Cloud_Shy 陪你解读《Effective Python 3rd Edition》:从练气到老魔

大家好呀,欢迎来到博主新开的《Effective Python 3rd Edition》学习笔记系列,毕竟也读过几百篇 SCI ,这次来试试阅读原版学习是一种怎样的体验。小伙伴们感兴趣的话,请一定要点赞,收藏加关注呀!
第一章 Pythonic Thinking
Python 程序员倾向于保持清晰明了,选择简单胜于复杂,并力求提高可读性。
Item 4:编写辅助函数而不是复杂表达式
Python 简洁的语法结构使得编写可实现大量逻辑的单行表达式变得十分简便。
例如,假设我想要解码从网站 URL 中获取的查询字符串。这里每个查询字符串参数都代表一个整数值:
>>> from urllib.parse import parse_qs
>>> my_values = parse_qs("red=5&blue=0&green=", keep_blank_values = True)
>>> print(repr(my_values))
{'red': ['5'], 'blue': ['0'], 'green': ['']}这里的查询字符串参数的数量是不确定的,包含多个值,单一值,存在但值为空等情况,还可能完全缺失。对结果字典使用 get 方法时,每种情况下都会返回不同的值:
>>> print("red: ", my_values.get("red"))
red: ['5']
>>> print("Green: ", my_values.get("green"))
Green: ['']
>>> print("Opacity: ", my_values.get("opacity"))
Opacity: None如果某个参数未被提供或处于空白状态时能自动赋以默认值 0,那将会非常方便。起初我可能倾向于通过布尔表达式来实现这一点,因为感觉这种逻辑暂时还不需要用到完整的 if 语句或辅助函数。
Python 的语法使得这一选择变得异常简单。其中的诀窍在于,空字符串、空列表和零值都会隐式地评估为 False。因此,当第一个子表达式为 False 时,下面的表达式将评估为紧随运算符之后的子表达式:
>>> # For query string 'redred=5&blue=0&green='
>>> red = my_values.get("red", [""])[0] or 0
>>> green = my_values.get("green", [""])[0] or 0
>>> opacity = my_values.get("opacity", [""])[0] or 0
>>> print(f"Red: {red!r}")
Red: '5'
>>> print(f"Green: {green!r}")
Green: 0
>>> print(f"Opacity: {opacity!r}")
Opacity: 0红色之所以能正常工作,是因为关键字 "红" 存在于 my_values 字典中。通过 get 调用的方法所获取到的值是一个包含一个成员的列表:即字符串 "5"。该项是通过访问列表中的索引 0 来获取的。随后,表达式判定该字符串不为空,因此给出该操作得出的结果值。最后,赋值给变量 red 的值为 "5"。
Green 之所以能够发挥作用,是因为 my_values 字典中的值其实是一个包含一个成员的列表:一个空字符串。该列表中位于索引 0 的项被成功获取。
该表达式判定字符串为空,因此其返回值应为操作右侧的参数,即 0。最后,变量 green 被赋值为 0。
opacity 生效,是因为 my_values字典中的值完全缺失。get 的行为是,如果键在字典中不存在,则会返回其第二个参数(参见 Item 26:"优先使用 getover 和 inand KeyErrorto Handle Missing Dictionary Keys")。在此情况下,默认值是一个包含一个成员的列表:一个空字符串。因此,当字典中找不到 opacity 时,这段代码所执行的操作与绿色案例完全相同。
带有 get、""、0 和 'or' 的复杂表达式难以辨识,然而它无法满足我的全部需求。我还希望确保所有参数值都能被转换为整数,这样我就能立即在数学表达式中使用它们。为此,我采用内置函数将每个表达式包裹起来,以便将字符串解析为整数:
>>> red = int(my_values.get("red", [""]) [0] or 0)这种逻辑现在极难读懂。其中充斥着大量的视觉噪声。代码显得难以接近。刚刚阅读这段代码的人将不得不花费大量时间仔细分析其中的表达式,以弄清其实际功能。尽管保持简洁是件好事,但试图将所有内容都挤在一行内并不值得尝试。
尽管 Python 确实支持用于实现内嵌 if/else 行为的条件表达式,但在这种情况下使用它们所生成的代码与上述布尔运算符示例相比并没有明显更易理解(参见 Item 7:"考虑使用条件表达式处理简单的内嵌逻辑")
>>> red_str = my_values.get("red", [""])
>>> red = int(red_str[0]) if red_str[0] else 0另外,也可以在一连串的语句中使用完整的 if 语句来实现相同的逻辑。像这样将各个步骤逐一罗列开来,会使原本较为紧凑的版本显得更加复杂。
>>> green_str = my_values.get("green", [""])
>>> if green_str[0]:
... green = int(green_str[0])
... else:
... green = 0既然这种逻辑已扩展至多条语句中,要用于为其他变量(如红色)进行赋值时,复制和粘贴操作就会变得较为困难。如果我希望能够反复利用这一功能------哪怕只是像本示例中那样进行两到三次重复操作------那么编写一个辅助函数将是最佳选择:
>>> def get_first_int(values, key, default = 0):
... found = values.get(key, [""])
... if found[0]:
... return int(found[0])
... return default调用代码比使用 or 运算符的复杂表达式以及使用条件表达式的两行版本要清晰得多:
>>> green = get_first_int(my_values, "green")一旦你的表达变得复杂起来,就到了考虑将其分解为更小单元------如中间变量------并将逻辑移至辅助函数中的时候了。你在可读性 方面所获得的收益,始终会超过简洁性 可能带来的好处。切勿让 Python 针对复杂表达式的简洁语法令你陷入此类混乱局面。请遵循 DRY 原则 :不要自我重复。
注意:
- Python 的语法使得编写过于复杂且难以阅读的单行表达式变得非常容易。
- 将复杂的表达式移至辅助函数中,特别是当您需要重复使用相同的逻辑时。
Item 5:优先选择多重分配解包而不是索引
Python 有一个内置的元组类型,可用于创建不可变的、有序的值序列(有关类似的数据结构,请参阅 Item 56:"创建不可变对象的首选数据类")。 元组可以为空,也可以包含单个项目:
no_snack =()
snack =("chips",)元组还可以包含多个项目,如字典中的这些键/值对所示:
>>> snack_calories = {"chips": 140, "popcorn": 80, "nuts": 190,}
>>> items = list(snack_calories.items())
>>> print(items)
[('chips', 140), ('popcorn', 80), ('nuts', 190)]元组中的成员可以通过数字索引和切片来访问,就像在列表中一样:
>>> item = ("Peanut butter", "Jelly")
>>> first_item = item[0] # Index
>>> first_half = item[:1] # Slice
>>> print(first_item)
Peanut butter
>>> print(first_half)
('Peanut butter',)一旦创建了元组,您就无法通过向索引分配新值来修改它:
>>> pair = ("Chocolate", "Peanut butter")
>>> pair[0] = "Honey"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignmentPython 还有解包语法,允许在单个语句中分配多个值。 您在解包作业中指定的模式看起来很像尝试改变元组(这是不允许的),但实际上它们的工作方式完全不同。例如,如果您知道一个元组是一对,则可以将其分配给具有两个变量名称的元组,而不是使用索引来访问其值:
>>> item = ("Peanut butter", "Jelly")
>>> first, second = item # Unpacking
>>> print(first, "and", second)
Peanut butter and Jelly与访问元组索引相比,解包的视觉噪音更少,并且通常需要更少的代码行。 当分配给列表、序列和可迭代对象中任意可迭代对象的多个级别时,解包的相同模式匹配语法也有效。 我不建议在代码中执行以下操作,但了解它的可能性及其工作原理很重要:
>>> favorite_snacks ={
... "salty": ("pretzels", 100),
... "sweet": ("cookies", 180),
... "veggie": ("carrots", 20),
... }
>>> ((type1, (name1, cals1)),
... (type2, (name2, cals2)),
... (type3, (name3, cals3))) =favorite_snacks.items()
>>> print(f"Favorite {type1} is {name1} with {cals1} calories")
Favorite salty is pretzels with 100 calories
>>> print(f"Favorite {type2} is {name2} with {cals2} calories")
Favorite sweet is cookies with 180 calories
>>> print(f"Favorite {type3} is {name3} with {cals3} calories")
Favorite veggie is carrots with 20 caloriesPython 新手可能会惊讶地发现,解包甚至可以用于交换值,而无需创建临时变量。 在这里,使用带有索引的典型语法来交换列表中两个位置之间的值,作为升序排序算法的一部分:
>>> def bubble_sort(a):
... for _ in range(len(a)):
... for i in range(1, len(a)):
... if a[i] < a[i -1]:
... temp = a[i]
... a[i] = a[i -1]
... a[i -1] = temp
...
>>> names = ["pretzels", "carrots", "arugula", "bacon"]
>>> bubble_sort(names)
>>> print(names)
['arugula', 'bacon', 'carrots', 'pretzels']但是,使用解包语法,可以在一行中交换索引:
>>> def bubble_sort(a):
... for _ in range(len(a)):
... for i in range(1, len(a)):
... if a[i] < a[i - 1]:
... a[i - 1], a[i] = a[i], a[i - 1]
...
