本文主要是基于学习的datawhale关于langchain、langgraoh课程,记录的学习过程与个人看法。
安装依赖
安装langchain、langgraph、openai依赖及用于管理环境变量(python-dotenv)的辅助依赖
pip install langchain langgraph openai langchain_openai python-dotenv验证依赖版本
方式一:代码验证
python
import langchain
import langgraph
import openai
#验证langchain、langraph和openai的版本,可以通过以下命令
print("LangChain版本:", langchain.__version__)
print("LangGraph版本:", importlib.metadata.version("langgraph"))
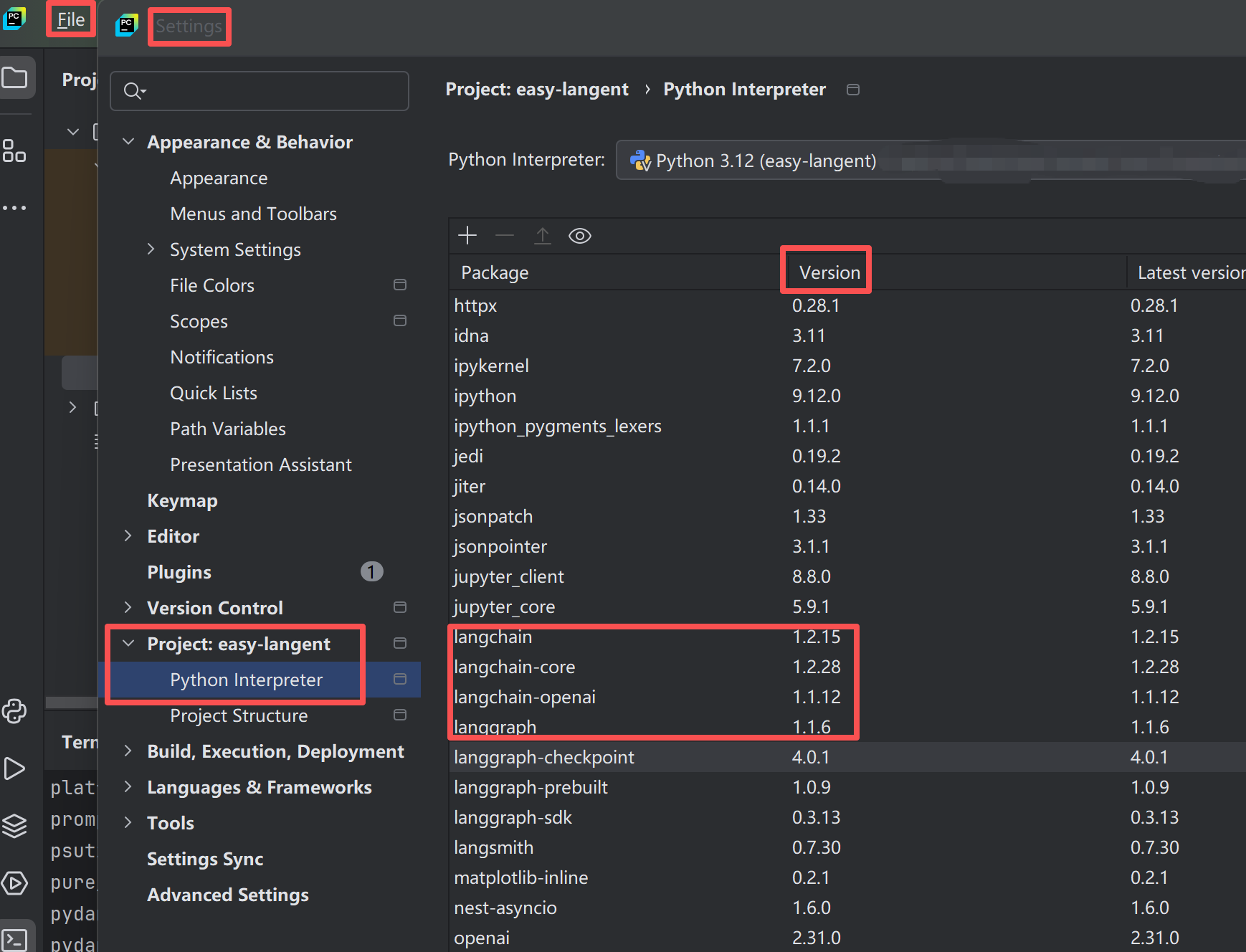
print("OpenAI版本:", openai.__version__)方式二:如果使用的是pycharm,也可以在界面查看
Pycharm-File-Settings-Project-Python Innterpreter查看依赖的版本号
HelloWorld入门
LangChain入门示例
python
import os
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
# 加载.env环境变量
load_dotenv()
# 获取环境变量中的apikey url和模型名称
API_KEY = os.getenv("API_KEY")
BASE_URL = os.getenv("BASE_URL")
MODEL_NAME = os.getenv("MODEL_NAME")
print("API_KEY = ", API_KEY)
print("BASE_URL = ", BASE_URL)
print("MODEL_NAME = ", MODEL_NAME)
if not API_KEY:
raise ValueError("未检测到API_KEY,请检查.env文件是否配置正确")
# 初始化大模型
llm = ChatOpenAI(api_key=API_KEY, base_url=BASE_URL, model=MODEL_NAME, temperature=0.3)
# 构造提示词
prompt = "请写一段50字左右的LangChain学习建议,语言简洁、实用,适合初学者"
# 调用模型
response = llm.invoke(prompt)
# 生成结果
print("生成的学习建议:", response.content)容易出错的点
存放环境变量的.env文件中环境变量名称与代码中获取环境变量的名称不一致,比如:.env文件如下图所示
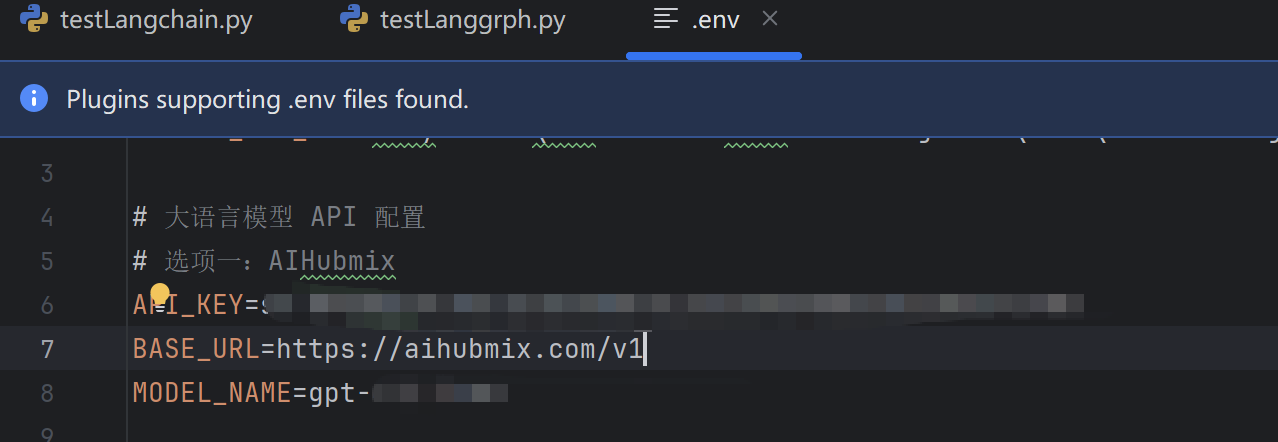
而代码中写的是
python
import os
API_KEY = os.getenv("OPEN_API_KEY")
BASE_URL = os.getenv("OPEN_BASE_URL")文件中没有定义名称为OPEN_API_KEY与OPEN_BASE_URL的环境变量,获取时肯定会报错。
LangGraph入门示例
python
# 1. 导入需要的模块
import os
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from typing import TypedDict
from dotenv import load_dotenv
# 2. 加载API密钥
load_dotenv()
# 3. 配置 API Key
API_KEY = os.getenv("API_KEY")
BASE_URL = os.getenv("BASE_URL")
MODEL_NAME = os.getenv("MODEL_NAME")
