作者:vivo 互联网项目团队- Ding Junjie
本文从 Coding Agent 为什么能率先跑通谈起,分析 OpenClaw 若要进入真实生产场景还缺哪些关键能力。核心判断是,要让 Agent 在业务世界稳定落地,必须把开放、分散、难回滚的执行环境,重构成一个可视化、相对封闭、可验证、可恢复的操作空间。
1分钟看图掌握核心观点👇
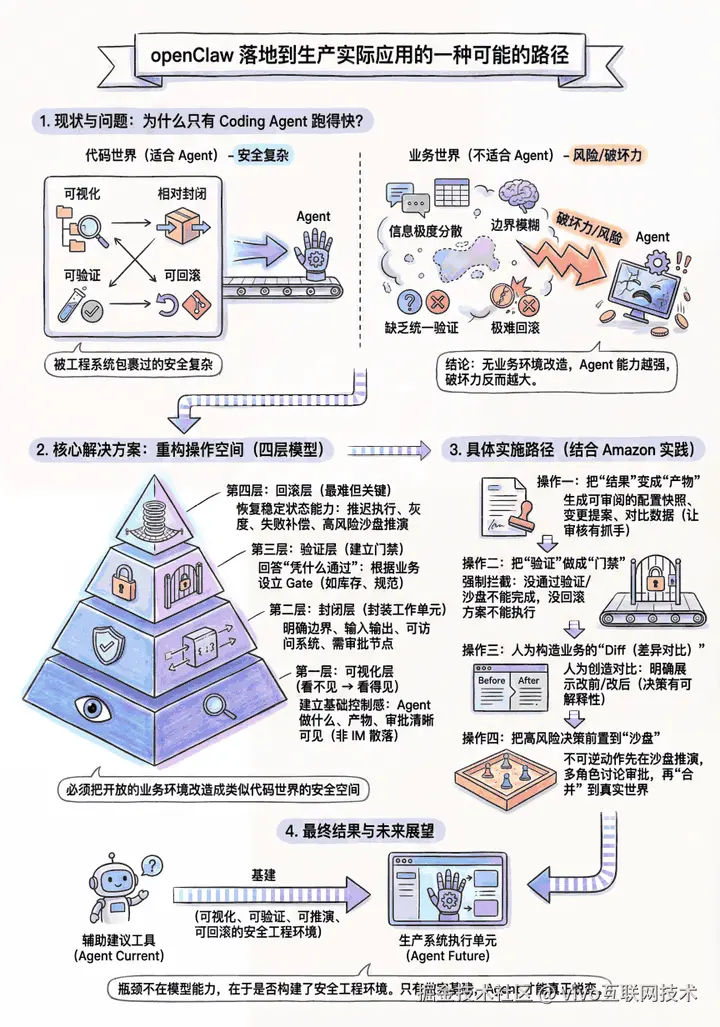
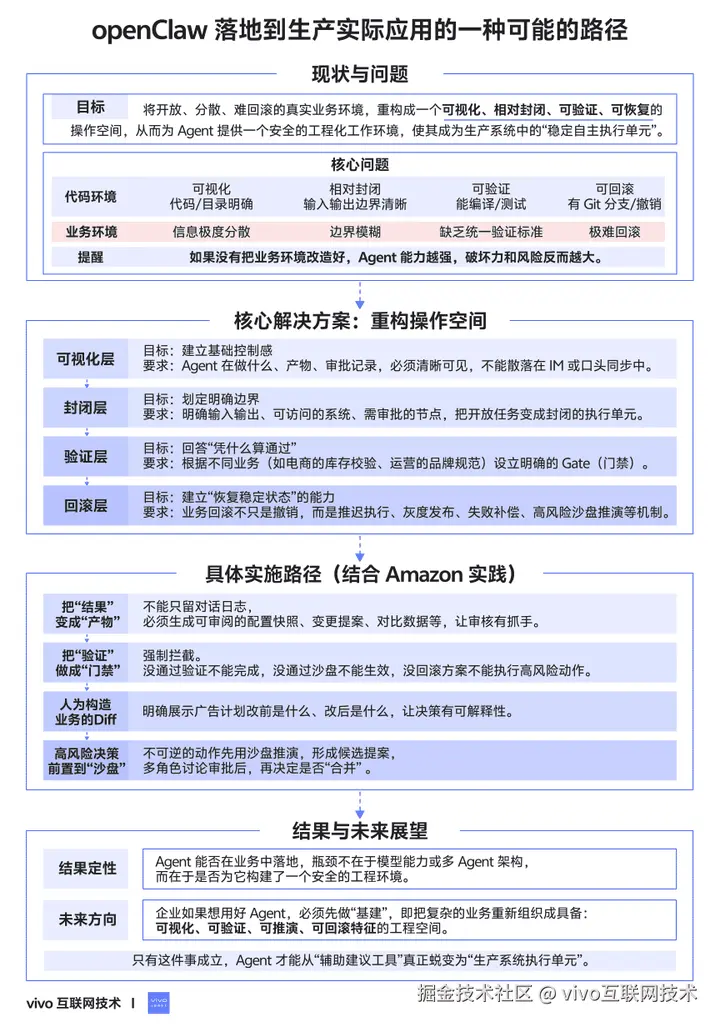
图 1 VS 图 2,您更倾向于哪张图来辅助理解全文呢?欢迎在评论区留言。
一、现状分析思考:Coding Agent 跑在前面
我从 2024 年初开始持续实践 Coding Agent,并尝试过一个开源项目。当时 Agent 的能力更多还是建立在既有框架设计之上,主要承担局部实现和集成工作,依赖选型与方案设计仍需要人工主导。到 2025 年底,这一范式并未发生根本变化,但返工率已经从约 50% 下降到约 20%(估算)。过去一年,我也一直在观察 Coding Agent 之外的 Agent 产品进展,整体上能形成广泛讨论的案例并不多,OpenClaw 是其中较有代表性的一个。
