近年来,检索增强生成(RAG)技术在无需重新训练的情况下,成功解决了大语言模型(LLM)面临的诸多难题。通过调用外部知识库,RAG 能够优化大语言模型的输出结果,有效缓解模型幻觉、领域专业知识匮乏以及信息过时等问题。
然而,数据库中不同实体间复杂的关联结构,给传统 RAG 系统带来了严峻挑战。针对这一问题,图检索增强生成(GraphRAG)技术利用实体间的结构信息,实现更精准、全面的检索,捕捉关联知识并生成更准确、贴合上下文的回复。
鉴于 GraphRAG 的创新性与应用潜力,对现有相关技术开展系统性梳理已迫在眉睫。本文首次对 GraphRAG 的方法体系进行了全面综述,规范化定义了 GraphRAG 的工作流程,涵盖基于图的索引构建、图引导检索和图增强生成三个核心阶段,并梳理了各阶段的关键技术与训练方法。
此外,本文还调研了 GraphRAG 的下游任务、应用领域、评估方法及工业落地案例。最后,我们展望了该领域未来的研究方向,以期为后续研究提供思路、推动领域发展。为追踪该领域的最新研究进展,我们创建了代码仓库:https://github.com/pengboci/GraphRAG-Survey。
CCS 概念分类:・计算方法 → 知识表示与推理・信息系统 → 信息检索;数据挖掘
(说明:CCS 是 ACM 计算机分类系统,→ 表示层级从属关系)
补充关键词: 大语言模型、图检索增强生成、知识图谱、图神经网络
1 Introduction
以 GPT-4 127、Qwen2 184、LLaMA 31 为代表的大语言模型的发展,在人工智能领域掀起了一场革命,从根本上改变了自然语言处理的格局。这些模型基于 Transformer 161 架构构建,并在丰富多元的大规模数据集上完成训练,在理解、解析与生成人类语言方面展现出前所未有的能力。这些技术突破的影响极为深远,已广泛渗透到医疗 103, 166, 203、金融 93, 125、教育 46, 169 等众多行业,让人机交互变得更加细腻、高效。
尽管大语言模型具备出色的语言理解与文本生成能力,但由于缺乏领域专属知识、实时更新信息以及预训练语料之外的专有知识,它们仍存在明显局限。这些信息缺口会导致模型出现被称为 **"幻觉"**61 的现象,即生成不准确甚至完全虚构的内容。因此,为大语言模型补充外部知识以缓解这一问题已成为当务之急。
检索增强生成(RAG)作为一项重要技术演进应运而生,它通过在生成流程中引入检索模块,提升生成内容的质量与相关性。RAG 的核心在于能够动态查询大规模文本语料,并将相关事实知识融入基础语言模型的输出回复中。这种融合不仅能丰富回复的上下文深度,还能显著提高事实准确性与针对性。凭借优异的效果与广泛的应用场景,RAG 已受到业界广泛关注,成为该领域的研究重点。
尽管 RAG 已经取得了令人瞩目的成果,并在各个领域得到广泛应用,但它在实际场景中仍面临诸多局限:
- 忽略关联关系:现实中文本内容并非孤立存在,而是相互关联的。传统 RAG 无法捕捉仅靠语义相似度无法表示的重要结构化关系知识。例如,在由引用关系构成的论文引用网络中,传统 RAG 方法仅根据查询检索相关论文,却忽略了论文间关键的引用关联。
- 信息冗余:RAG 通常以文本片段形式拼接成提示词,会导致上下文过长,进而引发 **"中间信息丢失"** 困境 104。
- 缺乏全局信息:RAG 只能检索部分文档,无法全面把握全局
图检索增强生成(GraphRAG) 作为一种创新方案应运而生,用以应对上述挑战。与传统 RAG 不同,GraphRAG 从预先构建的图数据库中检索包含与查询相关的关系知识的图元素,如图 1 所示。这些元素可以是节点、三元组、路径或子图,并被用于生成回复。
GraphRAG 考虑文本之间的相互关联,能够更准确、更全面地检索关系信息。此外,像知识图谱这类图数据可以对文本数据进行抽象与概括,从而显著缩短输入文本长度,缓解内容冗长问题。通过检索子图或图社区,我们能够获取全面信息,捕捉图结构中更广泛的上下文与关联,有效解决聚焦查询式摘要(QFS)的难题。
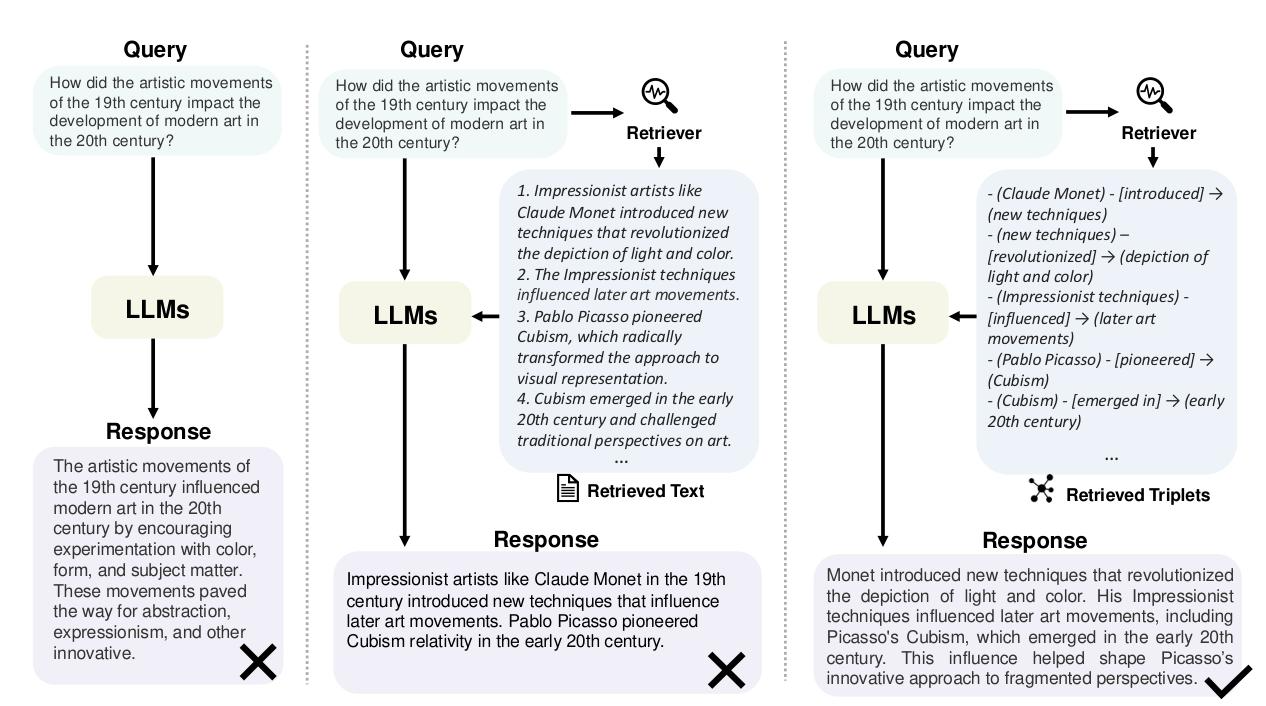
大语言模型可能会出现回答浅显、缺乏针对性的问题。检索增强生成(RAG)通过检索相关文本信息来直接作答,在一定程度上缓解了这一问题。图 1 直接使用大语言模型、RAG 与 GraphRAG 的对比然而,受限于文本长度以及实体关系在自然语言中灵活多变的表达形式,RAG 难以突出作为问题核心的 "影响" 类关系。与之不同,GraphRAG 方法利用图数据中显式的实体与关系表示,通过检索相关结构化信息实现精准作答。
本文首次 对图检索增强生成(GraphRAG)展开系统性综述。具体而言,我们首先介绍 GraphRAG 的工作流程,以及支撑该领域的基础背景知识。随后,我们按照 GraphRAG 流程的核心阶段对相关文献进行分类:在第 5、6、7 节分别阐述基于图的索引(G-Indexing) 、图引导检索(G-Retrieval)和图增强生成(G-Generation),并详细说明每个阶段的核心技术与训练方法。
此外,我们调研了 GraphRAG 的下游任务、应用领域、评估方法以及工业落地案例。这部分梳理阐明了 GraphRAG 在实际场景中的应用方式,并体现了其在各行业中的通用性与适应性。最后,鉴于 GraphRAG 研究仍处于起步阶段,我们深入探讨了潜在的未来研究方向。这一前瞻性论述旨在为后续研究铺路、启发新的研究思路、推动领域发展,最终助力 GraphRAG 走向更成熟、更具创新性的发展阶段。
我们的贡献可总结如下:
- 我们对现有最先进的 GraphRAG 方法 进行了全面、系统的综述 。我们给出了 GraphRAG 的形式化定义 ,并梳理了其通用工作流程 ,包括图索引(G-Indexing)、图引导检索(G-Retrieval)和图增强生成(G-Generation)。
- 我们论述了支撑现有 GraphRAG 系统的核心技术 ,涵盖图索引、图引导检索与图增强生成三大模块。针对每个模块,我们分析了当前主流的模型选型、方法设计与增强策略 ,并对比了这些模块所采用的多样化训练方法。
- 我们清晰梳理了与 GraphRAG 相关的下游任务、基准数据集、应用领域、评估指标、当前挑战与未来研究方向,并对领域进展与前景进行了全面论述。
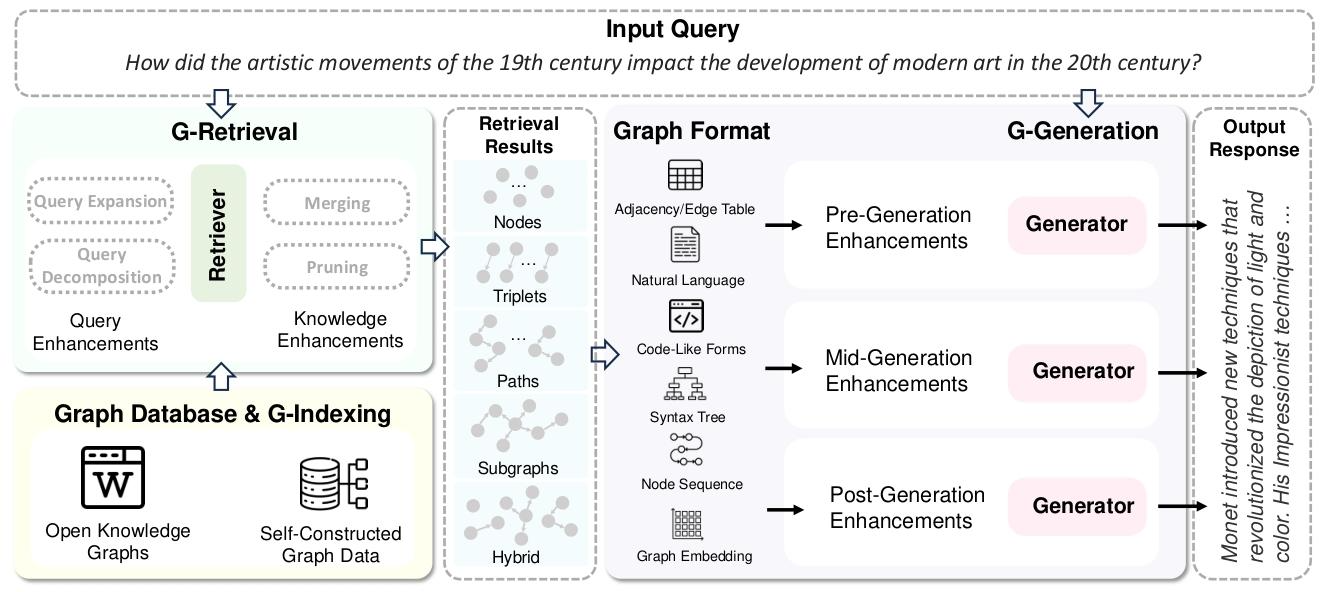
图 2 面向问答任务的 GraphRAG 框架总览在本综述中,我们将 GraphRAG 划分为三个阶段:基于图的索引(G-Indexing)、图引导检索(G-Retrieval)与图增强生成(G-Generation)。我们将检索来源分为开源知识图谱与自建图数据。系统可采用查询增强、知识增强等多种增强技术,以提升检索结果的相关性。与直接使用检索文本进行生成的 RAG 不同,GraphRAG 需要将检索到的图信息转换为生成器可接受的格式,从而提升任务性能。
章节组织。本综述其余部分的结构安排如下:第 2 章对比相关技术,第 3 章概述 GraphRAG 的通用流程。第 5--7 章分别对 GraphRAG 三大阶段(基于图的索引、图引导检索、图增强生成)的相关技术进行分类梳理。第 8 章介绍检索器与生成器的训练策略。第 9 章总结 GraphRAG 的下游任务、对应基准数据集、应用领域、评估指标及工业级 GraphRAG 系统。第 10 章展望未来研究方向。最后,第 11 章对本综述进行总结。
2 Comparison with Related Techniques and Surveys
在本节中,我们将 图检索增强生成(GraphRAG)与相关技术及对应综述进行对比,包括检索增强生成(RAG)、图上大语言模型(LLMs on graphs)以及知识库问答(KBQA)。
2.1 RAG
检索增强生成(RAG)将外部知识与大语言模型相结合以提升任务表现,通过融合领域专属信息确保内容的事实准确性与可信度。过去两年间,研究者已发表多篇 RAG 综合性综述 34, 45, 59, 62, 178, 195, 202。例如,Fan 等人 34 与 Gao 等人 45 从检索、生成及增强三方面对 RAG 方法进行分类;Zhao 等人 202 综述了面向不同模态数据库的 RAG 方法;Yu 等人 195 系统梳理了 RAG 方法的评估体系。这些工作为现有 RAG 方法提供了结构化的综合梳理,有助于深化对该领域的理解,并指出了该领域的未来发展方向。
