基于KAN神经网络的锂电池SOH估算模型(NASA数据集)
摘要:健康状态(State of Health,SOH)是锂电池全生命周期管理的核心指标。本文提出一种基于柯尔莫哥洛夫-阿诺德网络(Kolmogorov-Arnold Network,KAN)的锂电池SOH估算方法,以NASA电池老化数据集(B0005)为研究对象,通过多项式样条函数逼近非线性映射关系,结合L1/L2正则化与拟牛顿优化算法,实现对电池SOH的高精度估计。文章将从数据处理、网络架构到训练细节进行完整的代码级讲解。
目录
研究背景与意义
锂离子电池在新能源汽车、储能电站、消费电子等领域得到广泛应用。随着充放电循环次数增加,电池容量逐渐衰减,SOH(State of Health) 定义为:
SOH = C 现有容量 C 额定容量 × 100 % \text{SOH} = \frac{C_{\text{现有容量}}}{C_{\text{额定容量}}} \times 100\% SOH=C额定容量C现有容量×100%
准确估算SOH是实现电池管理系统(BMS)精细化运营的前提,也是预测剩余寿命(RUL)的基础。
传统方法的局限性
| 方法类别 | 代表算法 | 主要缺点 |
|---|---|---|
| 基于模型 | 等效电路模型、电化学模型 | 参数辨识困难,计算量大,泛化性弱 |
| 基于滤波器 | EKF、UKF、PF | 依赖精确模型,噪声协方差难以标定 |
| 传统机器学习 | SVM、GPR、RF | 特征工程依赖人工经验,难以捕捉长程时序依赖 |
| 深度学习 | LSTM、CNN、TCN | 黑盒特性强,可解释性差,训练数据需求量大 |
| KAN | 本文方法 | 可解释性强,参数效率高,非线性逼近能力突出 |
KAN网络作为2024年提出的新型神经网络架构,以其边上可学习激活函数的特性,在小样本科学计算场景中展现出优异性能,尤其适合电池SOH这类具有物理规律约束的回归任务。
KAN网络原理
柯尔莫哥洛夫-阿诺德表示定理
KAN的理论基础是柯尔莫哥洛夫-阿诺德(KA)表示定理:
任意连续多元函数 f : 0 , 1 n → R f: 0,1^n \to \mathbb{R} f:0,1n→R 均可表示为:
f ( x 1 , x 2 , ... , x n ) = ∑ q = 0 2 n Φ q ( ∑ p = 1 n ϕ q , p ( x p ) ) f(x_1, x_2, \ldots, x_n) = \sum_{q=0}^{2n} \Phi_q \left( \sum_{p=1}^{n} \phi_{q,p}(x_p) \right) f(x1,x2,...,xn)=q=0∑2nΦq(p=1∑nϕq,p(xp))
其中:
- ϕ q , p : 0 , 1 → R \phi_{q,p}: 0,1 \to \mathbb{R} ϕq,p:0,1→R 为内层单变量函数(边函数)
- Φ q : R → R \Phi_q: \mathbb{R} \to \mathbb{R} Φq:R→R 为外层单变量函数
KAN与MLP的本质区别
| 对比维度 | MLP(传统神经网络) | KAN |
|---|---|---|
| 激活函数位置 | 节点上(固定函数) | 边上(可学习函数) |
| 权重角色 | 线性变换系数 | 无固定权重,函数本身即参数 |
| 非线性来源 | 固定的ReLU/Sigmoid | 可训练的样条/多项式函数 |
| 可解释性 | 低(权重无直观含义) | 高(每条边的函数可直接可视化) |
| 参数效率 | 相对低 | 相对高(对平滑函数逼近效率更优) |
本文实现的简化KAN
考虑到MATLAB实现的工程可行性,本文采用多项式基函数替代标准KAN中的B样条,构建如下两层结构:
输入层 x ∈ R^{input_dim}
↓ φ_{q,p}(x_p):多项式逼近,阶数 poly_order=4
中间层 h ∈ R^{hidden_dim} (hidden_dim=8)
↓ Ψ_q(h_q):多项式逼近,阶数 poly_order=4
输出层 y ∈ R^1 (SOH预测值)NASA电池数据集介绍
数据集来源
本文使用 NASA Ames Prognostics Center of Excellence(PCoE) 公开发布的电池老化实验数据集,文件名 HF_B0005.xlsx 对应 B0005号电池(额定容量2 Ah,18650型)。
实验条件
| 参数 | 值 |
|---|---|
| 电池型号 | 18650锂离子电池 |
| 额定容量 | 2 Ah |
