

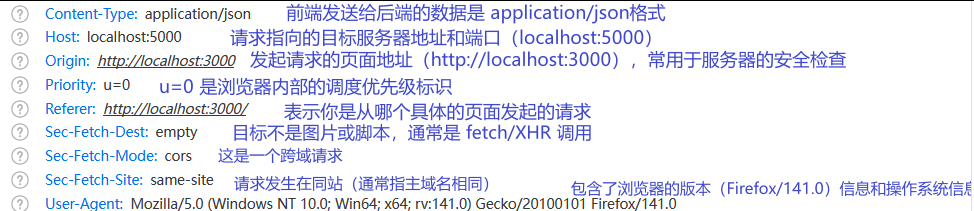
根据前端网络界面能获取的信息:
1.HTTP 请求的概要信息
请求基础信息:
-
POST : 这是 HTTP 请求方法 。
POST通常用于向服务器提交数据(例如登录表单、创建资源)。 -
Scheme : 协议方案 。
http表示使用的是未加密的超文本传输协议。 -
Host : 目标主机 。
localhost:5000说明请求发送到了你本地机器的 5000 端口。 -
Filename : 接口路径 。
/api/auth/login表明这是一个登录接口。 -
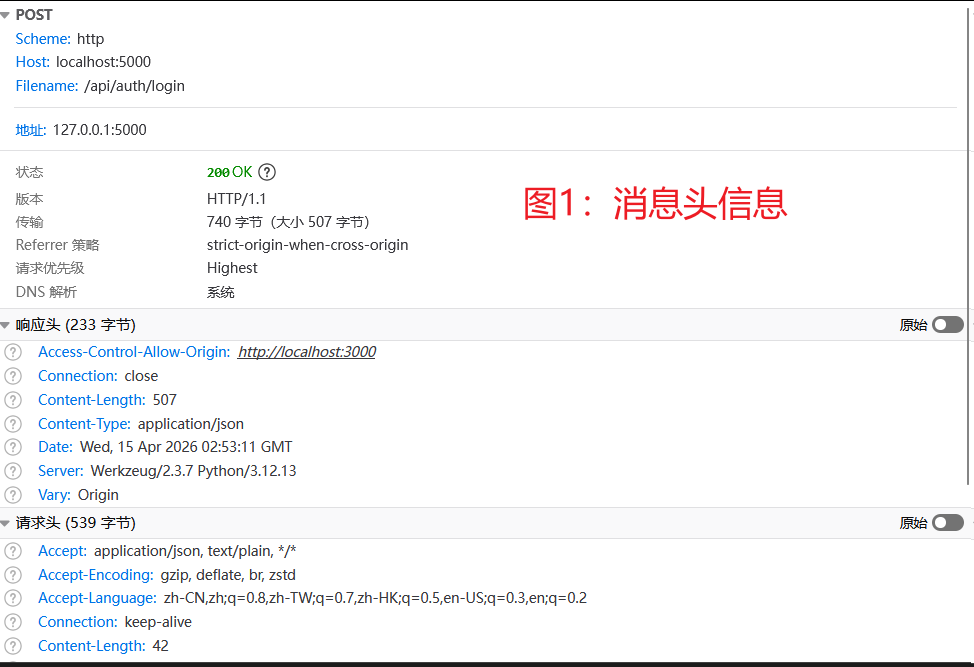
地址 (Address) :
127.0.0.1:5000是localhost对应的本地回环 IP 地址。
状态与性能:
-
状态 (Status) :
200 OK。这是最重要的信息,表示请求已成功处理,服务器正常返回了结果。 -
版本 (Version) :
HTTP/1.1。这是目前互联网上最常用的 HTTP 协议版本。 -
传输 (Transferred) :
740 字节 (大小 507 字节)。-
740 字节:是网络传输的实际流量(包括了 HTTP 头部信息)。
-
507 字节:是响应体(Payload)的原始大小。
-
-
Referrer 策略 :
strict-origin-when-cross-origin。这是一项安全策略,规定在跨域请求时,浏览器只发送域名信息,不发送完整的页面路径,以保护用户隐私。 -
请求优先级 (Priority) :
Highest。浏览器认为这个请求非常重要(通常登录请求或核心 API 都会被设为高优先级),会优先分配网络资源。 -
DNS 解析 :
系统。表示域名localhost的解析是由本地操作系统(如hosts文件)完成的,而不是通过外部 DNS 服务器。
2. 响应头 (Response Headers)
这是服务器返回给浏览器的信息,用于告诉浏览器如何处理接收到的数据。
-
Access-Control-Allow-Origin : 跨域资源共享 (CORS) 策略 。它指定了哪些网站可以访问该服务器。图中显示
http://localhost:3000被允许,这意味着运行在 3000 端口的前端应用可以合法获取 5000 端口的数据。 -
Connection : 连接状态 。
close表示服务器在发送完响应后将关闭 TCP 连接,不保持长连接。 -
Content-Length : 内容长度。表示返回的数据体(Entity Body)的大小,单位是字节(此处为 507 字节)。
-
Content-Type : 内容类型 。告诉浏览器返回的数据格式。
application/json说明返回的是 JSON 格式的结构化数据。 -
Date : 服务器时间。响应被产生的 GMT 时间。
-
Server : 服务器软件信息 。显示后端使用了
Werkzeug/2.3.7(Python 的 WSGI 工具库)以及Python/3.12.13。 -
Vary : 缓存校验依据 。
Origin告诉浏览器或缓存代理:如果请求的来源不同,即使 URL 一样,缓存的内容也可能不同。
3. 请求头 (Request Headers)
这是浏览器发送给服务器的信息,包含了请求的上下文和期望的返回格式。
-
Accept : 期望接收的类型 。浏览器告诉服务器:"我能理解 JSON、纯文本或者任何格式 (
*/*)"。 -
Accept-Encoding : 支持的压缩格式。浏览器支持 gzip、br 等压缩算法,服务器可以据此压缩数据以节省流量。
-
Accept-Language : 优先语言。浏览器首选中文(zh-CN),但也支持英文。
-
Connection : 连接要求 。
keep-alive请求服务器保持连接,以便后续请求可以复用。 -
Content-Length : 发送内容的长度。表示请求体(例如 POST 发送的数据)的大小为 42 字节。
-
Content-Type : 发送内容的格式 。前端发送给后端的数据是
application/json。 -
Host : 目标主机 。请求指向的目标服务器地址和端口(
localhost:5000)。 -
Origin : 请求来源 。发起请求的页面地址(
http://localhost:3000),常用于服务器的安全检查。 -
Priority : 请求优先级 。
u=0是浏览器内部的调度优先级标识。 -
Referer : 来源引用地址。表示你是从哪个具体的页面发起的请求。
-
Sec-Fetch-... : 安全元数据。
-
Dest: empty: 目标不是图片或脚本,通常是 fetch/XHR 调用。 -
Mode: cors: 这是一个跨域请求。 -
Site: same-site: 请求发生在同站(通常指主域名相同)。
-
-
User-Agent : 客户端标识。包含了浏览器的版本(Firefox/141.0)信息和操作系统信息。
下面是我登录成功后前端浏览器展示的请求、响应数据截图,能获取到哪些信息?
