【算法突围 02】树形结构与数据库索引:从 BST 到 B+ 树的演化与 MySQL 优化
📖 本文导读
为什么 1000 万数据查询,有索引只需 3 次磁盘 IO,没索引要遍历 1000 万次?MySQL 为何选择 B+ 树而非红黑树?什么是最左前缀原则和覆盖索引?
本文将沿着树的演化之路 (BST → AVL → 红黑树 → B+ 树),揭示每一步演化的痛点与解决方案 。通过图书馆检索类比 、Java 代码实现 (BST/TreeMap)、MySQL 实战(聚簇索引、二级索引、Explain 分析),带你彻底搞懂数据库索引底层原理。
适合人群:Java 后端开发、DBA、想优化 SQL 性能的开发者、准备大厂面试者。
阅读收获 :理解 B+ 树为何成为索引王者,掌握 SQL 优化技巧(最左前缀、覆盖索引、避免回表),能够自信回答"为什么 MySQL 用 B+ 树"等高频面试题。
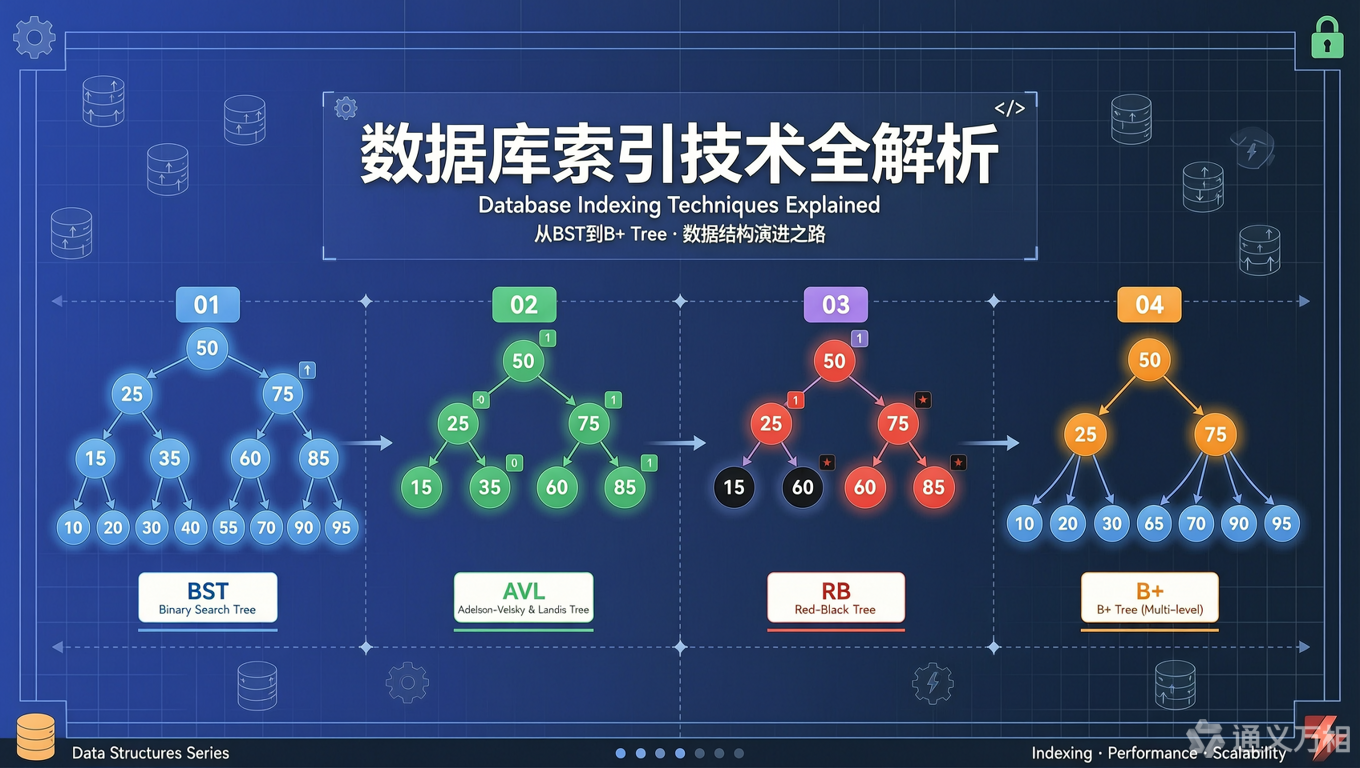
一、引言:为什么我们需要"树"?
