字节对编码(BPE)令牌化器
Unicode标准
Unicode是一种文本编码标准,它将字符映射到整数代码点。(2024年9月发布),该标准在168个脚本中定义了154,998个字符。(通常表示为U+0073,其中U+是常规前缀,0073是十六进制的115),字符""的代码点为29275。在Python中,你可以使用ord()函数将单个Unicode字符转换为它的整数表示。chr()函数将整数Unicode码位转换为具有相应字符的字符串。
bash
print(ord('牛'))
print(chr(29275))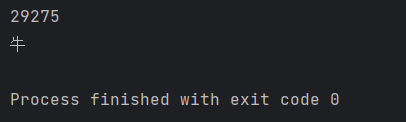
Problem (unicode1): Understanding Unicode (1 point)
- chr(0)返回什么Unicode字符?

- 此字符的字符串表示(repr ())与其打印表示有何不同?
在 Python 中,__repr__()返回的是对象的"官方"字符串表示,通常包含引号且尽量精确,以便能够通过eval()重新创建该对象;而__str__()返回的是"非正式"的可读表示,用于打印输出。对于单个字符(如'a'),__repr__()的结果是"'a'"(带外层引号),而__str__()的结果是'a'(无引号)。因此,打印时(调用print())实际使用的是__str__(),输出不带引号;而在交互式环境中直接显示对象时,调用的是__repr__(),输出带引号。 - 当这个字符出现在文本中时会发生什么?在你的Python解释器中尝试以下内容可能会有所帮助,看看它是否符合你的期望:
python
print(chr(0))
print("this is a test" + chr(0) + "string")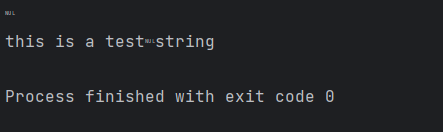
Unicode编码
虽然 Unicode 标准定义了从字符到码点(整数)的映射,但直接在 Unicode 码点上训练分词器(tokenizer)是不现实的,因为词汇表会过大(约 15 万个词条)且稀疏(许多字符非常罕见)。因此,我们转而使用一种 Unicode 编码方式,将每个 Unicode 字符转换为一个字节序列。Unicode 标准本身定义了三种编码:UTF-8、UTF-16 和 UTF-32,其中 UTF-8 是互联网上占主导地位的编码(超过 98% 的网页使用它)。
要在 Python 中将一个 Unicode 字符串编码为 UTF-8,可以使用 encode() 函数。要访问 Python 字节对象(bytes)的底层字节值,可以对其进行迭代(例如调用 list())。最后,可以使用 decode() 函数将 UTF-8 字节串解码回 Unicode 字符串。
python
test_string = "hello! こんにちは!"
utf8_encoded = test_string.encode("utf-8")
print(utf8_encoded)
print(type(utf8_encoded))
# Get the byte values for the encoded string (integers from 0 to 255).
print(list(utf8_encoded))
# One byte does not necessarily correspond to one Unicode character!
print(len(test_string))
print(len(utf8_encoded))
print(utf8_encoded.decode("utf-8"))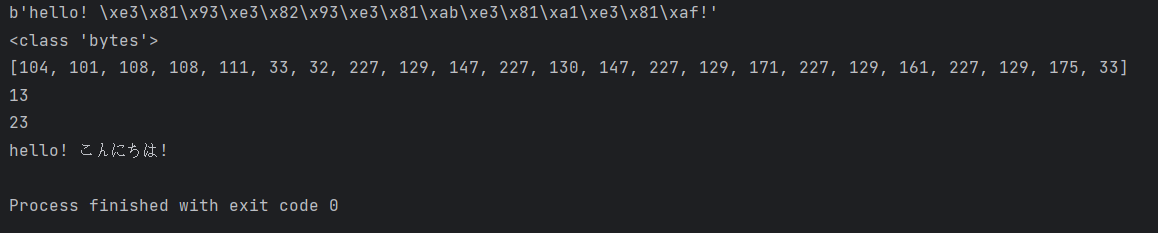
通过将 Unicode 码点转换为字节序列(例如通过 UTF-8 编码),我们实际上是把一个码点序列(取值范围为 0 到 154,997 的整数)转换为一个字节值序列(取值范围为 0 到 255 的整数)。这样,长度为 256 的字节词汇表处理起来就方便得多。当使用字节级的分词(tokenization)时,我们不需要担心出现词汇表外的词元(out-of-vocabulary tokens),因为任何输入文本都可以表示为 0 到 255 的整数序列。
- 为什么我们更喜欢在UTF-8编码的字节上训练我们的分词器,而不是UTF-16或UTF-32?
