提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 关联查询
-
- 什么是关联查询
- 内连接
- 左连接
- 右连接
- union
- 自连接
-
- [with rollup合计](#with rollup合计)
- 多字段分组
- 分组统计时,select后字段列表的问题
- having
- [order by](#order by)
- limit
-
- 一、关联查询基础概念
- 二、连接类型
-
- [1. 内连接(INNER JOIN)](#1. 内连接(INNER JOIN))
- [2. 左连接(LEFT JOIN)](#2. 左连接(LEFT JOIN))
- [3. 右连接(RIGHT JOIN)](#3. 右连接(RIGHT JOIN))
- [三、UNION 和 UNION ALL](#三、UNION 和 UNION ALL)
- [四、自连接(SELF JOIN)](#四、自连接(SELF JOIN))
- [五、分组查询(GROUP BY)](#五、分组查询(GROUP BY))
-
- [1. 基本用法](#1. 基本用法)
- [2. 多字段分组](#2. 多字段分组)
- [3. WITH ROLLUP(合计行)](#3. WITH ROLLUP(合计行))
- [六、HAVING 与 WHERE 的区别](#六、HAVING 与 WHERE 的区别)
- [七、ORDER BY 与 LIMIT](#七、ORDER BY 与 LIMIT)
- 八、易错点
关联查询
什么是关联查询
关联查询:两个或更多个表一起查询。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。
比如:员工表和部门表,这两个表依靠"部门编号"进行关联。
(1)凡是联合查询的两个表,必须有"关联字段"
关联字段是逻辑意义一样,数据类型一样,名字可以一样也可以不一样的两个字段。比如:t_employee(A表)中did和t_department(B表)中的did。
关联字段其实就是"可以"建外键的字段。当然联合查询不要求一定建外键。
(2)关联查询必须写关联条件,关联条件的个数 = n -- 1,n是联合查询的表的数量
2个表一起联合查询,关联条件数量是1,
3个表一起联合查询,关联条件数量是2,
4个表一起联合查询,关联条件数量是3,
否则就会出现笛卡尔积现象。
(3)关联条件可以用on子句编写,也可以写到where中
但是建议用on单独编写,这样可读性更好。
每一个join后面都要加on子句。
A inner|left|right join B on 关联条件