线性结构在海量数据下的无力感
想象一下,你管理着一个拥有 1000 万条用户记录 的系统。某天产品经理说:"帮我查一下 ID 为 9527 的用户信息。"
如果你用数组 存储,最坏情况下要遍历 1000 万次才能找到------O(N) 的时间复杂度,用户早就等得不耐烦了。
如果你用哈希表 ,确实能做到 O(1) 查找,但哈希表有个致命缺陷:它无法支持范围查询。产品经理改口说:"帮我查 ID 在 9000 到 10000 之间的所有用户",哈希表就傻眼了。
图书馆的检索目录 vs 一本本翻书
这时候,树形结构登场了。
想象你去图书馆找一本书:
- 线性查找就像从第一排书架开始,一本一本地翻,直到找到目标------效率极低。
- 树形索引 就像图书馆的检索系统:先查大类(计算机),再查子类(编程语言),再查具体书名(Java)------层层筛选,快速定位。
树形结构的核心优势:
- 查找快:从 1000 万条记录中找一条,只需比较 20~30 次(log₂N)。
- 支持范围查询:天然的有序性让区间查找变得简单。
- 动态增删:插入和删除不需要像数组那样大规模移动数据。
但树的世界并非一帆风顺。从最简单的二叉搜索树,到严格平衡的 AVL 树,再到"差不多平衡就行"的红黑树,最后到数据库的王者 B+ 树------每一步演化,都是为了解决前一代的痛点。下面,我们就沿着这条演化之路,一步步揭开树形结构的奥秘。
二、二叉搜索树(BST):理想很丰满,现实很骨感
2.1 定义:左小右大
二叉搜索树(Binary Search Tree,BST)是最简单的树形结构,它遵循一个简单规则:
对于任意节点,左子树的所有节点值 < 当前节点值 < 右子树的所有节点值
50
/ \
30 70
/ \ / \
20 40 60 80查找 60 的过程:
- 从根节点 50 开始,60 > 50,去右子树。
- 来到 70,60 < 70,去左子树。
- 来到 60,找到了!
只需 3 次比较,而数组需要遍历 5 个元素。数据量越大,优势越明显。
2.2 手写简易版 BST
java
/**
* 简易版二叉搜索树
* @param <T> 必须实现 Comparable 接口,用于比较大小
*/
public class BinarySearchTree<T extends Comparable<T>> {
private Node<T> root; // 根节点
/**
* 树节点:包含数据、左孩子、右孩子
*/
private static class Node<T> {
T data;
Node<T> left, right;
Node(T data) {
this.data = data;
this.left = null;
this.right = null;
}
}
/**
* 插入节点
* 规则:小值放左边,大值放右边
*/
public void insert(T data) {
root = insertRec(root, data);
}
private Node<T> insertRec(Node<T> root, T data) {
// 找到空位置,创建新节点
if (root == null) {
return new Node<>(data);
}
// 比较大小,决定放左边还是右边
int cmp = data.compareTo(root.data);
if (cmp < 0) {
root.left = insertRec(root.left, data); // 小值放左边
} else if (cmp > 0) {
root.right = insertRec(root.right, data); // 大值放右边
}
// 相等则不插入(去重)
return root;
}
/**
* 查找节点
* 时间复杂度:O(h),h 为树的高度
*/
public boolean search(T data) {
return searchRec(root, data);
}
private boolean searchRec(Node<T> root, T data) {
if (root == null) {
return false; // 没找到
}
int cmp = data.compareTo(root.data);
if (cmp == 0) {
return true; // 找到了!
} else if (cmp < 0) {
return searchRec(root.left, data); // 去左边找
} else {
return searchRec(root.right, data); // 去右边找
}
}
}2.3 缺陷:如果数据有序,退化成链表
BST 的最大问题在于:它太依赖数据的随机性了。
如果你按顺序插入 1, 2, 3, 4, 5:
1
\
2
\
3
\
4
\
5这哪里是树?分明就是链表! 查找时间复杂度从 O(log N) 退化到 O(N)。
2.4 思考:如何保持树的"身材"平衡?
