【深度学习】卷积神经网络CNN
0、白话概览
假如我们要处理一个30*30的图片,那么平铺展开后,输入层就是900个神经元,假如下一层的神经元是1000个,那么这个全连接层的总参数量就是90w个,参数过于庞大!
我们在图像中取一个3 * 3的矩阵,矩阵中的数值就是图像的灰度值 ,将此矩阵与卷积核 进行点乘 ,最终通过这种方式遍历滑过原图像的每个地方,这种方式叫做卷积运算。

在传统的图像处理领域,卷积核矩阵 是已知的,这样在P图时各个滤镜对应的就是不同的卷积核,从而得到不同的新图像。在深度学习领域,卷积核的值是未知的 ,是被训练出来的一组值,在神经网络中,就是将其中的一个全连接层,替换成卷积层 ,公式将矩阵的标准乘法替换成了卷积运算。
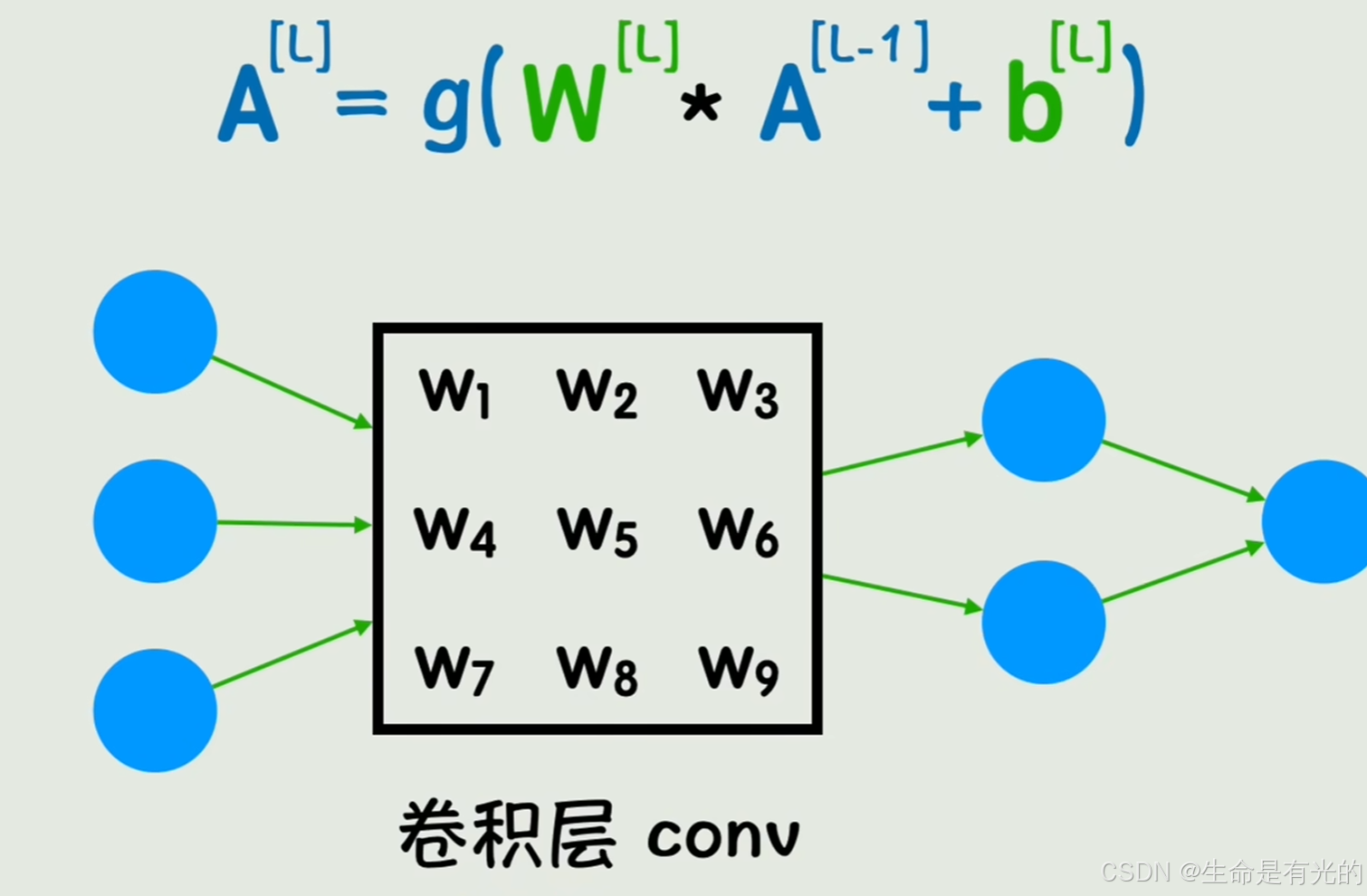