从广义视角来看,图检索增强生成(GraphRAG)可被视为检索增强生成(RAG)的一个分支,其从图数据库中检索相关的关系型知识,而非从文本语料库中获取。然而,与基于文本的传统 RAG 相比,GraphRAG 额外考虑了文本之间的关联关系,并将结构信息作为文本之外的补充知识融入模型。此外,在图数据构建过程中,原始文本数据通常会经过筛选与摘要提炼,从而提升图数据内部信息的精细度与凝练度。尽管此前关于 RAG 的综述已对 GraphRAG 有所涉及,但这些工作大多仍以文本数据融合为核心。本文与之不同,重点聚焦于结构化图数据的索引构建、检索过程与知识利用,这与纯粹处理文本信息存在本质区别,并催生了大量全新的技术方法。
2.2 LLMs on Graphs
大语言模型(LLMs)凭借其出色的文本理解、推理与生成能力,以及良好的泛化性和零样本迁移能力,正在彻底改变自然语言处理领域。尽管大语言模型最初专为纯文本处理设计,难以直接处理包含复杂结构信息的非欧几里得数据(如图数据)49,165,但相关领域已涌现大量研究工作 17,35,74,92,102,116,130,131,173,204。这些工作主要将大语言模型与图神经网络(GNNs)相结合,以提升对图数据的建模能力,进而在节点分类、边预测、图分类等下游任务上取得性能提升。例如,Zhu 等人 204 提出了一种名为 ENGINE 的高效微调方法,通过侧结构将大语言模型与图神经网络融合,用以增强图表示学习效果。
与这些方法不同,GraphRAG 侧重于通过查询从外部图结构数据库中检索相关的图元素。本文对 GraphRAG 的相关技术与应用进行了详细介绍,而这些内容在以往关于 图上大语言模型(LLMs on Graphs)的综述中并未涉及。
2.3 KBQA
知识库问答(KBQA)是自然语言处理领域的一项重要任务,旨在基于外部知识库回答用户的问题 41, 85, 86, 188,进而实现事实校验、文本检索增强与文本理解等目标。现有综述通常将知识库问答方法分为两大类:基于信息检索(IR)的方法与基于语义解析(SP)的方法。
具体而言,基于信息检索的方法 69, 70, 112, 113, 154, 167, 182, 196 从知识图谱(KG)中检索与查询相关的信息,并用于增强生成过程;而基于语义解析的方法 16, 19, 36, 48, 153, 191 则为每个查询生成逻辑表达式(LF),并在知识库上执行该表达式以获取答案。
3 Preliminaries预备知识
在本节中,我们介绍GraphRAG 的背景知识 ,以便读者更轻松地理解本综述内容。首先,我们介绍文本属性图(Text-Attributed Graphs) ,这是 GraphRAG 中普遍使用的通用图数据格式。随后,我们给出可用于检索与生成阶段的两类模型的正式定义:图神经网络(Graph Neural Networks)与语言模型(Language Models)。
3.1 Text-Attributed Graphs
GraphRAG 中使用的图数据可以统一表示为文本属性图(Text-Attributed Graphs, TAGs),其中节点和边都具有文本属性。形式化地,文本属性图可记为:G=(V,E,A,{xv}v∈V,{ei,j}i,j∈E)
其中:
- V 是节点集合
- E⊆V×V 是边集合
- A∈{0,1}∣V∣×∣V∣ 是邻接矩阵
此外,{xv}v∈V 和 {ei,j}i,j∈E 分别为节点和边的文本属性。文本属性图(TAGs)的一类典型实例是知识图谱(Knowledge Graphs, KGs):其中节点对应实体,边对应实体间的关系,而文本属性则是实体与关系的名称。
3.2 Graph Neural Networks
图神经网络(GNNs)是一类用于对图数据进行建模的深度学习框架。经典的图神经网络(如 GCN 83、GAT 162、GraphSAGE 52)采用消息传递机制来学习节点表示。
形式化表示为:第 l 层中每个节点的表示 hi(l−1) 通过聚合其邻居节点与边的信息进行更新:hi(l)=UPD(hi(l−1),AGGj∈N(i)MSG(hi(l−1),hj(l−1),ei,j(l−1)))(1)
其中:
- N(i) 表示节点 i 的邻居集合;
- MSG 为消息函数,基于当前节点、邻居节点及其连边计算消息;
- AGG 为聚合函数,采用置换不变方式(如均值、求和、最大值)合并接收的消息;
- UPD 为更新函数,利用聚合后的消息更新节点属性
随后,可通过读出函数(readout function) (如均值池化、求和池化或最大值池化)得到全局级表示:hG=READOUTi∈VG(hi(L))(2)
在 GraphRAG 中,图神经网络(GNNs)可用于为检索阶段学习图数据表示,同时也能对检索到的图结构进行建模。
3.3 Language Models
语言模型(LMs)在语言理解方面表现出色,主要分为判别式模型 与生成式模型两类。判别式模型(如 BERT 28、RoBERTa 107 和 SentenceBERT 140)专注于估计条件概率 P(y∣x),在文本分类、情感分析等任务中效果显著。与之相对,生成式模型(包括 GPT-3 14 和 GPT-4 127)旨在建模联合概率 P(x,y),适用于机器翻译、文本生成等任务。这些生成式预训练模型借助海量数据与数十亿参数,极大推动了自然语言处理(NLP)领域的发展,催生了在各类任务上表现卓越的大语言模型(LLMs)。
在早期阶段,RAG 与 GraphRAG 主要致力于改进判别式语言模型 的预训练技术 28, 107, 140。近年来,以 ChatGPT 128、LLaMA 31 和 Qwen2 184 为代表的大语言模型在语言理解领域展现出巨大潜力,并具备强大的上下文学习能力 。此后,RAG 与 GraphRAG 的研究重心转向增强语言模型的信息检索能力,以应对更复杂的任务并缓解幻觉问题,进而推动该领域的快速发展。
4 Overview of GraphRAG
如图 2 所示,GraphRAG是一种利用外部结构化知识图谱增强语言模型上下文理解能力、并生成更具依据的回复的框架。GraphRAG 的目标是从数据库中检索最相关的知识,从而提升下游任务的回答质量。其过程可形式化定义为:a∗=a∈Aargmax p(a∣q,G)(3)其中,a∗ 表示在给定文本属性图 G 的条件下,查询 q 对应的最优答案,A 为候选答案集合。
随后,我们使用图检索器 pθ(G∣q,G) 与答案生成器 pϕ(a∣q,G) 联合建模目标分布 p(a∣q,G)(θ、ϕ 为可学习参数),并利用全概率公式对 p(a∣q,G) 进行分解,公式如下:p(a∣q,G)=G⊆G∑pϕ(a∣q,G)pθ(G∣q,G)≈pϕ(a∣q,G∗)pθ(G∗∣q,G)(4)其中,G∗ 为最优子图。由于候选子图数量会随图谱规模呈指数级增长,因此需要高效的近似方法。公式 (4) 第一行由此被近似为第二行。具体而言,系统先通过图检索器抽取最优子图 G∗,再由生成器基于检索到的子图生成最终答案。
因此,在本综述中,我们将 GraphRAG 的整个流程划分为三个核心阶段:基于图的索引(G-Indexing) 、图引导检索(G-Retrieval)和图增强生成(G-Generation)。GraphRAG 的整体流程如图 2 所示,下面对每个阶段进行详细介绍。
基于图的索引(G-Indexing)。基于图的索引是 GraphRAG 的初始阶段,旨在确定或构建与下游任务相匹配的图数据库 G 并对其建立索引。该图数据库可来源于公开知识图谱 4,10,100,142,150,163、现有图数据 123,也可基于文本等私有数据源 32,51,89,172 或其他形式的数据 183 进行构建。索引过程通常包括节点与边属性映射、关联节点间指针建立,以及数据组织以支持快速遍历与检索操作。索引方式决定了后续检索阶段的粒度,对提升查询效率起到关键作用。
