
Elasticsearch 没有硬性的大小限制,但有一些明确的信号表明你已经超出了当前架构的承载能力。了解如何为分片设定大小、管理节点限制、按分层选择存储,以及使用 AutoOps 在问题发生之前进行检测。
Elasticsearch 新手?欢迎参加我们的 Elasticsearch 入门网络研讨会。你也可以开始免费云试用,或现在就在你的本地机器上尝试 Elastic。
Elasticsearch 没有硬性的大小限制。生产集群可以运行在 PB 级规模。但"过大"通常体现在三个方面:查询速度慢到超出你的服务级别协议( SLA ),某个节点达到其分片上限,或者由于所有数据都存放在同一高成本存储层而导致存储成本失控。本指南将介绍这些信号、关键指标以及应对方法。
真正重要的三个限制
在节点层面没有硬性的存储上限。Elastic 曾演示单个节点查询 1 PiB 数据。在早期版本中,每个分片的开销较高,因此曾有经验法则:每 GB 堆内存不超过 20 个分片。超过该限制会导致垃圾回收压力增大、集群状态更新变慢以及节点不稳定。在 7.x 和 8.x 版本中,通过一系列优化(更紧凑的元数据序列化、更高效的缓存、堆外数据结构以及压缩的集群状态),每个分片的开销显著降低,这一经验法则在 8.3 中被废弃,取而代之的是基于字段密度的容量规划方法。
真正决定上限的是工作负载类型。例如,配置为 31 GB 堆内存、20 TB 存储的冷节点可以轻松处理审计和数据保留类工作负载,因为其访问模式较少且以聚合为主。而相同配置在高并发文档搜索场景下则可能难以应对。
需要重点关注的三个方面:
- 分片大小:过大的单个分片会导致查询变慢以及恢复时间延长。
- 每节点分片数:每个节点都有上限,而索引生命周期管理( ILM )会自动创建分片,即使你没有主动跟踪。
- 存储层不匹配:数据在高成本快速存储层中保留时间过长。
分片大小
每个分片建议在 10 GB 到 50 GB 之间。官方建议将 ILM 的 rollover 触发点设置为每个主分片 50 GB,并以 10 GB 作为建议下限。每个分片应控制在 2 亿个文档以内。
分片过小会带来不必要的开销:为主节点增加更多元数据、消耗更多堆内存、增加网络流量。分片过大则会导致查询执行变慢,并且在节点故障后的恢复时间变长,因为 Elasticsearch 一次只恢复一个分片。
有一条规则可以不再使用:"每 GB 堆内存不超过 20 个分片" 的经验法则已在 Elasticsearch 8.3 中被废弃。新的建议更简单:关注下面的每节点 1000 个分片限制,并将分片大小保持在 10--50 GB(或 2 亿文档)范围内。
如何监控:
ini
`
1. # size per shard
2. GET _cat/shards?&h=index,store&v
`AI写代码
分片预算
每个非冻结数据节点最多支持 1000 个分片。ILM 会自动为你创建分片。如果你的策略是按天 rollover,并且有 5 个主分片和 1 个副本,那么每天会产生 10 个分片。在不做任何调整的情况下,一个节点大约在 100 天内就会被填满。
当接近上限时的应对选项:
- 更长的 rollover 周期:如果在时间触发之前分片没有达到 50 GB,可以改为按周或按月 rollover。
- 减少每个索引的分片数 :对于较小的每日数据量,通常 1 到 2 个主分片就足够。如果需要重新平衡现有索引,可以调整主分片数量。
