AutoGLM vs 豆包手机:拆解两条 GUI Agent 的技术路线
一、先说背景
从 2024 下半年开始,手机上的 AI Agent 突然火了------不是那种聊天机器人,而是真的能帮你"动手操作手机"的 Agent。这个赛道里跑出来两个最有代表性的玩家:智谱的 AutoGLM 和字节的豆包手机。
这两个东西干的事情差不多------你告诉它"帮我用高德导航去三里屯",它就自己打开高德、搜索、点导航,全程不用你碰屏幕。但实现思路差别很大:AutoGLM 本质上还是个"挂在系统外面的 App",靠无障碍服务 + 抓包来实现;豆包手机则直接把 Agent 做进了系统 ROM 里,拿着系统级签名权限搞事情。
本文借助AI辅助逆向分析的能力,把这两套方案的技术差异掰开了说清楚。
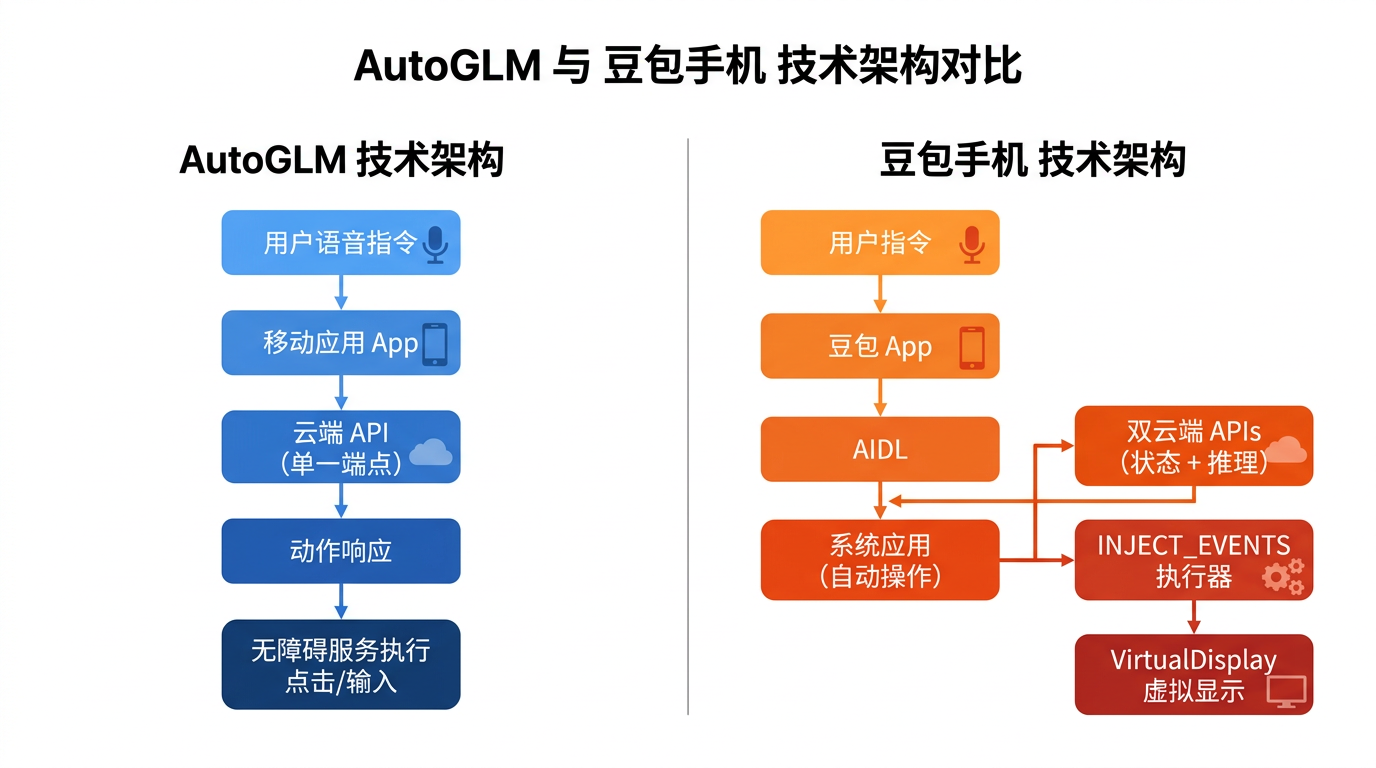
二、整体架构:一个挂外面,一个长里面
AutoGLM 的流程很直白:
用户说一句话 → App 拿到当前屏幕的 layout XML 和截图 → GZIP 压缩后一起扔给云端 agent.aminer.cn/agentapi/v2/proxy/controller → 云端模型想一想,返回一个"下一步动作"(比如点哪里、输什么字)→ App 执行 → 循环到任务结束。
一个接口打天下,整体非常轻量。它就是个普通 App,核心能力全在云端模型。
豆包手机就复杂多了:
字节在自家 ROM 里预装了一堆 com.obric.* 的系统应用------aikernel 做本地意图解析、autoaction 负责实际操作、还有 screenshot、deepcapture 等辅助角色。用户指令先经过豆包 App 判断是问答还是操作,如果是操作类的,就通过 AIDL 跨进程把指令传给 autoaction,然后 autoaction 每隔 3-5 秒截一次屏(大约 200-400KB 的 base64 图片)传给云端 inference 接口,云端模型看完截图告诉它下一步该干嘛。
简单说就是:AutoGLM 是"外挂式",豆包手机是"内置式"。