我最初对 OpenClaw 持较为审慎的态度。原因在于,在 Coding Agent 的既有范式下,人仍然承担着关键的监督、校验和兜底职责;一旦把执行链路完全放开,系统稳定性和安全边界都值得重点关注。随着行业讨论增多,我也开始重新评估这一路径的价值。我的结论不是简单认同当前方案,而是认为这一范式仍然值得继续探索,但前提是补齐安全、验证和回滚等关键能力。
先聊聊 Coding Agent 它为什么发展最快:
表面上看,这像是因为"代码比较适合大模型"。但如果只停留在这个解释上,重点其实会被遮蔽。真正的原因是代码所在的工作环境,天然更接近一个适合 agent 稳定工作的空间。
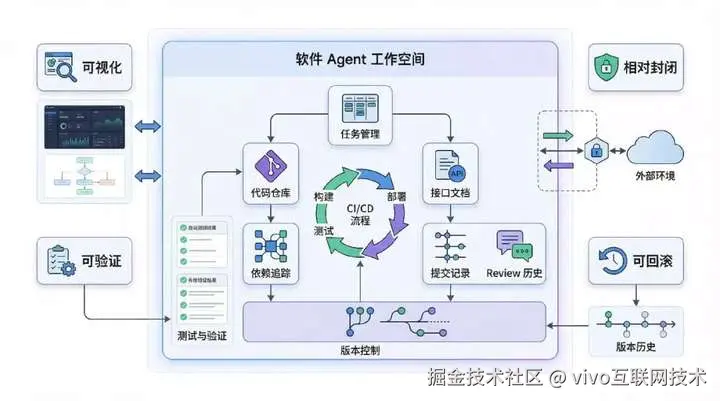
认真仔细观察Coding Agent,会发现它有四个重要特征:
-
它是可视化的。代码、目录、依赖、接口、提交记录、review 历史都摆在明面上。
-
它是相对封闭的。输入通常是仓库、文档、规范,输出通常是代码、测试结果、构建结果,边界比较清楚。
-
它是可验证的。可以用 typecheck、test、build、CI、review 去判断结果是不是成立。
-
它是可回滚的。分支、PR、revert、tag、回退发布,这些机制早就成熟了。
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
代码世界并不简单,它非常复杂。但它的复杂,是一种被工程系统包裹过的复杂。也正因为如此,agent 才能在这个空间里快速迭代、快速验证、快速修正。
二、其他业务为什么还没有出现现象级Agent?
