TL;DR
- 场景:基于Flink流处理引擎,将Kafka主题中的业务数据实时写入HBase维度表
- 结论:通过Flink RichSinkFunction实现Kafka到HBase的流式写入,支持insert/update/delete三种操作类型
- 产出:完整Scala源码(TableObject、AreaInfo、DataInfo、SinkHBase、SourceKafka),可直接复用

版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| Kafka消费者订阅 | ✅ 已验证 | FlinkKafkaConsumer消费dwshow主题 |
| JSON消息解析 | ✅ 已验证 | FastJSON解析database/table/type/data字段 |
| HBase连接管理 | ✅ 已验证 | ConnectionFactory创建连接,RichSinkFunction生命周期管理 |
| 维度表写入 | ✅ 已验证 | AreaInfo和DataInfo写入wzk_area和wzk_trade_orders表 |
| Insert操作 | ✅ 已验证 | Put写入新记录 |
| Update操作 | ✅ 已验证 | 同一rowkey执行Put覆盖 |
| Delete操作 | ✅ 已验证 | Delete删除指定记录 |
| 表自动创建 | ✅ 已验证 | createTableIfNotExists检查并创建HBase表 |
基本介绍
在 Kafka 中写入维度表(DIM)通常涉及将实时或批处理数据从 Kafka 主题(Topic)读取,并根据数据流中的信息更新维度表(DIM),这在数据仓库或数据湖的 ETL(提取、转换、加载)过程中非常常见。维度表(DIM)存储的是与业务数据相关的维度信息,例如客户、产品、地理位置等,用于支持 OLAP(联机分析处理)查询。
理解 Kafka 数据流
Kafka 是一个分布式流平台,用于高吞吐量的消息传递。在 ETL 过程中,Kafka 通常用作数据的消息队列或者流处理的来源。每当新数据生成时,它会被发布到 Kafka 中的某个主题(Topic),然后消费者(Consumer)可以从主题中获取数据进行处理。
设计维度表(DIM)
维度表通常包含业务实体的详细信息,如产品名称、客户信息、时间维度等。与事实表(Fact)不同,维度表的数据较为静态,但可能会随着时间更新(例如,客户地址变更或产品类别更新)。每个维度表通常有一个唯一的主键(如 customer_id 或 product_id)来标识记录。
Kafka 消费者(Consumer)
为了从 Kafka 中读取维度数据,需要创建一个消费者(Consumer),它会从 Kafka 的某个主题(Topic)中读取消息。这些消息通常是 JSON 格式,包含需要写入维度表的信息。消费者将从 Kafka 主题中获取数据,可能包括以下步骤:
- 连接到 Kafka 集群。
- 订阅一个或多个主题(Topics)。
- 消费消息并将其传递给后续的处理逻辑。
- 消费者的实现可以使用 Kafka 提供的客户端库,例如 Kafka 的 Java 客户端、Python 的 confluent-kafka 等。
数据处理和转换
在读取到 Kafka 消息后,消费者需要对数据进行必要的处理和转换。对于维度数据,处理逻辑可能包括:
- 数据解析:将消息从 Kafka 中的格式(例如 JSON)解析成结构化数据。
- 校验数据:检查数据是否符合业务规则,是否完整,是否有效。
- 维度数据更新:如果 Kafka 中的消息包含的维度信息已经存在,则更新相关记录;如果是新维度,则插入新记录。
维度表的更新
维度表的更新通常有两种常见的方式:
- 全量更新:每次从 Kafka 获取到新的数据时,都将其覆盖到维度表中。这种方式适用于数据变动较少或者可以接受重写的场景。
