目录
[一. 前言:](#一. 前言:)
[• 完整版:](#• 完整版:)
[1. 需要"均匀随机"抽取元素的场景](#1. 需要“均匀随机”抽取元素的场景)
[2. 随机化算法(Randomized Algorithms)](#2. 随机化算法(Randomized Algorithms))
[• 代码实现](#• 代码实现)
一. 前言:
我们都知道哈希表中 数据的存储是无序的,因此在查找的时候 ++平均时间复杂度都是 O(1)++
即使你这么牛背下来插入顺序,但是在扩缩容之后顺序又会变化,这你咋整呢?
如果我们想要知道数据储存的顺序怎么办呢? 这个时候我们有两种方法 "链表加强" 或者 "数组加强"
下面我们先来讲讲链表加强以及它背后的原理
二.链表加强哈希表,串联键值
++把这些键值用 链表的形式 串联起来,++
这时候大家肯定有些迷糊了,拉链法中不是已经用链表串起来了吗 ? 在数组中又应该怎么用链表串联起来呢?
如下图:
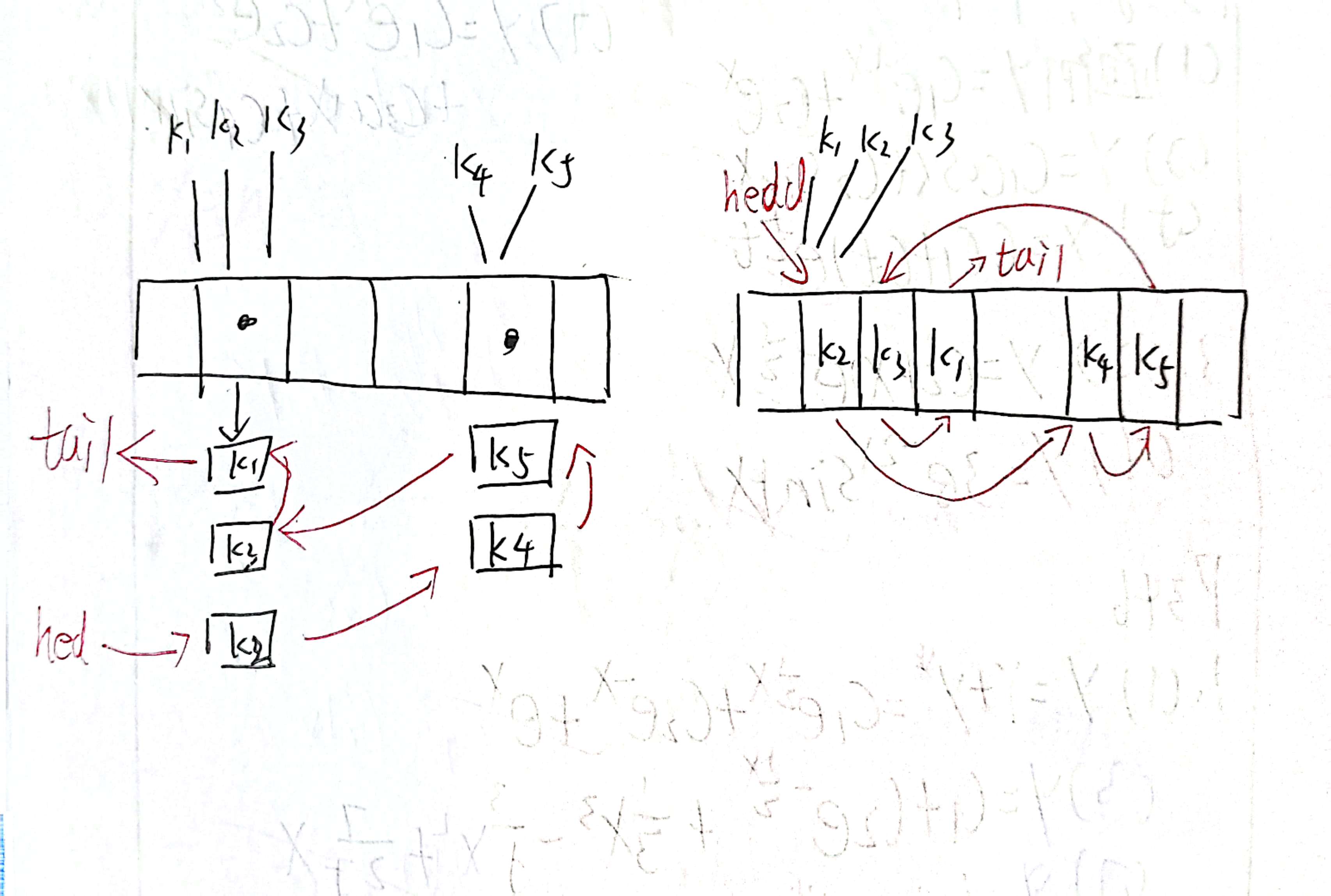
实现的时候,保留key不变,相当于在value的位置改成Node 结构体 ,通过指针彼此联系
如下:
原本:
cpp
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
using namespace std;
int main(){
unordered_map<string,string> map;
string key = "key";
string value = "value";
map[key] = value;
// map.insert({key,value})
cout << map[key] << endl;
}在给映射添加双链表之后:
cpp
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
using namespace std;
struct Node{
string key;
string value;
Node* next;
Node* prev;
Node (string key,string value):
key(std::move(key)) , value(std:: move(value)) , next(nullptr) , prev(nullptr) {}
};
int main(){
unordered_map<string,Node*> map;
string key = "key";
string value = "value";
map[key] = new Node(key,value);
// map.insert({key,new Node(key,value })
}哈希表中value数据类型是 Node* ,因此在堆上分配内存即可,
++这个move是 std::move(key)++ ,移动 参数 key 的内容到成员变量中,参数 key 变为"空壳"(有效但未指定状态),避免了内存分配和字符拷贝,性能更高。
直接传入key的话,相当于拷贝,重新复制了一份副本,效率不高
如果觉得手动释放指针很麻烦,可以用智能指针(以后详细的篇章,我会尽快学完更新,感觉在给自己挖坑)-----顺带一提C++14才有智能指针
cpp
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
#include<memory>
using namespace std;
struct Node{
string key;
string value;
Node* next;
Node* prev;
Node (string key,string value):
key(std::move(key)) , value(std:: move(value)) , next(nullptr) , prev(nullptr) {}
};
int main(){
unordered_map<string,unique_ptr<Node>> map;
string key = "key";
string value = "value";
map[key] = make_unique<Node>(key,value);
// map.insert({ key , make_unique<Node>(key,value) })
}使用智能指针就不用考虑内存泄露的问题,因为它会自动释放
具体实现:
初始化:
cpp
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
#include<memory>