- 增加节点:如果数据量确实需要按天 rollover 且分片数量较多,可以通过增加节点来分摊负载。
对于主节点,建议按每 3000 个索引分配 1 GB 堆内存进行规划。
如何监控:
ini
`
1. # shards per node
2. GET _cat/allocation?h=node,shards&v
`AI写代码
存储
搜索速度指南建议将至少一半的系统内存分配给操作系统文件系统缓存,并使用直连存储。远程存储通常性能较差。索引速度指南也强调了这一点,建议在写入密集型工作负载中,在多个本地 SSD 上使用 RAID 0。
对于热数据:不要使用网络附加存储( NAS )。NAS 会在每次读取时增加延迟,而且一些 NAS 系统没有正确实现 POSIX 文件系统语义,这可能导致数据损坏。应使用本地 SSD。
各存储层适用方案:
| 分层 | 存储 | 原因 |
|---|---|---|
| 热层 | 本地 SSD( DAS ) | 高 I/O、低延迟、安全的文件系统语义 |
| 温层 | HDD 可接受 | 查询压力较低,无活跃写入 |
| 冷层 | 可搜索快照 | 无需副本,约节省 50% 存储空间 |
| 冻结层 | 可搜索快照 | 相比温层最多可降低 20 倍成本( Enterprise 许可证 ) |
如何监控:
ini
`
1. # disk usage per node and role
2. GET _cat/allocation?h=node,node.role,disk.used,disk.avail,disk.percent&v
`AI写代码
在 Elastic Cloud 上可以跳过这一部分。你可以为每个分层选择硬件配置文件,由 Elastic 负责存储配置。
数据分层与 ILM

索引生命周期管理( ILM )会自动在不同分层之间移动数据:热、温、冷、冻结、删除。数据从热层向后移动得越远,存储成本就越低。
冷层和冻结层使用可搜索快照:
- 冷层(完全挂载):性能接近普通索引,无需副本,比温层约便宜 50%。
- 冻结层(部分挂载):相比温层最多可减少 20 倍存储成本,查询较慢,需要 Enterprise 许可证。
在规模化场景下,成本差异非常显著。Search Labs 的一项基准测试对 90 TB 数据进行了测量:全热层架构每月成本为 28,222 美元,而热 + 冻结架构降至 3,290 美元。
一个用于时间序列数据、热窗口为 14 天的典型 ILM 策略如下:
bash
`
1. {
2. "policy": {
3. "phases": {
4. "hot": {
5. "actions": {
6. "rollover": { "max_primary_shard_size": "50gb" }
7. }
8. },
9. "warm": {
10. "min_age": "14d",
11. "actions": {
12. "shrink": { "number_of_shards": 1 }
13. }
14. },
15. "cold": {
16. "min_age": "30d",
17. "actions": {
18. "searchable_snapshot": {
19. "snapshot_repository": "my_repository"