在训练现代大语言模型的分词器(尤其是字节级 BPE 或类似算法)时,选用 UTF-8 编码的字节流作为底层表示,而非 UTF‑16 或 UTF‑32,主要源于以下几个核心原因:
空间效率与序列长度
- UTF‑8 是变长编码 :ASCII 范围内的字符(英文、数字、标点)只占 1 字节,拉丁扩展、希腊、西里尔字母占 2 字节,常见中文占 3 字节,罕见字符占 4 字节。
- UTF‑16 至少占 2 字节 :英文文本会凭空多出一倍的空字节(如
A在 UTF‑16 中是0x41 0x00),导致字节序列长度翻倍。 - UTF‑32 固定占 4 字节:任何字符都浪费 3 倍以上的空间。
结果:对于互联网上占绝对优势的英文代码和自然语言文本,UTF‑8 的字节序列最短。字节级分词器直接在字节流上做合并,序列越短,计算开销越小,词汇表达到同等覆盖率所需的合并步数也更少。
-
避免"空字节陷阱"与词汇表污染
在 UTF‑16 字节流中,大量的
0x00字节会成为高频出现的独立符号,字节级 BPE 会将0x00与相邻字节(如0x41)频繁合并,形成(0x41, 0x00)这样的固定对。这不仅无意义地占用了词汇表容量,还迫使模型学习两种字节序(大端/小端)的差异。UTF‑8 的字节序列几乎不含
0x00(除非处理真正的空字符),且其 自同步前缀特性 使得字节流天然保留字符边界信息------你永远可以通过前几个高位 1 的数量判断当前字节是一个字符的开始还是延续。这为分词器合并规则提供了隐式的正则引导。 -
跨语言通用性与标准化
UTF‑8 是 Web 的事实标准 (超过 98% 的网页使用UTF‑8)。训练数据绝大多数原本就以 UTF‑8 存储。直接在原始 UTF‑8 字节上训练,绕过了将 UTF‑8 转为 UTF‑16 的预处理环节 ,既简化了数据管道,又避免了因转换产生的 BOM(字节顺序标记)或代理对错误。
UTF‑16 虽然在操作系统内核(Windows NT 内核、Java 早期内部字符串)中常见,但那是对内存中的字符处理而言。在存储和网络传输的字节流层面,UTF‑8 的紧凑性具有压倒性优势。
-
词汇覆盖率与未知字符处理
字节级分词的一个核心目标是 彻底消灭
<UNK>(未知词符) 。无论输入多么奇怪或错误的字节序列,模型都能逐字节处理。UTF‑8 是穷举且自愈的 :即使遇到部分损坏的 UTF‑8 序列(比如被截断的多字节字符),解码器也能识别出"无效字节"并替换为替换字符(�),但在字节级分词器眼中,它只是几个连续的、有特定值的普通字节,模型可以从上下文学会忽略或纠正它。 -
UTF‑16 如果遇到孤立的代理对(Surrogate Pair)或者奇数个字节的截断,处理起来会更加棘手,且极易产生不可打印的控制字符字节序列。
-
计算效率的实证
以 LLaMA、GPT‑2、Gemma 等主流模型为例,它们的 词汇表大小通常为 32k 至 256k。如果用 UTF‑16 字节流训练:
-
英文文本的序列长度翻倍,导致训练时的注意力矩阵计算量呈平方级增加。
-
要达到同样的文本压缩率,需要更大的词汇表(因为多出了大量无意义的
0x00组合需要被吸收进词符中)。
总结对比表
| 特性 | UTF‑8 (所选) | UTF‑16 | UTF‑32 |
|---|---|---|---|
| 英文文本字节长度 | 1 字节/字 | 2 字节/字 | 4 字节/字 |
| 有无冗余空字节 | 极少 | 大量 0x00 |
大量 0x00 |
| 词汇表利用效率 | 高(合并真实语义边界) | 低(浪费容量合并 0x00) |
极低 |
| 字符边界自同步 | 是(高位前缀规则) | 需处理代理对 | 固定长度 |
| 与 Web 数据兼容性 | 无缝衔接 | 需要重编码 | 需要重编码 |
结论 :UTF‑8 在字节级分词中实现了 最小序列长度、最低计算开销、最自然的语义边界对齐 三者之间的最优平衡。选择它并不是因为 UTF‑16 或 UTF‑32 "不能工作",而是因为它们会带来不必要的算力浪费和词汇表熵增。
子字标记化
尽管字节级分词能够缓解词级分词器面临的外词表问题,但将文本切分为字节会导致输入序列过长。这会拖慢模型训练速度------比如,一个包含 10 个单词的句子在词级语言模型中可能只需 10 个词符,而在字符级模型中可能长达 50 个甚至更多词符(取决于单词长度)。处理这些更长的序列需要在模型的每一步中投入更多计算。此外,在字节序列上进行语言建模难度更大,因为更长的输入序列会在数据中引入长程依赖。