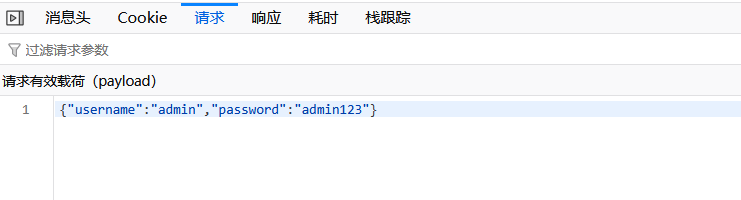
这两张截图展示了一个经典的 用户登录 API 通信。上图是浏览器发给服务器的"请求",下图是服务器给浏览器的"回信"。
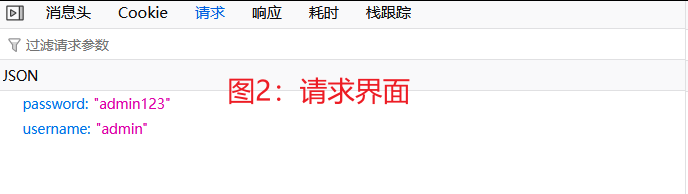
4、请求有效载荷 (Request Payload)
这是前端发往后端的原始数据。
-
格式: JSON 对象。
-
内容 : 包含
username(用户名: admin) 和password(密码: admin133)。 -
意义: 前端告诉后端:"我想用这个账号密码登录,请核对。
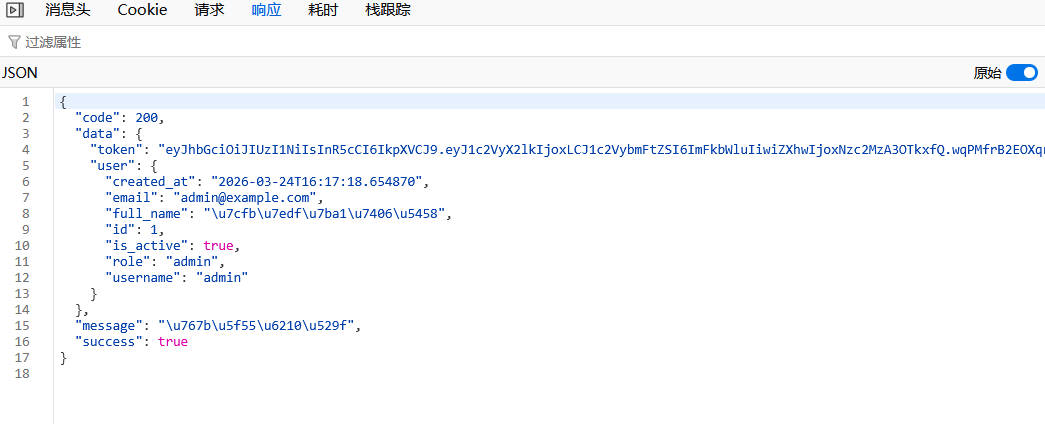
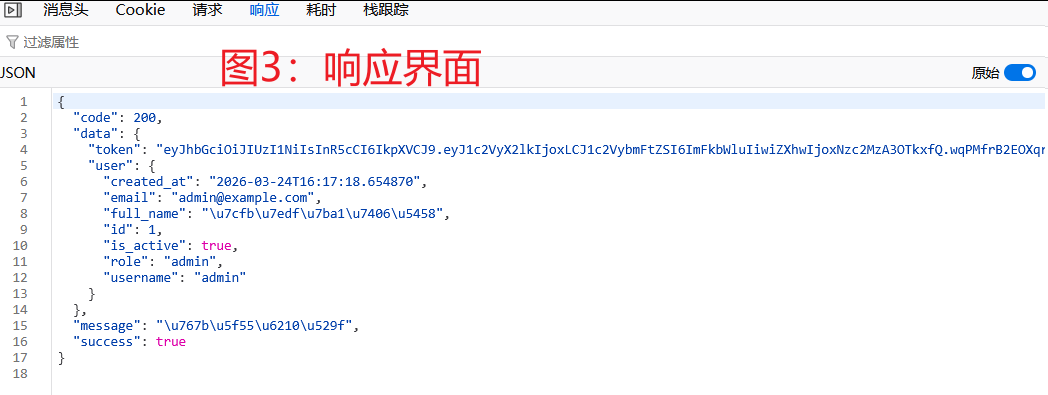
5、响应数据 (Response JSON)
后端核对通过后,返回了详细的信息。我们可以把这个 JSON 结构拆解来看:
1. 状态标识
-
code: 200: 业务状态码。通常 200 表示操作成功。 -
success: true: 一个布尔值,方便前端直接判断登录是否成功。 -
message: 提示信息(图中为 Unicode 编码\u767b\u5f55\u6210\u529f,转码后就是 "登录成功")。
2. 核心凭证 (Token)
-
token: 这一长串乱码(JWT - JSON Web Token)是最重要的部分。-
作用: 登录成功后,服务器给前端发的一张"临时通行证"。
-
后续使用 : 之后你访问需要权限的页面(如查看个人中心、修改资料)时,浏览器会自动在请求头带上这个 Token ,服务器看到它就知道你是
admin且已经登录过了。
-
3. 用户详细信息 (User Data)
这是服务器返回的当前登录用户的个人资料:
-
id: 数据库中的唯一编号(1)。 -
username/full_name: 账号名和真实姓名。 -
email: 关联的邮箱地址。 -
role: 用户权限等级(admin 表示管理员)。 -
is_active: true: 账号状态正常,未被封禁。 -
created_at: 账号创建的时间。
总结:接下来会发生什么?