A inner|left|right join B on 关联条件 inner|left|right join C on 关联条件
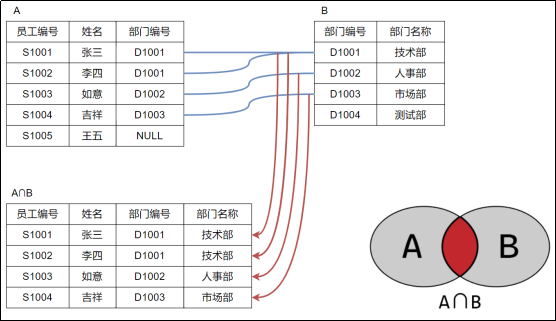
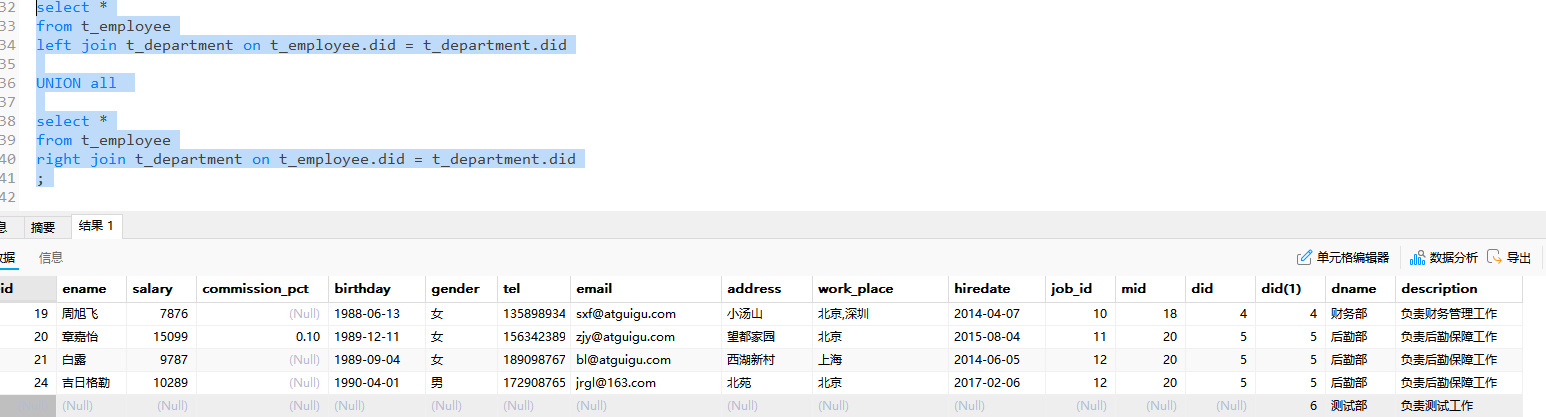
内连接
从结果来看其实内连接也就相当于扩展表,通过某种方式连接多个表,但是连接的一定是严丝合缝的,比如
这个A表中NULL,B表中不存在则不进行扩展
python
select *
from t_employee
where t_employee.did = 1;
python
select *
from t_employee
inner join t_department on t_employee.did = t_department.did
where t_department.did = 1;
select *
from t_employee
inner join t_department on t_employee.did = t_department.did
inner join t_job on t_employee.job_id = t_job.jid
where t_department.did = 1;

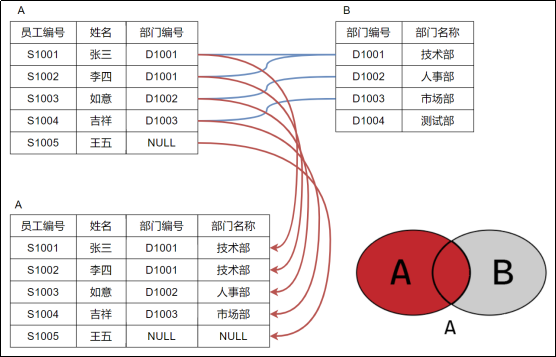
左连接
python
select *
from t_employee;
与内连接相比,多了两个A独有的
python
select *
from t_employee
left join t_department on t_employee.did = t_department.did;
python
select *
from t_employee
left join t_department on t_employee.did = t_department.did
left join t_job on t_employee.job_id = t_job.jid;
若是想去除交集部分则
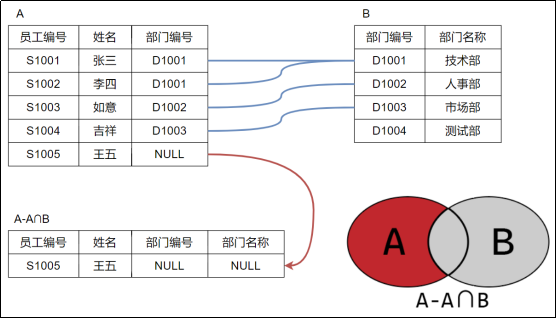
加上一个where进行筛选即可
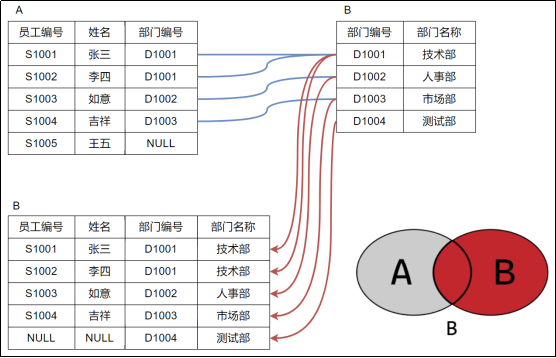
右连接
python
select *
from t_employee;
select *
from t_employee
right join t_department on t_employee.did = t_department.did;
与内连接相比多了一个B独有的


将独有的筛选出来
python
select *
from t_employee