print("API_KEY=",API_KEY,'\n', "BASE_URL=",BASE_URL,'\n',"MODEL_NAME=",MODEL_NAME)
if not API_KEY:
raise ValueError("未检测到 API_KEY,请检查 .env 文件是否配置正确")
# 4. 初始化大模型(和LangChain案例一样)
llm = ChatOpenAI(
api_key=API_KEY,
base_url=BASE_URL,
model=MODEL_NAME, # 注意:根据你使用的模型修改名称!!!! 后面章节不再继续说明
temperature=0.3
)
# 5. 定义 State
class WorkflowState(TypedDict, total=False):
user_role: str #存储用户角色
original_advice: str #存储原始学习建议
simplified_advice: str #存储精简后的建议
translate_advice: str #存储翻译后的建议
# 6. 定义节点
'''
入参:state 是一个符合 WorkflowState 结构的字典,包含工作流当前累积的所有数据。
逻辑:调用大模型(llm.invoke)完成一个具体任务。
返回值:不是整个新状态,而是一个字典片段。LangGraph 会自动将这个返回值合并(更新)到总状态中。
'''
def generate_advice(state: WorkflowState):
prompt = f"给{state['user_role']}写一段50字左右的 AI 学习建议。"
result = llm.invoke(prompt)
return {"original_advice": result.content}
def simplify_advice(state: WorkflowState):
prompt = f"把下面的学习建议精简到30字以内:{state['original_advice']}"
result = llm.invoke(prompt)
return {"simplified_advice": result.content}
def translate_advice(state: WorkflowState):
prompt = f"把精简后的建议{state['simplified_advice']}翻译成英文"
result = llm.invoke(prompt)
return {"translate_advice": result.content}
# 7. 构建工作流
'''
StateGraph 是 LangGraph 的核心类。
传入 WorkflowState 的作用是告诉图:我们传递的数据结构长什么样(包含 user_role、original_advice、simplified_advice、translate_advice)。
'''
workflow = StateGraph(WorkflowState)
'''
添加节点和连线
节点(Node):给刚才定义的函数起个名字,挂载到图上。
边(Edge):定义执行顺序。
START → "generate":程序一开始就执行 generate_advice。
"generate" → "simplify":generate 完成后自动执行 simplify。
"simplify" → "translate":simplify 完成后自动执行 translate。
"translate" → END:最后结束。
'''
workflow.add_node("generate", generate_advice)
workflow.add_node("simplify", simplify_advice)
workflow.add_node("translate", translate_advice)
workflow.add_edge(START, "generate")
workflow.add_edge("generate", "simplify")
workflow.add_edge("simplify", "translate")
