目录
- 一、File类与IO流概述
-
- [1.1 文件路径的写法和相对路径](#1.1 文件路径的写法和相对路径)
- [1.2 File类对象的创建](#1.2 File类对象的创建)
- [1.3 File类常用API](#1.3 File类常用API)
- [1.4 文件搜索](#1.4 文件搜索)
- [1.5 字符集的编码/解码](#1.5 字符集的编码/解码)
- [1.6 IO流概述](#1.6 IO流概述)
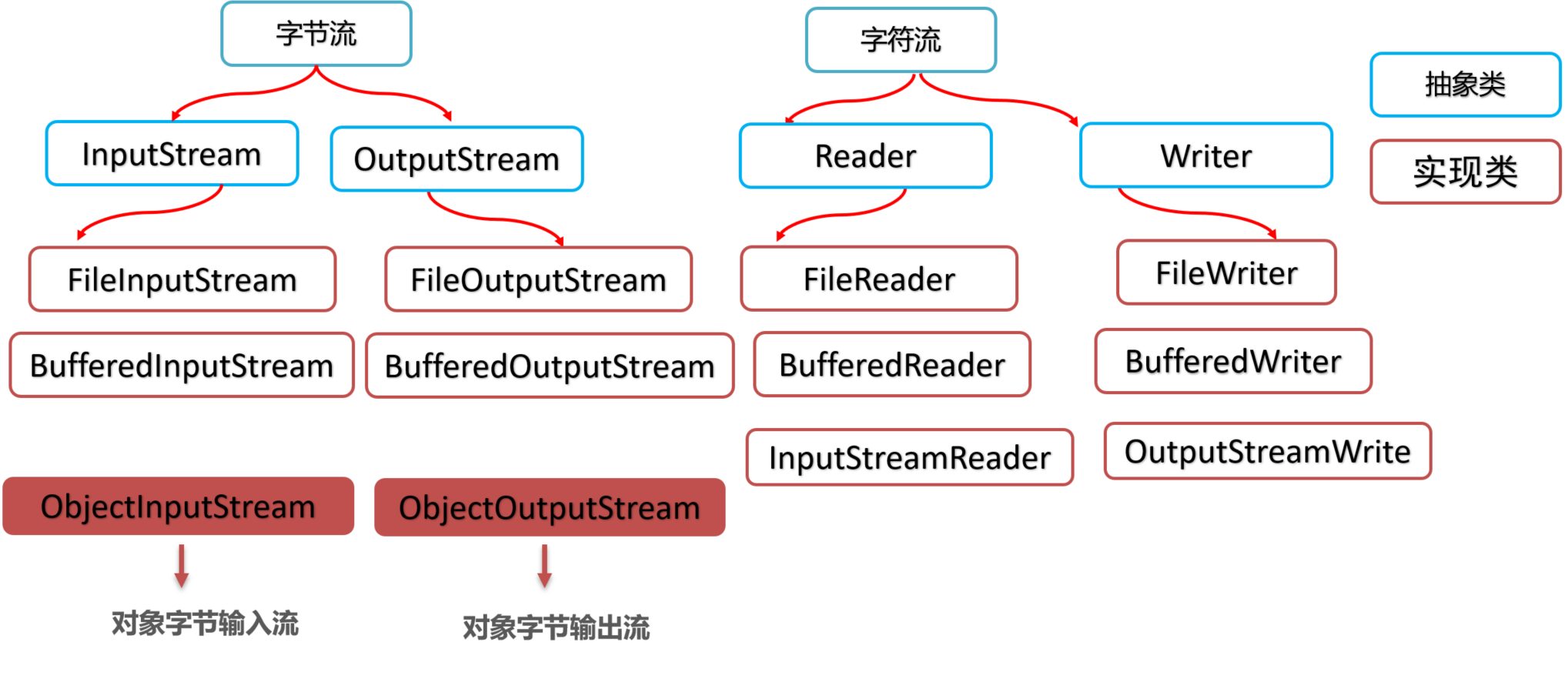
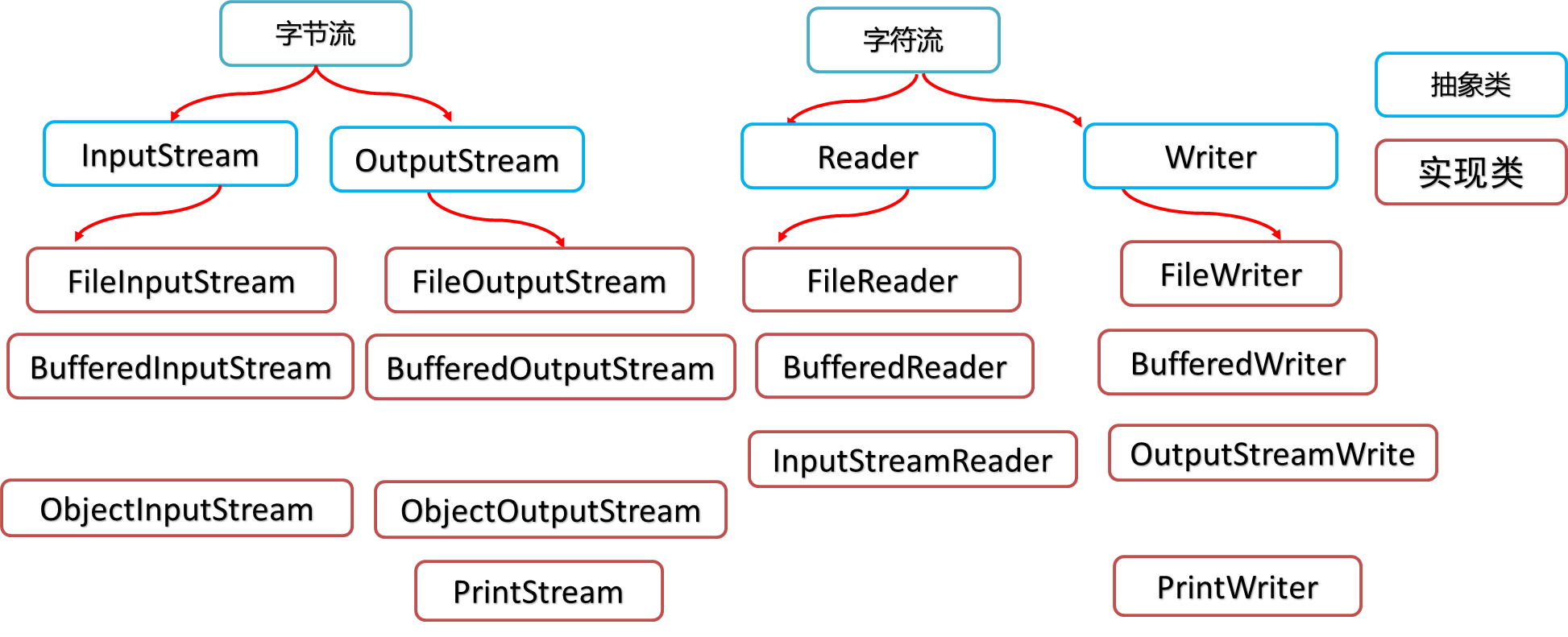
- [1.7 IO流的分类](#1.7 IO流的分类)
- [1.8 IO体系图](#1.8 IO体系图)
- 二、字节流
-
- [2.1 文件字节输入流(FileInputStream)](#2.1 文件字节输入流(FileInputStream))
-
- 创建对象与常用API
- [每次读取一个字节int read()](#每次读取一个字节int read())
- [每次读取一个字节数组int read(byte\[\] buffer)](#每次读取一个字节数组int read(byte[] buffer))
- 一次读完全部字节→避免解码中文输出乱码
- [2.2 文件字节输出流(FileOutputStream)](#2.2 文件字节输出流(FileOutputStream))
-
- 创建对象与常用API
- 追加管道与覆盖管道
- [每次写出一个字节void write()](#每次写出一个字节void write())
- [每次写出一个字节数组void write(byte\[\] buffer)](#每次写出一个字节数组void write(byte[] buffer))
- [每次写出一个字节数组的一部分write(byte\[\] buffer,int pos,int len)](#每次写出一个字节数组的一部分write(byte[] buffer,int pos,int len))
- [2.3 文件拷贝](#2.3 文件拷贝)
- [2.4 资源释放](#2.4 资源释放)
- 三、字符流
-
- [3.1 文件字符输入流(FileReader)](#3.1 文件字符输入流(FileReader))
-
- 创建对象与常用API
- [每次读取一个字符int read()](#每次读取一个字符int read())
- [每次读取一个字符数组int read(char\[\] buffer])](#每次读取一个字符数组int read(char[] buffer]))
- [3.2 文件字符输出流(FileWriter)](#3.2 文件字符输出流(FileWriter))
- [3.3 Properties](#3.3 Properties)
- [3.4 总结](#3.4 总结)
- 四、缓冲流
-
- [4.1 概述与体系图](#4.1 概述与体系图)
- [4.2 字节缓冲流](#4.2 字节缓冲流)
- [4.3 字节缓冲流改进文件拷贝](#4.3 字节缓冲流改进文件拷贝)
- [4.4 字符缓冲流](#4.4 字符缓冲流)
- [4.5 案例:拷贝出师表 并恢复顺序](#4.5 案例:拷贝出师表 并恢复顺序)
- 五、字符转换流
-
- [5.1 体系图与构造器](#5.1 体系图与构造器)
- [5.2 字符输入转换流](#5.2 字符输入转换流)
- [5.3 字符输出转换流](#5.3 字符输出转换流)
- 六、序列化
-
- [6.1 概述与体系图](#6.1 概述与体系图)
- [6.2 序列化(对象字节输出流)](#6.2 序列化(对象字节输出流))
- [6.3 反序列化(对象字节输入流)](#6.3 反序列化(对象字节输入流))
- 七、打印流
-
- [7.1 体系图](#7.1 体系图)
- [7.2 PrintStream/PrintWriter](#7.2 PrintStream/PrintWriter)
- [7.3 输出语句重定向](#7.3 输出语句重定向)
- 八、Commons-io包介绍
-
- [8.1 简介](#8.1 简介)
- [8.2 常用类和方法](#8.2 常用类和方法)
- [8.3 Maven坐标](#8.3 Maven坐标)
一、File类与IO流概述
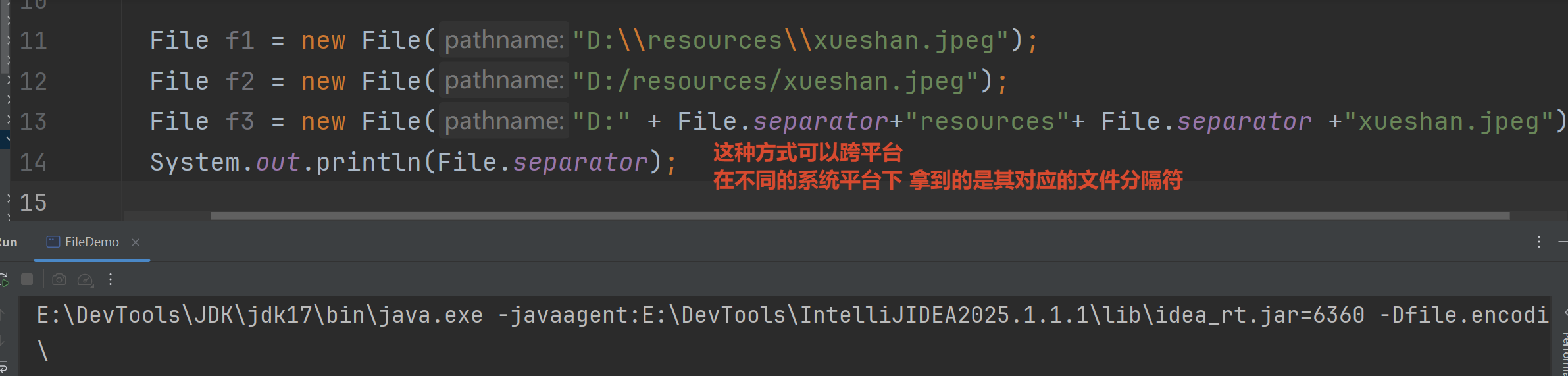
1.1 文件路径的写法和相对路径
第一种需要\\转义出\
第二种不会跟转义字符冲突
第三种可以跨平台
绝对路径依赖当前系统的具体盘符信息相对路径可以直接定位到当前工程下 把资源放在工程里 任何一个平台都可以使用这个路径

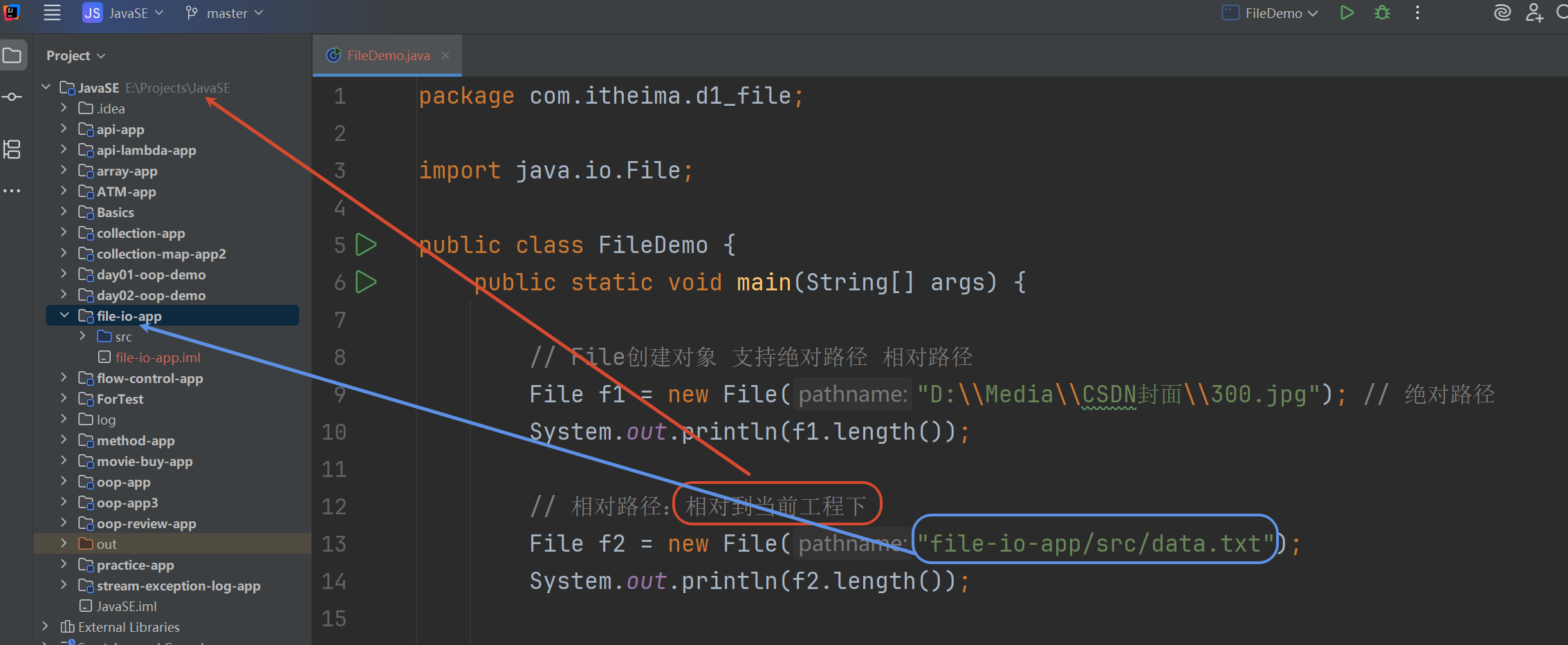
1.2 File类对象的创建
File类在java.io.File包下
File类的对象代表操作系统的文件/文件夹
File类提供了诸如创建文件对象、获取文件信息(大小 修改时间等)、删除文件、创建文件等等API
注意:File对象是不能直接读写文件内容的
File的对象可以是文件或者文件夹但是Java不像Windows会计算一个文件夹的总大小 所以一般Java里文件夹对象.length()没意义 不会返回准确的字节大小
如果想获得某个文件夹大小→递归遍历求和

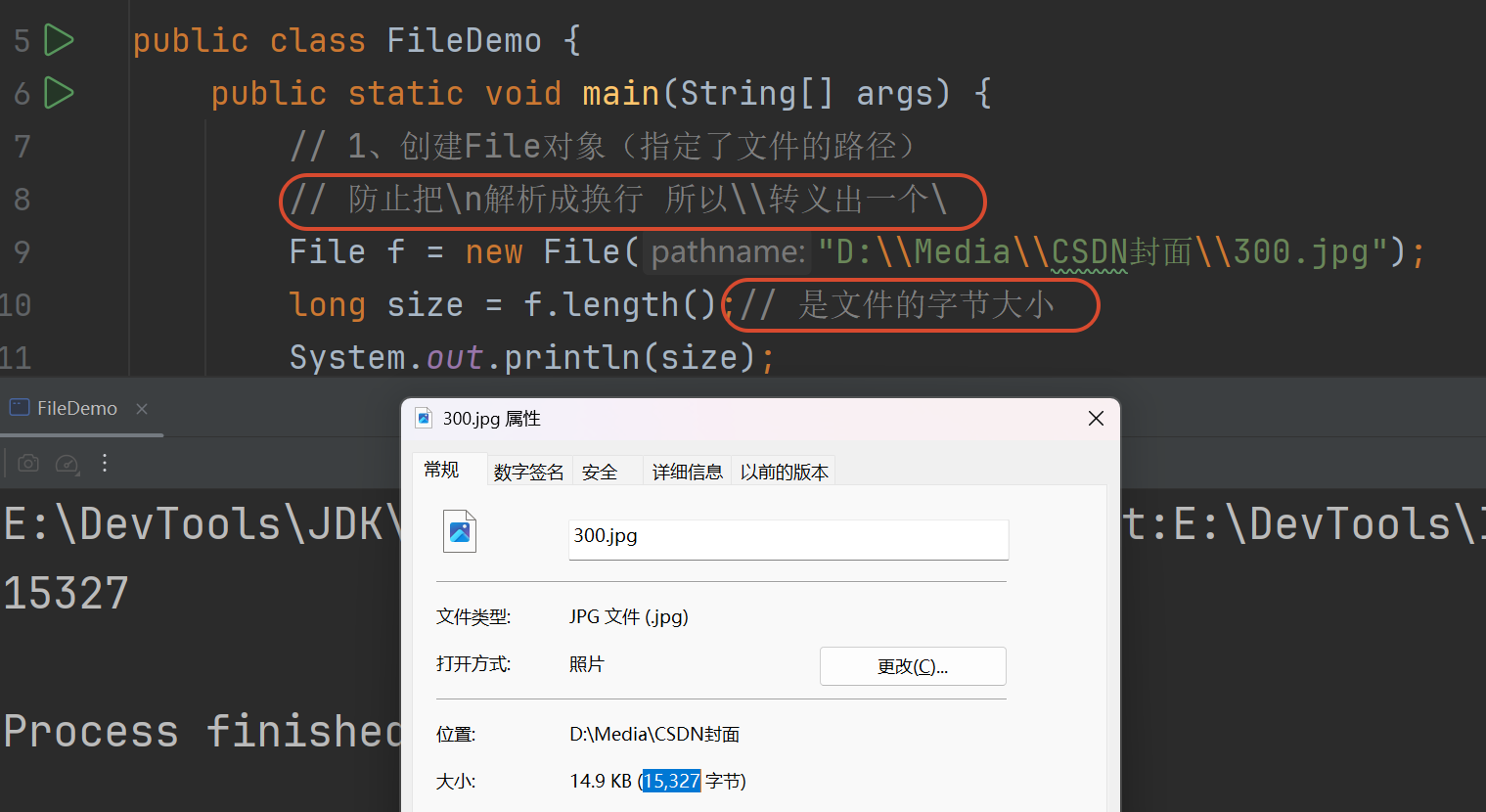

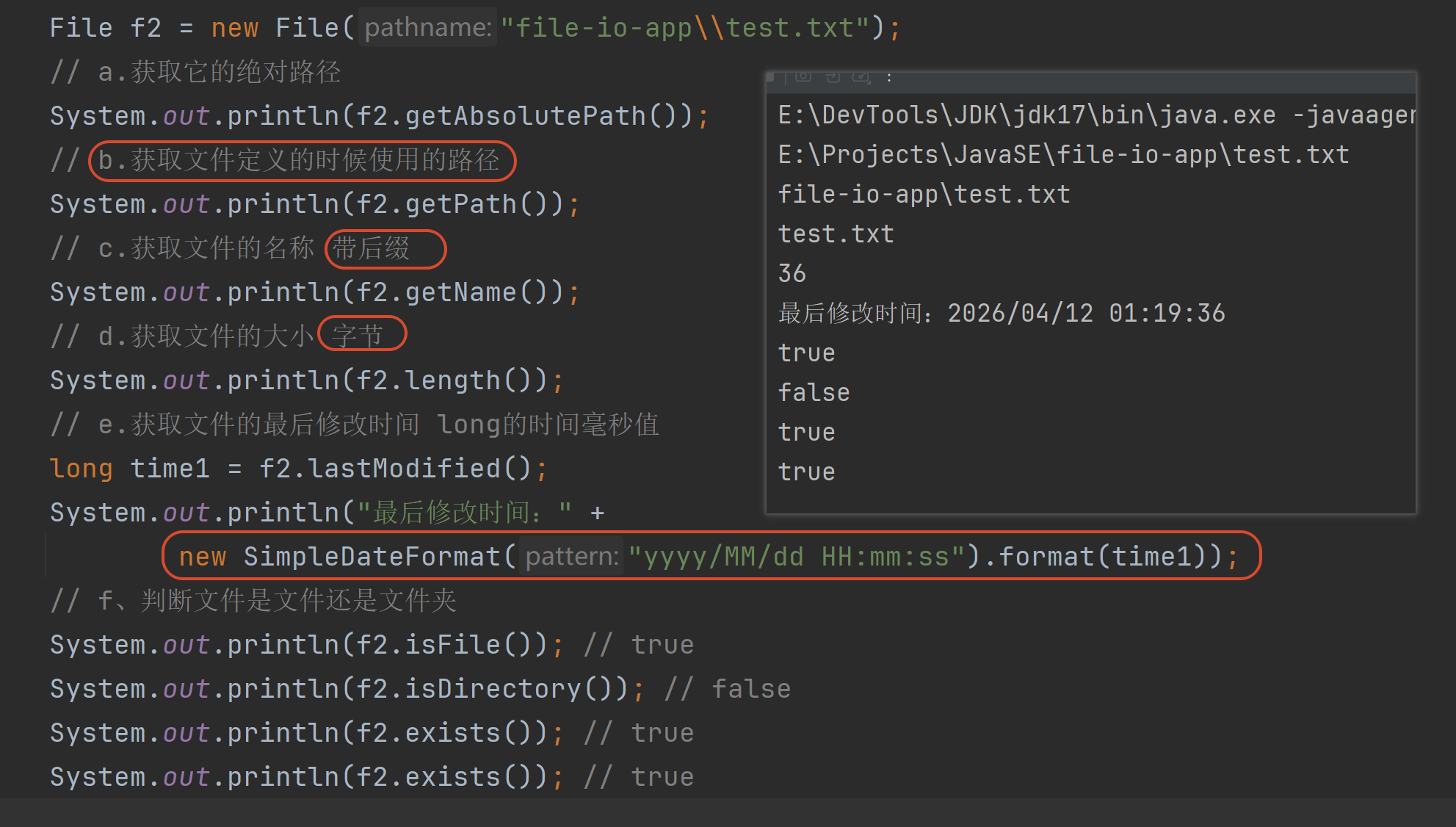
1.3 File类常用API
获取文件信息
public String getAbsolutePath() 返回此File对象的绝对路径名字符串
public String getPath() 获取创建文件对象的时候 用的路径
public String getName() 返回由此File表示的文件或目录的名称
public long length() 返回由此File表示的文件的字节大小
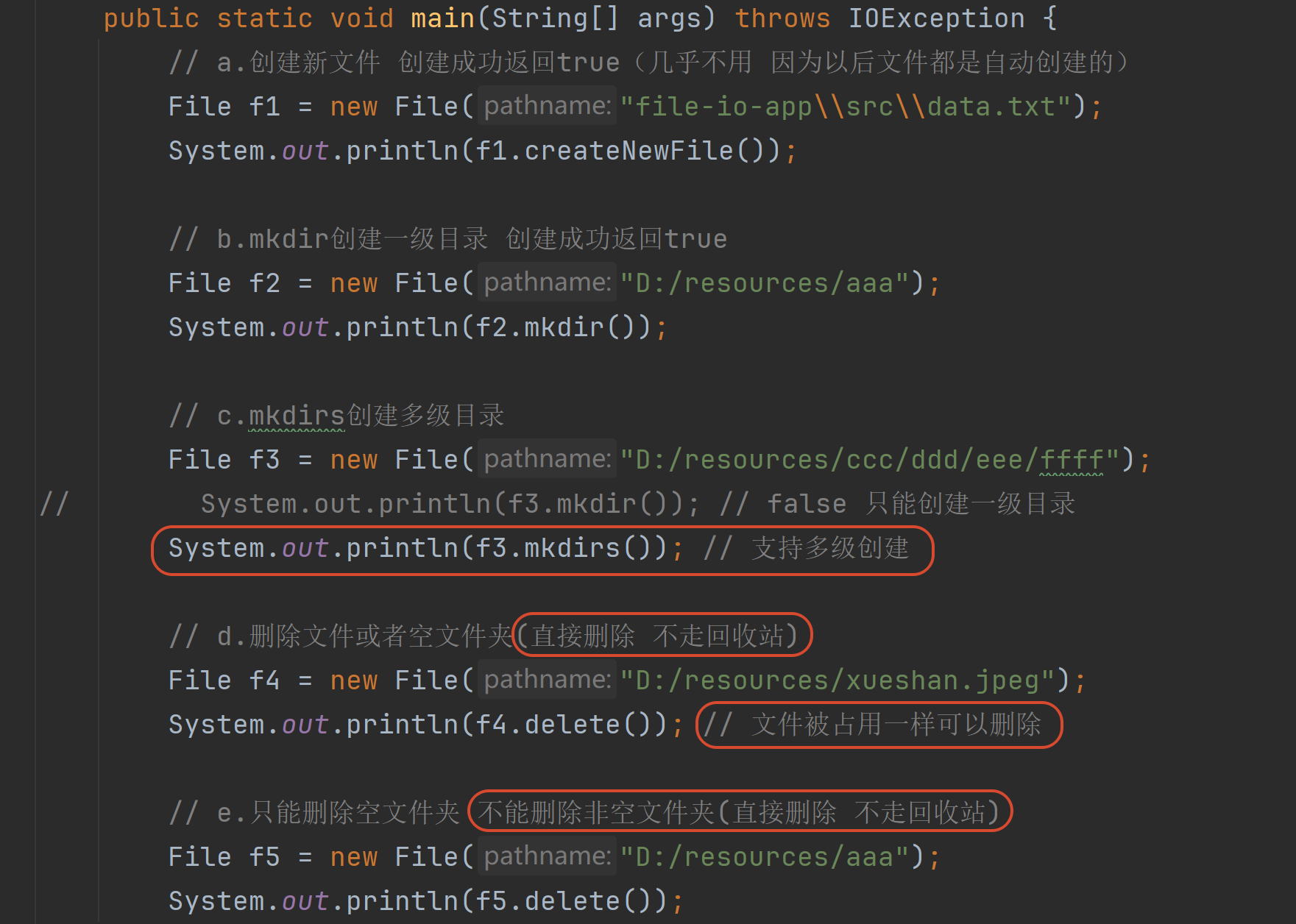
创建/删除文件
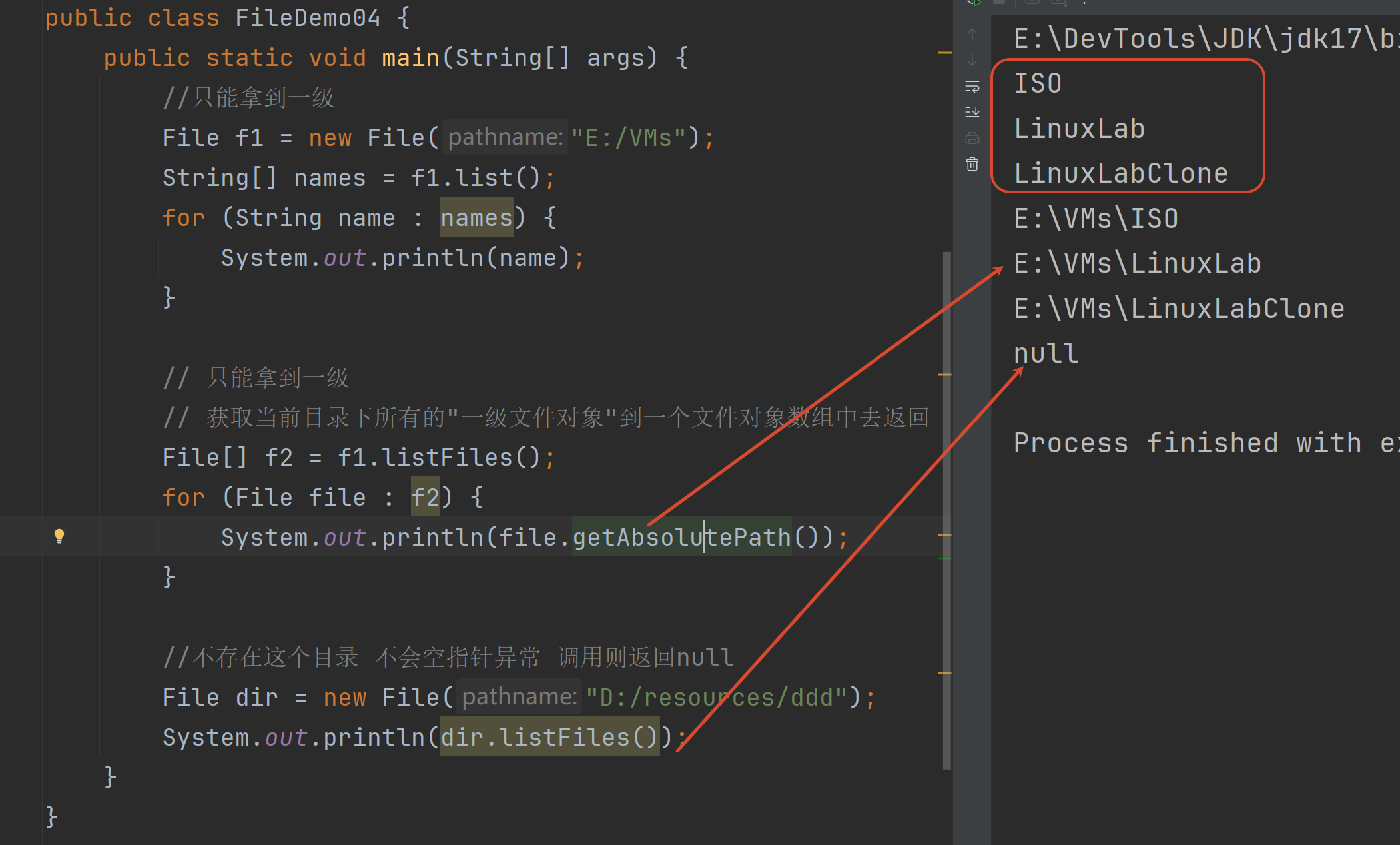
遍历文件夹 调用者必须是一个目录(文件夹)的File对象dir.listFiles 如果返回值是null 说明:
1.dir不是目录 是个文件
2.dir不存在 路径错误
3.权限不足(Java和Windows对于权限的理解是有偏差的)
4.IO异常



1.4 文件搜索
非规律化递归 流程化的编程思维

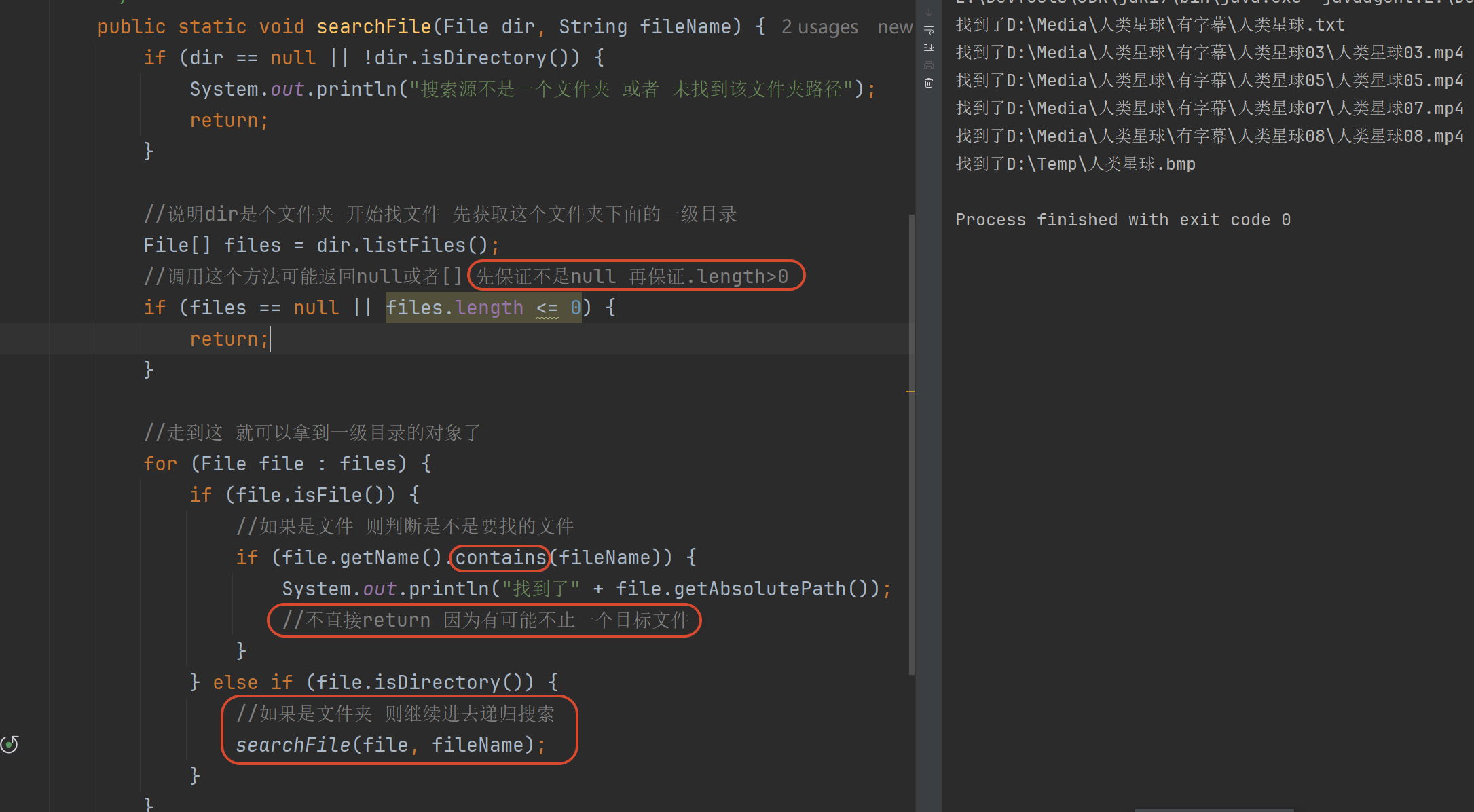
java
import java.io.File;
public class Search {
public static void main(String[] args) {
// 传入搜索源 和 要搜索的文件名称
searchFile(new File("D:/"), "人类星球");
}
/**
* 搜索某个目录下的全部文件/目录 找到目标文件
*
* @param dir 被搜索的源目录
* @param fileName 被搜索的目标文件名称
*/
public static void searchFile(File dir, String fileName) {
if (dir == null || !dir.isDirectory()) {
System.out.println("搜索源不是一个文件夹 或者 未找到该文件夹路径");
return;
}
//说明dir是个文件夹 开始找文件 先获取这个文件夹下面的一级目录
File[] files = dir.listFiles();
// 调用这个方法可能返回null(dir不是文件夹 文件夹路径错误 没有权限)或者[]
// 先保证不是null 再保证.length>0
if (files == null || files.length <= 0) {
//当前目录不存在一级文件对象了 不再继续找
return;
}
//走到这 就可以拿到当前目录的 一级文件对象
for (File file : files) {
if (file.isFile()) {
//如果是文件 则判断是不是要找的文件
if (file.getName().contains(fileName)) {//模糊查询
System.out.println("找到了" + file.getAbsolutePath());
//不直接return 因为有可能不止一个目标文件
}
} else if (file.isDirectory()) {
//如果是文件夹 则继续进去递归搜索
searchFile(file, fileName);
}
}
}
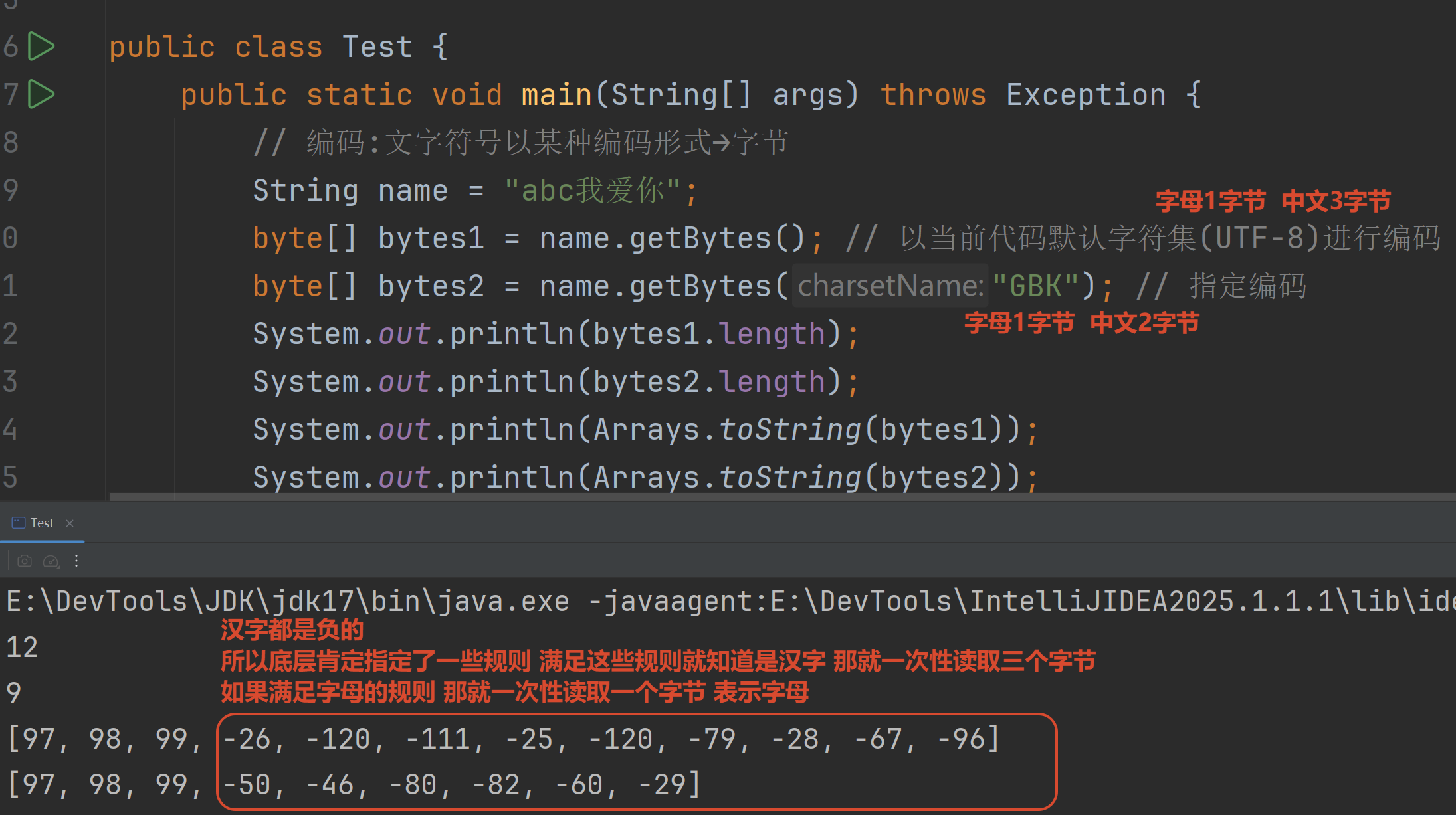
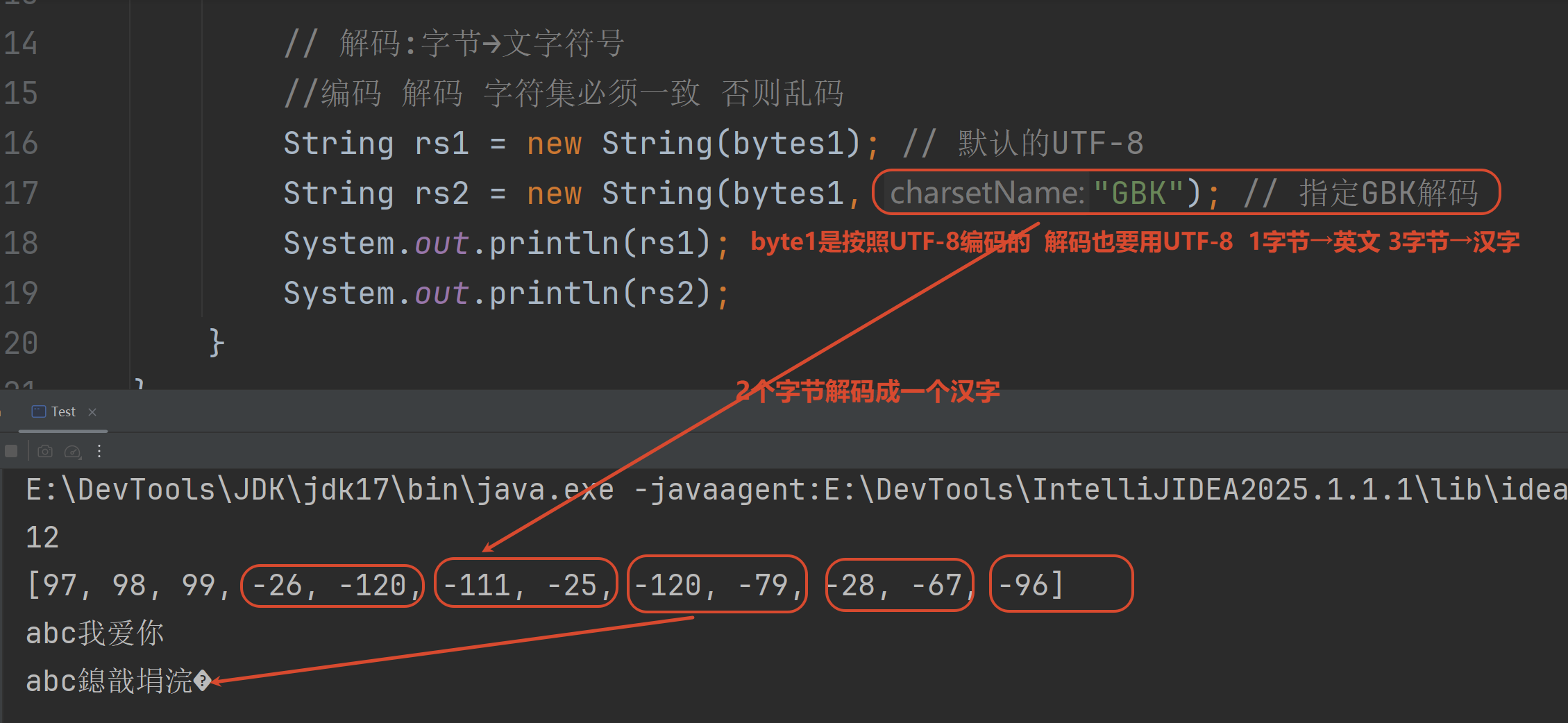
}1.5 字符集的编码/解码
编码是调用方法
解码是调用构造器
编码:字符串.getBytes()
解码:new String(字节数组)
本身编码的时候是把1个汉字→3个字节
解码的时候把2个字节→1个汉字 所以乱码
但是英文一直都是一个字节去编码解码 所以没有乱码

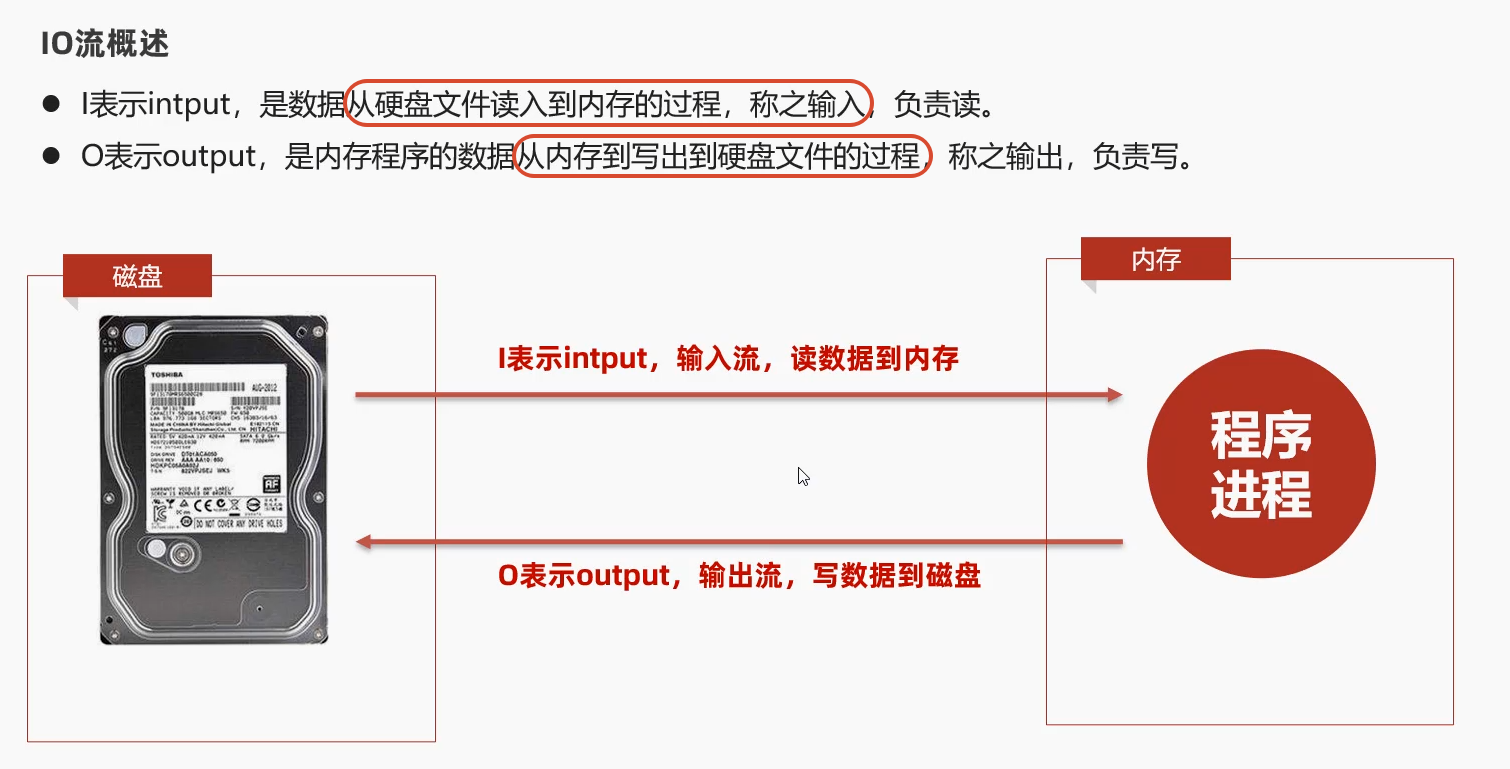
1.6 IO流概述
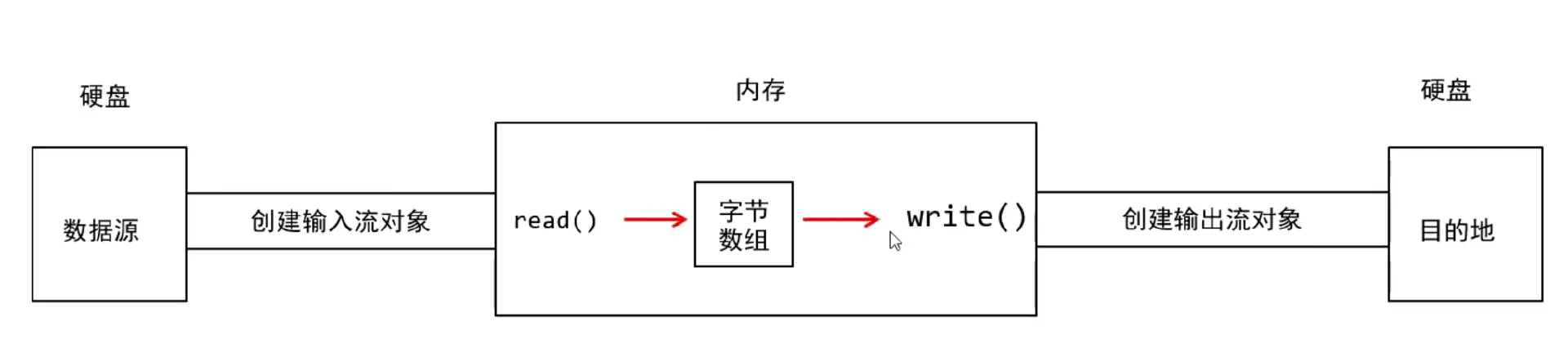
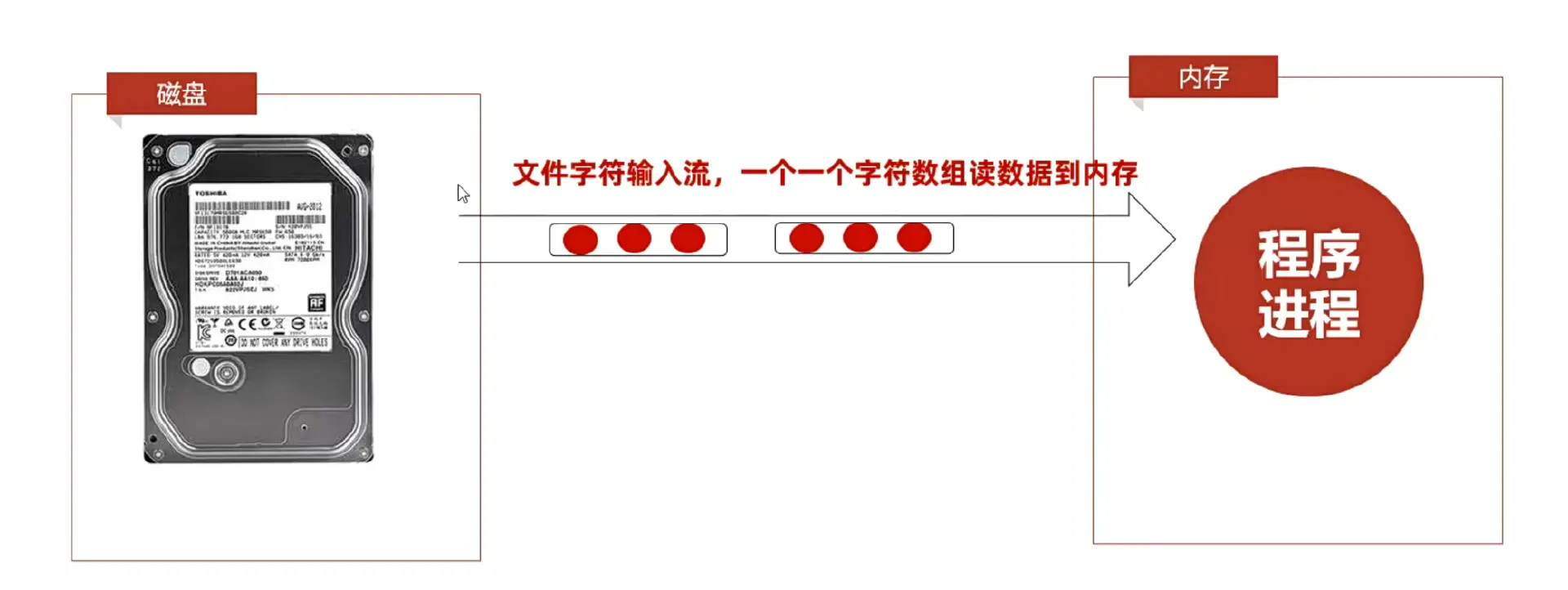
输入/输出流:读写数据

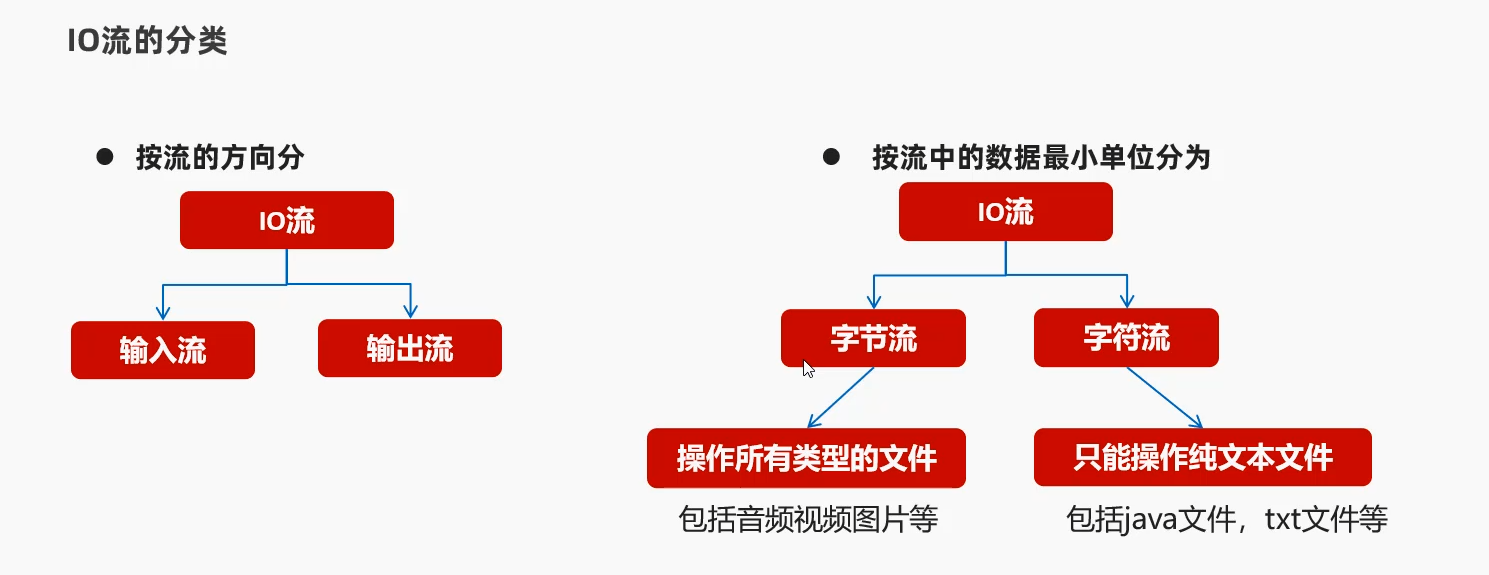
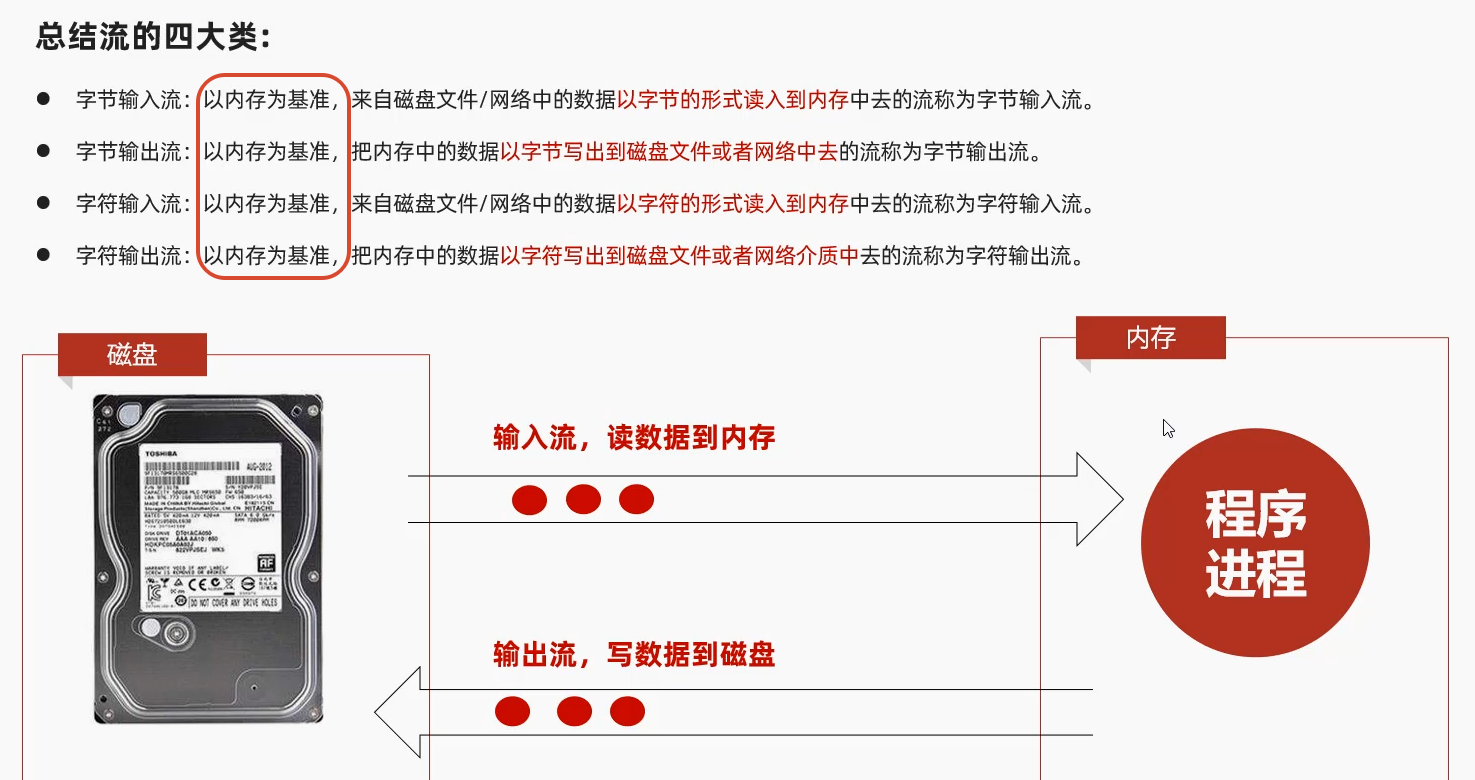
1.7 IO流的分类
都是以内存为基准 往内存去 就是输入 就是读入
记忆:
Reader就是读入 就是Input输入 读入到内存的
Writer就是写出 就是Output输出 写出到磁盘的
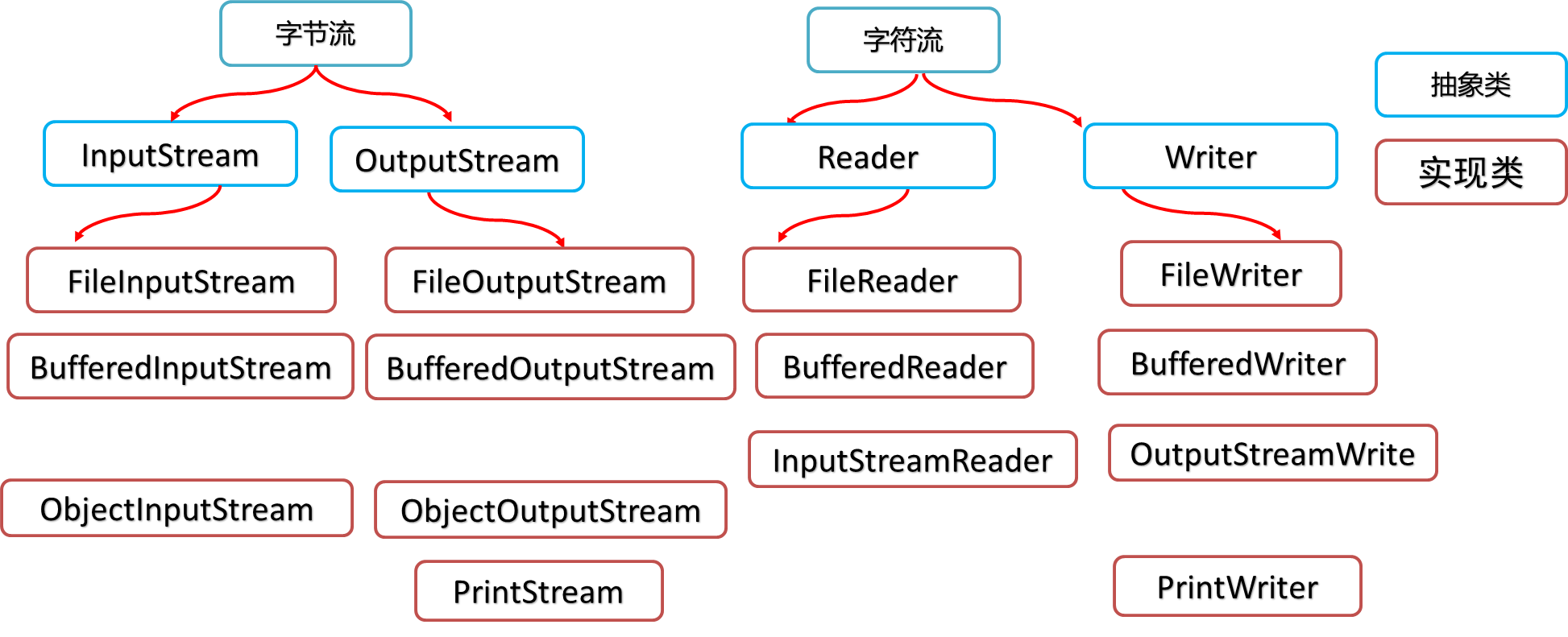
1.8 IO体系图
抽象类不能直接new
具体使用还是他们的实现子类
二、字节流
2.1 文件字节输入流(FileInputStream)
创建对象与常用API
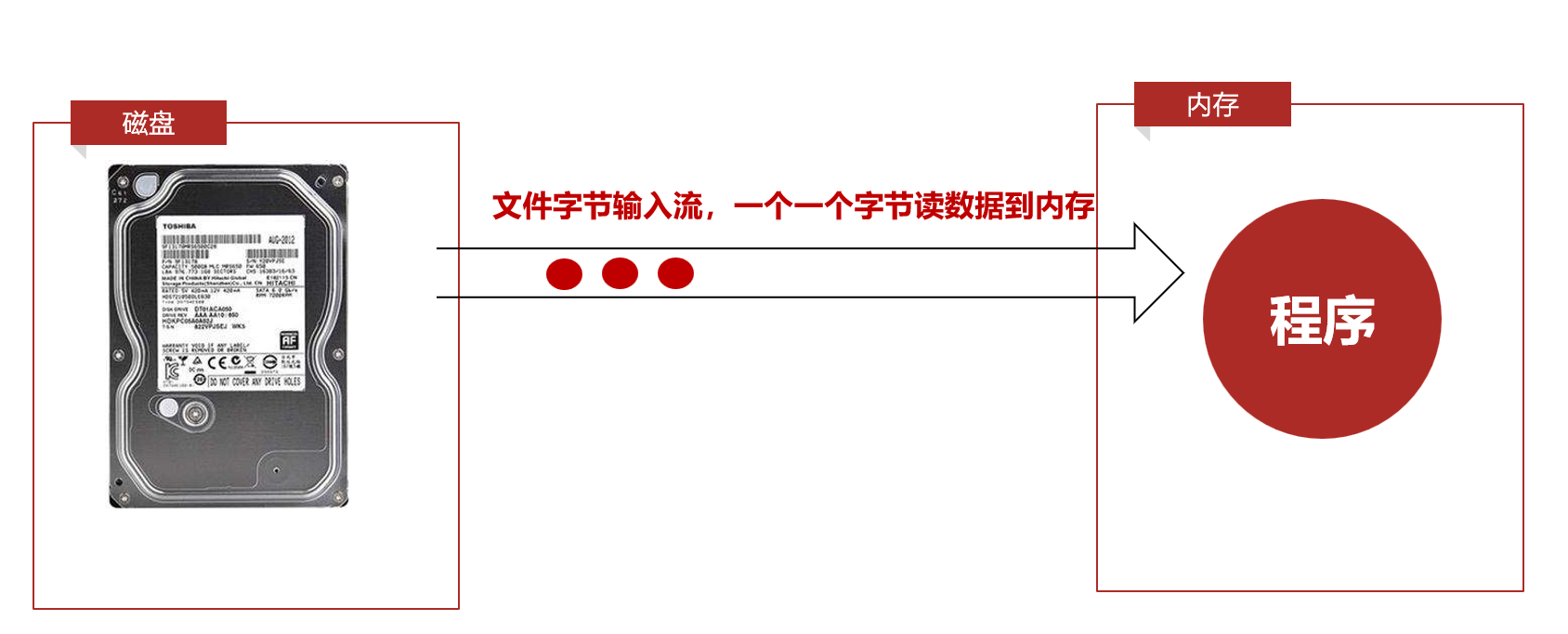
文件字节输入流 把数据按照字节读入内存
可以一个一个字节读入 也可以一组一组字节读入

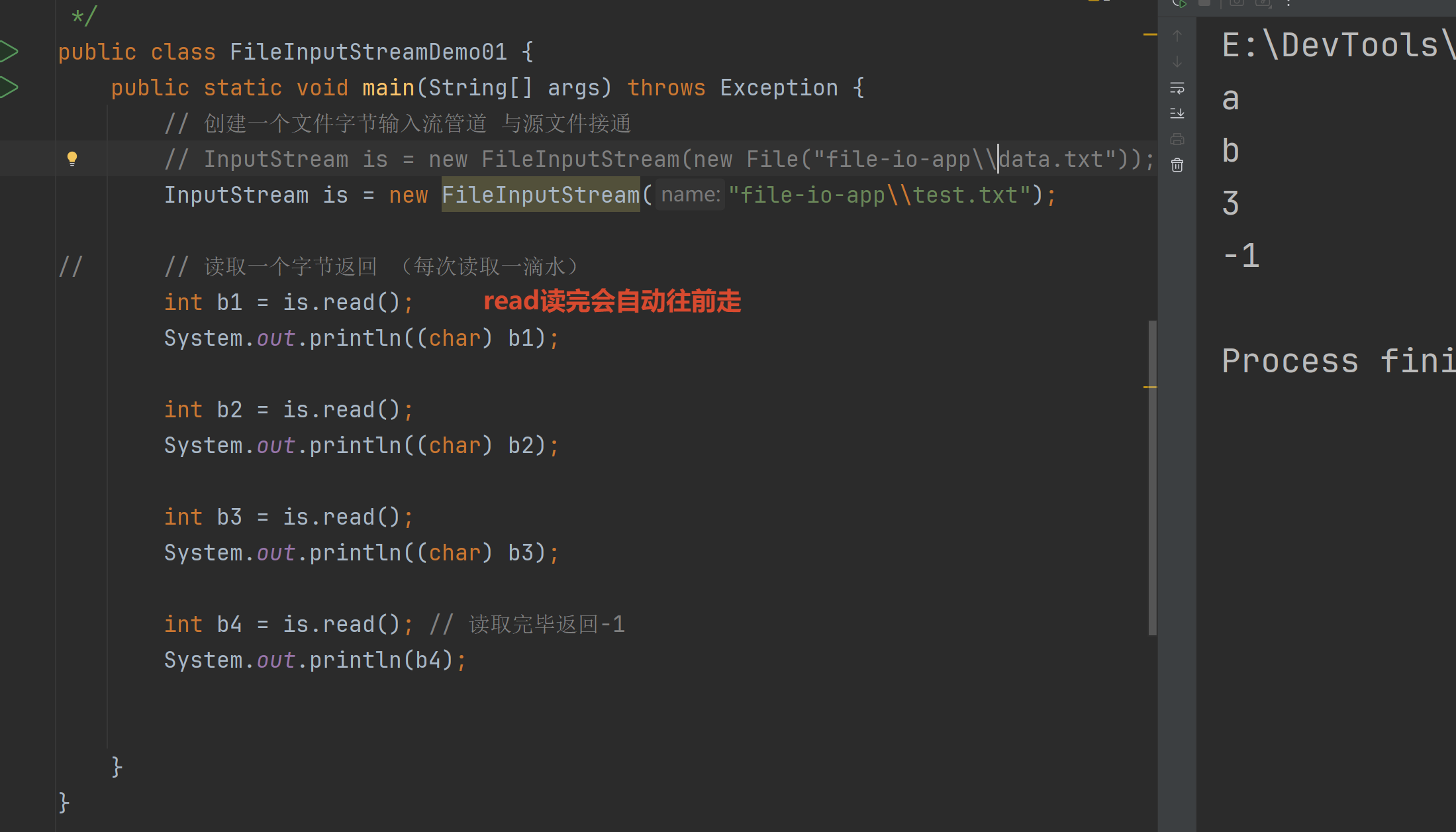
每次读取一个字节int read()
返回读取到的字节
没有字节可读就返回-1
循环改进:但是每次读取一个字节 节性能较慢 且出现中文字符无法避免乱码问题
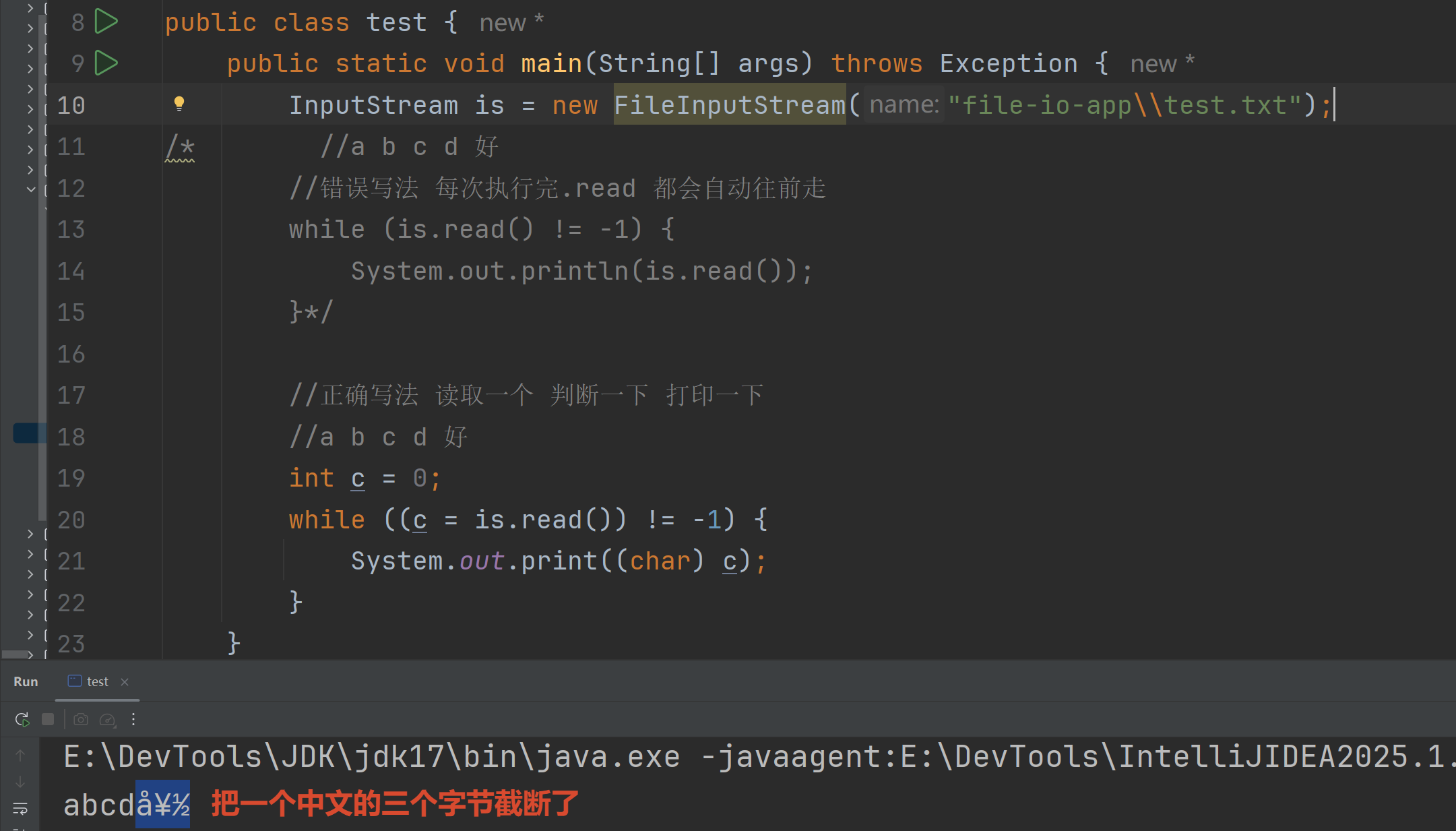
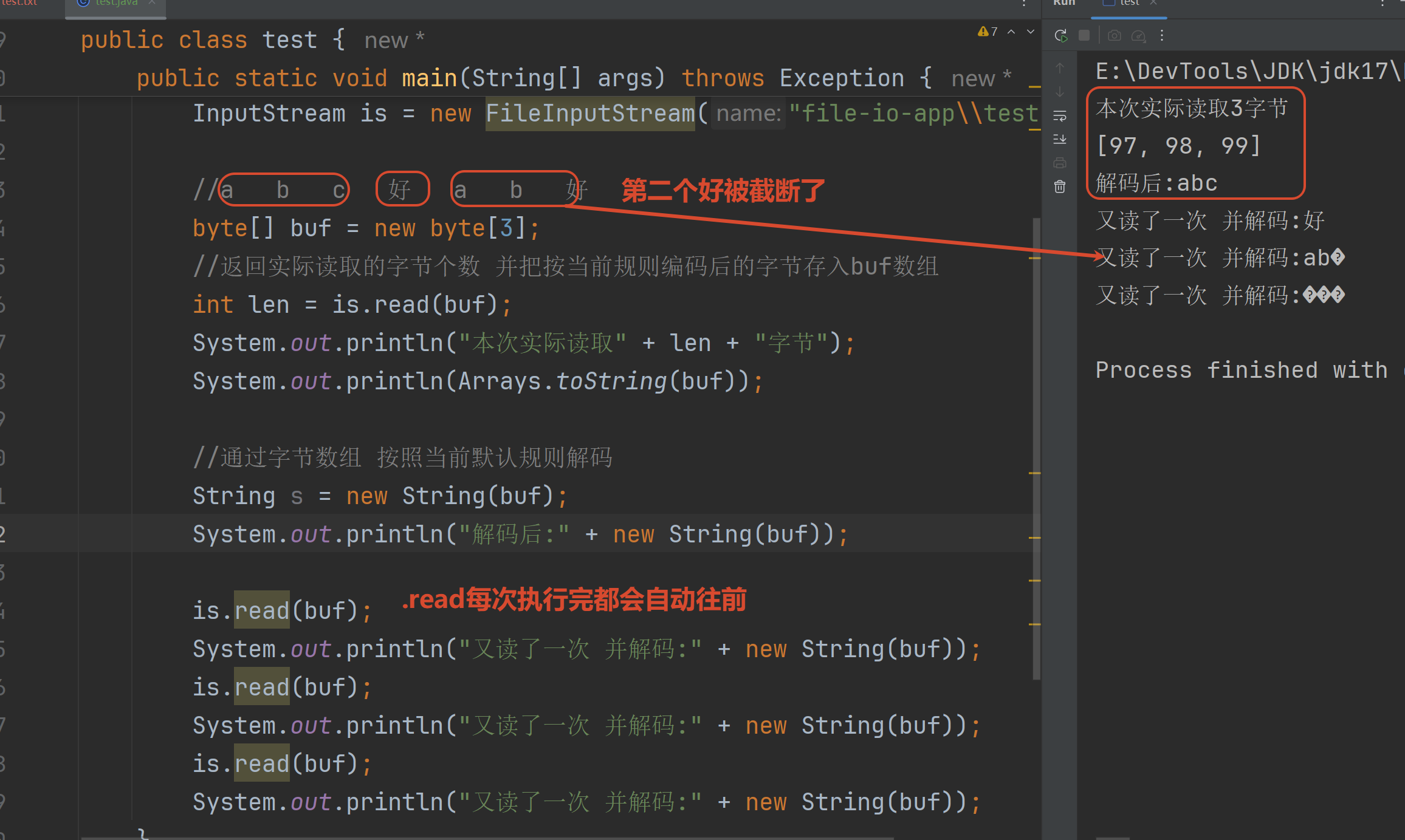
每次读取一个字节数组int read(byte\[\] buffer)
返回实际读取到了几个字节
没有字节可读就返回-1
执行完.read() 数组bytes里面存放的内容就是 按照当前规则编码之后的三个字节(英文1字节 中文3字节)
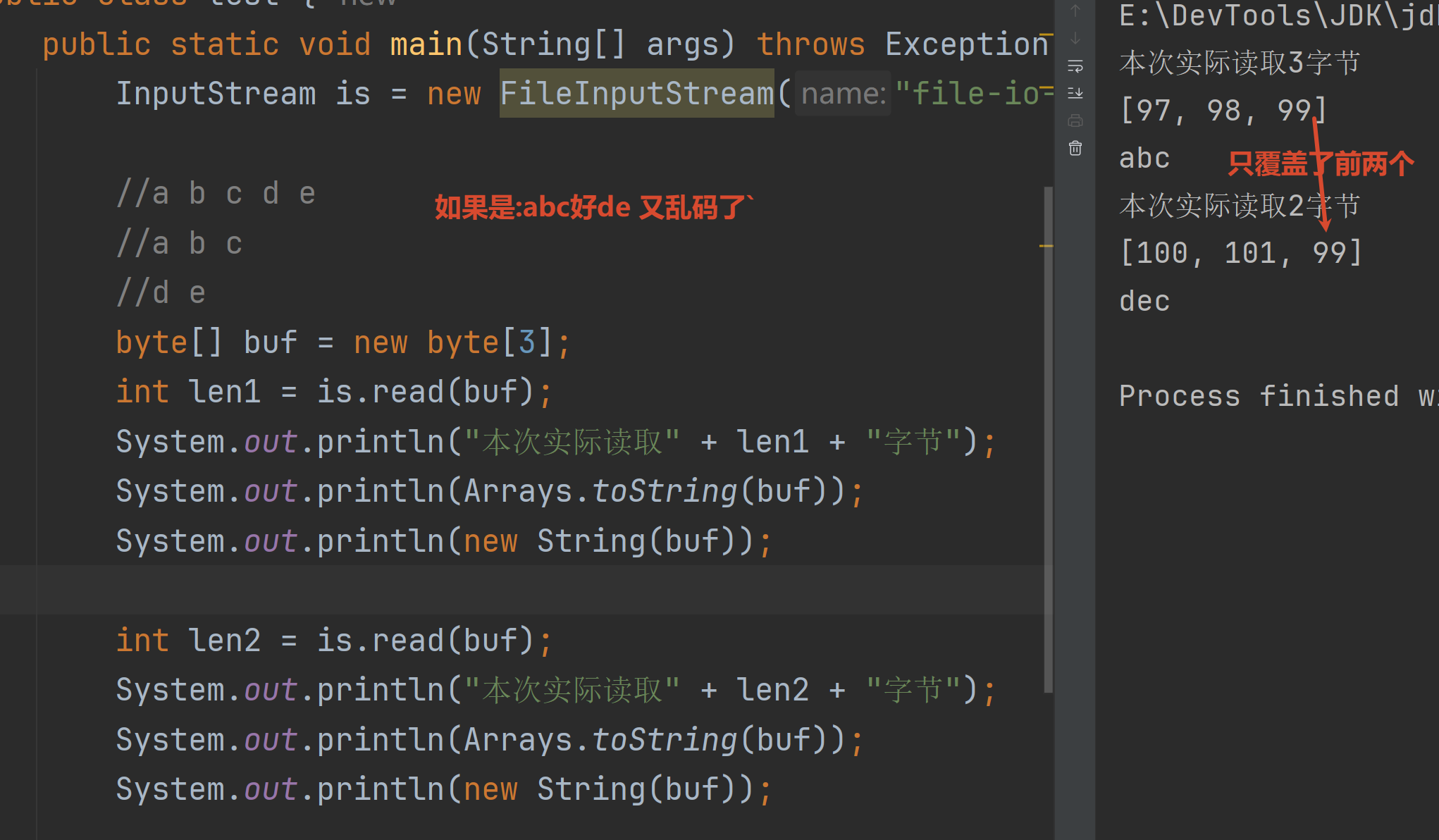
注意:最后一桶水 可能有上一桶水剩下的数据
改进:循环读取 并且确保实际读取多少字节 就解码多少字节
但是如果有中文 输出仍然很容易乱码
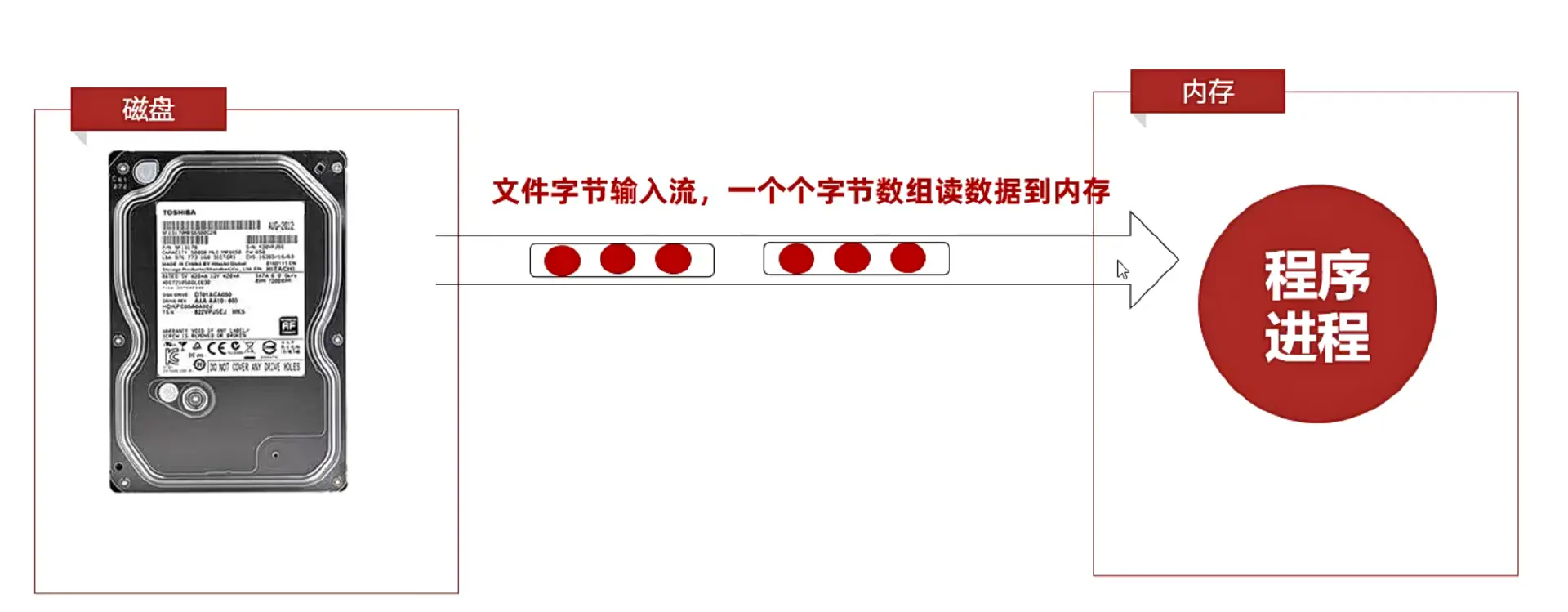

一次读完全部字节→避免解码中文输出乱码
其实字节流就始终是不适合读取文本文件的 字符流更合适
方式一:还是每次读取一个字节数组 但是把这个字节数组的大小=整个文件大小
方式2:官方API 按照当前字符集 直接一次性读完这个文件的全部字节到一个字节数组


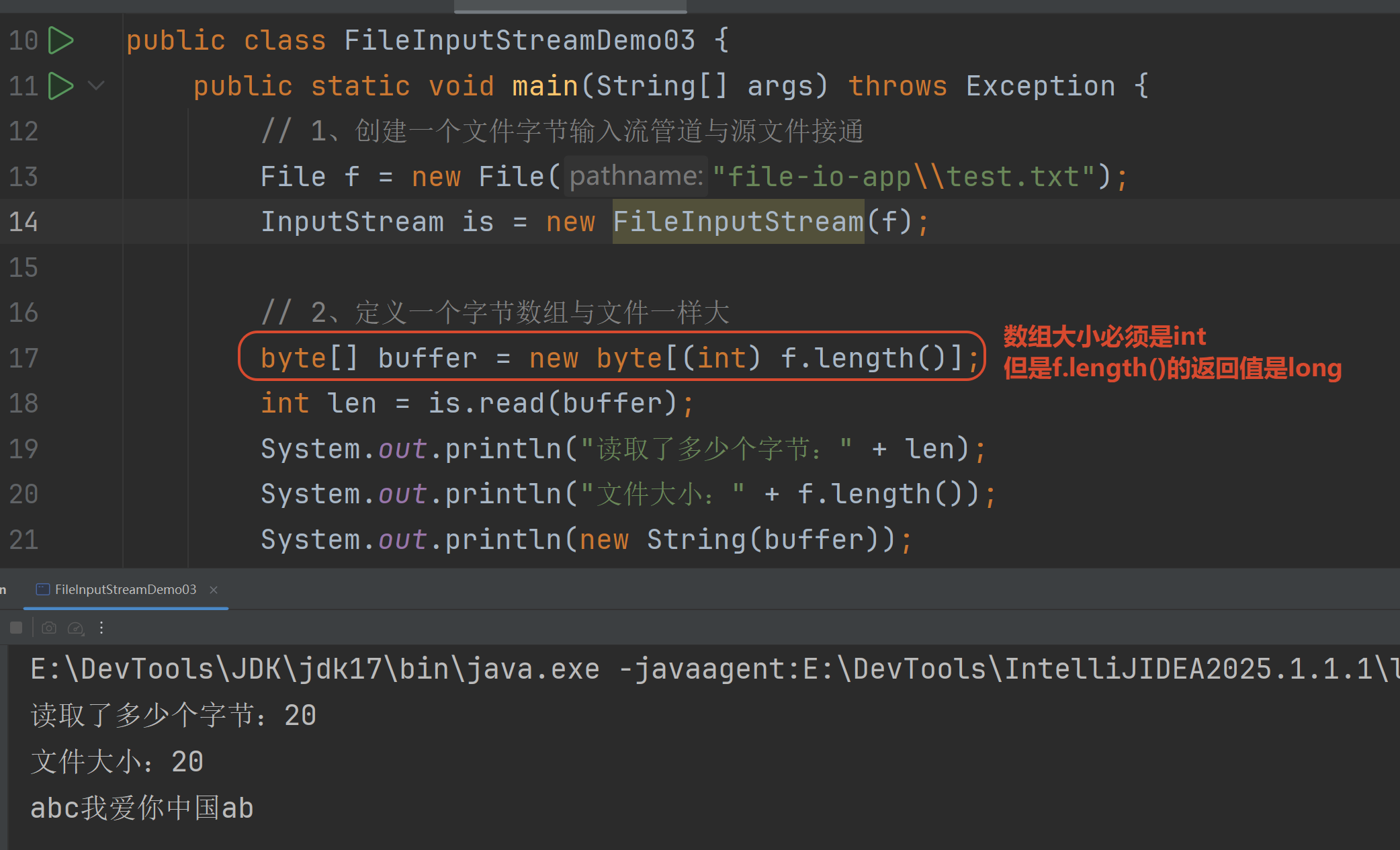
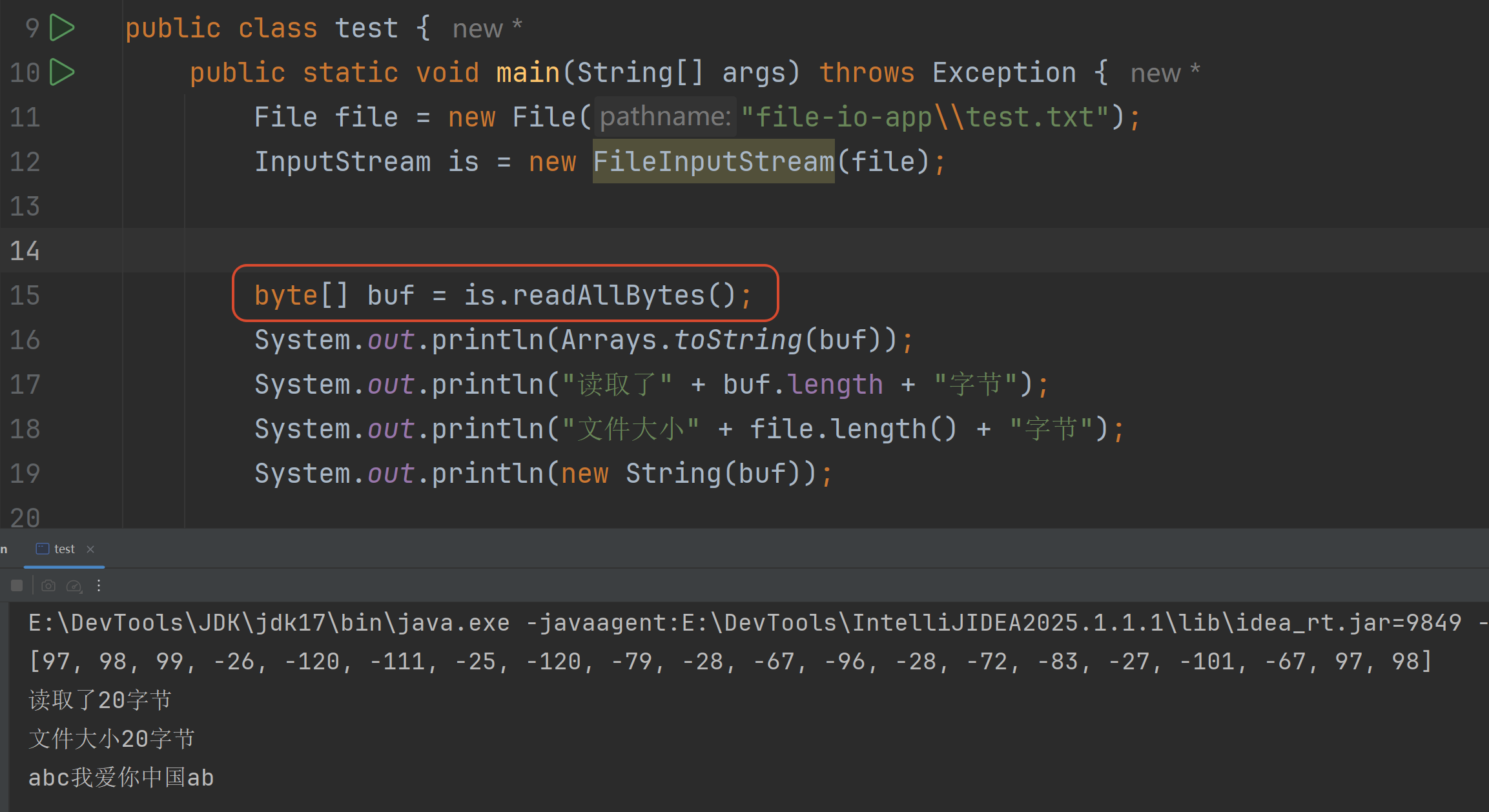
2.2 文件字节输出流(FileOutputStream)
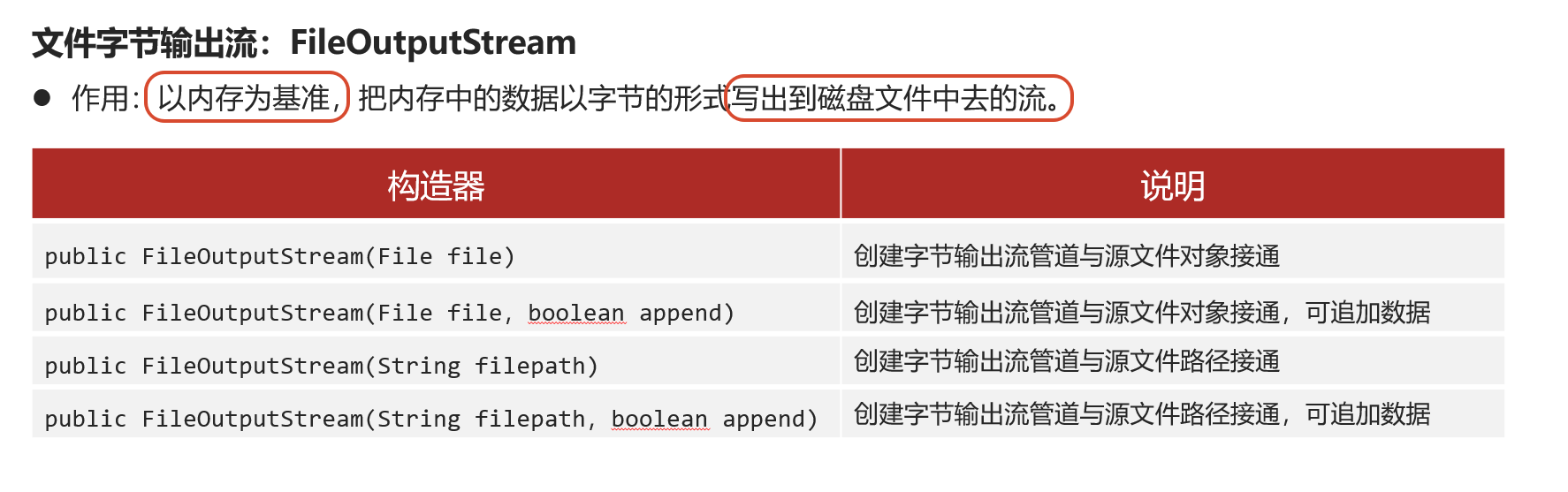
创建对象与常用API
按字节 把内存中的数据写出到磁盘文件
目标文件可以不存在 会自动创建 (但是读入内存的情况 文件必须要存在)flush():让write的数据生效(因为写数据的时候 可能是先在内存中缓存着的 此时如果断电 可能write就失败了)

追加管道与覆盖管道
注意:覆盖的情况 不是等write之后才覆盖 而是这个os2管道一旦new出来 就直接先清空目标文件

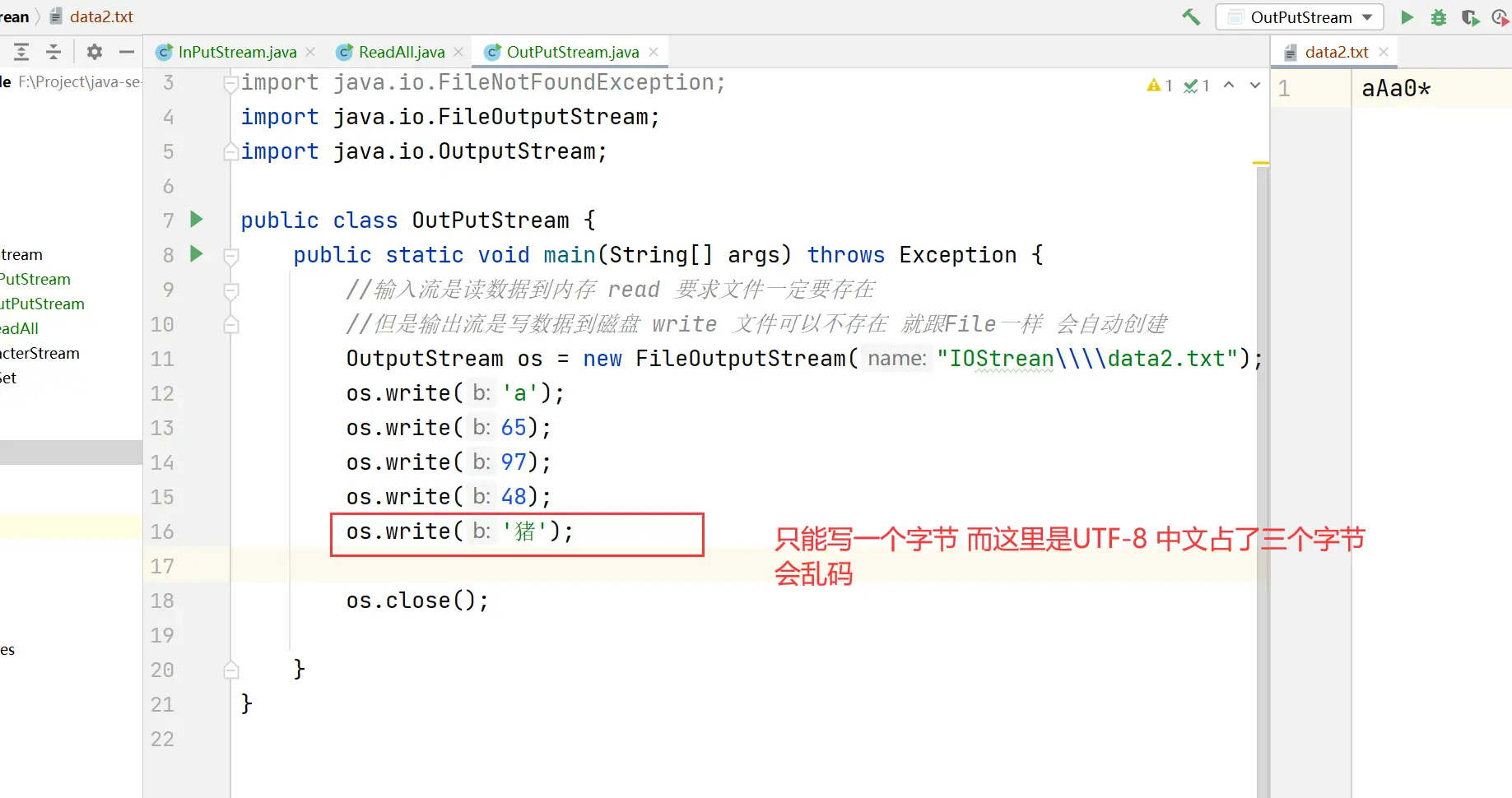
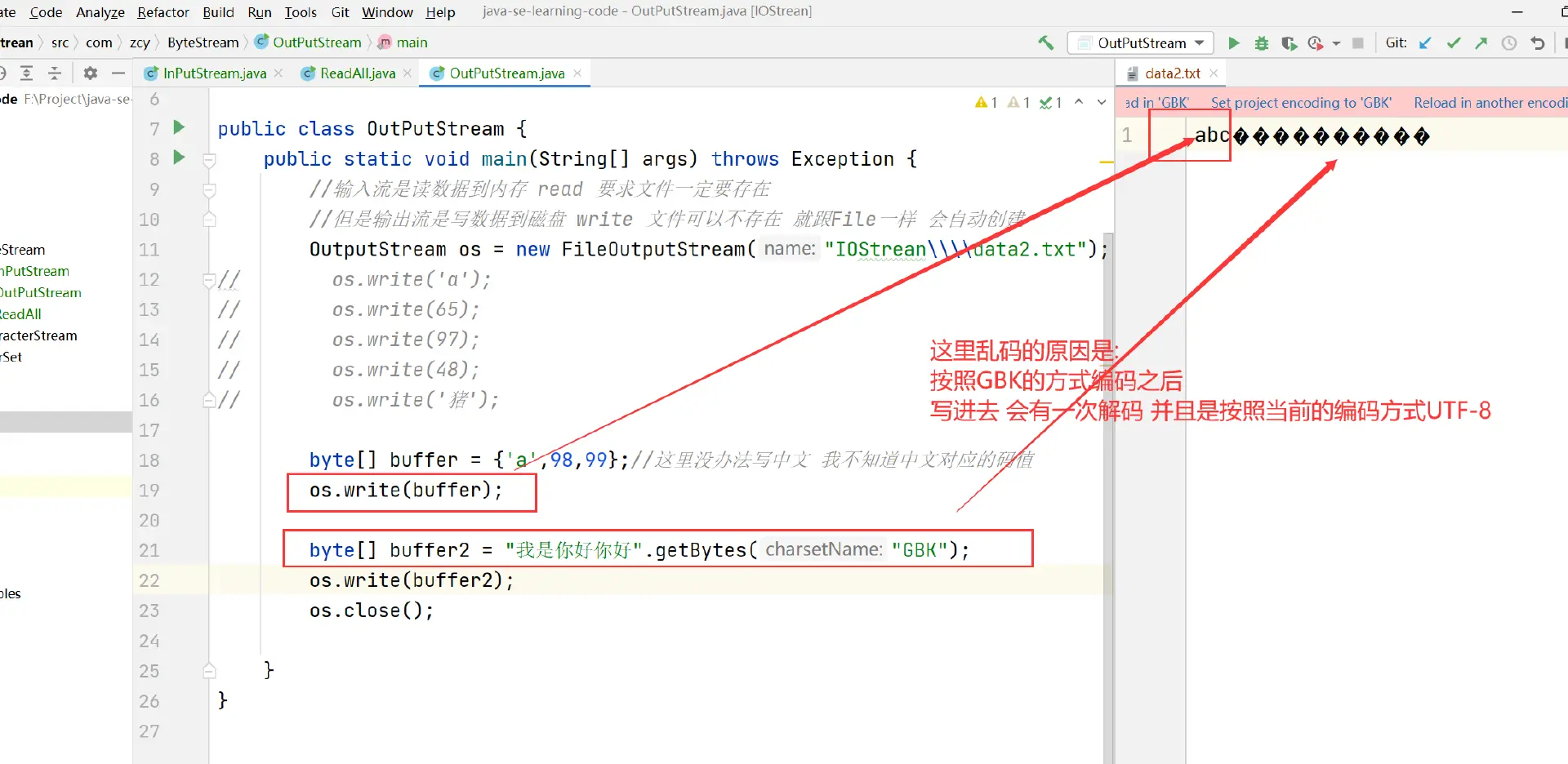
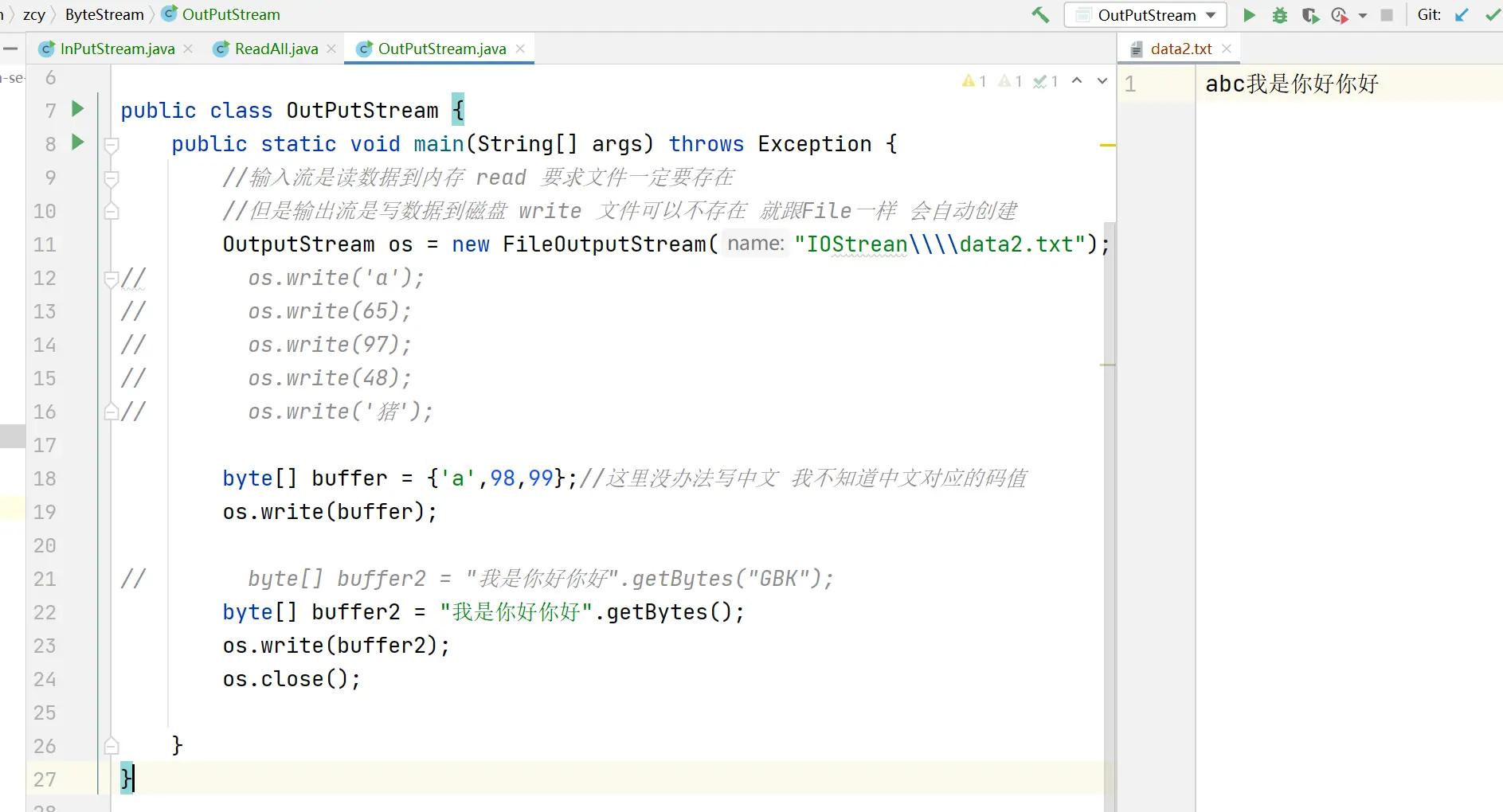
每次写出一个字节void write()
写中文字符 也会乱码(当前是UTF-8 一个中文三个字节 但是write一次只能写出一个字节)

每次写出一个字节数组void write(byte\[\] buffer)
总之记住:
如果解码和编码规则不一样 中文就会乱码 数字字母不会乱码
要避免规则不一致的情况!!
这样就不会乱码了 编码解码都是默认的UTF-8
每次写出一个字节数组的一部分write(byte\[\] buffer,int pos,int len)
如果想要换行:
os.write("\r\n".getBytes());// 换行 单独\n可能在Linux下就不适用了不能直接write字符串 只支持int类型或者字节数组 getBytes返回的就是编码后的字节数组


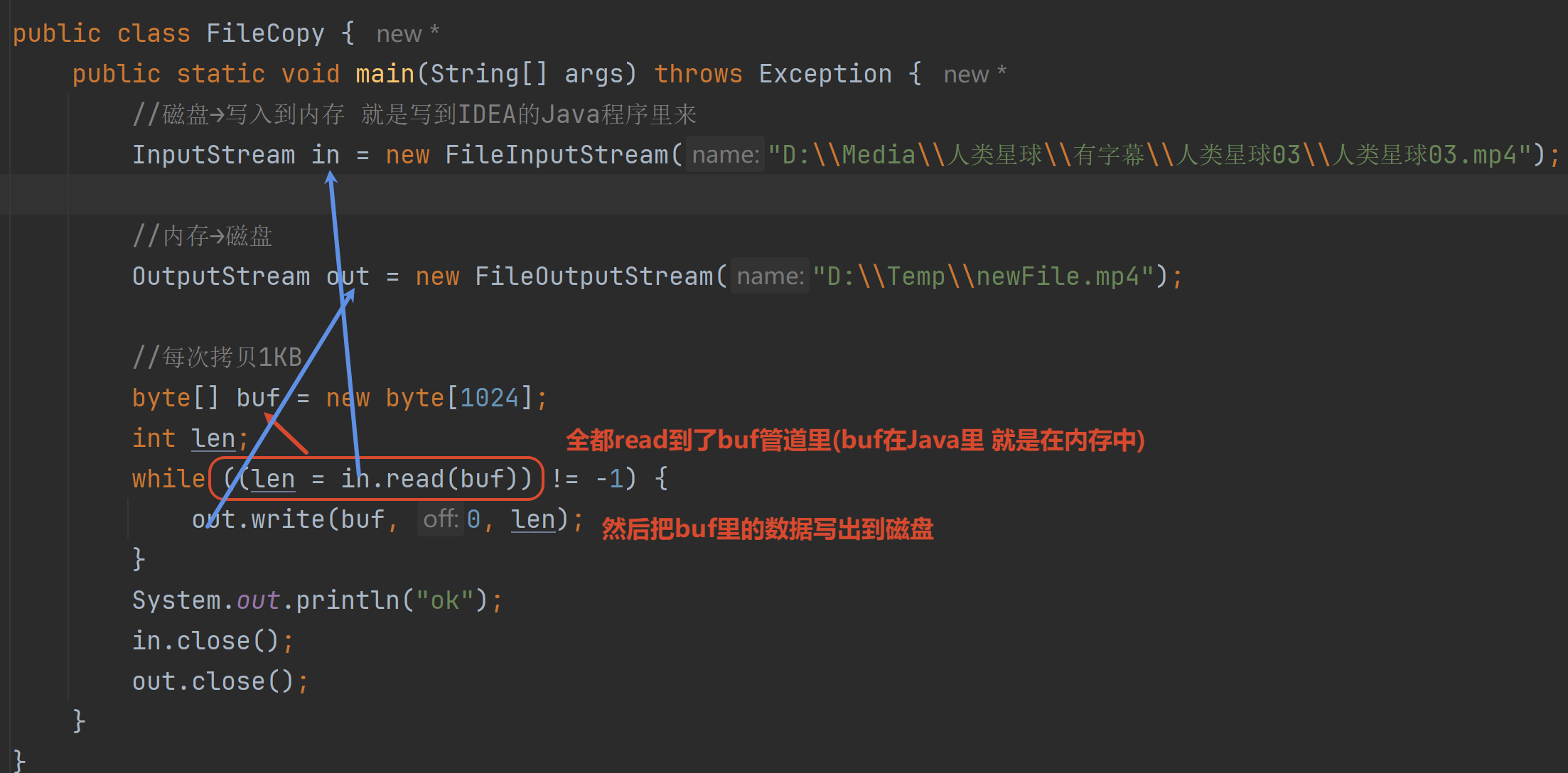
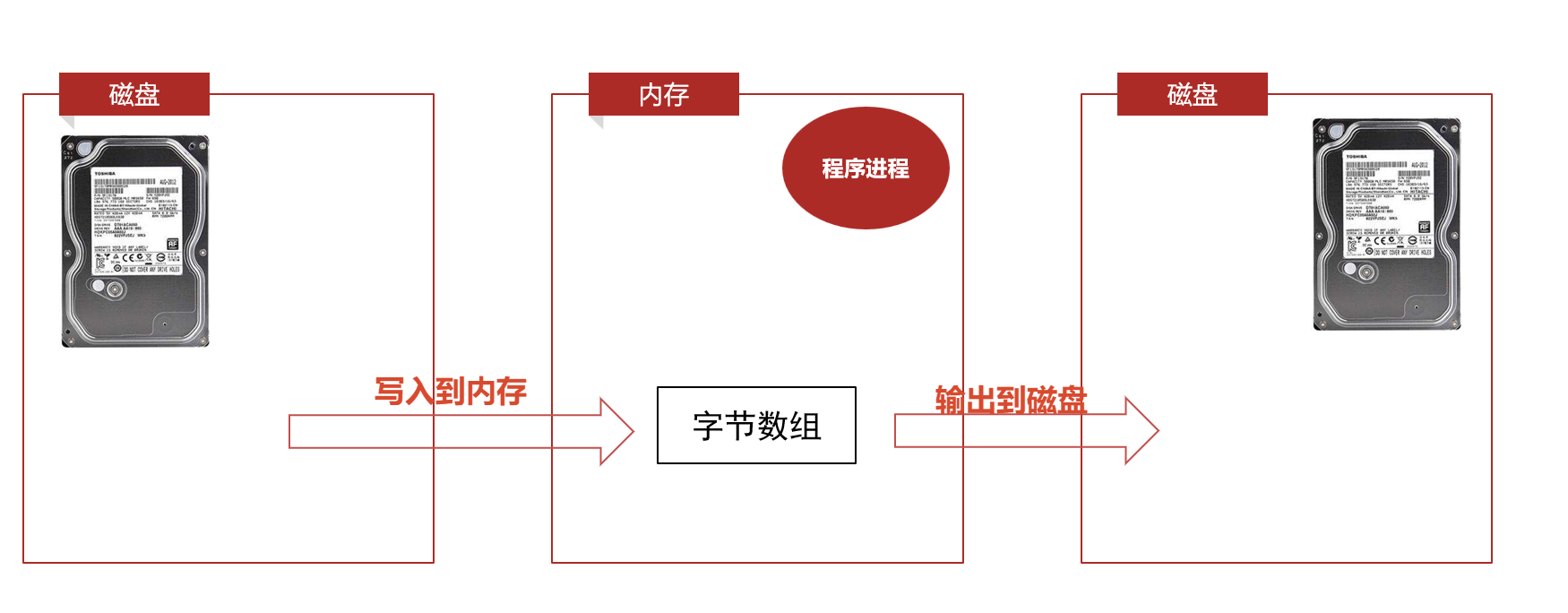
2.3 文件拷贝
总体来看
字节流适合做文件(音视频文件 文本文件都可以)的拷贝 因为任何文件都是以二进制(字节)来存储的
但是不适合做中文文本文件的读写(容易乱码)
参考代码:路径一定要写对 是文件→文件 out的文件可以没有 会自动创建
音视频 文本文件 都可以被拷贝

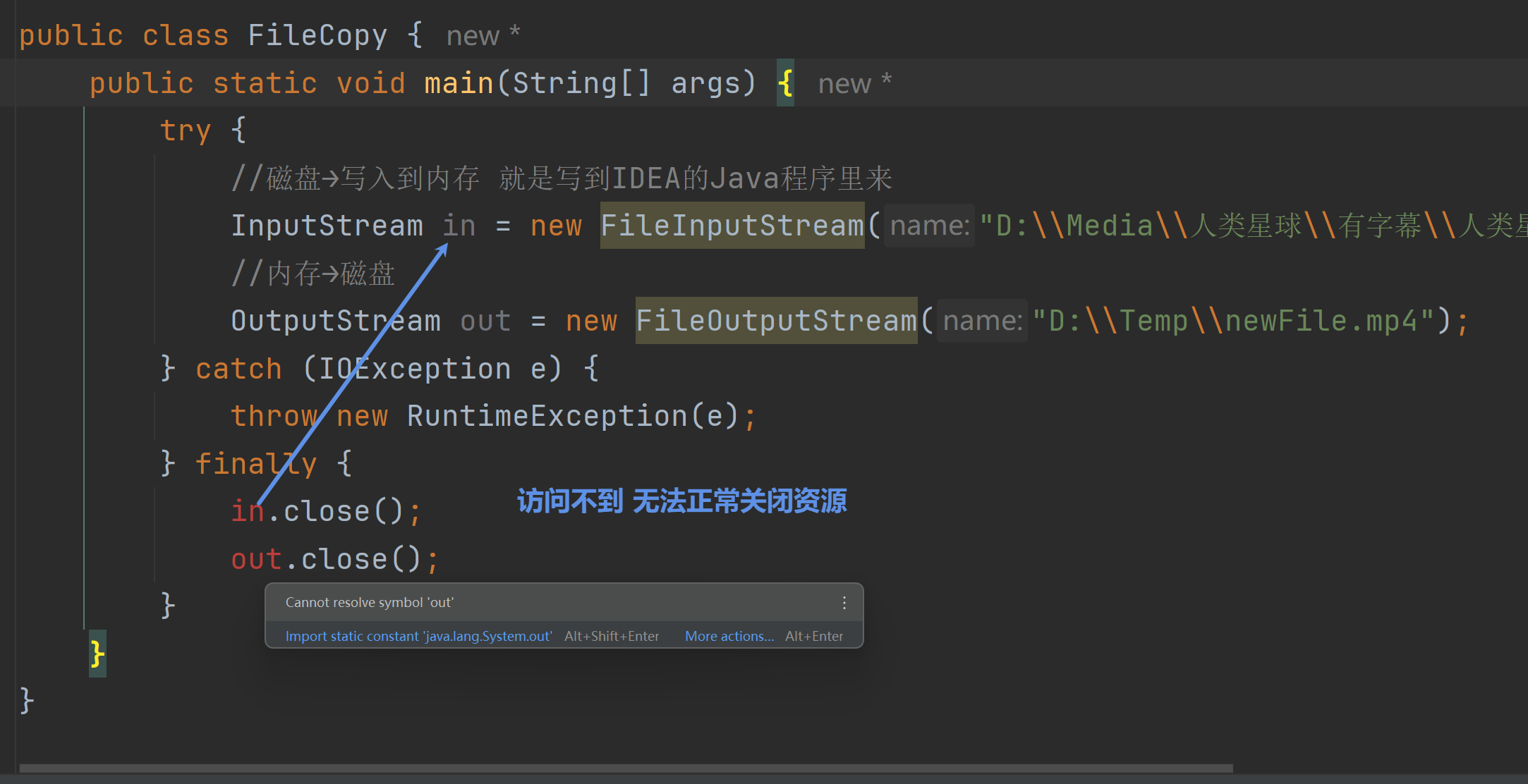
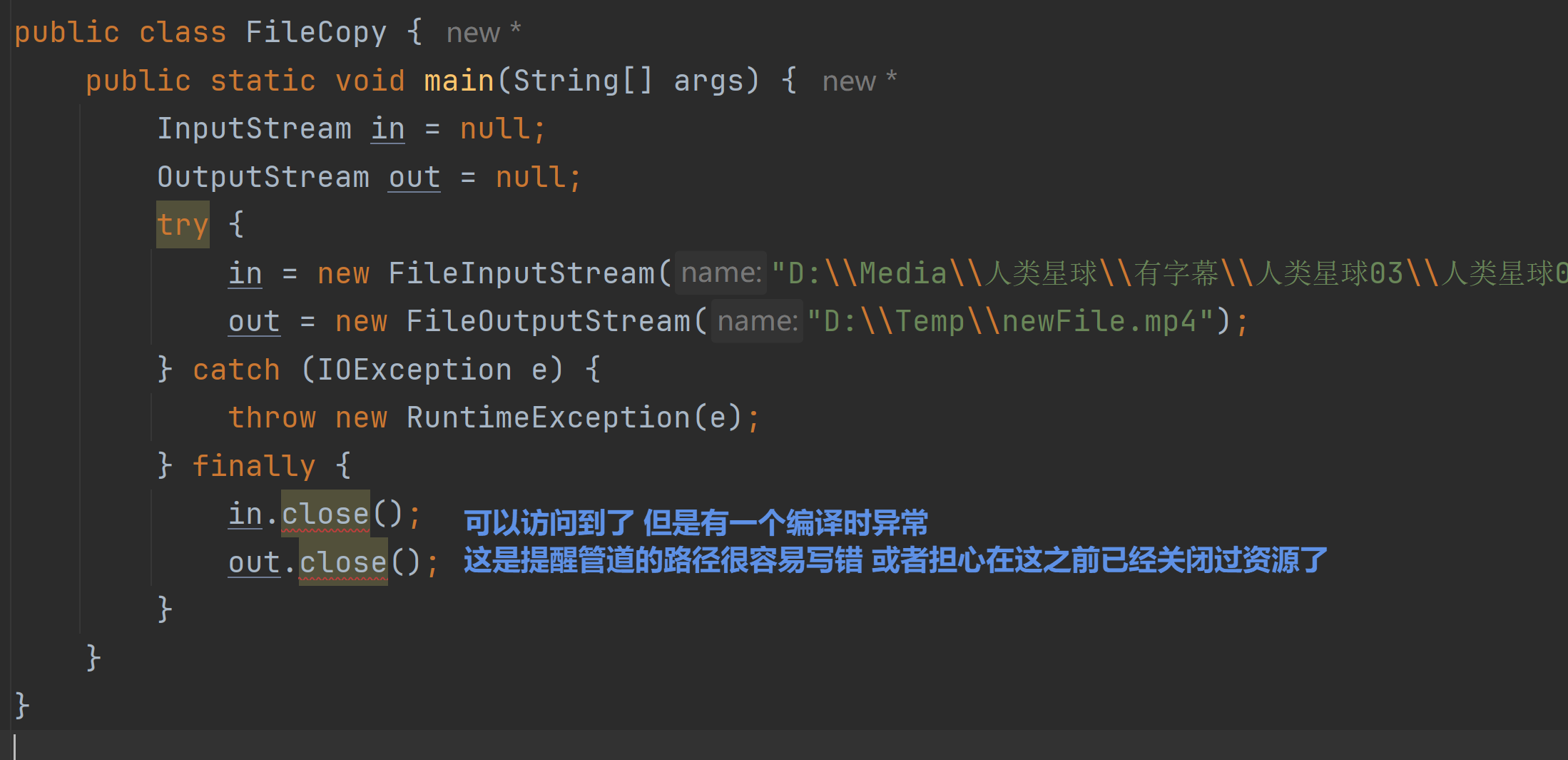
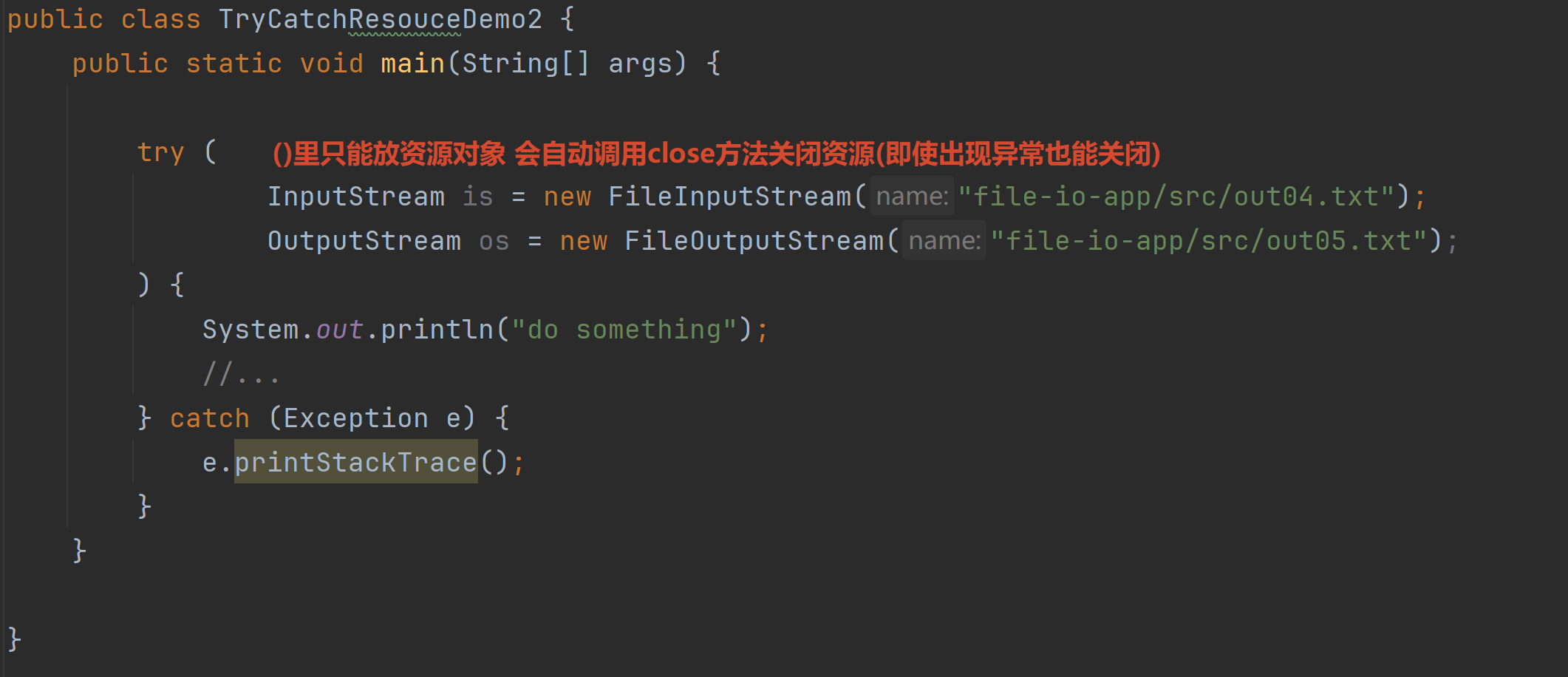
2.4 资源释放
try-catch-finally
问题:
解决方法:
那就再把上面的编译时异常try catch一下注意非空校验 这样就一定可以顺利释放资源了
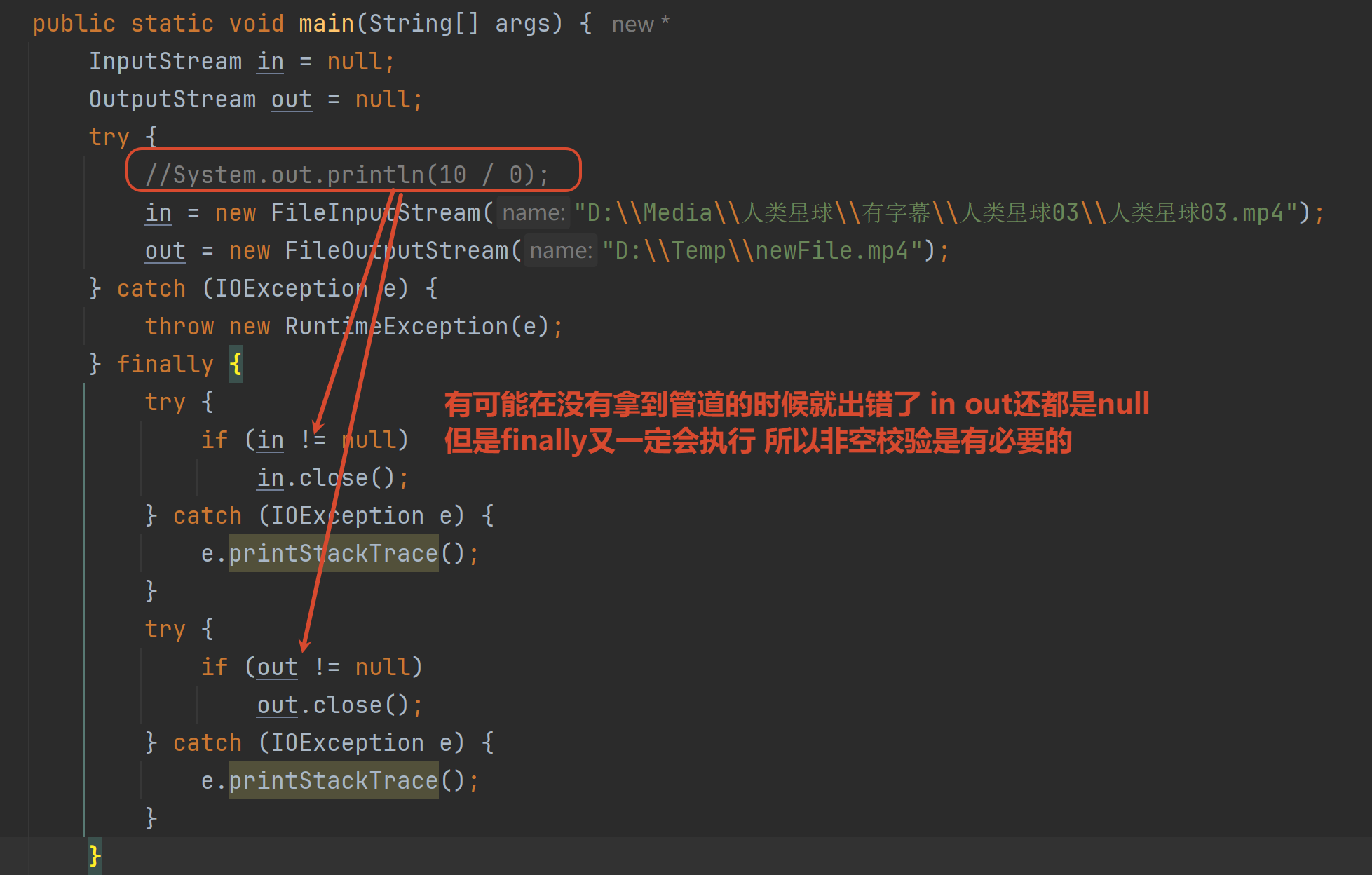
Java中什么是资源
注意:即使出现异常也会做关闭资源操作


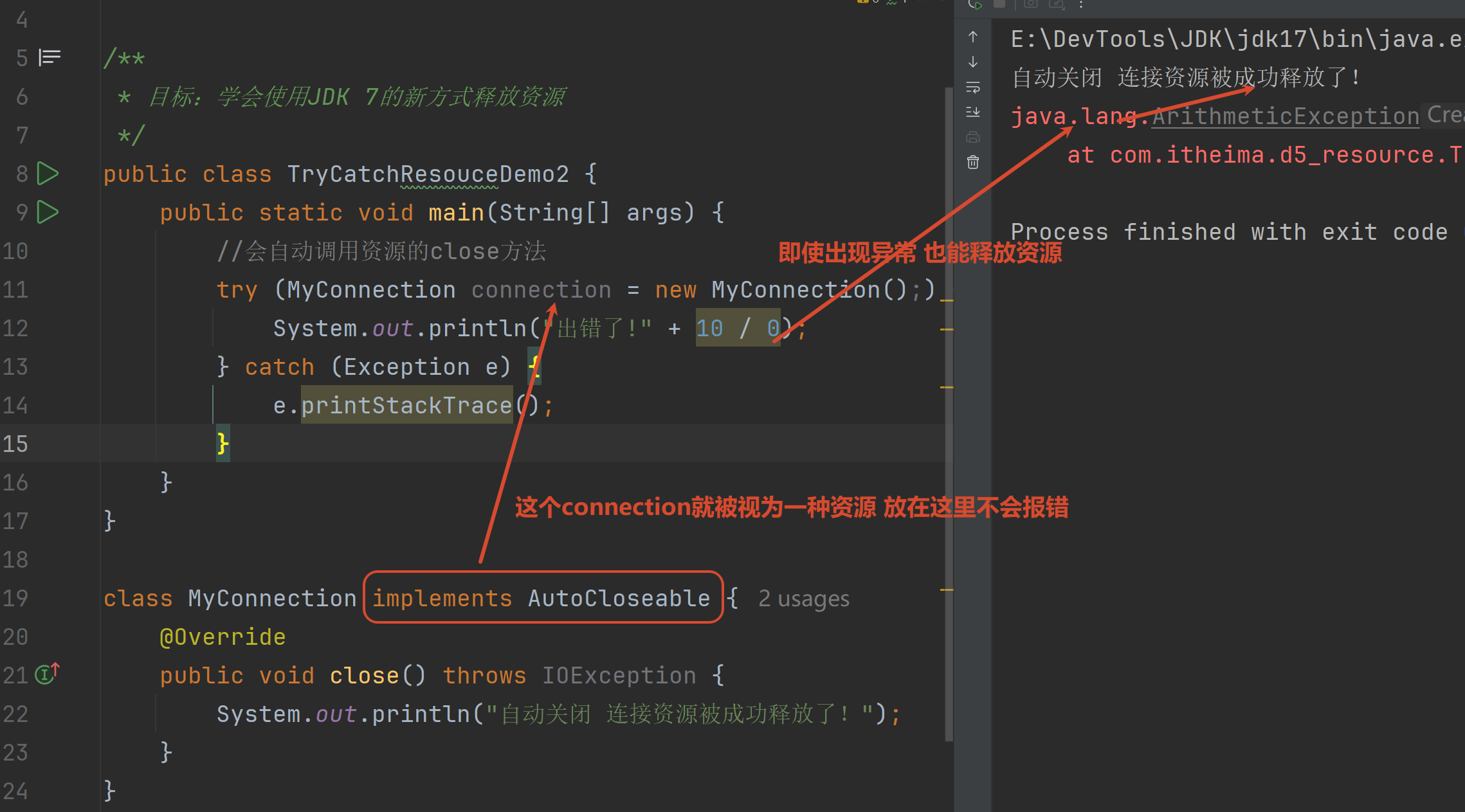
化简finally的释放资源
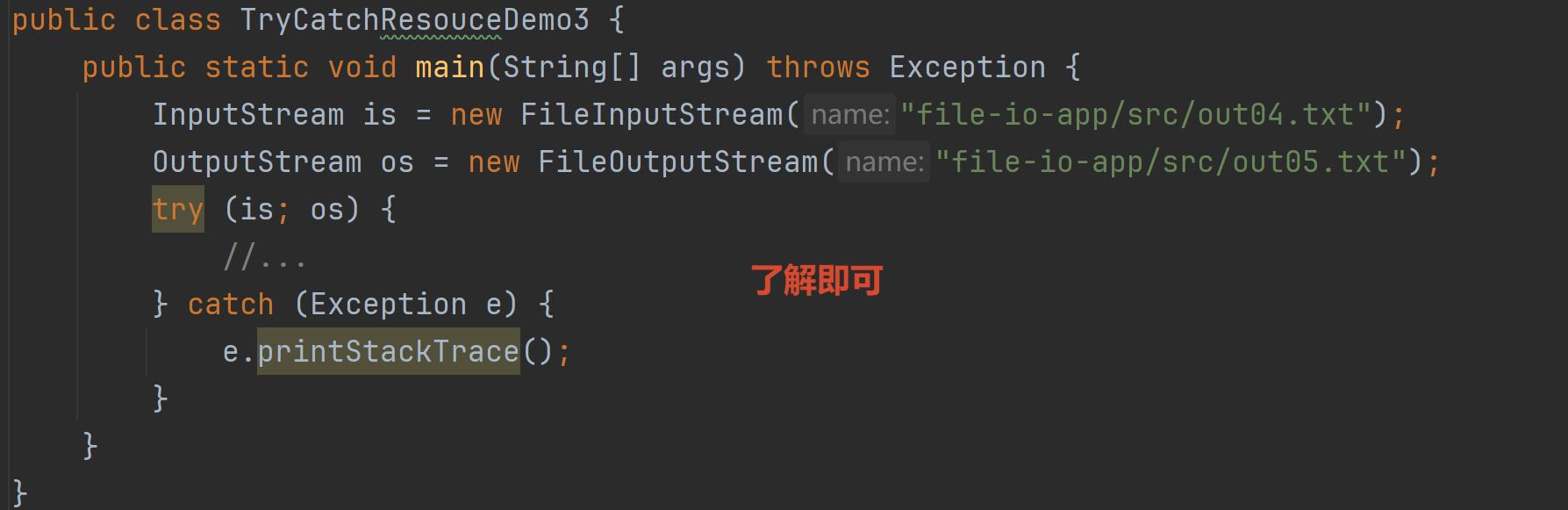
finally释放资源的代码太繁琐了
简化1:
简化2:

三、字符流
3.1 文件字符输入流(FileReader)
创建对象与常用API
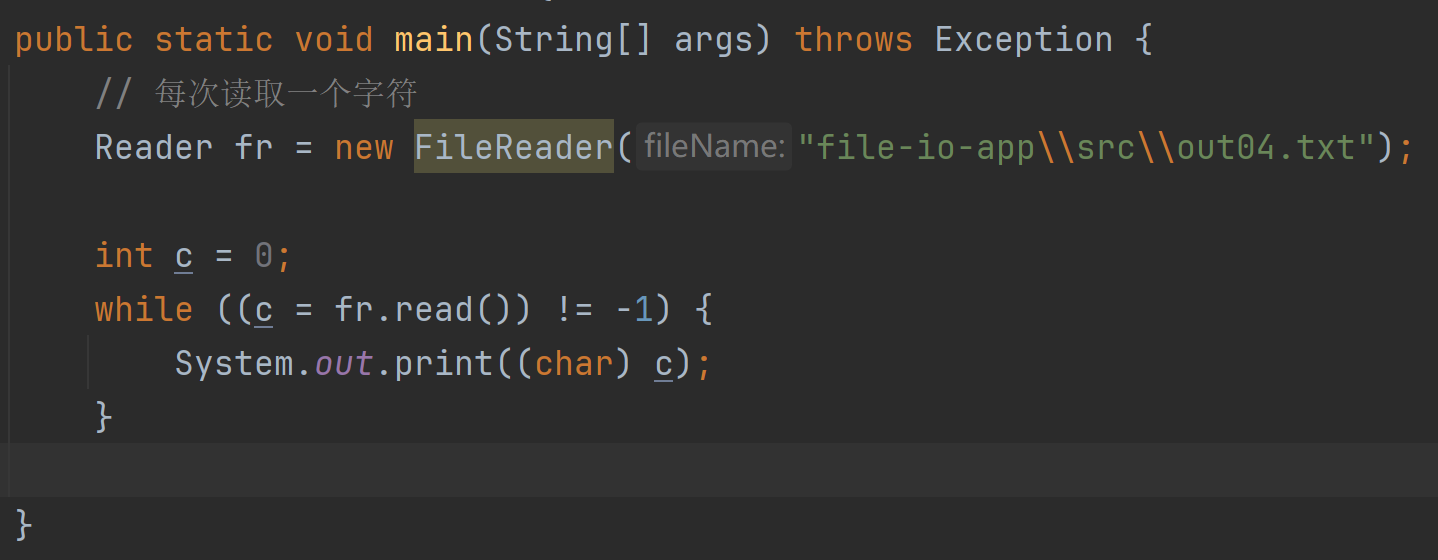
字节流读取中文输出可能会乱码 字符流更合适读取中文输出(按照单个字符读取)

每次读取一个字符int read()
读取到的是该字符编码后的码值(包括中文字符)
返回值是int 没有可读取的就返回-1

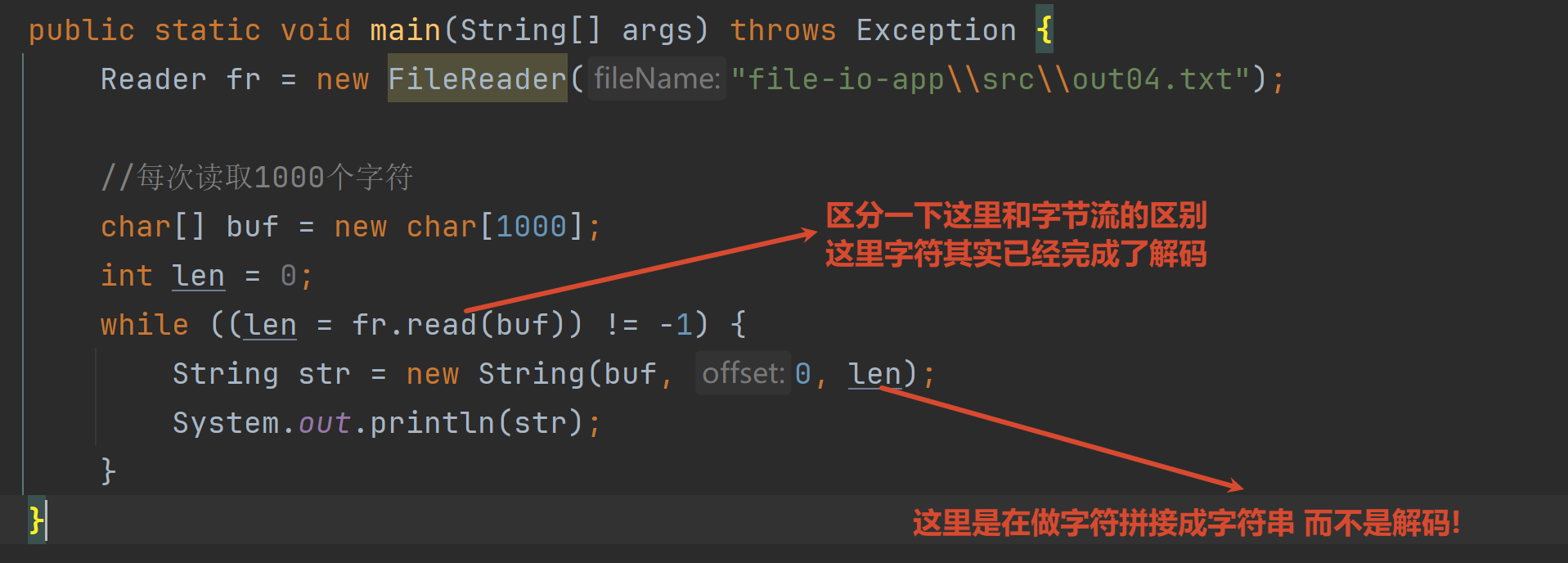
每次读取一个字符数组int read(char\[\] buffer])
每次读取一个字符数组→内存中
返回值是实际读取到的字符数 没有可读取的就返回-1
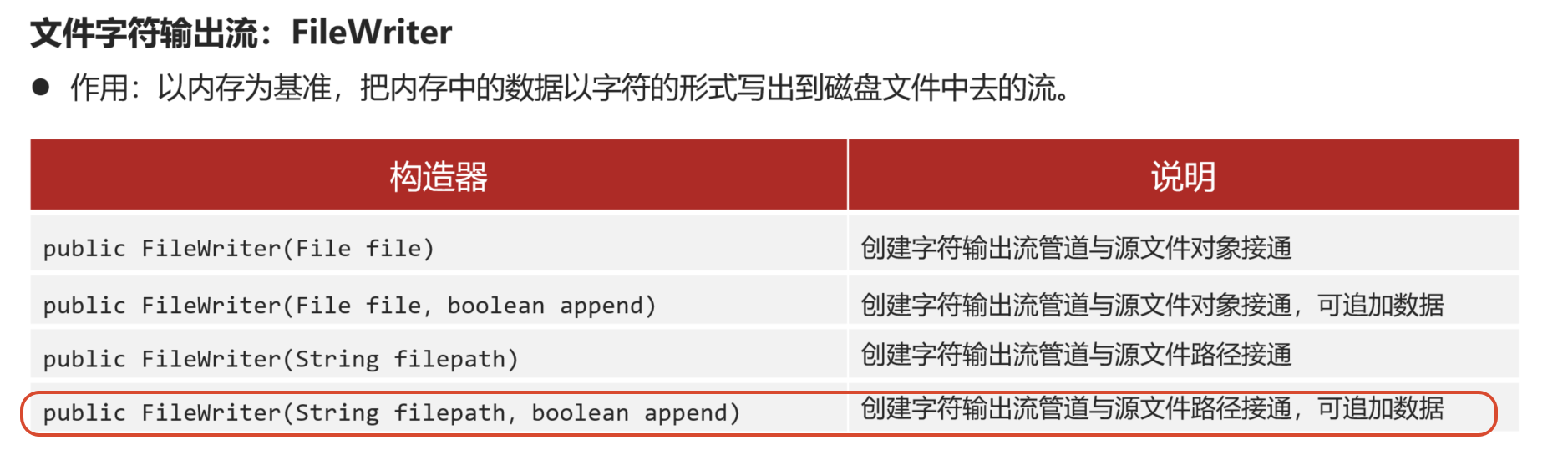
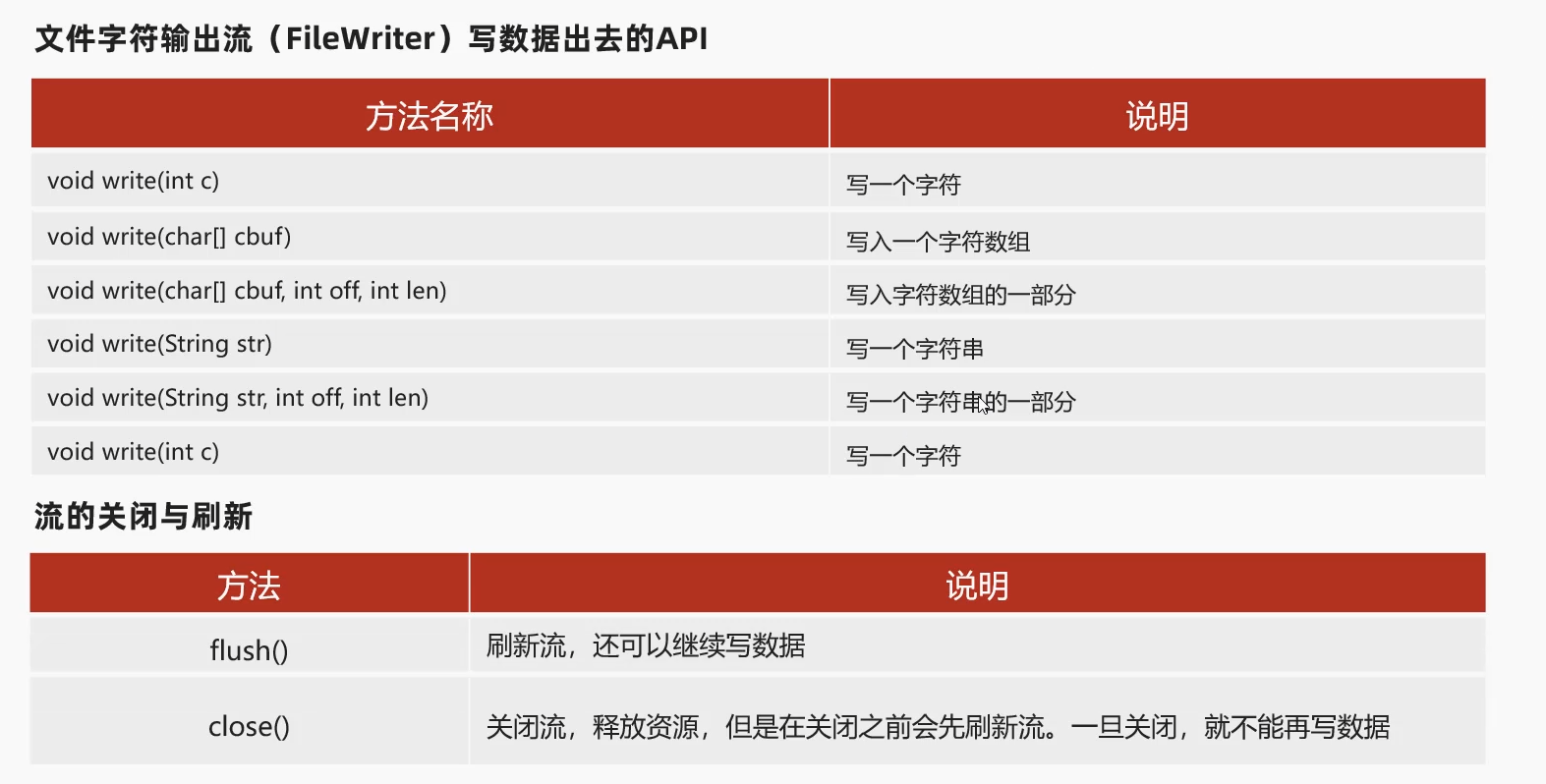
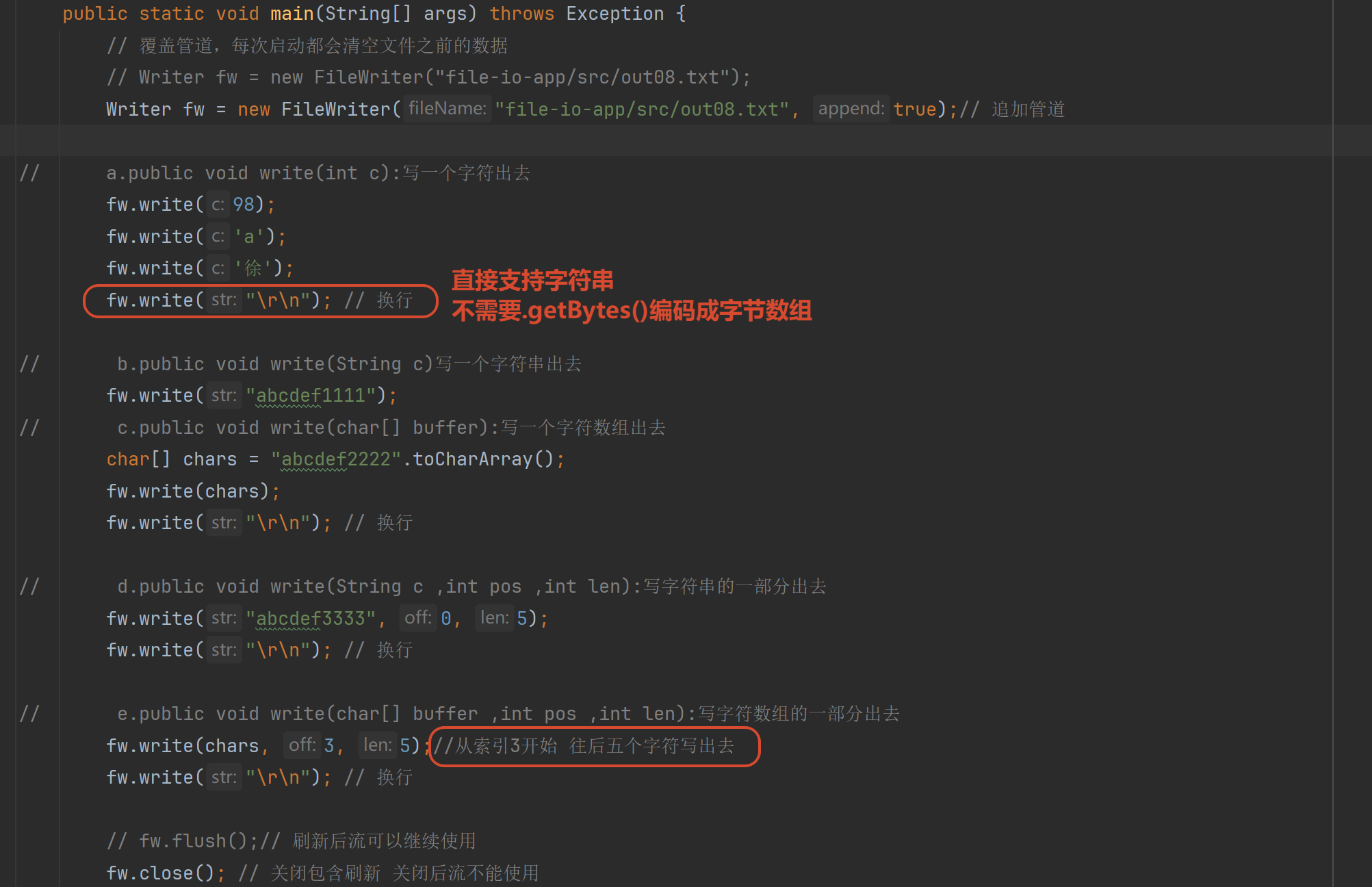
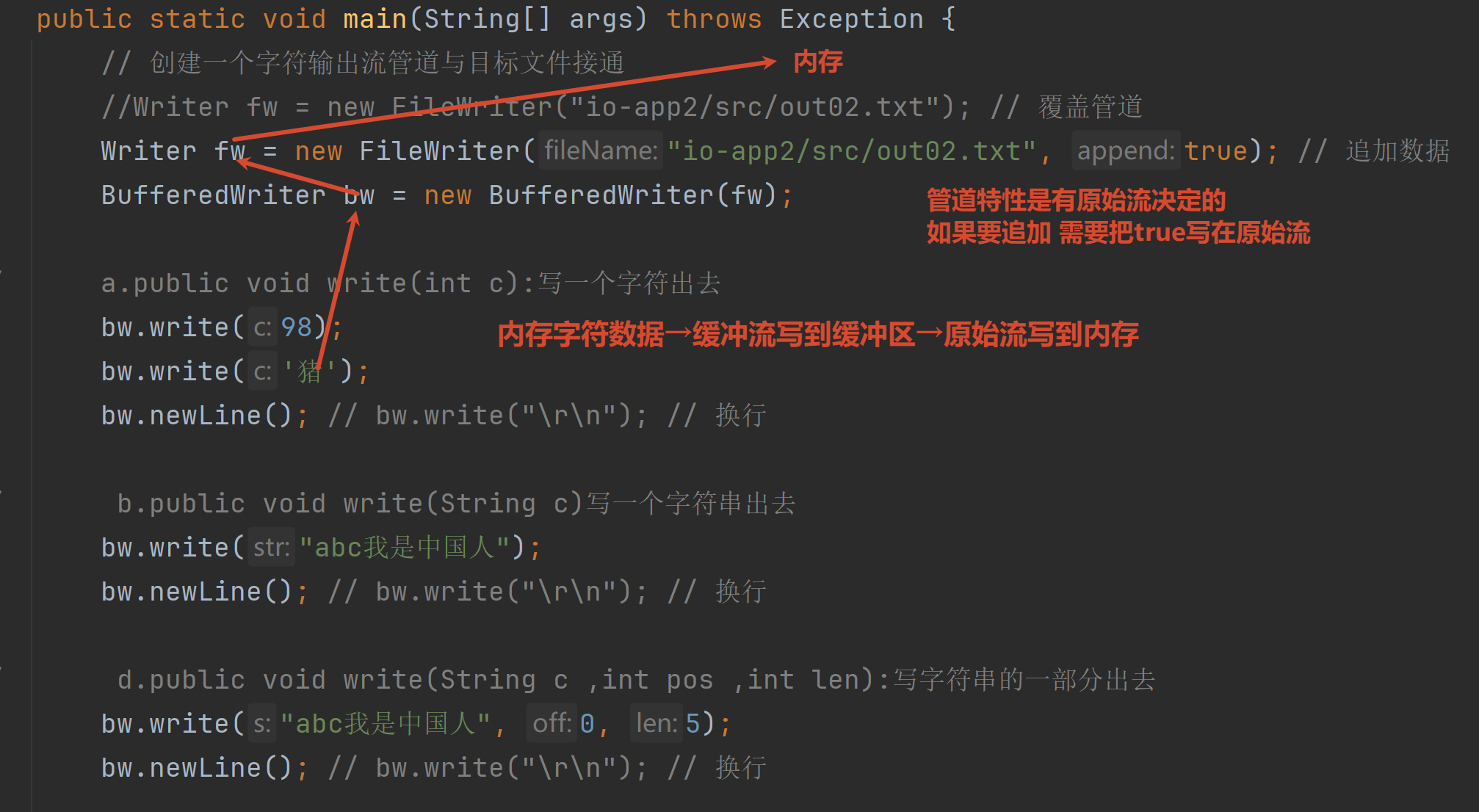
3.2 文件字符输出流(FileWriter)
注意写入一部分的第三个参数 表示长度 而不是索引
3.3 Properties
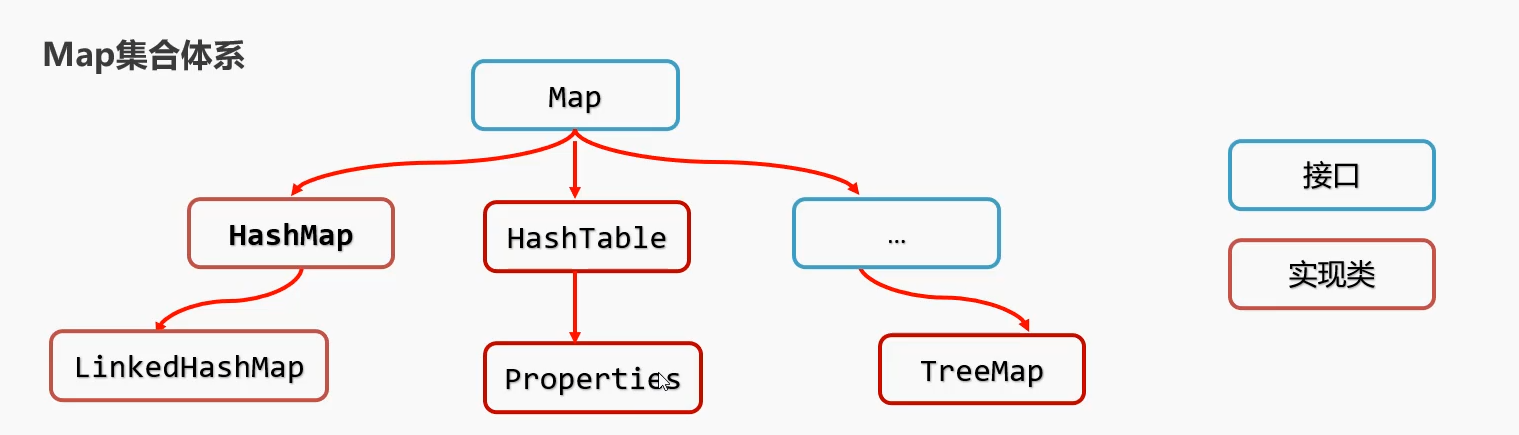
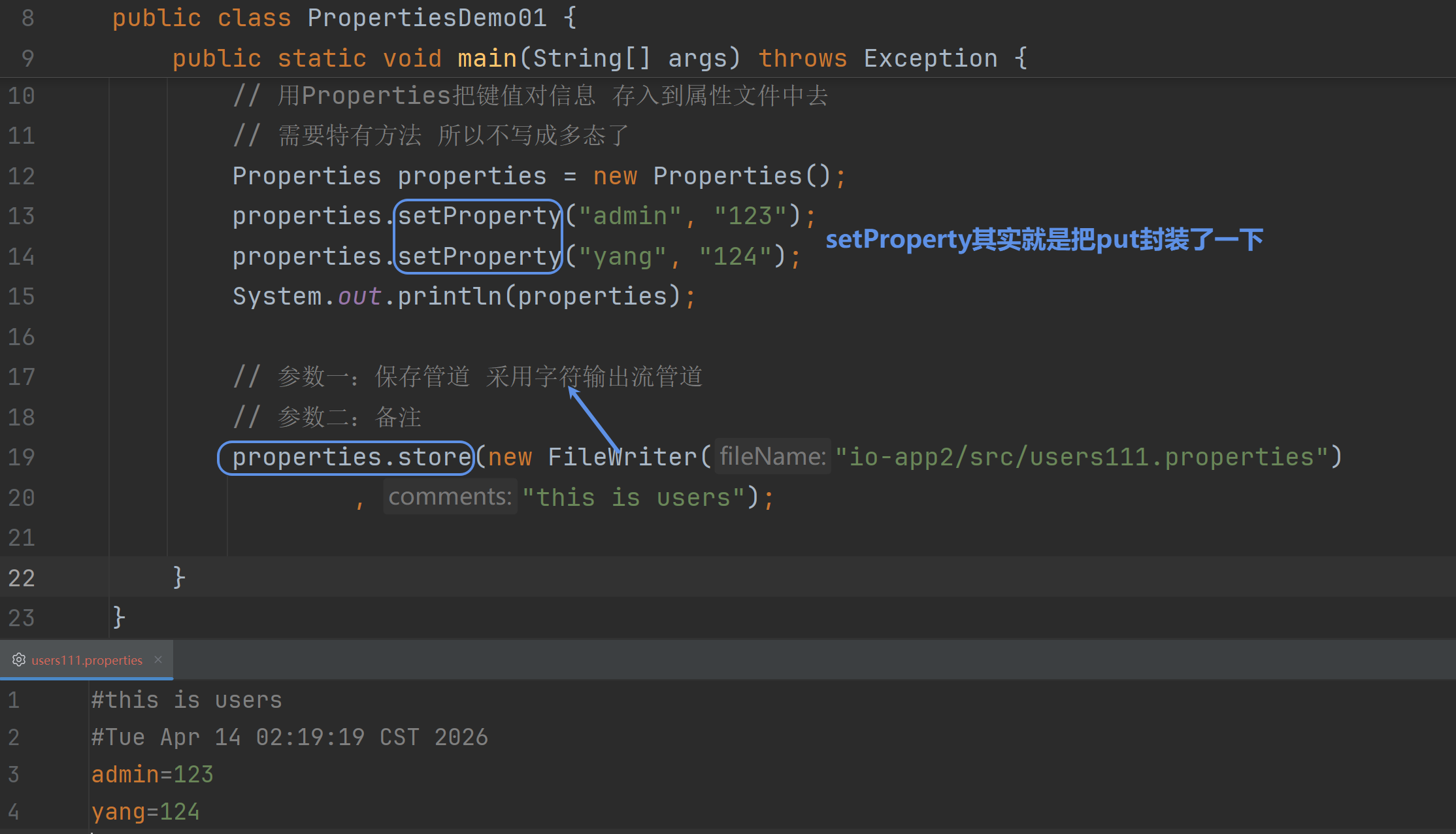
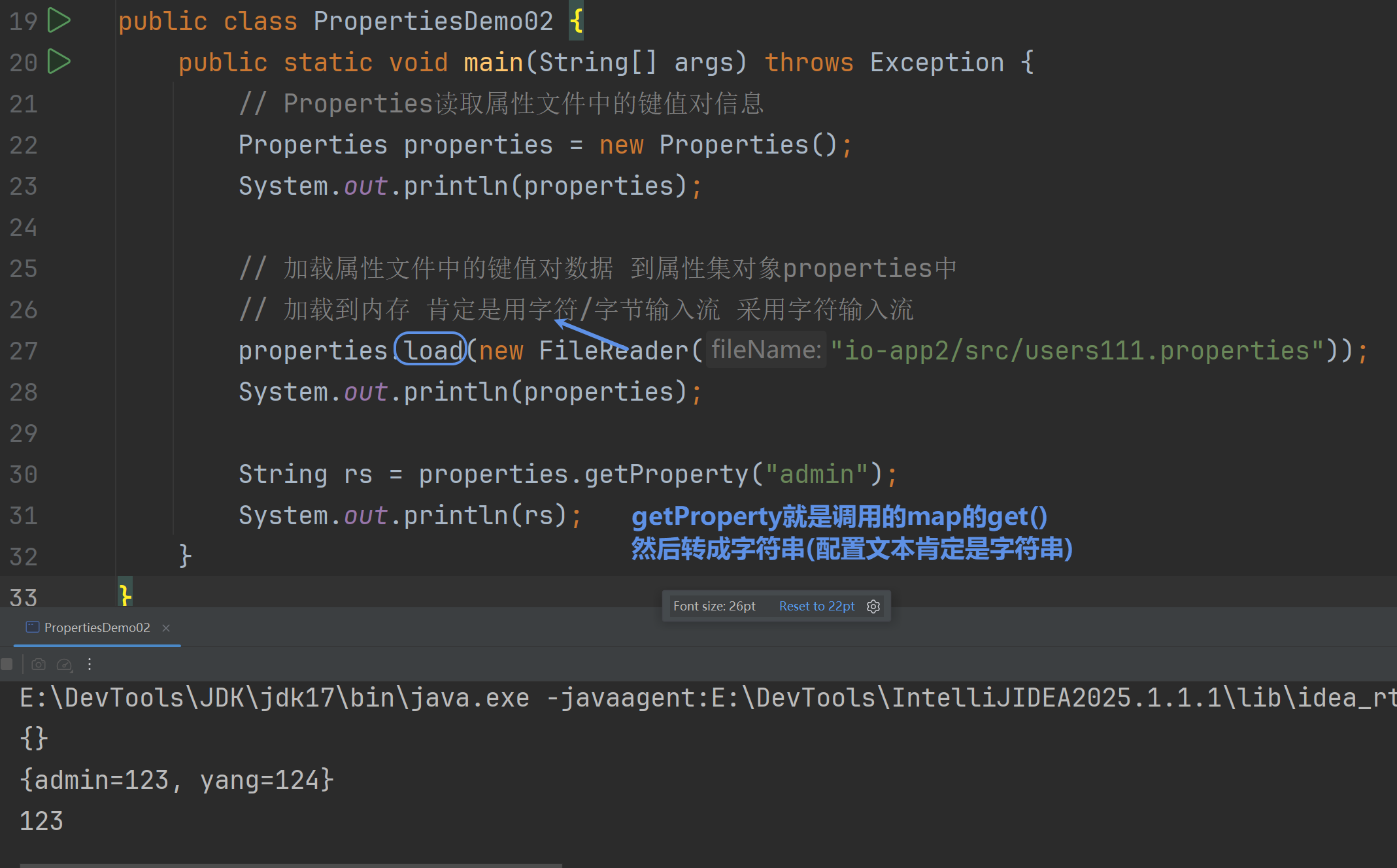
Properties:
1.保存内存中Properties集合的键值对数据→磁盘的属性文件 store()
2.加载磁盘的属性文件→内存中Properties对象中 load()
常用API:
store()从内存→磁盘配置文件
load()从磁盘配置文件→内存


3.4 总结
字节流适合做一切文件数据的拷贝 但是不适合读取中文内容输出
字符流适合读写文本文件
字符流会自动处理编码 字节流不会FileReader字符流:read()时自动解码→得到char\[\]数组 new String(char\[\],offset,len)是在拼接字符串
FileInputStream字节流:read()时是在得到字节编码→得到byte\[\]数组 new String(byte\[\],offset,len,charset)是在手动解码为字符串

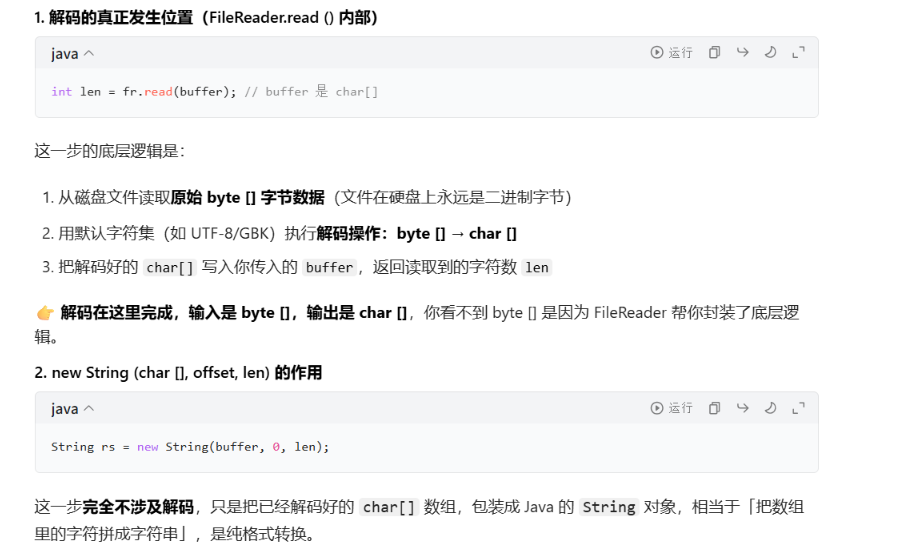
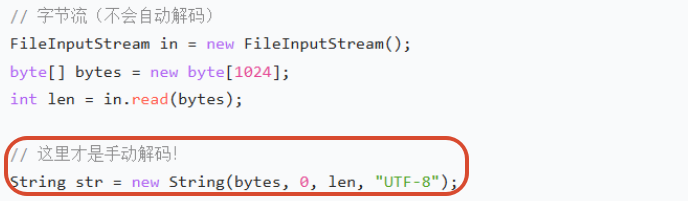
四、缓冲流
4.1 概述与体系图
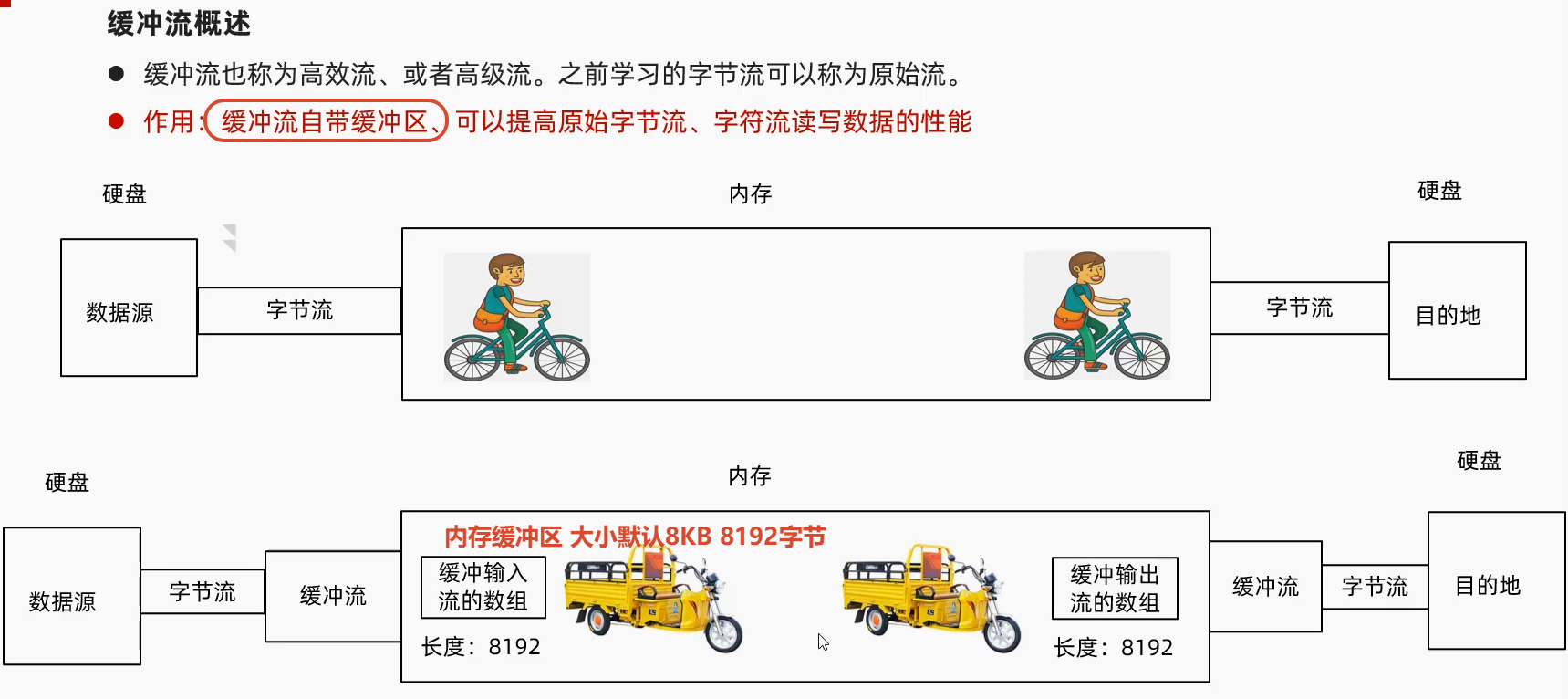
缓冲流提高效率的核心原理:减少频繁的磁盘I/O操作 用内存当"中转站"批量读写(用内存空间换I/O次数 )
普通字节/字符流 读一个字节就访问一次磁盘;写一个字节就刷一次磁盘 而磁盘I/O速度远慢于内存 频繁访问就会非常慢
缓冲流内部自带一个默认8KB的字节数组缓冲区
读取时 一次性从磁盘读一块数据到内存缓冲区 程序再从缓冲区逐个取数据 缓冲区空了 才再去磁盘读一批写出时 先把数据写到内存缓冲区 缓冲区满了/手动 flush /关闭流时 才一次性刷到磁盘
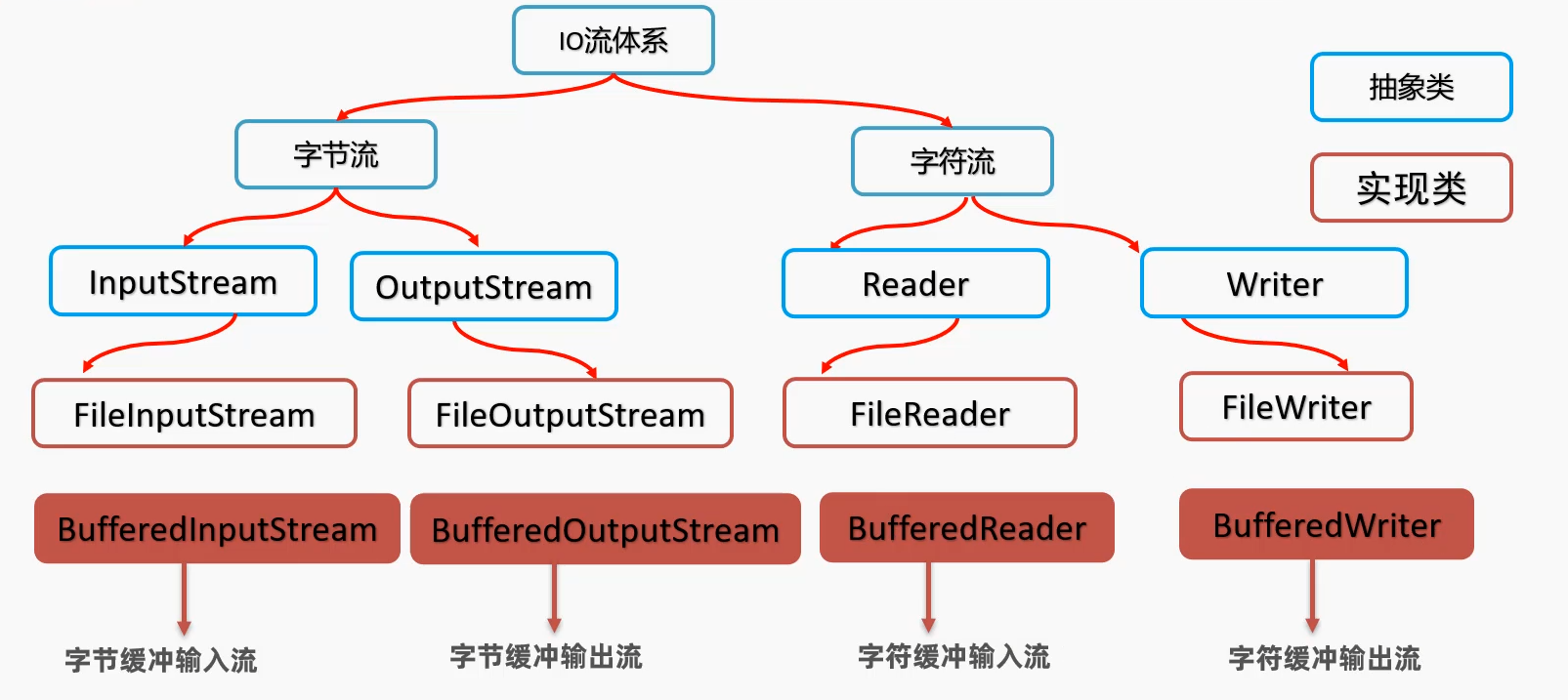
体系图:字节缓冲输入输出流
字符缓冲输入输出流


4.2 字节缓冲流
原始字节输入输出流→缓冲字节输入输出流
功能上没有太大的差异 只是提高了效率

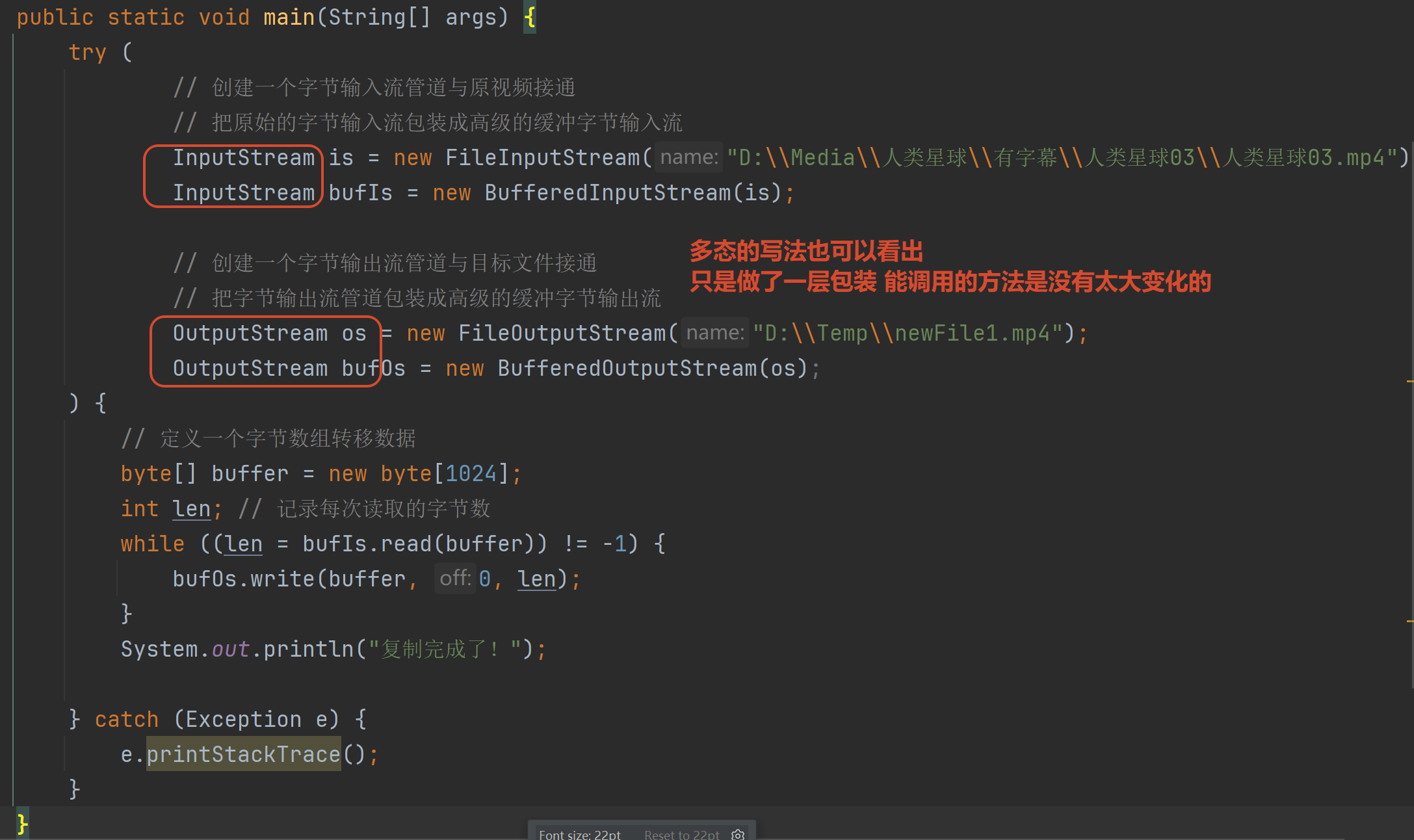
4.3 字节缓冲流改进文件拷贝
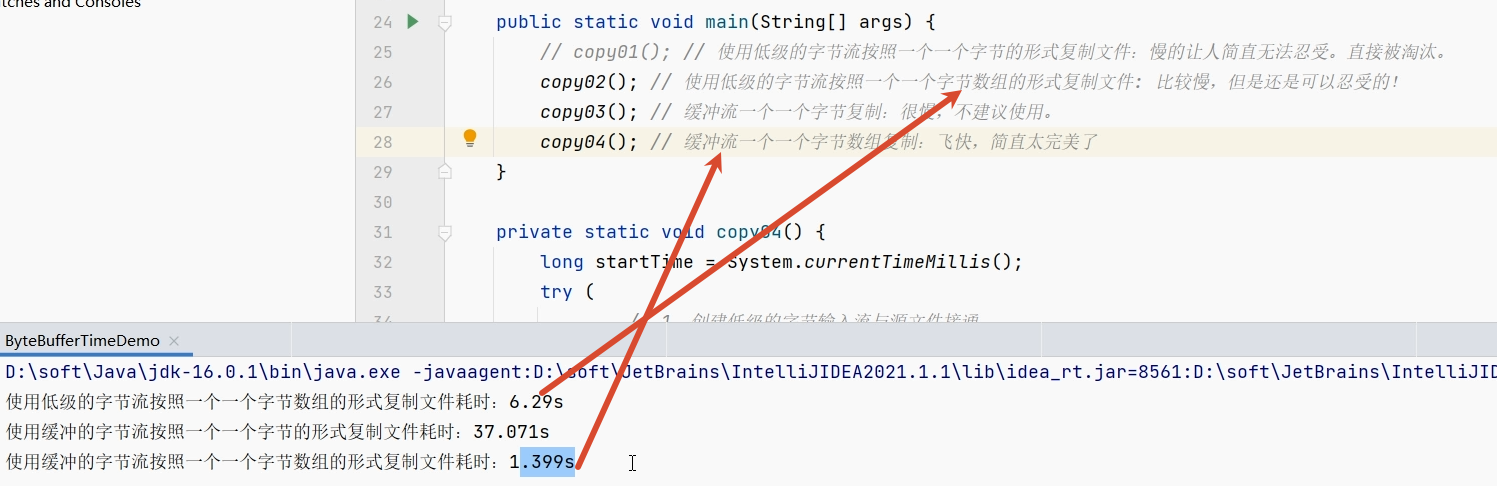
对比原始字节流(用is和os) 缓冲字节流(用bis和bos)的速度快了很多
最慢的就是原始字节流按照一个一个字节拷贝 缓冲字节流按照数组拷贝是最快的注意:
如果buffer数组的大小是1024字节=1KB 缓冲流是最快的
但是如果设置成8KB
原始字节流按照字节数组拷贝速度可能比缓冲流还快(就好像它也有了一个8KB缓冲区)
所以建议是 使用缓冲流+buffer数组设置为1KB
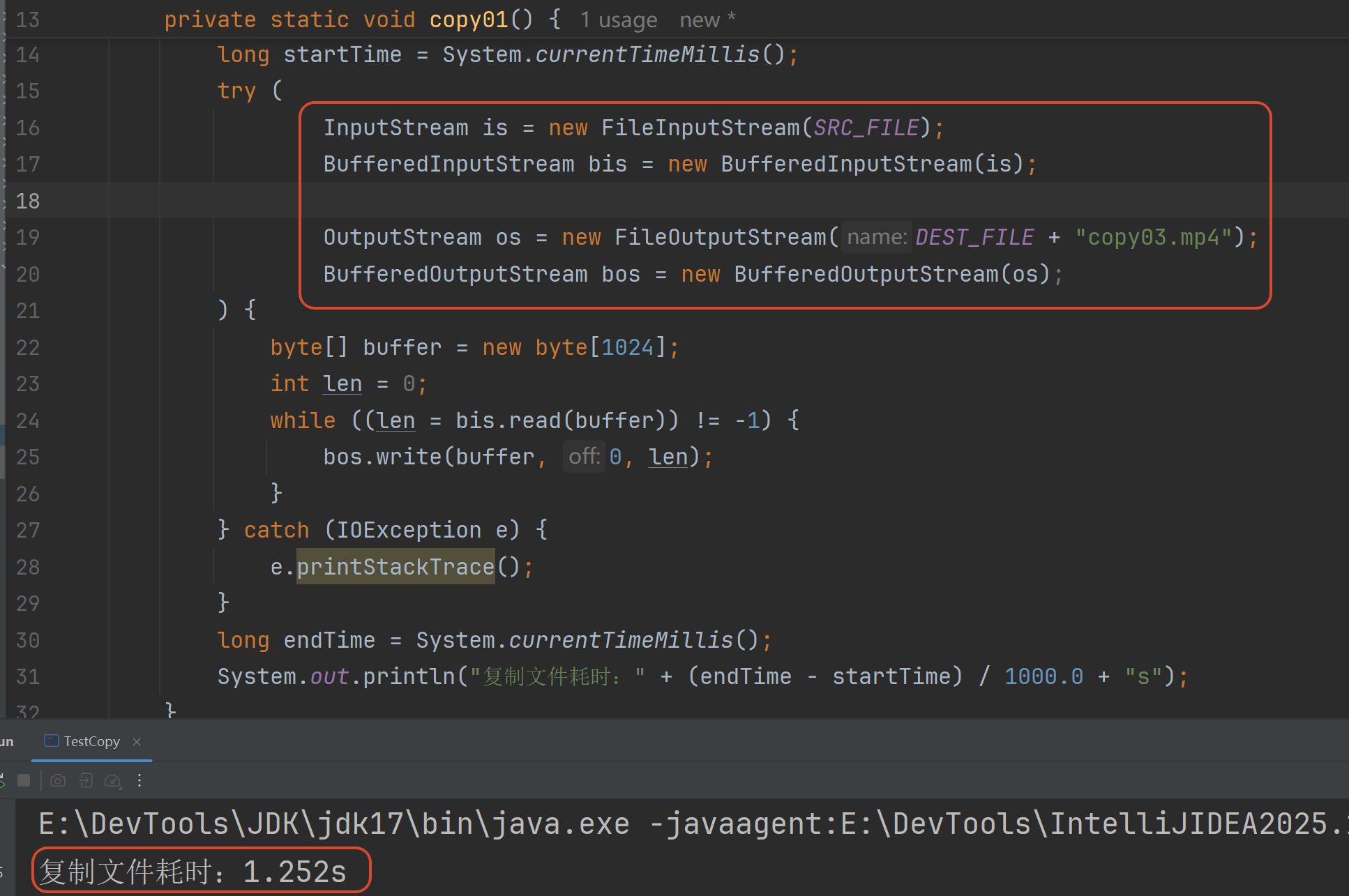
参考代码:
java
import java.io.*;
public class TestCopy {
private static final String SRC_FILE = "D:\\Media\\人类星球\\有字幕\\人类星球03\\人类星球03.mp4";
private static final String DEST_FILE = "D:\\Temp\\";
public static void main(String[] args) {
copy01();
}
private static void copy01() {
long startTime = System.currentTimeMillis();
try (
InputStream is = new FileInputStream(SRC_FILE);
BufferedInputStream bis = new BufferedInputStream(is);
OutputStream os = new FileOutputStream(DEST_FILE + "copy03.mp4");
BufferedOutputStream bos = new BufferedOutputStream(os);
) {
byte[] buffer = new byte[1024];
int len = 0;
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("复制文件耗时:" + (endTime - startTime) / 1000.0 + "s");
}
}4.4 字符缓冲流
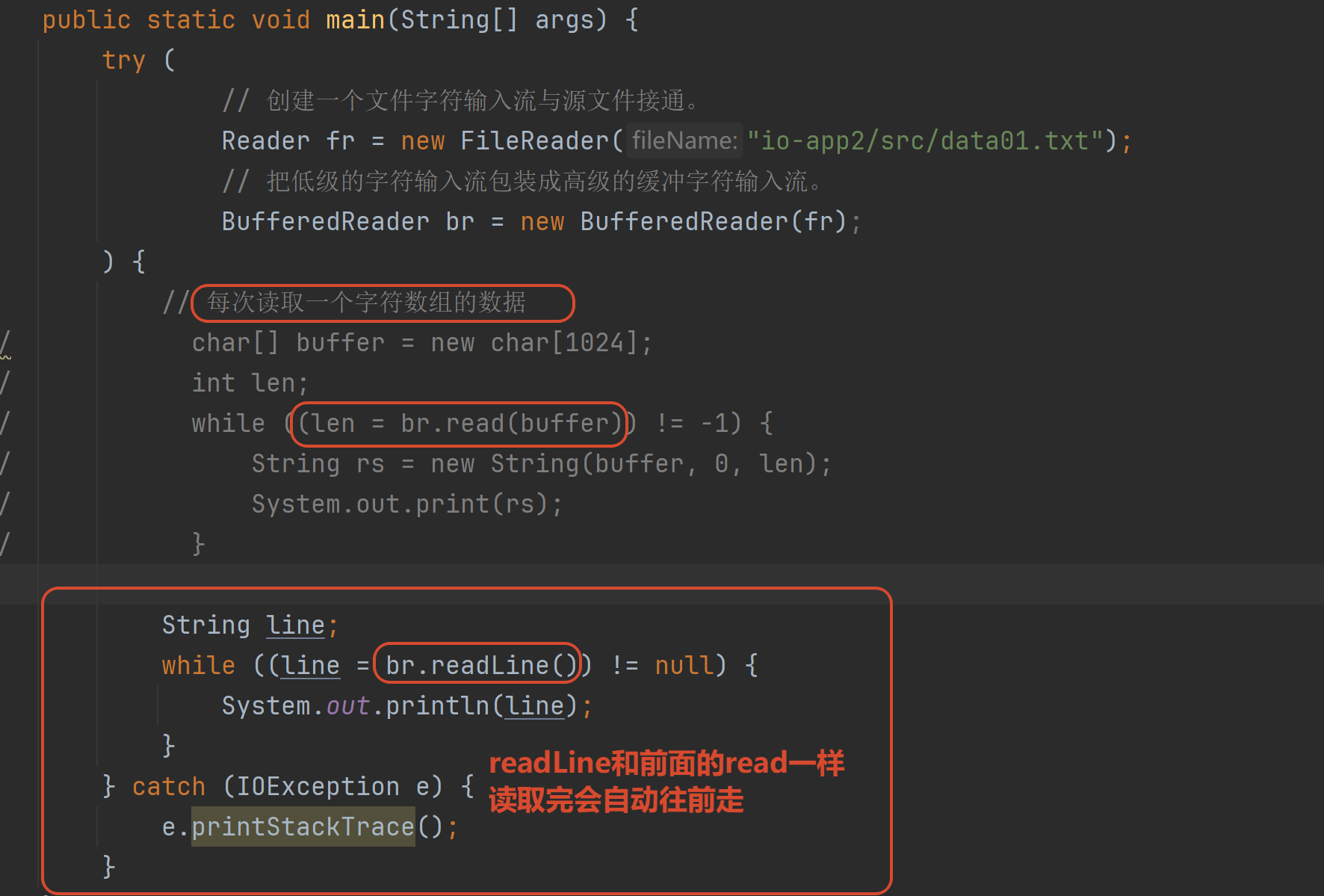
字符缓冲输入流多了一个本类特有的方法:按照一行一行来读数据readLine()
字符缓冲输入流 :把磁盘数据读取到→内存(程序)中
字符缓冲输出流多了一个本类特有的方法:写出数据的时候换行newLine()字符缓冲输出流 :把内存(程序)中数据输出到→磁盘数据



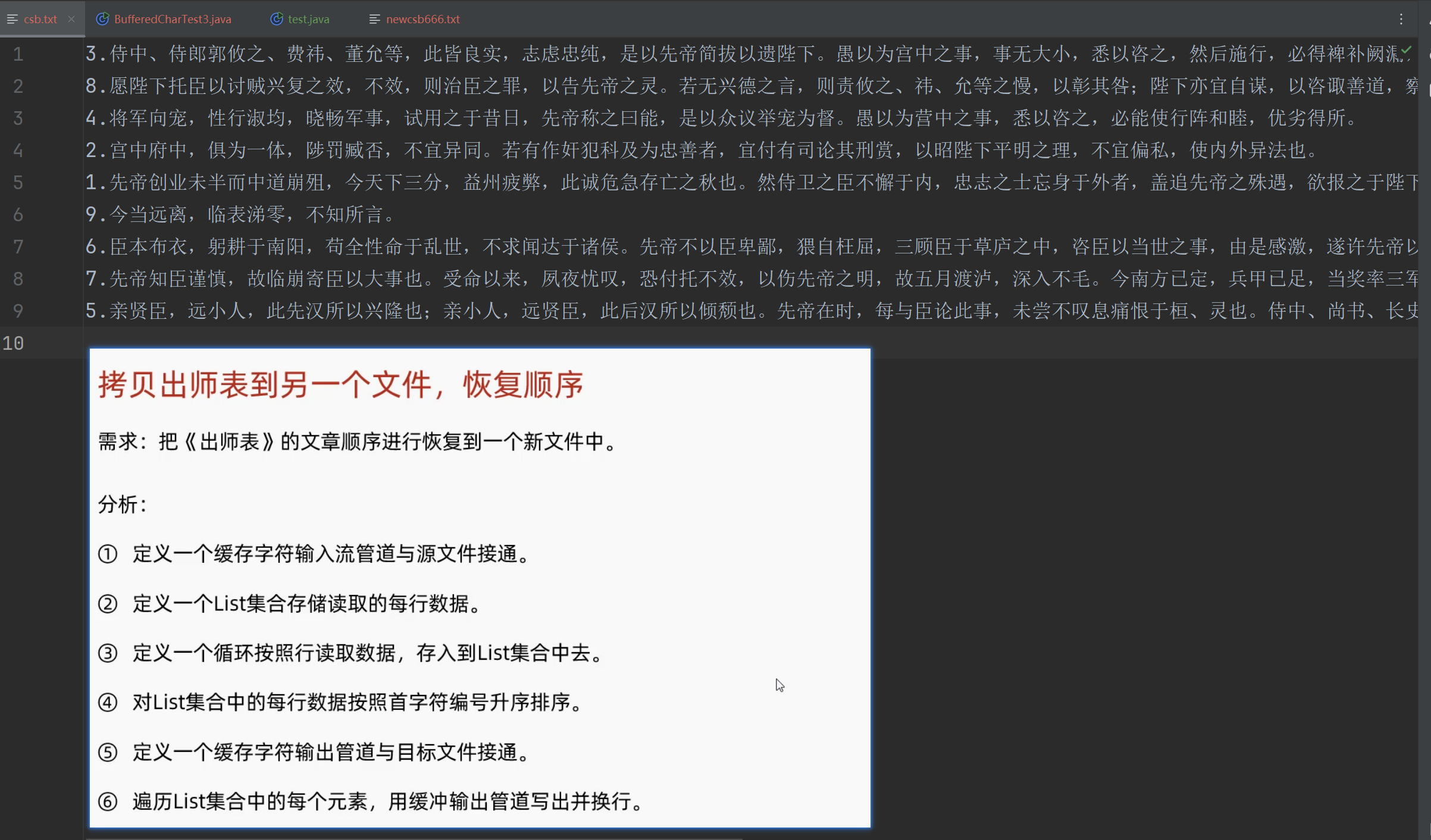
4.5 案例:拷贝出师表 并恢复顺序
文件数据→读取到内存→在内存排好序→拷贝到目标文件
下图只有1~9 自定义比较规则很简单 可以直接用charAt取到序号
拓展:如果序号不止一位数 比如11 10→正则表达式来写比较规则
参考代码:
java
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class test {
public static void main(String[] args) {
try (
//读入到内存
BufferedReader br = new BufferedReader(new FileReader("io-app2/src/csb.txt"));
//写出到目标文件
BufferedWriter bw = new BufferedWriter(new FileWriter("io-app2/src/newcsb1.txt"));
) {
List<String> list = new ArrayList<>();
//读取到数据 先暂存到内存 准备排序
String str = " ";
while ((str = br.readLine()) != null) {
list.add(str);
}
Pattern pattern = Pattern.compile("^\\d+");
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
int a = getNum(s1);
int b = getNum(s2);
return Integer.compare(a, b);
}
private int getNum(String s) {
Matcher m = pattern.matcher(s);
return m.find() ? Integer.parseInt(m.group()) : 0;
}
});
for (String s : list) {
bw.write(s);
bw.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}五、字符转换流
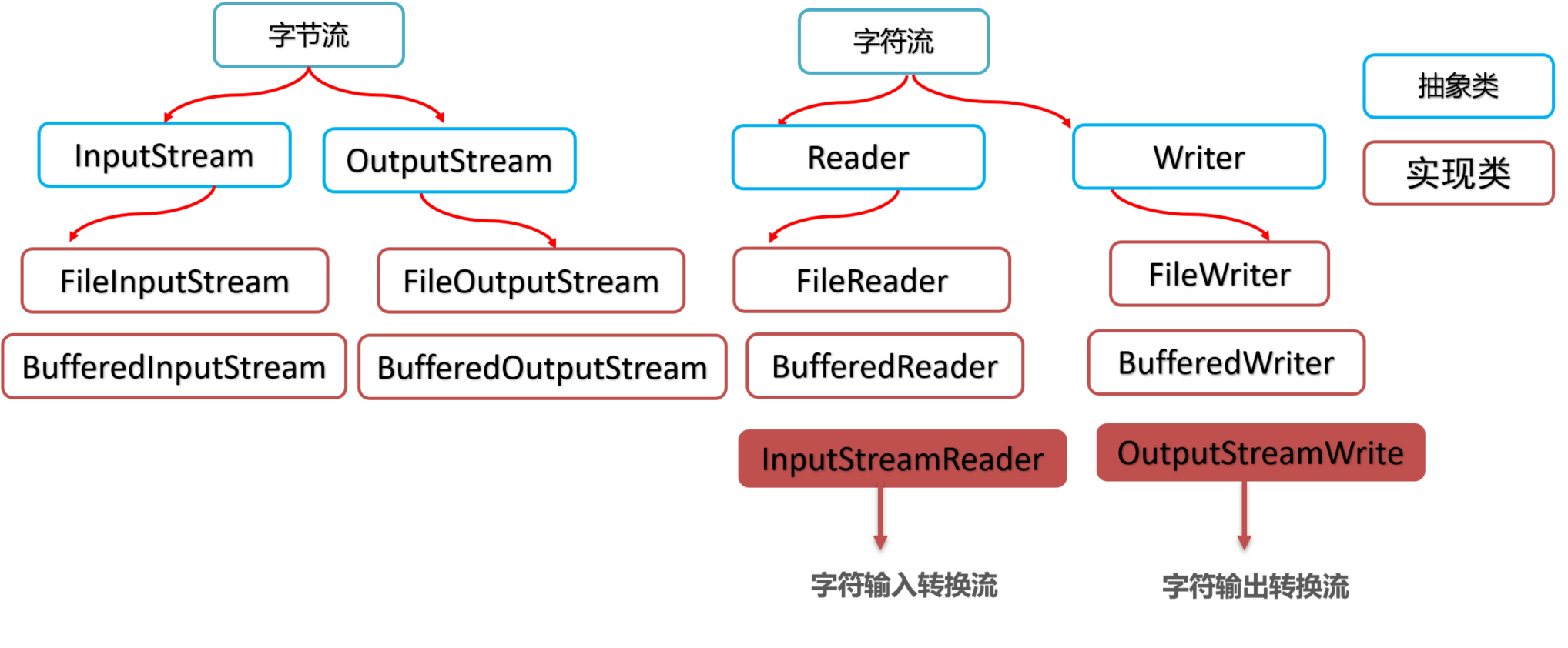
5.1 体系图与构造器
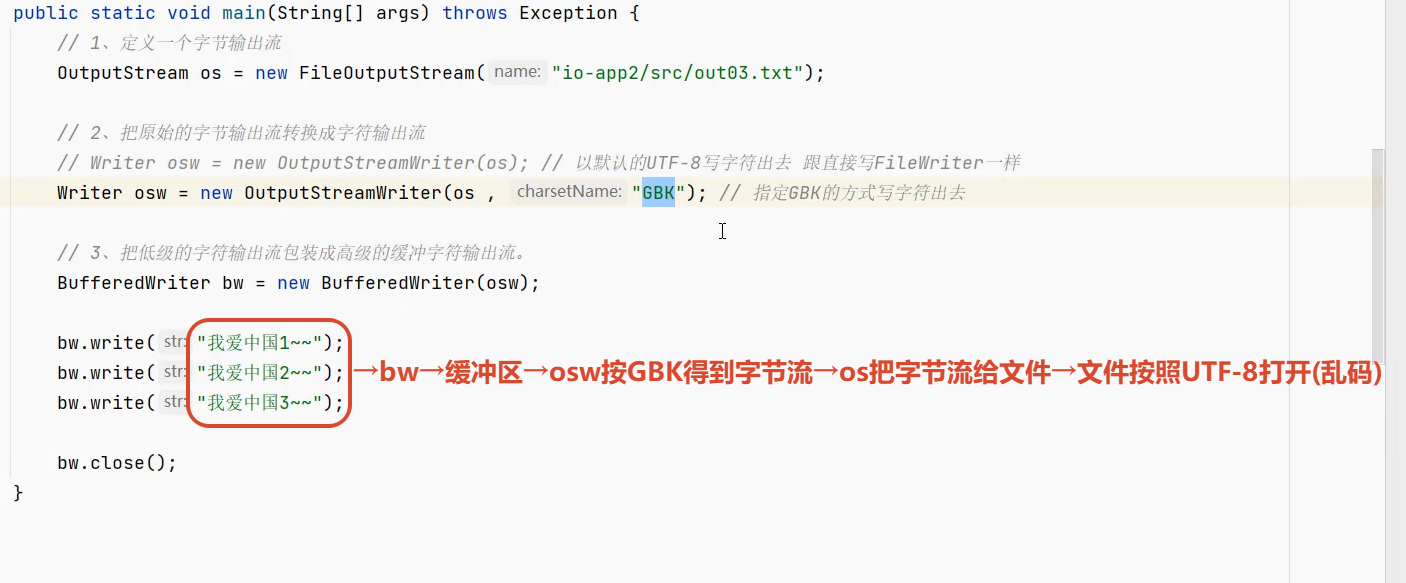
代码编码和文件编码不一致→乱码
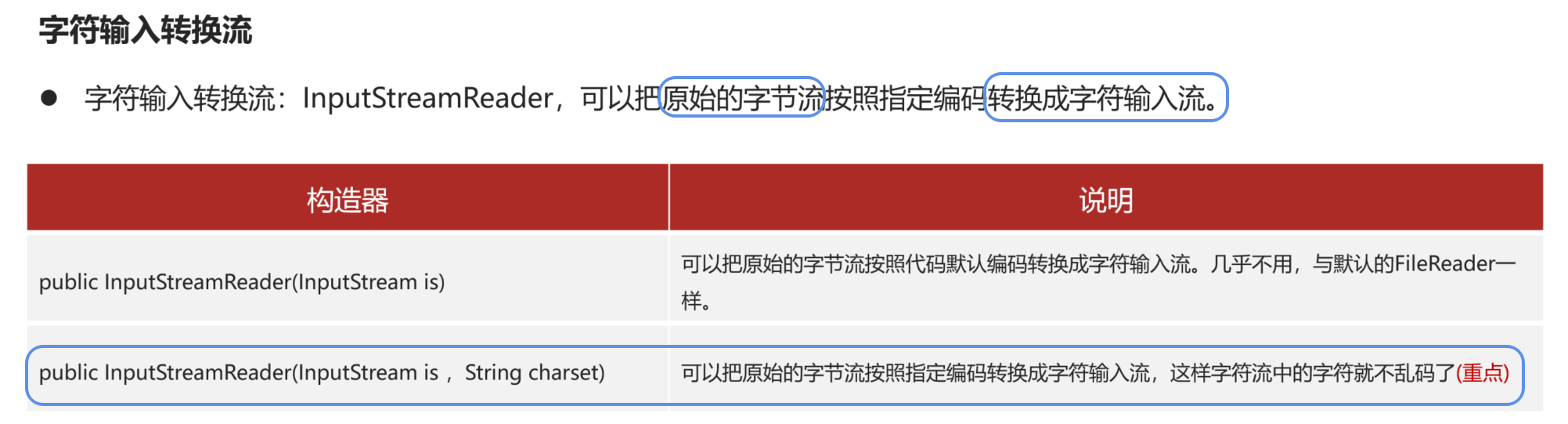
5.2 字符输入转换流
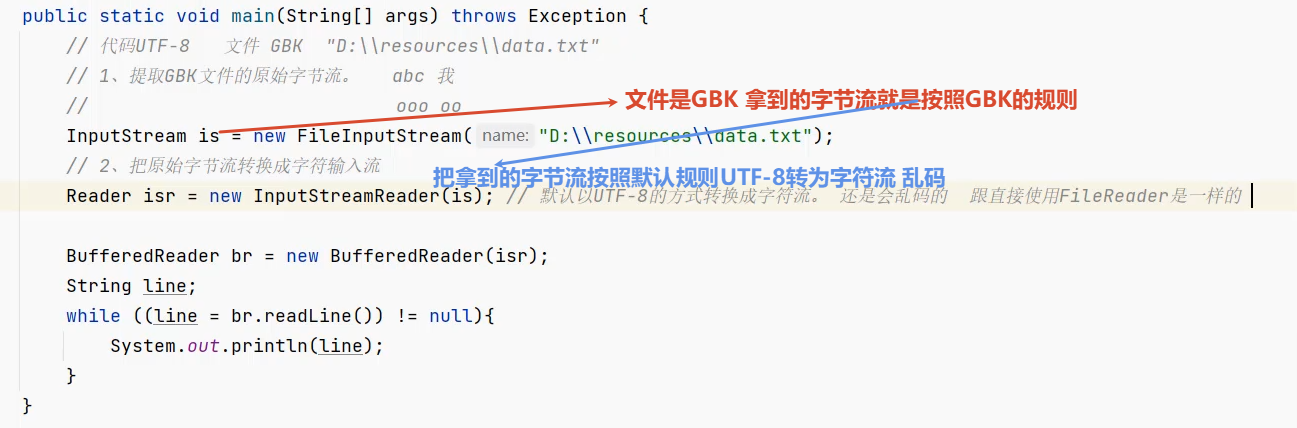
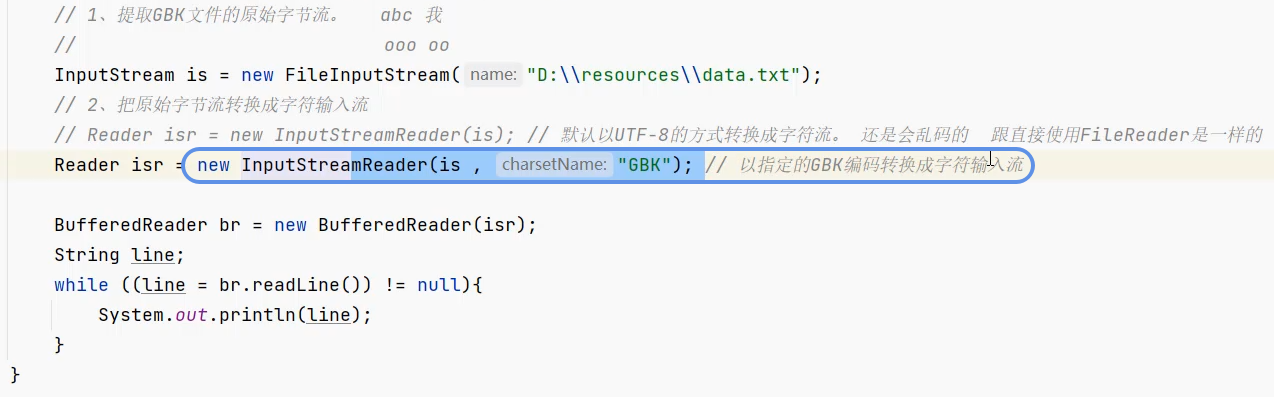
先提取文件的原始字节输入流→按照需要的编码→字符输入流
如果使用这个构造器 还是可能乱码:
文件是GBK 则指定按照GBK的规则把字节流→字符流 就不乱码:1.FileInputStream is = new FileInputStream(...) 从文件中原样读取原始字节 不做任何编码/解码 字节内容对应文件的GBK存储格式
2.new InputStreamReader(is, "GBK") 按照GBK编码规则 把读取到的GBK字节流 解码为字符流(不乱码) 若不指定编码 默认UTF-8(会乱码)
3.new BufferedReader(isr) 包装字符流 通过缓冲区提升读取效率
4.br.readLine() 从缓冲区读取已解码的字符行