right join t_department on t_employee.did = t_department.did
where t_employee.did is null;
union
-- union合并时要注意:
-- 两个表要查询的结果字段是一样的
-- union all 表示直接合并结果,保留重复的记录
-- union 表示合并结果时,去重
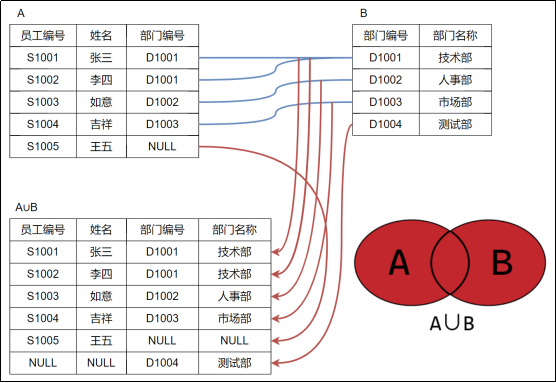
select *
from t_employee
left join t_department on t_employee.did = t_department.did
UNION
select *
from t_employee
right join t_department on t_employee.did = t_department.did
;

union all
自连接
原来一个表比如5列,自连接之后则是十列,所以其实也就是调整后面一个表的行顺序
python
use atguigu;
select
*
from t_employee as emp
inner join t_employee as mgr
on emp.mid = mgr.eid;
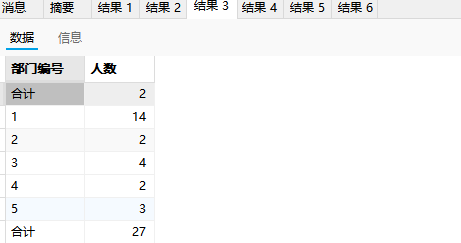
with rollup合计
python
-- 按照部门统计人数
select did,count(*)
from t_employee
group by did;
-- 按照部门统计人数,并合计总数
select did,count(*)
from t_employee
group by did with rollup;
select
ifnull(did,'合计') as "部门编号",
count(*) as "人数"
from t_employee
group by did with rollup;相当于多了最后一行汇总
多字段分组
MySQL 会把 did、job_id、gender 这三个字段的值组合起来看成一个整体。
只有当这三个字段的值完全相同,才认为是同一组。
对每一组使用 COUNT(*) 进行计数。
最终每组返回一行结果。
python
-- 按照不同的部门,不同的职位,分别统计男和女的员工人数
select did,job_id,gender,count(*)
from t_employee
group by did,job_id,gender;分组统计时,select后字段列表的问题
did = 1 这一组有两条记录(张三和李四)。
那 ename 这列到底应该显示 张三 还是 李四 呢?