问题的根源在于:BST 没有自我平衡的机制。当一侧的节点明显多于另一侧时,树就"歪了"。
解决方案:平衡二叉树------在插入和删除时,通过旋转操作保持树的平衡,确保左右子树的高度差不超过某个阈值。
下一节,我们来看看两种经典的平衡树:AVL 树和红黑树。
三、平衡的艺术:AVL 树与红黑树
3.1 AVL 树:严格的平衡主义者
AVL 树(由 Adelson-Velsky 和 Landis 发明)是一种严格平衡的二叉搜索树,它规定:
任意节点的左右子树高度差(平衡因子)不能超过 1
平衡因子 = 左子树高度 - 右子树高度
合法值:-1, 0, 1旋转操作:保持平衡的秘诀
当插入或删除导致平衡因子超出 -1, 1 时,AVL 树会通过旋转来恢复平衡。
左旋(Left Rotation):
旋转前(右边太重): 旋转后:
30 40
\ / \
40 → 30 50
\
50右旋(Right Rotation):
旋转前(左边太重): 旋转后:
50 40
/ / \
40 → 30 50
/
30双旋(先左旋再右旋,或先右旋再左旋):
旋转前(左右不平衡): 第一步左旋: 第二步右旋:
50 50 45
/ / / \
30 → 45 → 30 50
\ /
45 30AVL 树的缺点
AVL 树的平衡条件太严格了,导致插入和删除时的旋转操作非常频繁。
- 插入一个节点,最多需要 2 次旋转。
- 删除一个节点,最坏情况下需要 O(log N) 次旋转。
结论 :AVL 树适合读多写少的场景。如果频繁插入删除,旋转开销会成为性能瓶颈。
3.2 红黑树:"差不多平衡就行"
红黑树(Red-Black Tree)是一种弱平衡的二叉搜索树,它放宽了平衡条件,换取更少的旋转次数。
五大性质(通俗版)
-
节点只有红黑两色:每个节点要么是红色,要么是黑色。
-
根节点是黑色:就像家族族长,必须是"黑脸"。
-
叶子节点(NIL)是黑色:所有的空指针都视为黑色叶子。
-
红节点的孩子必须是黑色 :不能有两个连续的红色节点(红爸爸不能有红儿子)。
-
从根到任意叶子的黑节点数相同 :黑色完美平衡。
[30B] ← 根节点是黑色 / \ [20R] [40R] ← 红节点的孩子是黑色 / \ / \[10B] NIL NIL [50B] ← 黑节点高度相同(都是 2)
为什么红黑树旋转次数少?
红黑树的平衡条件是**"黑色完美平衡"**,而不是"高度完美平衡"。这意味着:
- 最长路径(红黑交替)不会超过最短路径(全黑)的 2 倍。
- 树的高度最多是 2log(N+1),仍然是 O(log N) 级别。
- 插入时最多 2 次旋转,删除时最多 3 次旋转。
结论 :红黑树的统计性能更优,适合频繁插入删除的场景。
3.3 JDK 中的应用
TreeMap:有序的键值对存储
java
// TreeMap 底层就是红黑树
TreeMap<Integer, String> map = new TreeMap<>();
map.put(50, "Apple");
map.put(30, "Banana");
map.put(70, "Cherry");
map.put(20, "Date");
map.put(40, "Elderberry");
// 天然有序!遍历时按 Key 排序输出
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " -> " + entry.getValue());
}
// 输出:
// 20 -> Date
// 30 -> Banana
// 40 -> Elderberry
// 50 -> Apple
// 70 -> Cherry
// 范围查询:查找 30 到 60 之间的所有键值对
Map<Integer, String> subMap = map.subMap(30, 60);
System.out.println(subMap); // {30=Banana, 40=Elderberry, 50=Apple}TreeMap 适用场景:
- 需要按键排序遍历的场景。
- 需要范围查询(subMap、headMap、tailMap)的场景。
- 实现一致性哈希算法的虚拟节点映射。
TreeSet:有序集合
java
// TreeSet 底层也是红黑树(基于 TreeMap)
TreeSet<Integer> set = new TreeSet<>();
set.add(50);
set.add(30);
set.add(70);
set.add(20);
set.add(40);
// 自动去重 + 自动排序
System.out.println(set); // [20, 30, 40, 50, 70]
// 获取最小/最大值
System.out.println(set.first()); // 20
System.out.println(set.last()); // 70
// 获取大于 35 的最小元素
System.out.println(set.higher(35)); // 40
// 获取小于 45 的最大元素
System.out.println(set.lower(45)); // 40TreeSet 适用场景:
- 需要自动排序 + 去重的场景。
- 实现滑动窗口中的有序数据结构。
- 排行榜、Top K 问题。
HashMap 桶内的红黑树
JDK 8 中,当 HashMap 某个桶的链表长度超过 8 时,会转换为红黑树,将查询时间从 O(N) 优化到 O(log N)。
3.4 三种树的特性对比
| 特性 | 二叉搜索树 (BST) | AVL 树 | 红黑树 |
|---|---|---|---|
| 平衡条件 | 无 | 严格(高度差 ≤ 1) | 宽松(黑高相同) |
| 查找时间 | O(N) 最坏 | O(log N) | O(log N) |
| 插入旋转 | 0 次 | 最多 2 次 | 最多 2 次 |
| 删除旋转 | 0 次 | 最多 O(log N) 次 | 最多 3 次 |
| 实现复杂度 | 简单 | 中等 | 较复杂 |
| 适用场景 | 数据随机 | 读多写少 | 读写均衡 |
| JDK 应用 | 无 | 无 | TreeMap、TreeSet、HashMap |
四、数据库的王者:B+ 树
4.1 为什么 MySQL 不用红黑树?
红黑树在内存中表现优异,但数据库的数据是存储在磁盘上的。磁盘 IO 是数据库性能的瓶颈,而红黑树有一个致命缺陷:
树太高,导致磁盘 IO 次数太多。
假设:
- 红黑树每个节点存 1 条数据。
- 数据量为 1000 万。
- 树的高度约为 log₂(1000万) ≈ 24 层。
这意味着一次查询最多需要 24 次磁盘 IO!每次 IO 耗时约 10ms,总耗时 240ms------用户早就等得不耐烦了。
4.2 B+ 树的结构:矮胖的"多路查找树"
B+ 树(B-Tree 的变种)是专门为磁盘存储设计的树形结构,它的核心特点是:
特点 1:多路查找(矮胖身材)
B+ 树的每个节点可以存多个键值 ,不再是二叉,而是多叉。
MySQL 默认页大小:16KB
假设每个键值对占 16 字节
一个节点可以存:16KB / 16B = 1024 个键值
树的高度计算:
- 第 1 层:1024 个键值
- 第 2 层:1024² ≈ 100 万个键值
- 第 3 层:1024³ ≈ 10 亿个键值
1000 万数据只需要 3 层!3 层 B+ 树 vs 24 层红黑树 :磁盘 IO 次数从 24 次降到 3 次,性能提升 8 倍!
特点 2:叶子节点存数据,非叶子节点存索引
非叶子节点(只存索引,不存数据):
┌─────────────────────────────────────┐
│ [10 | 20 | 30 | 40 | 50 | ... | 100] │ ← 只存 Key,用于导航
└─────────────────────────────────────┘
↓ ↓ ↓ ↓ ↓ ↓
指向下一层的指针
叶子节点(存实际数据,且按 Key 排序):
┌─────────────────────────────────────────────┐
│ [10→数据] [11→数据] [12→数据] ... [20→数据] │ ← 存 Key + 数据
└─────────────────────────────────────────────┘
↓
指向相邻叶子节点的指针(双向链表)好处:
- 非叶子节点可以存更多索引(因为不存数据),树更矮。
- 所有数据都在叶子节点,查询性能稳定(每次都要走到叶子)。
特点 3:叶子节点之间的双向链表(范围查询神器)
叶子节点链表:
[1→数据] ←→ [2→数据] ←→ [3→数据] ←→ ... ←→ [100→数据]范围查询 (如 WHERE id BETWEEN 10 AND 20):
- 通过 B+ 树找到 10。
- 顺着链表往后遍历,直到 20。
- 不需要再回到根节点!
时间复杂度:O(log N + M),M 是范围内的数据量。
4.3 聚簇索引 vs 二级索引
聚簇索引(Clustered Index):数据就是索引
类比:字典的拼音目录
拼音目录:
A → 啊、阿、吖...
B → 吧、把、爸...
特点:
- 叶子节点直接存完整数据行。
- 一张表只能有一个聚簇索引(因为数据只能有一种物理排序方式)。
- InnoDB 的主键索引就是聚簇索引。聚簇索引的叶子节点:
┌──────────────────────────────────────────────┐
│ Key=1 │ 完整数据行 (id, name, age, email...) │
├──────────────────────────────────────────────┤
│ Key=2 │ 完整数据行 (id, name, age, email...) │
├──────────────────────────────────────────────┤
│ Key=3 │ 完整数据行 (id, name, age, email...) │
└──────────────────────────────────────────────┘二级索引(Secondary Index):索引和数据分离
类比:字典的部首目录
部首目录:
亻 → 人(第 234 页)、你(第 567 页)、他(第 789 页)...
特点:
- 叶子节点存的是**主键值**,而不是完整数据。
- 通过二级索引找到主键后,需要**回表**查询聚簇索引获取完整数据。二级索引的叶子节点:
┌─────────────────────────────┐
│ Key='Alice' │ 对应的主键=42 │
├─────────────────────────────┤
│ Key='Bob' │ 对应的主键=17 │
├─────────────────────────────┤
│ Key='Carol' │ 对应的主键=88 │
└─────────────────────────────┘回表查询(回表)
sql
SELECT * FROM users WHERE name = 'Alice';执行过程:
- 在
name的二级索引中找到'Alice',拿到主键42。 - 回到聚簇索引,根据主键
42找到完整数据行。 - 返回结果。
这就是"回表"------通过二级索引找到主键,再通过主键找到数据。
如何避免回表? 使用覆盖索引(后面实战部分详细讲)。
4.4 B+ 树 vs B 树
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 所有节点都存数据 | 只有叶子节点存数据 |
| 叶子节点链表 | 无 | 有(双向链表) |
| 范围查询 | 需要中序遍历,复杂 | 直接遍历链表,简单高效 |
| 树的高度 | 相对较高 | 更矮(非叶子节点不存数据) |
| MySQL 使用 | 不使用 | InnoDB 默认索引结构 |
五、实战:如何利用索引原理优化 SQL?
5.1 最左前缀原则
假设创建了联合索引:
sql
CREATE INDEX idx_abc ON users (a, b, c);索引的排序逻辑 :先按 a 排序,a 相同再按 b 排序,b 相同再按 c 排序。
索引结构示意:
(a=1, b=1, c=1)
(a=1, b=1, c=2)
(a=1, b=2, c=1)
(a=2, b=1, c=1)
...能用到索引的查询:
sql
WHERE a = 1 -- ✓ 用到索引第 1 列
WHERE a = 1 AND b = 2 -- ✓ 用到索引第 1、2 列
WHERE a = 1 AND b = 2 AND c = 3 -- ✓ 用到索引全部列
WHERE a = 1 AND c = 3 -- ✓ 只用到第 1 列(b 缺失,c 无法使用)不能用到索引的查询:
sql
WHERE b = 2 -- ✗ 缺少第 1 列 a
WHERE b = 2 AND c = 3 -- ✗ 缺少第 1 列 a
WHERE c = 3 -- ✗ 缺少第 1、2 列为什么 WHERE b = 2 不能用到索引?
因为索引是按 (a, b, c) 排序的,不知道 a 的值,就无法定位 b 的位置。就像字典的拼音目录,你不告诉我是哪个字母开头,我怎么找"ba"在哪里?
5.2 覆盖索引:避免回表
sql
-- 表结构
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
email VARCHAR(100),
INDEX idx_name (name)
);
-- 查询 1:SELECT *
SELECT * FROM users WHERE name = 'Alice';
-- 执行过程:
-- 1. 在 idx_name 索引中找到 'Alice',拿到主键 id
-- 2. 回表查询聚簇索引,获取完整数据行
-- 3. 返回结果
-- 查询 2:只查索引列
SELECT name FROM users WHERE name = 'Alice';
-- 执行过程:
-- 1. 在 idx_name 索引中找到 'Alice'
-- 2. 直接返回 name(索引中已有,无需回表)
-- 这就是"覆盖索引"!覆盖索引的好处:
- 避免回表查询,减少一次磁盘 IO。
- 查询速度提升 2~3 倍。
实战技巧:
sql
-- 创建覆盖索引
CREATE INDEX idx_name_age ON users (name, age);
-- 查询可以覆盖
SELECT name, age FROM users WHERE name = 'Alice';
-- name 和 age 都在索引中,无需回表5.3 Explain 执行计划简单解读
sql
EXPLAIN SELECT * FROM users WHERE name = 'Alice';关键字段解读:
| 字段 | 含义 | 优化建议 |
|---|---|---|
| type | 访问类型 | system > const > eq_ref > ref > range > index > ALL。尽量避免 ALL(全表扫描) |
| possible_keys | 可能用到的索引 | 如果为空,说明没有可用索引 |
| key | 实际用到的索引 | 如果为空,说明没走索引 |
| rows | 预估扫描行数 | 越小越好 |
| Extra | 额外信息 | Using index 表示覆盖索引;Using where 表示回表过滤;Using filesort 表示需要排序,可能需优化 |
示例分析:
sql
EXPLAIN SELECT * FROM users WHERE age > 20;
-- type: ALL ← 全表扫描,糟糕!
-- rows: 1000000 ← 扫描了 100 万行
-- Extra: Using where
-- 优化:给 age 加索引
CREATE INDEX idx_age ON users (age);
EXPLAIN SELECT * FROM users WHERE age > 20;
-- type: range ← 范围查询,好!
-- key: idx_age ← 用到了索引
-- rows: 50000 ← 只扫描 5 万行六、总结与思维导图
树的演化路线图
二叉搜索树 (BST)
↓ 问题:数据有序时退化成链表
AVL 树
↓ 问题:旋转太频繁,写性能差
红黑树
↓ 问题:树太高,磁盘 IO 次数多
B+ 树 ← 数据库索引的王者面试高频点速查
1. B+ 树与 B 树的区别?
- B 树的所有节点都存数据;B+ 树只有叶子节点存数据。
- B+ 树的叶子节点之间有双向链表,支持高效范围查询。
- B+ 树的非叶子节点可以存更多索引,树更矮,磁盘 IO 更少。
2. 红黑树的五大性质?
- 节点只有红黑两色。
- 根节点是黑色。
- 叶子节点(NIL)是黑色。
- 红节点的孩子必须是黑色(不能有两个连续红节点)。
- 从根到任意叶子的黑节点数相同(黑色完美平衡)。
3. 为什么 MySQL 用 B+ 树而不用红黑树?
- 红黑树是二叉树,树太高,磁盘 IO 次数多。
- B+ 树是多路树,更矮胖,磁盘 IO 次数少。
- B+ 树的叶子节点链表支持高效范围查询。
4. 什么是最左前缀原则?
联合索引
(a, b, c)只能用于查询条件中包含a的情况。如果查询条件只有b或c,无法使用索引。
5. 什么是覆盖索引?
查询的字段都在索引中,不需要回表查询聚簇索引。可以减少一次磁盘 IO,提升查询性能。
思维导图
树形结构与数据库索引
├── 二叉搜索树 (BST)
│ ├── 左小右大
│ └── 缺陷:有序数据退化成链表
│
├── 平衡树
│ ├── AVL 树
│ │ ├── 严格平衡(高度差 ≤ 1)
│ │ └── 旋转频繁,写性能差
│ │
│ └── 红黑树
│ ├── 弱平衡(黑高相同)
│ ├── 五大性质
│ └── JDK 应用:TreeMap、TreeSet、HashMap
│
└── B+ 树(数据库索引)
├── 多路查找(矮胖)
├── 叶子节点存数据 + 双向链表
├── 聚簇索引(数据即索引)
├── 二级索引(需回表)
└── SQL 优化
├── 最左前缀原则
├── 覆盖索引
└── Explain 分析最后的话 :从 BST 到 B+ 树,每一步演化都是为了解决前一代的痛点。理解这些演化背后的原因,比死记硬背定义更重要。下次面试被问到"为什么 MySQL 用 B+ 树"时,你可以自信地说:"因为磁盘 IO 太贵,B+ 树够矮够胖,还能高效范围查询!"