在AI技术飞速迭代的今天,越来越多的开发者开始搭建属于自己的AI助手,但很多人都会遇到一个棘手的问题:明明给AI助手配置了向量数据库,它却始终记不住历史对话,每次交互都像"重新认识"一样。这背后的核心原因的很简单,我们最初搭建的基于RAG架构的AI助手,本质上只是给大语言模型(LLM)配备了一个外部查询工具,而非为动态记忆管理设计的系统。
随着AI助手的应用场景越来越复杂,从简单的问答交互到个性化的长期服务,静态知识库的局限性愈发明显。那么,具备动态记忆的AI助手到底该如何搭建?RAG架构、agentic RAG、Agent记忆系统的演化路线是怎样的?我们该如何根据自身需求进行选型,又该如何配置AI的记忆能力?
今天,我们就从技术演进的角度,一步步拆解从RAG到Agent记忆的完整路径,结合Milvus向量数据库的实操案例,手把手教你搭建具备动态记忆与按需检索能力的智能AI助手,让你的AI助手真正拥有"长期记忆",实现更自然、更个性化的交互体验。
一、认知前提:为什么静态知识库会被淘汰?
在深入技术细节之前,我们先搞清楚一个核心问题:为什么静态知识库无法满足现代AI助手的需求?
我们常见的AI助手知识库,大多是基于传统RAG架构搭建的。简单来说,就是先在离线状态下,把所有的文档、资料切成小块,转换成向量后存入向量数据库,等到用户提问时,再把用户的问题转换成向量,去数据库里检索最相似的内容,最后把检索结果和问题一起交给LLM生成答案。
这种模式在简单的问答场景下确实好用,比如查询产品说明书、技术文档等固定内容,但一旦涉及到动态交互,就会暴露三个致命问题。
第一,知识库无法实时更新。离线构建的知识库,在运行过程中无法添加新内容、修改旧内容,一旦知识过时,就必须停止服务,重新切分文档、生成向量、构建索引,效率极低。比如你更新了产品的功能参数,静态知识库无法实时同步,用户查询时得到的依然是旧信息。
第二,强制检索,浪费资源。不管用户的问题是否需要外部知识,传统RAG都会强制去数据库检索一遍。比如用户问"你还记得我喜欢简洁的回复吗",这种属于历史对话记忆,根本不需要去外部知识库检索,但传统RAG依然会执行检索操作,不仅浪费计算资源,还会降低响应速度。
第三,无法实现个性化记忆。静态知识库是"通用的",所有用户共享同一套知识,无法记录单个用户的偏好、习惯、历史对话细节。比如用户A喜欢用emoji交流,用户B喜欢详细的文字说明,静态知识库无法区分这两种需求,自然无法提供个性化的回复。
随着Agent技术的兴起,AI助手不再是简单的"问答机器",而是需要具备自主决策、动态学习、长期记忆的能力。这就要求我们跳出传统RAG的局限,从"只读的外部知识库"向"可读写的动态记忆系统"演进,而Milvus向量数据库,正是支撑这一演进的核心工具。
二、演进第一阶段:传统RAG,只读的外部知识库(基础入门)
虽然静态知识库有局限性,但它是搭建AI助手的基础,也是我们理解后续技术演进的关键。我们先从传统RAG的核心逻辑入手,搞清楚它的工作原理、技术难点,以及如何用Milvus实现一个基础的RAG系统。
2.1 什么是RAG?核心逻辑是什么?
RAG的全称是检索增强生成,最早在2020年由Lewis等人提出,核心目的是解决LLM的"知识截止日期"问题。我们都知道,LLM的训练数据是有时间限制的,比如某个LLM训练到2023年,就无法知道2024年的新信息,而RAG的作用,就是给LLM"外接"一个实时更新的知识库,让它在回答问题前,先去知识库中查询最新、最相关的信息,再结合自身的知识生成答案。
传统RAG的工作流程可以分为四个步骤,非常简单易懂。
第一步,离线准备。把需要用到的文档(比如产品手册、技术文档、行业报告等)切成合适的小块,这个过程叫做"文档切片"。切片不能太大,否则检索精度会下降;也不能太小,否则会丢失上下文信息,一般建议每块100-500字。
第二步,向量转换与存储。通过嵌入模型(比如OpenAI的text-embedding-ada-002),把每一块文档转换成向量,然后将向量和对应的文本、来源等信息一起存入向量数据库。这里的核心是"向量",它能把文本的语义信息转换成计算机能理解的数值,方便后续的相似性检索。
第三步,在线检索。当用户提出问题时,同样通过嵌入模型把问题转换成向量,然后用这个向量去向量数据库中检索最相似的Top-K块文档(一般K取5-10)。这个过程就像是"大海捞针",但向量数据库能通过索引技术,快速找到最相关的内容。
第四步,生成答案。把检索到的Top-K文档和用户的问题一起输入LLM,让LLM结合这些外部知识,生成准确、全面的答案。
2.2 传统RAG的核心技术难点:毫秒级检索
在搭建传统RAG系统时,最核心的技术挑战不是文档切片,也不是向量转换,而是如何在百万级、亿级的向量数据中,实现毫秒级的检索。
很多开发者一开始会尝试用传统数据库(比如MySQL、PostgreSQL)来存储向量,要么是直接存储向量数据,要么是使用简单的向量检索插件。但这种方式存在明显的短板:传统数据库本身不擅长处理向量数据,没有专门的向量索引,检索时只能逐一遍历所有向量,计算相似度,在百万级数据量下,检索延迟会达到几秒甚至几十秒,根本无法满足AI助手的实时交互需求。
而Milvus作为专门的向量数据库,就能完美解决这个问题。它支持多种专业的向量索引(比如HNSW、IVF_FLAT等),能够实现百亿级向量数据的毫秒级检索,而且还支持标量过滤、动态插入等功能,为后续的技术演进打下了基础。
2.3 Milvus实现传统RAG的完整实操(附代码)
下面我们用具体的代码,手把手教你用Milvus搭建一个基础的传统RAG系统。这里我们使用Python语言,结合OpenAI的嵌入模型,实现文档的批量插入和在线检索。
首先,我们需要安装必要的依赖包:
bash
pip install pymilvus openai然后,编写完整的代码,实现从连接Milvus、创建集合、构建索引,到批量插入文档、在线检索的全流程。
python
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
import openai
# ===== 工具函数:统一的向量化接口 =====
def embed(text):
"""将文本转换为向量,使用OpenAI的text-embedding-ada-002模型"""