图引导检索(G-Retrieval)。在完成基于图的索引之后,图引导检索阶段的核心是根据用户查询或输入,从图数据库中提取相关信息。具体而言,给定以自然语言表示的用户查询 q,检索阶段旨在从知识图谱中抽取最相关的元素(如实体、三元组、路径、子图),可形式化表示为:G∗=G-Retriever(q,G)=G⊆R(G)argmax pθ(G∣q,G)=G⊆R(G)argmax Sim(q,G),其中 G∗ 为检索得到的最优图元素,Sim(⋅,⋅) 用于衡量用户查询与图数据之间的语义相似度。R(⋅) 是为提升效率而对子图搜索范围进行约束的函数。
图增强生成(G-Generation)。图增强生成阶段的任务是基于检索到的图数据,合成有意义的输出或回复,包括回答用户查询、生成报告等。在该阶段,生成器以查询、检索到的图元素以及可选提示词为输入,生成最终回复,可形式化表示为:a∗=G-Generator(q,G∗)=a∈Aargmax pϕ(a∣q,G∗)=a∈Aargmax pϕ(a∣F(q,G∗)),其中,F(⋅,⋅) 是将图数据转换为生成器可处理格式的转换函数。
5 Graph-Based Indexing
图数据库的构建与索引是 GraphRAG 的基础,图数据库的质量直接决定 GraphRAG 的性能。在本节中,我们对图数据的选取、构建方法以及所采用的各类索引方式进行分类与总结。
5.1 Graph Data
GraphRAG 中使用多种类型的图数据来完成检索与生成任务。在本文中,我们根据数据来源 将其分为两类:开放知识图谱 与自建图数据。
5.1.1 开放知识图谱
开放知识图谱指来自公开知识库或数据库的图数据 4,10,150,163。使用这类知识图谱可大幅降低开发与维护所需的时间和资源。在本综述中,我们根据覆盖范围进一步将其分为两类:通用知识图谱 与领域知识图谱。
(1) 通用知识图谱。通用知识图谱主要存储通用的结构化知识,通常依靠全球社区的集体贡献与更新,以此保证知识库内容全面且持续更新。
百科知识图谱是一类典型的通用知识图谱,包含由人类专家和百科全书整理的大规模真实世界知识。例如:
- Wikidata163 是一个免费开放的知识库,存储维基百科、维基旅行、维基词典等维基媒体姊妹项目的结构化数据。
- Freebase10 是一个大规模的协同编辑知识库,整合了来自个人贡献以及维基百科等数据库的结构化数据。
- DBpedia4 利用维基百科条目中的信息框与分类体系,描述数百万级实体(人物、地点、事物等)信息。
- YAGO150 从维基百科、WordNet 与 GeoNames 中整合知识。
常识知识图谱是另一类通用知识图谱。这类图谱包含抽象的常识知识,例如概念之间的语义关联以及事件之间的因果关系。典型的常识知识图谱包括:
- ConceptNet100 是一种语义网络,其节点表示词语或短语,边表示语义关系。
- ATOMIC64, 142 用于建模事件之间的因果关系。
(2) 领域知识图谱如第 1 节所述,领域专用知识图谱对于提升大语言模型处理领域特定问题的能力至关重要。这些知识图谱提供特定领域的专业知识,帮助模型获得更深入的理解,并更全面地把握复杂的专业关系。
在生物医学领域,CMeKG 包含疾病、症状、治疗方案、药物以及各类医学概念间的关系等丰富数据。CPubMed-KG 是一个中文医学知识库,基于 PubMed 中海量的生物医学文献构建而成。
在电影领域,Wiki-Movies 从维基百科的电影相关文章中抽取结构化信息,将电影、演员、导演、类型及其他相关信息整理为结构化数据。
此外,Jin 等人构建了名为 GR-Bench 的数据集,包含学术、电商、文学、医疗、法律 五个领域的知识图谱。He 等人将 ExplaGraphs 和 SceneGraphs 中的三元组格式与 JSON 文件转换为标准图格式,并从 WebQSP 中选取需要两跳推理的问题,构建了通用图格式数据集 GraphQA,用于评估 GraphRAG 系统。
5.1.2 自主构建图数据
自主构建图数据能够将私有知识或领域专属知识 定制化地融入检索过程。对于本身不涉及图数据的下游任务,研究者通常会提出从多源数据(如文档、表格及其他数据库)中构建图结构,并利用GraphRAG提升任务性能。总体而言,这类自主构建的图与具体方法的设计紧密相关,从而区别于上述提到的开放领域图数据。
为建模文档之间的结构关系,Munikoti 等人 124 提出构建异质文档图 ,用以刻画多种文档层级关联,包括共引、共同主题、同一发表会议等关系。Li 等人 96 与 Wang 等人 172 则依据共享关键词建立段落之间的关联。
为挖掘文档内的实体关系,Delile 等人 26、Edge 等人 32、Gutiérrez 等人 51 以及 Li 等人 89 结合命名实体识别工具从文本中抽取实体,并借助语言模型进一步挖掘实体间关系,最终利用检索得到的实体与关系构建知识图谱。
此外,部分下游任务需要结合自身特性设计专属映射构建方法。例如,针对专利短语相似度推理任务,Peng 与 Yang 133 将专利数据库转化为专利 - 短语图:若短语出现在对应专利中,则建立专利节点与短语节点的连接;专利节点之间则依靠引用关系完成关联。
面向客服技术支持场景,Xu 等人 183 将历史问题数据建模为知识图谱:先把单个问题转化为树形结构以保留问题内部语义关联,再通过语义相似度结合阈值筛选规则,建立不同问题之间的关联关系。
5.2 Indexing
基于图的索引 对于提升图数据库查询操作的效率与速度至关重要,直接影响后续检索方法与检索粒度。常见的图索引方案主要分为:图结构索引 、文本索引 与向量索引三类。
5.2.1 图结构索引
图索引是最常用的索引方式,该方法完整保留图谱的整体结构,能够快速获取任意节点的全部边与邻接节点。在后续检索阶段,可结合广度优先搜索、最短路径算法等经典图搜索算法完成检索任务 73,75,112,113,154,158,189。

Fig. 3. The overview of graph-based indexing.
5.2.2 文本索引
文本索引是将图数据转化为文本描述以优化检索流程。这类文本描述会被存储至语料库中,进而可采用稀疏检索、稠密检索等各类文本检索技术。
部分研究通过预定义规则或模板,将知识图谱转换为易读的自然语言文本。例如,Li 等人 90、Huang 等人 63 与 Li 等人 95 利用预设模板,把知识图谱中的每条三元组改写为自然语言;Yu 等人 193 则将同一头实体对应的多条三元组合并为完整段落。
除此之外,还有方法对子图级别的信息进行文本化转换。例如,Edge 等人 32 先对图执行社区检测,再借助大语言模型为每个社区生成文本摘要。
5.2.3 向量索引
向量索引将图数据转化为向量表示,以此提升检索效率,实现快速检索与高效查询处理。例如,可结合查询嵌入无缝完成实体链接,并使用局部敏感哈希(LSH)66 等高效向量检索算法。G-Retriever 55 利用语言模型对图中节点与边的关联文本信息进行编码;GRAG 58 则通过语言模型将 k 阶中心网络转化为图嵌入,从而更好地保留结构特征。
5.2.4 混合索引
上述三种索引方式各具优势:图索引便于快速获取结构信息,文本索引能够简化文本内容检索,向量索引则可实现高效快速搜索。因此,在实际应用中,通常不再单独使用单一索引方案,而是采用多种索引相结合的混合索引策略。例如,HybridRAG 144 同时检索向量数据与图数据,以丰富检索内容;EWEK-QA 24 则融合了文本与知识图谱两种索引方式。
6 Graph-Guided Retrieval
在 GraphRAG 中,检索环节需要从外部图数据库中抽取精准、优质的图数据,是保障生成结果质量与内容相关性的关键。然而,图数据检索主要面临两大难题:(1)候选子图规模爆炸 :随着图谱规模扩大,候选子图数量呈指数级增长,亟需启发式搜索算法实现相关子图的高效筛选与检索。(2)相似度度量不足:若要精准衡量文本查询与图数据之间的匹配程度,就需要设计能够同时理解文本语义与图结构信息的算法。
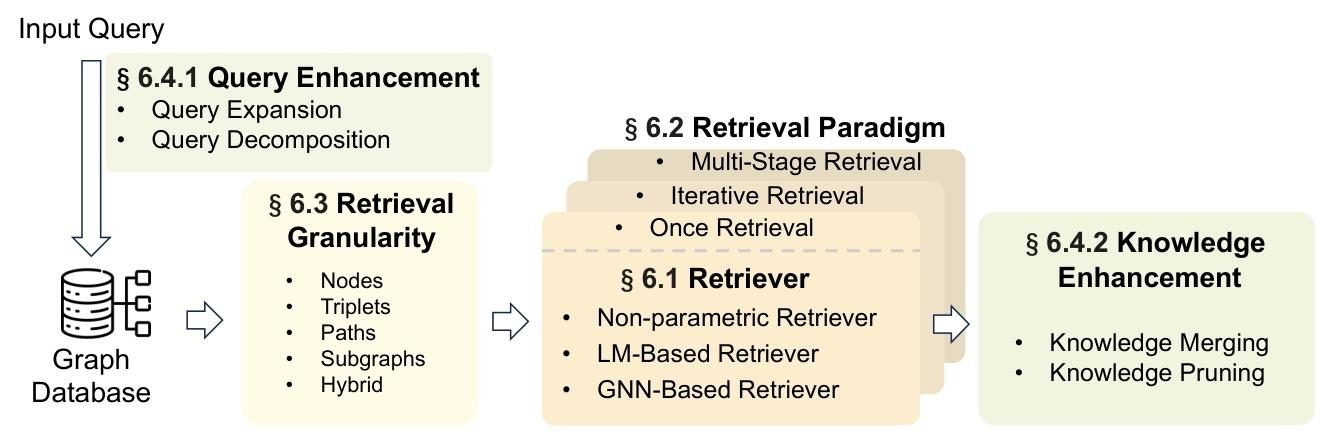
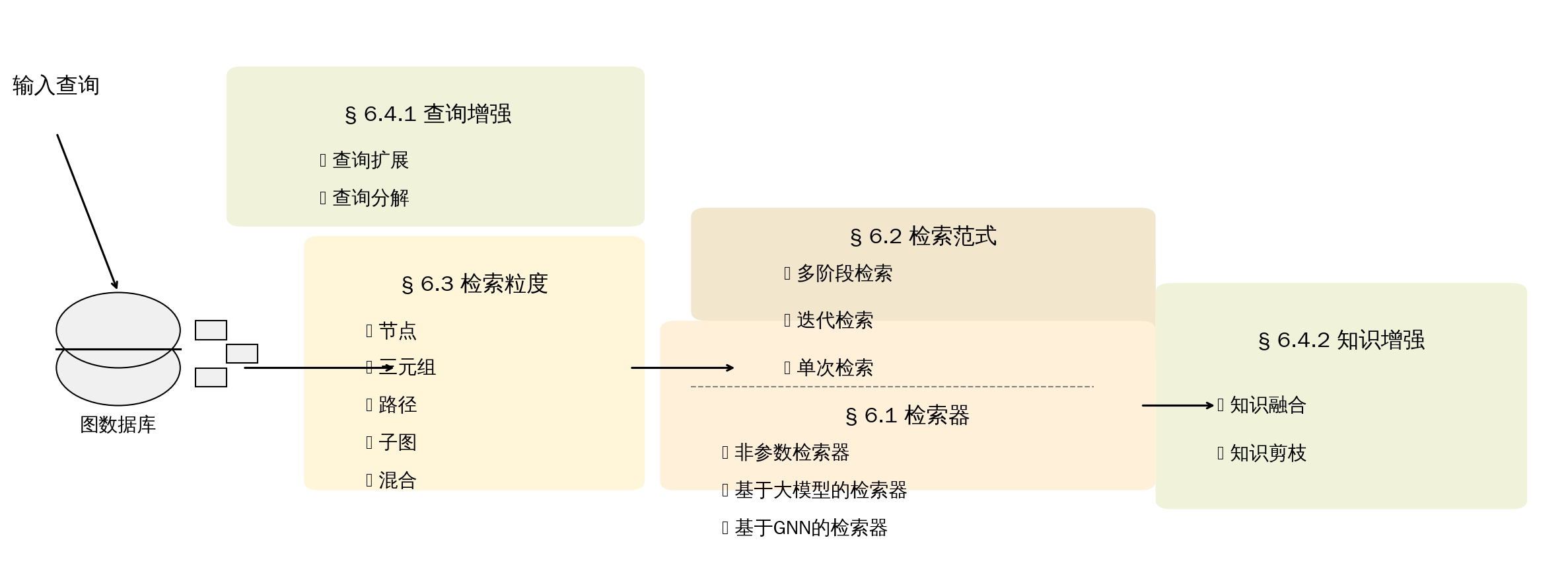
Fig. 4. The general architectures of graph-based retrieval.
