概述
Claude Code 是 Anthropic 的 CLI 编程 Agent。是一个受控工具循环 Agent------能理解代码库、编辑文件、执行命令、管理 git 的自主编程助手。
本篇文章会详细讲解Claude code中的核心设计,详细讲解可以查看参考文献。本篇文章侧重的核心设计包括:Agent Loop、上下文管理、工具管理、skill系统、多Agent架构几部分。
| 层次 | 技术选型 | 说明 |
|---|---|---|
| 运行时 | Bun | 高性能 JS/TS 运行时,支持编译时 Feature Flag 消除 |
| 语言 | TypeScript | 全量 TypeScript,严格类型检查 |
| UI 框架 | React + Ink(自研) | 基于 React 的终端 UI 框架,自研 Ink 渲染器(src/ink/,~1.0MB) |
| 布局引擎 | Yoga | Facebook 的 Flexbox 布局引擎,适配终端 |
| Schema 验证 | Zod | 运行时类型校验,用于工具输入、Hook 输出、配置验证 |
| CLI 框架 | Commander.js | 命令行参数解析,分发到 REPL/headless/SDK 模式 |
| API 协议 | Anthropic SDK | 官方 TypeScript SDK,支持流式响应 |
参考文献:
简略版:https://cloud-code-study.vercel.app/guide/01-agent-loop.html
详细版:https://diwang.info/how-claude-code-works/#/docs/04-tool-system
Claude code的一些核心设计
1.Generator-based 流式架构
claude code可以分为前端展示和后端的处理, 从API 调用到 UI 渲染,全链路使用 async function* 异步生成器。每个 Token、每个工具结果都能实时流向用户界面。
为什么是 Generator 而不是 Callback 或 Promise?因为callback模式当数据产生速度大于UI渲染速度的时候,没有自然的暂停机制,而promis是阻塞式的,如果想是西安流式,本质上还得实现generator。
Generator 模式:yield 天然就是流式语义------生产者(API 层)产出一个 token 就 yield 一次,消费者(UI 层)按自己的节奏拉取。
并且claude code的整体api调用大模型也是流式输出,并且工具执行也是流式,而不是等完整的消息返回,而是出一个tool执行一个。
2. 上下文管理(渐进式压缩)
包括了5级的压缩,第一级工具返回结果最大值限制裁剪,大结果存为文件,只返回概要。第二级,动态工具结果裁剪,基于rule-based的方法,合并中间多余的工具调用,如中间多次重试,最后执行正确,则删除中间尝试的部分。第三级,删除旧的工具执行结果,只保留最近5个,并且根据缓存是否过期有kv cache的优化,第四级是投影式上下文折叠,这个只是前端展示的不同,第五级就是利用子Agent来生成整个对话的摘要。
3. 工具系统
内部工具主要包含了7类。
文件操作类工具,如Bash,File Read、Edit、Write,Glob Grep。
网络检索类工具,Agent管理类工具,派生子Agent,Agent间通信等。
用户交互类工具,向用户提问,管理代办事项等。
系统/流程控制类工具,如规划模式,git隔离环境,生成概要等。
mcp集成类工具,如列出mcp读取mcp等。
团队协作类工具,如创建Agent团队,删除Agent团队等。
mcp中的tools也集成到tools中,但是名称会自动加上mcp_,用以区别。
MCP Server
├── Tools → 给模型调用的函数(注入为 function call)
│ 用户不直接触发,模型决定何时调
│
├── Resources → 被动数据(不自动注入)
│ 模型主动通过 List/Read 工具按需读取
│
