引言:时序数据洪流时代的选型之困
随着工业物联网(IIoT)、车联网、智慧城市等领域的快速发展,全球数据量正以指数级增长。据 IDC 预测,到 2025 年全球数据总量已突破 175 ZB,其中超过 80% 为时序数据------由传感器、设备、监控系统持续产生的带时间戳的结构化数据。面对如此庞大的时序数据洪流,选择一款合适的时序数据库(Time Series Database, TSDB)已成为企业数字化转型的关键决策。
然而,时序数据库市场百花齐放:InfluxDB、TimescaleDB、Apache IoTDB、QuestDB......面对众多选项,技术决策者往往陷入选型困境。本文将从大数据架构视角出发,重点对比国内外主流时序数据库的技术路线差异,并深入剖析 Apache IoTDB 为何正在成为越来越多企业的首选。
一、时序数据库的核心选型维度
在正式对比之前,我们需要明确评估一款时序数据库的关键指标:
| 维度 | 说明 |
|---|---|
| 写入吞吐 | 能否支撑百万甚至千万级每秒的数据点写入 |
| 查询性能 | 聚合、降采样、最新点查询、范围查询的响应速度 |
| 存储压缩 | 磁盘空间占用与压缩比,直接影响存储成本 |
| 生态集成 | 与大数据组件(Spark、Flink、Kafka 等)的对接能力 |
| 部署灵活性 | 是否支持边缘-云协同、轻量级单机与分布式集群 |
| 运维复杂度 | 集群管理、扩缩容、故障恢复的难度 |
| 查询语言 | SQL 兼容性与学习成本 |
这七个维度构成了时序数据库选型的"坐标系"。接下来,我们将主流产品放入这个坐标系中进行审视。
二、国外主流时序数据库的技术路线分析
2.1 InfluxDB:DevOps 监控领域的标杆
InfluxDB 由美国公司 InfluxData 开发,是目前全球知名度最高的时序数据库之一。它采用自研的 TSM(Time Structured Merge Tree)存储引擎,在 DevOps 监控、指标采集等场景表现出色。
优势:
- 生态完善,Telegraf 采集器 + InfluxDB 存储 + Chronograf 可视化 + Kapacitor 告警组成完整的 TICK 技术栈
- Flux 查询语言功能强大,支持复杂的数据转换
局限:
- Flux 语言学习曲线陡峭,与 SQL 差异较大,团队迁移成本高
- 集群版(InfluxDB Enterprise)需要商业授权,开源版本不支持原生分布式集群
- 面向工业物联网中的海量设备接入和高基数(high cardinality)场景时,性能衰减明显
- 存储压缩比在工业场景中不够理想,长期存储成本较高
2.2 TimescaleDB:SQL 阵营的代表
TimescaleDB 是基于 PostgreSQL 的时序数据库扩展,它的核心思路是"不重新发明轮子,而是在成熟的关系型数据库上增加时序能力"。
优势:
- 完全兼容 PostgreSQL 生态,可使用标准 SQL 查询
- 支持时序数据与关系数据的 JOIN 查询,适合混合分析场景
- Hypertable 自动分区机制降低了运维负担
局限:
- 作为 PostgreSQL 扩展,继承了 PostgreSQL 的架构限制,在海量时序写入场景下吞吐量存在瓶颈
- 分布式能力(Multinode)发展较晚,成熟度有待验证
- 存储引擎并非为纯时序场景深度优化,压缩比不及专用时序数据库
- 在边缘设备上部署时,PostgreSQL 的资源占用较重,不够轻量
2.3 小结