-
存储 : 前端通常会将这个
token存入浏览器的localStorage或SessionStorage中。 -
跳转 : 前端代码检测到
success: true,会执行页面跳转,带你进入后台管理系统首页。 -
鉴权 : 以后你发起的每一个新请求,都会拿着响应截图中这个
token去跟服务器"打招呼"。
这就是一个完整的"登录握手"过程!你的后端配置很规范,返回了标准的 RESTful 风格的数据结构。
【问题描述】
我的后端项目位置:output_sourcecode\,我在浏览器访问了http://localhost:3000/后,填入账号密码后成功登录了系统并进入到了系统首页,上面3张图是我的消息体、请求、响应的结果信息,现在我有几个疑问请你教会我:
1.我填写好账号密码点击提交后,浏览器成功跳转到系统首页这整个过程前后端都是如何工作的?这个过程中每一步都发生了什么?
2.如果从测试的角度出发,如果出错我应该如何去排查是否是后端的问题?具体要看消息体、请求、响应的什么字段信息?
疑问一:点击提交后到跳转首页,前后端是如何工作的?每一步发生了什么?
整个登录并跳转的过程,可以拆分为以下 5 个核心步骤 :
1. 前端收集数据并发送请求(浏览器 -> 后端)
-
动作 :你在前端( localhost:3000 )的输入框填入账号 admin 和密码 admin123 ,点击"登录"按钮。
-
发生的事情 :前端代码拦截了按钮点击事件,将账号密码打包成 JSON 格式(即你的图2:消息体),然后向后端服务地址 http://localhost:5000/api/auth/login 发起了一个 POST 请求(即你的图1:请求头)。
2. 后端接收并处理请求(后端内部) -
动作 :后端的 Python Web 服务(图1中 Server 显示为 Werkzeug/2.3.7 Python/3.12.13 )接收到了这个请求。
-
发生的事情 :后端代码从请求体中提取出 username 和 password 。接着,它会去数据库中查询有没有叫 admin 的用户,如果有,再比对密码是否正确(通常会比对加密后的哈希值)。
3. 后端生成凭证并返回响应(后端 -> 浏览器) -
动作 :后端验证账号密码完全正确,允许登录。
-
发生的事情 :后端生成一个加密的身份凭证,也就是 Token (图3中的 eyJhb... )。然后,后端将这个 Token、用户信息(邮箱、角色、全名等)以及"登录成功"的提示信息(图3中的 message ),打包成 JSON 格式,附带 HTTP 状态码 200 OK 返回给前端。
4. 前端处理响应并存储凭证(浏览器内部) -
动作 :前端接收到了后端返回的数据(图3)。
-
发生的事情 :前端代码检查发现 code: 200 且 success: true ,知道登录成功了。此时,前端会 把后端发来的 token 保存到浏览器的本地存储中 (通常是 LocalStorage 或 SessionStorage)。这个 Token 非常重要,相当于你的"门禁卡",以后前端请求其他需要登录的接口时,都会自动带上它。
5. 前端执行页面跳转(浏览器内部) -
动作 :前端发现一切顺利,执行页面切换。
-
发生的事情 :前端的路由机制(Router)将页面从 /login 跳转到系统首页(如 /home 或 /dashboard ),渲染出登录后的界面。
疑问二:如果出错,作为测试如何排查是否是后端问题?看哪些字段?
前后端分离的项目中, "甩锅"的界限非常明确:以网络请求(Network)抓包为准 。排查的核心原则是: 前端有没有发对?后端有没有回对?
你可以按照以下顺序排查:
第一步:检查【请求体 (Payload / JSON参数)】(图2)------ 确认前端有没有发对数据?
- 怎么看 : 如果你点击登录报错了,先看这里传给后端的 username 和 password 对不对。
- 判断归属 :
-
- ❌ 如果你明明输入了 admin ,但这里显示为空( username: "" ),或者字段名拼错了(比如写成了 user_name ,但后端要求 username ) 👉 这是前端的 Bug(数据没收集对或没传对) 。
-
- ✅ 如果这里的数据和你输入的一模一样,格式也没问题,说明前端任务完成了,继续往下看。
第二步:检查【请求头 (Headers) 的状态码】(图1)------ 确认后端服务状态
- 怎么看 : 看最上面的 状态 (Status Code) 。
- 判断归属 :
-
- ❌ 500 Internal Server Error : 绝对是后端的 Bug 。说明后端代码在处理逻辑时报错崩溃了(比如空指针、数据库连不上、SQL 写错了)。
-
- ❌ 404 Not Found :通常是前端请求了错误的接口地址(URL 写错了),或者后端根本没写这个接口。
-
- ❌ 405 Method Not Allowed :前端用错了请求方式(比如后端要求 POST,前端用了 GET)。
-
- ❌ 如果是跨域错误(CORS error,通常状态码显示红色或 failed) :一般是后端没有配置跨域允许头(图1中的 Access-Control-Allow-Origin )。这通常也是后端需要配合解决的问题。
第三步:检查【响应体 (Response)】(图3)------ 确认后端业务逻辑对不对
- 怎么看 : 如果 HTTP 状态码是 200 OK,说明网络通信没问题,此时必须看响应体里后端返回的 业务状态码 ( code ) 和 提示信息 ( message ) 。
- 判断归属 :
-
- ❌ 如果你输入了正确的账号密码,但后端返回 code: 400 或 success: false ,并且提示"密码错误"或"用户不存在" 👉 这是后端的 Bug(查询逻辑写错了或加密算法不匹配) 。
-
- ❌ 如果后端提示登录成功,但没有返回 token 字段(图3的 data 里面没有 token) 👉 这是后端的 Bug(漏发了通行证) 。
-
- ✅ 如果后端像图3一样,完美返回了 code: 200 、 token 以及正确的用户信息,但页面 就是没有跳转到首页 ,或者弹出了个奇怪的空白页 👉 这是前端的 Bug(前端没处理好成功的逻辑,或者跳转代码写错了) 。
总结一下测试排查口诀:
-
参数没传、传错、格式错 ------ 找前端。
-
报 500、报跨域、逻辑错、数据丢 ------ 找后端。
-
接口返回全对,但页面没反应、没跳转、展示乱 ------ 找前端。
请求头 (Headers) 的状态码 与 响应体里后端返回的业务状态码 ( code )是一回事吗?