using namespace std;
template <typename K, typename V>
struct Node{
K key;
V val;
Node* next;
Node* prev;
Node(K key,V val) : key(key) , val(val) , next(nullptr) ,prev(nullptr){};
};
template<typename K, typename V>
class MyLinked_Hashmap{
public:
MyLinked_Hashmap(){
head = new Node<K,V> (K(), V());
tail = new Node<K,V> (K(), V());
head->next = tail;
tail->prev = head;
}// 双向链表初始化
~MyLinked_Hashmap(){
Node<K,V>* current = head->next;
while (current != tail){
Node<K,V>* next = current->next;
delete current;
current = next;
}
delete head;
delete tail;
//另一宗写法直接让current = head, while条件写 current != nullptr
}
MyLinked_Hashmap(const MyLinked_Hashmap&) = delete;
MyLinked_Hashmap& opreator = (const MyLinked_Hashmap&) = delete;
};= delete 用法通常用于显示静止函数,表示++函数可见但是不可以用++ , 常用于 "禁止重载" "禁止拷贝"
这里禁止拷贝函数和 函数重载的隐式转化,为了避免浅拷贝(其实你也可以自己补全这两个函数实现深拷贝)
注意: head 和 tail 指针指向的都是虚拟节点,可以避免"边界条件" 的考虑
cpp
private:
Node<K,V>* head;//头指针
Node<K,V>* tail;//尾指针
unordered_map<K, Node<K,V>* > map;
//第一个是key,第二个是Node*类型的value(指向Node)
void addLastNode(Node<K,V> *new_node){
Node<K,V>* temp = tail->prev;
new_node->next = tail;
new_node->prev = temp;
temp->next = new_node;
tail->prev = new_node;
}//添加到链表最后,记录先后顺序
void removeNode(Node<K,V> *node){
Node<K,V> *next = node->next;
Node<K,V> *prev = node->prev;
prev->next = next;
next->prev = prev;
node->next = node->prev = nullptr;
} //只负责逻辑删除private : 定义 head 和 tail 指针 ,还有 哈希表
addLastNode() 添加新的节点到链表最后
removeNode() 逻辑上删除节点,制空但是内存上没有删除
• 增删改查
cpp
V get(K key){
if (map.find(key) == map.end()){
return V();
}
return map[key]->val;
} // 查找
void put(K key, V val){
if (map.find(key) == map.end()){
Node<K,V>* node = new Node<K,V>(key,val);
addLastNode(node); // 加在链表最后
map[key] = node;
return;
}
//存在就更改
map[key]->val = val;
}//增加,改
void remove(K key){
if (map.find(key) == map.end()){
return;
}//查找没找到
Node<K,V>* node = map[key]; //原始指针指向的底层
map.erase(key); // 清除key在哈希表的内存
removeNode(node); //链表逻辑删除
delete node;
}//删除这里值得一提的是 remove ,很多人会有疑问 erase不是会释放内存吗?为什么又重新用delete一遍。