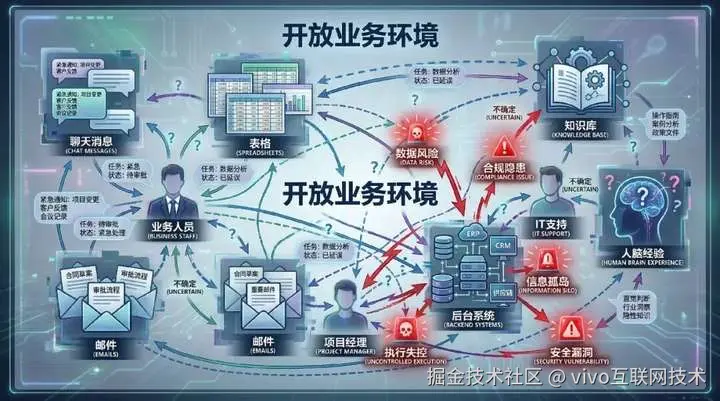
我们把视角放到业务真实世界,它们相对代码,更开放、自由。
业务信息散落在聊天、表格、邮件、后台系统、知识库和人脑经验里;任务边界经常不清楚,执行到一半就变形;验证标准不统一,很多时候只能说"先做了再看";更关键的是,很多业务动作一旦真的执行出去,根本没有代码世界那种轻松回滚的条件。
改一段代码错了,可以回退。
改一个价格、投一轮广告、发一批促销、改一版 listing、改一个库存规则,很多时候就不是一句"撤销"能解决的。它可能已经影响了转化、预算、库存、用户体验,甚至品牌感知。
所以业务环境本身并不是一个适合 Agent 稳定工作的环境。
如果没有把环境改造好,Agent 越强,风险反而越大。
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
三、从OpenClaw往生产落地走,还需要补什么
这个问题往前推,最终会落到一个更本质的方向上:
怎么把原本开放、分散、不可回滚的业务环境,重构成一个可视化、相对封闭、可验证、可回滚的操作空间。
这件事如果成立,业务 agent 才有规模化落地的前提。
如果不成立,多 agent 编排、角色分工、调 prompt、换模型,最后都只是把更强的执行能力放进一个没有护栏的环境里,权限成了双刃剑。
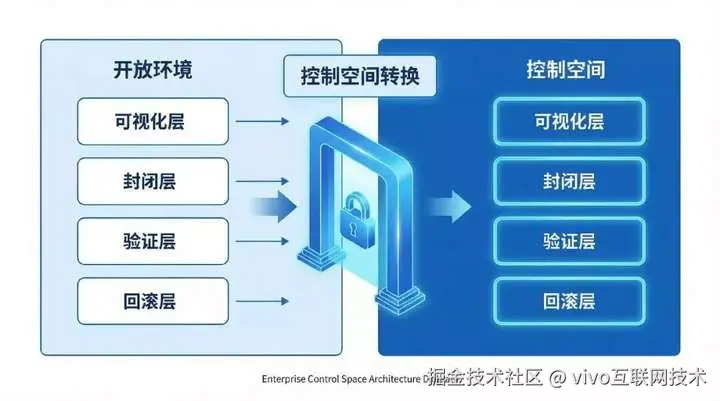
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
我认为,至少要有四层东西。
3.1 可视化层 -- Agent在做什么
首先要解决的是"看不见"的问题。
谁在做什么,为什么做,依据什么做,当前做到哪一步,产物是什么,谁批准的,谁驳回的,哪些动作已经真的执行到外部系统了,哪些还只是提案,这些都必须清晰可见。
如果这些信息仍然散落在 IM、口头同步和多个后台里,那么 Agent 越多,系统越不可控。
可视化绝不是为了好看,而是为了建立最基础的控制感。
3.2 封闭层--工作单元
业务之所以难,不只是因为复杂,还因为太开放。同一个任务,输入可能不断变化,执行边界不断扩大,权限和上下文也经常不明确。人可以依靠经验和临场判断处理部分不确定性,但 agent 需要更明确的边界与约束。
所以必须把任务重新封装成边界明确的工作单元:
-
输入是什么;
-
输出是什么;
-
可以访问哪些系统;
-
可以操作哪些对象;
-
哪些事情需要审批;
-
哪些状态允许继续,哪些状态必须停下。
这一步的本质,是把开放世界中的模糊动作,重构成相对封闭的执行单元。
没有这个步骤,agent 更可能停留在"辅助建议"阶段,难以稳定进入"自主执行"。
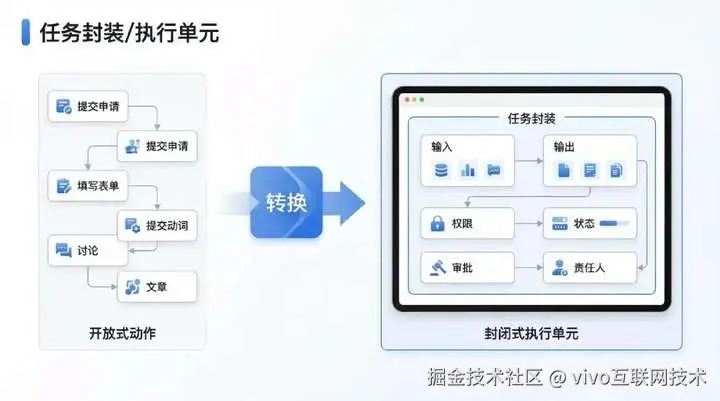
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
3.3 验证层--垂直领域需要自己去做的事情
代码世界之所以适合 agent,不只是因为有仓库,也因为它有验证。
业务世界要复制这种能力,就必须建立自己的验证层。
这个验证层不一定是测试框架,但一定要回答一个问题:
这次动作,凭什么算通过?
在不同业务场景里,验证方式会不同。
-
在软件场景里,可能是 CI、测试、review。
-
在电商场景里,可能是规则校验、库存校验、预算阈值、沙盘结果、人工审批。
-
在运营场景里,可能是投放限制、品牌规范、数据口径一致性、灰度结果。
必须有明确 gate。没有 gate,系统就只有执行,没有交付。
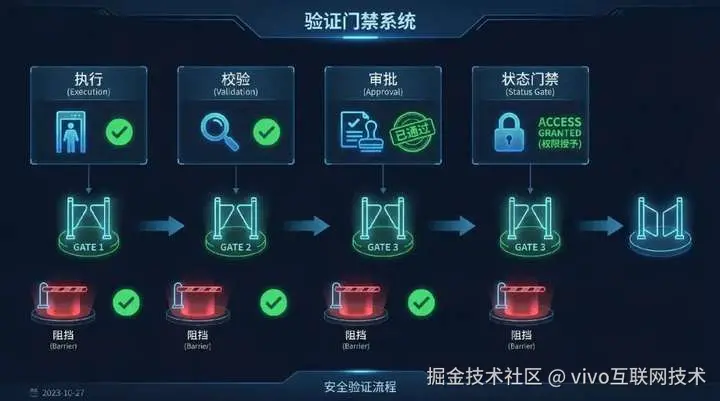
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
3.4 回滚层--最难做到的部分
这是最容易被忽略,但也是最决定生产可用性的部分。
回滚并不总是意味着"撤销上一步",尤其在业务场景里,很多动作天然不可逆。
所以业务里的回滚,更准确地说,是一套"恢复稳定状态"的能力。它可能包括:
-
正式生效前先推迟执行;
-
正式发布前先做灰度;
-
一旦失败,自动进入补偿动作;
-
关键变更必须有上一个版本快照;
-
高风险动作先在沙盘里跑一遍;
-
审核不通过时,不进入真实执行,而是返回上一个待修改状态。
代码世界里,git 承担了大量回滚能力。
业务世界里,这层能力必须被重新设计出来。
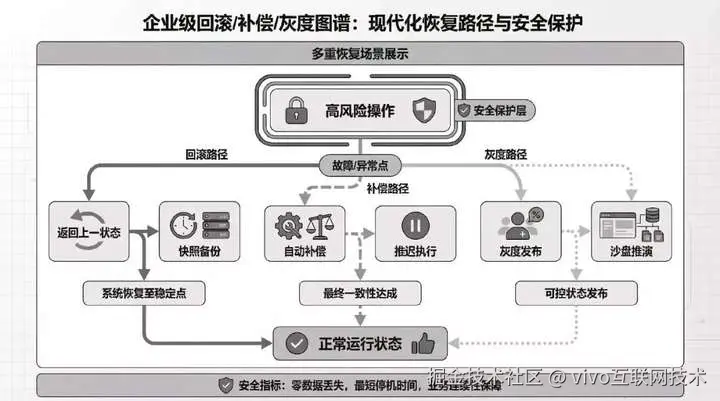
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
四、并非无解,Amazon 的实践
Amazon 在电商场景中构建了一个 agent canvas。它先将复杂、开放且难以回滚的管理动作映射到一个可推演、可比较、可审查的画布空间中,再基于 Agent 生成的建议逐步采纳和调整。借助这种可视化载体,系统既保留了人的交互选择,也降低了直接作用于真实系统的不确定性;同时,不同 canvas 版本也具备了类似 git 的版本管理特征。
本质上,是一种沙盘机制。
因为很多电商决策,一旦直接打到真实系统里,代价很高,甚至不可逆。
所以他们采取的是:先把问题、方案、预期影响、风险和资源消耗放进一个可视化沙盘里,形成一个可讨论、可审核、可比较的提案,再决定要不要把它推进到真实执行。
这和上面的判断完全一致:对于不可轻易回滚的业务场景,系统必须先提供一个"代理现实"的操作空间,让决策先在这个空间里被验证,再进入真实世界。
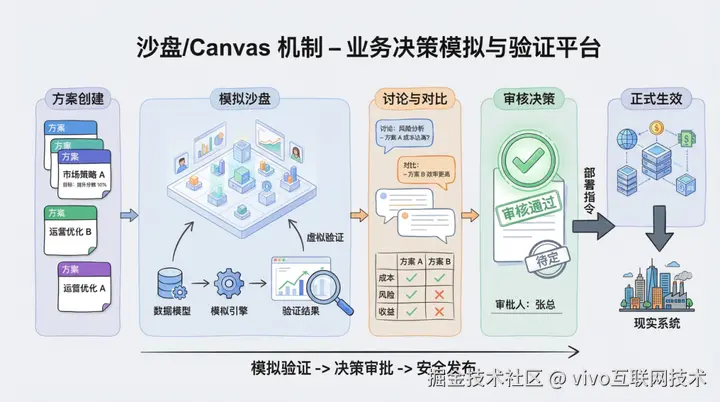
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
顺着这个逻辑继续往下推,从 openClaw走向生产落地,重点是下面这条路线。
4.1 把"结果"从文本变成"产物"
很多 agent 系统的问题在于,最终沉淀的只有对话和日志,这还不足以支撑审阅、审批和回溯。
真正可交付的系统,必须让结果变成可审阅、可比较、可存档的产物。
在软件里,这个产物是代码 diff、PR、测试结果。
在业务里,这个产物应该变成:
-
配置快照;
-
数据前后对比;
-
变更提案;
-
审批记录;
-
指标验证报告;
-
生效记录和补偿方案。
只有当"产物"被建立起来,审核和回滚才有抓手。
4.2 把验证做成门禁
如果验证只停留在"最好检查一下""建议 review 一下",系统仍然会在压力下退化成经验驱动。
-
没有通过验证,不能进入完成态;
-
没有通过审批,不能进入真实执行;
-
没有通过沙盘推演,不能进入高风险生效;
-
没有回滚或补偿方案,不能执行高风险动作。
一旦这一层建立起来,agent 的执行才开始变得可信。
4.3 把业务世界补出"diff"
业务世界天然没有 git diff,但不能因此接受"无法知道到底改了什么"。
生产级业务 agent 必须人为构造 diff 的等价物。
例如:
-
一个广告计划,改前是什么,改后是什么;
-
一个价格规则,旧版本是什么,新版本是什么;
-
一个 listing,标题、图片、卖点、A+ 内容改了哪些;
-
一个库存策略,阈值和补货规则怎么变化了;
-
一次审批,到底批准了哪一个版本的方案。
如果这层没有被建立起来,所谓"业务自动化"最终就容易演变为缺乏可解释性的执行过程。
4.4 把高风险决策前置到沙盘
当一个场景不可轻易回滚时,最好的办法不是事后补救,而是事前推演。
所以越往真实业务走,沙盘层越重要。
沙盘的价值不在展示,而在于提供一个可推演、可审查的决策空间。
它的真正作用是:
-
在真实执行前,先把方案对象化;
-
让多个角色可以围绕同一个对象讨论;
-
让 agent 的执行不再直接碰真实系统,而是先形成候选提案;
-
让批准、驳回、修改、对比都有明确载体。
当这一步成立后,业务世界开始第一次具备类似代码世界中的"分支"能力。
虽然它不一定叫 branch,但它的本质是一样的:先在安全空间里形成一个版本,再决定是否合并到真实世界。
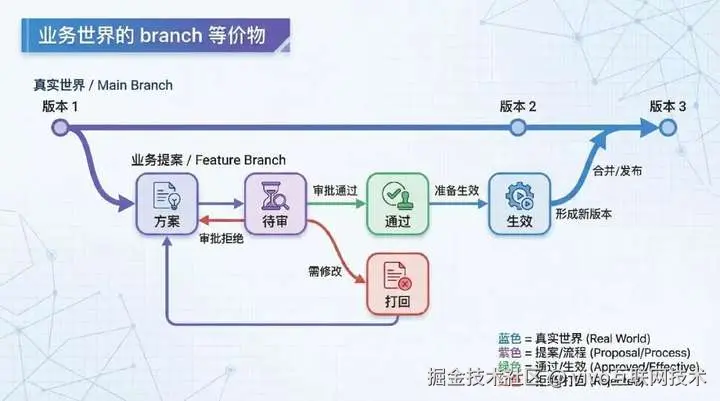
*图片来源于AI(lovart.ai)生成%25E7%2594%259F%25E6%2588%2590 "https://lovart.ai)%E7%94%9F%E6%88%90")
五、总结
Coding Agent 的成功,是代码世界先给 agent 提供了一个安全的工程空间。业务 Agent要想落地,也必须先拥有这样的空间。
真正值得做的,是先把公司的复杂业务重新组织成一个 Agent 可以稳定工作的工程环境。
这个环境至少要做到:
-
任务和沟通可视化;
-
权限与边界相对封闭;
-
执行结果可以验证;
-
高风险动作可以推演;
-
失败结果可以回滚、补偿或打回;
-
所有变化都有产物、有历史、有责任归属。
一旦这件事成立, Agent 就不再只是辅助工具,而会逐步成为可以进入生产系统的执行单元。
反过来看,如果这件事不成立,那么无论模型能力如何提升、多 Agent 架构如何演进,最后都很难真正落地到业务核心。