| 充电制度 | CC-CV(1.5A恒流充至4.2V,再恒压至20mA) |
| 放电制度 | 2A恒流放电至2.7V |
| 实验温度 | 室温(约24°C) |
| 循环次数 | 约168次(至容量衰减至额定值的70%) |
特征工程
数据文件中每一行代表一次充放电循环,特征列(前 input_dim 列)通常包含从充放电曲线中提取的健康特征因子(Health Indicators, HIs) ,最后一列为对应的 SOH 标签值。常见健康特征包括:
- 恒流充电阶段时长
- 恒压充电阶段电荷量
- 放电结束电压
- 充电初始电压
- 放电容量(直接指标)
- 充电电压曲线面积
数据预处理流程
顺序划分策略
与分类任务随机划分不同,电池SOH估算属于时序退化预测,必须保持时间顺序------前70%循环作训练集,后30%循环作测试集:
matlab
num_train = round(num_samples * 0.7); % 前70%
trainInd = 1:num_train; % 时序不可打乱!
testInd = (num_train + 1):num_samples;⚠️ 为何不能随机划分? 若随机划分,测试集中的"未来"数据会在训练集中出现,导致数据泄露(Data Leakage),评估结果虚高,不具工程参考价值。
归一化处理
将输入特征和输出标签均归一化到 0, 1 区间(而非-1,1),更适合多项式基函数的数值稳定性:
matlab
[p_train, ps_input] = mapminmax(X_train, 0, 1);
[t_train, ps_output] = mapminmax(Y_train, 0, 1);
% 测试集严格复用训练集的归一化参数
p_test = mapminmax('apply', X_test, ps_input);
t_test = mapminmax('apply', Y_test, ps_output);归一化后需将矩阵转置为 样本×特征 的行优先格式,以配合 forward_KAN 函数的输入约定:
matlab
p_train = p_train'; % [n_train × input_dim]
t_train = t_train'; % [n_train × 1]KAN网络架构设计
参数规模计算
KAN模型的全部可学习参数被展平为一维向量 theta,其总长度为:
φ 参数量(第一层)= input_dim × hidden_dim × poly_order
Ψ 参数量(第二层)= hidden_dim × poly_order
total = phi_size + psi_size以本文配置为例(input_dim 取决于数据,hidden_dim=8, poly_order=4):
θ 总长 = d × 8 × 4 ⏟ ϕ + 8 × 4 ⏟ Ψ = 32 d + 32 \theta_{\text{总长}} = \underbrace{d \times 8 \times 4}{\phi} + \underbrace{8 \times 4}{\Psi} = 32d + 32 θ总长=ϕ d×8×4+Ψ 8×4=32d+32
与同等规模MLP(约 d × 8 + 8 × 1 = 8 d + 8 d \times 8 + 8 \times 1 = 8d + 8 d×8+8×1=8d+8 参数)相比,KAN因每条边需要存储整个多项式系数,参数量更多,但表达能力更强。
参数初始化
matlab
theta = 0.01 * (2*rand(theta_len, 1) - 1); % 均匀分布在 [-0.01, 0.01]采用小幅度随机初始化,防止多项式高阶项在初始阶段产生数值爆炸,是保证训练稳定的关键。
前向传播实现
第一层:φ 映射(输入→隐藏)
对每个隐藏单元 q q q 和每个输入特征 p p p,计算多项式函数值并累加:
h q = ∑ p = 1 d ϕ q , p ( x p ) , ϕ q , p ( x ) = ∑ k = 1 K c k ⋅ x K − k h_q = \sum_{p=1}^{d} \phi_{q,p}(x_p), \quad \phi_{q,p}(x) = \sum_{k=1}^{K} c_k \cdot x^{K-k} hq=p=1∑dϕq,p(xp),ϕq,p(x)=k=1∑Kck⋅xK−k
多项式项矩阵结构 (以 poly_order=4 为例):