└── Prompts → 给用户用的 /slash 命令(不是 function call)
用户输入 /xxx 触发,展开为提示词模板3. 工具执行防御性分层安全
分为多层,首先zod sechema检查参数,其次validateInput检查参数是否合理。然后前置hook,然后canuseTool进行权限决策,包含了deny,ask,allow三种,然后执行工具,完成后有个后置hook。
4. Skill系统
skills实现渐进式披露,元数据层只包含名称+描述,指令层包含了skills.md,资源层包含了其他的文件或者一些可执行脚本。
5. 多智能体系统
有两类多Agent,一类是子Agent,另外一类是Team(团队)。
子Agent可创建四类Agent,包括通用,Explore(快速搜代码),plan(指定计划),Fork分身。三种执行方式,同步,异步,fork,Agent间通信用sendmessage,当开启 Coordinator 模式时,主 Agent 变成了纯粹的"指挥官"。
Team系统通过邮件系统进行沟通。
6. memory系统与Dream
memory包含了四层,从"个人专属"到"全公司共享"。
┌─────────────────────────────────────────────────────┐
│ 第4层:Managed Memory(管理员策略) │
│ /etc/claude-code/CLAUDE.md │
│ 全公司所有人都遵守的规则,由管理员维护 │
│ 例如:"所有提交必须通过 CI" │
├─────────────────────────────────────────────────────┤
│ 第3层:User Memory(用户个人) │
│ ~/.claude/CLAUDE.md │
│ 你个人的偏好,适用于所有项目 │
│ 例如:"我喜欢用 TypeScript,不要 JavaScript" │
├─────────────────────────────────────────────────────┤
│ 第2层:Project Memory(项目级) │
│ 项目根目录/CLAUDE.md 或 .claude/CLAUDE.md │
│ 项目团队共享的规则(可提交到 Git) │
│ 例如:"本项目使用 Prisma ORM" │
├─────────────────────────────────────────────────────┤
│ 第1层:Local Memory(本地) │
│ .claude/CLAUDE.local.md │
│ 你个人在这个项目里的笔记(gitignored) │
│ 例如:"我负责 auth 模块的重构" │
└─────────────────────────────────────────────────────┘除了手动维护 CLAUDE.md,Claude Code 还有一个自动记忆系统。它会在对话结束后,自动提取值得记住的信息。
系统主循环
Claude Code 的查询系统采用双层生成器架构,清晰分离会话管理与查询执行:
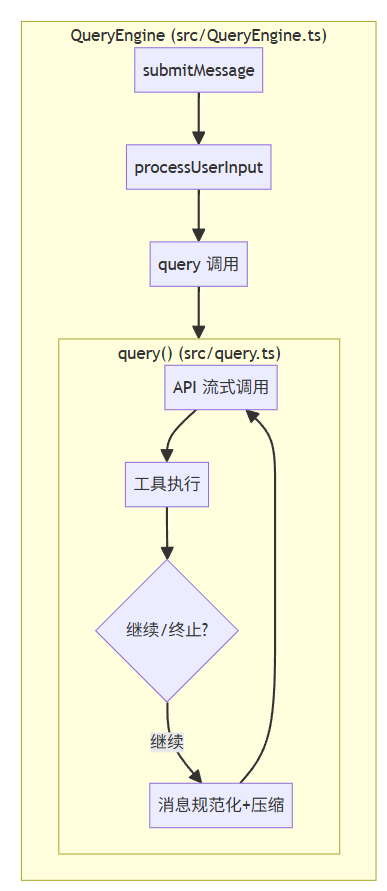
query就是claude code的核心循环,Claude Code 给我最大的感受就是他的上下文管理,传统的ReAct的 Agent Loop 就是"观察 → 思考 → 行动 → 再观察"的循环,但是Claude也把上下文压缩作为里面的一部分,更加类似于"上下文压缩 → 观察 → 思考 → 行动 → 再循环"。
单次循环过程如图:
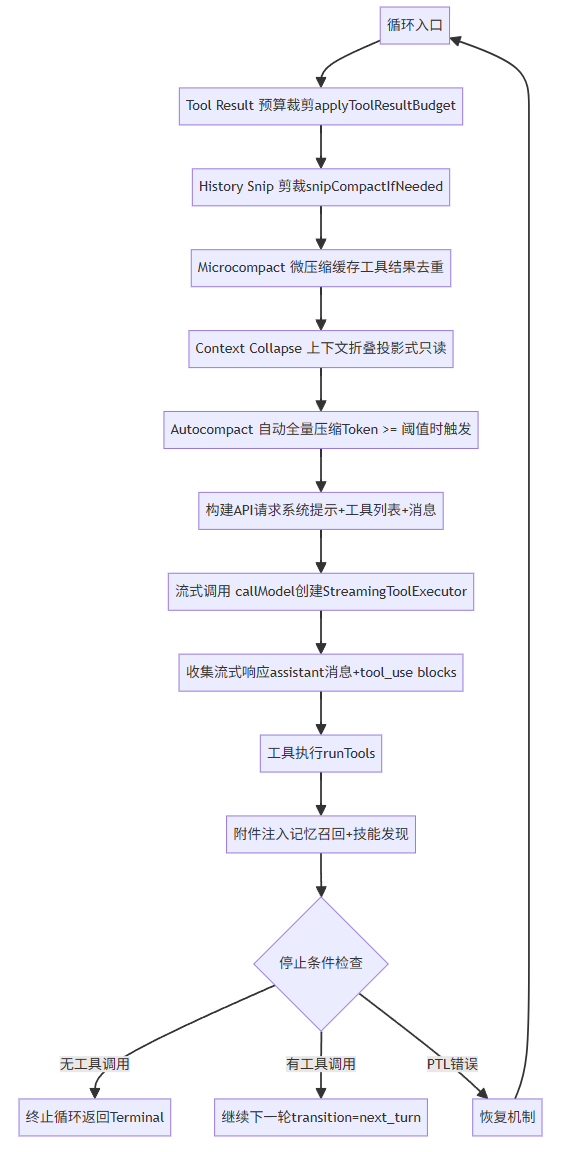
里面包含了几个重要部分:
第一步:5 级压缩流水线:消息列表依次经过 Tool Result Budget → Snip → Microcompact → Context Collapse → Autocompact。
第二步:上下文管理,构建prompt
第三步:流式调用 + 工具并行执行
上下文管理
