模型蒸馏(Knowledge Distillation)
模型蒸馏是一种模型压缩技术,核心思想是用大模型(教师)教小模型(学生),让小模型在保持较小规模的同时,尽可能接近大模型的性能。
模型蒸馏分为目标蒸馏和特征蒸馏
目标蒸馏
软硬标签

目标蒸馏过程
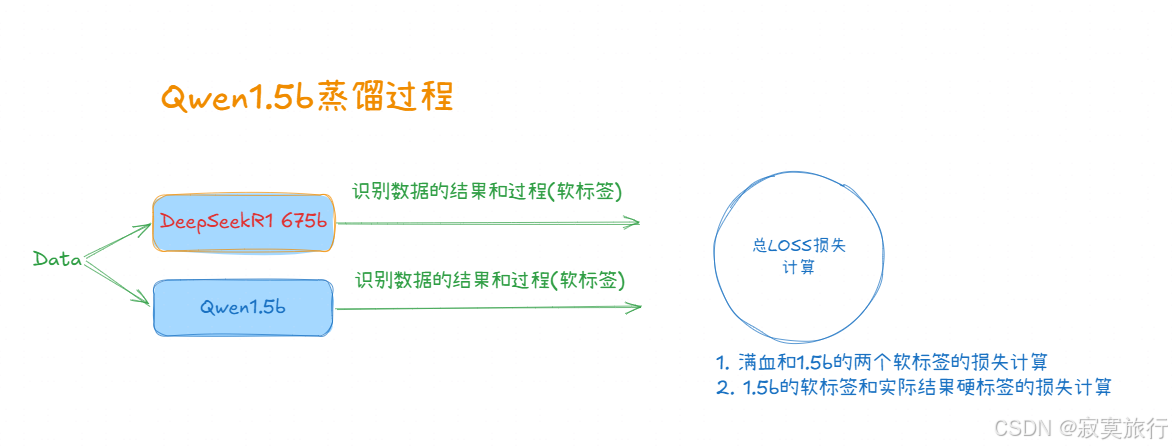
- 将 两个损失计算 加权计算后得到总的Loss损失函数,然后更新模型参数
- 整个过程可以用一个例子说明: 1.5b在 做试卷的题目, 满血 不仅要看1.5b 做的结果 (硬标签) 对不对, 还要看 题目的答题思路 (软标签) 是否正确;
特征蒸馏
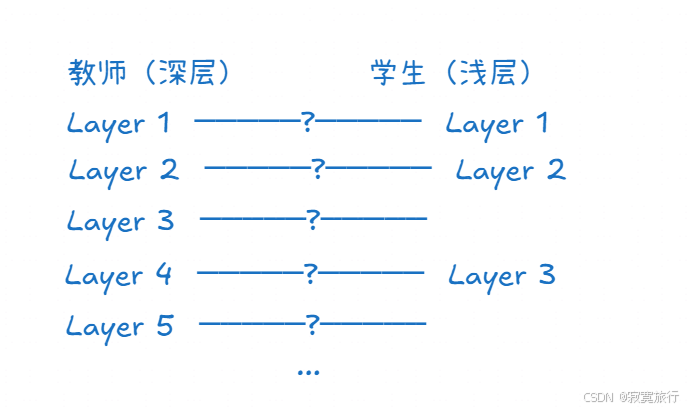
- 类似于做了一个 神经网络层 的关系映射 , 这样就能基本完美符合满血模型的真实思考过程了