P = x 1 3 x 1 2 x 1 1 x 2 3 x 2 2 x 2 1 ⋮ ⋮ ⋮ ⋮ x N 3 x N 2 x N 1 N × K \mathbf{P} = \begin{bmatrix} x_1^3 & x_1^2 & x_1 & 1 \\ x_2^3 & x_2^2 & x_2 & 1 \\ \vdots & \vdots & \vdots & \vdots \\ x_N^3 & x_N^2 & x_N & 1 \end{bmatrix}_{N \times K} P= x13x23⋮xN3x12x22⋮xN2x1x2⋮xN11⋮1 N×K
矩阵乘法 P ⋅ c \mathbf{P} \cdot \mathbf{c} P⋅c 即为对所有样本同时计算多项式值,比逐样本循环效率高出数十倍。
第二层:Ψ 映射(隐藏→输出)
结构与第一层完全对称,以中间层激活 h q h_q hq 为输入,输出累加得到最终预测:
y ^ = ∑ q = 1 H Ψ q ( h q ) \hat{y} = \sum_{q=1}^{H} \Psi_q(h_q) y^=q=1∑HΨq(hq)
损失函数与正则化
复合损失函数
本模型采用 MSE + L2 + L1 三项复合损失:
L ( θ ) = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 ⏟ MSE拟合损失 + λ ∥ θ ∥ 2 2 ⏟ L2正则 + α ∥ θ ∥ 1 ⏟ L1正则 \mathcal{L}(\theta) = \underbrace{\frac{1}{N}\sum_{i=1}^{N}(\hat{y}i - y_i)^2}{\text{MSE拟合损失}} + \underbrace{\lambda \|\theta\|2^2}{\text{L2正则}} + \underbrace{\alpha \|\theta\|1}{\text{L1正则}} L(θ)=MSE拟合损失 N1i=1∑N(y^i−yi)2+L2正则 λ∥θ∥22+L1正则 α∥θ∥1
matlab
mse_loss = mean((predictions - Y).^2);
l2_reg = lambda * sum(theta.^2); % lambda = 1e-4
l1_reg = alpha * sum(abs(theta)); % alpha = 1e-2
loss = mse_loss + l2_reg + l1_reg;两种正则化的作用对比
| 正则化类型 | 系数 | 数学形式 | 主要作用 | 对多项式系数的效果 |
|---|---|---|---|---|
| L2(岭回归) | λ=1e-4 | λ ∣ θ ∣ 2 2 \lambda|\theta|_2^2 λ∣θ∣22 | 防止参数过大,平滑模型 | 所有系数均匀缩小,抑制振荡 |
| L1(Lasso) | α=1e-3 | α ∣ θ ∣ 1 \alpha|\theta|_1 α∣θ∣1 | 产生稀疏解,自动特征选择 | 低重要性边的系数趋于精确0 |
两者结合(类似Elastic Net)兼顾平滑性与稀疏性,对于电池SOH这种特征间存在物理相关性的场景尤为重要:L1会自动"剪枝"冗余的多项式边,而L2防止保留边的系数过度放大。
维度安全处理
损失函数中包含多处维度检查,解决MATLAB中行/列向量不一致的常见问题:
matlab
% 确保预测值与标签维度一致
if size(Y, 1) ~= size(forward_fn(theta, X), 1)
Y = Y';
end
if size(predictions, 2) > size(predictions, 1)
predictions = predictions';
end模型训练策略
优化算法:拟牛顿法(L-BFGS)
选择 quasi-newton(即L-BFGS变体)而非梯度下降的原因:
| 对比项 | 梯度下降(SGD/Adam) | 拟牛顿法(L-BFGS) |
|---|---|---|
| 收敛速度 | 慢(一阶方法) | 快(近似二阶方法) |
| 超参数 | 需调学习率 | 无需学习率,自动线搜索 |
| 内存占用 | 低 | 中等(存储Hessian近似) |
| 适用数据量 | 大规模(数万样本以上) | 中小规模(电池数据典型场景) |
| 对损失面的要求 | 宽松 | 需损失函数较平滑 |
NASA B0005数据集样本量约168条,属于典型的小样本科学计算场景,拟牛顿法在此类问题上收敛速度远优于SGD类方法。
模型持久化
训练完成后保存模型参数,支持 TYPE=0 直接加载预训练模型进行推断,无需重新训练:
matlab
% 保存
save('KAN_model.mat', 'theta_opt', 'input_dim', 'hidden_dim', ...