Claude Code上下文管理的核心设计原则是KV cache的复用,因为前缀必须字节级完全一致才能命中缓存,所以很多固定的东西需要放到前面,而变化的则放到后面。
一次 API 请求的完整解剖
Claude API 的请求体有三个顶级字段:system(系统提示词数组)、tools(工具 schema 数组)、messages(消息数组),包含了memory中的内容(Cluade.md)。以下是它们的完整结构:
┌─────────────────────────────────────────────────────────────┐
│ system --- 系统提示词数组(多个 TextBlock 拼接) │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ [0] 归属头 (Attribution Header) │ │
│ │ [1] CLI 前缀 (交互模式 / -p 模式指令) │ │
│ │ ─── 静态内容 ─────────────────────────── 🔒 global ── │ │
│ │ [2] 核心指令 + 工具描述 + 安全规则 + 行为准则 │ │
│ │ (所有用户完全相同) │ │
│ │ ─── __SYSTEM_PROMPT_DYNAMIC_BOUNDARY__ ────────────── │ │
│ │ ─── 动态内容 ─────────────────────────── 不缓存 ───── │ │
│ │ [3] 输出风格、语言偏好、MCP 指令等 │ │
│ │ (因用户/会话而异) │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ tools --- 工具 schema 数组 │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ 内置工具 (Read, Edit, Bash, Grep, Write, Glob...) │ │
│ │ MCP 工具 (用户安装的,可能标记 defer_loading 延迟加载) │ │
│ │ 最后一个工具 ← 标记 cache_control 作为缓存断点 │ │
│ │ ── 断点之后 ── │ │
│ │ 服务端工具 (advisor 等,开关不影响缓存) │ │
│ └────────────────────────────────────────────────────────┘ │
│ │
│ messages --- 消息数组 │
│ ┌────────────────────────────────────────────────────────┐ │
│ │ [User] <system-reminder> │ │
│ │ CLAUDE.md 内容 + 当前日期 (会话开始时计算一次) │ │
│ │ </system-reminder> (isMeta) │ │
│ │ │ │
│ │ [User] 用户第 1 条消息 │ │
│ │ [Asst] 模型回复(可能包含 tool_use 块) │ │
│ │ [User] tool_result 结果 │ │
│ │ [User] 附件消息(每条都是独立的 isMeta 用户消息): │ │
│ │ ├ <system-reminder> 记忆文件内容 </...> │ │
│ │ ├ <system-reminder> 可用技能列表 </...> │ │
│ │ ├ <system-reminder> 延迟工具发现结果 </...> │ │
│ │ └ <system-reminder> MCP 指令增量 </...> │ │
│ │ [Asst] 模型第 2 轮回复 │ │
│ │ ...(消息不断增长,直到压缩机制介入) │ │
│ └────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘理解上面的静态结构之后,来看看动态过程------一轮对话(Turn N)中上下文经历了哪些变化:
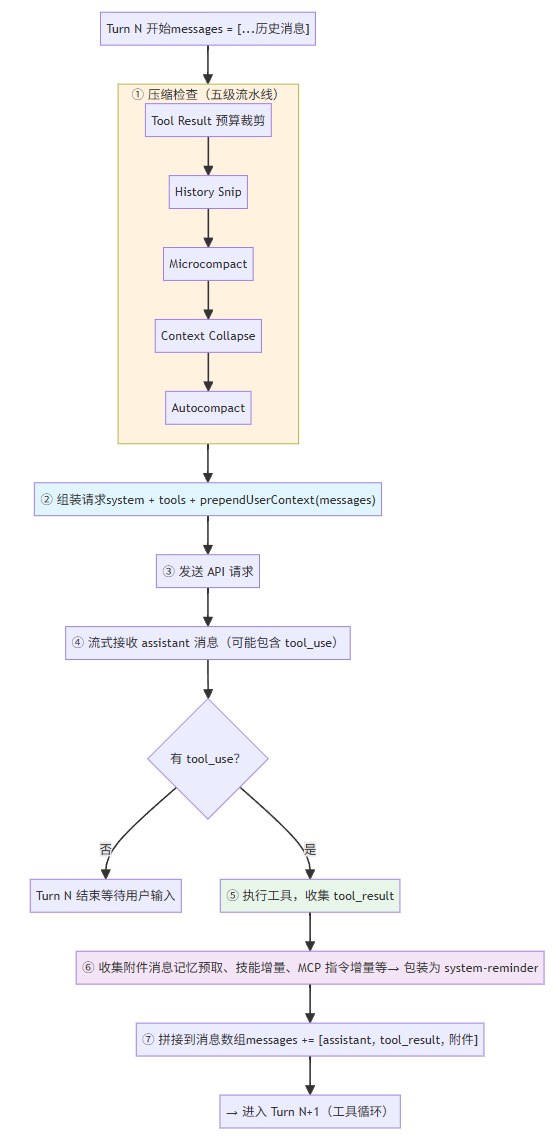
