gaussian-splatting
摘要:3D高斯 splatting(GS)已成为显式辐射场和计算机图形学领域的一种变革性技术。这种创新方法的特点是使用数百万个可学习的3D高斯,它与主流神经辐射场方法有显著区别------后者主要使用基于坐标的隐式模型将空间坐标映射到像素值。3D GS凭借其显式场景表示和可微渲染算法 ,不仅有望实现实时渲染能力,还引入了前所未有的可编辑性水平。这使得3D GS成为下一代3D重建和表示领域的潜在游戏规则改变者。在本文中,我们首次系统概述了3D GS领域的最新发展和关键贡献。我们首先详细探讨3D GS的基本原理及其兴起的驱动力,为理解其重要性奠定基础。我们讨论的一个重点是3D GS的实际适用性。通过实现前所未有的渲染速度,3D GS开辟了从虚拟现实到互动媒体等众多应用场景。此外,我们还对领先的3D GS模型进行了对比分析,通过各种基准任务对其进行评估,以突出它们的性能和实用价值。本综述最后指出了当前面临的挑战,并提出了未来研究的潜在方向。通过本次综述,我们旨在为新手和资深研究人员提供有价值的资源,以促进显式辐射场领域的进一步探索和发展。
关键词:3D高斯 splatting、显式辐射场、实时渲染、场景理解
2401.03890 A Survey on 3D Gaussian Splatting(原文)
机器学习+CG+线性代数+GPU性能编程
splatting:


体素:
体素:体素是三维空间中的体积像素的简称。它类似于二维图像中的像素,但在三维空间中表示立体体素单元。体素可以被看作是一个立方体,具有一定的体积、位置和属性。
(a)点云(Point clouds);
(b) 体素网格(Voxel grids);
(c) 多边形网格(Polygon meshes);
(d) 多视图表示(Multi-view representations)
a. 点云是三维空间(xyz坐标)点的集合。
b. 体素是3D空间的像素。量化的,大小固定的点云。每个单元都是固定大小和离散坐标。
c. mesh是面片的集合。
d. 多视图表示是从不同模拟视点渲染的2D图像集合。
体素网格是用固定大小的立方块作为最小单元,来表示三维物体的一种数据结构。
体素可以看成粗略版的点云。
Splatting抛雪球法------学习笔记-CSDN博客
3Dgaussion分布:【较真系列】讲人话-3d gaussian splatting全解(原理+代码+公式)【1】 捏雪球_哔哩哔哩_bilibili
选择点云->进行膨胀(高斯膨胀)->高斯小球填充得出模型