这里需要知道: 代码中容器哈希表储存的是 key--node* ,注意是指针,容器并不知道要释放原始指针指向的内存,因此需要我们手动删除(如果用智能指针,或者直接让容器管理对象,而不是用原始指针,就没有这种问题)
在删除在容器中的内存后,逻辑上删除链表中位置,最后彻底释放内存。
• 工具函数
cpp
//工具函数
bool count(K key){
return map.find(key) != map.end();
}//检测元素是否存在
vector<K> keys(){
vector<K> keyList;//返回key,借助链表
for (Node<K,V> *temp = head->next; temp != tail; temp = temp->next){
keyList.push_back(p->key);
}
return keyList;
}//储存在数组里面,返回出来
size_t size(){
return map.size();
}//key--value对数
bool empty(){
return map.empty();
}• 完整版:
cpp
#include<iostream>
#include<unordered_map>
#include<vector>
#include<string>
#include<memory>
using namespace std;
template <typename K, typename V>
struct Node{
K key;
V val;
Node* next;
Node* prev;
Node(K key,V val) : key(key) , val(val) , next(nullptr) ,prev(nullptr){};
};
template<typename K, typename V>
class MyLinked_Hashmap{
private:
Node<K,V>* head;//头指针
Node<K,V>* tail;//尾指针
unordered_map<K, Node<K,V>* > map;
//第一个是key,第二个是Node*类型的value(指向Node)
void addLastNode(Node<K,V> *new_node){
Node<K,V>* temp = tail->prev;
new_node->next = tail;
new_node->prev = temp;
temp->next = new_node;
tail->prev = new_node;
}//添加到链表最后,记录先后顺序
void removeNode(Node<K,V> *node){
Node<K,V> *next = node->next;
Node<K,V> *prev = node->prev;
prev->next = next;
next->prev = prev;
node->next = node->prev = nullptr;
} //只负责逻辑删除
public:
MyLinked_Hashmap(){
head = new Node<K,V> (K(), V());
tail = new Node<K,V> (K(), V());
head->next = tail;
tail->prev = head;
}// 双向链表初始化,头指针和尾指针指向的是虚拟节点,避免边界条件
~MyLinked_Hashmap(){
Node<K,V>* current = head->next;
while (current != tail){
Node<K,V>* next = current->next;
delete current;
current = next;
}
delete head;
delete tail;
//另一宗写法直接让current = head, while条件写 current != nullptr
}
//禁止拷贝函数,避免浅拷贝
MyLinked_Hashmap(const MyLinked_Hashmap&) = delete;
MyLinked_Hashmap& operator=(const MyLinked_Hashmap&) = delete;
V get(K key){
if (map.find(key) == map.end()){
return V();
}
return map[key]->val;
} // 查找
void put(K key, V val){
if (map.find(key) == map.end()){