结论是:它们绝对不是一回事!
我们可以用一个很形象的例子来区分它们: 寄快递 。
-
HTTP 状态码(请求头的状态码) = 快递公司的物流状态 (快递是否成功送达你家)。
-
业务状态码(响应体里的 code) = 包裹里面的商品状态 (商品是完好的,还是碎了,或者卖家发错货了)。
一、 HTTP 状态码(HTTP Status Code)
这是由 HTTP 协议标准 规定的,全世界所有的 Web 服务器(如 Nginx, Tomcat, Flask等)和浏览器都认识它。它出现在你截图1的 状态: 200 OK 这里。
1. 它表示什么信息?
它表示 这一次网络通信(HTTP 请求)本身的宏观结果 。
它只关心:你的请求有没有成功到达服务器?服务器有没有成功接收并给出一个答复?
常见的 HTTP 状态码分为 5 大类:
-
2xx (成功) :代表网络请求成功。最常见的是 200 OK 。
-
3xx (重定向) :代表请求的资源换地方了,你需要去新的地址找。
-
4xx (客户端错误) :代表**你(前端/客户端)**可能做错了什么。
-
- 400 Bad Request :你发的参数格式不对,服务器解析不了。
-
- 401 Unauthorized :你没登录(没有 Token),不认识你。
-
- 403 Forbidden :你登录了,但你权限不够,不让你看。
-
- 404 Not Found :你请求的 URL 地址不存在。
- 5xx (服务器错误) :代表**服务器(后端)**出问题了。
-
- 500 Internal Server Error :后端代码报错了(抛异常了,比如空指针、除以0)。
-
- 502 Bad Gateway / 504 Gateway Timeout :后端的网关或代理出问题了。
2. 它有什么用?
-
给浏览器和网络设备看的 :浏览器看到 404 就知道不用等了,看到 500 就知道服务器挂了,看到 302 就会自动帮你跳转页面。
-
用于粗粒度的错误排查 :只要看到 5xx ,测试人员可以直接提 Bug 给后端;看到 404 ,可以直接检查请求 URL。
二、 业务状态码(Business Code / Custom Code)
这是由你们公司的后端开发人员自己定义的 ,通常放在响应体(JSON 数据)的根节点,比如你截图3里的 "code": 200 (有些公司喜欢用 0 代表成功,有些用 10000 代表成功,完全由你们自己定)。
1. 它表示什么信息?
它表示在 网络通信成功(HTTP 状态码是 200)的前提下,具体的业务逻辑执行结果 。
举个例子,登录接口:
-
- 网络通信成功了(HTTP 200 OK)。
-
- 但是,用户输入的密码是错的!
-
- 这个时候,后端该怎么告诉前端"密码错了"呢?这就是业务状态码的工作了。
后端可能会这样定义业务状态码字典(举例):
-
- "code": 200 (或 0 ):业务成功(登录成功)。
-
- "code": 1001 :用户名不存在。
-
- "code": 1002 :密码错误。
-
- "code": 1003 :账号被锁定。
-
- "code": 1004 :验证码错误。
2. 它有什么用?
- 给前端代码看的 :前端代码通过判断这个 code ,来决定给用户弹什么提示框。
-
- if (res.code === 200) -> 跳转到首页。
-
- if (res.code === 1002) -> 弹窗提示"密码错误,请重试"。
- 精细化的业务错误排查 :测试人员看到 HTTP 200,说明接口通了,但看到业务 code: 1002 ,就知道是测试数据(密码)给错了,而不是系统有 Bug。
三、 总结:它们是如何协作的?
在实际开发中,最标准的协作流程是这样的:
-
第一层过滤(HTTP 状态码) :前端发起请求,如果遇到 404 或 500 ,前端的底层网络库(如 Axios)会直接抛出异常,提示"网络错误或服务器异常",此时根本不会去解析里面的 JSON。
-
第二层处理(业务状态码) :如果 HTTP 状态码是 200 ,说明包裹安全送达。前端打开包裹(解析 JSON),读取里面的 code 。
-
如果是你们约定的成功码(如 200 ),则提取 data 里的数据并展示。
-
如果是其他错误码(如 1002 ),则提取 message 里的错误信息展示给用户。
注意: 在你的截图3中,后端恰好把业务成功码也定义成了 200 ( "code": 200 )。这在很多项目中很常见,但这只是一个"巧合",它和外面那个绿色的 HTTP 200 OK 是两码事。如果密码错了,外面依然是绿色的 HTTP 200 OK ,但里面的 JSON 会变成 {"code": 401, "message": "密码错误"}
