文章目录
-
- 引言:一个根本性问题
- [一、 认知框架:异常检测的两种世界观](#一、 认知框架:异常检测的两种世界观)
- [二、 统计与分布方法:用数学模型定义常态](#二、 统计与分布方法:用数学模型定义常态)
-
- [1. 3σ 原则/Z-Score:正态分布作为"标准模具"](#1. 3σ 原则/Z-Score:正态分布作为“标准模具”)
- [2. 箱线图法:让数据自己定义身体](#2. 箱线图法:让数据自己定义身体)
- [三、 基于距离/密度的方法:用邻近关系定义常态](#三、 基于距离/密度的方法:用邻近关系定义常态)
-
- [1. KNN(K 近邻):社交网络中的"孤僻者"](#1. KNN(K 近邻):社交网络中的“孤僻者”)
- [2. LOF(局部离群因子):群体中的"格格不入者"](#2. LOF(局部离群因子):群体中的“格格不入者”)
- [四、 综合对比与选择指南](#四、 综合对比与选择指南)
- 结语:从算法回到问题
引言:一个根本性问题
"什么是正常,什么又是异常?"
这不仅是数据分析师面对一堆数据点时的疑问,在某种程度上,也是一个哲学命题。在机器的世界里,异常检测 的本质,就是为这个模糊的命题赋予可计算、可操作的答案。其目标简洁而深刻:在看似规律的海量数据中,自动识别那些显著偏离预期模式、行为或结构的罕见实例。
本文将以一种自上而下的方式,从异常检测的"第一性原理"出发,逐步拆解其核心思想,并依据经典分类框架,深入对比主流算法,旨在构建一个既见森林、又见树木的清晰认知。
一、 认知框架:异常检测的两种世界观
所有异常检测算法,都围绕着同一个核心任务展开:**建立"正常"的模型,并据此定义"异常"**。而方法的根本分野,始于对"何为正常"这一基础问题的不同回答。
我们可以用一个统一的"模型-残差"框架来理解所有方法:
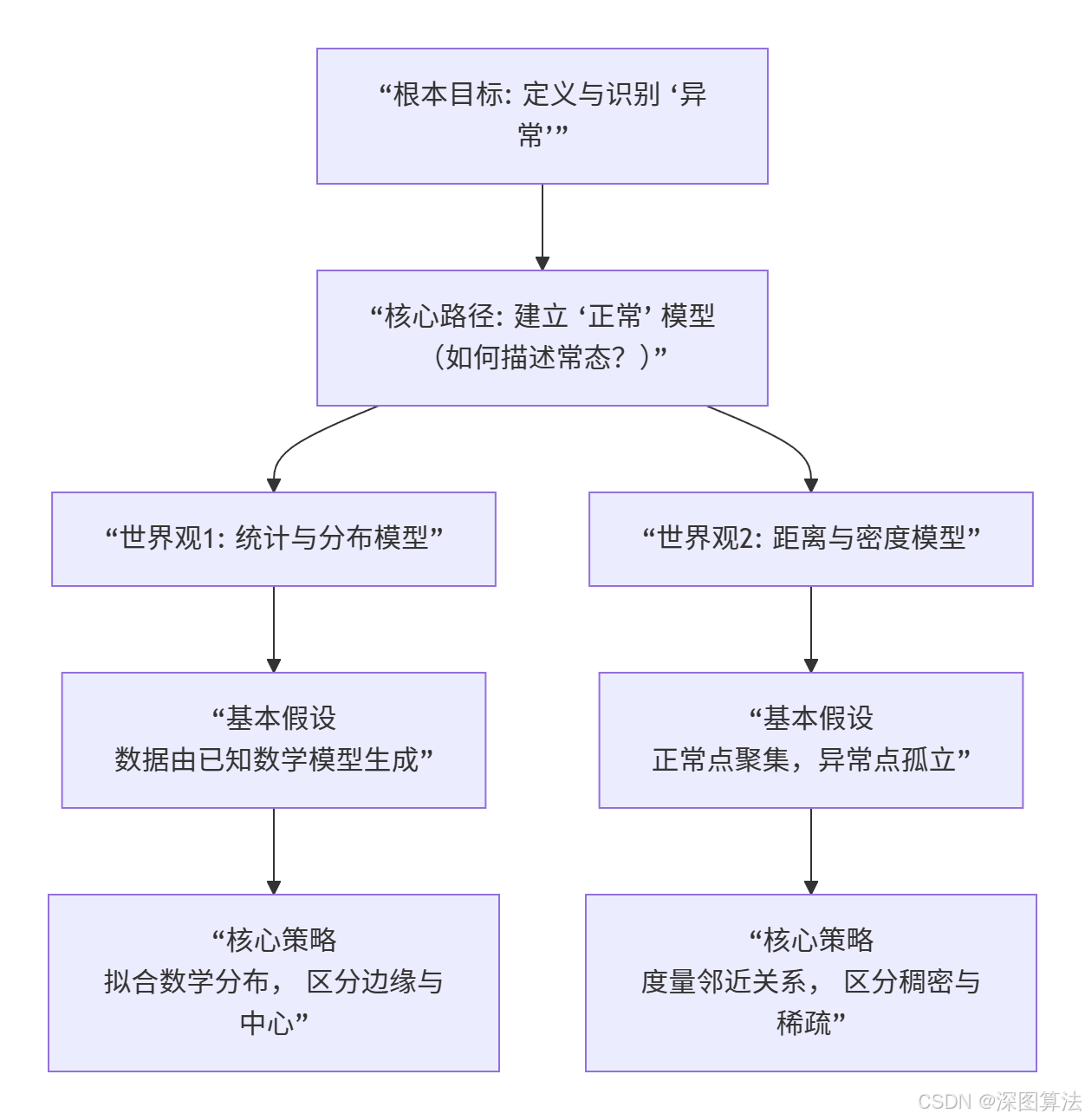
上图揭示了两大流派的核心差异。接下来,我们将深入每一分支,探究其具体实现。
二、 统计与分布方法:用数学模型定义常态
第一性原理 :"正常"世界是稳定且有规律的,可以用一个已知的数学模型(如正态分布)精确描述。任何严重偏离这个模型"中心"或"主体"的数据,都是需要被检视的异常。
这类方法从上帝视角,为整个数据集预设了一个理想的结构框架。
1. 3σ 原则/Z-Score:正态分布作为"标准模具"
-
核心思想可视化:
正态分布曲线如同一个"标准模具"。 正常数据应完美填充模具主体[μ-3σ, μ+3σ]。 落在模具边缘之外(如左侧尾部)的数据点,因无法被"模型"容纳而被视为异常。 -
第一性原理拆解:
- 根本假设 :数据生成过程严格遵循正态分布。这是该方法有效性的基石。
- 正常模型:以均值(μ)为对称中心,标准差(σ)描述扩散程度的钟形曲线。
- 异常定义:在概率意义上极不可能发生的事件,即落在分布尾端(通常为 μ±3σ 以外,涵盖 99.73% 数据)的数据点。
-
优劣与场景:
-