子词分词是词级分词器与字节级分词器之间的折中方案。注意,字节级分词器的词表仅有 256 个条目(字节值从 0 到 255)。子词分词器通过扩大词表规模来换取对输入字节序列更优的压缩效果。例如,若字节序列 b'the' 在我们的原始文本训练数据中频繁出现,将其纳入词表就能把原本 3 个词符的序列缩减为单个词符。
那么,如何挑选要加入词表的子词单元呢?Sennrich 等人 2016 提出使用字节对编码(BPE;Gage, 1994)------一种通过反复将最频繁出现的字节对替换("合并")为一个全新未用索引的压缩算法。注意,该算法向词表中添加子词词符的目的,在于最大化输入序列的压缩率------若某个单词在输入文本中出现次数足够多,它最终就会被表示为一个独立的子词单元。
通过 BPE 构建词表的子词分词器通常被称为 BPE 分词器。在本作业中,我们将实现一个字节级 BPE 分词器,其词表条目为单个字节或经过合并的字节序列。这使得我们在处理集外词与管理输入序列长度两方面兼得其利。构建 BPE 分词器词表的过程,即称为"训练"BPE 分词器。
BPE Tokenizer Training
词表初始化
分词器的词表是字节串词符到整数 ID 的一一映射。由于我们训练的是字节级 BPE 分词器,初始词表就是所有字节的集合。因为字节的可能取值共有 256 种(0 到 255),初始词表的大小即为 256。
预分词
有了词表之后,原则上你可以统计文本中各字节对相邻出现的频率,并从最高频的字节对开始进行合并。然而,这种做法的计算开销相当大------因为每次合并后,我们都必须重新完整扫描一遍语料库。此外,直接在语料库上合并字节还可能产生仅在标点符号上有所区别的词符(例如 dog! 与 dog.)。尽管这些词符语义上高度相似(仅末尾标点不同),它们却会被分配完全不同的词符 ID。
为避免上述问题,我们会对语料库进行预分词 。可以将其理解为对语料库的一种粗粒度分词,帮助我们更高效地统计字符对的出现次数。例如,单词 'text' 可能是一个出现了 10 次的预分词单元。此时,当我们统计字符 't' 与 'e' 相邻出现的频率时,只需知道单词 'text' 中存在这一相邻对,即可将其计数值加 10,而无需遍历整个语料库。由于我们训练的是字节级 BPE 模型,每个预分词单元都表示为一段 UTF-8 字节序列。Sennrich 等人 2016 的原始 BPE 实现采用简单的按空白符切分作为预分词方式(即 s.split(" "))。而我们则采用基于正则表达式的预分词器(由 GPT-2 使用;Radford 等人,2019),其实现见 github.com/openai/tiktoken/pull/234/files:
使用这个pre-tokenizer交互式地分割一些文本可能会很有用,以更好地了解其行为:
python
import regex as re
PAT = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
print(re.findall(PAT, "some text that i'll pre-tokenize"))
在代码中使用时,建议改用 re.finditer,以便在构建从预分词单元到其频次的映射过程中,避免将预分词后的单词全部存储于内存。
计算 BPE 合并
至此,我们已将输入文本转换为预分词单元,并将每个预分词单元表示为一个 UTF-8 字节序列,现在可以开始计算 BPE 合并操作了(即训练 BPE 分词器)。
从高层次来看,BPE 算法会反复统计每一对相邻字节的出现频次,并找出频次最高的字节对(如 ("A", "B"))。随后,该最高频字节对 ("A", "B") 的每一次出现都会被合并 ------即替换为一个新的词符 "AB"。这个新合并的词符会被加入词表;因此,BPE 训练完成后的最终词表大小 = 初始词表大小(本例中为 256)+ 训练过程中执行的 BPE 合并操作次数。出于效率考虑,在 BPE 训练期间,我们不考虑跨越预分词单元边界的字节对 ²。在计算合并时,若出现频次相同的平局情况,则按字典序较大的字节对优先 的规则确定性地打破平局。例如,若字节对 ("A", "B")、("A", "C")、("B", "ZZ") 与 ("BA", "A") 均为最高频,我们将合并 ("BA", "A"):
python
print(max([("A", "B"), ("A", "C"), ("B", "ZZ"), ("BA", "A")]))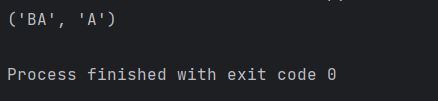
