一、问题的起点:三个系统,三个"昨天"
去年底,我们对接了一家华中地区的装备制造企业。年产值50亿,信息化的底子不算差------SAP管采购、WMS管库存、自研MySQL系统管订单。三套系统各自运转正常,但一旦涉及跨部门协作,问题就暴露无遗。
生产调度部门每天早上做的第一件事,是导出WMS的库存报表和SAP的采购在途数据,手工对Excel,然后安排当天的排产计划。这套流程有两个致命问题:
-
数据滞后一个完整业务日。WMS的库存快照是T-1日23:59生成的,但夜班产线可能已经消耗了大量物料。调度员看到的"可用库存",和仓库实物的差异经常在15%以上。
-
人工对表本身就是风险源。SKU超过8000个,供应商200余家,采购、仓储、生产三方的"版本"几乎不可能对齐。有一次因为采购系统未及时更新交期变更,导致一条产线停工4小时。
这并非个例。据行业调研,超过70%的制造企业正在经历数据孤岛带来的效率瓶颈。区别在于,这家企业决定不再忍了。
二、诊断:为什么传统ETL"治不好"这个病?
在介入之前,企业IT团队已经尝试过用定时任务解决问题。具体方案是:每天凌晨通过Kettle从WMS和SAP抽取数据,写入MySQL,生成汇总视图供第二天使用。
这套方案在业务量小的时候还能凑合,但问题在于它从架构层面就决定了上限:
1.定时批处理(现状)
-
每天只跑一次,数据永远是"昨天的"
-
全量抽取,数据库I/O压力巨大
-
凌晨跑批失败 → 第二天没数据可用
-
新接入一个数据源要改2天调度脚本
2.CDC实时同步(目标)
-
变更即同步,数据延迟降至秒级
-
仅传输增量变更,资源消耗极低
-
断点续传,网络抖动不丢数据
-
新增数据源可视化配置,30分钟上线
核心矛盾很清楚:传统ETL的设计假设是"人等数据"------每天看一次报表就够了。但制造业供应链的决策节奏,已经从"日级"加速到了"小时级"甚至"分钟级"。
三、CDC落地:从Binlog监听到断点续传
CDC是整个方案中最关键的一环,也是最容易出现坑的地方。以下是我们在落地过程中的几个关键决策和技术细节。
1.日志位点 vs 时间戳:同步坐标的选择
CDC需要知道"上次同步到哪里了"。常见的有两种方式:
| 维度 | 时间戳方式 | 日志位点方式 |
|---|---|---|
| 原理 | 记录 update_time 字段 | 记录 Binlog/WAL 的 offset |
| 数据遗漏风险 | 高------同一毫秒内多条变更可能丢失 | 无------日志天然有序 |
| 对源表要求 | 必须有 update_time 字段 | 无特殊要求 |
| 性能影响 | 需给源表加索引 | 无------读日志而非查表 |
结论:日志位点方式在所有维度上都优于时间戳。我们最终选用了基于Binlog offset的增量同步策略,这同样是目前Debezium、Canal、Flink CDC等主流CDC框架的标准做法。
2.断点续传:网络抖动怎么办?
制造业的生产环境网络并不总是稳定的。车间到机房的链路偶尔会有几百毫秒的抖动,极端情况下甚至会断连几秒。
我们的CDC引擎内置了断点续传机制:
plaintext
-- 断点续传的核心逻辑(伪代码)
-- 1. 同步前,从位点记录表中读取上次的 Binlog offset
SELECT binlog_file, binlog_position
FROM cdc_checkpoint
WHERE source = 'wms_sqlserver';
-- 2. 从该 offset 开始消费变更数据
-- 3. 每消费一批数据,更新位点
UPDATE cdc_checkpoint
SET binlog_file = 'mysql-bin.001234',
binlog_position = 45678,
updated_at = NOW()
WHERE source = 'wms_sqlserver';这保证了即使网络中断5分钟甚至5小时,恢复后也会从断点继续消费,不会重复处理,也不会丢失任何变更。在半年的运行中,这套机制经受住了3次机房网络割接和1次SQL Server主从切换的考验。
3.数据一致性:如何处理"先删后插"的更新?
SAP在更新一条采购单时,常见的做法是先DELETE再INSERT。如果在两次Binlog事件之间发生消费中断,下游可能会短暂看到"采购单消失了"。
解决方案是在CDC引擎层面引入事务合并窗口:同一个事务内的多条变更(DELETE + INSERT),在下游合并为一条UPDATE处理。这个窗口通常设置为500ms,足以覆盖绝大多数事务场景,同时对实时性的影响可以忽略不计。
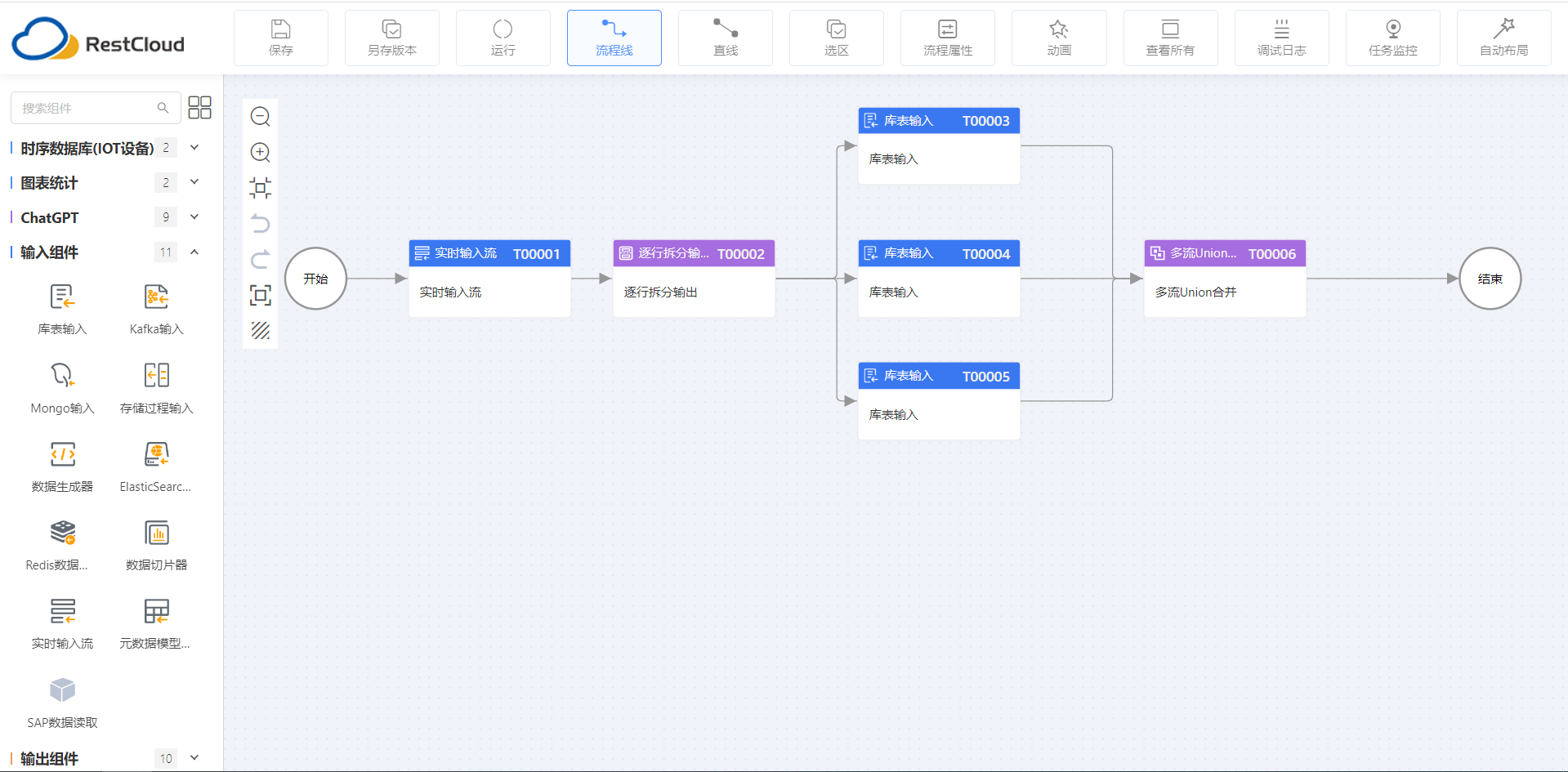
可视化流程编排:通过拖拽组件即可完成从数据抽取、转换到加载的全流程配置:
四、效果验证:数字不会说谎
项目分两期上线。一期覆盖WMS和MySQL订单系统的实时同步,二期接入SAP。以下是运行3个月后的核心数据:
| 指标 | 改造前(Kettle批处理) | 改造后(CDC实时同步) | 提升幅度 |
|---|---|---|---|
| 数据同步延迟 | T+1(24小时) | ≤500ms | 提升 99.99% |
| 单次传输数据量 | 全量(约2.3GB/次) | 仅增量(平均8KB/次) | 降低 99.7% |
| 源数据库I/O压力 | 凌晨跑批时CPU峰值80% | 日常CPU增量<3% | 大幅降低 |
| 同步失败恢复 | 人工排查,平均2小时 | 自动断点续传 | MTTR → 0 |
| 新数据源接入周期 | 3-5天(写脚本+调试) | 半天(可视化配置) | 缩短 90% |
但最有价值的不是这些技术指标,而是业务层面的改变:
-
库存准确率从87%提升到98.6%。调度员不再需要手工对表,排产计划直接基于实时库存数据生成。
-
物料短缺预警提前了8小时。以前是"仓库反馈缺料了才急调",现在是系统自动检测到库存水位低于安全阈值,提前触发采购补单。
-
月度库存周转率提升了12%。因为数据透明度的提高,采购部门能更精确地控制安全库存量,释放了约300万的沉淀资金。
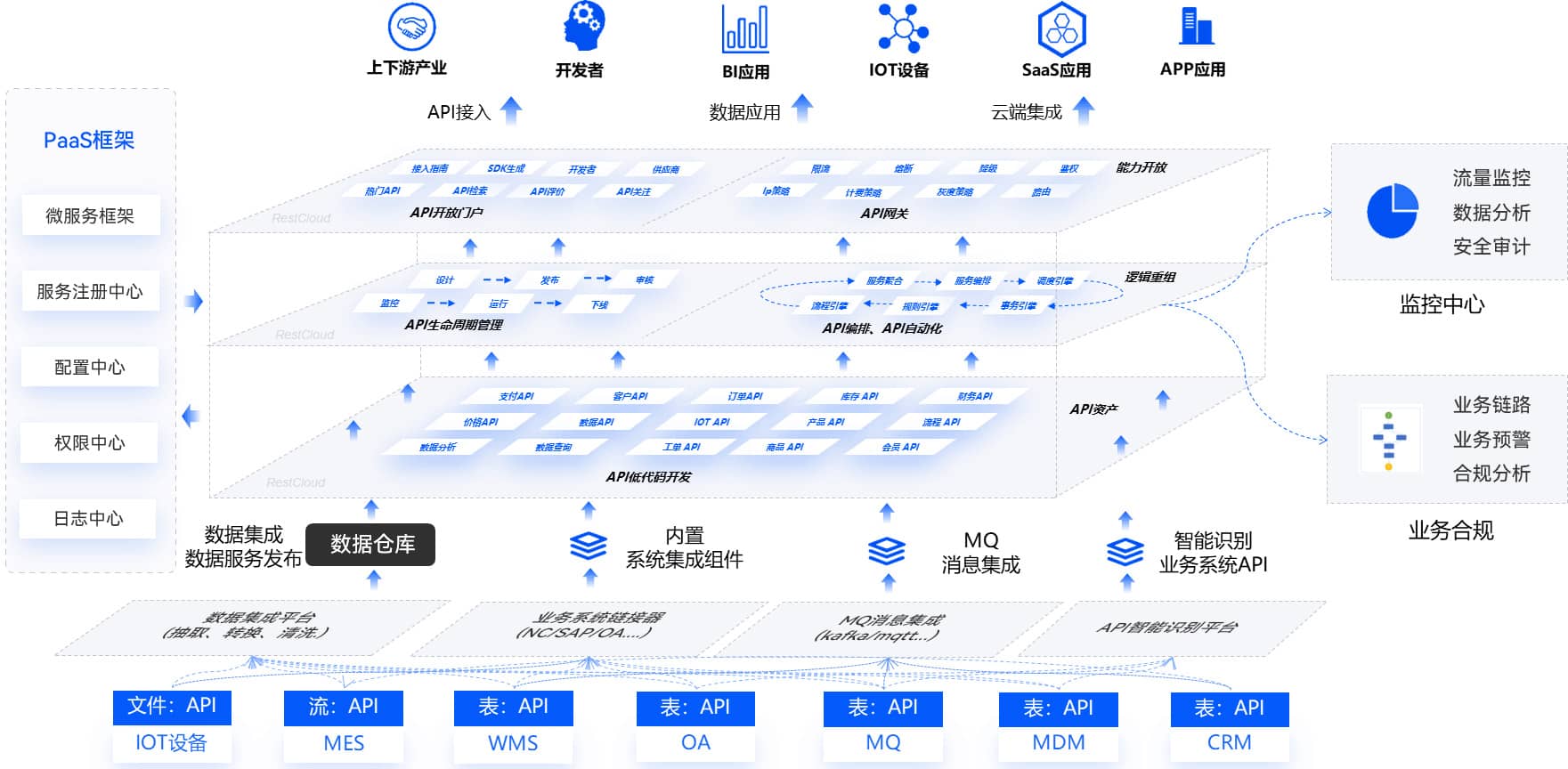
数据集成+API服务的统一平台架构,支撑从数据采集到服务化交付的完整链路:
五、选型复盘:技术方案的关键取舍
在技术选型阶段,团队内部有过几次比较激烈的讨论,这里把核心取舍摊开来说。
CDC框架选型
| 方案 | 类型 | 优势 | 问题 | 最终结论 |
|---|---|---|---|---|
| Debezium + Kafka | 开源组合 | 生态成熟,多消费者场景强 | 运维复杂度高,需要维护Kafka集群 | 过重------企业没有多消费者需求 |
| Canal + 自研消费端 | 开源 | 轻量,国内社区活跃 | 仅支持MySQL,需要自建消费框架 | 覆盖不全------WMS用的SQL Server |
| Flink CDC | 开源 | 流批一体能力强 | 学习曲线陡,JVM运维成本高 | 大材小用------不需要复杂流计算 |
| ETLCloud 内置CDC | 国产商业 | 多源支持、可视化配置、断点续传内置 | 商业产品需评估成本 | ✅ 最终选择------社区版免费可用 |
选择ETLCloud内置CDC的核心原因有三点:
-
多数据源原生支持。SAP(通过RFC/IDoc)、SQL Server(通过CDC特性)、MySQL(通过Binlog),一套平台全覆盖,不需要分别部署三套CDC工具。
-
可视化配置降低了运维门槛。企业数据团队只有4个人,没有专职的Kafka运维工程师。ETLCloud的Web化配置让数据工程师可以直接上手,不需要学习新框架。
-
社区版无功能阉割。CDC能力、断点续传、多数据源支持全部包含在免费版中,这在国内ETL产品中相当少见。
六、踩坑记录:三个真实教训
教训一:SQL Server CDC必须先启用数据库级特性
WMS用的SQL Server 2019,CDC功能需要数据库级别和表级别分别启用。我们在测试环境一切正常,到了生产环境报错------生产库DBA没有执行 sys.sp_cdc_enable_db。浪费了半天时间排查。
plaintext
-- SQL Server 启用CDC(必须在源库执行)
USE [WMS_Database];
GO
-- 启用数据库级CDC
EXEC sys.sp_cdc_enable_db;
GO
-- 启用表级CDC
EXEC sys.sp_cdc_enable_table
@source_schema = 'dbo',
@source_name = 'inventory_master',
@role_name = NULL;
GO教训二:大事务合并窗口不能设置过大
前面提到用500ms的事务合并窗口处理SAP的"先删后插"。测试时我们发现,如果把窗口设到5秒,某些批量操作的实时性会明显下降------比如仓库的一次批量入库300条记录,下游要等5秒才能看到全部数据。500ms是一个比较合理的平衡点。
教训三:API层的权限设计要前置
第一期上线后,物流部门直接调用了采购系统的API查看供应商信息。这不是技术bug,而是权限模型设计时没有把"部门数据隔离"考虑进去。后来补充了RBAC权限矩阵:
plaintext
-- API权限控制示例
-- 采购部门:只能访问采购单和供应商相关API
GRANT API_ACCESS ON '/api/supply-chain/purchase/*' TO ROLE 'procurement';
GRANT API_ACCESS ON '/api/supply-chain/supplier/*' TO ROLE 'procurement';
-- 生产调度:只能访问库存和生产相关API
GRANT API_ACCESS ON '/api/supply-chain/inventory/*' TO ROLE 'production';
GRANT API_ACCESS ON '/api/supply-chain/schedule/*' TO ROLE 'production';
-- 物流部门:只能访问发货和追踪相关API
GRANT API_ACCESS ON '/api/supply-chain/shipping/*' TO ROLE 'logistics';七、总结
回顾整个项目,从需求诊断到架构设计,从CDC选型到API服务化交付,有几个核心认知值得分享:
-
数据集成的目标不是"同步数据",而是"让数据能在正确的时间出现在正确的地方"。T+1的报表对月度复盘有用,但T+0的实时数据才能避免产线停工。
-
架构选型要克制,不要为了技术而技术。企业数据团队4个人,上Debezium+Kafka+Flink全套方案技术上没问题,但运维负担会压垮团队。选择匹配团队能力的方案,比选择"最先进"的方案更重要。
-
CDC是2026年数据集成的基础设施,不是可选功能。就像网络从拨号升级到宽带一样,实时数据同步正在从"锦上添花"变成"不可或缺"。
-
国产数据集成工具已经可以替代传统商业ETL。从功能覆盖度到易用性,国产平台已经没有明显短板,加上信创适配和本地化服务,选型逻辑正在发生变化。
如果你的企业也在面临类似的数据孤岛问题,建议从最小可行的CDC同步开始,先打通一个核心数据链路(比如库存),验证效果后再逐步扩展。千里之行,始于足下。