引言
高并发服务的瓶颈,很多时候不在业务逻辑,而在 IO 处理方式。如果一个线程只能盯着一个连接等数据,那连接数一上来,系统资源很快就会被耗尽。
所以理解 BIO、NIO、AIO 和 IO 多路复用,本质上是在理解:
"一个程序如何高效地同时处理大量连接。"
BIO:同步阻塞 IO
BIO 的特点很直接:
- 同步
- 阻塞
调用线程在执行读写操作时,会一直等待,直到数据准备好或者操作完成。
可以把它理解成:
"一个人盯着一个水壶,水不开就一直等。"
优点是模型简单,编码直观;缺点是线程利用率低,连接一多就很难扛住。
NIO:同步非阻塞 IO
NIO 的关键是"非阻塞"。
当应用进程发起读操作时,如果内核数据还没有准备好,不会一直卡住线程,而是立刻返回。程序可以先去做别的事,稍后再回来继续处理。
这可以理解成:
"一个人不停地轮询很多个水壶,哪个烧开了就处理哪个。"
NIO 通常会配合缓冲区和选择器一起使用。
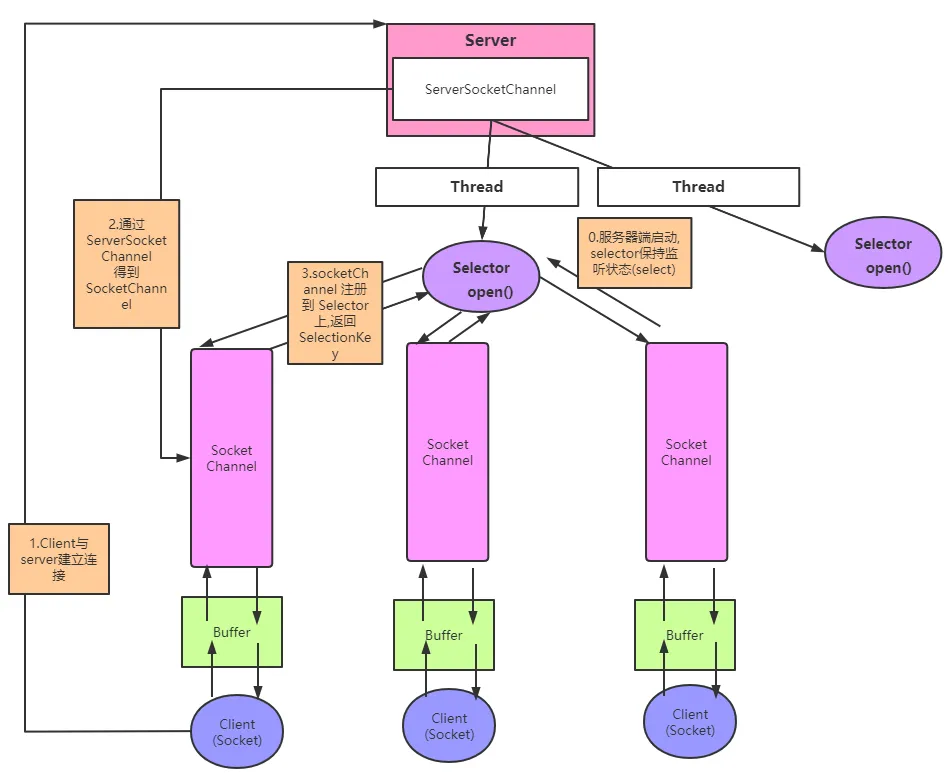
NIO 的典型流程
- 服务端通过
ServerSocketChannel接收连接。 - 把
SocketChannel注册到Selector上。 Selector监听多个通道的就绪事件。- 某个通道可读或可写时,应用程序再去处理。
- 处理完成后继续等待下一轮事件。
NIO 的核心价值是:
"一个线程可以管理多个连接,而不是一个线程只服务一个连接。"
NIO 工作流程示意图如下:
AIO:异步非阻塞 IO
AIO 比 NIO 更进一步。
NIO 虽然不阻塞,但通常仍需要应用程序主动轮询或处理就绪事件;AIO 则是由系统在 IO 完成后主动通知应用。
还是用烧水类比:
- NIO:你不断去看哪些水壶烧开了
- AIO:水壶烧开后主动叫你
AIO 的理论上限更高,但不同平台的支持成熟度和实现复杂度不完全一致,实际工程里 NIO 和基于多路复用的模型更常见。
什么是 IO 多路复用
IO 多路复用的目标是:
"让一个线程同时监听多个文件描述符,当其中某些就绪时再处理。"
常见实现有三种:
selectpollepoll
它们本质上都在做同一件事:帮助应用进程找到"哪些连接现在可以读写"。
select 的机制
select 的核心思路是使用位图结构记录要监听的文件描述符。
基本流程如下:
- 应用程序准备一个
fd_set集合。 - 调用
select,把集合从用户态拷贝到内核态。 - 内核检查哪些文件描述符已经就绪。
- 返回后,应用程序遍历整个集合,找出可读可写的描述符并处理。
select 的缺点
- 单次可监听的 fd 数量有限,常见上限是 1024
- 每次调用前都要重新设置监听集合
- 用户态和内核态之间有拷贝开销
- 每次返回后都要线性扫描所有 fd,时间复杂度是
O(N)
select 多路复用机制示意图如下:

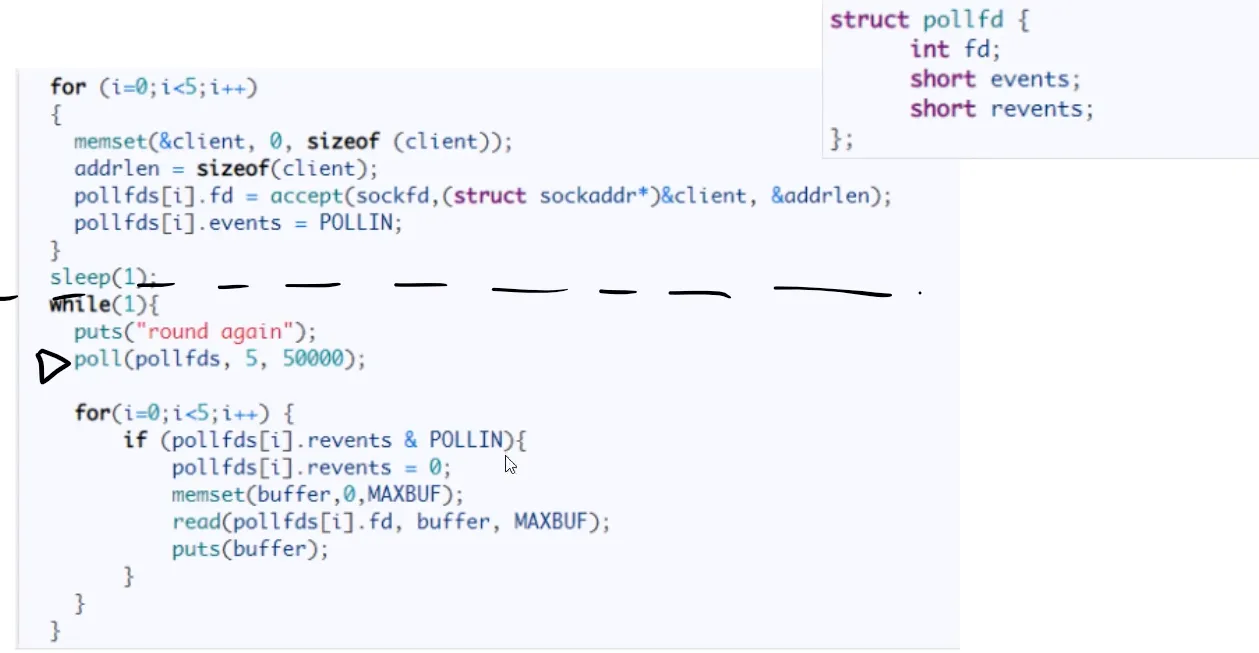
poll 的机制
poll 和 select 思路类似,但不再使用固定大小的位图,而是使用 pollfd 数组。
它解决了 select 的一个明显问题:
- 不再受 1024 个 fd 的硬限制
但它仍然有两个主要问题:
- 用户态到内核态仍然需要拷贝
- 返回后仍然要遍历整个描述符集合,复杂度仍是
O(N)
所以 poll 比 select 更灵活,但没有本质改变扫描成本。
poll 多路复用机制示意图如下:
epoll 的机制
在 Linux 下,epoll 是高并发网络编程的核心能力之一。
它的典型流程是:
epoll_create创建一个 epoll 实例epoll_ctl注册、修改或删除要监听的 fdepoll_wait等待就绪事件
epoll 的关键优势在于:
- 监听集合和就绪集合分离
- 不需要每次都把所有 fd 从用户态重新传给内核
- 返回时给出的就是就绪事件列表
因此实际处理时,只需要遍历已经就绪的那些 fd,而不是扫描全部 fd。
epoll 的优点
- 没有
select的 1024 限制 - 不需要每次重置整个监听集合
- 大量连接场景下性能更好
- 更适合高并发服务器
epoll 多路复用机制示意图如下:

三者对比
可以把三者区别总结成一句话:
select:能用,但连接数和扫描成本都比较受限poll:去掉了 fd 数量限制,但扫描问题仍在epoll:更适合海量连接场景,只关注真正就绪的事件
如何理解"同步"和"阻塞"
这两个词很容易混淆。
阻塞 vs 非阻塞
说的是当前线程在系统调用时会不会被卡住等待。
同步 vs 异步
说的是 IO 完成后,由谁来负责拿结果。
- 同步:应用自己主动处理结果
- 异步:系统完成后主动通知应用
总结
IO 模型这部分,最重要的不是背定义,而是记住下面这个演进逻辑:
- BIO:一个线程盯一个连接,简单但浪费
- NIO:线程不阻塞,可以管理多个连接
- IO 多路复用:帮助线程高效发现哪些连接就绪
- epoll:Linux 高并发场景下最常见的选择
- AIO:由系统在完成后主动通知,更偏异步
如果你后面准备继续学 Netty、Reactor 模型,这一篇就是基础前置。
如果这篇文章对你有帮助,欢迎继续阅读本系列后续内容。若文中有不准确或需要补充的地方,也欢迎指出。