1.正则表达式:是一种用特定语法规则组成的字符串模式,用来描述、匹配或替换文本中符合某种规则的字符序列,可以理解为是专门用于文本处理的"高级查找和匹配公式"。
(1) 字符串前的r标识什么意思?
r 表示当前这个字符串中的转义字符无效,作为普通字符串使用
(2) re模块提供的如下三个函数的作用与区别 ?
match("正则表达式", "文本字符串"):从字符串的开头开始匹配
search("正则表达式", "文本字符串"):从任意位置开始,搜索第一个匹配项
findall("正则表达式", "文本字符串"):从任意位置开始,搜索所有匹配项
s1 = "18809090000是我的手机号, 你记住了吗? 我的另一个手机号是18800008888,两个QQ号分别是155998992 和 18809091293821 你记住了吗?"
s2 = "我的手机号是18809090000, 你记住了吗? 我的另一个手机号是18800008888,两个QQ号分别是155998992 和 18809091293821 你记住了吗?"
(1) match:从字符串的开头开始匹配(匹配第一个匹配项)
python
import re
s1 = "18809090000是我的手机号, 你记住了吗? 我的另一个手机号是18800008888,两个QQ号分别是155998992 和 18809091293821 你记住了吗?"
s2 = "我的手机号是18809090000, 你记住了吗? 我的另一个手机号是18800008888,两个QQ号分别是155998992 和 18809091293821 你记住了吗?"
# match - 从字符串的开头开始匹配(匹配第一个匹配项) ----> Match 对象
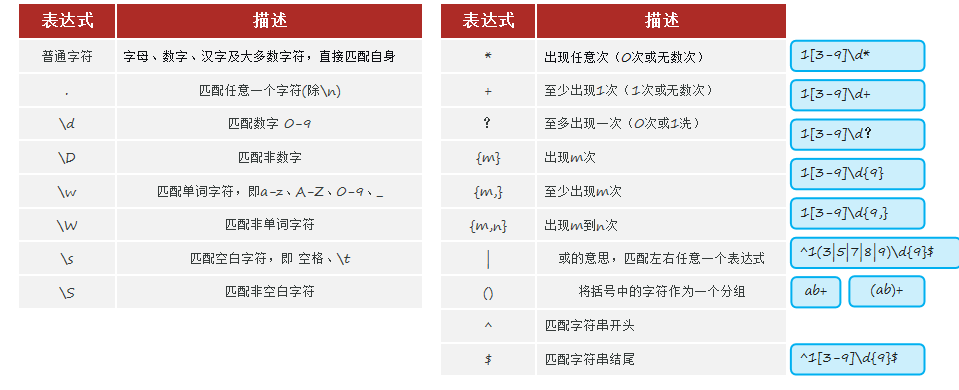
# r"1[3-9]\d{9}" 表示第1位是1(1),第2位在3-9之间([3-9]),第3-11位为数字(\d{9})
# r"1[3-9]\d{9}" ==> "1[3-9]\\d{9}" 其中r表示字符串中的反斜杠为本身含义,而不是转义字符
result = re.match(r"1[3-9]\d{9}", s1)
print(result.group()) # 获取到匹配的结果
print(result.span()) # 获取匹配项的索引
print(result.start()) # 获取匹配项的开始索引
print(result.end()) # 获取匹配项的结束索引18809090000
(0, 11)
0
11
(2) search:从任意位置开始, 搜索第一个匹配项
python
# search - 从任意位置开始, 搜索第一个匹配项 ----> Match 对象
result = re.search(r"1[3-9]\d{9}", s2)
print(result.group()) # 获取到匹配的结果
print(result.span()) # 获取匹配项的索引
print(result.start()) # 获取匹配项的开始索引
print(result.end()) # 获取匹配项的结束索引18809090000
(6, 17)
6
17
(3) findall:从任意位置开始, 搜索所有匹配项
python
# findall - 从任意位置开始, 搜索所有匹配项 ---> list
result = re.findall(r"1[3-9]\d{9}", s2)
print(result)'18809090000', '18800008888', '18809091293'
(4)
python
import re
s1 = "18809090000是我的手机号,188开头的,以00结尾的;我的另一个手机号是15500008888,两个QQ号分别是1259989092和13809091293821,邮箱为python666@163.com,请给我发邮件。"
# 正则表达式
print(re.findall(r"188.*", s1)) # * 匹配任何个 字符
print(re.findall(r"188.?", s1)) # ? 匹配0个或者1个 (最多出现一次) 字符
print(re.findall(r"188.+", s1)) # + 匹配1个或者多个 (最少出现一次) 字符(1) '18809090000是我的手机号,188开头的,以00结尾的;我的另一个手机号15500008888,两个QQ号分别是1259989092和13809091293821,邮箱为python666@163.com,请给我发邮件。'
(2) '1880', '188开'
(3) '18809090000是我的手机号,188开头的,以00结尾的;我的另一个手机号是15500008888,两个QQ号分别是1259989092和13809091293821,邮箱为python666@163.com,请给我发邮件。'
(5)
python
print(re.findall(r"188\d{8}", s1)) # {8} 匹配8个 数字
print(re.findall(r"155\d{6,10}", s1)) # {6,10} 匹配6到10个 数字
print(re.findall(r"155\d{6,}", s1)) # {6,} 匹配6个或者更多 数字'18809090000'
'15500008888'
'15500008888'
(6)
python
print(re.findall(r"1[38]\d{8}", s1)) # [38] 匹配3或者8
print(re.findall(r"1[^38]\d{8}", s1)) # [^38] 匹配非 3或者8
print(re.findall(r"1[3-9]\d{8}", s1)) # [3-9] 匹配3到9 (范围)
print(re.findall(r"^1[3-9]\d{9}", s1)) # ^ 匹配开头
print(re.findall(r"^1[3-9]\d{9}$", s1)) # $ 匹配结尾'18809090000'
'15500008888'
'15500008888'
(7)
python
print(re.findall(r"1[38]\d{8}", s1)) # [38] 匹配3或者8
print(re.findall(r"1[^38]\d{8}", s1)) # [^38] 匹配非 3或者8 (既不是3也不是8)
print(re.findall(r"1[3-9]\d{8}", s1)) # [3-9] 匹配3到9 (范围)
print(re.findall(r"^1[3-9]\d{9}", s1)) # ^ 匹配开头 (以1开头)
print(re.findall(r"^1[3-9]\d{9}$", s1)) # $ 匹配结尾 (以1为字符串开头,任意数字结尾)'1880909000', '1380909129'
'1550000888', '1259989092'
'1880909000', '1550000888', '1380909129'
'18809090000'
(8)
python
# \w 匹配任何单词字符(a-z、A-Z、0-9、_、其它语言字符) -- 默认行为
# r"\w+@\w+\.\w+" 表示 以任意个字符开头(\w+),中间必须有一个@(@),后面再有任意个字符(\w+),再有一个. (\.),最后有任意个字符(\w+)
print(re.findall(r"\w+@\w+\.\w+", s1))
# \w 匹配任何单词字符(a-z、A-Z、0-9、_)
# re.ASCII 表示只会匹配ASCII(不会匹配到中文,韩文等字符)
print(re.findall(r"\w+@\w+\.\w+", s1, re.ASCII))'邮箱为python666@163.com'
'python666@163.com'
(9)
python
s2 = "现在的时间是2026-02-06 10:05:25, 今天的天气还可以, 气温是28度 "
print(re.findall(r"\d{4}-\d{2}-\d{2}", s2))
print(re.findall(r"(\d{4})-(\d{2})-(\d{2})", s2))'2026-02-06'
('2026', '02', '06')