我们可以用更抽象、更简洁的图来表示,同时对于卷积层、池化层可以有很多个 ,这种适用于图像识别领域的实际网络结构,就是卷积神经网络CNN:
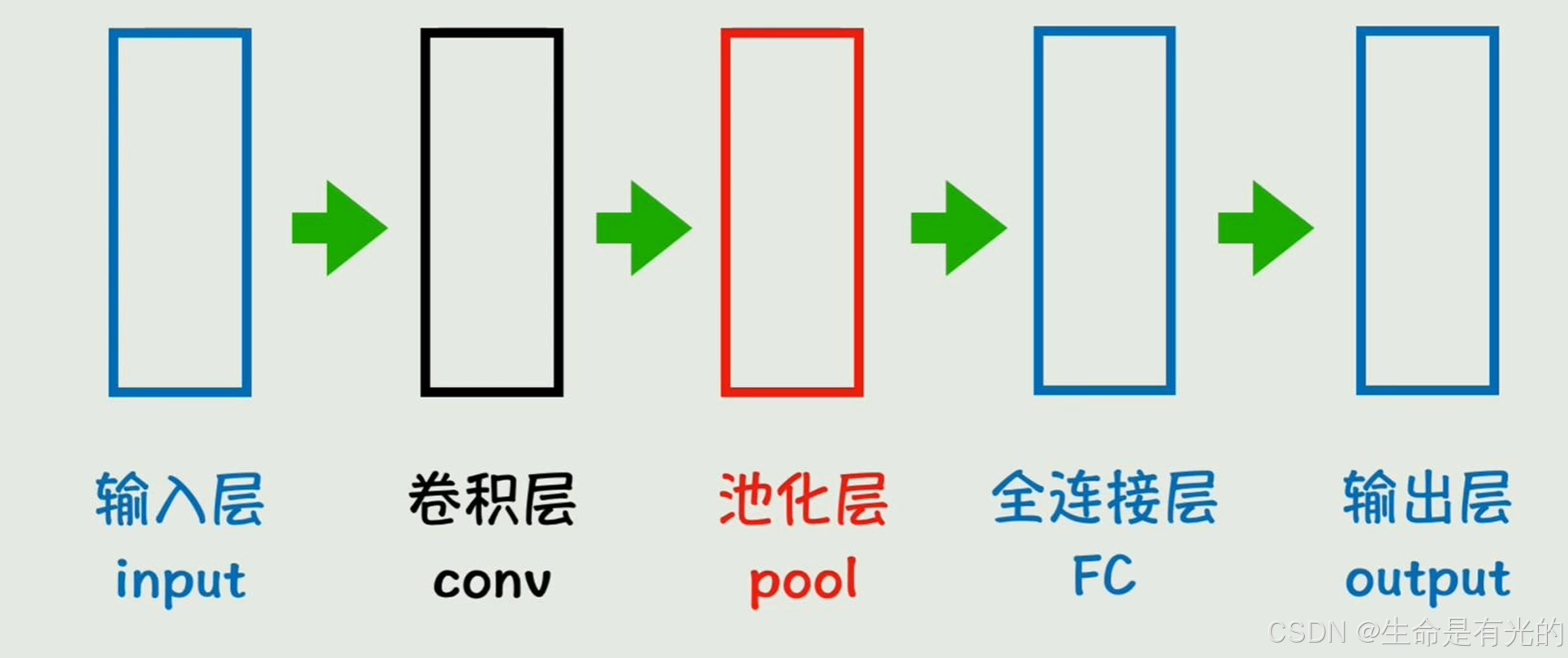
1、卷积神经网络CNN
1.1、图像基础知识
图像是由像素点组成的,每个像素点的取值范围为:0,255,像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。在深度学习中,我们使用的图像大多是彩色图,彩色图由RGB 3个通道组成,如下图所示:
python
# 像素值的理解
def test01():
# 全0数组是黑色的图像
# [200, 200, 3]代表数组的形状,也就是这个数组有三个维度。第一个维度和第二个维度的大小都是 200,第三个维度的大小是 3。在图像领域,前两个维度分别代表图像的高度和宽度,而第三个维度代表颜色通道(红、绿、蓝)
img = np.zeros([200, 200, 3])