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response["data"][0]["embedding"]
# ===== 步骤1:连接Milvus并创建Collection(集合,类似数据库中的表) =====
# 连接本地Milvus服务(如果是远程服务,替换host和port即可)
connections.connect(host="localhost", port="19530")
# 定义集合的字段(类似表的列)
fields = [
# 主键字段,自增,用于唯一标识每条数据
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
# 文本内容字段,存储文档切片后的文本
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
# 向量字段,存储文本对应的向量,维度为1536(对应text-embedding-ada-002模型)
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536),
# 来源字段,存储文档的来源(比如文档路径、网址等)
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=512),
]
# 创建集合 schema(类似表结构)
schema = CollectionSchema(fields=fields, description="RAG Knowledge Base(传统RAG知识库)")
collection = Collection(name="rag_knowledge", schema=schema)
# ===== 步骤2:创建向量索引,提升检索速度 =====
# 这里使用HNSW索引,适合高维向量的快速检索,metric_type为COSINE(余弦相似度)
index_params = {
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {"M": 16, "efConstruction": 256}
}
# 为embedding字段创建索引
collection.create_index(field_name="embedding", index_params=index_params)
# ===== 步骤3:离线索引,批量插入文档 =====
def ingest_documents(documents):
"""批量插入文档到Milvus向量库,适合离线准备阶段"""
texts = []
embeddings = []
sources = []
# 遍历文档列表,提取文本、生成向量、记录来源
for doc in documents:
texts.append(doc["text"])
embeddings.append(embed(doc["text"]))
sources.append(doc["source"])
# 组装数据,注意顺序要和fields的顺序一致(除了auto_id的id字段)
data = [texts, embeddings, sources]
# 插入数据
collection.insert(data)
# 刷新数据,确保持久化到磁盘
collection.flush()
print(f"✅ 已索引 {len(documents)} 条文档,成功存入Milvus向量库")
# ===== 步骤4:在线检索,RAG查询 =====
def rag_retrieval(query, top_k=5):
"""传统RAG检索:每次查询都强制检索,返回最相似的top_k条文档"""
# 将集合加载到内存,提升检索速度(首次加载较慢,后续复用)
collection.load()
# 将用户查询转换为向量
query_embedding = embed(query)
# 检索参数,ef越大,检索精度越高,但速度越慢
search_params = {"metric_type": "COSINE", "params": {"ef": 100}}
# 执行检索
results = collection.search(
data=[query_embedding], # 查询向量(可批量查询,这里单次查询)
anns_field="embedding", # 用于检索的向量字段
param=search_params, # 检索参数
limit=top_k, # 返回的最相似文档数量
output_fields=["text", "source"] # 检索结果中需要返回的字段
)
# 返回第一条查询的结果(批量查询时可遍历results)
return results[0]
# ===== 使用示例:批量插入文档 + 在线检索 =====
if __name__ == "__main__":
# 模拟需要插入的文档列表(实际应用中可从文件、数据库中读取)
docs = [
{"text": "Milvus是一款开源的向量数据库,支持HNSW、IVF_FLAT等多种向量索引,能够实现百亿级向量的毫秒级检索", "source": "docs/milvus_intro.md"},
{"text": "RAG(检索增强生成)的核心是给LLM配备外部知识库,让LLM回答问题前先查询相关资料,提升答案的准确性和时效性", "source": "docs/rag_intro.md"},
{"text": "OpenAI的text-embedding-ada-002模型是一款常用的文本嵌入模型,生成的向量维度为1536,适合用于文本相似性检索", "source": "docs/embedding_model.md"},
{"text": "Milvus支持多种数据操作,包括插入、查询、更新、删除,同时支持标量过滤,能够满足复杂场景的检索需求", "source": "docs/milvus_operation.md"},
{"text": "传统RAG的局限性在于知识库是只读的,运行时无法更新,且每次查询都强制检索,浪费计算资源", "source": "docs/rag_limit.md"}
]
# 批量插入文档
ingest_documents(docs)
# 模拟用户查询
user_query = "什么是向量数据库?它有什么优势?"