MySQL 无法决定,所以就报错了(或在低版本中随机显示一个)
did 是分组字段,同一个组里 did 值一定相同。
COUNT(*) 是聚合函数,对一组数据计算出一个结果。
python
-- 分组统计时,select后面只写和分组统计有关的字段
-- 其他无关字段不要出现,否则会引起歧义
select eid,ename,did,count(*)
from t_employee
group by did;
-- eid,ename此时不应该出现在select后面
select did,count(*)
from t_employee
group by did;having
having子句后面也写条件。
where是对原表中的记录的筛选。where后面不能出现分组函数。
having是对统计结果(分组函数计算后)的筛选。having后面能出现分组函数。
python
-- 查询每一个部门薪资超过10000的男女员工的人数,显示部门编号,部门的名称,性别,人数
-- 只显示人数低于3人的
select t_department.did,dname,gender,count(eid)
from t_employee right join t_department
on t_employee.did=t_department.did
where salary>10000
group by t_department.did,gender
having count(eid)<3;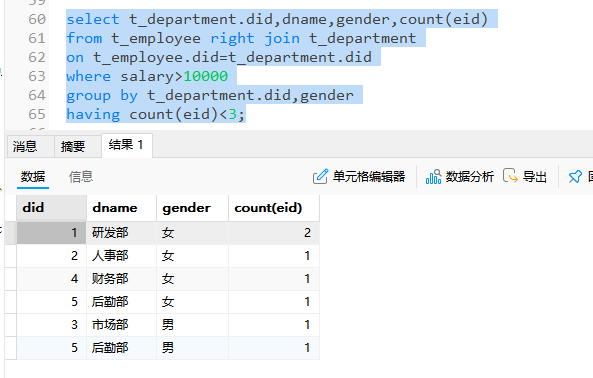
order by
asc代表升序,desc代表降序,默认升序。
python
select t_department.did,dname,gender,COUNT(*)
from t_department
LEFT JOIN t_employee
on t_department.did=t_employee.did
WHERE salary>10000
GROUP BY t_department.did,gender
HAVING COUNT(*)<3
ORDER BY count(*)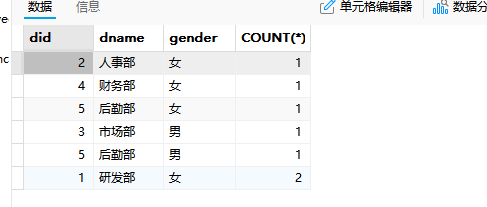
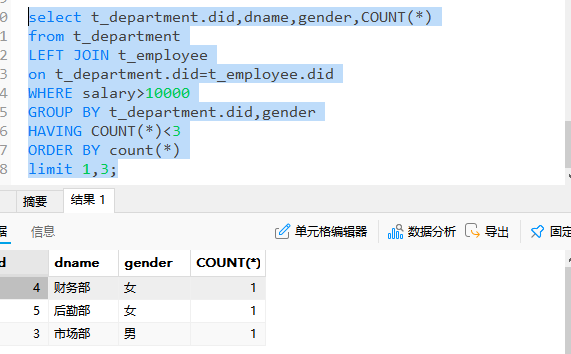
limit
limit子句是用于分页显示结果。
limit m,n:
表示从第m个记录开始找n条记录显示,其中m是从0开始的
总结
一、关联查询基础概念
关联查询 :将两个或两个以上有关联关系的表一起查询。
核心规则:
- 参与关联的表之间必须有关联字段(逻辑意义相同、数据类型一致的字段)。
- 关联条件个数 = 表数量 - 1 。否则会出现笛卡尔积(数据爆炸)。
- 关联条件推荐写在
ON子句中(可读性更好),每个JOIN后面都要跟ON。
二、连接类型
1. 内连接(INNER JOIN)
- 只返回两个表中关联条件匹配的记录(交集)。
- "严丝合缝",不匹配的记录不会出现。
示例:
sql
SELECT e.ename, d.dname, j.jname
FROM t_employee e
INNER JOIN t_department d ON e.did = d.did
INNER JOIN t_job j ON e.job_id = j.jid;2. 左连接(LEFT JOIN)
- 以左表为主 ,显示左表所有记录。
- 右表匹配不上的记录,右表字段显示为
NULL。
经典用法(查找左表中有而右表中没有的记录):
sql
SELECT *
FROM t_employee e
LEFT JOIN t_department d ON e.did = d.did
WHERE d.did IS NULL; -- 找出没有部门的员工3. 右连接(RIGHT JOIN)
- 以右表为主 ,显示右表所有记录。
- 左表匹配不上的记录,左表字段显示为
NULL。
经典用法:
sql
SELECT *
FROM t_employee e
RIGHT JOIN t_department d ON e.did = d.did
WHERE e.did IS NULL; -- 找出没有员工的部门实际开发建议 :优先使用 LEFT JOIN,逻辑更清晰易读。