Node<K,V>* node = new Node<K,V>(key,val);
addLastNode(node); // 加在链表最后
map[key] = node;
return;
}
//存在就更改
map[key]->val = val;
}//增加,改
void remove(K key){
if (map.find(key) == map.end()){
return;
}//查找没找到
Node<K,V>* node = map[key]; //原始指针指向的底层
map.erase(key); // 清除key在哈希表的内存
removeNode(node); //链表逻辑删除
delete node;
}//删除
//工具函数
bool count(K key){
return map.find(key) != map.end();
}//检测元素是否存在
vector<K> keys(){
vector<K> keyList;//返回key,借助链表
for (Node<K,V> *temp = head->next; temp != tail; temp = temp->next){
keyList.push_back(temp->key);
}
return keyList;
}//储存在数组里面,返回出来
size_t size(){
return map.size();
}//key--value对数
bool empty(){
return map.empty();
}
};
int main(){
MyLinked_Hashmap<string,int> map;//---封装成的类
map.put("a",1);
map.put("c",2);
map.put("d",4);
map.put("f",10);
map.put("h",15);//添加
for (const auto key : map.keys()){
cout << key << " ";
}//map.keys()是一个数组,如果用的是for i 循环 size(),就不能按顺序输出了
cout << endl;
map.remove("c");
cout << map.count("c") << endl;
for (const auto& key : map.keys()){
cout << key << " ";
}
cout << endl;
system("pause");
return 0;
}成功的封装了一个 能够输出 插入顺序的 哈希表 ,
三.数组加强哈希表
前言:
这个解决了 哈希表本身不能++高效访问 随机元素++ ,还有记录插入数据顺序。
这时候就有读者有疑惑了,这个哈希表访问随机数有什么用啊,好像没有什么应用场景吧?
这么想就大错特错了,这个可以应用在
1. 需要"均匀随机"抽取元素的场景
如果你需要从一堆数据中公平地随机选出一个代表,标准哈希表做不到 O(1)O(1) 的均匀随机。
- 抽奖系统 :假设有一个在线用户池,你要从中随机抽一个幸运用户。如果用标准哈希表,你得先把所有 Key 导出来放到数组里再随机,每次抽奖都要 O(N)O(N),人多了会卡死。用
ArrayHashMap,每次抽奖都是 O(1)O(1)。- 游戏掉落:怪物死亡后,从它可能掉落的物品列表中随机选一个。如果这个列表动态变化(有的物品被移除),你需要高效的随机访问。
2. 随机化算法(Randomized Algorithms)
很多高级算法依赖"随机性"来避免最坏情况或提高平均性能。
- 快速排序的优化 :经典快排如果每次选第一个元素做基准(Pivot),在有序数组下会退化成 O(N2)O(N2)。为了保险,我们会随机选一个元素做 Pivot。如果数据存储在支持 O(1)O(1) 随机访问的结构中,这一步就非常高效。
- 随机采样(Reservoir Sampling) :在数据流中随机保留 kk 个样本。虽然流式算法有专门技巧,但如果数据是静态集合且频繁增删,
ArrayHashMap能支持高效的随机读取和删除。
我们要实现在一个有O(1)的时间复杂度 并且能够随机访问哈希表元素的算法
有的朋友会想到用 ctime 中的 srand()设置一个随机种子,然后 rand() % arr.size(),生成0---arr.size()的随机数
虽然这个方法能在O(1)内实现,但是它要求哈希表中不能有"空洞"(就是空余部分)。
比如说一个哈希表底层数组 arr = {0 , 1 , nul, 5, 6} 如果随机访问到 arr3 = null ,这个时候系统会随机生成一个数,要是生成的数是 0,1,5,6中的一个, 那你不就炸了吗?