- 增量更新:根据时间戳、有效性标志或版本号等信息,更新已有的维度记录。这种方式适用于数据会有更新(如地址或状态变更)的场 景。
增量更新时,通常会执行以下操作:
- 查找是否已有该维度记录(例如通过 dimension_id)。
- 如果存在且数据发生变化,则更新该记录,同时更新 valid_to 时间,并插入一条新的记录,设置 valid_from 和 valid_to 时间。
- 如果不存在该记录,则直接插入新的维度数据。
写入到目标存储(DIM)
在数据处理后,需要将更新后的维度数据写入目标存储。这通常是一个数据库(例如 MySQL、PostgreSQL 或 NoSQL 数据库)或数据仓库(例如 Snowflake、Google BigQuery、Redshift)中的维度表(DIM)。
数据存储更新(事务性考虑)
对于维度表的更新,通常需要确保数据的一致性。可以使用事务来确保数据在更新过程中的一致性,防止数据丢失或重复。例如,可以在事务中执行所有的更新和插入操作,确保如果操作失败,可以回滚。
TableObject
创建样例 TableObject
scala
case class TableObject(database: String, tableName: String, typeInfo: String, dataInfo: String) extends SerializableAreaInfo
scala
case class AreaInfo(
id: String,
name: String,
pid: String,
sname: String,
level: String,
citycode: String,
yzcode: String,
mername: String,
Lng: String,
Lat: String,
pinyin: String
)DataInfo
scala
case class DataInfo(
modifiedTime: String,
orderNo: String,
isPay: String,
orderId: String,
tradeSrc: String,
payTime: String,
productMoney: String,
totalMoney: String,
dataFlag: String,
userId: String,
areaId: String,
createTime: String,
payMethod: String,
isRefund: String,
tradeType: String,
status: String
)ConnHBase
scala
class ConnHBase {
def connToHbase:Connection ={
val conf : Configuration = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","h121.wzk.icu,h122.wzk.icu,h123.wzk.icu")
conf.set("hbase.zookeeper.property.clientPort","2181")
conf.setInt(HConstants.HBASE_CLIENT_OPERATION_TIMEOUT,30000)
conf.setInt(HConstants.HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD,30000)
val connection = ConnectionFactory.createConnection(conf)
connection
}
}SinkHBase
scala
class SinkHBase extends RichSinkFunction[util.ArrayList[TableObject]] {