workflow.add_edge("translate", END)
'''
编译与执行
compile():把图"冻结"成一个可执行的程序对象。
invoke():传入初始状态(只有角色,没有建议内容),启动工作流。
'''
app = workflow.compile()
# 8. 执行
result = app.invoke({"user_role": "高校学生"})
# 9. 输出
print("原始学习建议:")
print(result["original_advice"])
print("\n精简后学习建议:")
print(result["simplified_advice"])
print("\n翻译后的学习建议:")
print(result["translate_advice"])代码解释
什么是TypeDict
python
class WorkflowState(TypedDict, total=False):
user_role: str #存储用户角色
original_advice: str #存储原始学习建议
simplified_advice: str #存储精简后的建议TypedDict:告诉 Python WorkflowState这个类是一个有固定键名、固定值类型的字典。
total=False:表示字典中的所有键都是可选的(即可以不传某个字段,也不会报类型错误)。
字段定义:仅是类型注解,运行时没有任何强制校验或默认值生成。
怎么使用
TypedDict 不是一个需要实例化的类,它只是一个类型蓝图。依然使用花括号 {} 来创建字典
定义了 TypedDict 后,它的使用方式和普通 Python 字典完全一样。区别仅在于: IDE 会给你提示,静态检查工具会帮你纠错。
python
from typing import TypedDict
class WorkflowState(TypedDict, total=False):
user_role: str
original_advice: str
simplified_advice: str使用方式
python
state: WorkflowState = {} # 声明变量类型为 WorkflowState
state["user_role"] = "student"
state["original_advice"] = "Practice Python daily."
print(state["user_role"]) # 输出: student作为函数参数的类型声明与使用
python
def process_advice(data: WorkflowState) -> str:
# 因为定义了类型,IDE 知道 data.get 应该填什么键
original = data.get("original_advice", "")
role = data.get("user_role", "guest")
return f"为 {role} 生成: {original}"
input_data = {
"user_role": "teacher",
"original_advice": "Focus on pedagogy"
}
result = process_advice(input_data)节点函数定义
对LangChain和LangGraph的认识
- 从名称看来,LangChain是链式的,类似于线性结构,处理的是类似于流水线式的简单任务;而LangGraph是图,也就是有节点和边的图,从示例代码中也可以看到,LangGraph对于图的定义是开发者可以根据业务逻辑自由定义的,灵活性更高。
- 示例代码给人的直观感受是langchain不适合复杂流程,就当前这个案例而言,可能很多人会有疑问langchain和大家日常所使用的deepseek、豆包等工具实现的功能是一样的吗?langchain只是需要有代码基础的人实现批量任务的吗?接下来我们从后续课程中继续寻找答案;langraph给人的直观感受是自定义性强,可以自己去设计工作流状态、节点以及节点的连接方式,比较适合复杂任务。
本文代码部分来源:datawhale easy-langent项目