print(f"\n用户查询:{user_query}")
print("检索结果:")
# 执行检索
results = rag_retrieval(user_query, top_k=3)
# 遍历检索结果,打印相似度、文本内容和来源
for i, hit in enumerate(results, 1):
print(f"{i}. 相似度: {hit.score:.3f} | 内容: {hit.entity.get('text')} | 来源: {hit.entity.get('source')}")运行上述代码后,我们就能实现一个基础的传统RAG系统。但通过代码和实际操作,我们很容易发现传统RAG的局限性:每次查询都必须执行检索,哪怕是简单的历史对话查询;知识库一旦插入文档,运行时无法更新、删除;所有文档都存在同一个集合中,无法区分领域、类型,检索精度会随着数据量的增加而下降。
这些问题在简单的问答场景下影响不大,但如果我们要搭建一个能够长期交互、个性化服务的AI助手,就必须进入下一个阶段,agentic RAG。
三、演进第二阶段:agentic RAG,按需检索,让AI学会"自主决策"
传统RAG的核心问题,在于把"检索"当成了必选项,而不是可选项。就像一个人不管遇到什么问题,都先去查字典,哪怕是自己已经知道答案的问题,效率极低。而agentic RAG的突破,就是把检索变成了一种"工具",让Agent(智能体)自主决策:是否需要检索、检索什么来源、检索结果是否可信。
简单来说,agentic RAG就是给AI助手增加了一个"大脑",让它在回答问题前,先判断这个问题是否需要去外部知识库检索。比如用户问"你好",AI助手可以直接回复"你好,有什么可以帮你?",不需要检索;如果用户问"Milvus支持哪些向量索引?",AI助手判断自己的内置知识不够准确,就会去外部知识库检索相关内容,再生成答案。
3.1 agentic RAG的核心突破:检索决策与多Collection隔离
agentic RAG有两个核心突破,一个是"检索决策机制",另一个是"多Collection隔离架构"。
检索决策机制,就是Agent通过分析用户的问题,自主判断是否需要检索。它的核心逻辑是:先判断问题是否属于内置知识(比如简单的问候、基础概念),如果是,直接生成答案;如果不是,再判断需要检索哪个领域的知识,然后执行检索;检索完成后,还要评估检索结果的质量,如果结果质量太低(比如相似度不足),就会触发 fallback 策略(比如去网页搜索)。
而多Collection隔离架构,是为了解决传统RAG中"所有文档混存"的问题。在传统RAG中,所有领域的文档都存在同一个Collection中,检索时很容易出现"无关结果",比如检索"Milvus的API使用",却返回了"Milvus的安装教程",检索精度下降。
多Collection隔离架构的思路很简单:为不同的领域、不同类型的知识,创建独立的Collection。比如产品文档创建一个Collection,API参考创建一个Collection,客户案例创建一个Collection,技术博客创建一个Collection。这样Agent在检索时,就可以根据问题类型,精准路由到对应的Collection,避免无关结果的干扰,同时还能为不同的Collection设置差异化的检索策略(比如不同的索引参数、过滤条件)。
3.2 Milvus实现agentic RAG的实操(附代码)
下面我们依然用Python代码,结合Milvus,实现一个agentic RAG系统。核心要点是创建多个独立的Collection,让Agent根据问题类型,动态路由检索,同时实现检索质量评估和决策。
python
from pymilvus import connections, Collection
import openai
# 先初始化向量化函数(和传统RAG一致)
def embed(text):
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response["data"][0]["embedding"]
# 连接Milvus服务(和传统RAG一致)
connections.connect(host='localhost', port='19530')
# ===== 第一步:创建多个专业领域的Collection =====
# 这里我们创建4个Collection,分别对应不同的知识领域
# 注意:实际应用中,每个Collection的创建过程和传统RAG的Collection创建一致,这里简化展示
class MultiSourceRAG:
def __init__(self):
# 存储不同领域的Collection,key为领域名称,value为Collection实例
self.collections = {
"product_docs": Collection("product_docs"), # 产品文档(比如Milvus的产品介绍、功能说明)
"api_reference": Collection("api_reference"), # API参考(比如Milvus的Python SDK API文档)
"customer_cases": Collection("customer_cases"), # 客户案例(比如Milvus的实际应用案例)
"tech_blogs": Collection("tech_blogs") # 技术博客(比如Milvus的技术解析、最佳实践)
}
# 将所有Collection加载到内存,提升检索速度(可根据实际情况动态加载/卸载)
for coll in self.collections.values():
coll.load()
# ===== 第二步:Agent决策,智能检索路由 =====
def smart_retrieve(question, agent_decision):
"""
Agent决策驱动的检索:根据Agent的决策,动态路由到对应的Collection进行检索
agent_decision:Agent的决策结果,字典格式,包含以下字段:
- need_retrieval:是否需要检索(True/False)
- target_collections:需要检索的Collection列表(比如["api_reference", "tech_blogs"])
- top_k:需要返回的最相似文档数量
- filters:检索过滤条件(比如按发布日期过滤)
"""
# 如果Agent判断不需要检索,直接返回空列表
if not agent_decision["need_retrieval"]:
return []
# 初始化多源RAG,获取所有领域的Collection
rag = MultiSourceRAG()
results = []
# 遍历需要检索的Collection,执行检索
for coll_name in agent_decision["target_collections"]:
# 获取当前Collection
collection = rag.collections[coll_name]
# 构建动态过滤表达式(比如过滤出2024年之后发布的文档)
filter_expr = None
if "filters" in agent_decision:
filters = agent_decision["filters"]
# 这里以发布日期过滤为例,实际可根据字段灵活扩展
if "publish_date" in filters:
filter_expr = f'publish_date {filters["publish_date"]}'
# 执行检索(这里使用IP相似度,适合高维向量检索,可根据实际情况调整)
search_params = {"metric_type": "IP", "params": {"nprobe": 16}}
search_results = collection.search(
data=[embed(question)],
anns_field="embedding",
param=search_params,
limit=agent_decision["top_k"],
expr=filter_expr, # 应用过滤条件(Milvus支持标量过滤,非常灵活)
output_fields=["text", "source", "publish_date"] # 返回需要的字段
)
# 将当前Collection的检索结果添加到总结果中
results.extend(search_results[0])
# 返回所有检索结果
return results
# ===== 第三步:检索质量评估,Agent自主判断检索结果是否可用 =====
def retrieve_with_quality_check(question, threshold=0.7):
"""
Agent评估检索质量,决定下一步行动:
- 如果检索结果的相似度都低于阈值,触发fallback策略(比如网页搜索)
- 如果有高质量结果,直接使用这些结果生成答案
"""
# 这里以检索产品文档为例,实际可根据Agent决策动态选择Collection
collection = Collection("product_docs")
collection.load()
# 执行检索
results = collection.search(
data=[embed(question)],
anns_field="embedding",
param={"metric_type": "IP", "params": {"nprobe": 16}},
limit=5
)
# 过滤低质量结果(相似度低于threshold的结果)
high_quality_results = [
hit for hit in results[0]
if hit.score >= threshold
]
# Agent根据过滤结果做决策
if not high_quality_results:
# 没有高质量结果,触发fallback
return {"action": "FALLBACK_TO_WEB_SEARCH", "reason": "本地知识库召回质量不足,需补充网页搜索"}
else:
# 有高质量结果,使用这些结果生成答案
return {"action": "USE_RESULTS", "data": high_quality_results}
# ===== 使用示例:Agent决策检索 + 质量评估 =====
if __name__ == "__main__":
# 模拟Agent的决策结果(实际应用中,Agent可通过LLM分析问题生成决策)
# 示例1:用户问"Milvus的Python SDK如何创建Collection?",需要检索API参考和技术博客
agent_decision1 = {
"need_retrieval": True,
"target_collections": ["api_reference", "tech_blogs"],
"top_k": 3,
"filters": {"publish_date": ">= 2024-01-01"} # 只检索2024年之后的文档
}
question1 = "Milvus的Python SDK如何创建Collection?"
print(f"用户查询1:{question1}")
results1 = smart_retrieve(question1, agent_decision1)
print("检索结果:")
for i, hit in enumerate(results1, 1):
print(f"{i}. 相似度: {hit.score:.3f} | 内容: {hit.entity.get('text')[:50]}... | 来源: {hit.entity.get('source')} | 发布日期: {hit.entity.get('publish_date')}")
# 示例2:用户问"你好,我想了解Milvus",Agent判断不需要检索,直接回复
agent_decision2 = {
"need_retrieval": False
}
question2 = "你好,我想了解Milvus"
print(f"\n用户查询2:{question2}")
results2 = smart_retrieve(question2, agent_decision2)
if not results2:
print("Agent决策:不需要检索,直接回复用户")
print("回复:你好!Milvus是一款开源向量数据库,专注于海量向量数据的存储和检索,广泛应用于AI助手、推荐系统等场景。如需了解更多细节,可以问我具体问题哦~")
# 示例3:检索质量评估
question3 = "Milvus 2.5版本新增了哪些功能?"
print(f"\n用户查询3:{question3}")
quality_check_result = retrieve_with_quality_check(question3, threshold=0.7)
print(f"Agent质量评估结果:{quality_check_result}")
if quality_check_result["action"] == "USE_RESULTS":
print("高质量检索结果:")
for hit in quality_check_result["data"][:2]:
print(f" 相似度: {hit.score:.3f} | 内容: {hit.entity.get('text')[:50]}...")
else:
print("执行Fallback策略:启动网页搜索,补充最新信息")通过上面的代码,我们实现了一个简单的agentic RAG系统。可以看到,Agent能够根据问题类型自主决策是否检索、检索哪个领域的知识,还能评估检索结果的质量,避免无效检索。
但agentic RAG依然有一个核心问题没有解决:它的知识库依然是"只读"的。Agent可以决定什么时候读、读什么,但不能在运行时写入新知识、更新旧知识、删除过时知识。比如用户告诉AI助手"我喜欢简洁的回复,多用emoji",agentic RAG无法把这个偏好存储起来,下次用户交互时,依然无法提供个性化的回复;再比如用户修正了某个信息"我之前说的旅行时间是11月,不是10月",agentic RAG也无法更新这个记忆。
这个问题,就需要我们进入第三个阶段,Agent memory(智能体记忆)系统,实现记忆的完整CRUD能力。
四、演进第三阶段:Agent Memory,动态记忆,让AI拥有"长期记忆"
Agent Memory的核心,是让AI助手拥有和人类一样的"记忆能力":能够实时保存对话中的用户偏好、事件细节,能够检索历史会话中的相关记忆,能够修正用户提供的新信息,能够清理过期或无效的记忆。这就要求底层的存储系统,必须支持运行时的写入、读取、更新、删除(CRUD)操作,而Milvus的多Collection隔离、动态CRUD、混合索引等功能,正是实现Agent Memory的关键。
4.1 Agent Memory的核心需求:记忆分类与生命周期管理
人类的记忆是有分类的,比如我们会记住自己的长期偏好(比如喜欢的颜色、沟通方式),会记住近期的事件(比如明天要去开会),会记住一些事实性知识(比如地球是圆的)。不同类型的记忆,生命周期、重要性都不同,如果混合存储,就会出现很多问题。
比如,把用户的长期偏好和临时的对话记录混存,检索"用户沟通偏好"时,就会混杂大量无关的临时对话,检索精度下降;无法为不同类型的记忆设置差异化的过期策略,要么误删长期偏好,要么临时对话无限膨胀,拖垮系统性能。
因此,Agent Memory的核心需求,就是"记忆分类"和"生命周期管理"。我们可以按照记忆的生命周期和用途,将其分为三类,每类记忆使用独立的Collection存储,设置差异化的策略。
第一类,程序性记忆(Procedural Memory)。主要存储用户的长期偏好、行为规则、习惯等,比如"用户喜欢简洁的回复,多用emoji""用户对技术术语敏感,需要通俗解释"。这类记忆的生命周期很长,通常保留数月甚至数年,重要性很高。
第二类,情景记忆(Episodic Memory)。主要存储对话历史、用户提到的事件、临时需求等,比如"用户10月15日要去巴黎旅行,需要推荐景点""用户今天问了Milvus的安装方法"。这类记忆的生命周期中等,通常保留30-90天,超过期限后可以自动清理。
第三类,语义记忆(Semantic Memory)。主要存储事实性知识、用户提供的特定信息等,比如"埃菲尔铁塔高330米,建于1889年""用户的公司是做人工智能的"。这类记忆的生命周期较长,通常长期有效,但可以被用户修正。
通过这种分类,我们可以为每类记忆设置独立的Collection,配置不同的索引参数、过滤条件、过期策略,既保证检索精度,又能合理管理内存和存储资源。
4.2 Milvus实现Agent Memory的完整架构(附代码)
下面我们用Milvus实现一个完整的Agent Memory系统,包含记忆的分类存储、写入、检索、更新、删除(CRUD)全操作,结合具体的应用场景,让大家能够直接复用。
python
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection
from datetime import datetime
import openai
# 初始化向量化函数(和之前一致)
def embed(text):
response = openai.Embedding.create(
input=text,
model="text-embedding-ada-002"
)
return response["data"][0]["embedding"]
# 连接Milvus服务
connections.connect(host='localhost', port='19530')
# ===== 第一步:定义标准化的记忆Collection Schema =====
def create_memory_collection(name, description):
"""创建标准化的记忆Collection,适用于所有类型的记忆"""
fields = [
# 主键字段,自增,唯一标识每条记忆
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
# 用户ID字段,用于隔离不同用户的记忆(多用户场景必备)
FieldSchema(name="user_id", dtype=DataType.VARCHAR, max_length=64),
# 记忆内容字段,存储具体的记忆文本
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=5000),
# 向量字段,存储记忆内容的向量,维度1536(对应text-embedding-ada-002)
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=1536),
# 重要性字段,用于过滤低重要性记忆(0-1之间,值越高越重要)
FieldSchema(name="importance", dtype=DataType.FLOAT),
# 创建时间字段,用于生命周期管理(时间戳格式)
FieldSchema(name="created_at", dtype=DataType.INT64),
# 元数据字段,存储额外信息(比如记忆类型、分类等),JSON格式
FieldSchema(name="metadata", dtype=DataType.JSON),
]
# 创建Collection Schema
schema = CollectionSchema(fields=fields, description=description)
# 创建Collection
collection = Collection(name=name, schema=schema)
# 为向量字段创建HNSW索引,提升检索速度
collection.create_index(
field_name="embedding",
index_params={"index_type": "HNSW", "metric_type": "IP", "params": {"M": 16}}
)
# 为用户ID字段创建标量索引,加速用户隔离过滤
collection.create_index(field_name="user_id", index_params={"index_type": "TRIE"})
# 加载Collection到内存
collection.load()
return collection
# ===== 第二步:初始化三种类型的记忆Collection =====
class AgentMemorySystem:
def __init__(self):
# 程序性记忆:用户偏好与行为规则(长期有效)
self.procedural_memory = create_memory_collection(
"procedural_memory", "用户偏好与行为规则,长期有效"
)
# 情景记忆:对话历史与事件记录(30-90天过期)
self.episodic_memory = create_memory_collection(
"episodic_memory", "对话历史与事件记录,短期有效"
)
# 语义记忆:事实性知识(长期有效,可修正)
self.semantic_memory = create_memory_collection(
"semantic_memory", "事实性知识,长期有效可修正"
)
# 初始化Agent记忆系统(全局单例,避免重复创建)
memory_system = AgentMemorySystem()
# ===== 核心操作1:记忆写入(Create),实时存储用户记忆 =====
def store_memory(memory_type, user_id, content, importance=0.5, metadata=None):
"""
实时写入记忆到对应的Collection
memory_type:记忆类型(procedural/episodic/semantic)
user_id:用户ID,用于隔离不同用户的记忆
content:记忆内容(文本)
importance:记忆重要性(0-1,默认0.5)
metadata:元数据(字典格式,可选)
"""
# 根据记忆类型,选择对应的Collection
if memory_type == "procedural":
collection = memory_system.procedural_memory
elif memory_type == "episodic":
collection = memory_system.episodic_memory
else: # semantic
collection = memory_system.semantic_memory
# 准备数据,注意字段顺序和Schema一致
data = [{
"user_id": user_id,
"content": content,
"embedding": embed(content),
"importance": importance,
"created_at": int(datetime.now().timestamp()), # 当前时间戳
"metadata": metadata or {} # 元数据,默认空字典
}]
# 实时插入数据
collection.insert(data)
# 刷新数据,确保持久化
collection.flush()
print(f"✅ 已存储{memory_type}记忆(用户{user_id}): {content[:50]}...")
# ===== 核心操作2:记忆检索(Read),智能检索用户相关记忆 =====
def retrieve_memories(user_id, query, memory_type="all", top_k=5, min_importance=0.3):
"""
智能检索用户的相关记忆,支持多类型记忆检索和过滤
user_id:用户ID,只检索该用户的记忆
query:检索关键词(比如"巴黎旅行""沟通偏好")
memory_type:检索的记忆类型(all/procedural/episodic/semantic)
top_k:返回的最相似记忆数量
min_importance:最低重要性阈值,过滤低重要性记忆
"""
# 将检索关键词转换为向量
query_embedding = embed(query)
# 存储检索结果,key为记忆类型,value为检索结果
results = {}
# 构建过滤表达式:用户隔离 + 重要性过滤
filter_expr = f'user_id == "{user_id}" && importance >= {min_importance}'
# 检索参数,ef越大,精度越高,速度越慢
search_params = {"metric_type": "IP", "params": {"ef": 100}}
# 选择需要检索的Collection
collections_to_search = []
if memory_type in ["all", "procedural"]:
collections_to_search.append(("procedural", memory_system.procedural_memory))
if memory_type in ["all", "episodic"]:
collections_to_search.append(("episodic", memory_system.episodic_memory))
if memory_type in ["all", "semantic"]:
collections_to_search.append(("semantic", memory_system.semantic_memory))
# 遍历需要检索的Collection,执行检索
for mem_type, collection in collections_to_search:
search_results = collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=top_k,
expr=filter_expr,
output_fields=["content", "importance", "created_at", "metadata"]
)
# 将检索结果存入results字典
results[mem_type] = search_results[0]
return results
# ===== 核心操作3:记忆更新与删除(Update & Delete),动态维护记忆 =====
def update_memory(collection, memory_id, new_content, new_importance=None):
"""
更新记忆内容(Milvus 2.3+支持upsert操作,推荐使用)
注意:生产环境中,不推荐使用"先删后插",建议使用Milvus的upsert(原子操作,避免数据丢失)
collection:需要更新的Collection实例
memory_id:需要更新的记忆ID(主键)
new_content:新的记忆内容
new_importance:新的重要性(可选,默认沿用原重要性)
"""
# 先查询旧记忆的信息,获取原重要性(如果未指定新重要性)
if new_importance is None:
# 查询旧记忆
old_memory = collection.query(
expr=f"id == {memory_id}",
output_fields=["importance"]
)
if old_memory:
new_importance = old_memory[0]["importance"]
else:
print("❌ 未找到需要更新的记忆,更新失败")
return
# 方案1:先删后插(存在数据丢失风险,仅用于演示)
# 删除旧记忆
collection.delete(expr=f"id == {memory_id}")
# 插入新记忆
data = [{
"user_id": collection.query(expr=f"id == {memory_id}", output_fields=["user_id"])[0]["user_id"],
"content": new_content,
"embedding": embed(new_content),
"importance": new_importance,
"created_at": int(datetime.now().timestamp()),
"metadata": collection.query(expr=f"id == {memory_id}", output_fields=["metadata"])[0]["metadata"]
}]
collection.insert(data)
collection.flush()
print(f"✅ 已更新记忆(ID:{memory_id}): {new_content[:50]}...")
# 方案2:使用Milvus的upsert操作(原子操作,推荐生产环境使用)
# data = [{
# "id": memory_id, # 必须指定主键ID,upsert会根据ID更新或插入
# "user_id": "user_123",
# "content": new_content,
# "embedding": embed(new_content),
# "importance": new_importance,
# "created_at": int(datetime.now().timestamp()),
# "metadata": {}
# }]
# collection.upsert(data)
# collection.flush()
def forget_memory(collection, criteria):
"""
选择性遗忘记忆(清理过期、低重要性的记忆)
collection:需要清理的Collection实例
criteria:清理条件(字典格式),支持以下条件:
- older_than_days:清理多少天前的记忆
- min_importance:清理低于该重要性的记忆
"""
# 构建清理过滤表达式
filter_expr = []
# 时间过滤:清理指定天数前的记忆
if "older_than_days" in criteria:
# 计算截止时间戳(当前时间 - 天数*每天的秒数)
cutoff_time = int(datetime.now().timestamp()) - criteria["older_than_days"] * 86400
filter_expr.append(f"created_at < {cutoff_time}")
# 重要性过滤:清理低于指定重要性的记忆
if "min_importance" in criteria:
filter_expr.append(f"importance < {criteria['min_importance']}")
# 如果有过滤条件,执行删除操作
if filter_expr:
filter_expr = " && ".join(filter_expr)
# 执行删除
delete_count = collection.delete(expr=filter_expr)[0]
print(f"🗑️ 已清理符合条件的记忆 {delete_count} 条,过滤条件:{filter_expr}")
else:
print("❌ 未指定清理条件,无法执行遗忘操作")
# ===== 使用示例:CRUD全流程实操 =====
if __name__ == "__main__":
# 模拟用户ID(实际应用中可从登录信息中获取)
user_id = "user_123"
# 场景1:写入三种类型的记忆
print("=== 场景1:写入记忆 ===")
# 写入程序性记忆(用户沟通偏好,重要性高)
store_memory(
memory_type="procedural",
user_id=user_id,
content="用户喜欢简洁的回复,多用emoji,避免使用复杂的技术术语",
importance=0.8,
metadata={"category": "communication_style"}
)
# 写入情景记忆(用户旅行计划,重要性高)
store_memory(
memory_type="episodic",
user_id=user_id,
content="用户提到11月15日要去巴黎旅行,需要推荐景点和美食",
importance=0.9,
metadata={"event_type": "travel_plan", "date": "2024-11-15"}
)
# 写入语义记忆(事实性知识,重要性中等)
store_memory(
memory_type="semantic",
user_id=user_id,
content="埃菲尔铁塔位于法国巴黎,高330米,建于1889年,是巴黎的标志性建筑",
importance=0.7,
metadata={"entity": "埃菲尔铁塔", "source": "wikipedia"}
)
# 场景2:检索用户相关记忆
print("\n=== 场景2:检索记忆 ===")
# 检索用户的巴黎旅行相关记忆(所有类型)
query = "用户的巴黎旅行计划"
memories = retrieve_memories(
user_id=user_id,
query=query,
memory_type="all",
min_importance=0.7
)
print(f"检索关键词:{query}")
for mem_type, hits in memories.items():
if hits:
print(f"\n【{mem_type}记忆】:")
for hit in hits[:2]:
print(f" 相似度: {hit.score:.3f} | 内容: {hit.entity.get('content')[:60]}... | 重要性: {hit.entity.get('importance')}")
# 场景3:更新记忆(用户修正旅行时间)
print("\n=== 场景3:更新记忆 ===")
# 假设我们查询到旅行计划的记忆ID是12345(实际应用中可通过检索获取)
update_memory(
collection=memory_system.episodic_memory,
memory_id=12345,
new_content="用户提到11月20日要去巴黎旅行,需要推荐景点和美食",
new_importance=0.9
)
# 场景4:遗忘过期记忆(清理90天前的低重要性情景记忆)
print("\n=== 场景4:遗忘记忆 ===")
forget_memory(
collection=memory_system.episodic_memory,
criteria={"older_than_days": 90, "min_importance": 0.4}
)通过上面的代码,我们实现了一个完整的Agent Memory系统,具备记忆的分类存储、写入、检索、更新、删除全能力。这个系统能够实时记录用户的偏好、对话历史、事实知识,能够根据用户的查询精准检索相关记忆,能够动态更新和清理记忆,真正让AI助手拥有了"长期记忆"。
需要注意的是,生产环境中,我们需要优化几个细节:一是使用Milvus的upsert操作替代"先删后插",避免数据丢失;二是为情景记忆设置定时清理任务,自动删除过期记忆;三是优化检索参数,根据数据量调整HNSW的M、ef等参数,平衡检索精度和速度。
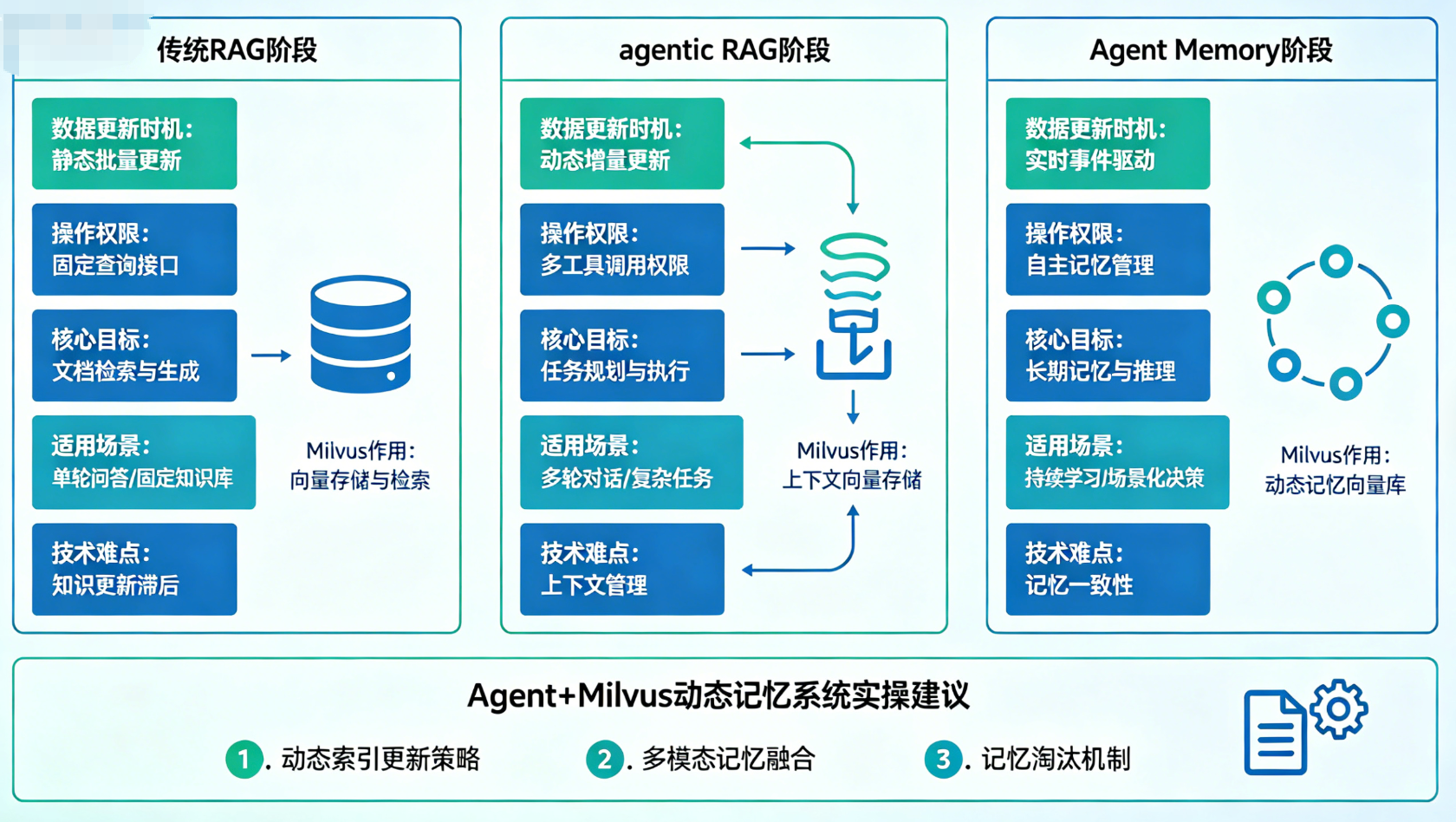
五、三个阶段的本质差异:从"只读"到"读写"的蜕变
回顾从传统RAG到Agent Memory的三个演进阶段,我们不难发现,核心变化体现在两个关键维度:数据更新时机和操作权限。这两个维度的变化,决定了AI助手从"问答机器"到"智能体"的蜕变。
5.1 三个阶段的核心差异总结
我们用一张表格,清晰总结三个阶段的核心差异,方便大家选型和理解。
第一阶段,传统RAG:只读的外部知识库。数据更新时机是离线阶段,运行时只支持查询操作,无法更新、删除数据。核心目标是解决LLM的知识截止日期问题,适合简单的问答场景,比如产品说明书查询、技术文档检索。技术难点在于向量检索的精度和速度,Milvus的向量索引能够很好地解决这个问题。
第二阶段,agentic RAG:按需检索的智能检索。数据更新时机依然是离线阶段,运行时依然只支持查询操作,但增加了检索决策机制。核心目标是提升检索效率,避免无效检索,适合中等复杂度的问答场景,比如多领域知识查询、个性化问答。技术难点在于Agent的检索决策逻辑,需要结合LLM实现精准的路由和质量评估。
第三阶段,Agent Memory:动态可读写的记忆系统。数据更新时机是运行时,支持完整的CRUD操作,能够实时写入、更新、删除记忆。核心目标是实现AI助手的长期记忆和个性化服务,适合复杂的交互场景,比如智能助手、私人顾问、客户服务机器人。技术难点在于记忆的分类管理、生命周期控制和工程化落地。
5.2 反直觉的发现:技术难度下降,工程难度上升
在梳理这三个阶段的演进过程中,我们会发现一个反直觉的现象:技术难度在下降,而工程难度在上升。
传统RAG的核心技术难点,是如何实现海量向量的毫秒级检索,需要深入理解向量索引算法、相似度计算等技术细节,对开发者的技术能力要求较高。而到了Agent Memory阶段,Milvus已经把CRUD、向量索引、标量过滤等核心功能都封装好了,开发者不需要再深入底层技术,只需要调用API即可实现记忆的全操作,技术难度大大降低。
但工程难度却在不断上升。传统RAG只需要做好文档切片、向量插入、检索查询即可,工程复杂度较低;而Agent Memory阶段,需要解决一系列工程决策问题:什么信息值得记?记多久?什么时候更新?什么时候忘掉?这些问题没有统一的答案,需要结合具体的应用场景来决策。
比如,用户的随口抱怨要不要记?如果记,会增加记忆量,影响检索精度;如果不记,可能会错过用户的潜在需求。再比如,用户提供的信息有误,AI助手该如何修正记忆?三个月不登录的用户,记忆要不要清理?清理多少?这些问题都需要开发者结合业务场景,制定合理的记忆策略,而这正是Agent Memory工程化落地的核心难点。
六、实操建议:如何快速落地Agent+Milvus动态记忆系统?
对于大多数开发者来说,不需要从零开始搭建整个系统,可以基于我们前面的代码,结合自身的应用场景,逐步落地Agent+Milvus动态记忆系统。这里给大家提供几个实操建议,帮助大家少走弯路。
6.1 选型建议:根据场景选择合适的阶段
如果你的应用场景是简单的问答,比如产品说明书查询、技术文档检索,不需要长期记忆,那么传统RAG就足够了,搭建简单、维护成本低。
如果你的应用场景是多领域问答,需要减少无效检索,提升响应速度,那么可以选择agentic RAG,重点优化Agent的检索决策逻辑。
如果你的应用场景是个性化交互,需要长期记忆用户的偏好、习惯、历史对话,那么必须选择Agent Memory,重点做好记忆分类和生命周期管理。
6.2 Milvus配置优化建议
Milvus的配置直接影响系统的性能,这里给大家几个关键的配置建议:
第一,索引选择。如果是中小规模数据(百万级以下),可以使用HNSW索引,兼顾检索速度和精度;如果是大规模数据(亿级以上),可以使用IVF_FLAT索引,检索速度更快,适合高并发场景。
第二,参数调整。HNSW索引的M参数建议设置为16-32,efConstruction参数建议设置为256-512,ef参数建议设置为100-200,根据数据量和检索精度需求调整。
第三,多Collection优化。为不同类型的记忆创建独立的Collection,设置差异化的索引参数和过滤条件,避免数据混存导致的检索精度下降。
第四,定时任务。为情景记忆设置定时清理任务,比如每天清理一次90天前的低重要性记忆,避免内存和存储资源被占用。
6.3 工程化落地建议
第一,多用户隔离。通过user_id字段,隔离不同用户的记忆,避免记忆混淆,保护用户隐私。
第二,记忆策略明确。提前制定记忆的分类规则、重要性评估标准、过期策略,比如哪些信息属于程序性记忆,哪些属于情景记忆,重要性如何划分,过期时间如何设置。
第三,容错处理。在记忆更新、删除时,做好容错处理,比如使用Milvus的upsert操作,避免数据丢失;在检索失败时,触发fallback策略,比如网页搜索、默认回复。
第四,监控与优化。监控系统的检索速度、精度、内存占用等指标,根据实际运行情况,优化索引参数、记忆策略,提升系统性能。