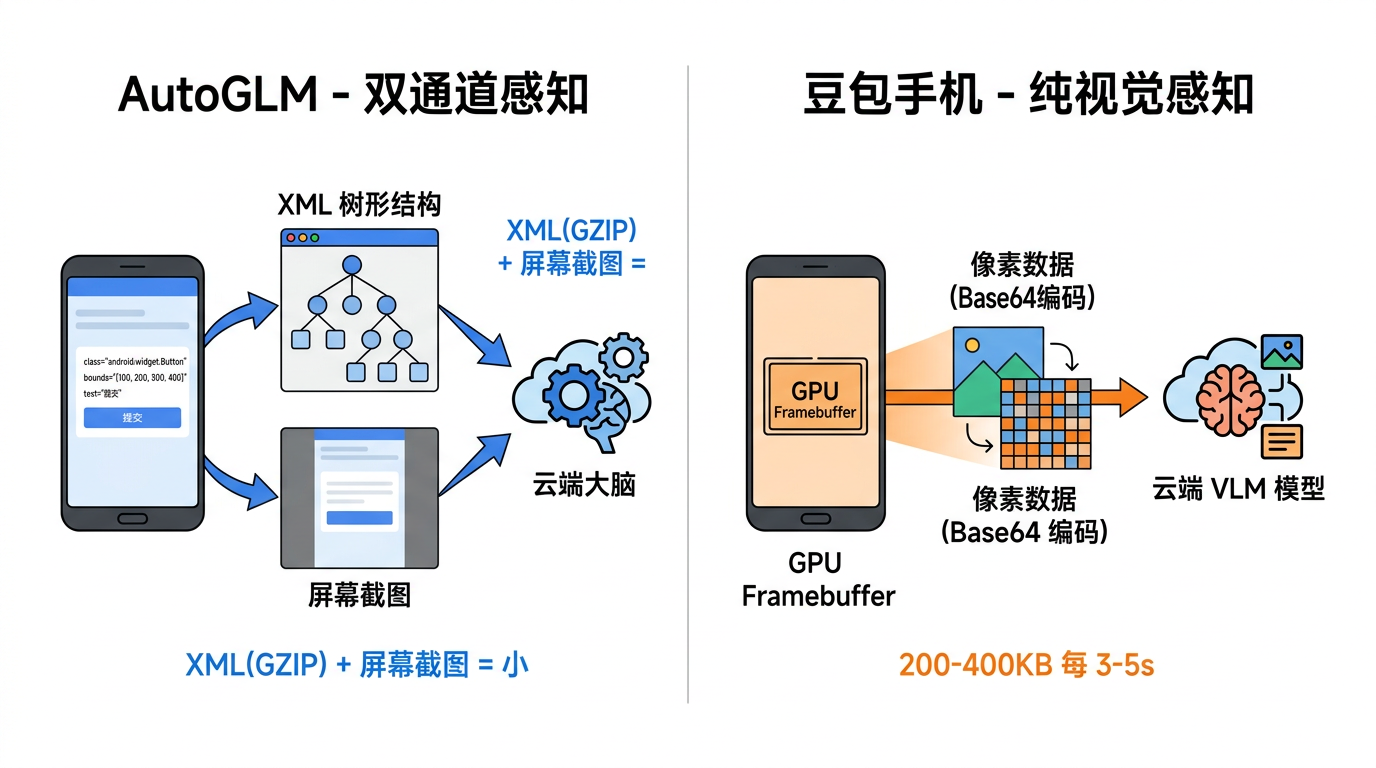
三、怎么"看"屏幕:XML+截图 vs 纯截图
这是两者一个挺本质的区别。
AutoGLM 的做法是"两条腿走路"。早期抓包分析显示,它会把当前页面的整个 View 树 dump 成 XML------里面每个控件的 class、resource-id、text、bounds、clickable 属性都有,GZIP 压完体积也不大。同时再附一张截图。这样云端模型既能通过 XML 精确知道"哪个按钮在哪个坐标",又能通过截图理解视觉语义。对模型来说相当友好,定位元素很准。
不过值得注意的是,开源版 Open-AutoGLM 走了一条更轻的路:它只截图,不抓 XML。通过 adb shell screencap 拿到 PNG 截图后转 base64,直接扔给视觉语言模型(VLM)。模型自己从图里判断要点哪里,返回归一化坐标(0-999 坐标系)。这说明随着 VLM 能力增强,XML 作为"拐杖"的必要性在降低------但有 XML 的版本精度确实更高。
豆包手机走的是纯视觉路线。它直接申请了 READ_FRAME_BUFFER 这个系统级权限,能读到 GPU 帧缓冲里的原始画面。什么 XML 不 XML 的,管它什么自绘 UI、Flutter、游戏界面------反正我都能截到。全靠云端的视觉模型(uitars)来"看图说话"。
代价也很明显:每次上行 200-400KB 的截图,对网络要求高;而且一旦断网,啥也干不了。有评论说"这手机网络要求很高",确实如此。AutoGLM 的 XML + 截图加一起比这小得多,回包延迟稳定在 1-4 秒。
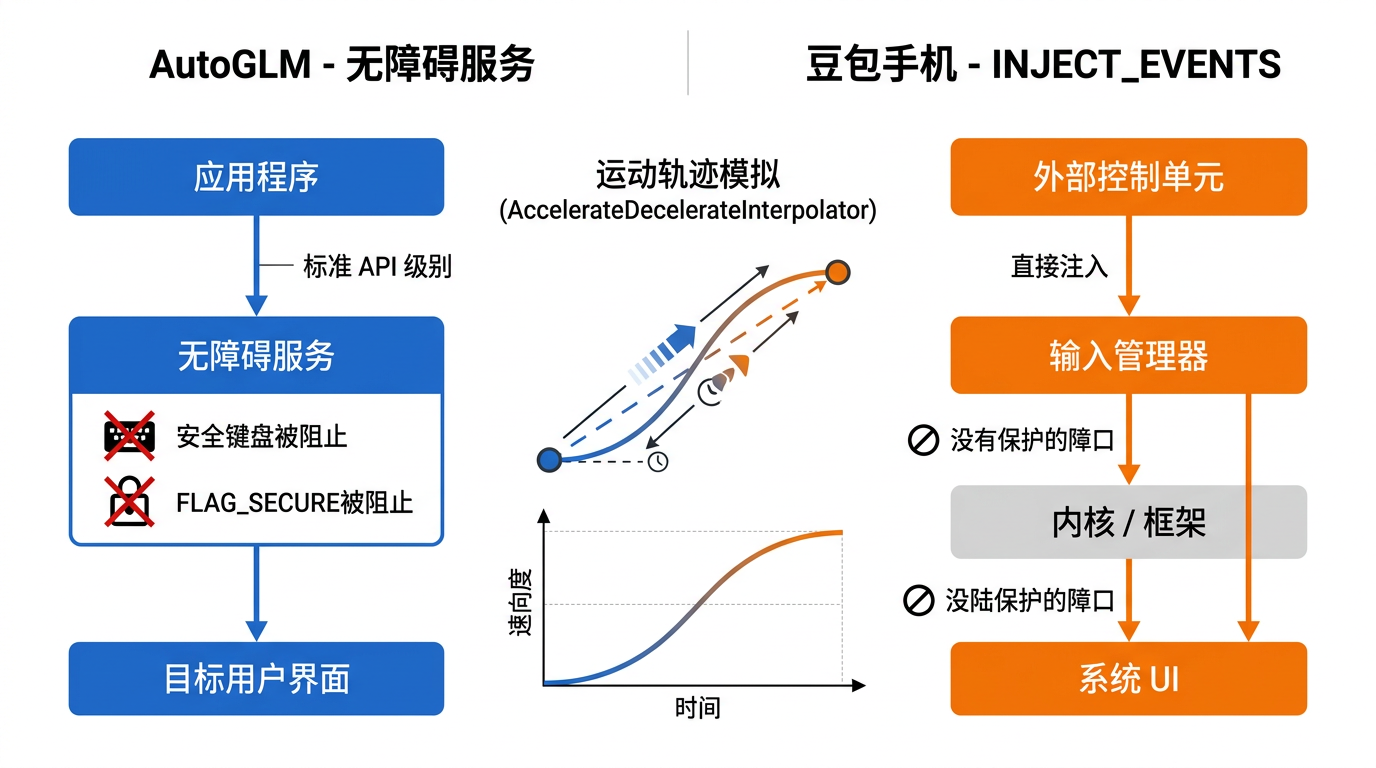
四、怎么"动手"操作:ADB/无障碍 vs 事件注入
这块差别最大,可以说是"外部遥控 vs 系统内核特权"的区别。