五级压缩流水线
这是 Claude Code 上下文管理的核心机制。当对话越来越长,Token 使用量不断增长,五级压缩流水线逐级启动。设计哲学是渐进式压缩------先用成本最低的手段尝试释放空间,只在必要时才动用更重的武器。
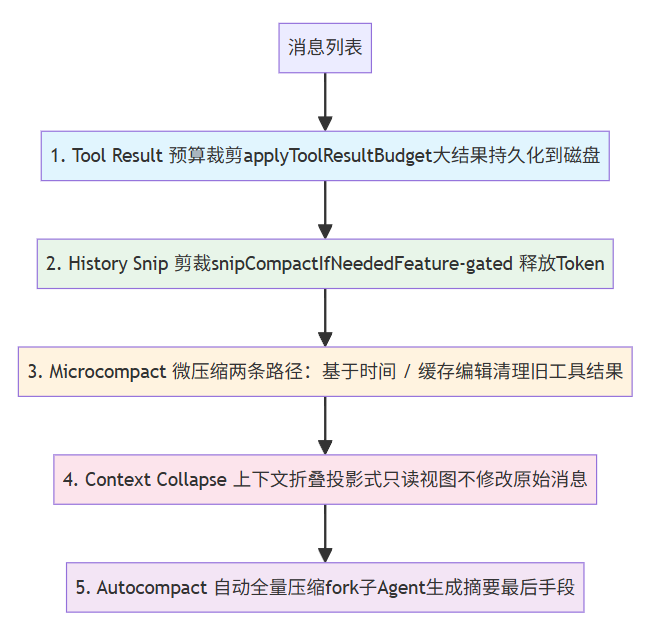
Level 1: Tool Result 预算裁剪:
对单次工具调用结果进行处理,设置一个最大值,但不是简单截断,而是持久化到磁盘上下文中只保留一个紧凑的引用消息。
Level 2: History Snip:
利用启发式规则,来去除冗余的部分,如重复的工具输出(执行了三次ls),过程中的草稿,比如模型尝试修复一个 Bug,它用了 Edit 工具改了 5 次代码才成功。
Level 3: Microcompact:
删除旧的工具执行结果,只保留最近5个,但是为了重用KV cache又两种方式,因为如果删除了工具执行结果,那么token序列就变了,不能复用。
如果服务器缓存已过期(5分钟),那么直接删除工具调用结果,如果缓存没有国企,那么上传cache_reference,相当于工具返回结果的id,配合服务器,在推理的时候加上mask即可。
Level 4: Context Collapse:
投影式上下文折叠------关键特性是它不修改原始消息,这个只是前端展示的时候折叠。
Level 5: Autocompact:
这是最后的手段------当所有轻量级压缩都无法将 Token 使用量控制在安全范围内时,系统 fork 一个子 Agent 来生成整个对话的摘要。
模型会输出9个部分
请写一份详细的摘要,涵盖以下部分:
1. 主要请求和意图
2. 关键技术概念
3. 文件和代码片段(保留关键代码)
4. 遇到的错误和修复方案
5. 解决问题的过程
6. 所有用户消息(直接引用原文)
7. 待办任务
8. 当前工作进展
9. 可选的下一步建议压缩后恢复机制:
Autocompact 的风险是让模型"忘记"刚编辑的文件。系统会在压缩后自动执行 runPostCompactCleanup(),会恢复最近 5 个文件:从压缩前的 readFileState 缓存中取出最近读取的 5 个文件,每个限 5K Token,作为附件消息注入。
压缩请求本身可能超限,最多重试3次
system-reminder 注入机制
Claude Code 需要在对话的各个位置注入系统级信息------当前可用的延迟工具列表、记忆文件内容、安全提醒等。但直接插入这些内容会产生一个问题:模型可能误认为这是用户说的话,从而做出不恰当的响应。
注入位置
1.用户上下文前置(prependUserContext() in src/utils/api.ts):
CLAUDE.md 内容、当前日期等被包装在 标签中,作为第一条 isMeta 用户消息插入:
createUserMessage({
content: `<system-reminder>
As you answer the user's questions, you can use the following context:
# claudeMd
${claudeMdContent}
# currentDate
Today's date is 2026-04-01.
IMPORTANT: this context may or may not be relevant to your tasks.
</system-reminder>`,
isMeta: true,
})2.附件消息:
记忆预取结果、延迟工具列表(Tool Search 的发现结果)、技能列表、Agent 定义列表等,都作为附件消息注入,内容包裹在 system-reminder>中。
3.工具结果中的提醒:
某些工具在返回结果时附带系统提醒。如文件读取发现文件为空时:Warning: file exists but is empty
长期记忆
有一些注意事项或者长期记忆存放于CLAUDE.md,并且是一个多级的发现形式,可从多个地方发现。
