RAG与Agent性能调优:第8节:打造可配置,可扩展的自动化预处理流水线
Gitee地址:https://gitee.com/agiforgagaplus/OptiRAGAgent
文章详情目录:RAG与Agent性能调优
上一节:第9节:FAISS,HNSW还是BM25?如何选择最适合业务的向量检索引擎?如何选择最适合业务的向量检索引擎
下一节:第11节:HNSW参数调优难?掌握SQ8量化压缩技术实现速度与准确率平衡
混合检索的作用
混合检索结合关键词匹配和语义搜索的优势,提供更准确与上下文更有关的内容,进而让检索更加全面
混合检索的架构
混合检索架构通常包括关键词匹配、语义搜索和结果重排序等组件
关键词匹配:使用BM25等传统的关键词匹配算法,快速筛选与查询关键词相关的文档
语义搜索:利用向量空间模型,将文档和查询转换为向量表示,通过云弦相似度计算文档与查询的相似性
结果重排序:根据关键词匹配和语义搜索的结果,通过模型学习调整结果的排名顺序提升与查询相关较高的文档排名靠前
混合检索的效果
混合检索的效果通常取决于架构设计、数据质量和模型训练
较高的召回率:通过关键词匹配和语义搜索的组合,能够更加全面的筛选相关文档,提升召回率
较高的准确性:通过结果重排序模型提更与查询相关的文档排名靠前的准确率,提升用户体验
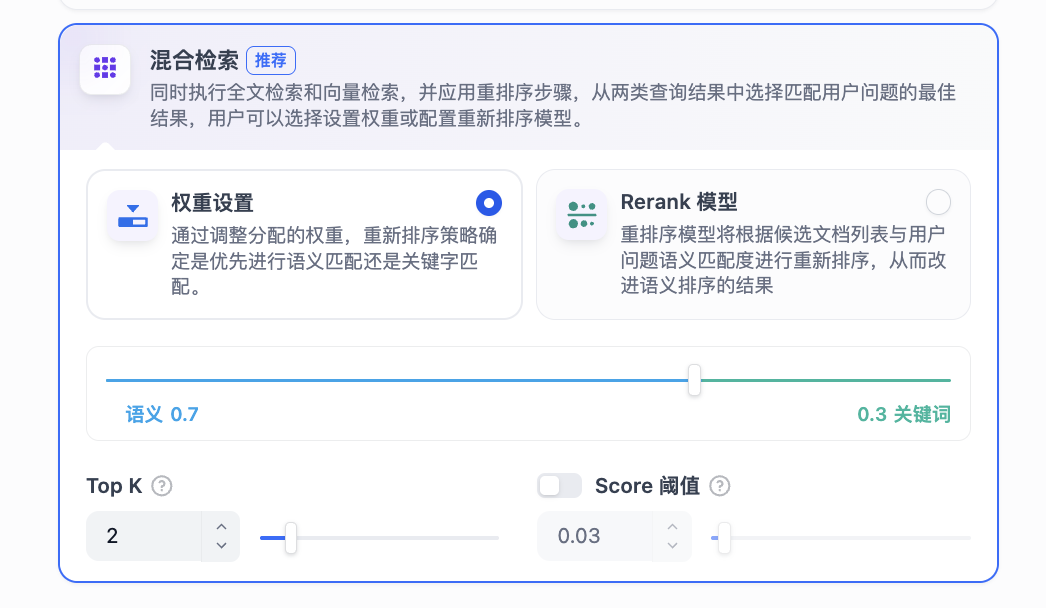
Dify中混合检索的设置
Milvus+LlamaIndex构建混合检索
%pip install llama-index-vector-stores-milvus
%pip install llama-index-embeddings-openai
%pip install llama-index-llms-openai启动Milvus服务器
Docker 部署
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.18
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.6.0-rc1
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
MQ_TYPE: woodpecker
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus使用docker compose up -d
注意:Milvus Standalone、Milvus Distributed 和 Zilliz Cloud 目前支持全文搜索,但 Milvus Lite 尚不支持全文搜索。
# 加载文档
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./10/docs/").load_data()
print("Example document:\n", documents[0])使用BM25执行混合检索
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext, VectorStoreIndex
URI = "http://localhost:19530" # Milvus URI
vector_store = MilvusVectorStore(
uri=URI,
# token=TOKEN,
dim=1536, # vector dimension depends on the embedding model
enable_sparse=True, # enable the default full-text search using BM25
overwrite=True, # drop the collection if it already exists
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)参数说明:
- dim (int, optional):Collections 的嵌入向量维度。
- enable_sparse (bool):用于启用或禁用稀疏嵌入。默认为假。
启动混合检索
在查询阶段启用混合搜索,将vector_store_query_mode 设置为 "hybrid"。
开启后,将对语义搜索和全文搜索的搜索结果进行合并和 Rerankers。
import textwrap
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", similarity_top_k=10
)
response = query_engine.query("孙悟空名字的由来?")
print(textwrap.fill(str(response), 100))
for idx, node in enumerate(response.source_nodes, 1):
print(f"结果 {idx}: ")
print(textwrap.fill(str(node.node.text), 100))
print("\n")
# 导入必要的库
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
import textwrap
# 1. 加载文档
print("Loading documents...")
documents = SimpleDirectoryReader("./10/docs/").load_data() # 替换为你的文档路径
# 2. 构建索引
print("Building index...")
index = VectorStoreIndex.from_documents(documents)
# 3. 设置混合检索参数
alpha = 0.1 # 权重参数:越大越偏向语义检索,越小偏向关键词检索
top_k = 10 # 返回前 top_k 个结果
retriever = index.as_retriever(
retriever_mode="hybrid",
similarity_top_k=top_k,
alpha=alpha
)
# 4. 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=retriever)
# 5. 执行查询
query = "孙悟空名字的由来?"
print(f"\nQuery: {query}")
response = query_engine.query(query)
print("\nResponse:")
print(textwrap.fill(str(response), 100))
# 6. 输出来源文档片段
print("\nSource Nodes:")
for idx, node in enumerate(response.source_nodes, 1):
print(f"结果 {idx}: ")
print(textwrap.fill(str(node.node.text), 100))
print("\n")
# 导入必要的库
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
import textwrap
# 1. 加载文档
print("Loading documents...")
documents = SimpleDirectoryReader("./10/docs/").load_data() # 替换为你的文档路径
# 2. 构建索引
print("Building index...")
index = VectorStoreIndex.from_documents(documents)
# 3. 设置混合检索参数
alpha = 0.9 # 权重参数:越大越偏向语义检索,越小偏向关键词检索
top_k = 10 # 返回前 top_k 个结果
retriever = index.as_retriever(
retriever_mode="hybrid",
similarity_top_k=top_k,
alpha=alpha
)
# 4. 创建查询引擎
query_engine = RetrieverQueryEngine(retriever=retriever)
# 5. 执行查询
query = "孙悟空名字的由来?"
print(f"\nQuery: {query}")
response = query_engine.query(query)
print("\nResponse:")
print(textwrap.fill(str(response), 100))
# 6. 输出来源文档片段
print("\nSource Nodes:")
for idx, node in enumerate(response.source_nodes, 1):
print(f"结果 {idx}: ")
print(textwrap.fill(str(node.node.text), 100))
print("\n")加权平均
LlamaIndex支持通过alpha参数对语意和关键词检索结果进行线性加权融合
- alpha=1.0 表达完全依赖语气检索
- alpha=0.0表达完全依赖关键词检索
- 中间值则表示两者加权融合
扩展
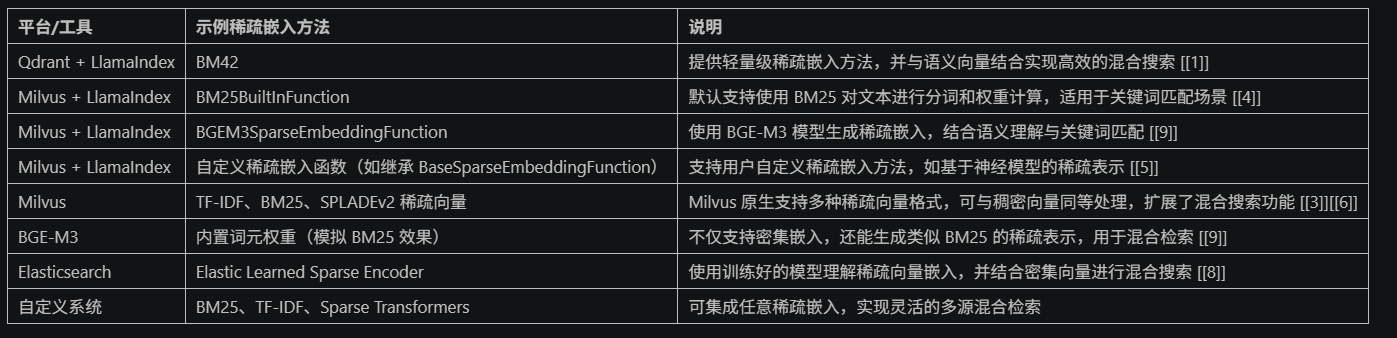
支持混合检索的平台,工具及其稀疏嵌入方法