直接寻址法和拉链法中不可避免的 会存在 "空洞" ,尤其是拉链法中
或者用线性一个个遍历,这个也不符合要求,这种算法的时间复杂度起码是O(N)。
那么我们应该怎么做呢?
很简单,在原有哈希表的基础上,我们可以额外创建一个数组,把哈希表里面的 "key" 全部存入到数组中,访问的时候:
cpp
#include<iostream>
#include<vector>
#include<unordered_map>
using namespace std;
class MyArrayHashmap{
vector<int> arr;
unordered_map<int,int> map;
void put(int key,int value){
if (map.find(key) == map.end()){
map[key] = value;
arr.push_back(key);
return ;
}
map[key] = value; // 改
}
int get(int key){
if (!map.count(key)){
return int();
}
return map[key];
}
int randomkey(){
return arr[rand() % arr.size()];
}//随机访问
void remove(){
}//删除
};在删除数据的时候,我们有没有能够不搬移arr数据(时间复杂度为O(N)),在时间复杂度O(1)的方法呢?
我们可以把 要删除的数据 "交换" 到 数组末尾,在数组末尾删除的数据 时间复杂度为O(1)
例子:
array = { 1 , 2 ,3 , 4 ,5} , 要删除2 --- 这里的交换是值交换 ,这样时间复杂度就是O(1)
之后 array = { 1 , 5 ,3 , 4 , 2} ,直接把2删除,此时时间复杂度是O(1)
• 代码实现
1.初始化
这个完整代码中,arr数组不止储存 key ,储存的是 key---value 对,
cpp
#include<iostream>
#include<vector>
#include<unordered_map>
#include<string>
#include<random>
using namespace std;
template<typename K, typename V>
class Myarray_hashmap{
struct Node{
K key;
V val;
Node(K key, V val) : key(key) , val(val){ };
};
//int是储存在数组中索引
unordered_map<K,int> map;
vector<Node> arr; // 储存key-value
//随机数生成器
default_random_engine e;
public:
Myarray_hashmap(){
random_device rd;
e.seed(rd());
}哈希表中储存的是 key----数组下标
可能有读者会疑问: 为什么链表加强的时候,为什么不像数组一样,哈希表不直接储存
key -- value ,为什么在 Node 中还要 初始化为 (key,value)?
Node结构体中储存key和value,++是为了在链表中查询的时候,能够找到++
如果没有那个key ,而且value存在重复的情况,你应该怎么区分?
同理在数组也是一样的,你在Node中如果只储存value,不储存key,那么在删除数组元素的时候,你是爽了。但是哈希表逻辑删除的时候,没有key对应,怎么寻找它在哈希表的下标呢?
这个random库后续我会更新(第三个坑了,呜呜呜,属于是越学越多,越发现自己的无知).