特殊词符
某些字符串(例如 <|endoftext|>)通常被用于编码元数据(如文档之间的边界)。在对文本进行编码时,我们往往希望将特定字符串视为"特殊词符",使其永远不会被切分成多个词符 (即始终作为一个整体词符保留)。例如,序列结束标记 <|endoftext|> 应当始终作为单个词符(即对应单一的整数 ID)保留,这样我们才能知道何时停止从语言模型继续生成内容。这些特殊词符必须添加到词表中,以获取固定的对应词符 ID。Sennrich 等人 2016 论文中的算法 1 给出了一种低效的 BPE 分词器训练实现(大致遵循上述步骤)。作为初步练习,不妨先实现并测试该函数,以检验自己的理解是否到位。
BPE训练示例
以下为 Sennrich 等人 2016 给出的一个典型示例。假设语料库包含如下文本:
low low low low low
lower lower widest widest widest
newest newest newest newest newest newest并且词表中含有一个特殊词符 <|endoftext|>。
词表初始化
我们用特殊词符 <|endoftext|> 以及全部 256 个字节值来初始化词表。
预分词
为简化起见并专注于合并过程,本例中假设预分词仅按空白符切分。经过预分词与计数后,得到如下频率表:
{low: 5, lower: 2, widest: 3, newest: 6}将其表示为 dict[tuple[bytes], int] 形式会更为方便,例如 {(l,o,w): 5 ...}。注意,在 Python 中单个字节同样是 bytes 对象。Python 中不存在专门表示单字节的 byte 类型,正如不存在专门表示单个字符的 char 类型一样。
合并过程
首先,我们考察每一对相邻字节,并将它们在各单词中出现的频率求和,得到:
{lo: 7, ow: 7, we: 8, er: 2, wi: 3, id: 3, de: 3, es: 9, st: 9, ne: 6, ew: 6}其中 ('es') 与 ('st') 频次并列最高,按规则取字典序较大的字节对,即 ('st')。随后合并预分词单元,结果变为:
{(l,o,w): 5, (l,o,w,e,r): 2, (w,i,d,e,st): 3, (n,e,w,e,st): 6}第二轮中,(e, st) 成为频次最高的字节对(计数为 9),我们将其合并,得到:
{(l,o,w): 5, (l,o,w,e,r): 2, (w,i,d,est): 3, (n,e,w,est): 6}持续此过程,最终获得的合并序列如下:
['s t', 'e st', 'o w', 'l ow', 'w est', 'n e', 'ne west', 'w i', 'wi d', 'wid est', 'low e', 'lowe r']若我们仅执行 6 次合并,则合并序列为:
['s t', 'e st', 'o w', 'l ow', 'w est', 'n e']此时词表包含的元素为:
[<|endoftext|>, [...256 个字节字符], st, est, ow, low, west, ne]基于此词表与合并规则,单词 newest 将被分词为 [ne, west]。
使用BPE Tokenizer训练
让我们在 TinyStories 数据集上训练一个字节级 BPE 分词器。有关如何查找或下载该数据集的说明,请参阅第 1 节。开始之前,建议先浏览一下 TinyStories 数据集的内容,以便对数据有所了解。
预分词的并行化
你将会发现,预分词步骤是一个主要瓶颈。可以通过 Python 内置的 multiprocessing 库对代码进行并行化来加速预分词。具体而言,我们建议在并行实现预分词时,对语料库进行分块处理,同时确保每个块的边界恰好位于某个特殊词符的起始位置。你可以直接使用以下链接中的起始代码来获取分块边界,然后据此将工作分配到各个进程中:
由于我们从不希望跨越文档边界进行合并,这种分块方式总是有效的。就本次作业而言,你始终可以采用这种切分方式,无需担心遇到不包含 <|endoftext|> 的超大语料库这种极端情况。
预分词前移除特殊词符