三、UNION 和 UNION ALL
用于合并多个查询的结果集。
UNION:合并后自动去重,性能稍慢。UNION ALL:直接合并,保留所有记录(包括重复),性能更好。
注意 :合并的 SELECT 语句必须列数相同、顺序一致、数据类型兼容。
四、自连接(SELF JOIN)
同一个表自己与自己进行连接,常用于上下级关系 、树形结构查询。
示例(查询员工及其领导):
sql
SELECT
e.ename AS 员工,
m.ename AS 领导
FROM t_employee e
LEFT JOIN t_employee m ON e.mid = m.eid;关键 :必须给同一张表起不同别名。
五、分组查询(GROUP BY)
1. 基本用法
sql
SELECT did, COUNT(*) AS 人数
FROM t_employee
GROUP BY did;2. 多字段分组
sql
SELECT did, job_id, gender, COUNT(*)
FROM t_employee
GROUP BY did, job_id, gender;理解要点 :多个字段会组合成一个联合分组键 ,只有当所有字段的值完全相同时,才算同一组。
3. WITH ROLLUP(合计行)
sql
SELECT
IFNULL(did, '合计') AS 部门,
COUNT(*) AS 人数
FROM t_employee
GROUP BY did WITH ROLLUP;会在最后增加一行总计记录。
六、HAVING 与 WHERE 的区别
| 对比项 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 分组之前 | 分组之后 |
| 筛选对象 | 原始记录 | 分组后的统计结果 |
| 是否能用聚合函数 | 不能 | 可以(AVG、COUNT、SUM等) |
| 典型用途 | 过滤原始数据 | 过滤分组后的结果 |
记忆口诀:
WHERE 筛原始,HAVING 筛结果;
WHERE 前面过滤,HAVING 后面统计。
七、ORDER BY 与 LIMIT
ORDER BY:对最终结果进行排序。ASC(升序,默认)、DESC(降序)。LIMIT m,n:分页。从第m+1条记录开始,取n条记录(m从 0 开始)。
推荐写法:
sql
SELECT * FROM t_employee
ORDER BY salary DESC
LIMIT 20, 10; -- 第3页,每页10条八、易错点
-
关联条件个数不足
- n 张表关联,至少需要 n-1 个
ON条件,否则产生笛卡尔积,数据爆炸。
- n 张表关联,至少需要 n-1 个
-
LEFT JOIN / RIGHT JOIN 判断 NULL 时写错表
LEFT JOIN要判断右表 字段IS NULL。RIGHT JOIN要判断左表 字段IS NULL。- 这是最经典也最容易错的点。
-
GROUP BY 时 SELECT 出现非分组、非聚合字段
- 如
SELECT ename, did, COUNT(*)并GROUP BY did,会因为ename在组内不唯一而报错(only_full_group_by模式)。
- 如
-
WHERE 和 HAVING 混淆
- 在
HAVING中才能使用聚合函数(如HAVING COUNT(*) > 5)。 WHERE中使用聚合函数会直接报错。
- 在
-
UNION时列数、顺序、类型不一致- 合并的多个 SELECT 必须结构完全一致。
-
自连接忘记起别名
- 自连接必须给同一张表起不同别名,否则字段引用冲突。
-
LIMIT m,n中 m 的含义理解错误- m 是偏移量(从 0 开始),不是"第 m 条"。正确理解为"从第 m+1 条开始取 n 条"。
-
不写 ORDER BY 就使用 LIMIT 分页
- 分页结果顺序不稳定,强烈建议加上
ORDER BY。
- 分页结果顺序不稳定,强烈建议加上
-
连续使用多个 RIGHT JOIN
- 可读性极差,建议统一改写为
LEFT JOIN。
- 可读性极差,建议统一改写为
-
性能问题
- 关联字段没有索引、多表关联过多、
LIMIT偏移量过大等都会导致查询极慢。
- 关联字段没有索引、多表关联过多、