不难发现,InfluxDB 和 TimescaleDB 各有千秋,但它们的共同局限在于:并非为工业物联网场景量身打造。InfluxDB 擅长 IT 监控但高基数场景吃力;TimescaleDB SQL 兼容好但写入吞吐受限。当设备规模从万台跃升至百万台、数据采样频率从秒级提升至毫秒级时,这些产品往往会暴露性能短板。
三、Apache IoTDB:为工业物联网而生的时序数据库
3.1 项目背景
Apache IoTDB 是清华大学软件学院主导研发的时序数据库,2018 年进入 Apache 孵化器,2020 年正式成为 Apache 顶级项目。它从诞生的第一天起就瞄准了工业物联网这一核心场景,在架构设计上充分考虑了海量设备、高频采样、边缘-云协同等工业领域的实际需求。
值得一提的是,IoTDB 的核心研发团队在时序数据管理领域有超过十五年的学术积累,相关研究成果发表在 VLDB、SIGMOD、ICDE 等国际顶级数据库会议上,这是大多数时序数据库产品所不具备的深厚学术根基。
3.2 核心技术优势
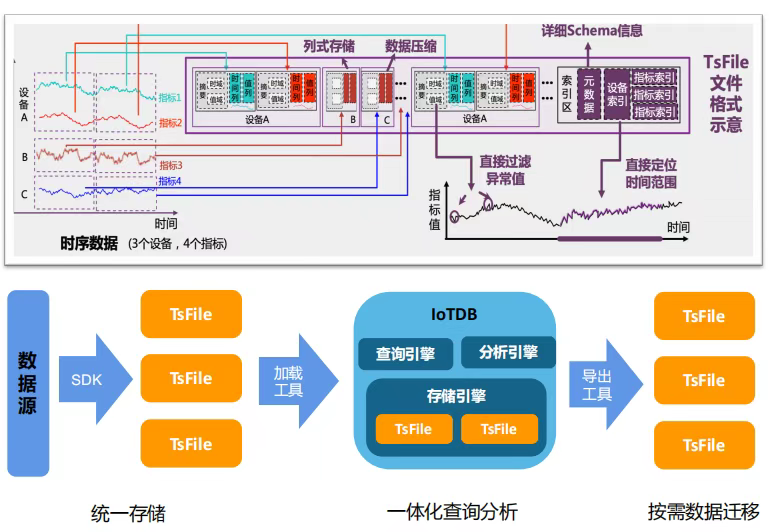
(1)TsFile 自研列式存储格式

IoTDB 采用了自研的 TsFile 列式存储文件格式。与通用存储引擎不同,TsFile 针对时序数据的特征(时间有序、数值密集、数据类型固定)进行了深度优化:
- 高压缩比:通过多种编码算法(RLE、GORILLA、ZIGZAG 等)和二级压缩机制,在工业实测中可达到 10:1 甚至更高的压缩比,显著降低存储成本
- 高效读写:列式存储天然适配聚合查询,只需读取所需列,大幅减少 I/O 开销
- 文件可移植 :TsFile 作为独立文件格式,可以在边缘端生成后直接传输到云端加载,实现真正的"数据即文件"
(2)百万级写入吞吐
在标准基准测试中,IoTDB 单机写入吞吐可达数百万数据点/秒,分布式集群模式下更是可线性扩展至数千万级别。这一性能表现来源于精心设计的写入路径:
- 采用 WAL(预写日志)+ MemTable 的经典写入架构
- 异步刷盘与多级合并策略,平衡写入性能与读放大
- 批量写入接口(InsertRecords)减少网络交互开销

(3)SQL-like 查询语言,低学习成本
IoTDB 提供了 SQL 风格的查询语言,支持:
sql
-- 聚合查询
SELECT avg(temperature), max(humidity)
FROM root.factory.device1
WHERE time >= 2026-01-01T00:00:00
GROUP BY ([0, 1d), 1h);
-- 最新点查询
SELECT last_value(temperature) FROM root.factory.*;
-- 降采样查询
SELECT avg(temperature)
FROM root.factory.device1
ALIGN BY CALENDAR (1h);对于有 SQL 基础的工程师来说,上手成本极低,无需学习全新的查询语言。
(4)边缘-云协同架构
这是 IoTDB 区别于其他时序数据库的核心差异化能力。在工业场景中,数据往往需要在边缘网关、工厂机房、云端数据中心之间流转。IoTDB 提供了一整套边缘-云协同方案:
- 边缘轻量部署:IoTDB 可以在资源受限的边缘设备(如树莓派、工业网关)上运行,最低仅需 100MB 内存
- TsFile 同步:边缘端生成的 TsFile 可以直接同步到云端 IoTDB 集群,无需通过 ETL 转换
- 数据路由与订阅 :支持基于时间范围和设备路径的精准数据同步,避免全量传输
(5)大数据生态无缝集成
作为 Apache 基金会项目,IoTDB 天然与大数据生态深度集成:
- Spark / Flink:IoTDB 提供了 Spark Connector 和 Flink Connector,TsFile 也可以直接作为 Spark 的数据源,实现大规模批处理和流式分析