管理策略文件:从 MDM(移动设备管理)策略中读取的指令(如 /etc/claude-code/CLAUDE.md),如公司的统一规范。
用户主目录:~/.claude/CLAUDE.md 下的全局配置,可被git管理
项目文件:从 CWD 向上遍历目录树,查找每一层的指令文件
本地文件:CLAUDE.local.md(不提交到 git 的个人指令),自己的私货
显式附加目录:--add-dir 参数指定的额外目录
文件名模式:每个目录下检查 CLAUDE.md、.claude/CLAUDE.md,以及 .claude/rules/ 目录下的所有 .md 文件。这意味着你可以将不同领域的指令拆分成独立文件(如 .claude/rules/testing.md、.claude/rules/style.md),系统会自动加载它们。
优先级排序:文件按从远到近的顺序加载------靠近 CWD 的文件后加载,因此优先级更高。这符合"就近原则":项目根目录的全局规则可以被子目录的局部规则覆盖。由于 LLM 对上下文末尾的内容关注度更高(近因效应),后加载的指令在模型的"注意力"中权重更大。
核心工具
Claude Code 的所有能力,包括内部工具和mcp在api层面都抽象为tool,统一管理。
这套系统的核心架构分为三层:
- 设计层:Tool 泛型接口(src/Tool.ts)------定义每个工具必须实现的契约:执行逻辑、输入 Schema、安全语义标记(只读/破坏性/并发安全)、权限检查、UI 渲染
- 组装层:getAllBaseTools() → getTools() → assembleToolPool()(src/tools.ts)------从编译时裁剪到运行时过滤,最终将内置工具和 MCP 工具合并为统一的工具池
- 执行层:StreamingToolExecutor(src/services/tools/)------在模型流式输出的同时并发执行工具,处理权限检查、Hook 回调和结果格式化。
Claude Code 包含 66+ 内置工具,按功能域分为 7 类。这些分类反映了 coding agent 的核心能力模型:文件操作是基础(读写搜索是最高频操作),Agent 管理支撑多 Agent 协作,用户交互和系统控制保证人在回路中的控制力,MCP 集成则提供无限扩展的出口。工具集的选择原则是"覆盖开发者日常工作流的 95% 场景"------剩下的 5% 通过 BashTool(万能后备)和 MCP 扩展兜底。
| 类别 | 工具 | 说明 |
|---|---|---|
| 文件操作 | BashTool | Shell 命令执行(最复杂的工具) |
| FileReadTool | 读取文件内容(支持图片、PDF、Jupyter) | |
| FileEditTool | 精确字符串替换编辑(核心编辑工具) | |
| FileWriteTool | 创建/覆盖文件 | |
| GlobTool | 按模式匹配文件 | |
| GrepTool | 正则搜索文件内容(基于 ripgrep) | |
| NotebookEditTool | Jupyter Notebook 编辑 | |
| 网络 | WebFetchTool | 获取网页内容 |
| WebSearchTool | API 驱动的网络搜索 | |
| Agent 管理 | AgentTool | 派生子 Agent(多 Agent 架构核心) |
| TaskOutputTool | 输出任务结果 | |
| TaskStopTool | 停止后台任务 | |
| TaskCreate/Get/Update/ListTool | 任务管理 v2(详见 第 15 章) | |
| SendMessageTool | Agent 间通信 | |
| 用户交互 | AskUserQuestionTool | 向用户提问 |
| TodoWriteTool | 管理待办列表 | |
| SkillTool | 加载并执行技能系统 | |
| 系统/流程控制 | EnterPlanModeTool | 进入规划模式 |
| ExitPlanModeTool | 退出规划模式 | |