20. }
21. }
22. },
23. "frozen": {
24. "min_age": "90d",
25. "actions": {
26. "searchable_snapshot": {
27. "snapshot_repository": "my_repository"
28. }
29. }
30. },
31. "delete": {
32. "min_age": "365d",
33. "actions": { "delete": {} }
34. }
35. }
36. }
37. }
`AI写代码根据你的查询模式调整 min_age 值。每周查询的数据可以比每天查询的数据更早转移到冷层。
AutoOps
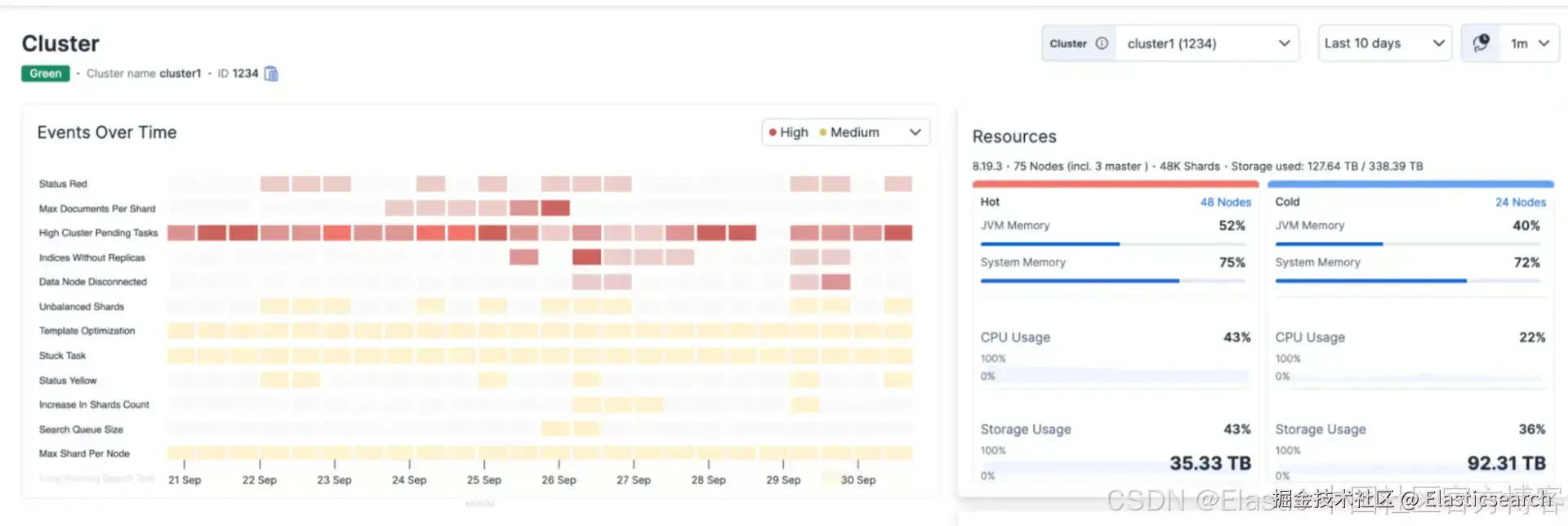
截至 2026 年 2 月,AutoOps 对所有 Elasticsearch 用户免费开放,不受许可证等级限制。在 Elastic Cloud 上,它已默认启用。对于 Elastic Self-Managed、Elastic Cloud Enterprise( ECE )以及 Elastic Cloud on Kubernetes( ECK )部署,通过 Cloud Connect使用轻量级 Elastic Agent 连接集群,大约 5 分钟即可完成。需要互联网连接;不支持离线( air-gapped )部署。
AutoOps 每 10 秒采样数百个指标,并通过根因分析和修复命令提示问题。但它不会自动应用修复操作。
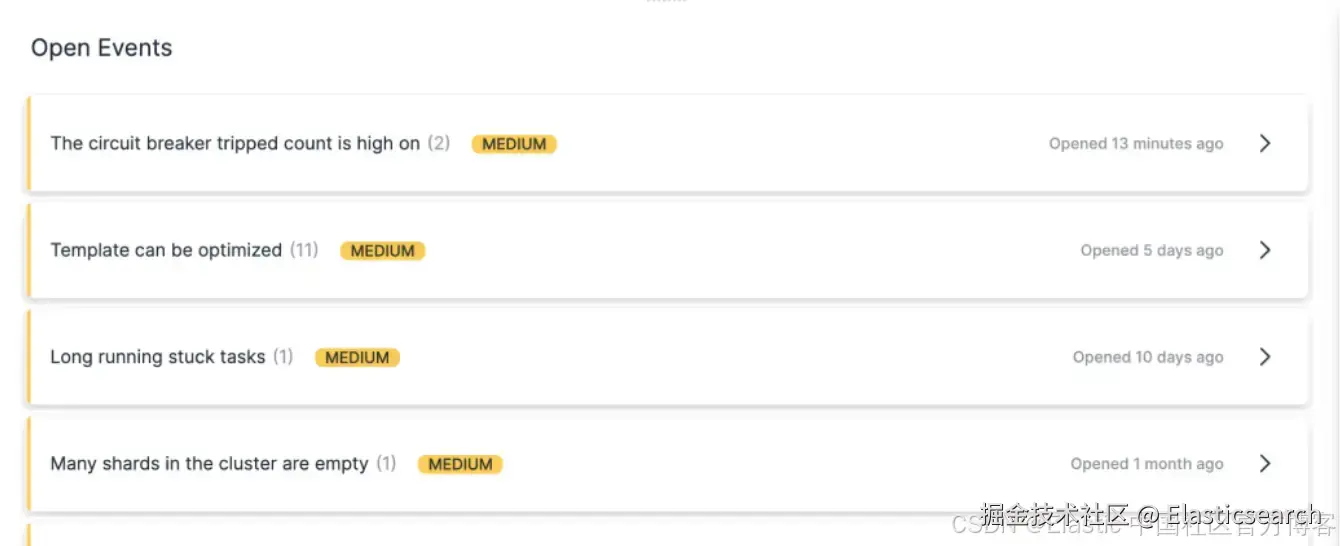
对于大规模部署,它可以检测:
- 分片大小超过推荐范围的增长情况。
- 没有 ILM 策略且已增长过大的索引。
- 节点之间的分片不均衡。
- 在触发分配失败之前的磁盘水位线违规情况。
- 索引拒绝与摄取瓶颈问题。
- 大规模聚合导致的慢查询与 circuit breaker 触发。
它内置超过 100 个可自定义告警,并可将通知路由到 PagerDuty、Slack、Teams 或任何 webhook。
结论
关注分片大小(10--50 GB),在 ILM 运行过程中跟踪每节点分片预算,将热数据放在本地 SSD 上,并对很少查询的数据使用冷层和冻结层。
在 Elastic Cloud 上,硬件配置文件和 AutoOps 会帮你处理大部分这些问题。对于自建部署,这是一份检查清单,而通过 Cloud Connect 使用 AutoOps 则是你的早期预警系统。如果你不确定你的节点在特定工作负载下能承载多少数据,可以在最终确定硬件规格前使用 Rally 用自己的数据进行基准测试。
参考
- 分片大小规划
- 数据分层
- Elasticsearch 分片与副本指南
- 如何减少分片数量
- 如何增加主分片数量
- 优化磁盘空间与使用
- 可搜索快照基准测试
- AutoOps 文档
- Rally:Elastic 用于测试集群规模的基准框架
- Elastic 存储效率优化网络研讨会( Christian Dahlqvist 和 Alan Woodward )
- 使用 Rally 进行集群规模规划网络研讨会( Christian Dahlqvist 和 Daniel Mitterdorfer,关于基准测试方法论 )