>>> names = ["pretzels", "carrots", "arugula", "bacon"]
>>> bubble_sort(names)
>>> print(names)
['arugula', 'bacon', 'carrots', 'pretzels']这种交换的工作方式是首先评估赋值的右侧 (ai, ai - 1),并将其值放入一个新的临时、未命名元组中(例如在循环的第一次迭代中的 ("carrots", "pretzels"))。然后使用赋值左侧的解包模式 (ai - 1, ai) 来接收该元组值并将其分别分配给变量名 ai - 1 和 ai。 这会将索引 0 处的 "pretzels" 替换为 "carrots",并将索引 1 处的 "carrots" 替换为 "pretzels"。最后,临时未命名元组默默消失。
解包的另一个有价值的应用是在 for 循环和类似构造的目标列表中,例如推导式和生成器表达式(请参阅 Item:"使用推导式代替映射和过滤器"和 Item 44:"考虑大型列表推导式的生成器表达式")。
例如,在这里我不使用解包来迭代一个零食列表:
>>> snacks = [("bacon", 350), ("donut", 240), ("muffin", 190)]
>>> for i in range(len(snacks)):
... item = snacks[i]
... name = item[0]
... calories = item[1]
... print(f"#{i+1}: {name} has {calories} calories")
...
#1: bacon has 350 calories
#2: donut has 240 calories
#3: muffin has 190 calories这可行,但很吵。 为了索引到 snack 结构的各个级别,需要许多额外的字符。 现在,通过使用解包和枚举内置函数来实现相同的输出(请参阅 Item 17:"优先选择枚举而不是范围"):
for rank, (name, calories) in enumerate(snacks, 1):
print(f"#{rank}: {name} has {calories} calories")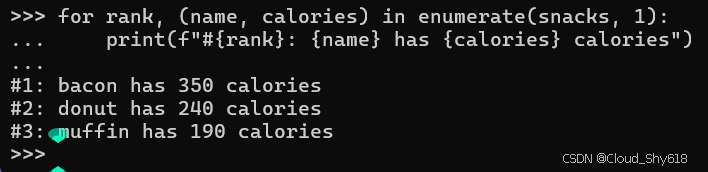
这是编写此类循环的 Pythonic 方式;它简短且易于理解。 通常不需要使用索引来访问任何内容。
Python 为列表构造提供了额外的解包功能(请参阅 Item 16:"优先于切片进行 Catch-All 解包")、函数参数(请参阅 Item 34:"使用可变位置参数减少视觉噪音")、关键字参数(请参阅 Item 35:"使用关键字参数提供可选行为")、多个返回值(请参阅 Item 31:"返回专用结果对象而不是要求函数调用者解包三个以上)变量")、结构模式匹配(参见 Item 9:"考虑流程控制中的解构匹配;避免使用 if 语句就足够了")等等。
明智地进行解包将使您能够尽可能地避免索引,从而产生更清晰、更 Pythonic 的代码。 然而,这些功能并非没有需要考虑的陷阱(请参阅 Item 6:"始终用括号包围单元素元组")。解包在赋值表达式中也不起作用(请参阅 Item 8:"使用赋值表达式防止重复")。
注意:
- Python 有称为解包的特殊语法,用于在单个语句中分配多个值。
- 解包在 Python 中得到了推广,可以应用于任何可迭代对象,包括可迭代对象中的许多级别的可迭代对象。
- 您可以通过使用解包来避免显式索引到序列中,从而减少视觉噪音并提高代码简洁性。
Item 6:始终用括号包围单元素元组
Python 中有四种元组文字值。 第一种是左括号和右括号内以逗号分隔的项目列表:
first = (1, 2, 3)第二种与第一种类似,但包含一个可选的尾随逗号,这样可以在跨多行时保持一致性并简化编辑:
second = (1, 2, 3,)
second_wrapped = (
1,
2,
3, # Optional comma
)第三种是以逗号分隔的项目列表,没有任何括号:
third = 1, 2, 3最后,第四种与第三种类似,但有一个可选的尾随逗号:
fourth = 1, 2, 3,Python 将所有这些构造视为相同的值:
assert first == second == third == fourth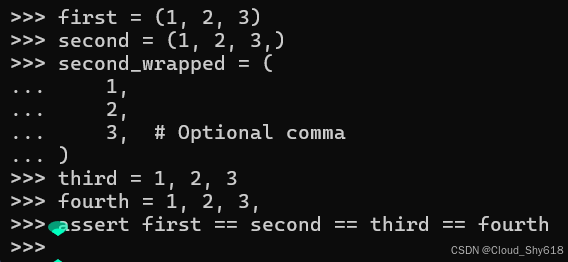
然而,创建元组时还需要考虑三种特殊情况 。 第一种情况是空元组,它只是左括号和右括号:
empty = ()第二种特殊情况是单元素 元组的形式:必须包含尾随逗号。 如果省略尾随逗号,那么您拥有的是带括号的表达式而不是元组:
single_with = (1,)
single_without = (1)
assert single_with != single_without
assert single_with[0] == single_without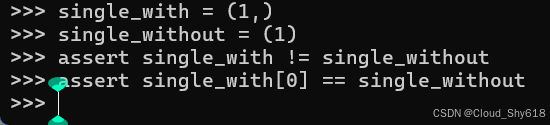
第三种特殊情况与第二种类似,只是没有括号:
single_parens = (1,)
single_no_parens = 1,
assert single_parens == single_no_parens
第三种特殊情况(不带括号的尾随逗号)可能会导致难以诊断的意外问题。 考虑来自电子商务网站的以下函数调用,该网站存在难以发现的错误:
to_refund = calculate_refund(
get_order_value(user, order.id),
get_tax(user.address, order.dest),
adjust_discount(user) + 0.1),您可能期望返回类型是整数、浮点数或小数,其中包含要退还给客户的金额。 但事实上,它是一个元组!