AutoGLM 的执行通道其实经历了一次演进。原始版本走的是 Android 无障碍服务(AccessibilityService),和 UiAutomator 一个级别。但到了开源版 Open-AutoGLM,它改用了 ADB(Android Debug Bridge)来控制设备------本质上是通过 USB 或 WiFi 连接,用 adb shell input tap x y 这种命令来点击,adb shell input swipe 来滑动。
具体流程是这样的:模型返回一个相对坐标(0-1000 的归一化坐标系),客户端做一次坐标转换 x = element[0] / 1000 * screen_width,然后直接执行 ADB 命令。文字输入更有意思------它会先通过广播机制切换到专门的 ADB Keyboard(不占屏幕空间),然后用 adb shell am broadcast -a ADB_INPUT_B64 --es msg <base64编码的文本> 来输入。输入完再切回原来的键盘。
而且 AutoGLM 还有一个关键的架构设计:规划-接地双模块分离。Planner(规划模块)负责把用户指令拆成人类可读的步骤描述,比如"点击搜索框→输入'咖啡'→选择最近的店→选椰子拿铁→设置半糖→确认订单";Grounder(接地模块)再把每个步骤翻译成具体的屏幕坐标和操作类型。这种拆分让系统更容易调试和优化------规划出错还是定位出错,一目了然。
ADB 方案的好处是不需要无障碍权限(很多用户对无障碍权限很敏感),也不需要 root,只要手机开了开发者选项就行。2.0 版本更激进------直接把操作环境搬到了云手机上(无影 AgentBay),本地设备零侵入。坏处嘛,ADB 毕竟是开发调试工具,操作速度和稳定性不如系统级方案,而且需要保持 ADB 连接。
豆包手机完全不走这些"外部"路线。它在 AndroidManifest 里声明了 INJECT_EVENTS 权限------这个权限只有系统签名应用才能拿到------然后通过反射调用 InputManager.injectInputEvent() 直接往底层注入触摸事件和按键事件。这比 ADB 或无障碍都狠多了,等于直接模拟硬件输入,任何 App 都分不出来这是真人还是机器(至少在 MotionEvent 层面几乎没区别)。
