
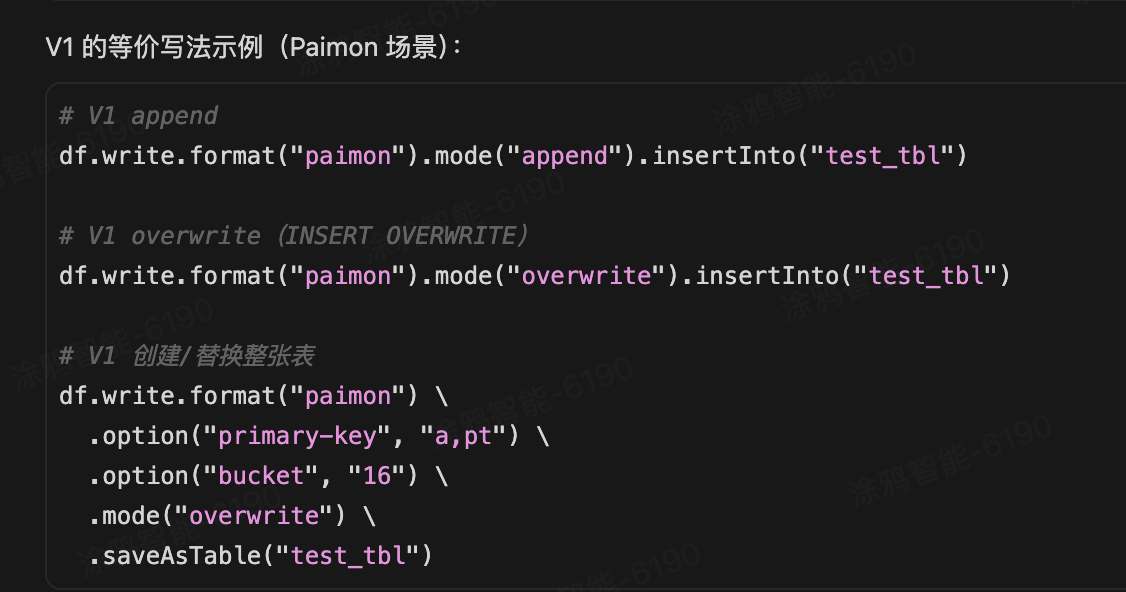
5种写入动作
spark新接口 DataSource V2:
介绍:
df.writeTo(...) 返回的是 DataFrameWriterV2,是 Spark 3.x 引入的 DataSource V2 写接口,与旧的 df.write (DataFrameWriter V1) 是两套完全不同的 API
案例:
df.writeTo("paimon.bi_dwd.tb1") \
.using("paimon") \
.replace()
api 区别:
.create()
等价 SQL:CREATE TABLE ... AS SELECT ...(CTAS)
表不存在:建表 + 写数据
表已存在:抛异常
.createOrReplace()
等价 SQL:CREATE OR REPLACE TABLE ... AS SELECT ...
表不存在:建表 + 写数据
表已存在:先 DROP 再 CREATE,相当于完整重建表并写入新数据
注意:会丢失原表所有数据及表结构定义,适合每次全量刷新场景
.replace()
等价 SQL:REPLACE TABLE ... AS SELECT ...
表不存在:抛异常
表已存在:DROP + CREATE 重建写入
.append()
等价 SQL:INSERT INTO ...
向已有表追加数据(INSERT INTO 语义)
表不存在会报错,不会自动建表
不支持 .using() / .tableProperty()(表已存在,无需配置)
.overwritePartitions()
等价 SQL:INSERT OVERWRITE ...(动态分区模式)
覆盖 DataFrame 中涉及到的分区,其他分区数据保留
相当于 spark.sql.sources.partitionOverwriteMode=dynamic 的 INSERT OVERWRITE接口对比

案例
动态覆盖的分区表 且表可能不存在
python
writer = (
df_sink.writeTo("paimon.db1.tb1")
.using("paimon")
.tableProperty("bucket", "16")
.tableProperty("bucket-key", "uid")
.partitionedBy("dt")
)
try:
writer.overwritePartitions()
except Exception:
# 表不存在时 overwritePartitions 会抛异常,改用 create
writer.create()