| EnterWorktreeTool | 进入 Git Worktree 隔离 | |
| ExitWorktreeTool | 退出 Worktree | |
| BriefTool | 生成简要摘要 | |
| ToolSearchTool | 搜索并加载延迟工具 | |
| ConfigTool | 配置管理 | |
| MCP 集成 | ListMcpResourcesTool | 列出 MCP 资源 |
| ReadMcpResourceTool | 读取 MCP 资源 | |
| MCPTool | MCP 工具代理 | |
| LSPTool | 语言服务器操作 | |
| 团队协作 | TeamCreateTool | 创建 Agent 团队 |
| TeamDeleteTool | 删除 Agent 团队 | |
| ListPeersTool | 列出同级 Agent |
工具接口(设计层)
工具接口中包括了三类数据,元数据,提示词和描述,schema,安全与权限,ui渲染等。
export type Tool<Input, Output, P extends ToolProgressData> = {
// ===== 元数据 =====
name: string // 工具唯一标识
aliases?: string[] // 别名(兼容旧名称)
maxResultSizeChars: number // 结果最大字符数
shouldDefer?: boolean // 是否延迟加载(ToolSearch 动态发现)
// ===== 核心执行 =====
call(args, context, canUseTool, parentMessage, onProgress?): Promise<ToolResult<Output>>
// ===== 提示词与描述 =====
description(input, options): Promise<string>
prompt(options): Promise<string>
// ===== Schema 定义 =====
inputSchema: Input // Zod 输入 Schema
inputJSONSchema?: ToolInputJSONSchema // JSON Schema(API 兼容)
// ===== 安全与权限 =====
isConcurrencySafe(input): boolean // 是否可并发执行
isReadOnly(input): boolean // 是否只读操作
isDestructive?(input): boolean // 是否破坏性操作
validateInput?(input, context): Promise<ValidationResult>
checkPermissions(input, context): Promise<PermissionResult>
// ===== UI 渲染(React 组件)=====
renderToolUseMessage(input, options): React.ReactNode
renderToolResultMessage?(content, progress, options): React.ReactNode
}所有工具的创建都通过 buildTool() 工厂函数完成。
按需工具注册与组装(组装层)
三层过滤。
并且有两种注入的方式。工具数量少时,全量注入。工具数量超过阈值时只注入少量常驻工具,其余工具以摘要形式写入 system prompt(每个工具一行 hint),模型先调用 ToolSearchTool,搜到需要的工具后,该工具才被动态注入到下一轮请求的 tools 列表中。
全部工具
│
▼ 第1层:Feature Flag 过滤
│ (某些工具只在特定条件下可用)
│
▼ 第2层:权限 Deny 规则过滤
│ (settings.json 中禁用的工具直接移除)
│
▼ 第3层:MCP 工具合并
│ (外部 MCP 服务器提供的工具加入池中)
│
▼