# 展示图像
plt.imshow(img)
plt.show()
# 全255数组是白色的图像
img = np.full([200, 200, 3], 255)
# 展示图像
plt.imshow(img)
plt.show()
matplotlib只建议做图像读取和显示,不建议再多做其他的。OpenCV!
python
def test01():
# 读取图像
img = plt.imread("../data/profile.jpg")
# 图像形状 高H,宽W,通道C
print("图像的形状(H, W, C):\n", img.shape)
# 展示图像
plt.imshow(img)
plt.axis("off") # 关闭坐标轴的显示
plt.show()
1.2、卷积神经网络概述
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络 . 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成:
- 卷积层负责提取图像中的局部特征
- 池化层用来大幅降低参数量级(降维)
- 全连接层用来输出想要的结果
1.3、卷积层
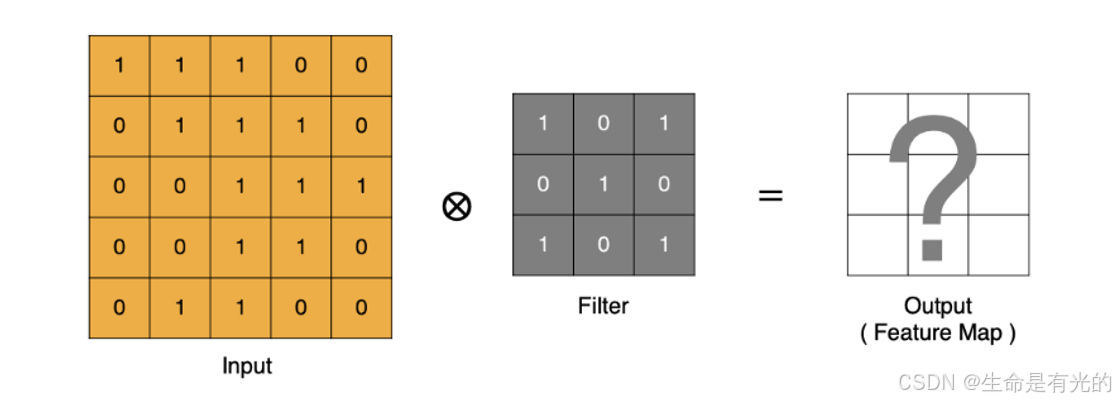
- input 表示输入的图像
- filter 表示卷积核 , 也叫做卷积核(滤波矩阵)
- input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
1.3.1、卷积运算
卷积运算本质上就是在卷积核和输入数据的局部区域间做点积(点乘)