【这是一个Delete请求的案例】
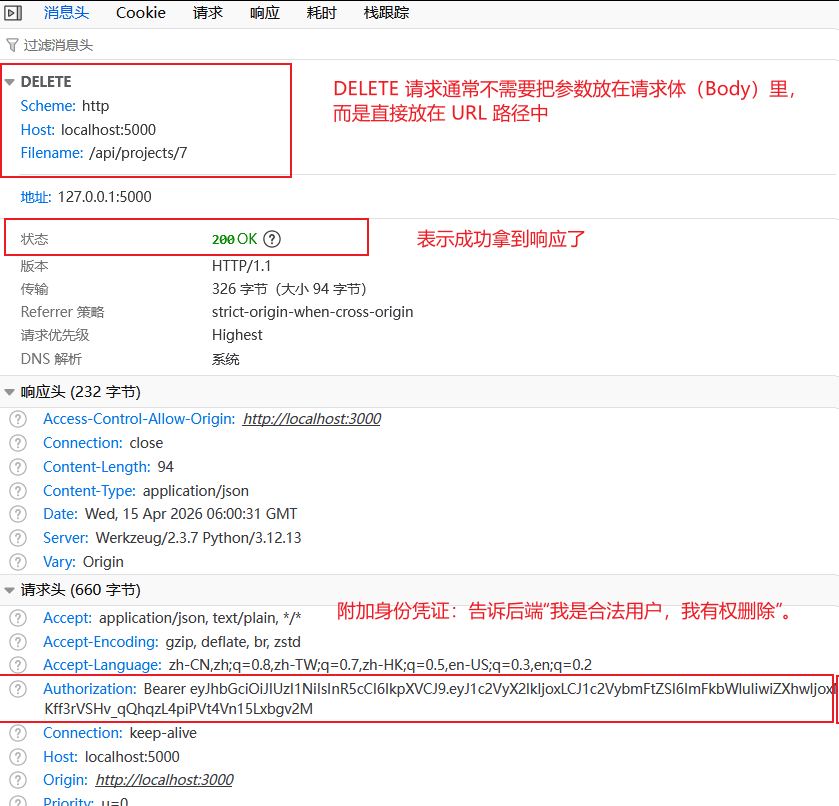
阶段一:前端发起删除请求
1. 用户触发操作 :你在浏览器 (`localhost:3000/projects`) 的项目列表中,点击了某个项目的"删除"按钮,并可能在弹出的确认框中点击了"确定"。
2. 前端构造请求:
- **确定目标资源:**前端知道你要删除的是 ID 为 `7` 的项目,因此将请求的 URL 拼接为 `/api/projects/7`(见图1中的 Filename)。
- 选择 HTTP 方法:按照 RESTful 规范,删除资源使用 `DELETE` 方法(见图1最上方的 `DELETE` 标识)。与之前登录时的 `POST` 不同,`DELETE` 请求通常不需要把参数放在请求体(Body)里,而是直接放在 URL 路径中。
- 附加身份凭证: 这是一个需要登录才能操作的接口。前端代码从本地存储(LocalStorage)中取出之前登录成功时获取的 Token,放入了请求头中:`Authorization: Bearer eyJhb...`(见图1的"请求头"部分)。**这是非常关键的一步,告诉后端"我是合法用户,我有权删除"。**
**3. 发送网络请求:**浏览器将这个 `DELETE` 请求通过网络发送给后端服务 (`localhost:5000`)。
阶段二:后端处理删除请求
1. 接收并路由请求 :后端的 Web 框架(这里是 Python 的 Werkzeug/Flask)接收到请求,根据 URL `/api/projects/7` 和方法 `DELETE`,将请求交给对应的"删除项目"的控制器函数来处理。
2. 身份与权限校验:
- 后端首先解析请求头中的 `Authorization: Bearer Token`。
- 验证这个 Token 是否有效、是否过期,从而确认是谁发起的请求(比如解析出是 `admin` 用户)。
- (可选)后端可能还会进一步检查:这个用户有没有权限删除 ID 为 `7` 的项目?
3.执行业务逻辑(操作数据库):
- 校验通过后,后端连接数据库。
- 执行类似 `DELETE FROM projects WHERE id = 7` 的 SQL 语句(或者将该项目的状态标记为"已删除",即软删除)。
4. 构造并返回响应:
- 数据库操作成功后,后端构造响应结果。
- 状态码设为 `200 OK`(见图1的"状态")。
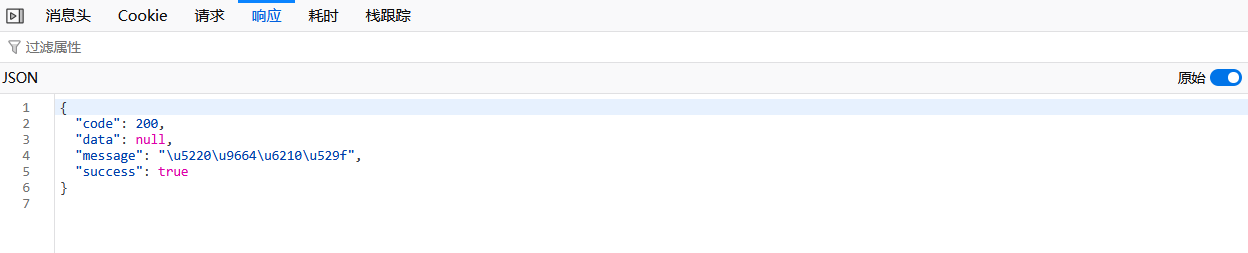
- 响应体(JSON)构造为:`{"code": 200, "data": null, "message": "删除成功", "success": true}`(见图2)。对于删除操作,通常不需要返回具体的数据,所以 `data` 是 `null`,重点是告诉前端 `success: true`。
- 将响应发送回浏览器。
阶段三:前端接收响应并更新页面
1. 前端接收并解析响应 :浏览器的网络层接收到了后端返回的 HTTP 200 响应和 JSON 数据。前端的网络请求库(如 Axios)将其解析出来。
2. 判断业务结果 :前端代码判断响应体中的 `success == true` 或者 `code == 200`,确认后端确实已经把数据删掉了。
3. 提示用户 :前端调用组件(如 Element Plus 的 ElMessage),在页面右上角弹出一个绿色的提示框:"删除成功"(这个文字通常就是读取的响应体中的 `message` 字段,你图2中 unicode 编码 `\u5220\u9664\u6210\u529f` 解码后就是"删除成功")。
4. 更新页面视图(最关键的一步) :
为了让用户在页面上看到项目真的没了,前端通常有两种做法来更新表格:
- 做法 A(重新请求,最常见):前端再次向后端发送一个 `GET /api/projects` 的请求,获取最新的项目列表数据,然后用新数据重新渲染表格。因为项目 7 已经在数据库被删了,所以新的列表里自然就没有它了。
- 做法 B(前端本地剔除):为了节省网络请求,前端直接在本地维护的项目列表数组(Array)中,找到 ID 为 7 的那个对象并将其剔除(比如使用 `array.filter(item => item.id !== 7)`),Vue/React 这样的框架监听到数据变化,会自动将表格中对应的那一行移除。
