-
作者:Michael Knyszek & Austin Clements(Go 运行时团队)
Go 1.25 悄悄带来了一个实验性的新垃圾回收器,代号 Green Tea。在 Google 内部的生产环境中,多数服务的 GC CPU 开销降低了 10%,部分服务降低了高达 40%。Go 团队计划在 Go 1.26 将其设为默认 GC。
这篇文章从头讲清楚:现有 GC 为什么慢,Green Tea 改了什么,以及这个看似简单的想法背后藏着多少工程细节。
现有 GC 是怎么工作的
对象与指针
Go 的 GC 只关心两件事:对象(object) 和 指针(pointer)。
对象是堆上分配的内存块,指针是引用这块内存的数字地址。GC 的任务是找出哪些对象还在被程序使用,把剩下的回收掉。
标记-清扫算法
Go GC 使用的是经典的 标记-清扫(mark-sweep) 算法,分两个阶段:
标记阶段(Mark):从一组"根"出发------全局变量、goroutine 栈上的局部变量------沿着指针向外遍历整个对象图,把访问过的对象全部标记为"存活"。这本质上就是一次图的广度/深度优先搜索。
清扫阶段(Sweep):遍历堆上所有对象,把没有被标记到的对象的内存标记为可用,供分配器复用。
算法本身并不复杂。但实际情况是,Go 程序可能有 20% 甚至更多的 CPU 时间花在 GC 上,这笔开销实在不小。
标记-清扫:从根出发遍历对象图,未访问的对象即为垃圾
问题出在哪里
对 GC 开销做分解分析,可以得到两个关键数据:
- GC 总时间的约 90% 花在标记阶段,清扫阶段只占 10%;
- 标记阶段中,约 35% 以上的时间是在等待内存访问,也就是 CPU 在空等数据从主存搬进来。
后者才是真正的根子。
随机跳跃的图泛洪
图泛洪的工作模式决定了它在内存访问上的随机性:
扫描对象 A → 发现指针 → 跳到内存某处的对象 B → 发现指针 → 跳到另一处的对象 C → ...两个相互引用的对象,在内存里未必相邻,往往差了几 KB 甚至几 MB。每次跳转,CPU 都要等待新地址的数据从主存加载进来。现代 CPU 的 L1 缓存命中只需 4 个时钟周期,而主存访问可能需要几百个周期------差了将近 100 倍。
更糟的是,每次扫描的工作量很小,而且高度依赖上一次的结果(得到指针之后才知道下一步去哪),CPU 的乱序执行和预取机制完全无法发挥作用。一位 Go 团队的工程师把这种情况直接称为"微架构灾难"。
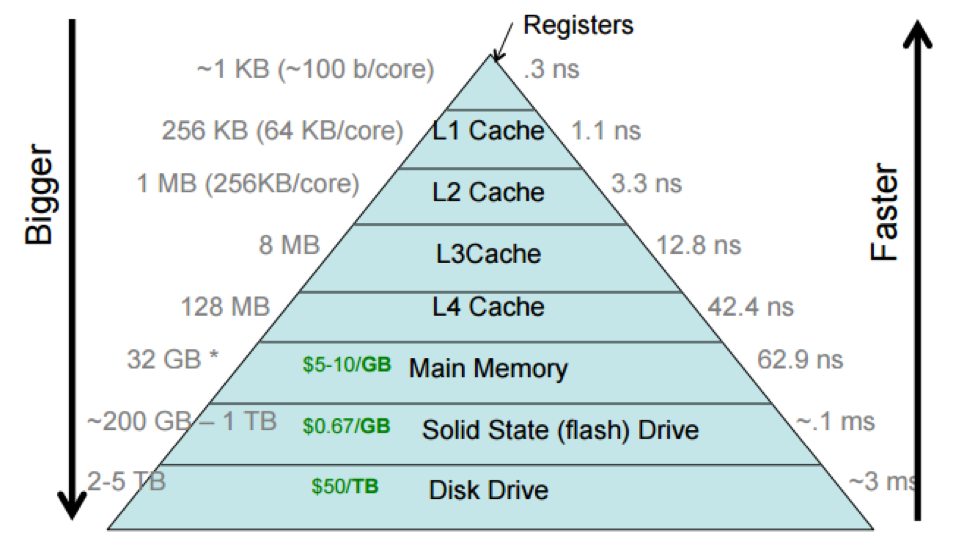
L1 缓存与主存之间的延迟差距可达 100 倍
硬件趋势让问题越来越严重
让人担忧的是,这个问题随着硬件发展在持续恶化:
NUMA(非均匀内存访问):内存与 CPU 核心的亲和性越来越强,跨 NUMA 节点的内存访问比本地访问慢很多,而图泛洪无法感知这一点。
内存带宽下降:虽然 CPU 核心数不断增加,但单核可用内存带宽在下降,随机访问的代价更高了。
核心数增加:标记阶段是并行的,多个 goroutine 同时往一个共享的"待扫描对象队列"里放和取,队列竞争成为瓶颈。
向量指令无法利用:AVX-512 等向量指令擅长处理规整、连续的数据,而每次只处理一个大小不固定的对象,完全无法利用这类硬件加速。
Green Tea 的核心思想
Go 团队给出的解法只有一句话:
以页(page)为单位追踪和扫描,而不是以对象为单位。
Go 运行时中,页(page)是 8 KiB 的连续对齐内存块,同一页内的对象大小相同。这个特性,是 Green Tea 一切优化的基础。
具体改了什么
原始 mark-sweep 的工作列表里放的是对象 ,Green Tea 的工作列表里放的是页。
同时,每个对象的元数据从 1 bit 变成 2 bit:
- seen bit:是否发现过指向该对象的指针
- scanned bit:是否已经扫描过该对象的指针
扫描流程变成:
- 从工作列表里取出一个页;
- 对比该页所有对象的 seen bit 和 scanned bit,找出"已发现但未扫描"的对象;
- 按内存顺序依次扫描这些对象(它们都在同一页内,物理上相邻);
- 扫描中发现新指针时,把目标对象所在的页加入工作列表(如果不在的话),并设置目标对象的 seen bit。
关键变化在于:同一页内的多个对象被集中在一次工作流中处理,而不是每发现一个对象就立刻去追它的指针。工作列表使用先进先出(队列)而非先进后出(栈),目的是让页在队列中等待时,能尽量积累更多待扫描对象,从而在一次处理中扫更多内容。
用公路比喻
博客里用了一个很形象的比喻:
原来的图泛洪像是在城市里开车------不断地转弯、停红灯、躲行人,引擎永远无法提速。
Green Tea 则是驶上高速公路------更少的转弯,更长的直线,CPU 终于可以连续地处理一段内存,让缓存预取机制发挥作用。
扫描路径的直观对比
原始 mark-sweep 在上面的示例堆中需要 7 次独立扫描,频繁在不同页之间跳跃;Green Tea 只需 4 次扫描,多次在同一页内连续处理多个对象。
堆越大,这种效果越显著------因为同一页内积累的待扫描对象会更多。
AVX-512 向量加速
Green Tea 还带来了另一个传统 GC 完全无法实现的能力:用向量指令批量处理整页的扫描元数据。
同一页内的所有对象大小相同,因此页内的所有元数据(seen bits、scanned bits、指针位图)都有固定的格式和规律。现代 x86 CPU 上的 AVX-512 提供 512 bit 宽的向量寄存器,恰好可以一次性容纳整页的元数据。
扫描内核的核心步骤大致如下:
- 将 seen bits 和 scanned bits 一次性加载进向量寄存器;
- 用位运算求差集,得到"本轮需要扫描的对象"位图;
- 将每个对象对应的 1 bit 展开成该对象占用的所有 word(8 字节)数量的 bits;
- 与指针位图求交集,得到"本轮所有需要追踪的指针"的精确位置;
- 批量读取指针值,写入缓冲区。
这套流程几乎全部在 CPU 寄存器内完成,不需要随机访问内存,每次循环处理 64 字节。其中最关键的是 VGF2P8AFFINEQB 这条指令------它来自 x86 的"Galois Field New Instructions"扩展,可以高效完成步骤 3 中的 bit 展开,只需几个 CPU 周期。
AVX-512 的 512 位宽寄存器,恰好可以容纳整页的元数据
对于传统的图泛洪,因为每个对象大小不同,元数据格式不固定,这条路完全走不通。Green Tea 以页为单位的设计,天然解决了这个前提条件。
实测效果
根据 Go 团队公开的数据:
| 场景 | GC CPU 开销降低 |
|---|---|
| 典型工作负载(众数) | 约 10% |
| 部分工作负载 | 最高 40% |
| 向量加速(预期,Go 1.26) | 额外再降 10% |
换算成整体 CPU 开销:如果一个服务原本有 10% 的时间在跑 GC,那么 10%~40% 的 GC 改善意味着整体节省 1%~4% 的 CPU。在大规模生产环境中,这是非常可观的数字。
Green Tea 已经在 Google 内部大规模上线,结果与基准测试一致。
不过,也有例外情况。Green Tea 的核心假设是"同一页内可以积累到足够多的待扫描对象"。如果程序的对象图非常稀疏,每次只能在同一页内扫到 1~2 个对象,那么 Green Tea 积累等待的开销反而会超过收益。Go 团队对这种情况做了特殊处理(单对象页直接走简化路径),但尚未完全消除这类场景下的回退。
如何启用
Go 1.25(实验性,无向量加速):
bash
GOEXPERIMENT=greenteagc go build ./...Go 1.26(计划成为默认,含向量加速):
bash
# 不需要任何额外设置,默认即是 Green Tea
# 如需回退:
GOEXPERIMENT=nogreenteagc go build ./...Go 团队目前正在收集反馈。如果遇到了性能回退或者看到了明显提升,建议在 GitHub Issue #73581 上回复,帮助团队改进 Go 1.26 的正式版本。
这个想法从何而来
Green Tea 的"以页为单位"核心思想,看起来简单,实际上是 Go 团队多年探索的结果。
最初的想法可以追溯到 2018 年------有趣的是,团队里没有人记得到底是谁最先提出的,大家都以为是别人的主意。
2024 年,Austin Clements 日本四处寻觅咖啡馆,喝了无数抹茶,并由此构思出了早期版本的原型!这个原型证明了绿茶的核心理念是可行的。从此,便开始了绿茶的研发之路。GC 的代号"Green Tea",就是这样来的。2025 年,Michael Knyszek 完成了完整的实现和生产化,各种细节在过程中也不断演化调整。
从一个想法到可以大规模使用,中间有大量"行不通的中间方案"和"必须搞清楚的工程细节"。
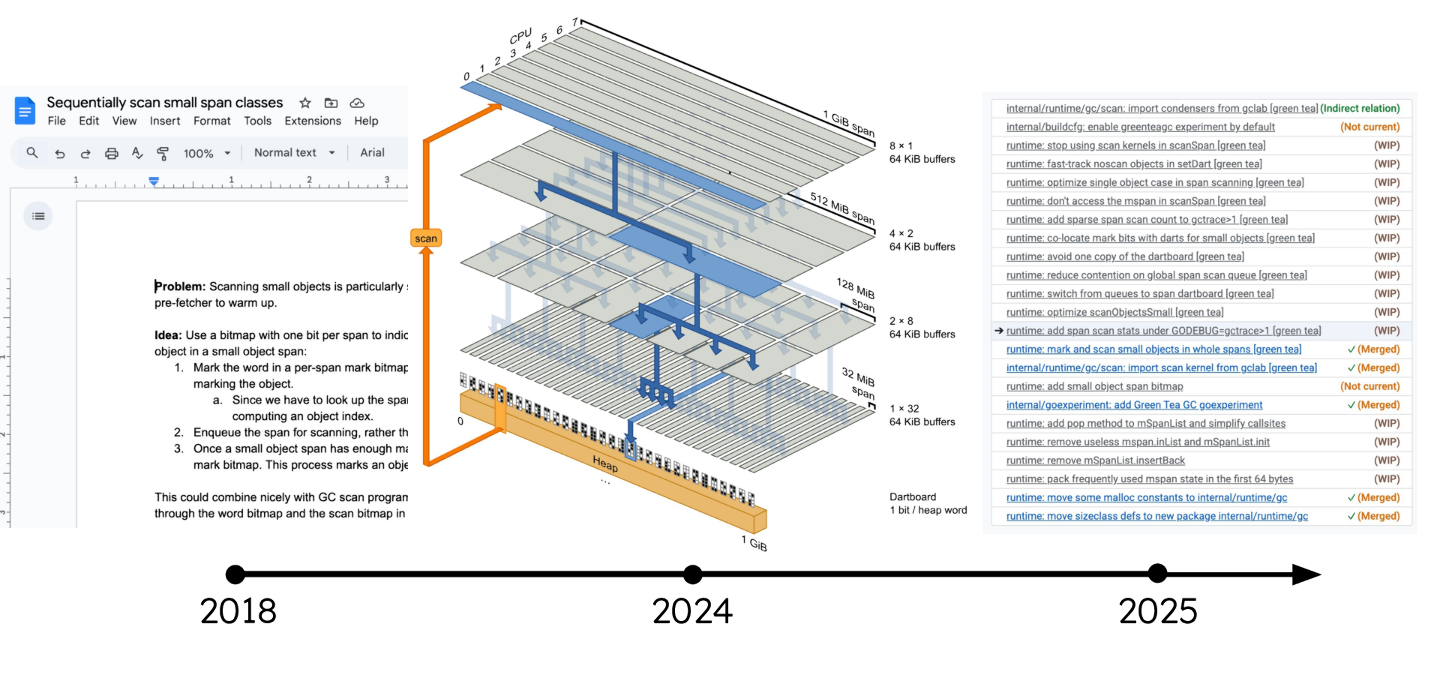
上图 是Go 团队在博客里的一张时间线图,列出了 2018 年以来尝试过但被放弃的各种中间方案。
总结
Green Tea GC 的核心改变,用一句话概括:把"追着对象跑"改成了"把一页内的事情做完再走"。
这个改变让 GC 的内存访问模式从随机跳跃变成连续扫描,进而让 CPU 缓存能够真正发挥作用,并且首次为 GC 标记阶段引入了 AVX-512 向量加速。
对于大多数 Go 服务来说,不需要改一行业务代码,只需要升级到 Go 1.25 并设置一个环境变量,或者等待 Go 1.26 正式发布,GC 开销就能有可见的改善。
参考资料:
- 原文:https://go.dev/blog/greenteagc
- Green Tea GitHub Issue:https://github.com/golang/go/issues/73581
- Go GC 指南:https://go.dev/doc/gc-guide
- AVX-512 扫描内核源码:https://cs.opensource.google/go/go/+/master:src/internal/runtime/gc/scan/scan_amd64.s