'poly_order', 'ps_input', 'ps_output');
% 加载(TYPE=0时)
load('KAN_model.mat', 'theta_opt', ...);工程实践提示 :归一化参数(
ps_input,ps_output)必须随模型权重一同保存,否则加载后预测时的反归一化将产生错误结果。
评价指标体系
模型从四个维度对预测结果进行定量评估:
指标定义
MAE = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{N}\sum_{i=1}^{N}|y_i - \hat{y}_i| MAE=N1i=1∑N∣yi−y^i∣
RMSE = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(y_i - \hat{y}_i)^2} RMSE=N1i=1∑N(yi−y^i)2
MAPE = 1 N ∑ i = 1 N ∣ y i − y ^ i ∣ ∣ y i ∣ × 100 % \text{MAPE} = \frac{1}{N}\sum_{i=1}^{N}\frac{|y_i - \hat{y}_i|}{|y_i|} \times 100\% MAPE=N1i=1∑N∣yi∣∣yi−y^i∣×100%
R 2 = 1 − ∑ i = 1 N ( y i − y ^ i ) 2 ∑ i = 1 N ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{N}(y_i - \hat{y}i)^2}{\sum{i=1}^{N}(y_i - \bar{y})^2} R2=1−∑i=1N(yi−yˉ)2∑i=1N(yi−y^i)2
matlab
function [mae, mse, rmse, mape, R2] = calc_error(Y_real, Y_pred)
error = Y_real - Y_pred;
abs_error = abs(error);
rel_error = abs_error ./ abs(Y_real);
rel_error(~isfinite(rel_error)) = 0; % 防止零值除法
mae = mean(abs_error);
mse = mean(error.^2);
rmse = sqrt(mse);
mape = mean(rel_error) * 100;
SS_res = sum(error.^2);
SS_tot = sum((Y_real - mean(Y_real)).^2);
R2 = 1 - (SS_res / SS_tot);
end各指标的解读方向
| 指标 | 理想值 | 特点 | 在SOH估算中的意义 |
|---|---|---|---|
| MAE | → 0 | 对异常值不敏感,反映平均偏差 | 直接体现SOH估计误差的工程量级(如±1%) |
| RMSE | → 0 | 对大误差惩罚强,反映误差波动 | 衡量最坏情况下的预测质量 |
| MAPE | → 0% | 相对误差,跨尺度可比 | 评估SOH从高到低不同阶段的预测一致性 |
| R² | → 1 | 衡量预测值对实际退化趋势的解释程度 | R²>0.99 才具备工程实用价值 |
可视化分析
代码生成四幅图形,从不同角度全面评估模型性能:
图1:预测结果对比曲线
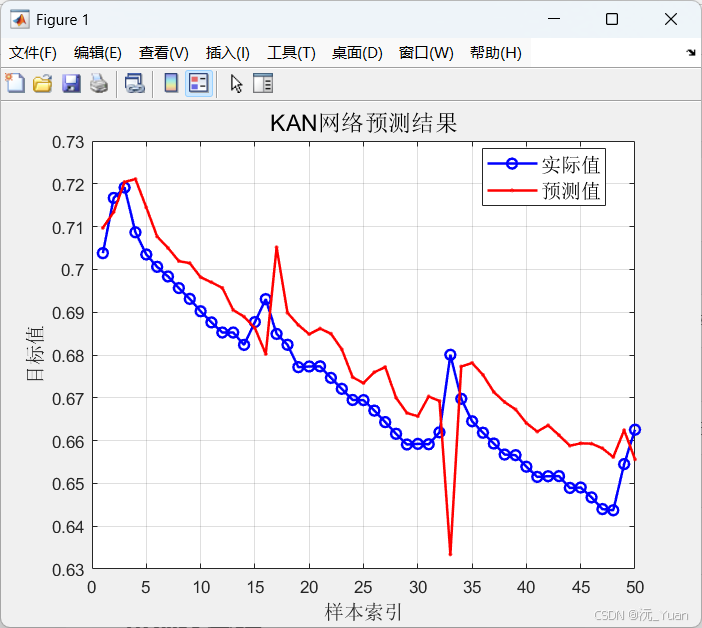
关注点:预测曲线是否紧密跟随实际SOH退化趋势;在容量突降("拐点")附近的跟踪能力。
图2:逐样本预测误差
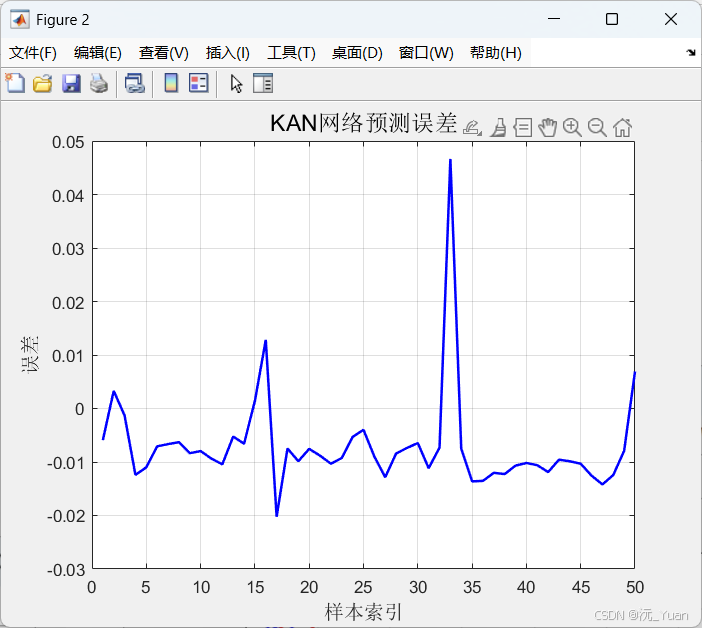
关注点:误差是否随循环次数增加呈现系统性漂移(趋势性误差暗示模型在测试集末段外推能力不足)。
图3:残差分布直方图
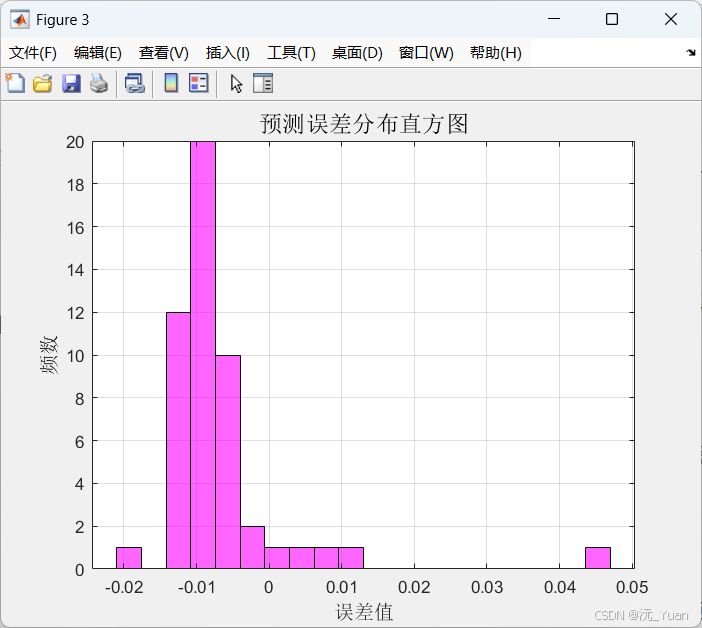
关注点:残差是否近似正态分布且均值为0(符合无偏估计假设);是否存在重尾(偶发大误差)。
图4:预测值与实际值回归图
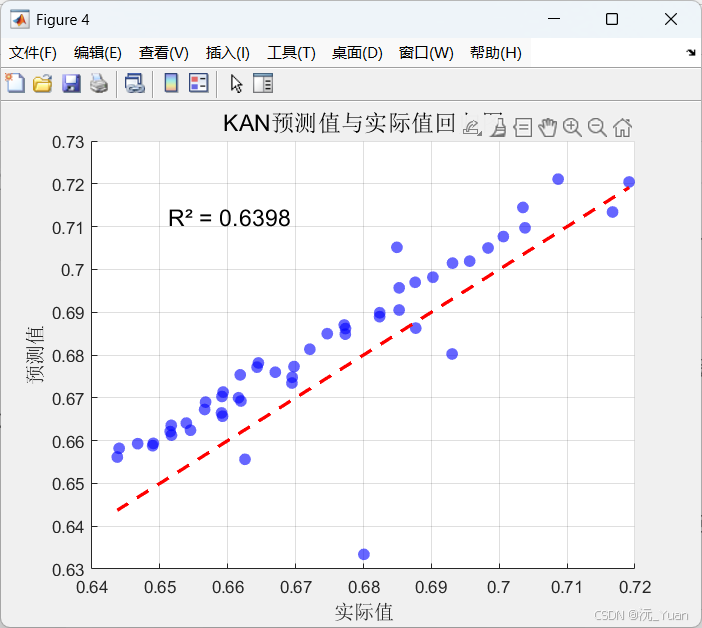
关注点:散点是否紧密分布在对角线(y=x)附近;偏离方向可判断模型是否系统性高估或低估SOH。
完整参数配置总览
matlab
%% ====== 超参数配置汇总 ======
TYPE = 1; % 1=重新训练,0=加载预训练
train_ratio = 0.70; % 训练集比例(前70%循环)
test_ratio = 0.30; % 测试集比例(后30%循环)
hidden_dim = 8; % KAN隐藏单元数(H)
poly_order = 4; % 多项式阶数(K,范围2-8)
lambda = 1e-4; % L2正则化系数
alpha = 1e-3; % L1正则化系数
max_iter = 100; % 最大迭代次数超参数敏感性分析
| 超参数 | 增大的影响 | 减小的影响 | 建议范围 |
|---|---|---|---|