这就是一个标准的 `DELETE` 操作的全生命周期!你可以看到,前后端各司其职,通过 HTTP 协议和 JSON 数据完成了完美的配合,最终给用户呈现了流畅的操作体验。
【这是一个Post请求+新增用户案例】
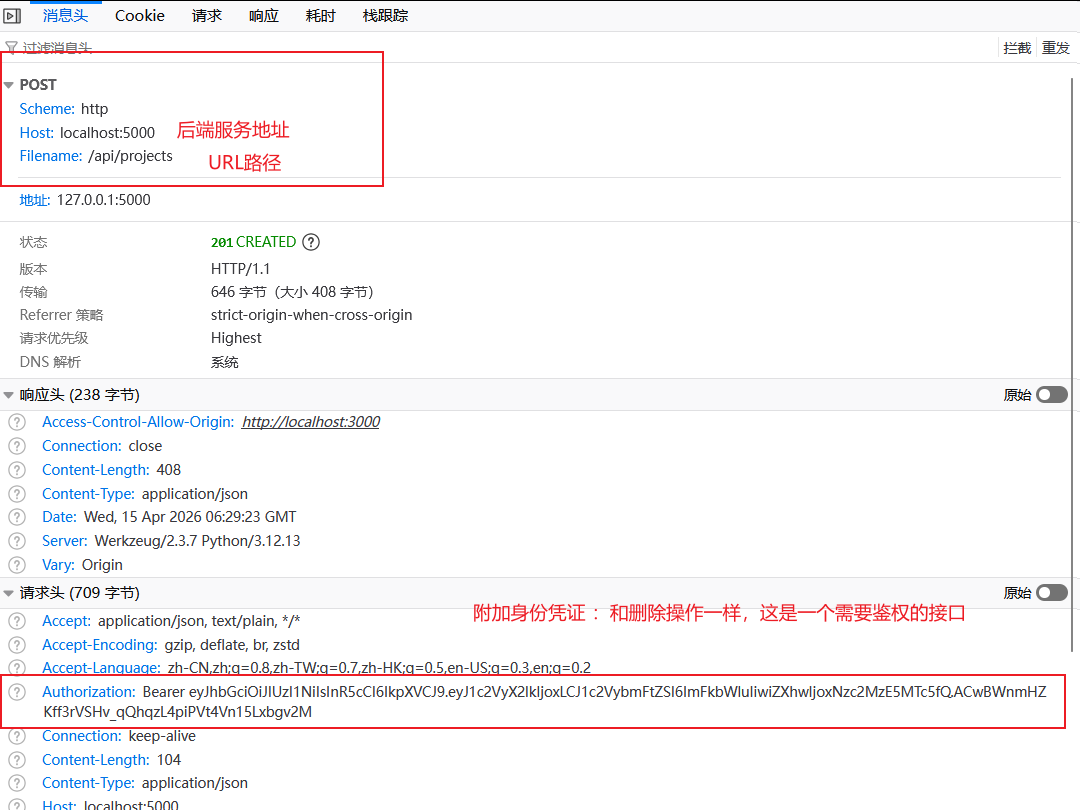
这是一个标准的 RESTful API `POST` 操作,也就是"创建资源"的过程。通过这三个请求(登录 POST、删除 DELETE、新增 POST),你基本已经把接口测试最核心的增删改查(CRUD)逻辑看透了。
让我们像之前一样,把从点击新增按钮到页面更新的过程拆解开来:
阶段一:前端发起新增请求
1. 用户触发操作:
你在浏览器 (`localhost:3000/projects`) 点击了"新增项目"按钮。
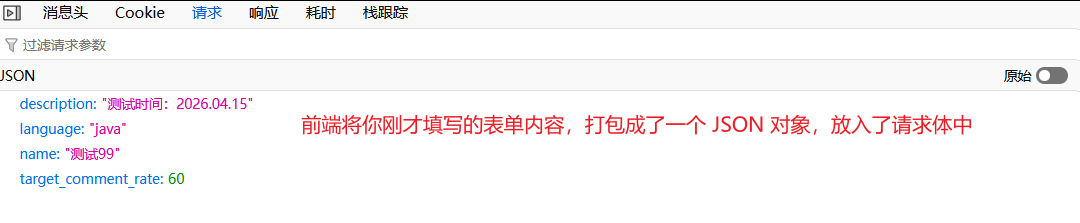
页面弹出了一个表单,你在表单中填写了项目的各种信息:
- 项目名称:`测试99`
- 编程语言:`java`
- 目标注释率:`60`
- 描述信息:`测试时间:2026.04.15`
填写完毕后,你点击了表单的"提交"或"保存"按钮。
2. 前端构造请求:
- 确定目标资源与方法:按照 RESTful 规范,向一个集合中添加新元素,使用的是 `POST` 方法,URL 指向该集合的根路径,即 `/api/projects`(见图1中的 Filename 和最上方的 POST)。
- 打包数据(Payload):前端将你刚才填写的表单内容,打包成了一个 JSON 对象,放入了**请求体**中(见图2)。这就是你要发送给后端的具体"货物"。
- 附加身份凭证:和删除操作一样,这是一个需要鉴权的接口。前端从本地读取 Token,放在了请求头的 `Authorization` 字段中(见图1),告诉后端是谁在尝试创建这个项目。
**3. 发送网络请求:**浏览器将携带 JSON 数据的 `POST` 请求发送给后端服务 (`localhost:5000`)。
阶段二:后端处理新增请求
1. 接收并路由请求: 后端 Web 框架接收到请求,看到是 `POST /api/projects`,便将其路由给对应的"创建项目"控制器。
2. 身份校验与参数验证:
- 后端首先验证你的 Token,确认你是合法用户。
- 后端接着会**校验你传过来的 JSON 数据(图2)**。它会检查:必填项 `name` 有没有填?`target_comment_rate` 是不是数字?`language` 的值在不在允许的列表(如 java, python, c++ 等)里?这一步非常关键,是保证数据库数据质量的第一道防线。
3. 执行业务逻辑(操作数据库):
- 校验通过后,后端连接数据库。
- 后端执行 `INSERT` SQL 语句,将你提供的数据(`测试99`, `java`, `60` 等)写入到 `projects` 表中。
- 在插入数据库时,数据库会自动为这个新项目生成一个唯一的 ID(这里生成的是 `8`),并且后端通常会自动补充一些字段,比如创建时间 `created_at`、项目拥有者 `owner_id`(从你的 Token 中解析出来的用户 ID)、默认状态 `status`(如 active)。
4. 构造并返回响应:
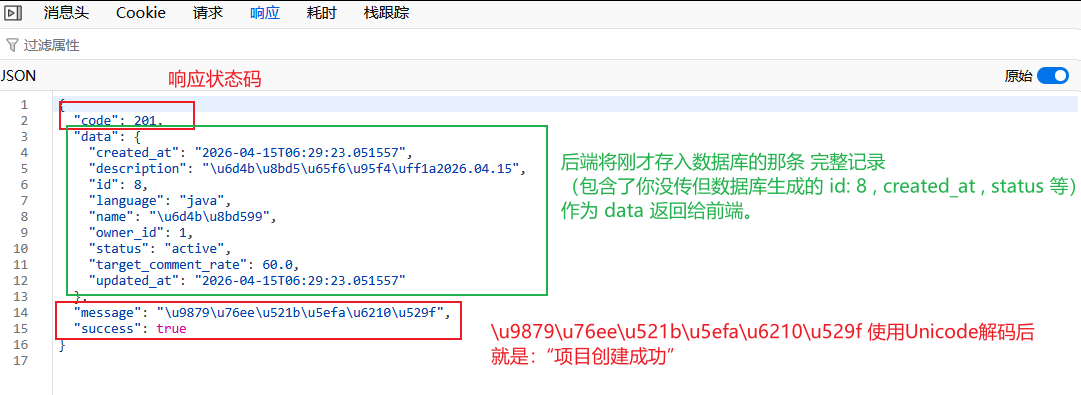
- 数据库插入成功后,后端构造响应结果(见图3)。
- 注意看状态码:这里返回的是 `201 CREATED`(图1状态)。这是一个非常标准的 HTTP 状态码,专门用来表示"你的 POST 请求成功了,并且服务器已经为你创建了一个新的资源"。
- 响应体(图3):后端将刚才存入数据库的那条**完整记录**(包含了你没传但数据库生成的 `id: 8`, `created_at`, `status` 等)作为 `data` 返回给前端。这很有用,因为前端马上就需要这个新生成的 ID!
阶段三:前端接收响应并更新页面
1. 前端接收并解析响应:前端接收到 `201 CREATED` 和图3的 JSON 数据。
2. 判断业务结果:前端判断 `code === 201` (或 `success === true`),确认项目创建成功。
**3. 提示用户:**前端弹出一个绿色提示框:"项目创建成功"(图3 message 字段 `\u9879\u76ee\u521b\u5efa\u6210\u529f` 的解码)。
4. 更新页面视图:
同样,前端有两种方式让这个新项目出现在表格中:
- 做法 A(重新请求列表):前端再次发送 `GET /api/projects`,获取包含这个新项目的最新列表,重新渲染表格。
- 做法 B(前端本地追加):为了提升性能,前端直接把刚才后端返回的那个完整对象(图3的 `data` 部分,里面包含了关键的 `id: 8`),`push` 到前端本地维护的项目列表数组中。Vue/React 会监听到数组变化,自动在表格最后面追加一行显示这个新项目。
- 关闭表单弹窗:最后,前端代码会将之前填写的那个"新增项目"弹窗关闭,并将表单内容清空,为下一次操作做准备。
通过这两个例子的对比,你是否发现接口测试的规律了?**不管是增删改查,其实都是在玩转"方法(Method) + 路径(URL) + 凭证(Headers) + 数据(Body) + 结果(Response)"这五个要素。**
基于我的项目而言,对于我的项目中http://localhost:3000/projects页面又新增了一个项目这个操作而言,**后端校验前端传过来的 JSON 数据格式内容、与后端处理完后响应的data数据的具体的json格式内容在哪里看?对应的前后端代码在哪写着呢?**
这是一个深入到代码本质的好问题!在真正的开发中,前后端之所以能配合得天衣无缝,正是因为它们"遵守了共同的契约"。
下面我结合你的实际代码,带你看看这个 JSON 格式是怎么被定下来的,以及在哪里可以看到具体的代码实现:
1. 前端传过来的 JSON 格式是怎么确定的?
前端发出的 JSON 数据结构(如你截图里的 name , language , target_comment_rate 等),是根据**后端的 API 接口文档(或后端代码要求)**来构建的。
在你的项目中,我们可以直接看后端接收请求的代码:后端控制器代码 : project_api.py
output_sourcecode/backend/app/api/project_api.py
python
@bp.route('', methods=['POST'])
@token_required
def create_project(current_user):
"""
创建项目
请求体:{"name": "string", "description": "string", "language": "string", "target_comment_rate": float}
"""
data = request.get_json() # 这里获取了前端传来的 JSON
if not data or not data.get('name'):
return error_response('项目名称不能为空', 400)
# 从 data 字典中提取对应的字段,用来创建数据库对象
project = Project(
name=data['name'],
description=data.get('description', ''),
owner_id=current_user.id,
language=data.get('language', 'python'),
target_comment_rate=data.get('target_comment_rate', 70.0)
)**解释 :**后端代码里写得很清楚,它期望 data 这个字典里包含 name 字段,并且会尝试去取 description 、 language 和 target_comment_rate 。如果前端传了别的乱七八糟的字段(比如传了个 abc: 123 ),后端在这里根本不去读取它,直接丢弃。
与之对应的, 前端发送请求的代码 在这里:前端表单提交代码 : index.vue
output_sourcecode/frontend/src/views/projects/index.vue
python
// 提交表单
const submitForm = async () => {
// ... 前置校验略 ...
// 这里就是前端按照后端的"契约"组装出来的 JSON 结构!
const data = {
name: projectForm.name,
description: projectForm.description,
language: projectForm.language,
target_comment_rate: projectForm.targetRate
}
// 发送 POST 请求
response = await api.createProject(data)2. 后端响应的 data 里的 JSON 格式在哪看?