更讲究的是滑动实现:它用 ValueAnimator 驱动每一帧的坐标变化,配合 AccelerateDecelerateInterpolator(先加速后减速)来模拟真实的手指滑动轨迹------做到这个份上,确实很难被简单的行为检测抓住。
还有个细节:点击之前它会做"像素级前置检查",对比一下点击位置附近 4 像素的颜色有没有变化。如果发现页面已经跳了(比如弹了个广告),就不盲目点了。这种防误触机制在无障碍方案里基本做不到。
文字输入方面,AutoGLM 通过 ADB Keyboard 广播机制输入(base64 编码传输,不占屏幕空间);豆包手机则强行拉起自己预装的豆包输入法 com.bytedance.android.doubaoime 来配合------连输入法都是自己的。
三者的层级关系可以这样理解:ADB 是"用 USB 线遥控",无障碍是"在系统里装个助手",INJECT_EVENTS 是"直接当系统本身"。AutoGLM 选了最轻量的 ADB(开源版)/ 无障碍(原版),豆包手机选了最重的 INJECT_EVENTS。
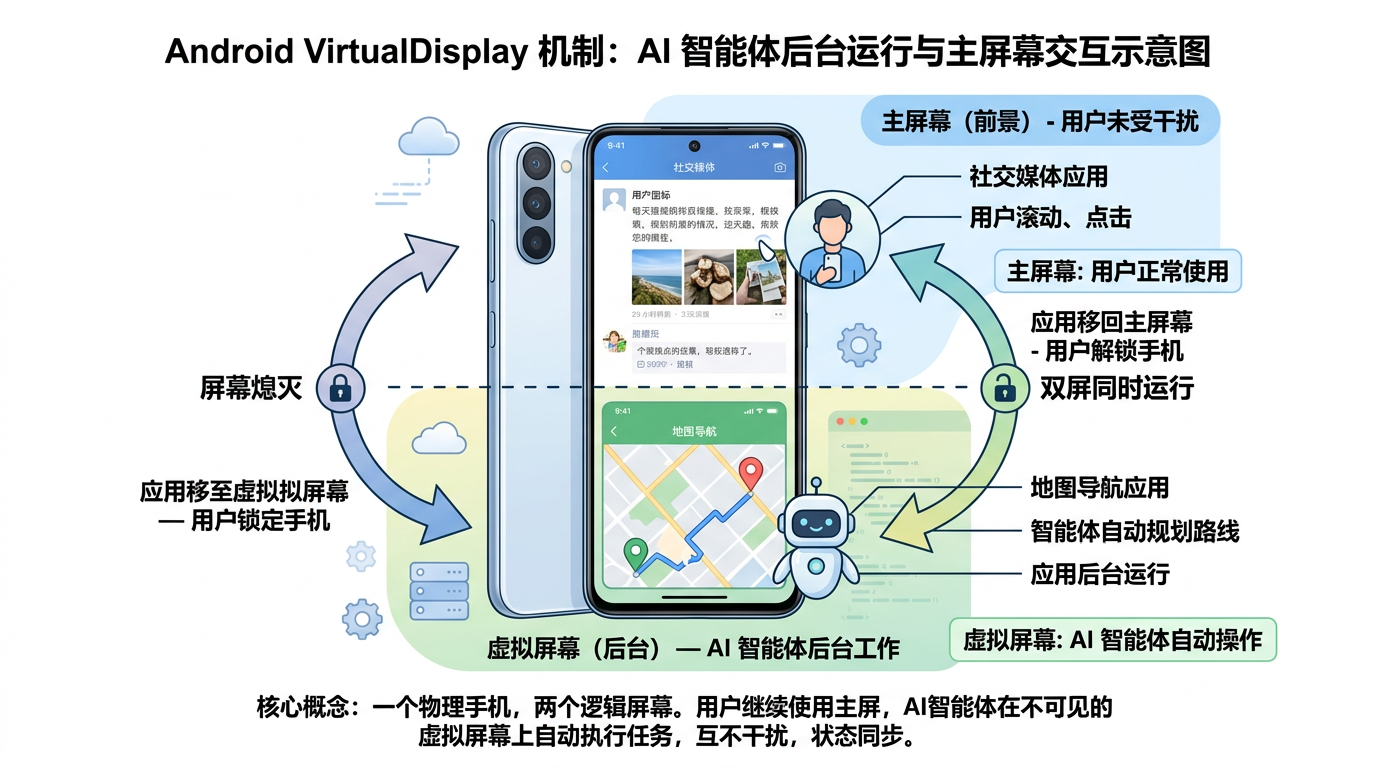
五、虚拟显示器:豆包手机的杀手锏
这是豆包手机最骚的操作。
AutoGLM 工作的时候,操作发生在你正在看的屏幕上------它点什么你都能看到,但你也没法同时做别的事,只能看着它操作。
豆包手机用了 Android 的 VirtualDisplay 机制,相当于在后台"凭空造了一块屏幕"。要操控的 App 被偷偷移到虚拟屏上运行,autoaction 在虚拟屏上点点点,你的主屏该刷抖音刷抖音、该聊微信聊微信,互不干扰。
它还做了完善的状态管理:亮屏的时候把虚拟屏里的 App 搬回主屏给你看进度;灭屏了就把 App 藏进虚拟屏继续干活;App 被杀了能感知到(trackingAppTerminated)。这一套 TaskStackListener + BroadcastReceiver 的调度,确保了"后台操作"这件事能稳定运行。
说白了:你可以一边刷手机,一边让 AI 在后台帮你干活。这是把 Agent 做到系统层才能实现的体验。
六、模型和协议:简单粗暴 vs 精细分工
AutoGLM 的网络协议简单到极致:就一个 controller 接口,进去是 XML + 截图 + instruction(总目标),出来是一个 JSON------里面 action 告诉你干嘛(Launch / Tap / Type / Interact / finish),bbox 和 absolute_coordinates 告诉你在哪干,kwargs 带具体参数(比如输入什么文字)。遇到拿不准的事(比如搜出多个地点选哪个),就返回 Interact action 加 message 字段反问用户。
抓包作者做了个有意思的对比实验:执行"预制任务"和"随机说一个任务",接口耗时都在 1-4 秒,没有明显差异。结论是每次都实时过大模型,不存在什么"预置脚本"------但模型训练里肯定塞了大量的 App 操作经验。
豆包手机的协议就重了:state 接口管会话生命周期(session_id、device_id、model_name 等一堆字段),inference 接口管单次推理。本地 aikernel 先做轻量级意图分类和权限校验(比如判断是不是在操作金融 App,是就直接拦掉),过关了才发到云端。请求/响应用 Kotlin 协程状态机驱动,有完整的挂起恢复机制。
一句话总结:AutoGLM 是"轻客户端 + 重云端",豆包手机是"中客户端 + 重云端 + 端侧兜底"。
七、可靠性和安全:各有各的坑
可靠性方面:
AutoGLM 靠 XML 的结构化语义兜底。XML 里的 resource-id、bounds、clickable 这些属性很强,模型不容易"点歪"。遇到弹窗等异常,客户端可能通过分析 XML 结构特征来判断,然后引导用户自行处理。信息不够的时候就 Interact 反问用户补齐参数。
豆包手机则在客户端做了更重的防护:点击前先检查 Activity 有没有变(变了就放弃)、再做像素对比(界面变了就不点)、还会回看最近 3 步历史操作。这套"多重保险"在长任务里确实更不容易翻车。
安全方面:
这块争议就大了。AutoGLM 好歹还是个普通 App,权限边界清晰,最大的风险是无障碍滥用和截图上传的隐私问题。
豆包手机的权限列表看了让人头皮发麻------READ_FRAME_BUFFER(读屏幕帧缓冲)、CAPTURE_SECURE_VIDEO_OUTPUT(捕获 DRM 保护的内容)、INJECT_EVENTS(注入输入事件)、FORCE_STOP_PACKAGES(强杀应用)、DEVICE_POWER(控制电源)......理论上它几乎可以对手机为所欲为。
实际上也确实引发了风控大战:多家 App 厂商已经对豆包手机做了识别和拦截,豆包官方也在 2025 年 12 月主动下线了金融类操作,限制了游戏、社交等场景。评论区有人说"从创新上看开了个好头,从产品上看这个模式已经被抵制坏了"------很现实的总结。
八、对比总览
| 维度 | AutoGLM | 豆包手机(autoaction) |
|---|---|---|
| 形态 | 普通 App + 无障碍服务 | 系统级应用矩阵(com.obric.*) |
| 感知通道 | layout XML(GZIP)+ 截图 | 屏幕帧缓冲截图(base64)+ 任务栈事件 |
| 关键权限 | ADB 调试权限(开源版)/ 无障碍服务(原版) | INJECT_EVENTS、READ_FRAME_BUFFER 等系统签名权限 |
| 执行通道 | ADB shell 命令(开源版)/ 无障碍 API(原版) | 反射 InputManager.injectInputEvent 注入事件 |
| 多屏能力 | 仅主屏,操作可见 | VirtualDisplay 后台执行,前台不受影响 |
| 输入法 | ADB Keyboard(广播 + base64) | 预装豆包输入法 |