• 增删改查
cpp
V get(K key){
if (!map.count(key)){
return V();
}//没有就返回NULL
int index = map[key]; // 数组下标
return arr[index].val;
}
void put(K key, V val){
if (containkey(key)){
int i = map[key];
arr[i].val = val;
return ;
}
arr.push_back(Node(key,val));
map[key] = arr.size()-1;//计入下标
}
void remove(K key){
if (!map.count(key)){
return ;
}
int index = map[key];
Node node = arr[index];
Node temp = arr.back();//把node和back换位置
swap(arr[index],arr.back());
map[temp.key] = index;
arr.pop_back();//删除换位
map.erase(node.key);
}增加的时候, 先在哈希表里加入 "key" ,还有数组对应的下标。 之后,在数组中添加key--value
查: 查的是val值,通过哈希表知道对应元素的数组下标,就可以直接访问
删: 先数组元素换位----这一步保证在尾部删除 O(1)时间复杂度。 然后 , 不要忘记先更改 "原尾部数组元素的哈希表下标" ,先后删除 数组尾部元素与哈希表对应key( stl总结中提到 哈希表erase是按 key来删除)
• 工具函数
cpp
K randomKey(){
if (arr.empty()) return K();
int n = arr.size();
uniform_int_distribution<int> u(0,n-1);
int randomIndex = u(e);
return arr[randomIndex].key;
}//这一步我回头学明白了再讲解
bool containkey(K key){
return map.count(key);
}//数组中储存的是结构体
int size(){
return map.size();
}
vector<Node> array()const{
return arr;;
}randomKey 随机返回 key 值
• 测试:
cpp
int main(){
Myarray_hashmap<string,int> map;
map.put("a",1);
map.put("b",2);
map.put("c",4);
map.put("d",5);
for (auto &node : map.array()){
cout << node.key << ":" << node.val << endl;
}
cout << "------" << endl;
cout << map.get("a") << endl;
cout << map.randomKey() << endl;
map.remove("a");
for (auto &node : map.array()){
cout << node.key << ":" << node.val << endl;
}
cout << "-------" << endl;
cout << map.randomKey() << endl;
cout << map.randomKey() << endl;
system("pause");
return 0;
}完整的看一遍:
cpp
#include<iostream>
#include<vector>
#include<unordered_map>
#include<string>
#include<random>
using namespace std;
template<typename K, typename V>
class Myarray_hashmap{
struct Node{
K key;
V val;
Node(K key, V val) : key(key) , val(val){ };
};
//int是储存在数组中索引
unordered_map<K,int> map;
vector<Node> arr; // 储存key-value
//随机数生成器
default_random_engine e;
public:
Myarray_hashmap(){
random_device rd;
e.seed(rd());
}
V get(K key){
if (!map.count(key)){
return V();
}//没有就返回NULL
int index = map[key]; // 数组下标
return arr[index].val;
}
void put(K key, V val){
if (containkey(key)){
int i = map[key];
arr[i].val = val;
return ;
}
arr.push_back(Node(key,val));
map[key] = arr.size()-1;//计入下标
}
void remove(K key){
if (!map.count(key)){
return ;
}
int index = map[key];
Node node = arr[index];
Node temp = arr.back();//把node和back换位置
swap(arr[index],arr.back());
map[temp.key] = index;
arr.pop_back();//删除换位
map.erase(node.key);
}
K randomKey(){
if (arr.empty()) return K();
int n = arr.size();
uniform_int_distribution<int> u(0,n-1);
int randomIndex = u(e);
return arr[randomIndex].key;
}//这一步我回头学明白了再讲解
bool containkey(K key){
return map.count(key);
}//数组中储存的是结构体
int size(){
return map.size();
}
vector<Node> array()const{
return arr;;
}
};
int main(){
Myarray_hashmap<string,int> map;
map.put("a",1);
map.put("b",2);
map.put("c",4);
map.put("d",5);
for (auto &node : map.array()){
cout << node.key << ":" << node.val << endl;
}
cout << "------" << endl;
cout << map.get("a") << endl;
cout << map.randomKey() << endl;
map.remove("a");
for (auto &node : map.array()){
cout << node.key << ":" << node.val << endl;
}
cout << "-------" << endl;
cout << map.randomKey() << endl;
cout << map.randomKey() << endl;
system("pause");
return 0;
}四.总结
不管是链表强化哈希表,还是数组强化哈希表 都是 能够实现 "查找插入顺序的功能"
数组强化哈希表 能够在O(1)时间复杂度下 实现返回 "随机值"----随机赌博系统 , "抽卡" maybe
---因为链表无法像数组一样 快速访问下标,需要遍历O(N)。
如果喜欢我的文章的话,请给我一个免费的赞和收藏,你们的支持都是我前进的动力。
关注之后,可以及时看到我发布的新文章哦 ,我会努力填坑的。