedding,此 Embedding再和中间语义张量 C共同送给 GRU来预测出 'Welcome';图中的 S0、S1、S2、S3都是隐藏层张量,它们不仅可以横向箭头也可以向上箭头表示,但向上的如 S1不能直接得到 'welcome',它要经过一个 nn.Linear() 因为 linear才能输出,才能进行预测。图中 GRU接收了 3个参数:中间语义张量 C、GO、S0
)