hidden_dim |
表达能力增强,训练变慢,过拟合风险增加 | 欠拟合,模型简单 | 4 ~ 16 |
poly_order |
逼近复杂函数能力增强,数值不稳定风险增加 | 仅能拟合低阶关系 | 2 ~ 6 |
lambda(L2) |
模型更平滑,可能欠拟合 | 过拟合风险增加 | 1e-5 ~ 1e-3 |
alpha(L1) |
模型更稀疏,自动剪枝 | 保留更多边 | 1e-3 ~ 1e-1 |
max_iter |
拟合更充分,训练时间增加 | 可能训练不充分 | 50 ~ 500 |
总结与展望
本文小结
本文实现了一套完整的基于KAN的锂电池SOH估算流程:
- 数据层:时序顺序划分(70/30),0,1 归一化,防止数据泄露
- 模型层:两层多项式KAN,参数向量化存储,支持保存/加载
- 训练层 :MSE + L1 + L2复合损失,拟牛顿法优化,
max_iter=100 - 评估层:MAE / RMSE / MAPE / R² 四维指标,四类可视化图表
与主流方法的对比优势
| 对比维度 | LSTM | CNN-LSTM | KAN(本文) |
|---|---|---|---|
| 可解释性 | 低 | 低 | 高(每条边可视化) |
| 小样本性能 | 一般(需大量数据) | 一般 | 优(参数效率高) |
| 训练收敛速度 | 慢(需大量epoch) | 中等 | 快(拟牛顿二阶收敛) |
| 特征选择能力 | 无 | 局部感受野 | 自动(L1稀疏化边) |
潜在改进方向
| 方向 | 说明 |
|---|---|
| B样条替代多项式 | 将多项式基函数替换为标准KAN的B样条,提升对局部非线性的逼近精度 |
| 多电池迁移学习 | 在B0005基础上预训练,迁移到B0006/B0007,验证跨电池泛化能力 |
| 时序特征融合 | 引入滑动窗口,将历史多步SOH序列作为额外输入特征 |
| 不确定性量化 | 结合MC Dropout或Ensemble方法,输出SOH估计的置信区间 |
| 在线更新机制 | 设计增量学习策略,随电池服役过程中持续更新模型参数 |
📌 运行说明:
- 数据文件
HF_B0005.xlsx需与脚本置于同一目录下,最后一列为SOH标签,其余列为健康特征- 首次运行设置
TYPE=1训练并保存模型;后续推断设置TYPE=0直接加载KAN_model.mat- MATLAB版本建议 R2021b 及以上(
fminunc的quasi-newton算法在旧版本中行为有差异)