为解决上述难题,现有研究已投入大量工作优化检索流程。本文综述围绕 GraphRAG 检索环节的多个维度展开分析,包括检索器选型、检索范式、检索粒度以及各类高效增强方法。图 4 展示了图引导检索的通用架构。
6.1 Retriever
在 GraphRAG 中,各类检索器在处理检索任务的不同环节时各有优势。本文依据底层模型的不同,将检索器划分为三类:非参数检索器 、基于大语言模型的检索器 与基于图神经网络的检索器。需要说明的是,查询编码、实体链接等预处理阶段所使用的模型不在此分类范围内,此类模型因方法而异,并非本文的核心研究对象。
6.1.1 非参数检索器
非参数检索器依托启发式规则或传统图搜索算法实现,不依赖深度学习模型,检索效率较高。例如,Yasunaga 等人 189 与 Taunk 等人 158 会检索包含每个问题 - 选项对主题实体的 k 跳路径。G-Retriever 55 对经典的 ** 奖赏收集斯坦纳树(PCST)** 算法进行改进,引入边权重代价,优化相关子图的抽取效果。Delile 等人 26 以及 Mavromatis 和 Karypis 119 先提取查询文本中提及的实体,再检索与这些实体相关的最短路径。上述方法通常需要先开展实体链接预处理,完成图谱节点匹配后,再执行检索操作。
6.1.2 基于语言模型的检索器
语言模型凭借强大的自然语言理解能力,可作为 GraphRAG 中高效的检索工具。该类模型擅长处理与解析各类自然语言查询,能够灵活适配图框架下的多种检索任务。本文将语言模型主要分为两类:判别式语言模型 与生成式语言模型。
子图检索器(Subgraph Retriever)196 以 RoBERTa 107 作为检索模型,从主题实体出发,通过序列决策过程逐步扩展并检索相关路径。KG-GPT 80 依托大语言模型,生成指定实体的 Top-K 关键关联关系集合。Wold 等人 176 采用微调后的 GPT-2 生成推理路径。StructGPT 67 借助大语言模型自动调用多项预定义工具函数,以此检索并整合关联信息,辅助后续推理。
6.1.3 基于图神经网络的检索器
图神经网络(GNN)擅长理解并利用复杂的图结构信息。基于图神经网络的检索器通常先对图数据进行编码,再依据不同检索粒度与查询文本的相似度完成打分排序。
例如,GNN-RAG 119 首先对图谱进行编码,为每个实体分配相关性得分,并通过设定阈值筛选出与查询相关的实体。EtD 99 采用多轮迭代方式检索关联路径:每一轮迭代中,先通过 LLaMA2 160 筛选当前节点的连通边,再利用图神经网络生成下一阶节点的嵌入表示,供大模型开展下一轮筛选。
6.1.4 小结与讨论
在检索过程中,非参数检索器具备较高的检索效率,但由于未结合下游任务进行训练,容易出现检索精准度不足的问题。与此同时,基于语言模型与图神经网络的检索器虽然检索精度更高,却会产生巨大的计算开销。依托三者的互补特性,现有大量研究提出混合检索方案,以兼顾检索效率与检索准确率。多数方法采用多阶段检索策略,在不同阶段搭配不同模型完成检索。例如,RoG 112 先通过大语言模型生成规划推理路径,再从知识图谱中抽取符合该规划的实际路径;GenTKGQA 44 利用大语言模型从查询语句中推理出核心关系与约束条件,并依据约束规则抽取对应三元组。
6.2 Retrieval Paradigm检索范式
在 GraphRAG 中,不同的检索范式 ------ 包括单次检索、迭代检索与多阶段检索 ------ 对提升检索信息的相关性与深度起着关键作用。
- 单次检索:旨在通过一次操作获取所有相关信息。
- 迭代检索 :基于上一轮检索到的信息进行进一步搜索,逐步聚焦于最相关的结果。本文将迭代检索进一步划分为自适应检索 与非自适应检索,二者的唯一区别在于检索的停止条件是否由模型决定。
- 多阶段检索:将检索过程划分为多个阶段,每个阶段可采用不同类型的检索器,以获得更精准、更多元的搜索结果。
6.2.1 单次检索
单次检索的目标是通过一次查询操作获取全部相关信息。
其中一类方法 51, 58, 90 利用嵌入相似度来检索最相关的信息片段。另一类方法则通过预定义规则或模式,直接从图数据库中抽取三元组、路径或子图等特定结构化信息。
例如:
- G-Retriever 55 使用扩展的 PCST(奖赏收集斯坦纳树)算法来检索最相关的子图;
- KagNet 97 抽取所有主题实体对之间长度不超过 k 的路径;
- Yasunaga 等人 189 与 Taunk 等人 158 抽取包含所有主题实体及其 2 跳邻接节点的子图。
此外,本小节还包含若干多路检索方法。这类方法采用解耦式、独立化的检索设计,可并行运算且整体仅执行一次检索。例如,Luo 等人 112 与 Cheng 等人 20 首先利用大语言模型生成多条推理路径,再通过 BFS 检索器,在知识图谱中依次检索与每条路径相匹配的子图。KG-GPT 80 将原始查询拆解为多个子查询,并对每个子查询一次性完成相关信息的检索。
6.2.2 迭代检索
迭代检索需要执行多轮检索步骤,后续检索依赖前一轮的检索结果。该类方法通过不断迭代,加深对信息的理解,补足检索内容,提升信息完整度。本文将迭代检索进一步划分为两类:(1)非自适应检索、(2)自适应检索。下文将对这两类方法展开详细综述。
(1)非自适应检索非自适应检索方法通常遵循固定的检索流程,通过设定最大迭代次数或阈值来终止检索。例如,PullNet 151 通过固定 T 轮迭代检索与问题相关的子图。每一轮迭代中,该方法依据自定义检索规则筛选部分已检索实体,并在知识图谱中遍历关联边,完成实体范围扩展。KGP 172 在每轮迭代中,首先根据上下文与图谱节点的相似度筛选种子节点;再利用大语言模型对种子节点的邻接节点上下文进行摘要与更新,为下一轮迭代提供支撑。
(2)自适应检索自适应检索的显著特征是由模型自主判断并决定检索的最优终止时机。例如,文献 50,182 利用语言模型进行跳数预测,以此作为检索结束的判断依据。还有部分研究将模型生成的特殊标记或文本作为检索终止信号。如 ToG 113,154 引导大模型智能体探索多条可行推理路径,直至模型判定依托现有推理路径足以回答问题,随即停止检索。文献 196 训练 RoBERTa 模型,从各个主题实体出发延伸推理路径;该方法引入名为「结束」的虚拟关系,用于终止检索流程。
另一种常用方案是将大模型作为智能体,使其可直接生成问题答案,以此作为迭代终止的标志。例如,文献 67, 69, 75, 155, 170 提出基于大语言模型的智能体,在图谱上开展推理。该类智能体能够自主判定需要检索的信息、调用预定义检索工具,并依据已获取的检索信息,主动终止检索流程。
6.2.3 多阶段检索
多阶段检索将检索过程线性划分为多个阶段,阶段之间会穿插检索增强、乃至生成等额外处理步骤。在多阶段检索框架中,不同阶段可搭配不同类型的检索器,使系统能够结合多种检索技术,适配查询的不同特征与需求。
例如,Wang 等人 171 首先采用非参数检索器,抽取查询推理链中实体的 n 跳路径;经过剪枝处理后,再对剪枝子图内的实体,进一步检索其一跳邻接节点。OpenCSR 53 将检索分为两个阶段:第一阶段,检索主题实体的所有一跳邻居;第二阶段,计算这些邻居节点与其他节点的相似度,筛选相似度最高的前 k 个节点开展二次检索。GNN-RAG 119 先通过图神经网络筛选出最可能为答案的前 k 个节点,再逐一检索查询实体与候选答案实体之间的全部最短路径。
6.2.4 小结与讨论
在 GraphRAG 中,单次检索通常复杂度更低、响应速度更快,适用于对实时性有要求的应用场景。反观迭代检索,其时间复杂度普遍更高,尤其在采用大语言模型作为检索器时,处理耗时会显著增加。但该方式能够通过多轮迭代不断优化检索信息、迭代生成结果,进而获得更高的检索准确率。因此,实际选用检索范式时,需结合具体应用场景与业务需求,在准确率与时间复杂度之间进行权衡。
6.3 Retrieval Granularity
结合不同任务场景与索引类型,研究人员设计了多种检索粒度(即从图数据中抽取关联知识的呈现形式),主要分为:节点、三元组、路径、子图。每种检索粒度各具优势,分别适配不同实际应用场景。下文将逐一详细介绍各类检索粒度。
6.3.1 节点
以节点为检索粒度,可针对图中的独立单元实现精准检索,十分适用于定向查询与特定信息抽取任务。在知识图谱中,节点通常指代实体;而在其他文本属性图中,节点还可包含用于描述自身属性的文本信息。通过检索图内节点,GraphRAG 系统能够充分挖掘节点的属性、关联关系及上下文信息,进而输出详细推理依据。
例如,Munikoti 等人 124、Li 等人 96 与 Wang 等人 172 构建文档图,并检索其中相关的段落节点;Liu 等人 99、Sun 等人 151 和 Gutiérrez 等人 51 则从构建完成的知识图谱中完成实体检索。
6.3.2 三元组
一般而言,三元组以主语 - 谓语 - 宾语的元组形式,由实体及其相互关系构成,为图中的关系数据提供结构化表达。三元组的结构化形式能够实现清晰、规整的数据检索,在需要重点理解实体间关系与上下文关联的场景中具备显著优势。
Yang 等人 185 将包含主题实体的三元组作为关联信息进行检索。Huang 等人 63、Li 等人 90 以及 Li 等人 95 先通过预定义模板,将图数据中的所有三元组转换为文本语句,再借助文本检索器筛选出相关三元组。
但直接从图数据中检索三元组,往往存在上下文广度与深度不足的问题,难以捕捉间接关系与推理链路。针对该问题,Wang 等人 164 提出依据原始问题生成逻辑链,并分别检索每条逻辑链对应的相关三元组。
6.3.3 路径
路径粒度的数据检索可理解为捕捉实体之间的关系序列,能够增强上下文理解与逻辑推理能力。在 GraphRAG 中,路径检索具备独特优势,可有效挖掘图结构内的复杂关联与上下文依赖关系。
然而,随着图谱规模扩大,可行路径数量会呈指数级增长,导致计算复杂度急剧上升,因此路径检索往往存在较大挑战。为解决这一问题,部分方法依托预定义规则检索相关路径。例如,Wang 等人 171 与 Lo、Lim 108 会先筛选查询中的实体对,再遍历查找二者之间所有n 跳以内的连通路径。HyKGE 73 将路径划分为三类:普通路径、共同祖先链与共现链,并采用对应规则分别完成三类路径的检索。
除此之外,还有部分方法借助模型在图谱中开展路径搜索。ToG 113,154 通过提示大语言模型智能体,在知识图谱上执行束搜索,挖掘多条可辅助答题的推理路径。Luo 等人 112、Wu 等人 182 及 Guo 等人 50 先利用模型生成可靠的推理方案,再依据方案检索匹配的相关路径。GNN-RAG 119 首先识别问题中提及的实体,随后抽取实体之间所有满足指定长度约束的关联路径。
6.3.4 子图
子图检索的核心优势在于能够完整捕获图谱内的全局关联上下文。该检索粒度可让 GraphRAG 抽取并解析复杂大图结构中隐藏的关联模式、逻辑序列与依赖关系,助力深度挖掘信息,实现对语义关联更细致、全面的理解。
为兼顾信息完整性与检索效率,部分研究采用规则化初筛 策略先获取候选子图,再对其进行精细化筛选与后续处理。Peng 与 Yang 133 在自建的专利 - 短语图谱中,检索专利短语的中心子图 。Yasunaga 等人 189、Feng 等人 40 以及 Taunk 等人......158 首先筛选出主题实体及其两跳邻居作为节点集合,再选取首尾实体均位于该节点集合内的边,以此构成子图。此外,还有一类基于嵌入表示的子图检索方法。例如,Hu 等人 58 先对图数据库中所有的 k 跳自我中心网络进行编码,再凭借嵌入向量之间的相似度,检索与查询相关的子图。Wen 等人 175 与 Li 等人 89 依据预定义规则,抽取两类证据子图:路径证据子图与邻居证据子图。OpenCSR 53 从少量初始种子节点出发,逐步向外扩展新增节点,最终生成完整子图。
除上述直接子图检索方法外,还有部分研究提出:先检索相关路径,再基于路径构建对应子图。例如,Zhang 等人 196 训练 RoBERTa 模型,通过序列决策过程挖掘多条推理路径,随后合并不同路径中的重复实体,最终整合生成目标子图。
6.3.5 混合检索粒度
综合上述各类检索粒度的优缺点,部分研究者提出采用混合检索粒度,即从图数据中同时获取多种粒度的关联信息。该粒度方案可增强系统能力,既能精准捕捉细粒度实体关系,又能兼顾大范围上下文理解,从而减少冗余噪声,提升检索内容的相关性。
现有多项研究利用大语言模型智能体实现复杂混合信息检索。Jin 等人 75、Jiang 等人 67、Jiang 等人 69、Wang 等人 170 与 Sun 等人 155 提出,依托大模型智能体,自适应灵活选取节点、三元组、路径、子图等多种粒度开展检索。
6.3.6 小结与讨论
(1) 在实际应用中,各类检索粒度之间并无明确界限:子图可由多条路径构成,而路径又可由若干三元组组合形成。(2) 节点、三元组、路径、子图等不同粒度,在 GraphRAG 流程中各有优势。选择检索粒度时,需结合具体任务场景,在检索内容完整性与检索效率之间做好权衡。对于简单查询或强调节省耗时的场景,优先选用实体、三元组等细粒度检索,可有效优化检索速度与内容相关性。而面对复杂推理场景,结合多种粒度的混合检索方式效果更佳,能够更全面地解析图结构与实体关系,提升生成回答的深度与准确性。综上,GraphRAG 在粒度选择上具备高度灵活性,可高效适配不同领域、多样化的信息检索需求。
6.4 Retrieval Enhancement
为保障高质量检索效果,研究人员提出了多种技术,用以优化用户查询与检索到的知识内容。本文将查询增强 分为查询扩展与查询分解两类,将知识增强划分为合并与剪枝两种方式。以上策略从整体上优化了检索流程。
虽然查询重写等技术 114, 117, 132, 137 在通用检索增强生成(RAG)中应用广泛,但在图检索增强生成(GraphRAG)场景下使用较少。因此,本文暂不深入探讨这类方法,即便它们理论上可适配并迁移至 GraphRAG 框架中使用。
6.4.1 查询增强
针对查询所采用的优化策略,通常通过预处理技术丰富查询信息,从而提升检索效果。主要包含查询扩展 与查询分解两种方式。
6.4.2 知识增强
获取初始检索结果后,需通过知识增强策略对检索内容进行精细化优化。该阶段主要包括知识合并 与知识剪枝,以此突出呈现核心关联信息。此类方法旨在确保最终检索结果既具备信息完备性,又高度贴合用户的实际信息需求。
另一类方法利用查询与检索信息之间的相似度完成排序。例如,Cheng 等人 20 结合子图与查询在关系及细粒度概念上的相似度,对候选子图进行重排序。Taunk 等人 158 先对两跳邻居节点做聚类,再删除与输入查询相似度最低的聚类簇。Yasunagaaga 等人 189 借助预训练语言模型计算问题上下文与知识图谱实体节点的相关度分数,并依据该分数对检索子图进行剪枝。Wang 等人 171、Jiang 等人 70、Gutiérrez 等人 51 与 Luo 等人 110 采用 ** 个性化网页排序(Personalized PageRank)** 算法对候选检索信息排序,以便后续筛选。Liu 等人 101 训练......该研究训练预训练语言模型(PLM)计算检索信息与查询文本的相似度,并依据相似度分数对检索路径重新排序。G-G-E 43 先将检索得到的原始子图切分为若干个子子图,再分别计算每个子子图与查询的相似度;剔除低相似度子图后,将剩余高相似子子图合并,形成最终的优化子图。
此外,第三类方法通过设计全新指标实现重排序。例如,Munikoti 等人 124 提出一种指标,可同时衡量检索文本块的影响力 与时效性。KagNet 97 将检索路径拆解为三元组,并结合知识图谱嵌入(KGE)技术计算置信度分数,以此完成路径重排序。基于大语言模型的方法擅长捕捉复杂语言模式与细微语义差异,能够更精准地对检索结果排序或生成回答。为避免引入噪声信息,Wang 等人 171 与 Kim 等人 80 提出调用大语言模型进行核验,对无关图数据做剪枝处理。

Fig. 5. The overview of graph-enhanced generation.
7 Graph-Enhanced Generation
生成阶段是 GraphRAG 中的另一关键环节,旨在将检索到的图数据与用户查询信息相融合,从而提升回答质量。该阶段需根据下游任务选择合适的生成模型,再将检索得到的图数据转换为生成模型可适配的格式。生成模型同时接收查询文本与转换后的图数据作为输入,输出最终回答。除上述基础流程外,借助生成增强技术,可进一步强化查询与图数据之间的交互、丰富生成内容,以此优化输出效果。本节行文结构与图增强生成的整体框架如图 5 所示。
7.1 Generators
生成器的选择通常取决于当下的下游任务类型。对于判别式任务(如选择题问答)或可转化为判别式任务的生成类任务(如知识库问答),可借助图神经网络或判别式语言模型学习数据表征。随后将这些表征映射至不同答案选项对应的预测分值,进而输出回答。此外,也可直接采用生成式语言模型生成答案。但对于纯生成类任务,仅依靠图神经网络与判别式语言模型远远不够。这类任务需要输出文本内容,因此必须搭配解码器模块。
7.1.1 图神经网络(GNNs)
图神经网络(GNN)具备强大的图数据表征能力,在判别式任务中表现尤为优异。GNN 可直接对图数据进行编码,捕捉图结构中复杂的关联关系与节点特征。编码结果经多层感知机(MLP)处理后,输出预测结果。此类方法大多采用经典 GNN 模型(如 GCN 83、GAT 162、GraphSAGE 52、图 Transformer 147),或在原模型基础上进行改造,以更好适配下游任务。