print(type(to_refund))
>>>
<class 'tuple'>问题是最后一行末尾多余的逗号。 删除逗号修复代码:
to_refund2 = calculate_refund(
get_order_value(user, order.id),
get_tax(user.address, order.dest),
adjust_discount(user) +0.1) # No trailing comma
print(type(to_refund2))
>>>
<class 'int'>像这样的逗号字符可能会被意外插入到您的代码中,从而导致行为发生变化,即使经过仔细检查也很难追踪到。 错误的分隔符也可能是由于编辑元组、列表、集合或函数调用中的项目而忘记删除剩余的逗号而留下的。 这种情况发生的频率比您想象的要高!
没有括号的单元素元组的另一个问题是它们不能轻松地从赋值移动到表达式中。 例如,如果我想将单元素元组 1, 复制到列表中,我必须用括号将其括起来。 如果我忘记这样做,我最终会向周围的表单而不是元组传递更多的项目或参数:
value_a = 1, # No parentheses, right
list_b = [1,] # No parentheses, wrong
list_c = [(1,)] # Parentheses, right
print('A:', value_a)
print('B:', list_b)
print('C:', list_c)
>>>
A: (1,)
B: [1]
C: [(1,)]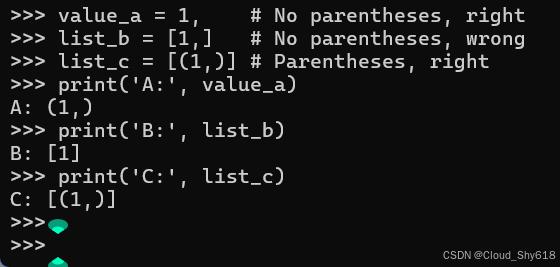
单元素元组也可以作为解包语法的一部分位于赋值的左侧(请参阅 Item 5:"优先选择多重赋值解包而不是索引"、Item 31:"返回专用结果对象而不是要求函数调用者解包超过三个变量"和 Item 16:"优先选择 Catch-All 解包而不是切片")。 令人惊讶的是,所有这些赋值都是允许的,具体取决于返回的值,但它们会产生三种不同的结果:
def get_coupon_codes(user):
...
return[['DEAL20']]
...
(a1,), = get_coupon_codes(user)
(a2,) = get_coupon_codes(user)
(a3), = get_coupon_codes(user)
(a4) = get_coupon_codes(user)
a5, = get_coupon_codes(user)
a6 = get_coupon_codes(user)
assert a1 not in (a2, a3, a4, a5, a6)
assert a2 == a3 == a5
assert a4 == a6有时,自动源代码格式化工具(请参见 Item 2:"遵循 PEP 8 风格指南")和静态分析工具(请参见 Item 3:"不要指望 Python 在编译时检测错误")可以使尾随逗号问题更加明显。 但通常情况下,直到程序或测试套件开始表现奇怪时,它才会被忽视。 避免这种情况的最佳方法是始终使用括号编写单元素元组,无论它们位于赋值的左侧还是右侧。
注意:
- Python 中的元组文字值可能具有可选的括号和可选的尾随逗号,但少数特殊情况除外。
- 单元素元组需要在它包含的一项后面有一个逗号,并且可以有可选的括号。
- 表达式末尾很容易出现无关的尾随逗号,这会将表达式的含义更改为单元素元组,从而破坏程序。