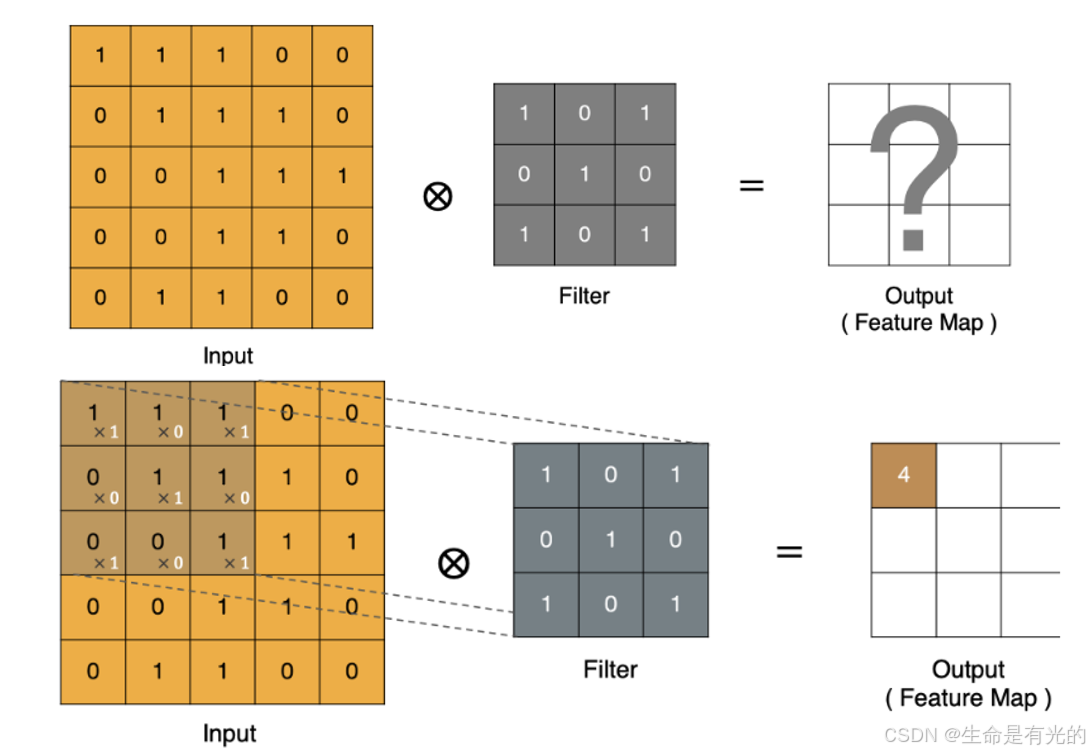
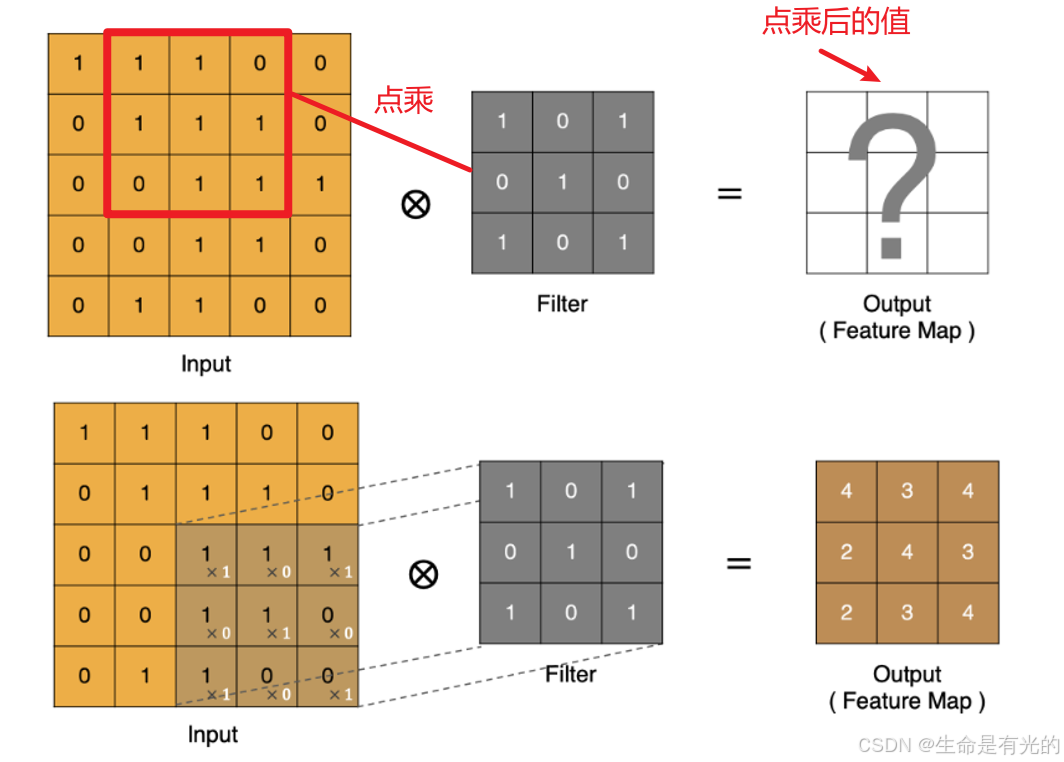
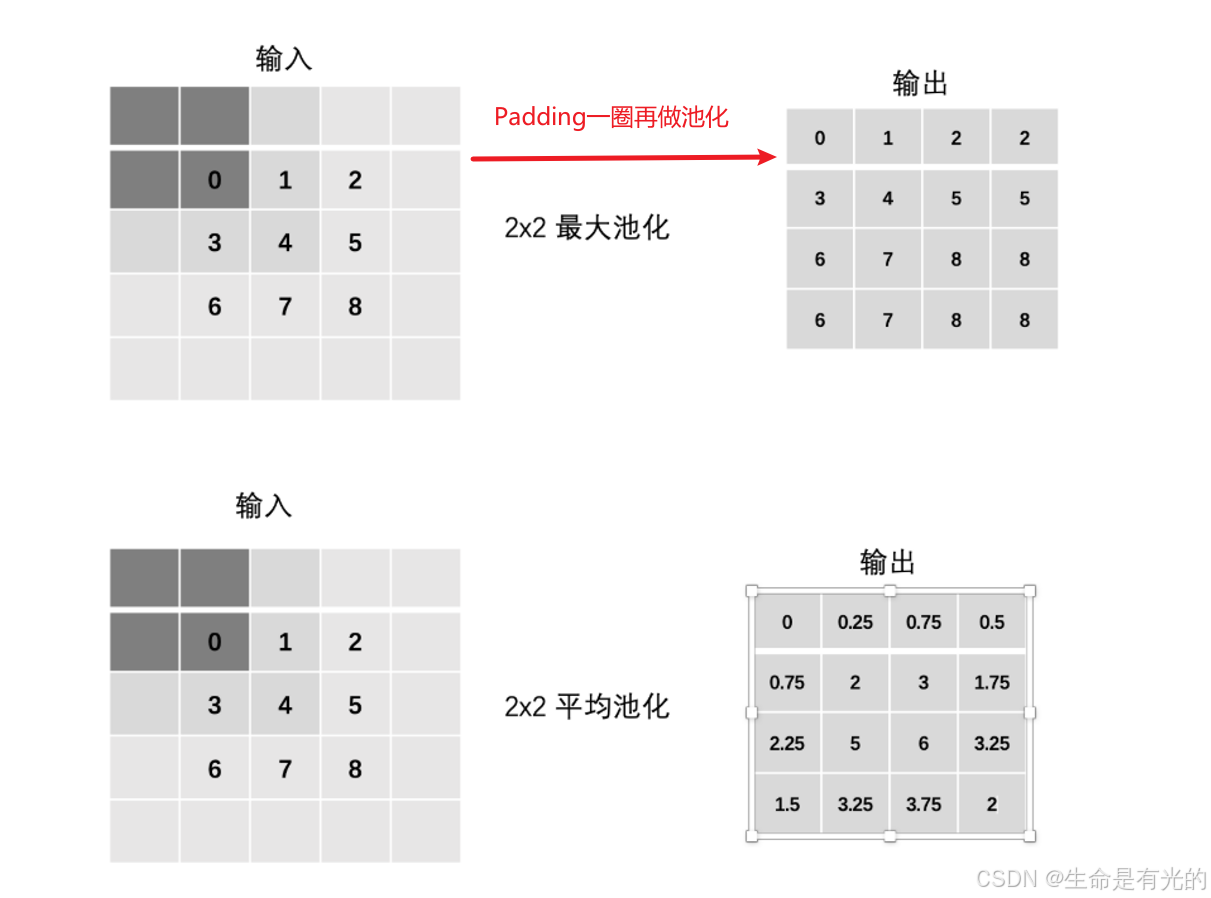
1.3.2、Padding填充
我们上面进行点乘的步长Stride 为1,假如步长Stride为3,就会出现如下情况:
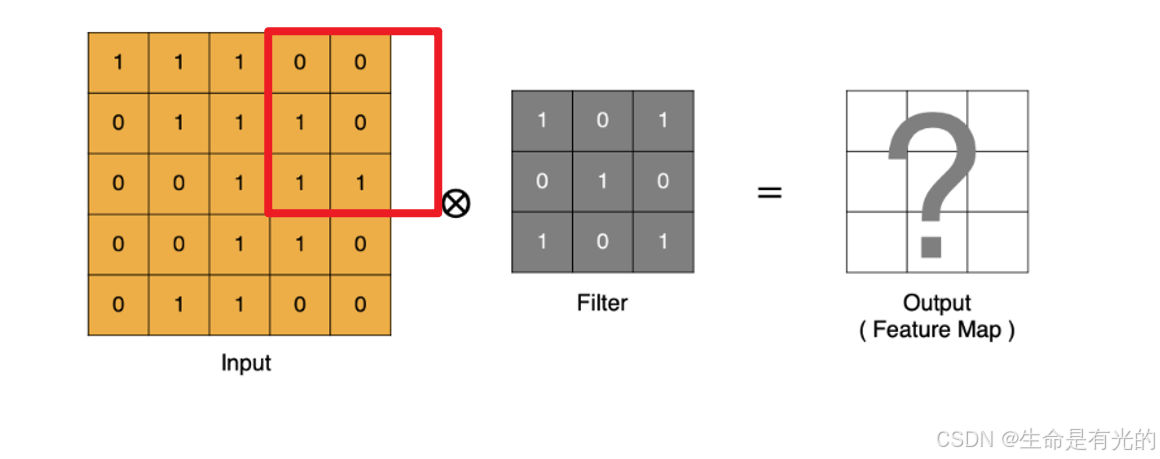
于是这个时候就需要进行Padding填充,填充0。但是实际上我们padding都是四周都填充。通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding 来实现。
1.3.3、多通道卷积计算
- 实际图像是多通道的,我们的卷积核也要是多通道的。
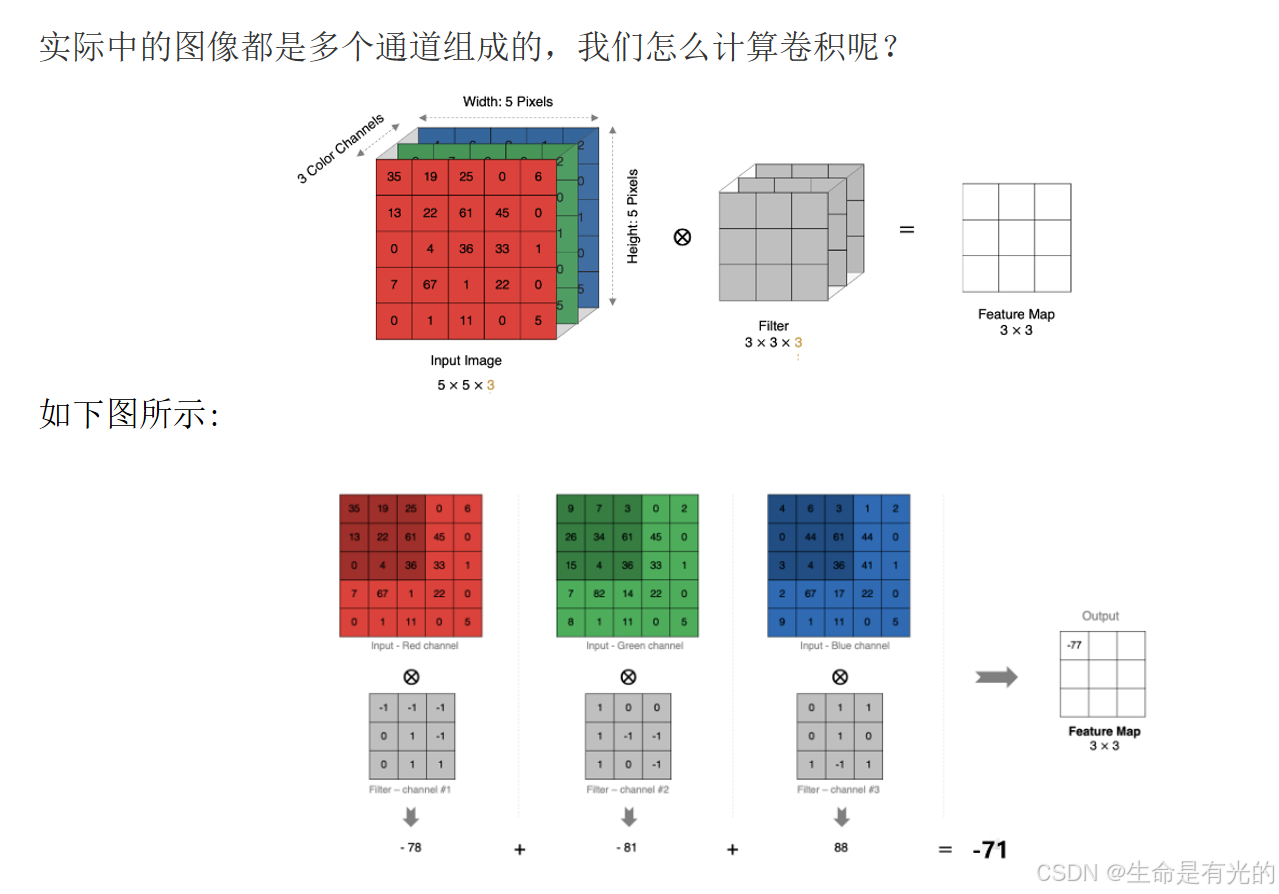