优点:极度简单、高效、可解释性极强。均值与标准差即为模型的全部参数。
-
局限:
- 假设脆弱:现实数据常偏离正态,强假设不成立时效果差。
- 全局污染:异常点自身会"污染"均值与标准差的计算,导致模型失真(掩蔽效应)。
-
适用 :数据确信符合或近似正态分布,且需快速初步筛查。
-
2. 箱线图法:让数据自己定义身体
-
核心思想可视化:
将数据按大小排序,将其想象成一个"人体"。 Q1(下四分位数)到Q3(上四分位数)是"躯干"(IQR)。 1.5倍IQR的长度是"手臂"的合理延伸范围。 落在手臂范围之外的点,如同脱离身体的异物,被定义为异常。 -
第一性原理拆解:
- 根本假设 :放弃 对数据具体分布形态的先验假设,是一种非参数方法。
- 正常模型 :用数据自身的分位数(Q1, Q3)来定义"主体"范围。IQR(Q3-Q1)描述了数据的密集程度。
- 异常定义:远离数据主体密集区域的"离群"点,其距离超过主体范围(IQR)的 1.5 倍(一个经验系数)。
-
优劣与场景:
- 优点:稳健,不受极端值影响,不依赖分布假设,结果直观可视。
- 局限:判断标准相对固定、粗糙,对微妙异常不敏感。
- 适用 :探索性数据分析的首选,尤其在数据分布未知、存在偏态时。
小结 :统计与分布方法是模型驱动 的。它们试图用一个简洁的数学或统计模型来概括"正常",优点在于快速、直观、可解释 ,但代价是对模型假设的强依赖。
三、 基于距离/密度的方法:用邻近关系定义常态
第一性原理 :"正常"的点彼此相似、聚集。异常点则与大多数点不同,表现为"远离"群体或在局部区域"形单影只"。
这类方法不预设全局模型,转而从数据点之间的局部关系中涌现出对正常的认知。
1. KNN(K 近邻):社交网络中的"孤僻者"
-
核心思想可视化:
将数据点视为一个社交网络中的人。 计算每个人到其K个最近朋友的平均距离。 一个"正常"的人,身边总有一些朋友(平均距离近)。 一个"异常"的人,则离所有人都很远(平均距离远),像一个孤僻者。 -
第一性原理拆解:
- 根本假设:正常点处于密集区域,与邻居亲近;异常点远离任何密集区域。
- 正常模型 :邻居的平均距离。一个点的"正常程度"由其到 K 个最近邻居的距离平均值衡量。
- 异常定义 :拥有最大 K 近邻平均距离的点。
-
优劣与场景:
-
优点:概念直观,无需分布假设,可处理复杂形状的多维数据。
-
局限:
- 计算代价高:需计算所有点对距离,复杂度为 O(n²)。
- 距离失效:在高维空间中,所有点距离趋于相似,区分度下降(维度灾难)。
-
适用:数据集规模适中、维度不高,异常表现为"全局孤立点"。
-
2. LOF(局部离群因子):群体中的"格格不入者"
-
核心思想可视化:
在一个密度不均的聚会中(如吧台拥挤,散台稀疏)。 在散台区,一个人离其他人几米远可能"还算正常"(局部密度低)。 在拥挤的吧台,一个人与最近者保持一米距离就显得"非常异常"(局部密度高)。 LOF检测的正是这种相对于**所处局部环境**的异常。 -
第一性原理拆解:
- 根本假设 :数据的密度是变化的。异常是相对 于其局部邻域而言的。
- 正常模型 :局部可达密度。通过比较一个点的密度与其 K 个邻居的密度来建模。
- 异常定义 :一个点的密度显著低于其大部分邻居的密度。LOF 值 >> 1 表示异常。
-
优劣与场景:
- 优点 :能捕捉局部异常,是 KNN 的"智能化"升级,适用于密度不均匀的数据集。
- 局限:计算复杂度更高,对参数(近邻数 K)更敏感。
- 适用 :数据中存在多个密度不同的簇,且异常点可能隐藏在某个看似不孤立的区域(如稀疏簇中的稍密点,或密集簇中的稀疏点)。
小结 :距离/密度方法是数据驱动 的。它们从数据本身的几何或拓扑结构中学习"正常",优点在于更通用、能发现复杂异常 ,但代价是计算成本高、需调参、可解释性相对较弱。
四、 综合对比与选择指南
基于以上分析,我们可以从第一性原理的视角,对这两大流派进行终极对垒:
| 比较维度 | 统计与分布方法 | 基于距离/密度的方法 |
|---|---|---|
| 哲学根基 | 模型先验:世界服从某个已知数学形式。 | 关系先验:物以类聚,异常孤立。 |
| 核心操作 | 拟合参数,计算偏差。 | 计算距离,比较密度。 |
| 计算效率 | 高(O(n)或更低) | 低(通常 ≥O(n²)) |
| 假设强弱 | 强假设(依赖特定分布) | 弱假设(仅依赖距离/密度概念) |
| 多变量处理 | 弱(常需独立处理或强假设) | 强(直接处理多维空间点) |
| 异常类型 | 主要检测全局异常 | 可检测全局 与局部异常(尤其 LOF) |
| 结果解释 | 非常直观("它落在 3σ 以外") | 相对直观("它离大家太远/这里就它最稀疏") |
如何选择?------ 回归第一性思考
-
审视数据本质:
- 如果你的数据有明显的理论分布(如测量误差近正态),或你对"正常"有明确的统计定义,从统计方法开始。
- 如果你的数据是多维的、结构未知、且你相信"异常就是离群点",距离/密度方法是更安全的选择。
-
明确异常定义:
- 你想找的是偏离整体平均的"极端值"吗?选统计方法。
- 你想找的是在任何局部环境中都显得"格格不入"的点吗?选LOF。
-
权衡约束条件:
- 速度与可解释性至上 :选箱线图 (通用)或3σ 原则(若正态)。
- 精度与复杂性容忍 :选LOF (密度不均)或KNN(全局孤立)。
结语:从算法回到问题
异常检测的旅程,始于对"正常"与"异常"的本质追问。我们看到了两种回答:
一种是用一个简洁的数学模型 去规定正常,另一种是用数据点间的邻近关系去涌现正常。
没有放之四海而皆准的"最佳算法",只有与数据本质及问题定义最契合的思想。统计方法以其简洁和深刻,在满足假设时展现出强大力量;距离密度方法则以其灵活与通用,应对着复杂多变的世界。
理解它们的第一性原理,不是为了记住公式,而是为了在面临新的异常检测任务时,能够穿透技术表象,直指问题核心,做出那个最根本、也最明智的选择。这,便是自上而下思考的魅力所在。