- Kafka:支持将数据推送到 Kafka Topic,便于构建实时数据管道
- Hadoop / Hive:TsFile 格式可被 Hadoop 生态直接读取
- Grafana:原生支持 Grafana 可视化插件
这种深度集成意味着企业可以在现有大数据平台上无缝引入 IoTDB,而无需重构整个数据架构。
3.3 分布式架构演进
IoTDB 采用了 ConfigNode + DataNode 的分离式架构:
- ConfigNode:负责集群元数据管理,包括数据分区策略、节点拓扑等
- DataNode:负责数据存储与查询执行
这种架构设计支持:
- 水平扩展:增加 DataNode 即可线性提升集群容量
- 高可用:多副本机制保证数据可靠性
- 弹性伸缩:可根据负载动态调整节点数量
四、场景化选型建议
基于以上分析,我们给出不同场景下的选型建议:
场景一:工业物联网 / 制造业
推荐:Apache IoTDB
理由:IoTDB 在海量设备接入、高频数据采集、边缘-云协同等方面具有原生优势。其 TsFile 格式和列式存储针对传感器数据深度优化,压缩比和查询性能均表现优异。
场景二:IT 基础设施监控
推荐:InfluxDB
理由:InfluxDB 在 DevOps 监控场景生态最成熟,TICK 技术栈开箱即用,适合指标采集、告警、可视化等 IT 运维需求。
场景三:业务数据 + 时序数据混合分析
推荐:TimescaleDB
理由:基于 PostgreSQL 的天然优势,适合需要在同一系统中同时处理时序数据和业务关系数据的场景。
场景四:车联网 / 智慧交通
推荐:Apache IoTDB
理由:车联网场景具有设备规模大(百万级车辆)、采样频率高(毫秒级 CAN 总线数据)、边缘端数据预处理需求强等特点,IoTDB 的边缘-云协同和高吞吐写入能力与之高度匹配。
五、总拥有成本(TCO)视角的考量
选型不仅要看技术指标,更要看总拥有成本。从这个角度出发,IoTDB 的优势更加凸显:
- 存储成本:TsFile 的高压缩比可将存储空间需求降低至竞品的 1/5 至 1/10,在海量数据场景下意味着百万级的存储成本节省
- 开源许可:IoTDB 采用 Apache 2.0 开源协议,无商业授权费用,集群功能完全开源
- 运维成本:边缘-云一体的架构减少了数据搬运和 ETL 开发的工作量
- 学习成本:SQL-like 查询语言降低了团队培训成本
对于需要企业级支持、商业版功能(如高可用集群方案、专业运维工具、7×24 技术支持)的用户,IoTDB 的商业化公司**天谋科技(Timecho)**提供了完善的企业版产品和服务,可根据业务需求灵活选择。
六、总结
时序数据库的选型没有"银弹",不同场景需要不同的最优解。但如果你面临的是工业物联网、车联网、智慧能源等场景------设备规模大、采样频率高、需要边缘-云协同、需要与大数据平台深度整合------那么 Apache IoTDB 无疑是目前市场上最值得重点评估的时序数据库之一。
它兼具学术深度的技术积累和 Apache 开源社区的生命力,在高吞吐写入、存储压缩、SQL 易用性、边缘-云协同等关键维度上建立了显著优势。更重要的是,它是一款由中国团队主导的 Apache 顶级项目,在本土化支持、国产化适配、合规性保障等方面具有先天优势,在当前技术自主可控的战略背景下,这一点尤为关键。
相关链接:
- Apache IoTDB 官方下载:https://iotdb.apache.org/zh/Download/
- 天谋科技企业版官网:https://timecho.com