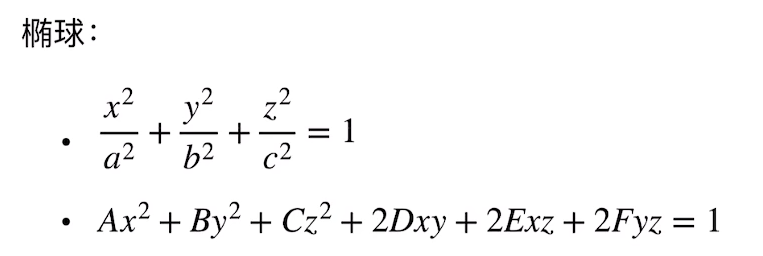
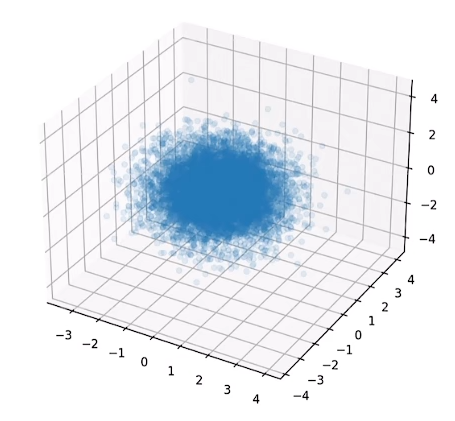



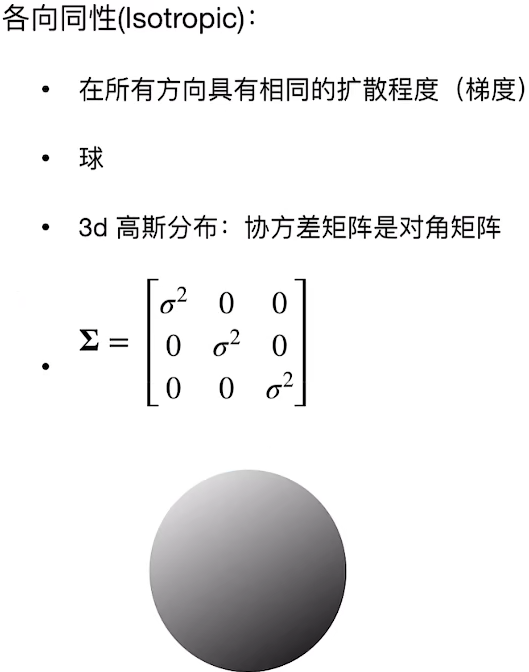
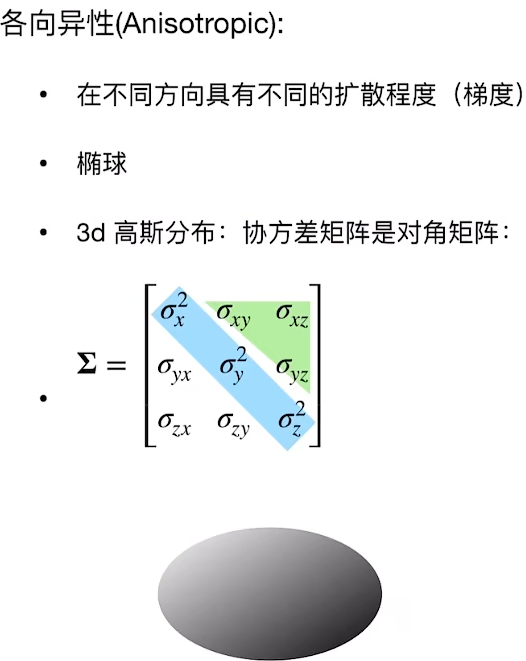


3Dsplatting算法:
3D Splatting算法是一种用于场景重建和渲染的技术。该算法优化从稀疏SfM点云开始,会创建一组三维高斯分布,可通过colmap先创建出一个初始化点云,且仅通过一组照片就能进行估算。它能保持连续体积辐射场的理想特性,用于场景优化,同时避免了空白空间中不必要的计算。
在训练过程中,每经过一定的轮数(densification_interval),会进行一系列操作。包括点的修剪,即移除不透明度极低的点以减少计算量;高斯的分裂和克隆,根据梯度范数和高斯范数,对满足条件的高斯进行分裂和克隆操作,以此提高模型的表达能力;参数更新,使用优化器(如Adam)更新权重张量W;中间结果展示与保存,每100个轮次显示生成的图像,并保存当前的训练结果
python
# 以下为简单示意代码,并非完整实现
import torch
import torch.optim as optim
# 假设这些是高斯点云的参数
points = torch.randn(100, 3) # 点的位置
opacity = torch.rand(100) # 不透明度
weights = torch.randn(100) # 权重
# 定义优化器
optimizer = optim.Adam([weights], lr=0.001)
# 模拟训练轮次
densification_interval = 10
for epoch in range(100):
if epoch % densification_interval == 0:
# 点的修剪
low_opacity_indices = opacity < 0.1
points = points[~low_opacity_indices]
opacity = opacity[~low_opacity_indices]
weights = weights[~low_opacity_indices]
# 高斯的分裂和克隆(此处简单示意,实际复杂)
# 假设根据某种条件选择部分高斯进行操作
split_indices = torch.randint(0, len(points), (10,))
# 分裂和克隆操作...
# 前向传播和损失计算(此处省略)
loss = torch.sum(weights) # 简单示例
# 参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
# 中间结果展示与保存
print(f"Epoch {epoch}: Loss = {loss.item()}")
# 保存当前训练结果
torch.save({
'points': points,
'opacity': opacity,
'weights': weights
}, f'training_result_epoch_{epoch}.pt')单张图片训练3d高斯模型:
使用单张图片训练3D高斯模型可以采用以下方法:
-
**利用图像生成RGB和深度图**:从单张图像生成RGB和深度图,然后将像素反投影到3D空间,创建密集的表面对齐高斯点云。之后通过Poisson表面重建提取高质量的纹理网格,同时利用高斯投影进行新视角合成(Novel View Synthesis) 。
-
**借助已有代码框架进行处理**:可以参考相关博客中提供的`train_video.py`代码。不过单张图片需要先模拟类似视频帧处理的流程,例如可以将单张图片复制多次模拟视频帧,然后通过ffmpeg截取(这里单张图片虽无需截取,但可模拟流程),再放到colmap中进行稀疏重建,最后把点云和相机位姿图片放到3D高斯中训练,得到训练结果 。
-
**遵循3D高斯应用实践流程**:
-
**特征提取与匹配**:对单张输入图像提取SIFT/SURF等特征点,虽然单张图片难以建立传统意义上图像间的对应关系,但可以通过一些先验知识或模型来模拟特征对应,构建图像间几何约束,为后续相机位姿计算提供依据 。
-
**相机位姿估计 (SfM)**:计算该单张图像的拍摄位置、方向(外参)和内部参数(内参),这是3D高斯模型训练的必要前提 。
-
**稀疏点云重建**:生成场景的稀疏三维点云,作为3D高斯模型的初始化位置,每个点对应一个初始高斯分布 。
-
**稠密点云生成 (MVS)**:这是可选步骤,对稀疏点云补充细节,生成更密集的三维点云,以提供更丰富的几何信息,提升3D高斯模型细节表现 。
-
**格式转换**:输出3D高斯模型可识别的相机参数和点云文件,建立从传统摄影测量到神经渲染的桥梁 。
colmap:
在训练 3D Gaussian Splatting 之前,COLMAP 的作用可以概括为:从一组无序/有序的二维图像中,自动重建出场景的相机参数和稀疏点云,为后续的高斯泼溅训练提供必要的几何与相机信息。
具体来说,COLMAP 会做以下几件事:
-
相机标定
估计每张图片的相机内参(焦距、主点、畸变系数等)和外参(相机在世界坐标系中的位置和朝向)。
-
运动恢复结构(SfM)
通过特征匹配、三角测量、光束法平差(Bundle Adjustment),生成一个稀疏的 3D 点云(每个点对应图像中匹配的特征点)。
-
输出标准格式
将结果保存在
sparse/0/目录下,包含:-
cameras.bin:相机内参 -
images.bin:每张图片的位姿 -
points3D.bin:稀疏点云
-
训练参数:
| 参数 | 说明 | 默认值 | 建议/备注 |
|---|---|---|---|
-s, --source_path |
数据集路径 ,包含COLMAP生成的sparse目录和images目录。 |
必填 | 训练前必须指定。 |
-m, --model_path |
训练模型和日志的保存路径。 | output/<随机名> |
用于指定存放模型和日志的目录。 |
--iterations |
训练总迭代次数。 | 30_000 |
可减少以缩短训练时间或测试流程。 |
-r, --resolution |
图像加载分辨率。 | 自动缩放 (宽度>1600) | 可降低分辨率以节省显存。 |
-w, --white_background |
使用白色背景代替黑色。 | False |
若数据集背景为白色,建议开启。 |
--data_device |
图像数据加载到的设备。 | cuda |
显存不足时可设为cpu(训练会变慢)。 |
--sh_degree |
球谐函数阶数,影响视角相关效果。 | 3 |
测试时可设为0加速。 |
python
#!/usr/bin/env python3
"""
Gaussian-Splatting 训练启动脚本
用法: python run_train.py
"""
import subprocess
import sys
import os
from pathlib import Path
# ==================== 配置参数(请根据需要修改) ====================
# 数据集路径(必须包含 images/ 和 sparse/0/ 子目录)
DATA_PATH = "data" # 相对路径或绝对路径
# 输出模型保存路径(None 表示自动生成)
MODEL_PATH = None # 例如 "output/my_scene"
# 训练迭代次数
ITERATIONS = 30_000 # 30k 是默认值,测试时可减少到 5_000
# 图像加载分辨率(-r 参数,1=原图,2=半分辨率,4=1/4 分辨率)
RESOLUTION = 1 # 显存不足时增大数值
# 背景色(True=白色,False=黑色)
WHITE_BACKGROUND = False
# 球谐函数阶数(3=全彩色,0=无视角相关颜色)
SH_DEGREE = 3
# 数据加载设备("cuda" 或 "cpu",显存不足时用 "cpu")
DATA_DEVICE = "cuda"
# 密度控制开始和结束的迭代步数
DENSIFY_FROM_ITER = 500
DENSIFY_UNTIL_ITER = 15_000
# 学习率(可选,一般保持默认)
POSITION_LR_INIT = 0.00016
POSITION_LR_FINAL = 0.0000016
FEATURE_LR = 0.0025
OPACITY_LR = 0.05
SCALING_LR = 0.005
ROTATION_LR = 0.001
# ==================== 参数检查 ====================
data_path = Path(DATA_PATH)
if not data_path.exists():
print(f"❌ 错误:数据集路径不存在: {data_path.resolve()}")
sys.exit(1)
if not (data_path / "images").exists():
print(f"❌ 错误:缺少 images 目录: {data_path / 'images'}")
sys.exit(1)
if not (data_path / "sparse").exists():
print(f"❌ 错误:缺少 sparse 目录(请先运行 COLMAP): {data_path / 'sparse'}")
sys.exit(1)
print("✅ 数据集检查通过")
# ==================== 构建命令行 ====================
cmd = [
sys.executable, "train.py", # 使用当前 Python 解释器
"-s", str(data_path),
"--iterations", str(ITERATIONS),
"-r", str(RESOLUTION),
"--sh_degree", str(SH_DEGREE),
"--data_device", DATA_DEVICE,
"--densify_from_iter", str(DENSIFY_FROM_ITER),
"--densify_until_iter", str(DENSIFY_UNTIL_ITER),
"--position_lr_init", str(POSITION_LR_INIT),
"--position_lr_final", str(POSITION_LR_FINAL),
"--feature_lr", str(FEATURE_LR),
"--opacity_lr", str(OPACITY_LR),
"--scaling_lr", str(SCALING_LR),
"--rotation_lr", str(ROTATION_LR),
]
if WHITE_BACKGROUND:
cmd.append("-w")
if MODEL_PATH:
cmd.extend(["-m", MODEL_PATH])
# ==================== 执行训练 ====================
print("\n🚀 启动训练,命令如下:")
print(" ".join(cmd))
print("\n" + "=" * 80)
try:
subprocess.run(cmd, check=True)
except subprocess.CalledProcessError as e:
print(f"\n❌ 训练失败,错误码: {e.returncode}")
sys.exit(e.returncode)
except KeyboardInterrupt:
print("\n⏸️ 训练被用户中断")
sys.exit(1)
print("\n🎉 训练完成!")查看模型效果:
(gaussian_splatting) C:\Users\lenovo\Desktop\3Drebuild\gaussian-splatting>C:\Users\lenovo\Desktop\3Drebuild\gaussian-splatting\viewers\bin\SIBR_gaussianViewer_app.exe -m C:\Users\lenovo\Desktop\3Drebuild\gaussian-splatting\output\3e9615e1-9
用viewers
或者超级Splat编辑器拖拽ply文件进入网页