最终工具池
(这才是模型实际能"看到"的工具)工具执行生命周期(执行层)
每次工具调用都经过以下完整权限检查链(src/services/tools/toolExecution.ts)
runToolUse(block)
├─ 1. Zod schema 校验输入参数
├─ 2. tool.validateInput()(工具自定义校验,可选,如file类工具校对路径里是否真的有)
├─ 3. runPreToolUseHooks() ← 前置 hooks,预埋的扩展
├─ 4. canUseTool() 权限决策
│ ├─ deny 规则匹配 → 拒绝(记入 permissionDenials)
│ ├─ ask 规则匹配 → 弹出用户确认对话框(阻塞)
│ └─ allow → 通过
├─ 5. tool.call(input, context, ...) ← 实际执行
├─ 6. runPostToolUseHooks() ← 后置 hooks,预埋的扩展
└─ 7. 格式化为 tool_result 消息块,返回给 LLM大结果处理,会将内容存入磁盘,避免单个工具结果撑爆上下文。
多智能体架构
子Agent
┌─────────────────────────────────────────────┐
│ 主 Agent (Main Session) │
│ │
│ 用户: "调研这个项目的架构,然后写个新模块" │
│ │
│ 主 Agent 决定:拆成两步 │
│ │
│ ┌──────────────┐ ┌───────────────────┐ │
│ │ 子Agent A │ │ 子Agent B │ │
│ │ (Explore) │ │ (General Purpose) │ │
│ │ │ │ │ │
│ │ 只读工具: │ │ 全部工具: │ │
│ │ Read,Grep, │ │ Read,Write,Edit, │ │
│ │ Glob,Bash │ │ Bash,Grep... │ │
│ │ │ │ │ │
│ │ 结果:"项目用 │ │ 结果:"已创建新 │ │
│ │ React+Node" │ │ 模块 src/new/" │ │
│ └──────┬───────┘ └────────┬──────────┘ │
│ │ │ │
│ └──────┬─────────────┘ │
│ ▼ │
│ 汇总结果,回复用户 │
└─────────────────────────────────────────────┘有四种Agent角色,分别实现不同的任务。
| 类型 | 职责 | 可用工具 | 模型 |
|---|---|---|---|
| General Purpose | 通用任务 | 全部工具 | 继承父级 |
| Explore | 快速搜代码 | Read, Grep, Glob, Bash (只读) | Haiku (更快更省) |
| Plan | 制定计划 | 只读工具 | 继承父级 |
| Fork | 分身 (隐式) | 父级完全相同的工具 | 继承父级 |
并且三种执行方式
同步执行 异步执行 Fork(分身)
──────── ──────── ────────
主Agent 主Agent 主Agent
│ │ │
├─ 派出子Agent ├─ 派出子Agent ├─ fork 分身
│ │ │ │ │ │ │
│ │ 执行中... │ ▼ │ ▼ ▼
│ │ │ 继续干别的事 │ 分身1 分身2
│ │ │ │ │ │
│ ◄─ 结果返回 │ │ │ │
│ │ ◄─ 收到通知 │ │ │
▼ ▼ ▼ ▼ ▼
继续后续工作 处理通知中的结果 汇总所有分身的结果Agent 间通信利用SendMessage。
// src/tools/SendMessageTool/SendMessageTool.ts (lines 67-87)
{
to: string, // 接收者:"agent-名字", "*"(广播)
summary: string, // 5-10 字摘要
message: string, // 消息内容
}