例如,HamQA 30 设计双曲图神经网络学习检索图数据的表征,利用查询与图谱之间的层级关联信息完成建模。Sun 等人 152 在消息传递过程中,计算邻居节点的网页排名分数,并以此分数为权重进行信息聚合,增强中心节点对高相关邻居节点信息的融合能力。Mavromatis 与 Karypis 118 将查询解码为多组指令向量,通过 GNN 模拟广度优先搜索(BFS)强化指令解码与推理执行;同时结合自适应推理机制,融入知识图谱感知信息动态更新指令,提升推理效果。
7.1.2 语言模型(LMs)
语言模型具备强大的文本理解能力,同时也可作为生成器使用。在将语言模型与图数据结合的场景中,需要先将检索得到的图数据转换为特定结构化格式。该转换过程能够确保语言模型有效理解并利用结构化信息。这些格式将在 7.2 节详细阐述,对于保留图数据的关联关系与层级结构至关重要,进而提升模型对复杂数据类型的解析能力。图数据完成格式转换后,将与用户查询拼接融合,一同输入至语言模型中。
对于仅编码器模型(如 BERT 28、RoBERTa 107),其主要应用于判别式任务。与图神经网络(GNN)类似,该类模型先对输入文本进行编码,再通过多层感知机(MLP)将表征映射到答案空间 63,70,90。
而编码器 - 解码器 模型与仅解码器模型(如 T5 138、GPT-4 127、LLaMA 31),可同时胜任判别式任务与生成式任务。这类模型在文本理解、内容生成与逻辑推理方面表现优异,能够直接处理文本输入并输出自然语言回答 32,73,75,112,119,154,164,171。
7.1.3 混合模型
鉴于图神经网络擅长刻画图数据的结构特征,且语言模型具备强大的文本理解能力,大量研究开始融合这两种技术,以生成逻辑连贯的回答。本文将混合生成方法划分为两种不同架构:级联范式 与并行范式。
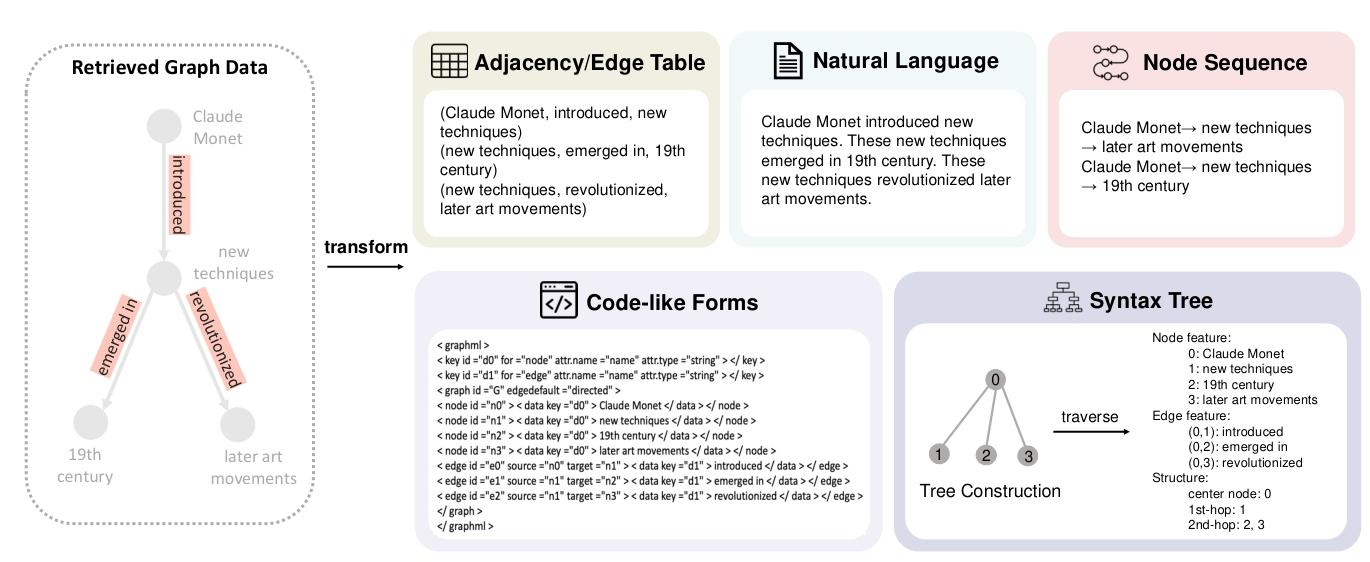
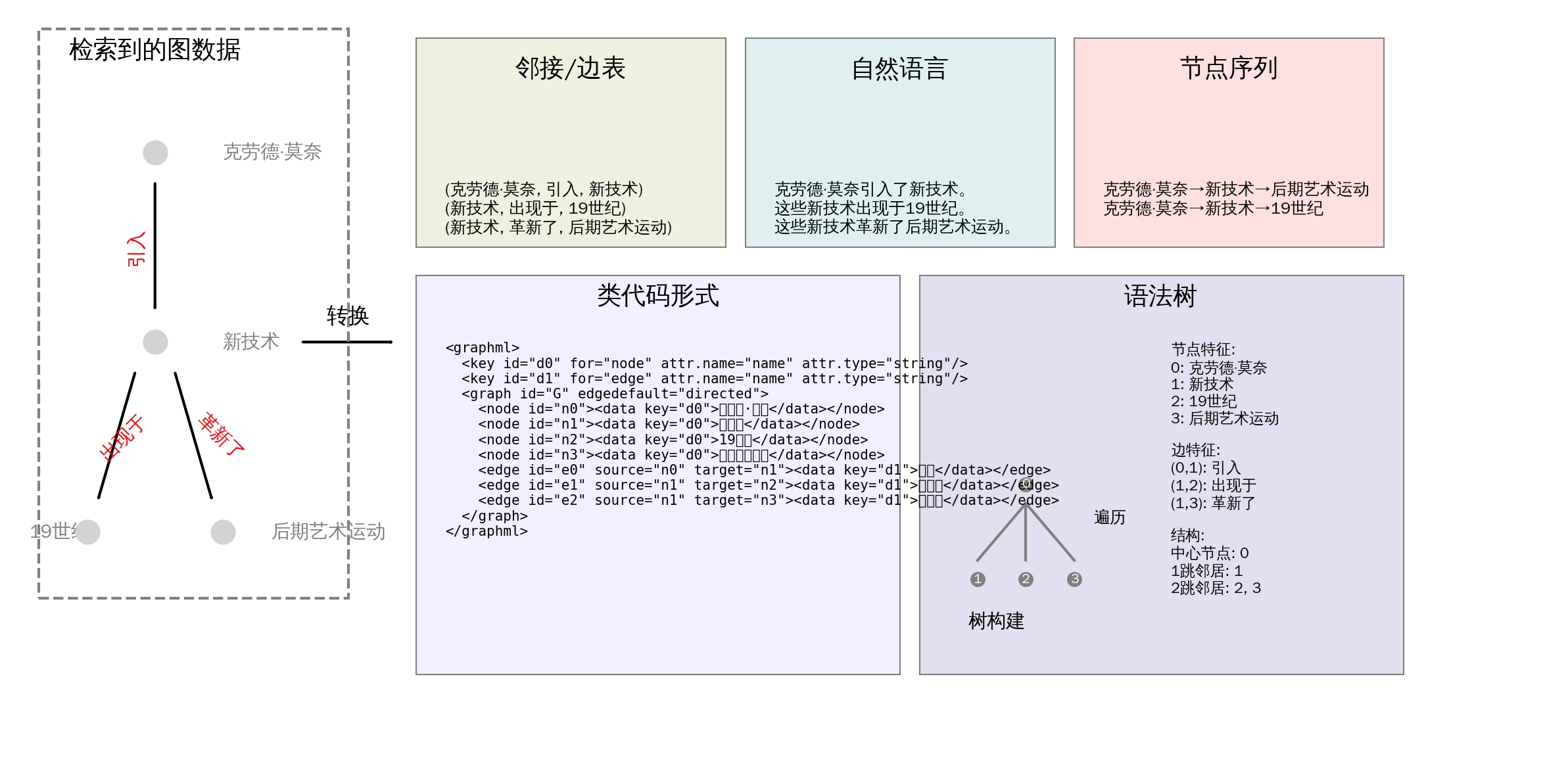
图 6 图语言形式示意图 以左侧检索得到的子图为例,展示其转换为邻接表 / 边表、自然语言、节点序列、类代码格式 以及语法树的实现方式,用以适配不同生成器的输入格式要求。
由图神经网络(GNN)得到的图表征 ,以及语言模型(LM)借助注意力机制生成的文本表征。Yasunagaaga 等人 189、Munikoti 等人 124 与 Taunk 等人 158 直接将图表征与文本表征进行拼接融合。
另一种方法是设计专用模块,将图神经网络与语言模型相结合,使融合后的表征同时包含结构信息 与文本信息。例如,Zhang 等人 199 提出了名为 GreaseLM 层的模块,该模块同时集成图神经网络层与语言模型层。在每一层中,该模块通过双层多层感知机融合文本表征与图表征,再将融合结果传入下一层。无独有偶,ENGINE 204 提出了 G-Ladders 架构,通过旁路结构融合语言模型与图神经网络,以此优化节点表征,提升下游任务效果。
讨论混合模型结合了图神经网络对图数据的表征能力与语言模型对文本数据的理解能力,具备广阔的应用前景。但如何有效融合这两种模态的信息,仍是一大难题。
7.2 Graph Formats图数据格式
当使用图神经网络作为生成器时,可直接对图数据进行编码。然而,若以语言模型作为生成器,图数据的非欧几里得特性 会带来难题 ------ 其无法与文本数据直接拼接并输入语言模型。为解决该问题,研究人员借助图转换模块 ,将图数据转化为语言模型可适配的格式。该转换方式能让语言模型有效处理并利用结构化图谱信息,进而提升文本生成能力。本文综述将图数据的适配形式归纳为两大类:图语言 与图嵌入。下文将结合图 6 的实例演示该转换过程,并展开详细介绍。
7.2.1 图语言
图描述语言是一套专门用于刻画与表示图数据的形式化符号系统。它规定了统一的语法与语义框架,用以描述图中的组成元素及其相互连接关系。借助这类语言,用户可以生成、处理和解析图数据,使其以机器可理解的形式呈现。它们支持定义图的整体结构、指定节点与边的属性,也能实现对图结构的各类操作与查询。下文将分别介绍五种图语言形式:邻接 / 边表、自然语言、代码形式、语法树、节点序列。
讨论
优质的图语言应兼具完整性、简洁性与可理解性 。完整性指需完整捕获图结构中的全部核心信息,确保不遗漏关键内容。简洁性要求文本描述足够精简,避免出现中间信息丢失问题 104,同时防止超出语言模型的输入长度限制。过长的输入会削弱语言模型的处理能力,易造成上下文缺失或数据解读截断。可理解性则保障大语言模型能够轻松识别并解析该表达形式,从而精准还原图的拓扑结构。不同图语言具备各自特性,其选型会对下游任务的最终性能产生显著影响 38。
7.2.2 图嵌入
上述图语言方法将图数据转换为文本序列,这可能导致上下文过长,带来高昂的计算成本,甚至超出大语言模型的处理上限。此外,即便借助图语言,当前的大语言模型仍难以完全理解图的结构信息 49。因此,利用图神经网络将图表示为嵌入向量,成为一种颇具前景的替代方案。
这类方法的核心挑战在于,如何将图嵌入与文本表征融合到同一个语义空间中。当前研究主要聚焦于前文讨论过的提示词微调方法;也有部分方法采用 ** 解码器融合(FiD, Fusion-in-Decoder)** 架构 65, 194:先将图数据转换为文本,再通过语言模型编码器进行编码,最终输入解码器 29, 37, 193。
值得注意的是,将图表征直接输入语言模型的方案,目前主要适用于开源模型,而不适用于 GPT-4 等闭源模型 127。虽然图嵌入方法规避了处理超长文本输入的问题,但也面临其他挑战,例如难以保留实体名称等精确信息,以及泛化能力较弱等问题。
7.3 Generation Enhancement
在生成阶段,除了将检索到的图数据转换为生成器可接受的格式,并与查询一同输入以生成最终回答外,众多研究者还探索了各类生成增强方法,用以提升输出回答的质量。依据作用阶段的不同,这些方法可分为三类:生成前增强、生成中增强 与生成后增强。
7.3.1 生成前增强
生成前增强技术,旨在将数据与表征输入生成器之前,对其质量进行优化提升。事实上,生成前增强与检索阶段并无清晰的划分边界。本文将从原始图谱中检索知识、并对检索结果进行合并与剪枝的过程定义为检索阶段,而在此之后的优化操作,均归属于生成前增强范畴。
常用的生成前增强手段,主要对检索得到的图数据进行语义扩充,从而拉近图数据与文本查询的语义关联,实现二者更紧密的融合。
Wu 等人 182 利用大语言模型对检索图数据进行重写,提升转换后自然语言文本的流畅度与语义丰富度。该方法不仅能将图数据转化为更通顺自然的表述,还可进一步扩充语义信息。与之相反,DALK 89 则依托检索到的图数据对用户查询进行改写。
Cheng 等人 20 先借助大语言模型生成推理方案,并依据该方案作答。Taunk 等人 158 与 Yasunagaaga 等人 189 聚焦于增强图神经网络的能力,使其学习与查询强相关的图表征。具体做法为:抽取问答对中的全部名词(或直接利用完整问答对),将其作为新节点插入检索子图中。
Mavromatis 和 Karypis 118 提出一种生成前优化方法:将查询表征拆解为多个向量,并称其为指令,每条指令对应查询的不同特征。在利用图神经网络对检索子图进行消息传递与学习时,将这些指令作为约束条件,辅助建模推理。
此外,还有部分方法会引入图数据以外的额外信息。例如,PullNet 151 融合实体相关文档,MVP-Tuning 63 则检索其他相似问题作为补充信息。
7.3.2 生成中增强
生成中增强是指在文本生成过程中所采用的优化技术。该类方法通常依据中间输出结果或上下文信息,动态调整生成策略。
TIARA 148 引入约束解码机制,用以限制输出范围、降低生成错误。在逻辑表达式生成阶段,若约束解码器检测到当前正在生成模式类元素,便会限制下一时刻的生成词元,仅允许从包含知识库类别与关系的字典树候选集合中选择。相较于束搜索,该方法能够保证生成的模式元素均真实存在于知识图谱中,有效减少错误生成。
还有部分方法通过动态调整大语言模型的提示词,实现多步推理。例如 MindMap 175 模型在输出最终答案的同时,会同步生成完整推理过程。
7.3.3 生成后增强
生成后增强作用于初始回答生成完成之后。此类方法主要通过融合多份生成结果,整合得到最终回复。
部分方法侧重整合同一生成器在不同条件或不同输入下的输出结果。例如,Edge 等人 32 先为每个图谱社区分别生成摘要,再依据摘要生成查询回答,并利用大语言模型对所有回答进行打分;最终将回答按分数降序排列,依次纳入提示词,直至达到词元上限,再由大语言模型输出最终答案。Wang 等人 164 与 Kim 等人 80 先将原始查询拆解为若干子问题,逐个生成子问题答案,最后融合所有子答案,整合输出最终结果。