1.3.4、特征图的大小
输出特征图的大小与以下参数息息相关:
- size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1 * 1 、3 * 3、5 * 5
- Padding: 零填充的方式
- Stride: 步长
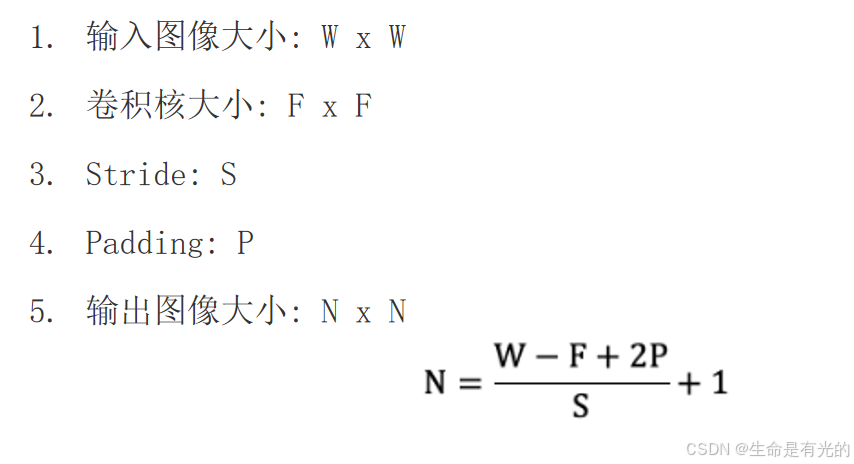
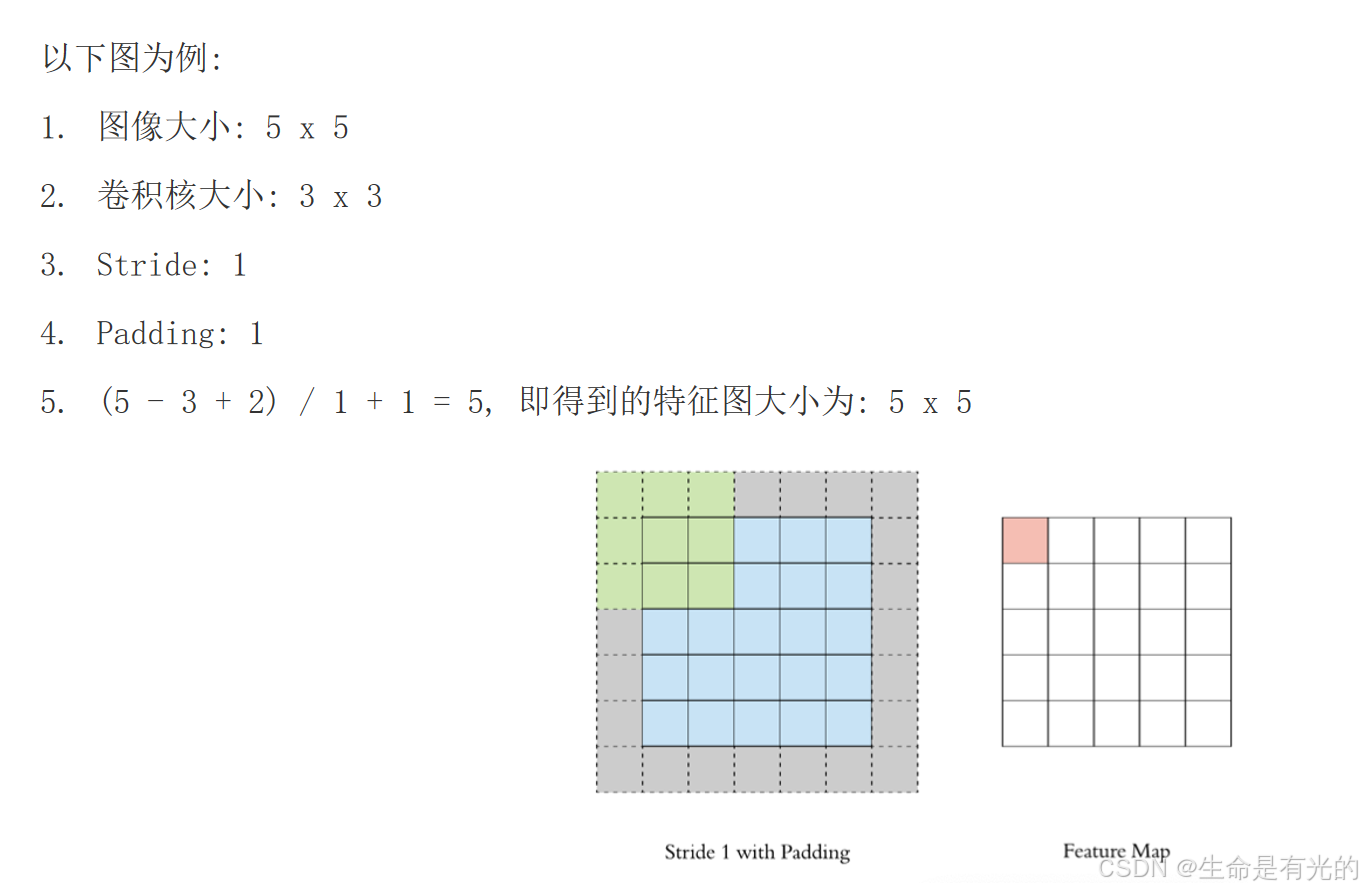
例如:
1.3.5、卷积层API
python
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,
out_channels: 输出通道,也可以理解为卷积核kernel的数量
kernel_size:卷积核的高和宽设置,一般为3,5,7...
stride:卷积核移动的步长
padding:在四周加入padding的数量,默认补0
"""
python
def test():
# 读取图像,形状: HWC(1080, 1080, 3)
img = plt.imread("./data/profile.jpg")
plt.imshow(img)
plt.axis('off')
plt.show()
# 构建卷积层
# in_channels=3:表示输入图像的通道数,这里因为是 RGB 图像,所以通道数为 3
# out_channels=3:表示卷积层输出的通道数,也就是卷积核的数量。这里输出通道数也设为 3
# kernel_size=3:表示卷积核的大小,这里使用的是 3x3 的卷积核
# stride=2:表示卷积核在图像上滑动的步长,这里步长为 2
# padding=0:表示在图像边缘填充的像素数,这里不进行填充
conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=2, padding=0)
# PyTorch中要求输入的是 C H W,所以我们将HWC(1080, 1080, 3)转换成CHW(3,1080,1080)
# 对张量的维度进行重排:原始图像数据的形状是 (H, W, C),通过 permute(2,0,1) 将其转换为 (C, H, W) 的形状,以满足 PyTorch 中卷积层输入的要求
img = torch.tensor(img).permute(2,0,1)
# 在张量的第 0 个维度上增加一个维度,将形状从 (C, H, W) 变为 (1, C, H, W),其中新增的第 0 个维度表示批量大小(这里批量大小为 1)
img = img.unsqueeze(0)
# img.to(torch.float32):将图像张量的数据类型转换为 torch.float32,因为 PyTorch 中的卷积层通常要求输入数据为浮点类型
# conv(img.to(torch.float32)):将处理后的图像张量输入到之前构建的卷积层中进行卷积操作,得到卷积后的特征图
feature_map_img = conv(img.to(torch.float32))
# 打印卷积后特征图的形状,其形状通常为 (批量大小, 输出通道数, 特征图高度, 特征图宽度)
print(feature_map_img.shape)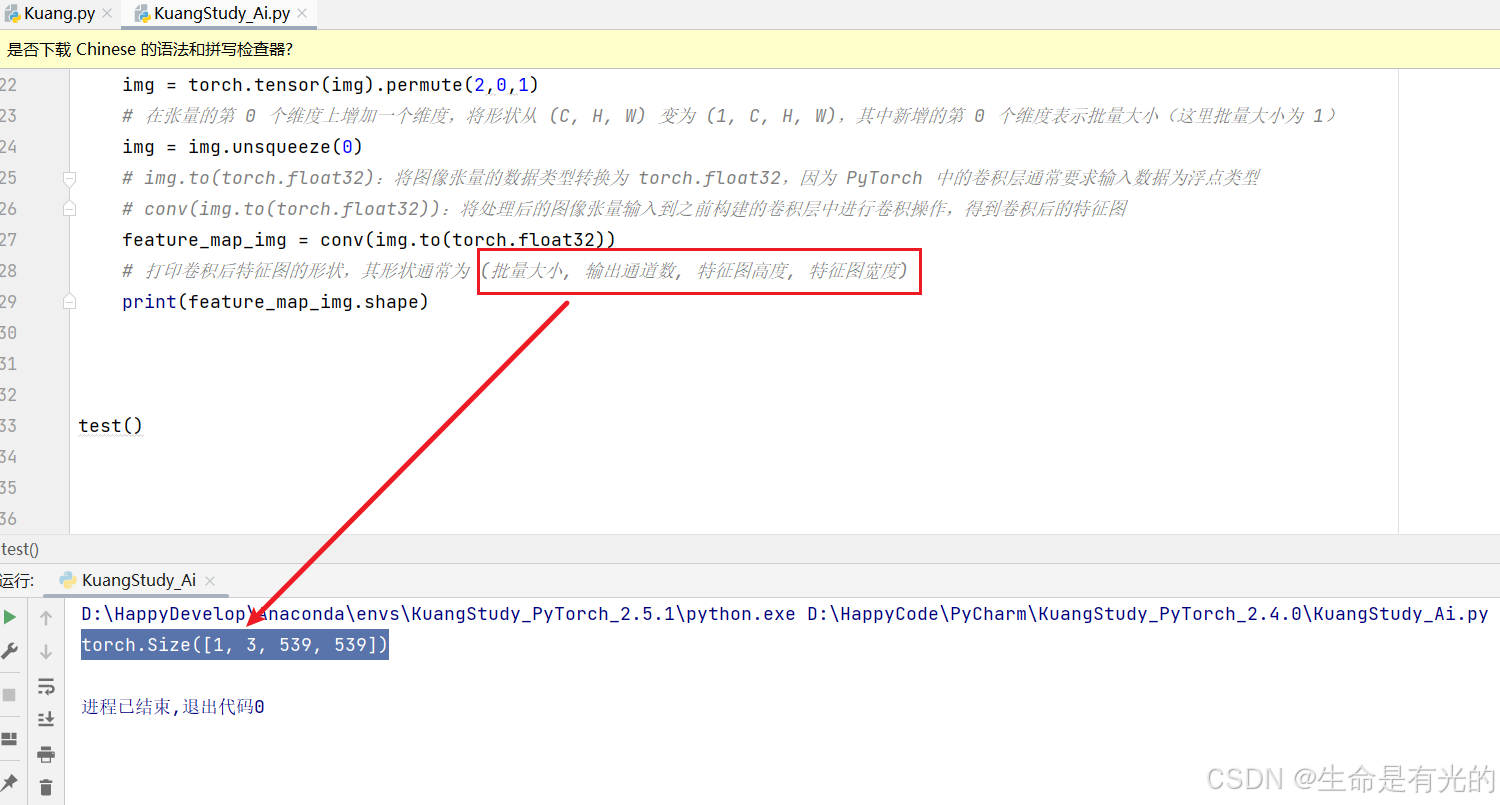
1.4、池化层
池化层 (Pooling) 降低维度, 缩减模型大小,提高计算速度。
- 降维是对特征图的宽高进行降维,通道是不会发生变化
- 卷积步长为2比池化的效果更好,2020年后就不再使用池化了。
- 最大池化
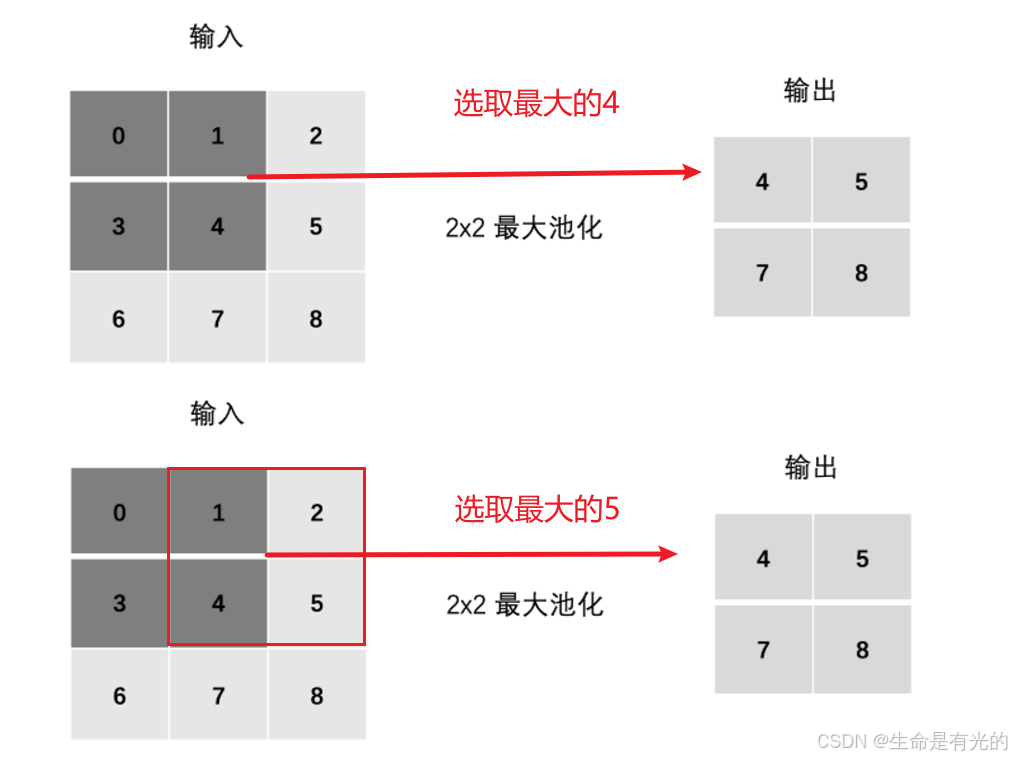
- 平均池化(基本不用)

当然我们还可以进行定义步长Stride:我们就把4×4的特征图降维成了2×2的
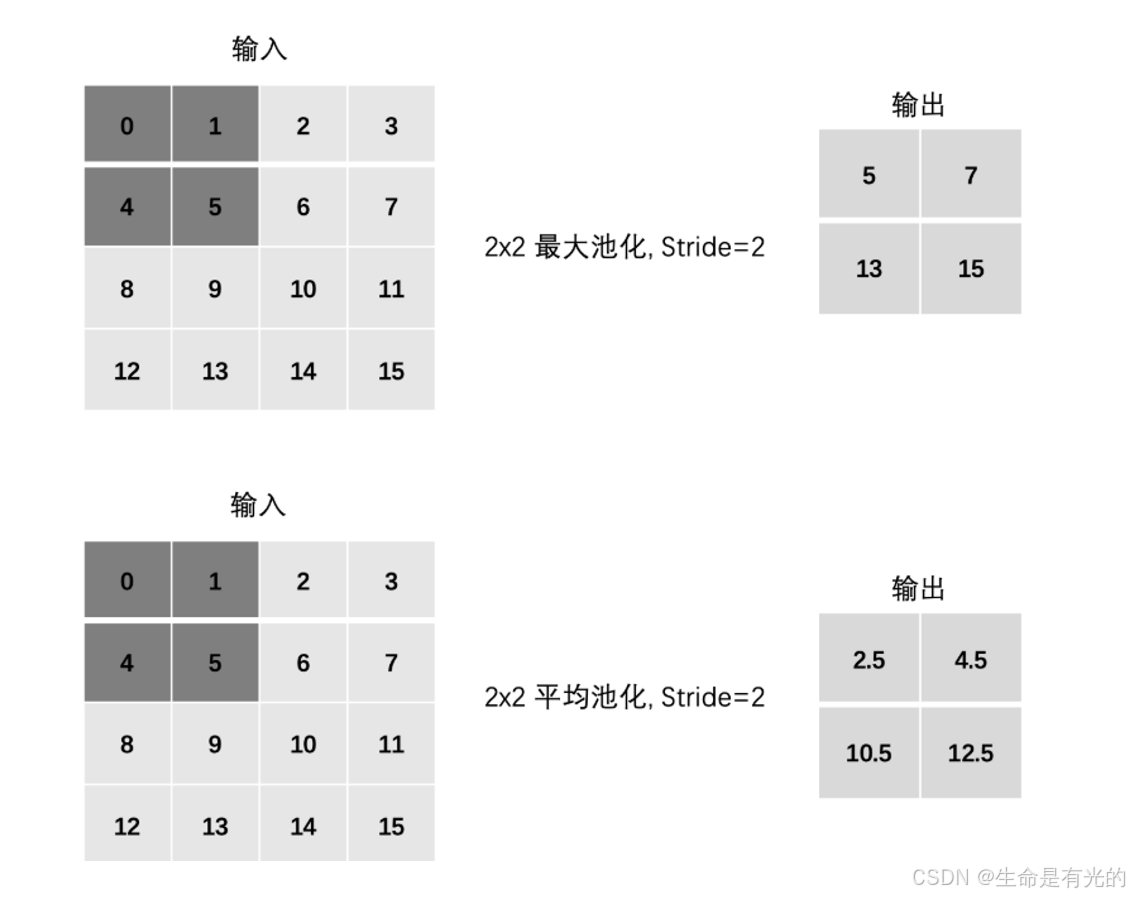
当然我们也可以进行padding: