TL;DR
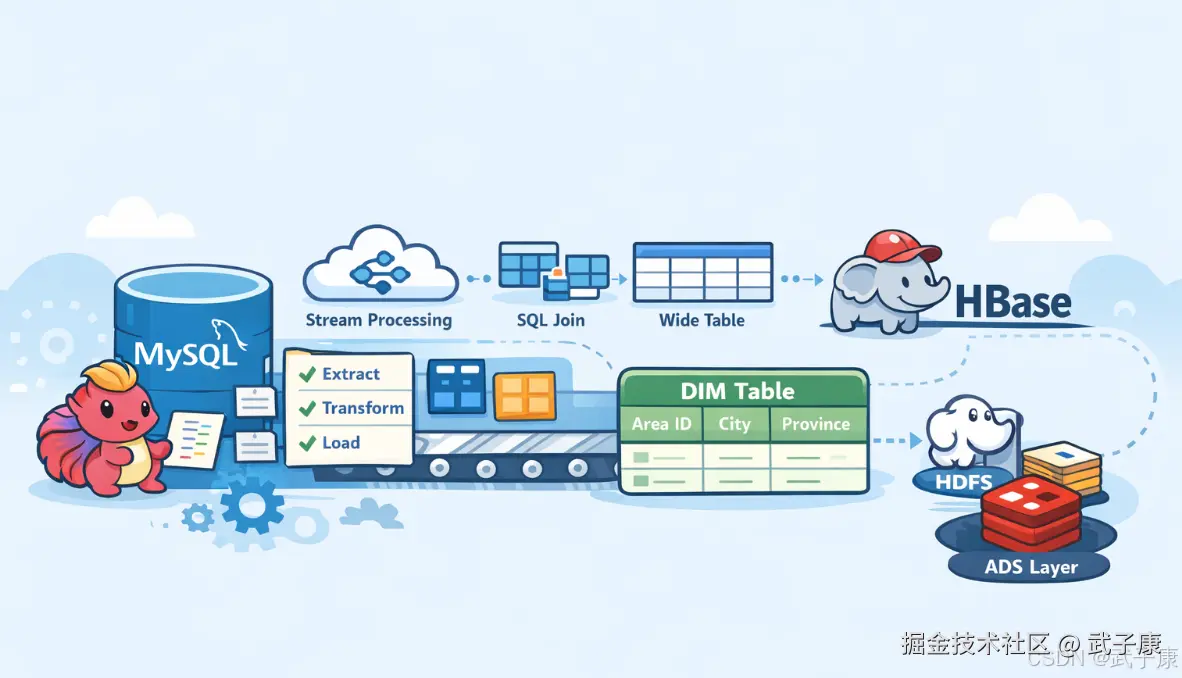
- 场景:基于 Flink 流处理将 MySQL 原始地区表数据抽取、转换、加载到 HBase 构建 DIM 层维度数据
- 结论:通过 HBaseReader 读取源数据,SQL 关联维度表生成宽表,HBaseWriterSink 回填目标表,实现离线+实时融合的维度数据处理
- 产出:完整 Scala 源码(HBaseReader、HBaseWriterSink、AreaDetailInfo),可直接用于生产环境
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| HBaseReader 数据读取 | ✅ 已验证 | 从 wzk_area 表读取原始数据,支持 Scan 全表扫描 |
| SQL 维度关联 | ✅ 已验证 | 三表 INNER JOIN 构建省市区层级维度 |
| HBaseWriterSink 回填 | ✅ 已验证 | 批量 Put 写入 dim_wzk_area 宽表 |
| Flink Checkpoint | ✅ 已验证 | EXACTLY_ONCE 模式保证数据一致性 |
| Redis ADS 层输出 | ✅ 已验证 | Jedis HSET 写入 Redis Hash |
DIM 层处理
实现思路
最原始的表 MySQL 中 area 到 HBase 中 转换 area 表 到 地区ID、地区的名字、城市ID、城市的名字、省份 ID、省份的名字 到 HBase 中
在分析交易过程时,可以通过卖家、买家、商品和时间等维度描述交易发生的环境,所以维度的作用一般是查询约束、分类汇总以及排序等。
HBaseReader
scala
class HBaseReader extends RichSourceFunction[(String, String)] {
private var conn: Connection = null
private var table: Table = null
private var scan: Scan = null
override def open(parameters: configuration.Configuration): Unit = {
val conf: Configuration = HBaseConfiguration.create()
conf.set(HConstants.ZOOKEEPER_QUORUM, "h121.wzk.icu,h122.wzk.icu,h123.wzk.icu")
conf.set(HConstants.ZOOKEEPER_CLIENT_PORT, "2181")
conf.setInt(HConstants.HBASE_CLIENT_OPERATION_TIMEOUT, 30000)
conf.setInt(HConstants.HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD, 30000)
val tableName: TableName = TableName.valueOf("wzk_area")
val cf1: String = "f1"
conn = ConnectionFactory.createConnection(conf)
table = conn.getTable(tableName)
scan = new Scan()
scan.addFamily(Bytes.toBytes(cf1))
}
override def run(ctx: SourceFunction.SourceContext[(String, String)]): Unit = {
val rs: ResultScanner = table.getScanner(scan)
val iterator: util.Iterator[Result] = rs.iterator()
while (iterator.hasNext) {
val result: Result = iterator.next()
val rowKey: String = Bytes.toString(result.getRow)
val buffer: StringBuffer = new StringBuffer()
for (cell: Cell <- result.listCells().asScala) {
val value: String = Bytes.toString(cell.getValueArray, cell.getValueOffset, cell.getValueLength)
buffer.append(value).append("-")
}
val valueString: String = buffer.replace(buffer.length() - 1, buffer.length(), "").toString
ctx.collect((rowKey, valueString))
}
}
override def cancel(): Unit = {
}
override def close(): Unit = {
try {
if (table != null) {
table.close()
}
if (conn != null) {
conn.close()
}
} catch {
case e: Exception => println(e.getMessage)
}
}
}HBaseWriterSink
scala
class HBaseWriterSink extends RichSinkFunction[String] {
var connection: Connection = _
var hbTable: Table = _
override def open(parameters: Configuration): Unit = {
connection = new ConnHBase().connToHbase
hbTable = connection.getTable(TableName.valueOf("dim_wzk_area"))
}
override def close(): Unit = {
if (hbTable != null) {
hbTable.close()
}
if (connection != null) {
connection.close()
}
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
insertDimArea(hbTable, value)
}
def insertDimArea(hbTable: Table, value: String): Unit = {
val infos: Array[String] = value.split(",")
val areaId: String = infos(0).trim
val aname: String = infos(1).trim
val cid: String = infos(2).trim
val city: String = infos(3).trim
val proid: String = infos(4).trim
val province: String = infos(5).trim
val put = new Put(areaId.getBytes())
put.addColumn("f1".getBytes(), "aname".getBytes(), aname.getBytes())
put.addColumn("f1".getBytes(), "cid".getBytes(), cid.getBytes())
put.addColumn("f1".getBytes(), "city".getBytes(), city.getBytes())
put.addColumn("f1".getBytes(), "proId".getBytes(), proid.getBytes())
put.addColumn("f1".getBytes(), "province".getBytes(), province.getBytes())
hbTable.put(put)
}
}AreaDetail
scala
case class AreaDetail(id: Int, name:String, pid: Int)AreaDetailInfo
scala
object AreaDetailInfo {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.enableCheckpointing(5000)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
val data: DataStream[(String, String)] = env.addSource(new HBaseReader)
val dataStream: DataStream[AreaDetail] = data.map(x => {
val id: Int = x._1.toInt
val datas: Array[String] = x._2.split("-")
val name: String = datas(5).trim
val pid: Int = datas(6).trim.toInt
AreaDetail(id, name, pid)
})
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
tableEnv.createTemporaryView("wzk_area",dataStream)
val sql : String =
"""
|select a.id as areaid,a.name as aname,a.pid as cid,b.name as city, c.id as proid,c.name as province
|from wzk_area as a
|inner join wzk_area as b on a.pid = b.id
|inner join wzk_area as c on b.pid = c.id
|""".stripMargin
val areaTable: Table = tableEnv.sqlQuery(sql)
println("--- sqlQuery ---")
val resultStream: DataStream[String] = tableEnv.toRetractStream[Row](areaTable).map(x => {
val row: Row = x._2
val areaId: String = row.getField(0).toString
val aname: String = row.getField(1).toString
val cid: String = row.getField(2).toString
val city: String = row.getField(3).toString
val proid: String = row.getField(4).toString
val province: String = row.getField(5).toString
areaId + "," + aname + "," + cid + "," + city + "," + proid + "," + province
})
resultStream.addSink(new HBaseWriterSink)
env.execute()
}
}DimArea
scala
case class DimArea(areaId:Int, aname:String, cid:Int, city:String, proId:Int, province:String)运行测试
执行 AreaDetailInfo.scala,运行效果如下所示:
DW 层处理
DW(Data WareHouse 数据仓库层),包含 DWD、DWS、DIM 层数据加工而成,主要完成数据架构与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
- DWD(Data Warehouse Detail 细节数据层),是业务层与数据仓库的隔离层,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,也即宽表化处理。
- DWS(Data WareHouse Service 服务数据层),基于 DWD 的基础数据,整合汇总成分析某一个主题域的服务数据,以分析的主题为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表
- 公共维度层(DIM):基于维度建模理念思想,建立一致性维度
- TMP 层:临时层,存放计算过程中临时产生的数据
需要注意的是,数据仓库层次划分不是固定不变的,可以根据实际需求进行适当裁剪或者添加,如果业务相对简单和独立,可以将 DWD、DWS 进行合并。
ADS层处理
ADS(Application Data Store 应用层数据)。基于 DW 数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等。
数据明细层
从数据明细层分析结果到 ClickHouse、Redis、Druid 等写入到 Redis 中。
scala
class MySinkToRedis extends RichSinkFunction[(CityOrder, Long)] {
private var jedis: Jedis = _;
override def open(parameters: Configuration): Unit = {
jedis = new Jedis("h121.wzk.icu", 6379, 6000);
jedis.select(0); // 选择 Redis 的第 0 个数据库
}
override def invoke(value: (CityOrder, Long), context: SinkFunction.Context[_]): Unit = {
if (!jedis.isConnected) {
jedis.connect();
}
val map = new HashMap[String, String]();
map.put("totalMoney", value._1.totalMoney.toString);
map.put("totalCount", value._1.totalCount.toString);
map.put("time", value._2.toString);
// 打印信息用于调试
println(s"${value._1.province}${value._1.city} 数据条目: ${map.size()}, 金额: ${map.get("totalMoney")}, 数量: ${map.get("totalCount")}, 时间: ${map.get("time")}");
try {
jedis.hset(s"${value._1.province}${value._1.city}", map);
map.clear();
} catch {
case e: Exception => e.printStackTrace();
}
}
override def close(): Unit = {
if (jedis != null) {
jedis.close();
}
}
}错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| HBaseConnection 连接超时 | Zookeeper 集群不可达或端口 2181 未开放 | 检查 h121/h122/h123.wzk.icu 网络连通性 | 确认 Zookeeper 服务运行中,防火墙放行 2181 |
| SQL 关联结果为空 | wzk_area 表数据未按 pid 层级关联 | 打印 dataStream 验证原始数据 | 确认地区数据包含完整的三级省市区层级 |
| ResultScanner 超时 | HBase client scanner timeout 配置过小 | 查看 HConstants.HBASE_CLIENT_SCANNER_TIMEOUT_PERIOD | 调大超时时间或减小每次 scan 的 batch size |
| Redis HSET 写入失败 | Jedis 未正确 select database 或连接断开 | 检查 jedis.isConnected 状态 | 重连前先 select(0) 确认数据库 |