在使用正则表达式模式(即调用 re.finditer)进行预分词之前,应当先从语料库(若使用并行实现,则是从当前块)中剥离所有特殊词符。务必以特殊词符作为分隔符对文本进行切分,以确保不会跨越这些词符所界定的文本边界发生合并。例如,若语料库(或语料块)形如 [文档1]<|endoftext|>[文档2],则应以特殊词符 <|endoftext|> 为分隔符进行切分,并分别对 [文档1] 和 [文档2] 进行预分词,从而杜绝合并操作跨越文档边界。这可通过 re.split 实现,将 "|".join(special_tokens) 作为分隔符传入(同时需谨慎使用 re.escape,因为特殊词符中可能包含 | 字符)。测试用例 test_train_bpe_special_tokens 将对此进行检验。
合并步骤的优化
前述示例中 BPE 训练的朴素实现之所以缓慢,是因为每次合并都需要遍历所有字节对以找出最高频字节对。然而,在每次合并之后,只有那些与刚合并的字节对存在重叠的字节对的频次计数会发生变化。因此,可以通过为所有字节对的频次建立索引,并对这些计数进行增量更新来提高 BPE 训练的速度,而不是每次都显式地遍历每一对字节来统计频次。采用这种缓存策略可以获得显著的加速效果,但需要注意,BPE 训练的合并部分在 Python 中是无法并行的。
BPE Tokenizer: Encoding and Decoding
文本编码
BPE 编码文本的过程与训练 BPE 词表的过程相呼应,主要包括以下几个关键步骤。
第一步:预分词。
首先,我们对输入序列进行预分词,并将每个预分词单元表示为 UTF-8 字节序列------这与 BPE 训练时的做法完全一致。我们将独立处理每个预分词单元,在其内部将这些字节合并为词表元素(不会跨越预分词单元的边界进行合并)。
第二步:应用合并规则。
接下来,我们按照 BPE 训练期间生成词表元素合并规则的顺序,依次将这些合并规则应用于我们的预分词单元上。
Example (bpe_encoding): BPE encoding example
例如,假设输入字符串为 'the cat ate',我们的词表为 {0: b' ', 1: b'a', 2: b'c', 3: b'e', 4: b'h', 5: b't', 6: b'th', 7: b' c', 8: b' a', 9: b'the', 10: b' at'},学习到的合并规则列表为 [(b't', b'h'), (b' ', b'c'), (b' ', 'a'), (b'th', b'e'), (b' a', b't')]。首先,预分词器会将此字符串切分为 ['the', ' cat', ' ate']。接着,我们逐个处理每个预分词单元,并应用 BPE 合并规则。
第一个预分词单元 'the' 初始表示为 [b't', b'h', b'e']。遍历合并规则列表,我们发现第一个可应用的规则是 (b't', b'h'),应用后该预分词单元变为 [b'th', b'e']。随后,再次从头遍历合并规则列表,找到下一个可应用的规则 (b'th', b'e'),应用后变为 [b'the']。最后再次查看合并规则列表,已无任何规则适用于此序列(整个预分词单元已合并为单个词符),BPE 合并步骤就此结束。对应的整数 ID 序列为 [9]。
对其余预分词单元重复此过程:预分词单元 ' cat' 在应用 BPE 合并规则后表示为 [b' c', b'a', b't'],对应整数序列 [7, 1, 5]。最后一个预分词单元 ' ate' 在应用 BPE 合并规则后变为 [b' at', b'e'],对应整数序列 [10, 3]。因此,编码输入字符串的最终结果为 [9, 7, 1, 5, 10, 3]。
特殊词符。
你的分词器在编码文本时,应能正确处理用户自定义的特殊词符(在构建分词器时提供)。
内存考量。
假设我们需要对一个无法完整加载至内存的大型文本文件进行分词。为了高效地处理这类大文件(或任意数据流),我们必须将其拆分为可管理的块,并依次处理每个块,从而将内存复杂度保持在常数级别,而非与文本大小成线性关系。在此过程中,必须确保不会出现一个词符跨越两个块边界的情况,否则分词结果将与将整个序列一次性载入内存的朴素分词方法产生差异。
文本解码
要将一个整数 ID 序列解码还原为原始文本,只需依次查找每个 ID 在词表中对应的条目(即一个字节序列),将它们拼接在一起,然后将拼接后的字节序列解码为 Unicode 字符串即可。请注意,输入的 ID 序列并不保证一定能映射到合法的 Unicode 字符串(因为用户可以输入任意整数 ID 序列)。当输入的词符 ID 无法产生合法的 Unicode 字符串时,你应当使用官方的 Unicode 替换字符 U+FFFD 来替代那些无法正确解码的字节。
示例代码
python
import os
from typing import BinaryIO
def find_chunk_boundaries(
file: BinaryIO,
desired_num_chunks: int,
split_special_token: bytes,
) -> list[int]:
"""
将文件切分为可以独立计数的块(Chunk)。
如果边界发生重叠(例如文件太小或分隔符太稀疏),返回的块数量可能会少于预期。
"""
# 确保传入的分隔符是字节串类型,因为文件是以二进制模式读取的
assert isinstance(split_special_token, bytes), "必须使用字节串(bytes)表示特殊 Token"
# 获取文件的总字节大小
file.seek(0, os.SEEK_END)
file_size = file.tell()
file.seek(0) # 回到文件开头
# 计算初步的理想块大小(字节数)
chunk_size = file_size // desired_num_chunks
# 初始的边界猜测:根据块大小进行均匀分布
# 边界数组包含起始位置 0 和结束位置 file_size
chunk_boundaries = [i * chunk_size for i in range(desired_num_chunks + 1)]
chunk_boundaries[-1] = file_size # 确保最后一个边界精确指向文件末尾
mini_chunk_size = 4096 # 每次向后搜索的缓冲区大小4k字节
# 遍历除了开头和结尾之外的所有中间边界点
for bi in range(1, len(chunk_boundaries) - 1):
initial_position = chunk_boundaries[bi]
file.seek(initial_position) # 跳转到初步猜测的边界位置
while True:
# 读取一小块数据进行扫描
mini_chunk = file.read(mini_chunk_size)
# 如果读到了文件末尾(EOF),说明后面没有分隔符了,直接设为文件末尾
if mini_chunk == b"":
chunk_boundaries[bi] = file_size
break
# 在当前小块数据中查找指定的分隔符
found_at = mini_chunk.find(split_special_token)
if found_at != -1:
# 如果找到了分隔符,将边界调整到该分隔符的确切位置
chunk_boundaries[bi] = initial_position + found_at
break
# 如果没找到,继续向后移动指针进行下一轮搜索
initial_position += mini_chunk_size
# set():去除重复的边界,防止多个猜测点指向同一个分隔符
# sorted():确保边界按从小到大的顺序排列
return sorted(set(chunk_boundaries))
import time
from tqdm import tqdm
def iter_text_chunks_with_monitor(
file_path: str,
chunk_size: int = 1_000_000, # 1MB
log_every: int = 5, # 每N个chunk打印一次
):
start_time = time.time()
bytes_processed = 0
chunk_count = 0
with open(file_path, "r", encoding="utf-8") as f:
buffer = []
buffer_size = 0
for line in f:
buffer.append(line)
buffer_size += len(line)
bytes_processed += len(line)
if buffer_size >= chunk_size:
yield "".join(buffer)
buffer = []
buffer_size = 0
chunk_count += 1
if chunk_count % log_every == 0:
log_status(
prefix="📘 分词器流式处理",
bytes_processed=bytes_processed,
start_time=start_time,
)
if buffer:
yield "".join(buffer)
# 当前进程所占内存
import psutil
import os
def get_memory_mb():
process = psutil.Process(os.getpid())
return process.memory_info().rss / 1024 / 1024
# 日志状态函数输出(内存占用、处理数据量、处理速度)
import time
def log_status(prefix, bytes_processed, start_time):
elapsed = time.time() - start_time
mb = bytes_processed / 1024 / 1024
throughput = mb / elapsed if elapsed > 0 else 0.0 # 计算吞吐量即每秒处理的数据量
mem = get_memory_mb()
print(
f"{prefix} | "
f"mem={mem:7.1f} MB | "
f"data={mb:8.1f} MB | "
f"speed={throughput:6.2f} MB/s"
)
from tokenizers import Tokenizer
from tokenizers.models import BPE
from tokenizers.trainers import BpeTrainer
from tokenizers.pre_tokenizers import ByteLevel
from tokenizers.decoders import ByteLevel as ByteLevelDecoder
from tokenizers.normalizers import NFKC
#from tqdm import tqdm
def train_bpe_tokenizer(
train_file: str,
val_file: str | None = None,
vocab_size: int = 50257,
num_chunks: int = 8,
output_dir: str = "./bpe_tokenizer",
):
os.makedirs(output_dir, exist_ok=True)
special_tokens = [
"<|endoftext|>",
"<|unk|>",
"<|pad|>",
"<|bos|>",
"<|eos|>",
]
tokenizer = Tokenizer(BPE(unk_token="<|unk|>"))
tokenizer.normalizer = NFKC()
# 设计GPT-2风格的BPE Tokenizer
tokenizer.pre_tokenizer = ByteLevel(add_prefix_space=True)
tokenizer.decoder = ByteLevelDecoder()
trainer = BpeTrainer(
vocab_size=vocab_size,
special_tokens=special_tokens,
show_progress=True,
)
def text_iterator():
# 训练集
for chunk in iter_text_chunks_with_monitor(
train_file,
chunk_size=1_000_000, # 每次处理大小约为1MB的原始数据,处理完就会清除数据方便继续处理
log_every=20,
):
yield chunk
# 验证集(可选)
if val_file is not None:
for chunk in iter_text_chunks_with_monitor(
val_file,
chunk_size=1_000_000,
log_every=10,
):
yield chunk
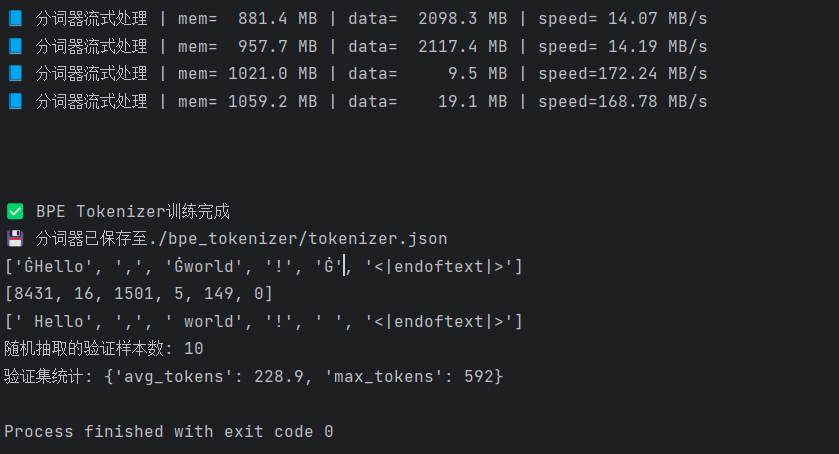
print("🚀 开始训练BPE Tokenizer...")
tokenizer.train_from_iterator(text_iterator(), trainer=trainer)
print("✅ BPE Tokenizer训练完成")
tokenizer.save(os.path.join(output_dir, "tokenizer.json"))
print(f"💾 分词器已保存至{output_dir}/tokenizer.json")
return tokenizer
if __name__ == "__main__":
train_path = "TinyStoriesV2-GPt4-train.txt"
val_path = "TinyStoriesV2-GPt4-valid.txt"
tokenizer = train_bpe_tokenizer(
train_file=train_path,
val_file=val_path,
vocab_size=50257, # 词表大小(通常设为32000或50257等)
num_chunks=16, # 读取文件时的分块数量(建议根据内存大小调整)
output_dir="./bpe_tokenizer",
)
encoded = tokenizer.encode(" Hello, world! <|endoftext|>")
print(encoded.tokens) # 打印编码后的token序列
print(encoded.ids) # 打印编码后的ID序列
# print(tokenizer.decode([1501])) # 输出应该是" world"(前面带个空格)
# 将Ġ替换回空格
clean_tokens = [t.replace('Ġ', ' ') for t in encoded.tokens]
print(clean_tokens)
# Token统计函数
def analyze_tokenizer(tokenizer, texts):
lengths = [len(tokenizer.encode(t).ids) for t in texts]
return {
"avg_tokens": sum(lengths) / len(lengths), # 平均处理token数
"max_tokens": max(lengths), # 最大token数,用于设置最大处理序列长度(决定是否截断序列处理)
}
import random
def load_stories(file_path, num_samples=None):
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
stories = [s.strip() for s in content.split("<|endoftext|>") if s.strip()]
if num_samples is not None:
n = min(num_samples, len(stories))
stories = random.sample(stories, k=n)
return stories
def load_tokenizer(tokenizer_json_path: str) -> Tokenizer:
tokenizer = Tokenizer.from_file(tokenizer_json_path)
return tokenizer
train_path = "TinyStoriesV2-GPT4-train.txt"
val_path = "TinyStoriesV2-GPT4-valid.txt"
test_texts = load_stories(val_path, num_samples=10)
# train_texts = load_stories(train_path, num_samples=20)
# print(f"随机抽取的训练样本数: {len(train_texts)}")
print(f"随机抽取的验证样本数: {len(test_texts)}")
tokenizer=load_tokenizer(r"D:\Learning_materials\Model_library\DIY_model\cs336\bpe_tokenizer\tokenizer.json")
# 分析训练集和验证集的token统计
# train_stats = analyze_tokenizer(tokenizer, train_texts)
val_stats = analyze_tokenizer(tokenizer, test_texts)
# print("训练集统计:", train_stats)
print("验证集统计:", val_stats)结果如下: