
大家好,我是半夏之沫 😁😁 一名金融科技领域的JAVA 系统研发😊😊
我希望将自己工作和学习中的经验以最朴实 ,最严谨 的方式分享给大家,共同进步👉💓👈
👉👉👉👉👉👉👉👉💓写作不易,期待大家的关注和点赞💓👈👈👈👈👈👈👈👈
前言
基于RAG 构建知识库的时候,需要选择Embedding 模型来将知识语料进行向量化 ,这就让很多人误以为向量化 等于Embedding,严格来讲,这两者并不完全等同。
本文将从向量化 ,Embedding 的由来和RAG 里的Embedding 这三方面展开,解释清楚向量化是什么,以及RAG 里的Embedding 和传统Embedding有什么不同。
正文
一. 文本向量化
为了让文本参与数学计算 ,需要将文本转换为数字,这里的数字实际上就是一个向量 ,将文本转换为向量的过程就叫做文本向量化。
词袋法 和TF-IDF 是两种简单且经典的文本向量化算法,可以通过这两个算法来理解文本向量化的核心思想。
1. 词袋法
假如给定如下三个句子。
Plain
猫喜欢鱼并且也喜欢玩耍
狗喜欢骨头
猫和狗都喜欢玩耍对每个句子进行分词,分词后表示如下。
Plain
猫 喜欢 鱼 并且 也 喜欢 玩耍
狗 喜欢 骨头
猫 和 狗 都 喜欢 玩耍从每个句子分词后的结果里提取不重复的词语,可以得到如下表格。
| 猫 | 喜欢 | 鱼 | 并且 | 也 | 玩耍 | 狗 | 骨头 | 和 | 都 |
|---|
上述表格称为词表。
此时根据词表,有两种方式将给定的三个句子表示成向量。
第一种方式是有去重词袋法。
统计词表中每个词在句子中是否出现,出现记作1 ,未出现记作0。
| 句子 | 猫 | 喜欢 | 鱼 | 并且 | 也 | 玩耍 | 狗 | 骨头 | 和 | 都 | 向量表示 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 猫喜欢鱼并且也喜欢玩耍 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1111110000 |
| 狗喜欢骨头 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0100001100 |
| 猫和狗都喜欢玩耍 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1100011011 |
第二种方式是无去重词袋法。
统计词表中每个词在句子中出现的次数,出现次数是多少就记作几。
| 句子 | 猫 | 喜欢 | 鱼 | 并且 | 也 | 玩耍 | 狗 | 骨头 | 和 | 都 | 向量表示 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 猫喜欢鱼并且也喜欢玩耍 | 1 | 2 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1211110000 |
| 狗喜欢骨头 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0100001100 |
| 猫和狗都喜欢玩耍 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1100011011 |
词袋法 有一个大前提 是:认为有很多相同词语 的句子之间的语义是相近 的。所以词袋法将句子转换为向量时,只关心句子里有什么词,这个词在句子中出现了多少次。
2. TF-IDF
将句子转换为向量后,向量里每个值就称作特征值 ,词在句子中越重要 ,特征值就应该越高。
考虑如下三个句子。
- 今天的 天气很好,但是我的 计划是在家里休闲的睡觉。
- 安逸的 生活是所有人的向往。
- 每天最开心的 事情就是美美的吃一顿。
注意到的 这个词出现的次数特别多,但是的 这个词没有什么语义,不应该 因为其出现的次数很高 就让其特征值很高。
所以引出了TF-IDF算法。
TF (Term Frequency )叫做词频 ,计算公式 是 TF=句子中总词数词在句子中出现次数,即认为一个词的重要性 与这个词在句子中出现的次数 呈正比。
IDF (Inverse Document Frequency )叫做逆向文档频率 (稀有度 ),计算公式 是 IDF=log含有该词文档数+1总文档数,即认为一个词如果在其它文档中出现得很少 ,则IDF 值就会很大,此时表示这个词稀有度很高。
稀有度 和含有该词文档数的曲线图可以表示如下。
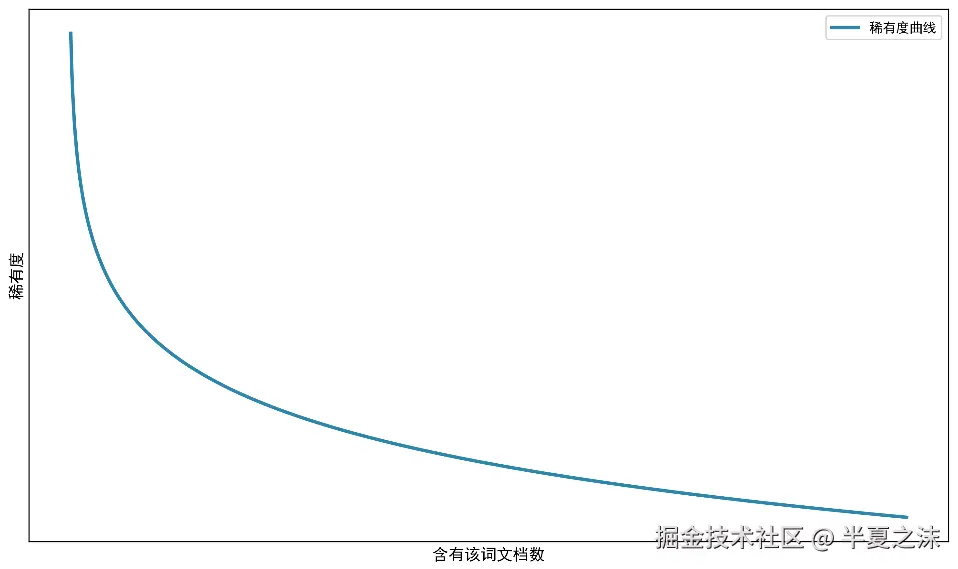
TF-IDF 值就是TF 值乘上IDF 值,即 TF−IDF=句子中总词数词在句子中出现次数×log含有该词文档数+1总文档数。
示例代码如下。
python
import math
from collections import Counter
# 准备三个句子并使用jieba完成分词
corpus = [
"我 爱 学习 数据 结构",
"我 爱 学习 算法",
"数据 结构 很 重要"
]
doc_words = [doc.split() for doc in corpus]
total_docs = len(doc_words)
# 计算TF
def compute_tf(word, doc):
word_count = Counter(doc)
return word_count[word] / len(doc)
# 计算IDF
def compute_idf(word, all_docs):
contain_word_docs = sum(1 for doc in all_docs if word in doc)
return math.log(total_docs / (contain_word_docs + 1)) + 1
# 计算TF-IDF
def compute_tfidf(doc_index):
current_doc = doc_words[doc_index]
tfidf_dict = {}
for word in set(current_doc):
tf = compute_tf(word, current_doc)
idf = compute_idf(word, doc_words)
tfidf = tf * idf
tfidf_dict[word] = round(tfidf, 4)
return tfidf_dict
# 输出结果
for i in range(total_docs):
print(f"📄 文档{i + 1} 的TF-IDF得分:")
print(compute_tfidf(i))
print("-" * 50)运行示例代码,输出结果如下。
Plain
📄 文档1 的TF-IDF得分:
{'数据': 0.2, '爱': 0.2, '学习': 0.2, '结构': 0.2, '我': 0.2}
--------------------------------------------------
📄 文档2 的TF-IDF得分:
{'算法': 0.3514, '学习': 0.25, '我': 0.25, '爱': 0.25}
--------------------------------------------------
📄 文档3 的TF-IDF得分:
{'重要': 0.3514, '数据': 0.25, '很': 0.3514, '结构': 0.25}
--------------------------------------------------示例代码中的三个句子通过TF-IDF就可以表示成如下向量。
| 句子 | 我 | 爱 | 学习 | 数据 | 结构 | 算法 | 很 | 重要 | 向量表示 |
|---|---|---|---|---|---|---|---|---|---|
| 我爱学习数据结构 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0 | 0 | (0.20.20.20.20.2000) |
| 我爱学习算法 | 0.25 | 0.25 | 0.25 | 0 | 0 | 0.3514 | 0 | 0 | (0.250.250.25000.351400) |
| 数据结构很重要 | 0 | 0 | 0 | 0.25 | 0.25 | 0 | 0.3514 | 0.3514 | (0000.250.2500.35140.3514) |
二. Embedding-word2vec
词袋法 和TF-IDF 有两个巨大缺点。
- 本质上是在统计词频 ,会丢失 词在上下文中的语义;
- 得到的向量维度 和词个数一样,导致语料库庞大时向量维度又高又稀疏 (稀疏 的意思是一个向量只有少数位置 上有 特征值,其余位置特征值 全部是0)。
为了解决这个问题,在03 年的A Neural Probabilistic Language Model (NNLM)中提出了Embedding 概念,也就是词嵌入。
Embedding 可以将高维稀疏 向量嵌入为低维稠密 向量,但是在2013 年以前,Embedding 模型的训练速度 上不来,所以一直没有大规模应用,直到2013 年谷歌先后在Efficient Estimation of Word Representations in Vector Space 和Distributed Representations of Words and Phrases and their Compositionality 这两篇论文中引出了word2vec 算法,才算是真正的把Embedding推到了大众视野前。
前面提到的词袋法 和TF-IDF 都是将句子表示成向量,但是如果要将一个一个的词语表示成向量,其实最原始且简单的方式是使用独热编码 (ont-hot)。
比如现在词表 是 我,你,他,好,坏,词表里每个词可以用独热编码表示如下。
| 词 | 独热编码 |
|---|---|
| 我 | 10000 |
| 你 | 01000 |
| 他 | 00100 |
| 好 | 00010 |
| 坏 | 00001 |
词表里每一个词通过独热编码 都能得到一个独一无二 的向量表示,但是缺点也很明显。
- 向量纬度高;
- 信息稀疏;
- 无法进行向量间 的运算。
此时需要通过Embedding 操作将高维 ,稀疏 且无法运算 的向量映射到低维 ,稠密 且可以运算的向量上。
word2vec 是Embedding经典算法之一,其有两种模式。
- CBOW。给定上下文预测中间的词;
- Skip-Gram。给定中间的词预测上下文。
下文将选择Skip-Gram 来对word2vec 算法进行讲解,在正式讲解前,有两点重要说明。
- word2vec 算法有一个重要 前提假设:句子中离得越近的词语相关度越高;
- 无论是NNLM 还是word2vec ,其本质都是神经网络 ,所以下面的讲解均是基于神经网络的训练阶段。
👉 正式 讲解Skip-Gram算法。
假如有一个语料库 ,并且从语料库中能提取出10000 个词,那么这10000 个词就组成了这个语料库的词表 ,按照独热编码 可以得到10000 个10000维的向量。
在某一次训练 时,从这10000 个词中假定选择了一个叫做"ants "的词来进行训练,此时称本次训练的中心词 是"ants ","ants "这个词通过独热编码可以得到下面这样一个向量。
0000000100...0
需要训练的神经网络结构是下面这样。
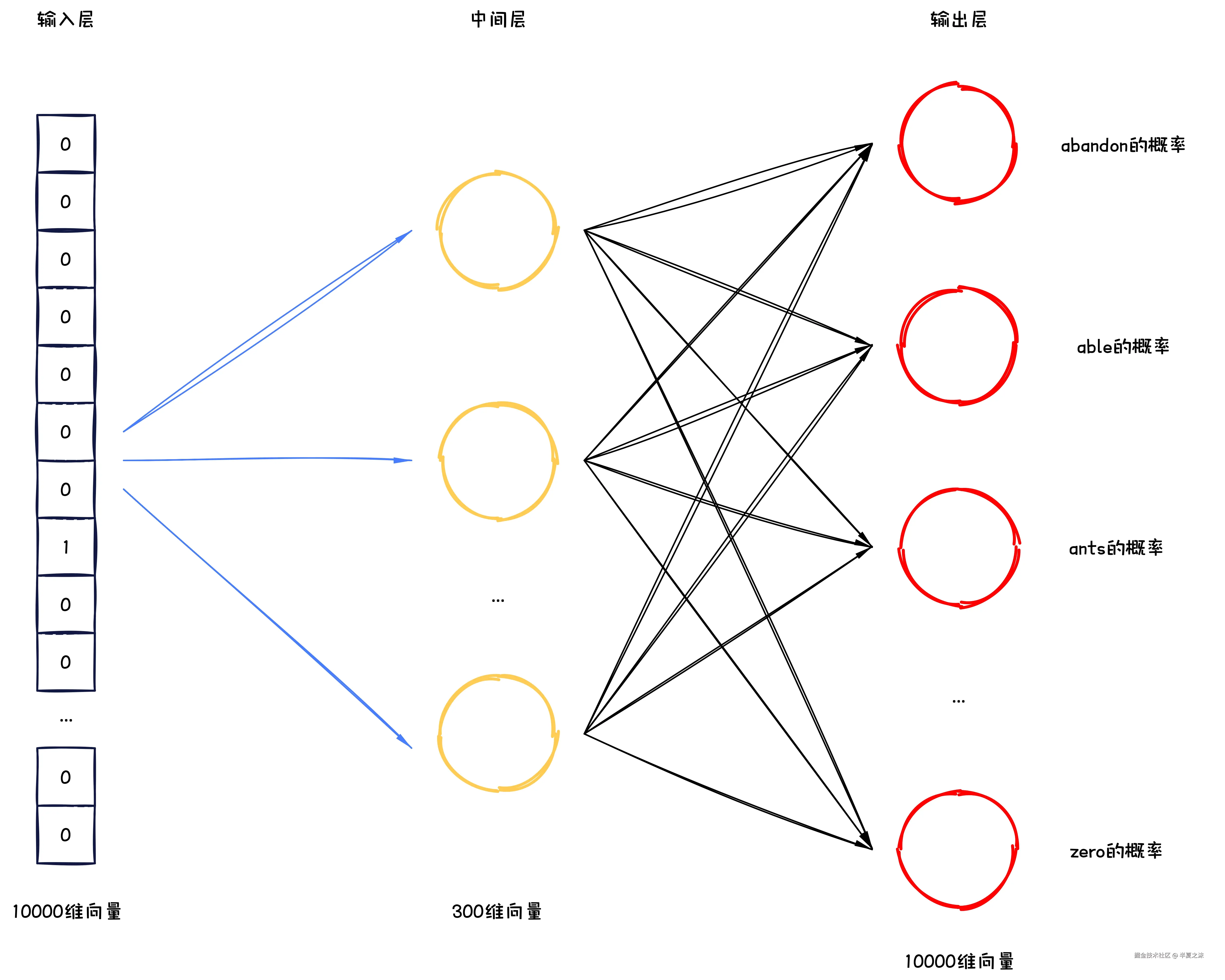
输入层 是10000 维的独热编码 向量,先与一个 Win⊆R10000×300的权重矩阵 相乘,做第一次线性变换 得到一个300 维的中间层 向量,然后300 维的中间层向量再与一个 Wout⊆R300×10000 的权重矩阵 相乘,做第二次线性变化 得到10000 个输出得分,这些输出得分 表示输入是"ants "的情况下,输出是词表中对应位置 的词的得分,得分越高 ,说明神经网络越认为应该输出这个词。
因为词表中有10000 个词,所以会有10000 个得分,对这些得分做Softmax 就可以得到输出概率 ,概率越高 ,说明神经网络越认为应该输出这个词。
有了输出概率 ,现在就要计算神经网络 的损失 ,前面提到Skip-Gram 是给定中间的词预测上下文,那么损失的计算就需要确定中间的词以及确定要预测多少个上下文的词。
在例子中,中心词 是"ants ",所以中间的词就是"ants ",此时从语料库中采样 得到一条包含中心词"ants"的句子,假定采样得到的这个句子表示如下。

现在有一个参数选项叫做窗口大小 ,如果确定为2 ,意思就是取中心词 左边2 个词,以及中心词 右边2 个词作为上下文 ,即一共要预测4 个上下文的词,在例子中就是给定"ants "时,窗口大小 如果为2 ,那么要预测的上下文 就是"are ","many ","carrying "和"things"。
再回顾一下word2vec 的重要前提假设。
句子中离得越近的词语相关度越高。
也就是给定中心词 ,那么和中心词 相关度最高 的词就是这个中心词的上下文 ,那么输出这些上下文 里的词的概率 就应该是最高 的,如果不是最高,说明预测产生了损失 ,所以在计算损失 时,只关注上下文 里的词的概率。
在例子中给定中心词 是"ants ",确定了窗口大小 是2 ,所以上下文 就是"are ","many ","carrying "和"things ",用 P(o∣c)表示给定中心词 是 c的情况下,神经网络预测输出词 为 o的概率,此时计算损失 时就只关心 P(are∣ants), P(many∣ants), P(carrying∣ants)和 P(here∣ants)。
再罗嗦一下,上面两段话想表达:
- 给定"ants ",输出"are ","many ","carrying "和"things "的概率越高 ,说明神经网络效果越好 ,损失越小 ,表明参数越准确;
- 给定"ants ",输出"are ","many ","carrying "和"things "的概率越小 ,说明神经网络效果越差 ,损失越大 ,表明参数越不准确。
损失函数 使用 L=−logP,那么在例子中,损失值计算如下。
L=−logP(many∣ants)−logP(are∣ants)−logP(carring∣ants)−logP(here∣ants)
在训练 神经网络时,希望损失值越小越好 ,所以基于损失值L 对 Win和 Wout的每个参数求偏导 得到梯度 ,然后更新 Win和 Wout的每个参数,让损失值L 逐渐变小,最终完成收敛 ,此时就认为训练完毕。
训练完毕后,得到了两个矩阵 Win和 Wout的,其中 Win就是需要的最终产物 ,在word2vec 算法中,Embedding 模型指的就是这个 Win矩阵中的一堆参数。
在例子的最开始,给定了10000 个10000 维的独热编码 向量,通过神经网络 训练得到了 Win⊆R10000×300矩阵,现在通过 Win矩阵可以将这10000 个独热编码 向量都映射成1 个300 维的嵌入 向量,并且映射关系唯一 ,以"ants"举例。
0000000100...0× 1711...23...1118...18...22525...2...13..................81...2...6122...4...5 =23182...24
此时 Win就相当于一个查找表 ,词表里每一个词,都可以从这个查找表 里直接查表得到一个向量表示,维度是300维。
通过gensim 包可以快速完成word2vec 的训练 和使用 ,相关代码可以让大语言模型帮助生成,这里不再演示。
三. RAG里面的Embedding
通常当需要基于RAG 做知识库 构建时,需要先准备知识语料 ,然后选择一个Embedding 模型,接着将知识语料按照指定策略分片 ,再接着将分片后的语料进行向量化 ,最后存入向量数据库。
在RAG 中,是将分片 后的一段内容 表示成一个向量 ,但是刚刚了解到的Embedding 模型是通过查找表 将一个词 (或者Token )转换为一个向量,所以RAG 里面的Embedding 和word2vec 的Embedding肯定是有所不同的。
RAG 中的Embedding结构通常可以表示如下。
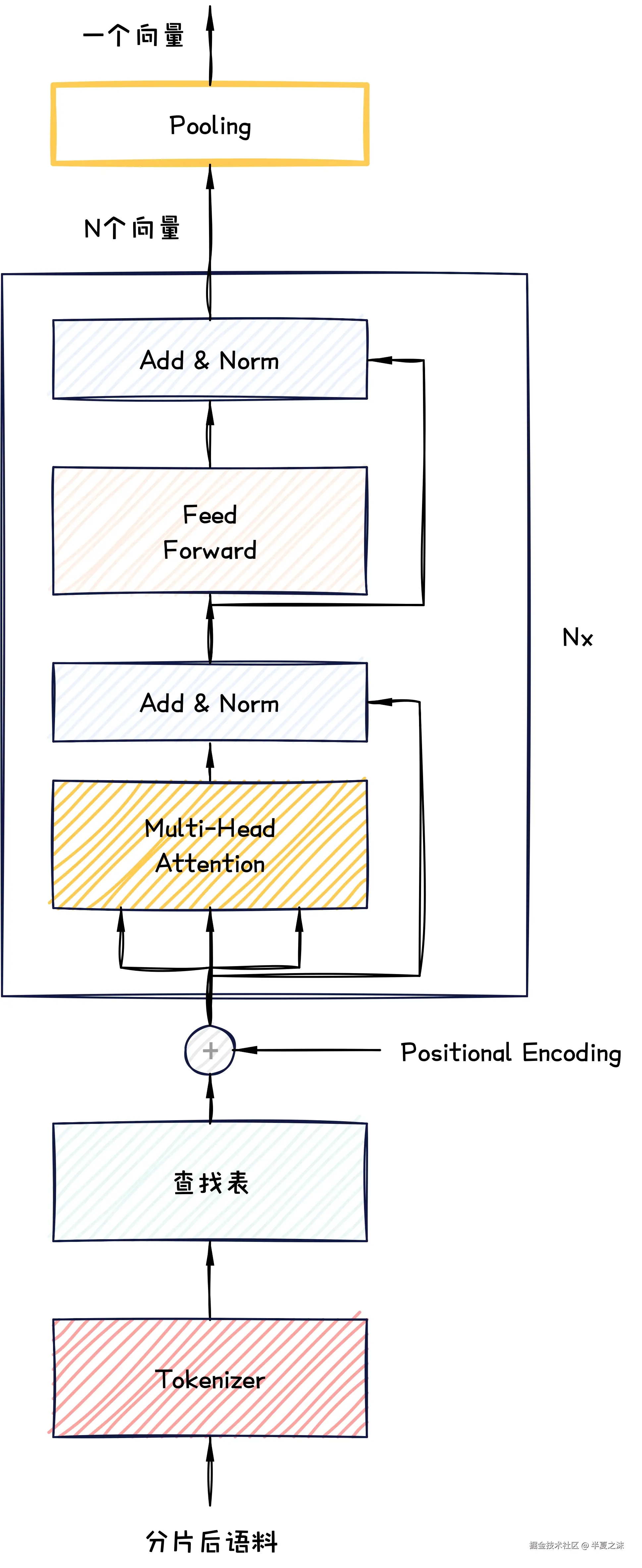
RAG 中做Embedding 前需要先对分片 内容进行分词 ,分词后得到Token 集合,比如分词后得到100 个Token ,同时Embedding 模型的嵌入维度 是1024 维,那么这100 个Token 经过查找表 后会得到100 个1024 维的向量,传统的Embedding 到这里就结束了,但是RAG 的Embedding 还有后面的流程:位置编码 ,Transformer 编码器和池化。
位置编码 (Position Encoding )就是将每个向量与位置向量 相加,让每个Token 对应的向量携带上位置信息,这里不做展开。
Transformer 编码器结构和大语言模型 里的Encoder 保持一致,由多头自注意力机制层 ,残差连接层 和前馈层 组成,经过位置编码后的100 个1024 维向量会在Encoder 中进行Nx 轮的信息聚合,信息聚合 后会得到新的100 个1024 维向量,此时这100 个1024 维向量中的任何一个向量,都可以认为其包含了分片后语料 中的完整信息 ,这是由Transformer 中的Encoder 的自注意力机制特性决定的,也不做展开。
池化 就是从Transformer 编码器送出的多个 向量中,按照一定的策略 选择一个 向量作为最终分片语料 的向量,RAG中常见的池化策略如下。
- CLS Pooling 。取第一个Token 的向量,在代码里面通常取名为cls_token_pooling;
- Last Token Pooling 。取最后一个Token 的向量,在代码里面通常取名为last_token_pooling。
因为RAG 中做Embedding 使用的是Transformer 中的Encoder ,所以在信息聚合 的时候,每个中心词 都能看到完整 的上下文 ,所以在信息聚合后,第一个Token 向量中包含的信息,和最后一个Token向量中包含的信息理论上应该是保持一致的。
到这里其实RAG 里面的Embedding 的结构就很清晰了,不单单有查找表 ,还额外加入了位置编码 ,Transformer 编码器和池化 ,额外需要说明的一点是,RAG 里面的Embedding的所有参数,是需要单独训练的。
聪明 的人已经发现了,除了RAG 的Embedding ,LLM 中也有Embedding ,且LLM 中的Embedding 其实更贴近于传统Embedding ,也就是做一个查找表 的作用,但是LLM 中的Embedding 不是单独训练的,而是在进行大语言模型训练 的时候,一并训练得到的。
大家好,我是半夏之沫 😁😁 一名金融科技领域的JAVA 系统研发😊😊
我希望将自己工作和学习中的经验以最朴实 ,最严谨 的方式分享给大家,共同进步👉💓👈
👉👉👉👉👉👉👉👉💓写作不易,期待大家的关注和点赞💓👈👈👈👈👈👈👈👈