5.3 字符输出转换流
把内存的数据按照某种编码规则写出去

六、序列化
6.1 概述与体系图
对象序列化→对象永久保存→把内存的对象存储到磁盘
注意:
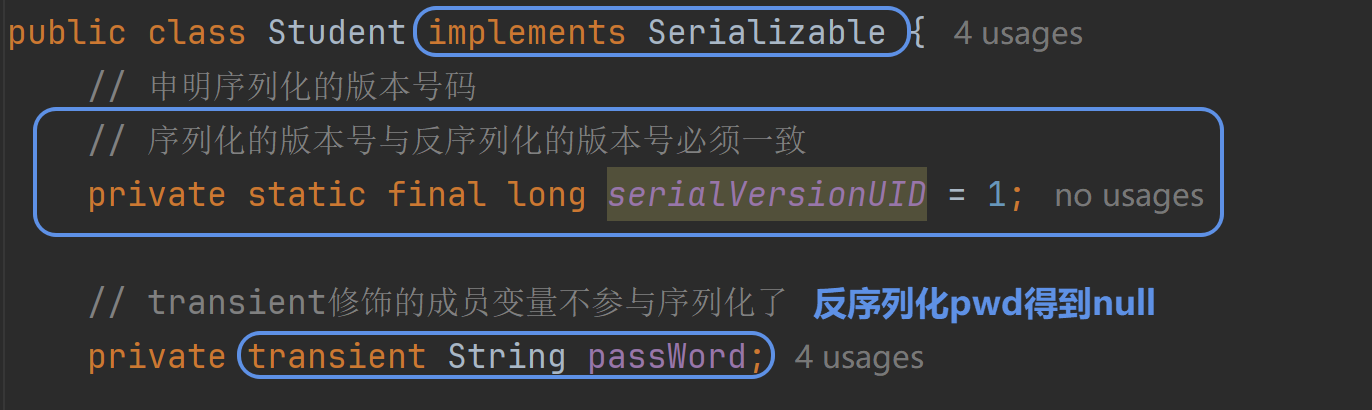
1.要序列化某个对象 该对象必须实现Serializable序列化接口
2.transient修饰的成员变量不参与序列化
3.序列化的版本号 与 反序列化的版本号必须一致(serialVersionUID )
4.序列化之后的对象 不是给人看的(看似乱码 实际不是乱码) 只是把这个对象信息永久保存了 下次可能要拿到这个对象
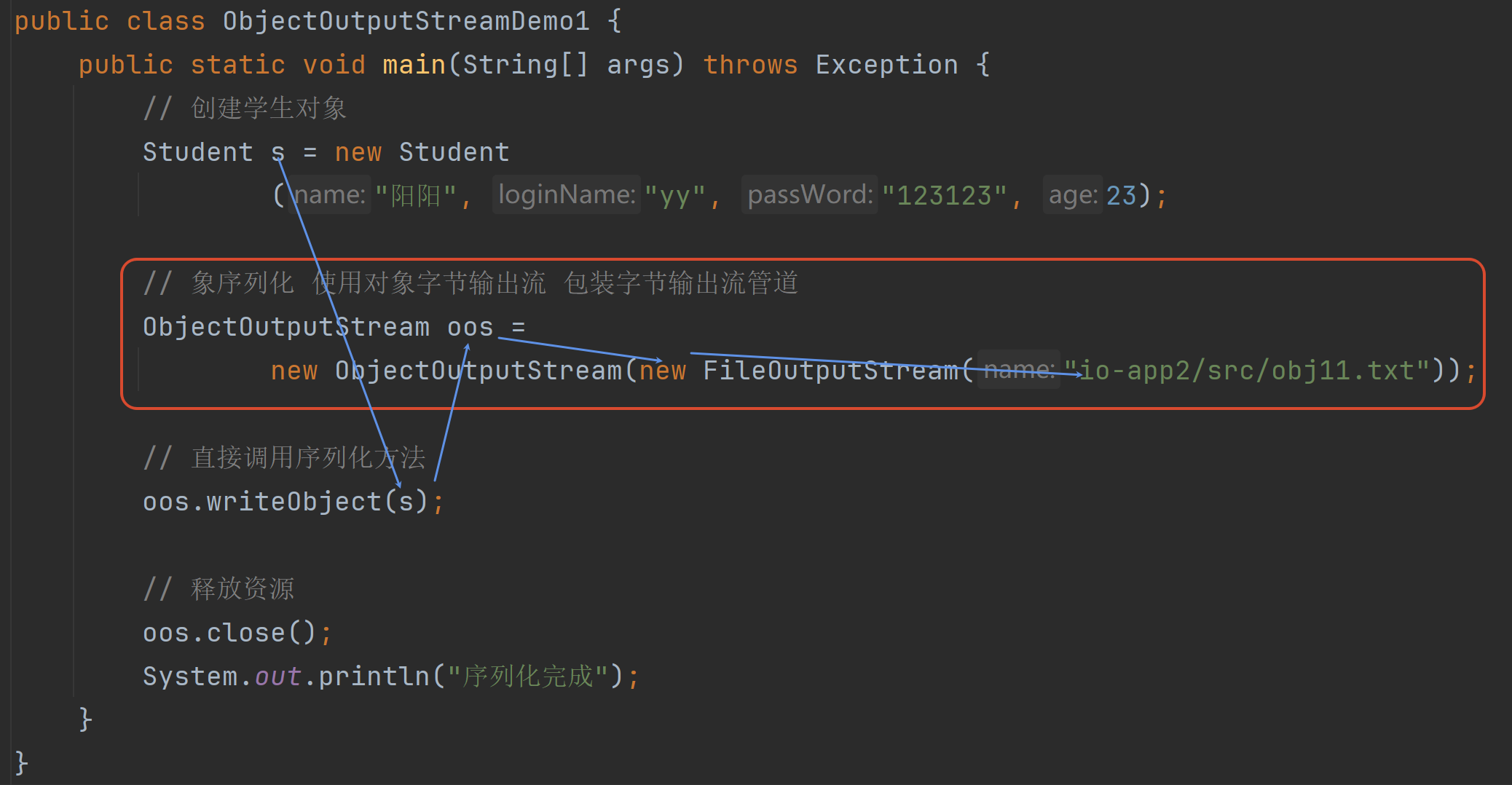
6.2 序列化(对象字节输出流)
把内存中的对象→磁盘中永久保存


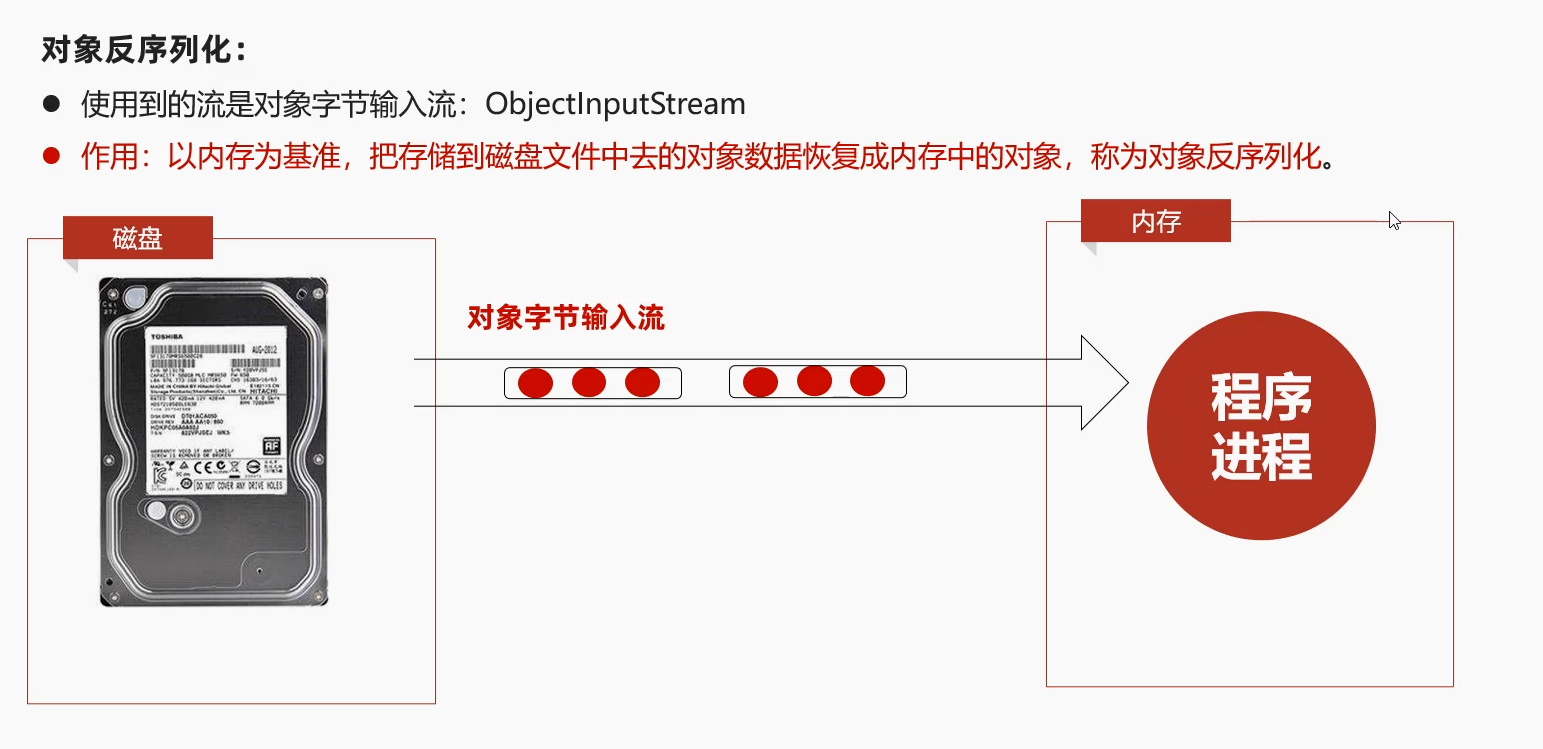
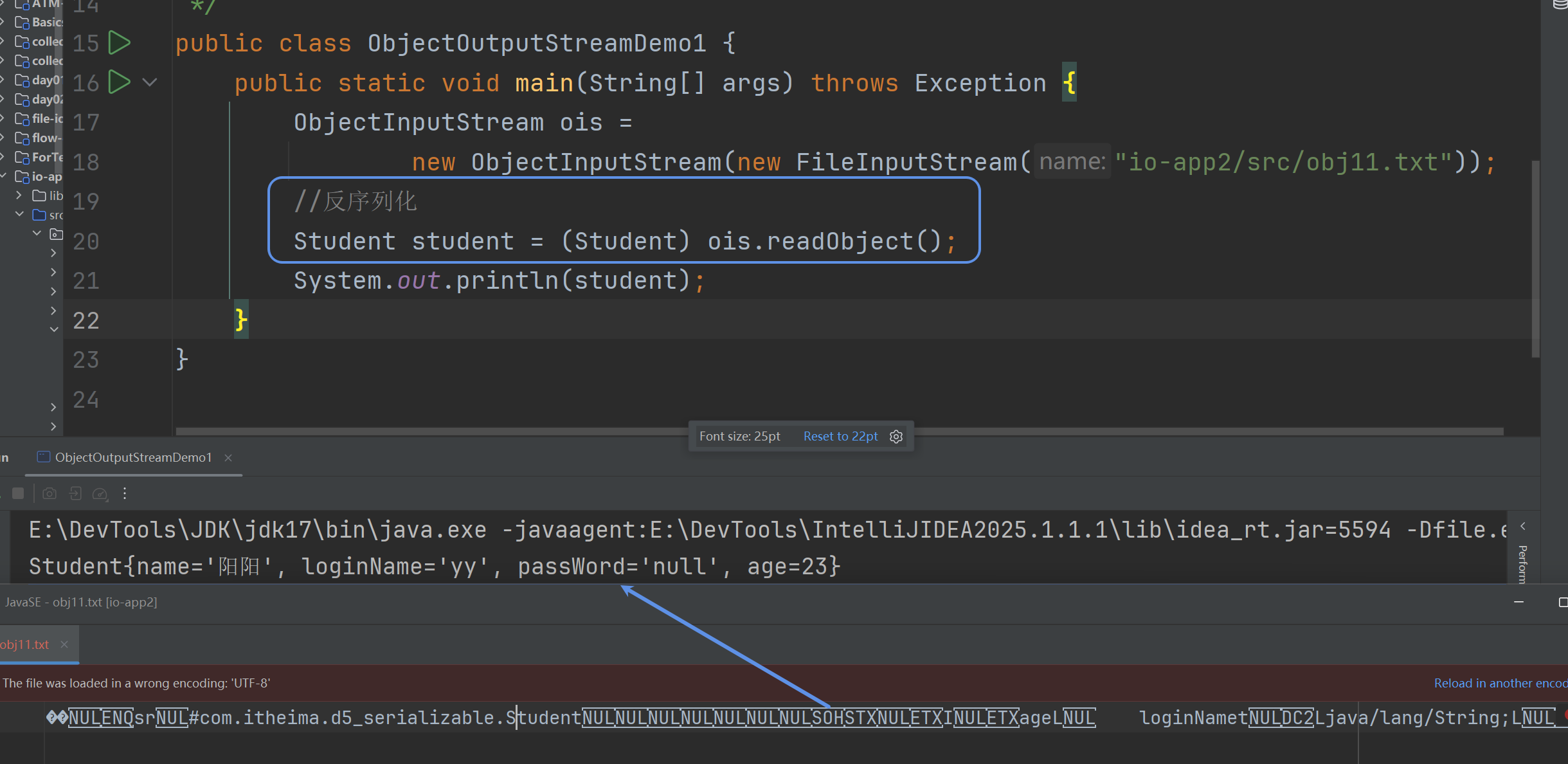
6.3 反序列化(对象字节输入流)
磁盘文件中的对象数据→内存中的Java对象

七、打印流
7.1 体系图
一种更方便 更高效(内部也基于缓冲流)的 写数据到磁盘中 的流
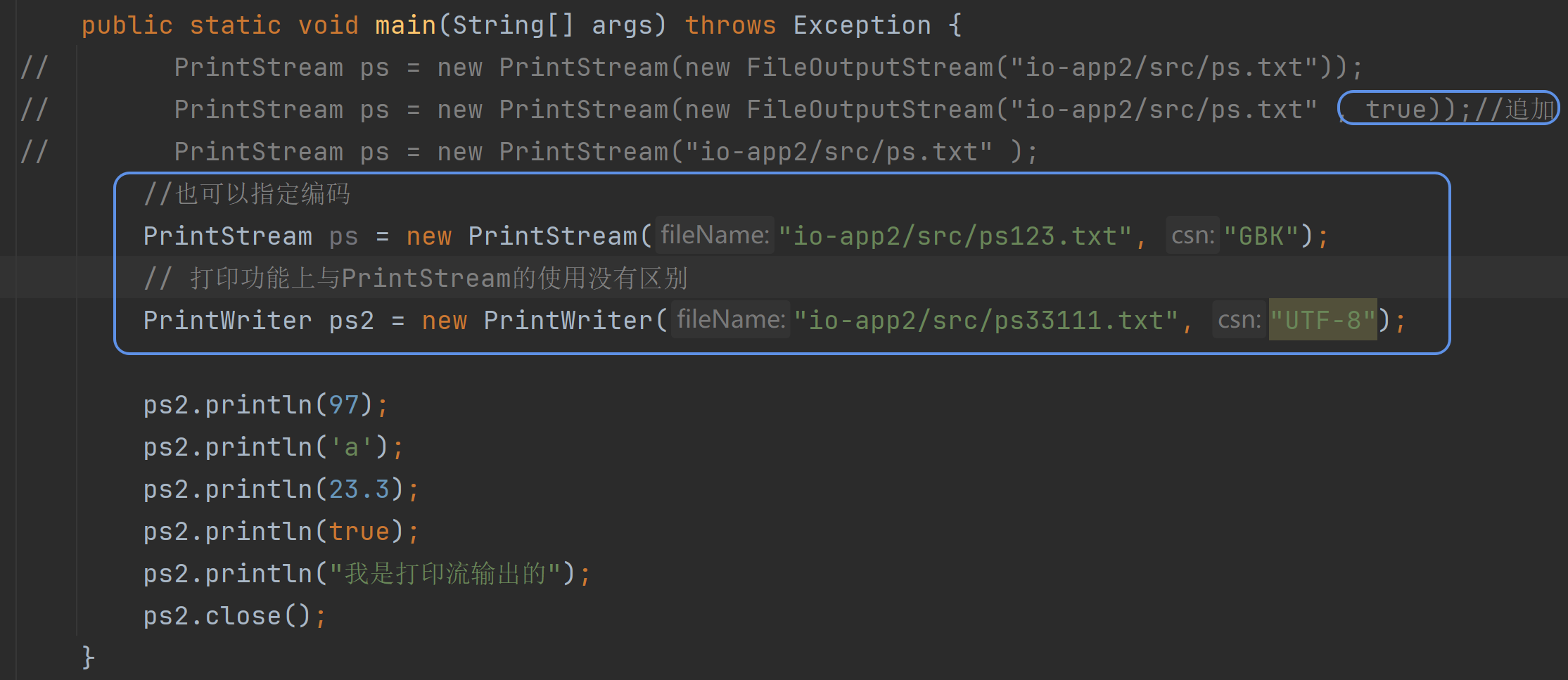
可以实现打印什么就是什么 所见即所得(97→97 a→a true→true)
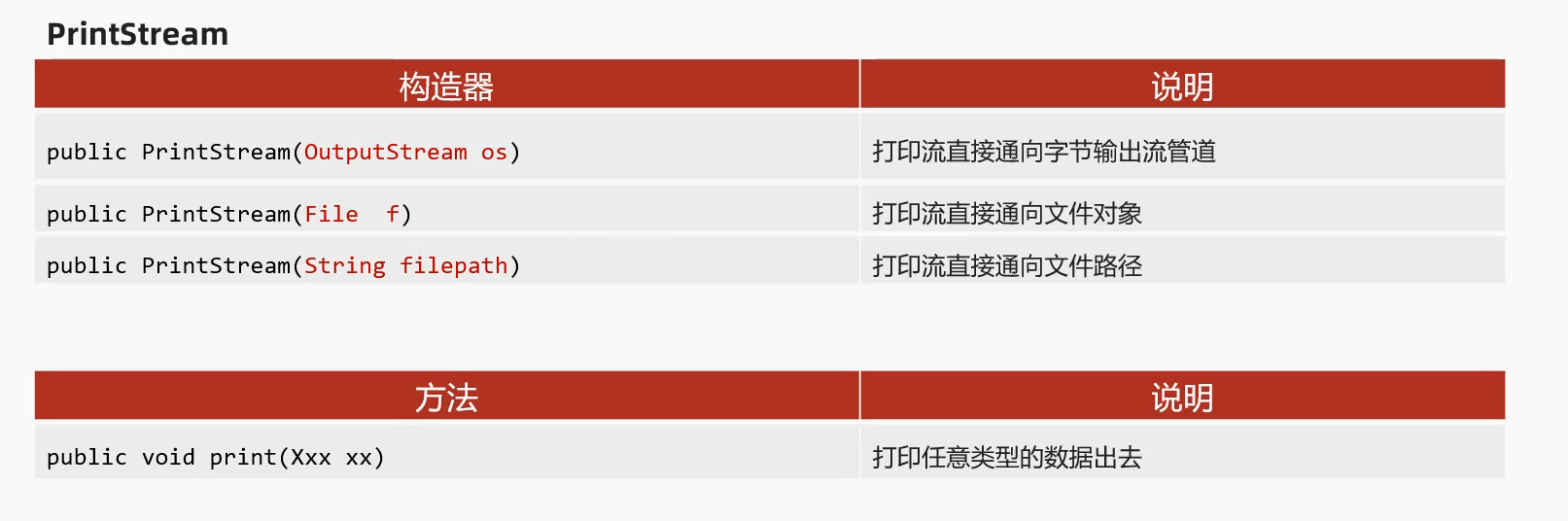
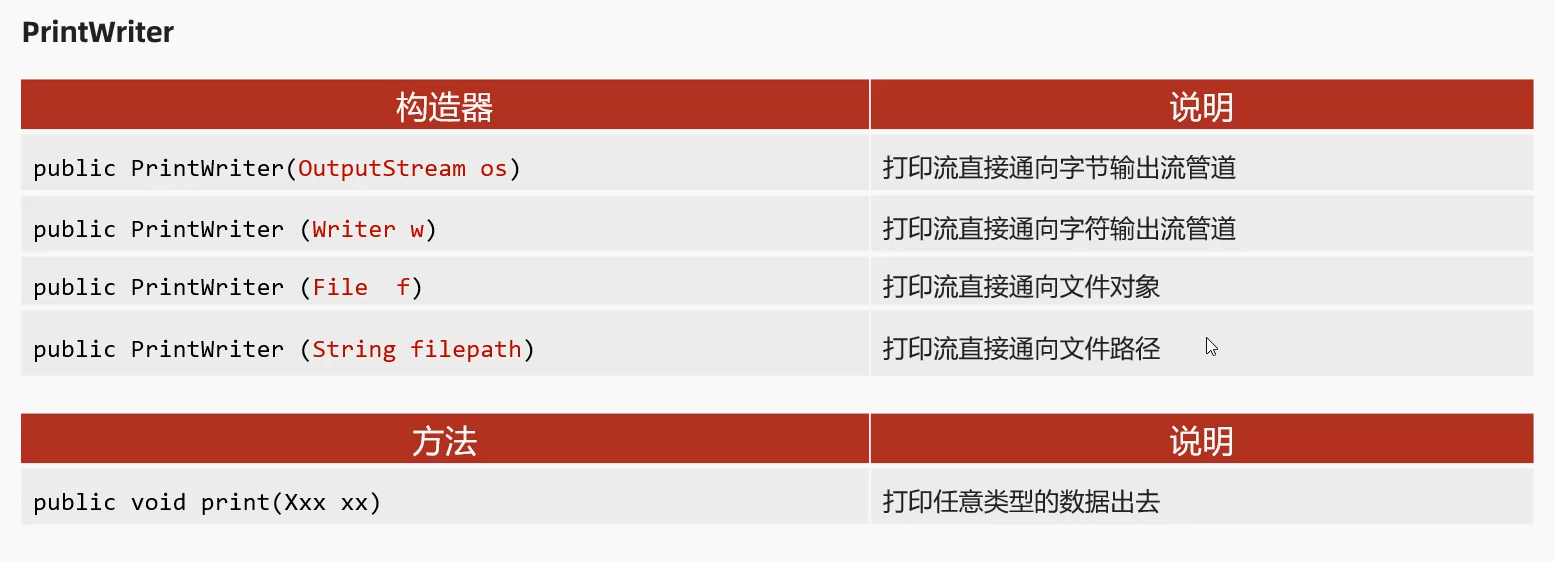
7.2 PrintStream/PrintWriter
PrintStream:
PrintWriter:
代码案例:追加数据要在原始管道加上true
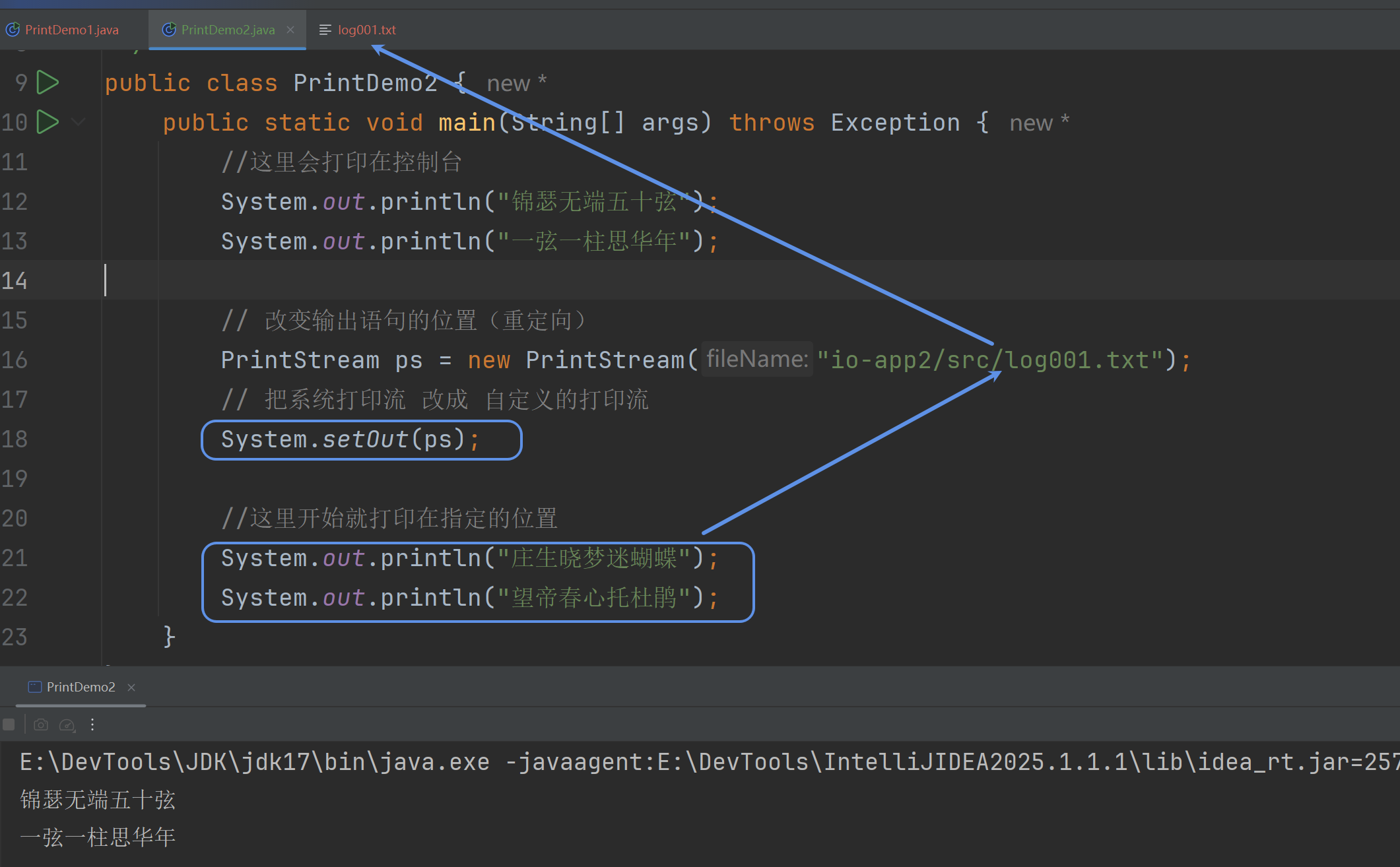
7.3 输出语句重定向
其实sout就是用的打印流 默认打印到控制台
System.setOut(ps)→用自己的打印流

八、Commons-io包介绍
8.1 简介
commons-io是apache开源基金组织提供的一组有关IO操作的类库 可以提高IO功能开发的效率
commons-io工具包提供了很多有关io操作的类(常用IOUtils FileUtils)
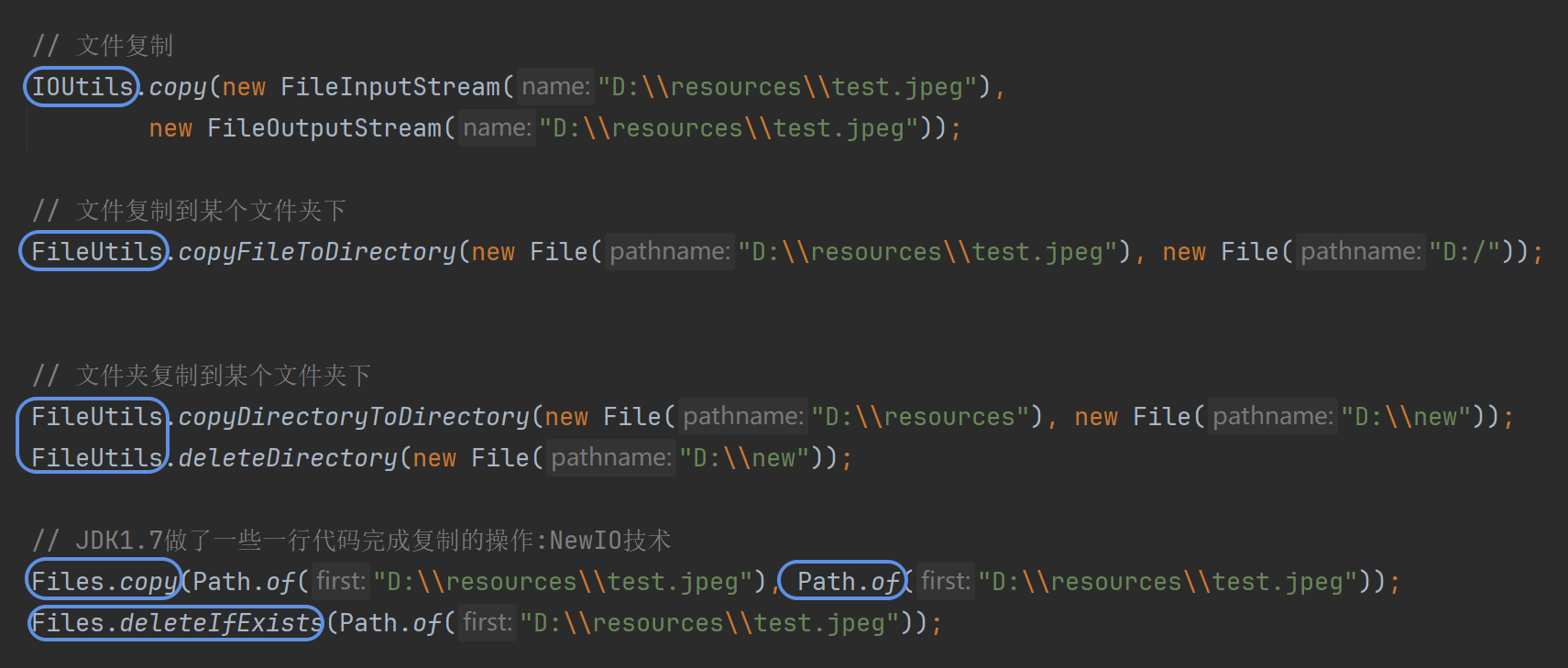
8.2 常用类和方法
FileUtils

8.3 Maven坐标
xml
<!-- Commons IO 最新稳定版 -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.16.1</version>
</dependency>