当你截图里看到 201 CREATED ,并且返回了一长串 JSON 数据(包含 id , created_at , status 等)时,这个返回格式是在后端的"模型(Model)类" 中定义的。
在 Python 的 Flask/SQLAlchemy 架构中,通常会给数据库模型写一个 to_dict() 方法,用来把数据库里的"一行数据"翻译成前端能看懂的"JSON 字典"。
我们来看看你后端的项目模型代码: 后端模型与序列化代码 : project.py
output_sourcecode/backend/app/models/project.py
python
class Project(db.Model):
# ... 前面是数据库字段定义,如 id, name, created_at 等 ...
def to_dict(self):
"""转换为字典(这就是最终返回给前端的 JSON 格式!)"""
return {
'id': self.id,
'name': self.name,
'description': self.description,
'owner_id': self.owner_id,
'language': self.language,
'target_comment_rate': self.target_comment_rate,
'status': self.status,
'created_at': self.created_at.isoformat() if self.created_at else None,
'updated_at': self.updated_at.isoformat() if self.updated_at else None
}结合第一步中的 project_api.py 代码
output_sourcecode/backend/app/api/project_api.py
python
# 最后一句代码
return success_response(project.to_dict(), '项目创建成功', 201)**解释 :**后端在插入数据库成功后,调用了刚才看到的 project.to_dict() ,这就完美解释了为什么你抓包看到的响应 JSON(图3)里,会有那么多你没有填写的字段------因为这个 to_dict() 方法把整个项目的完整画像都输出了。
总结
1. 输入(Request Payload)由谁定 :通常是后端定标准(比如通过 Swagger/Apifox 接口文档),前端通过 JS 对象( const data = {...} )去迎合这个标准。
2. 输出(Response Data)在哪看 :通常在后端的实体类(Model/Entity)的序列化方法(如 to_dict() 、 toJSON() 或 DTO 对象)中写死了返回的字段。
作为测试人员,你以后看到任何抓包的数据,都可以去后端代码里找对应的 @bp.route (路由)和 to_dict() (模型),就能把代码逻辑和抓包现象完美对应起来了!
附录:我的API 接口文档
1. 概述
本文档详细描述了"基于正则语义分析的 Python 轻量级代码注释率自动化审计系统"的后端 API 接口规范。前后端数据交互遵循 RESTful API 设计风格。
1.1 基础信息
-
基础 URL (Base URL) :
http://localhost:5000/api -
数据格式 : 请求和响应的 Content-Type 默认均为
application/json(文件上传接口除外)。 -
编码格式 :
UTF-8
1.2 全局响应格式 (Response Format)
为了方便前端统一处理,所有 API 的成功或错误响应都会被包裹在一个标准的 JSON 结构中:
python
{
"success": true, // 业务是否执行成功 (true/false)
"code": 200, // 业务状态码 (与 HTTP 状态码通常保持一致)
"message": "操作成功", // 提示信息 (用于前端直接弹窗展示)
"data": { ... } // 实际的业务数据 (对象、数组或 null)
}1.3 鉴权机制 (Authentication)
系统使用 JWT (JSON Web Token) 进行无状态鉴权。 除登录 (/auth/login) 和注册 (/auth/register) 外,其余所有接口均需要在 HTTP 请求头 (Headers) 中携带 Token:
python
Authorization: Bearer <你的_JWT_Token>2. 认证模块 (Auth API)
2.1 用户注册
-
接口路径 :
/auth/register -
请求方式 :
POST -
说明: 注册一个新用户账号。
-
请求参数 (Body):
python{ "username": "test_user", "email": "test@example.com", "password": "Password123", "full_name": "测试用户" // 可选 } -
响应示例:
python{ "success": true, "code": 201, "message": "注册成功", "data": { "user_id": 1, "username": "test_user" } }
2.2 用户登录
-
接口路径 :
/auth/login -
请求方式 :
POST -
说明: 验证用户名和密码,返回 JWT Token。
-
请求参数 (Body):
python{ "username": "test_user", "password": "Password123" } -
响应示例:
python{ "success": true, "code": 200, "message": "登录成功", "data": { "token": "eyJhbGciOiJIUzI1NiIs...", "user": { "id": 1, "username": "test_user", "email": "test@example.com", "role": "admin" } } }
2.3 获取当前用户信息
-
接口路径 :
/auth/profile -
请求方式 :
GET -
鉴权: 需要 Token
-
响应示例: 返回当前登录用户的完整信息。
3. 项目管理模块 (Project API)
3.1 创建项目
-
接口路径 :
/projects -
请求方式 :
POST -
鉴权: 需要 Token
-
请求参数 (Body):
python{ "name": "电商系统核心模块", "description": "包含订单和支付相关代码", "language": "python", "target_comment_rate": 60.0 } -
响应示例:
python{ "success": true, "code": 201, "message": "项目创建成功", "data": { "id": 8, "name": "电商系统核心模块", "description": "包含订单和支付相关代码", "language": "python", "target_comment_rate": 60.0, "status": "active", "created_at": "2026-04-15T06:29:23.051557" } }
3.2 获取项目列表 (分页)
-
接口路径 :
/projects -
请求方式 :
GET -
鉴权: 需要 Token
-
查询参数 (Query):
-
page: 当前页码,默认 1 -
page_size: 每页条数,默认 20 -
status: 项目状态过滤 (active/completed/archived)
-
-
响应示例:
python{ "success": true, "code": 200, "message": "获取成功", "data": { "items": [ { "id": 8, "name": "电商系统核心模块", "status": "active" } ], "total": 1, "page": 1, "page_size": 20, "total_pages": 1 } }
3.3 删除项目 (软删除)
-
接口路径 :
/projects/<project_id> -
请求方式 :
DELETE -
鉴权: 需要 Token
-
请求参数: 无 (目标资源ID放在 URL 中)
-
响应示例:
python{ "success": true, "code": 200, "message": "删除成功", "data": null }
3.4 修改项目信息
-
接口路径 :
/projects/<project_id> -
请求方式 :
PUT -
鉴权: 需要 Token
-
请求参数 (Body): 传入需要修改的字段即可 (如 name, description, status 等)
-
响应示例: 返回修改后的项目信息对象。