var connection : Connection = _
var hbTable : Table = _
override def open(parameters: Configuration): Unit = {
connection = new ConnHBase().connToHbase
hbTable = connection.getTable(TableName.valueOf("wzk_area"))
}
override def close(): Unit = {
if (hbTable != null) {
hbTable.close()
}
if (connection != null) {
connection.close()
}
}
override def invoke(value: util.ArrayList[TableObject], context: SinkFunction.Context[_]): Unit = {
value.forEach(x => {
println(x.toString)
val database: String = x.database
val tableName: String = x.tableName
val typeInfo: String = x.typeInfo
if ((database.equalsIgnoreCase("dwshow") && tableName.equalsIgnoreCase("wzk_trade_orders"))) {
if (typeInfo.equalsIgnoreCase("insert")) {
value.forEach(x => {
val info: DataInfo = JSON.parseObject(x.dataInfo, classOf[DataInfo])
insertTradeOrders(hbTable, info)
})
} else if (typeInfo.equalsIgnoreCase("update")) {
} else if (typeInfo.equalsIgnoreCase("delete")) {
}
}
if (database.equalsIgnoreCase("dwshow") && tableName.equalsIgnoreCase("wzk_area")) {
if (typeInfo.equalsIgnoreCase("insert")) {
value.forEach(x => {
val info: AreaInfo = JSON.parseObject(x.dataInfo, classOf[AreaInfo])
insertArea(hbTable, info)
})
} else if (typeInfo.equalsIgnoreCase("update")) {
value.forEach(x => {
val info: AreaInfo = JSON.parseObject(x.dataInfo, classOf[AreaInfo])
insertArea(hbTable, info)
})
} else if (typeInfo.equalsIgnoreCase("delete")) {
value.forEach(x => {
val info: AreaInfo = JSON.parseObject(x.dataInfo, classOf[AreaInfo])
deleteArea(hbTable, info)
})
}
}
})
}
def insertTradeOrders(hbTable: Table, dataInfo: DataInfo): Unit = {
val tableName = "wzk_trade_orders"
val columnFamily = "f1"
// 如果表不存在则创建
createTableIfNotExists(connection, tableName, columnFamily)
val put = new Put(dataInfo.orderId.getBytes)
put.addColumn("f1".getBytes, "modifiedTime".getBytes, dataInfo.modifiedTime.getBytes())
put.addColumn("f1".getBytes, "orderNo".getBytes, dataInfo.orderNo.getBytes())
put.addColumn("f1".getBytes, "isPay".getBytes, dataInfo.isPay.getBytes())
put.addColumn("f1".getBytes, "orderId".getBytes, dataInfo.orderId.getBytes())
put.addColumn("f1".getBytes, "tradeSrc".getBytes, dataInfo.tradeSrc.getBytes())
put.addColumn("f1".getBytes, "payTime".getBytes, dataInfo.payTime.getBytes())
put.addColumn("f1".getBytes, "productMoney".getBytes, dataInfo.productMoney.getBytes())
put.addColumn("f1".getBytes, "totalMoney".getBytes, dataInfo.totalMoney.getBytes())
put.addColumn("f1".getBytes, "dataFlag".getBytes, dataInfo.dataFlag.getBytes())
put.addColumn("f1".getBytes, "userId".getBytes, dataInfo.userId.getBytes())
put.addColumn("f1".getBytes, "areaId".getBytes, dataInfo.areaId.getBytes())
put.addColumn("f1".getBytes, "createTime".getBytes, dataInfo.createTime.getBytes())
put.addColumn("f1".getBytes, "payMethod".getBytes, dataInfo.payMethod.getBytes())
put.addColumn("f1".getBytes, "isRefund".getBytes, dataInfo.isRefund.getBytes())
put.addColumn("f1".getBytes, "tradeType".getBytes, dataInfo.tradeType.getBytes())
put.addColumn("f1".getBytes, "status".getBytes, dataInfo.status.getBytes())
hbTable.put(put)
}
def insertArea(hbTable: Table, areaInfo: AreaInfo): Unit = {
// val tableName = "wzk_area"
// val columnFamily = "f1"
// 如果表不存在则创建
// createTableIfNotExists(connection, tableName, columnFamily)
println(areaInfo.toString)
val put = new Put(areaInfo.id.getBytes())
put.addColumn("f1".getBytes(), "name".getBytes(), areaInfo.name.getBytes())
put.addColumn("f1".getBytes(), "pid".getBytes(), areaInfo.pid.getBytes())
put.addColumn("f1".getBytes(), "sname".getBytes(), areaInfo.sname.getBytes())
put.addColumn("f1".getBytes(), "level".getBytes(), areaInfo.level.getBytes())
put.addColumn("f1".getBytes(), "citycode".getBytes(), areaInfo.citycode.getBytes())
put.addColumn("f1".getBytes(), "yzcode".getBytes(), areaInfo.yzcode.getBytes())
put.addColumn("f1".getBytes(), "mername".getBytes(), areaInfo.mername.getBytes())
put.addColumn("f1".getBytes(), "lng".getBytes(), areaInfo.Lng.getBytes())
put.addColumn("f1".getBytes(), "lat".getBytes(), areaInfo.Lat.getBytes())
put.addColumn("f1".getBytes(), "pinyin".getBytes(), areaInfo.pinyin.getBytes())
hbTable.put(put)
}
def deleteArea(hbTable: Table, areaInfo: AreaInfo): Unit = {
val delete = new Delete(areaInfo.id.getBytes)
hbTable.delete(delete)
}
def createTableIfNotExists(connection: Connection, tableName: String, columnFamily: String): Unit = {
val admin = connection.getAdmin
try {
val table = TableName.valueOf(tableName)
// 检查表是否存在
if (!admin.tableExists(table)) {
val tableDescriptor = new HTableDescriptor(table)
val columnDescriptor = new HColumnDescriptor(columnFamily.getBytes())
tableDescriptor.addFamily(columnDescriptor)
// 创建表
admin.createTable(tableDescriptor)
println(s"表 $tableName 创建成功")
} else {
println(s"表 $tableName 已存在")
}
} finally {
admin.close()
}
}
}SourceKafka
scala
class SourceKafka {
def getKafkaSource(topicName: String) : FlinkKafkaConsumer[String] = {
val props = new Properties()
props.setProperty("bootstrap.servers", "h121.wzk.icu:9092")