另一类方法则组合或筛选不同模型 生成的回复。Lin 等人 97 和 Jiang 等人 68 融合图神经网络与大语言模型的输出,实现优势互补、协同优化。UniOQA 95 采用双路径答案生成方案:一是通过生成 Cypher 查询语言(CQL)语句执行查询并获取结果,二是直接基于检索到的三元组生成答案,再通过动态筛选机制择优确定最终回答。EmbedKGQA 145 除使用学习打分函数外,还额外设计基于图结构的规则化打分机制,结合两种分数筛选目标答案实体。Li 等人 94 将基于检索图数据生成的答案 与大语言模型自身知识库生成的回答进行融合。
除多结果融合外,KALMV 7 通过训练校验器,判别生成答案是否正确;若答案有误,进一步定位错误来源,区分问题出自生成阶段还是检索阶段。
8 Training
本节综述检索器与生成器的单独训练 及联合训练 方式。本文根据是否需要显式训练,将现有研究划分为无训练方法 与基于训练方法两类。
若采用 GPT-4 等闭源大语言模型作为检索器或生成器,通常使用无训练方案。该类方法主要依靠精心设计的提示词,调控大语言模型的检索与生成能力。尽管大语言模型具备强大的文本理解与推理能力,但无训练方法存在明显局限:由于未针对下游任务做专属优化,输出结果往往难以达到最优效果。
与之相对,基于训练的方法利用监督信号对模型进行训练或微调,使模型适配特定任务目标,进而提升检索与生成内容的质量及相关性。
检索器与生成器的联合训练,旨在强化二者协同能力,提升下游任务整体性能。这种协同范式能够充分发挥两个模块的互补优势,在信息检索与内容生成场景中,获得更稳定、高效的效果。
8.1 Training Strategies of Retriever检索器的训练策略
8.1.1 无训练方案
目前主流的无训练检索器主要分为两类。第一类为非参数化检索器,此类检索器依赖预设规则或传统图搜索算法实现检索,无需专用模型 158, 189。第二类则以预训练语言模型作为检索器。其中一部分研究利用预训练嵌入模型对查询进行编码,直接依据查询与图元素之间的相似度完成检索 90;另一部分研究采用生成式语言模型实现无训练检索,将实体、三元组、路径、子图等候选图元素整合为大语言模型的提示输入,模型依托语义关联,结合给定提示筛选出匹配的图结构要素 32, 75, 80, 119, 154, 164, 171。该类方法充分发挥语言模型强大的语义理解能力,无需额外训练,即可完成相关图元素的检索任务。
8.1.2 基于训练的方案
当检索粒度为节点 或三元组时,多数方法通过训练检索器,最大化检索真值与查询文本之间的相似度。例如,记忆神经网络(MemNNs)12 借助度量学习,让真值内容与查询在语义空间中紧密对齐,同时区分并隔离与查询无关的事实信息。
反之,当检索粒度为路径时,检索器训练通常采用自回归方式:将已生成的关系路径拼接至查询末尾,模型再基于该拼接后的输入,预测下一条关系 50, 182。
然而,绝大多数数据集缺乏检索内容的真实标注 ,这成为一大难点。为解决该问题,诸多方法基于远程监督构建推理路径,用以指导检索器训练。
例如,Zhang 等人 196、Feng 等人 39 与 Luo 等人 112,抽取查询实体与答案实体之间的所有路径(或最短路径),将其作为检索器的训练数据。此外,Zhang 等人 196 还在无监督场景下,利用关系抽取数据集实现远程监督。
还有一类方法依靠隐式中间监督信号训练检索器。例如 NSM 54 采用双向搜索策略,由两个检索器分别从头实体与尾实体开始双向遍历,训练监督目标为保证双方搜索路径尽可能收敛重合。KnowGPT 198 与 MINERVA 23 将选择邻接节点、构建路径或子图的过程建模为马尔可夫过程;围绕「检索结果是否包含答案」设计奖励函数,并采用策略梯度等强化学习算法对检索器进行优化。
8.2 Training of Generator生成器的训练
8.2.1 无训练方案
无训练生成器主要适用于闭源大语言模型,或需要严控训练成本的应用场景。该类方案将检索得到的图数据与用户查询共同输入大语言模型,模型依据提示词中的任务要求生成回复,全程依赖自身原生能力理解查询语义与图结构信息。
8.2.2 基于训练的方案
生成器训练可直接接收下游任务的监督信号。对于生成式大语言模型,可通过 监督微调(SFT) 完成训练:输入任务说明、查询内容与图数据,将模型输出与下游任务的标准答案进行比对学习 55,58,112。而对于用作生成器的图神经网络或判别式模型,则会采用适配下游任务的专属损失函数,实现高效训练 68,90,158,189,199。
8.3 Joint Training
联合训练检索器与生成器,能够充分发挥二者的互补优势,同步提升下游任务的整体性能。部分研究将检索器与生成器整合为单一模型(通常为大语言模型),并以检索与生成双重目标进行联合训练 112。该方式依托统一架构的协同能力,让模型在同一框架内无缝完成相关信息检索与连贯文本生成。
其他研究方法会先对检索器与生成器进行单独训练 ,再通过联合训练策略对两个模块共同微调。例如,子图检索器(Subgraph Retriever)196 采用交替训练范式:先固定检索器参数,利用图数据训练生成器;随后固定生成器参数,借助生成器的反馈信号指导检索器优化。该迭代训练方式可使两个模块协同迭代,同步提升整体性能。
9 Applications and Evaluation
本节将梳理归纳图检索增强生成(GraphRAG) 相关的下游任务、应用领域、基准数据集与评价指标,以及工业落地应用。表 1 汇总了现有 GraphRAG 技术,从下游任务、基准测试、实现方法与评估指标四大维度完成分类。该表格全面概述了 GraphRAG 技术在不同领域的各类研究方向与实际应用场景。
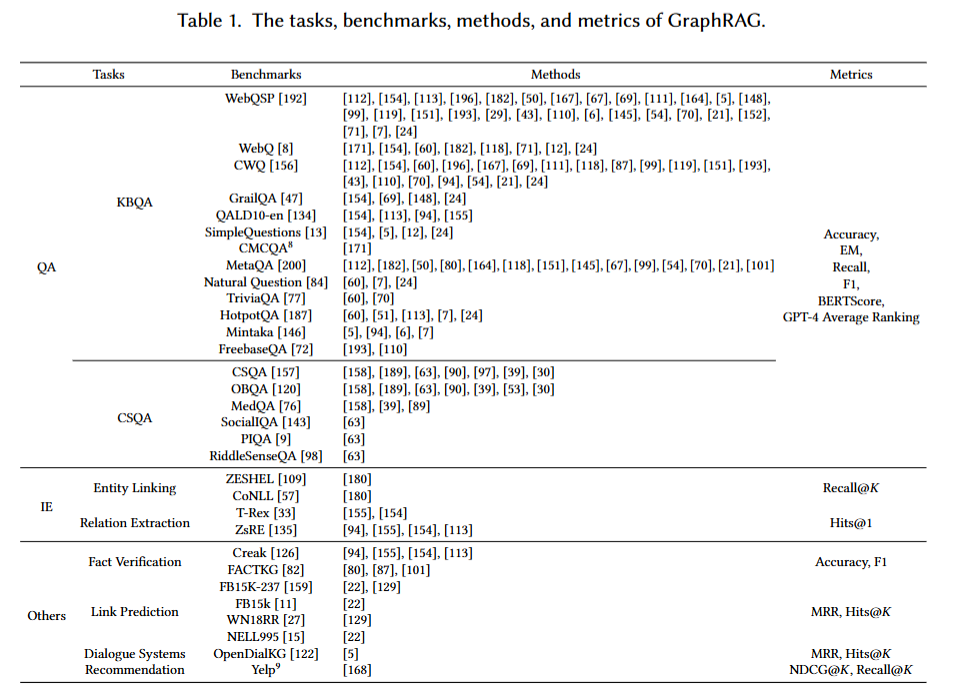
9.1.1 问答任务
问答任务具体包含 ** 知识库问答(KBQA)与常识问答(CSQA)** 两类。
9.1.2 信息检索
信息检索任务分为两类:实体链接(EL)与关系抽取(RE)。
9.1.3 其他任务
除上述下游任务外,GraphRAG 还可应用于自然语言处理领域的各类其他任务,包括事实核验、链接预测、对话系统与推荐系统等。
9.2 Application Domains
由于具备将结构化知识图谱与自然语言处理深度融合的突出能力,GraphRAG 已广泛应用于电商、生物医学、学术、文学、法律等各类场景,下文将展开具体介绍。
9.2.1 电子商务
电商领域的核心目标,是通过个性化推荐与智能客服,提升用户购物体验并促进销量增长。在该场景下,用户与商品的历史交互可自然构成图谱,隐性蕴含用户行为模式与偏好信息。随着电商平台数量增多、用户交互数据体量持续膨胀,利用 GraphRAG 技术抽取关键子图变得至关重要。
王等人 168 融合多类不同类型、不同参数的检索器,筛选相关子图并完成编码,用于时序化用户行为预测。为提升客服问答系统的模型性能,徐等人 183 构建包含问题内部关联与问题间关联的历史工单图谱。针对每一条用户查询,系统检索相似历史工单的子图,以此优化客服回复质量。
9.2.2 生物医学领域
近年来,GraphRAG 技术越来越多地应用于生物医学问答系统,实现了高水平的医疗决策辅助效果。在该领域中,每种疾病对应特定症状,每种药物含有特定有效成分,可针对性治疗相关疾病。
部分研究者 26, 89, 177 会面向特定业务场景自定义构建知识图谱;也有研究 73, 175, 185 选用 CMeKG、CPubMed-KG 等开源知识图谱作为检索数据源。
现有主流方法通常先通过非参数检索器完成初步检索,再结合重排序策略对检索结果筛选过滤 26, 73, 89, 175, 185。此外,还有部分研究利用检索到的知识重构模型输入文本,进而提升内容生成质量 89。
9.2.3 学术领域
在学术研究领域,每篇论文由一位或多位研究者撰写,并对应特定研究方向。学者隶属于各类科研机构,彼此之间存在合作、同单位任职等关联关系。上述要素均可构建为结构化知识图谱。基于该图谱运用 GraphRAG 技术,能够助力学术研究探索,例如预测学者潜在合作对象、研判特定学科的发展趋势等。
9.2.4 文学领域
与学术研究场景类似,文学领域也可搭建知识图谱:节点可代表书籍、作者、出版社、丛书等元素,边则标注「所著」「出版于」「所属丛书」等关联关系。借助 GraphRAG 技术,能够有效赋能智慧图书馆等实际应用场景。
9.2.5 法律领域
在法律场景中,案件与司法判例之间存在大量引用关联。法官在作出新判决时,常会援引过往判例,由此自然形成结构化图谱。该图谱以判例、判例集群、案卷、法院为节点,边则包含判例引用 、判例归属集群 、集群关联案卷 、案卷所属法院等关系。GraphRAG 应用于法律领域,可辅助律师与法律研究人员开展案件分析、法律咨询等各类工作。
9.2.6 其他领域
除上述应用场景外,GraphRAG 还广泛落地于其他实际业务场景,例如情报报告生成139、专利短语相似度检测 133 以及软件理解 1。
拉纳德与乔希 139 首先构建事件情节图谱(EPG),检索事件的核心关键信息,为情报报告的生成提供支撑。彭阳等人 133 搭建专利短语图谱,检索指定专利短语的自我中心网络,辅助完成短语相似度判定。阿尔哈纳纳等人 1 研发了一款智能对话机器人,用于解析指定软件包的依赖属性;该工具可自动构建依赖关系图谱,支持用户针对图谱内的各类依赖关系进行问答查询。
9.3 Benchmarks and Metrics基准数据集与评价指标
9.3.1 基准数据集
用于评估 GraphRAG 系统性能的基准数据集可分为两类。第一类为各类下游任务对应的专用数据集。本文依据 9.1 节的任务分类,整理汇总了相关基准及其对应实验文献,详细结果如表 1 所示。第二类是专为 GraphRAG 系统设计的综合基准,通常覆盖多类任务领域,从而实现全面的性能评测。
例如,STARK 179 面向半结构化知识库,评测大模型检索能力,涵盖商品搜索、学术文献检索、精准医疗查询三大场景,用以衡量现有 GraphRAG 系统的综合能力。He 等人 55 提出面向真实文本图谱的通用问答基准数据集 GraphQA,适用于场景图谱理解、常识推理、知识图谱推理等多项任务。
图谱推理基准 GRBENCH 75 专为大模型图谱增强研究构建,包含 1740 条问题,依托 10 个不同领域的知识图谱即可完成作答。CRAG 186 提供结构化查询数据集,并配套模拟接口以读取仿真知识图谱的数据,保障各类模型对比实验的公平性。
9.3.2 评价指标
GraphRAG 的评价指标主要分为两大类:下游任务效果(生成质量)与检索质量。
9.4 GraphRAG in Industry
本节主要聚焦工业级 GraphRAG 系统。该类系统的核心特征为:依赖工业级图数据库架构,或面向大规模图谱数据场景,具体说明如下。
微软 GraphRAG:该系统依托大语言模型构建实体级知识图谱,并预先生成相关实体集群的社区摘要,能够同时捕获文档集中的局部关联与全局关联,进而优化 ** 面向查询的摘要生成(QFS)** 任务效果。该项目也可借助 LlamaIndex、LangChain 等开源检索增强开发工具包快速部署落地。
星云图(NebulaGraph)GraphRAG:该项目是首个工业级 GraphRAG 系统,由星云图公司研发。系统将大语言模型(LLM)深度集成至 NebulaGraph 图数据库中,旨在输出更智能、更精准的检索结果。
蚂蚁集团 GraphRAG:该框架基于 DB-GPT、知识图谱引擎 OpenSPG、图数据库 TuGraph 等多项人工智能工程框架搭建而成。具体流程为:首先利用大语言模型从文档中抽取三元组知识,并存入图数据库;检索阶段,从用户问题中提取关键词,定位图谱对应节点,通过广度优先搜索(BFS)或深度优先搜索(DFS)遍历抽取子图;生成阶段,将检索得到的子图数据转为文本格式,结合上下文与用户问题一并输入大模型,完成答案生成。
Neo4j 推出的 NaLLM:NaLLM(融合 Neo4j 图数据库与大语言模型)框架,将 Neo4j 图数据库技术与大语言模型深度结合。该框架旨在探索并验证二者的协同能力,核心聚焦三大应用场景:面向知识图谱的自然语言交互接口、从非结构化数据构建知识图谱,以及结合静态数据与大模型数据生成分析报告。
LLM Graph Builder(Neo4j 出品) :这是 Neo4j 推出的一款知识图谱自动构建工具,适用于 GraphRAG 流程中的图数据库搭建与索引构建阶段。该工具主要依托大语言模型,从非结构化数据中自动抽取实体节点、语义关系及属性信息,并结合 LangChain 框架快速搭建结构化知识图谱。
10 Future Prospects
尽管 GraphRAG 技术已取得长足发展,但仍面临诸多长期存在的难题,亟待深入探究。本节将剖析 GraphRAG 领域当前普遍存在的挑战,并梳理未来的研究方向与发展思路。
10.1 Dynamic and Adaptive Graphs动态自适应图谱
多数 GraphRAG 方法 32, 41, 85, 86, 111, 188 均基于静态数据库构建;但随着时间推移,新的实体与关联关系会不断产生 20, 44, 181。如何快速完成数据变更更新,既是研究热点,也是一大挑战。及时纳入最新信息,对于提升模型效果、适配需要实时数据的新兴业务场景至关重要。研发高效的动态更新机制与新数据实时融合方案,能够大幅提升 GraphRAG 系统的实用性与内容相关性。
10.2 Multi-Modality Information Integration多模态信息融合
大多数知识图谱主要仅包含文本信息,缺少图像、音频、视频等多模态数据,而这类信息能够显著提升知识库的整体质量与内容丰富度 174。融入多元模态数据,有助于更全面、细致地理解图谱中存储的知识。但多模态数据的融合也带来了巨大挑战。随着信息量不断增加,图谱的复杂度与规模会呈指数级增长,极大增加管理与维护难度。面对规模的持续扩张,亟需研发先进方法与成熟工具,将不同类型的数据高效、无缝地融入现有图谱结构,保障扩充后知识图谱的准确性与可访问性。
10.3 Scalable and Efficient Retrieval Mechanisms可扩展且高效的检索机制
工业场景下的知识图谱往往包含数百万乃至数十亿个实体,规模庞大且结构复杂。然而,当前多数方法仅适用于仅有数千个实体的小规模知识图谱 32。在大规模知识图谱中高效精准地检索相关实体,仍是一项极具现实意义的重大难题。研发先进的检索算法与可扩展的底层架构是解决该问题的关键,以此确保系统能够承载海量数据,同时保持实体检索的高性能与高准确率。
10.4 Combination with Graph Foundation Model
近年来,图基础模型 42, 115 在各类图谱任务中取得重大突破,可高效解决多种图学习问题。如何利用该类模型优化现有 GraphRAG 全流程,是当前的核心研究课题。图基础模型的输入天然适配图结构数据,处理此类数据的效率远优于传统大语言模型。将该先进模型融入 GraphRAG 框架,能够大幅提升系统对图结构信息的处理与利用能力,进而全面增强整体性能与综合表现。
10.5 Lossless Compression of Retrieved Context检索上下文的无损压缩
在 GraphRAG 中,检索到的信息会以包含实体及其相互关系的图结构进行组织。随后,这类信息会被转换为大语言模型可理解的序列,进而形成超长上下文 。输入此类超长上下文会引发两大问题:大语言模型难以处理极限长序列,且推理过程中的海量计算会大幅增加使用成本与负担。为解决上述问题,对长上下文进行无损压缩至关重要。该技术可剔除冗余内容,将冗长语句精简为简洁且语义完整的短句,帮助大语言模型快速抓取上下文核心信息,同时加速推理运算。但设计可行的无损压缩方案存在不小难度。现有研究 41, 86 大多需要在压缩效率与信息留存之间做出权衡。因此,研发高效的无损压缩技术,是 GraphRAG 领域亟待突破且极具挑战性的关键方向。
10.6 Standard Benchmarks
GraphRAG 是一个较新兴的研究领域,目前缺乏统一、规范的基准测试体系来评估各类算法模型。建立标准化基准对该领域发展至关重要:它能提供统一的对比框架,实现对不同技术方案的客观评估,同时通过明确各方法的优劣短板,推动领域整体技术进步。这类基准体系需要涵盖多元且具有代表性的数据集、定义清晰的评价指标以及完整全面的测试场景,从而实现对 GraphRAG 方法严谨、有效的综合评测。
10.7 Broader Applications
当前 GraphRAG 的落地应用主要集中在客服系统、推荐系统、** 知识库问答(KBQA)** 等通用场景。若要将其拓展至医疗健康、金融服务、法律合规、智慧城市与物联网等更多复杂领域,则需要结合更为复杂的技术方案。
以医疗领域为例,GraphRAG 可整合医学文献、患者病历与实时健康数据,辅助疾病诊断、病历分析以及个性化治疗方案制定。在金融场景中,该技术能够通过分析交易记录、市场走势与用户画像,实现风控反诈、风险评估以及定制化理财建议。
在法律合规领域,借助法律文书、判例法与最新监管条例,GraphRAG 可实现全维度法条检索、合同内容审查以及合规风险监测。将 GraphRAG 进一步落地至各类复杂垂直领域,能够持续拓宽其应用边界与实际价值,为各行各业提供更精细、更具针对性的智能解决方案。
11 Conclusion
综上,本文全面综述了 GraphRAG 技术,对其基础理论、训练方法与应用场景进行了系统梳理与分类。GraphRAG 依托图谱数据中的关联关系知识,显著提升了信息检索的相关性、准确性与全面性,有效弥补了传统检索增强生成(RAG)技术的核心短板。同时,鉴于 GraphRAG 仍处于新兴发展阶段,本文梳理了现有评测基准,分析了当前面临的核心挑战,并指明了该领域未来的研究方向。