| 模型调用 | 规划-接地双模块,单接口三元组,1-4 秒/步 | 端侧 aikernel + 云端 uitars,state + inference 双接口 |
| 上行流量 | XML + 截图,较小 | 200-400KB 截图,每 3-5 秒一次 |
| 可靠性策略 | XML 语义 + Interact 补齐 | Activity 检查 + 像素对比 + 历史回看 + 虚拟屏状态机 |
| 离线能力 | 不行,强依赖云端 | 也不行,断网就歇菜 |
| 安全风险 | 无障碍滥用 + 隐私 | 权限过大,已被多家 App 风控 |
| 通用性 | 任意 Android 可用 | 仅限预装 obric 系统的特定 ROM |
九、说几句总结的话
AutoGLM 给行业打了个样:只要你有 ADB 连接 + 一个能看懂屏幕的大模型,就能在任何安卓手机上做出一个"能用"的 GUI Agent。它的"规划-接地"双模块设计让系统可解释性很强,开源后社区很快就复现出了各种玩法。2.0 版本更进一步搬到云手机上(无影 AgentBay),本地设备完全不侵入。工程门槛不高,验证速度快,是 2024 年这波 Agent 热潮里的"快速可达解"。
豆包手机则代表了另一种思路:把 Agent 做到系统层,用系统权限换来更强的操控能力和更好的用户体验(后台执行、不打扰用户)。但代价也很大------必须跟手机厂商深度绑定,必须承受整个 App 生态的安全对抗。
从技术演进的角度看,两者其实不是"谁取代谁"的关系,更像是同一条路上的"前后两站"。感知层从纯截图到 XML + 截图的融合还会继续演进(虽然纯 VLM 路线也在追赶);执行层从 ADB 到无障碍到事件注入再到未来可能出现的标准化 Agent API,方向也很明确;端云分工还在摸索中------AutoGLM 2.0 把执行环境搬到云手机上,豆包做到本地 ROM 里,两条路都有道理。
但最终决定这条赛道能走多远的,可能不是技术本身,而是 AI 厂商、手机厂商和 App 开发者之间能不能谈拢------权限该给多少、数据该怎么管、责任该谁来扛。技术先行,生态跟上,这事才能真正落地。