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
props.setProperty("group.id", "hbase-test")
props.setProperty("auto.offset.reset", "earliest")
new FlinkKafkaConsumer[String](topicName, new SimpleStringSchema(), props)
}
}KafkaToHBase
scala
object KafkaToHBase {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val kafkaConsumer = new SourceKafka().getKafkaSource("dwshow")
kafkaConsumer.setStartFromLatest()
val sourceStream = env.addSource(kafkaConsumer)
val mapped: DataStream[util.ArrayList[TableObject]] = sourceStream.map(x => {
val jsonObj: JSONObject = JSON.parseObject(x)
val database: AnyRef = jsonObj.get("database")
val table: AnyRef = jsonObj.get("table")
val typeInfo: AnyRef = jsonObj.get("type")
val objects = new util.ArrayList[TableObject]()
jsonObj.getJSONArray("data").forEach(x => {
objects.add(TableObject(database.toString, table.toString, typeInfo.toString, x.toString))
println(x.toString)
})
objects
})
mapped.addSink(new SinkHBase)
env.execute()
}
}启动项目
我们对表进行修改:
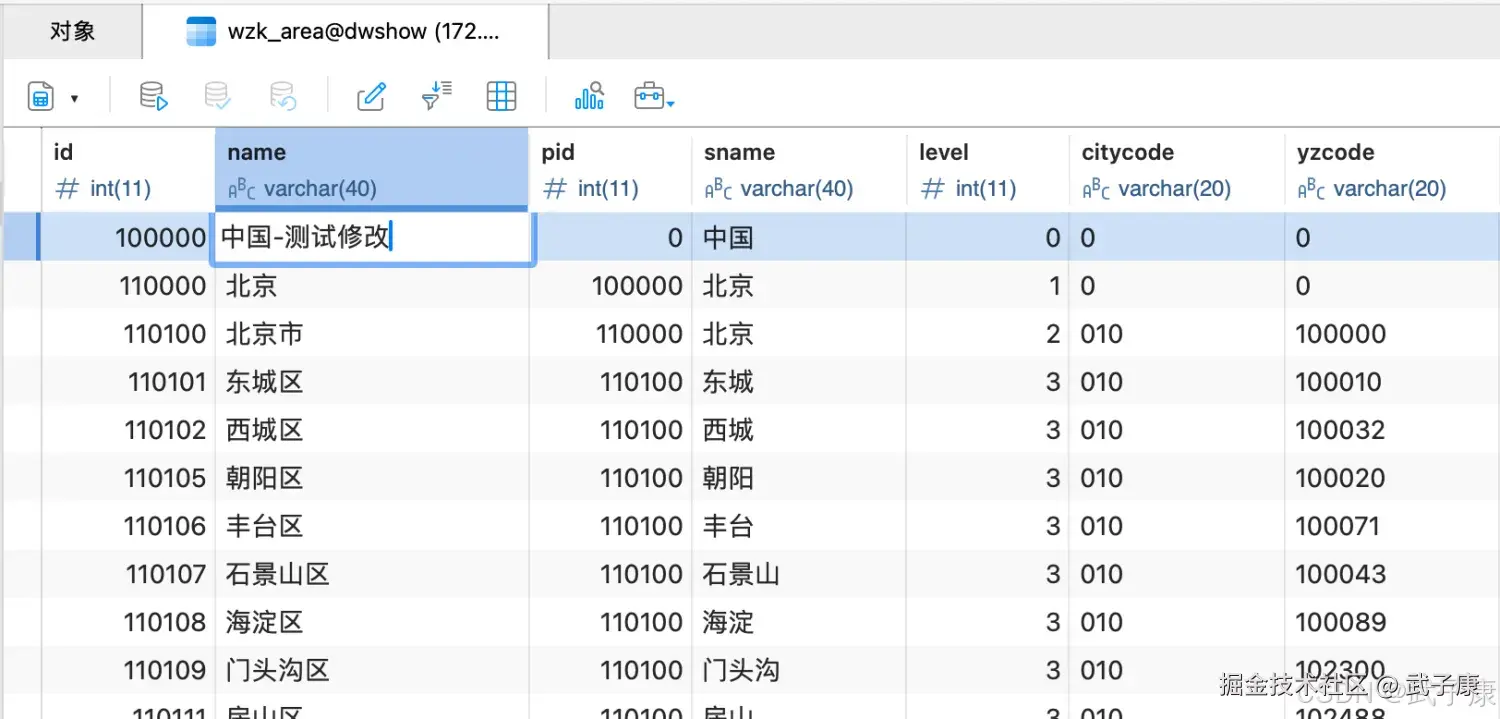
可以看到控制台对饮输出了内容:
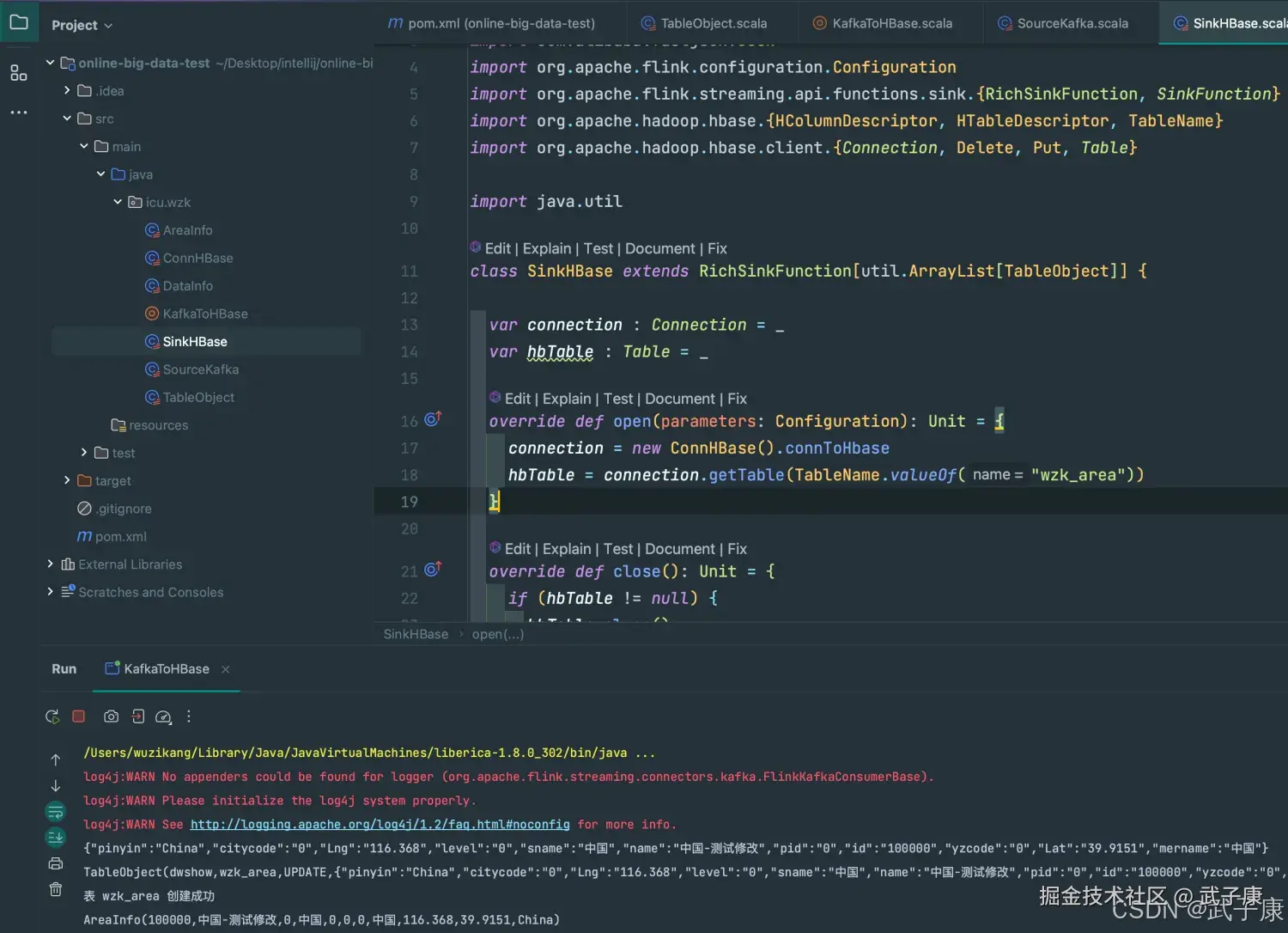
别的表也尝试修改一下:

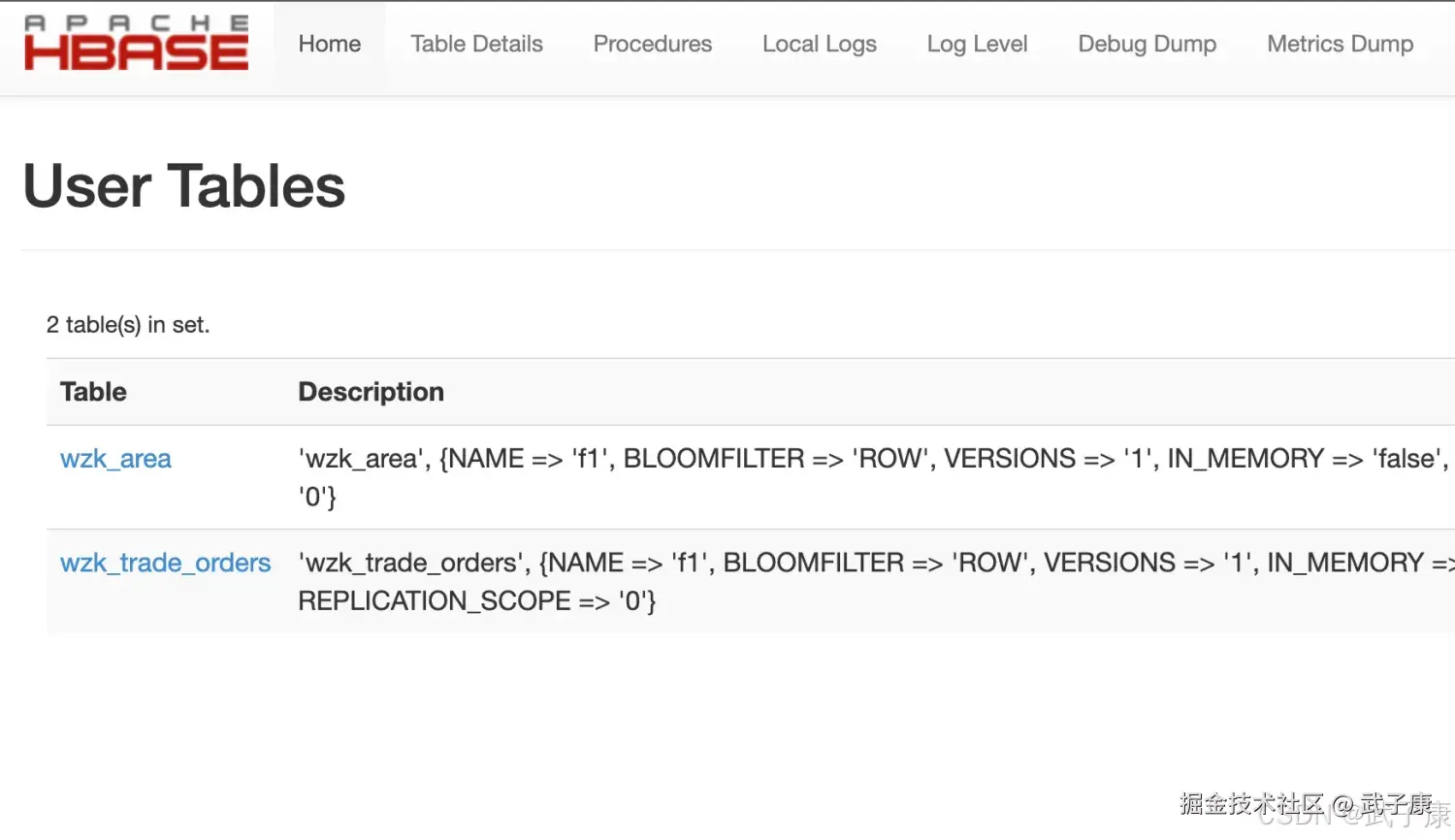
查看 HBase 可以看到数据已经有了:
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| HBase连接超时 | zookeeper.quorum配置错误或网络不通 | 检查conf.set("hbase.zookeeper.quorum")地址是否正确 | 确认ZK集群地址可达,端口2181开放 |
| 数据写入后查询不到 | rowkey冲突导致覆盖 | 检查Put使用的rowkey是否重复 | 确保rowkey唯一,或使用增量更新策略 |
| 表不存在异常 | createTableIfNotExists未被调用或表名错误 | 确认表名大小写与HBase中一致 | 先手动创建表或确保createTableIfNotExists执行 |
| Kafka消费延迟 | Flink checkpoint间隔过长或并行度不足 | 观察Flink UI中消费位点 | 调整checkpoint间隔,增加kafka分区数 |
| JSON解析异常 | 消息格式与case class不匹配 | 检查JSON字段名与DataInfo/AreaInfo定义 | 确保Kafka消息schema与解析类一致 |