Spring Boot概念
Spring Boot 是基于 Spring 框架的快速开发工具,核心作用是简化 Spring 项目的开发、配置和部署,让你能零配置 / 少配置快速搭建出生产级的 Java 应用。
解决痛点:传统 Spring 开发非常麻烦:
- 要手动写大量 XML / 注解配置
- 要自己管理依赖版本(容易冲突)
- 要配置服务器(Tomcat/Jetty)
- 部署、打包流程繁琐
Spring Boot 直接把这些事全自动化了。
Servlet和Spring的关系
Servlet是 Java 官方制定的一套标准接口,专门用来处理 HTTP 请求(浏览器访问、接口调用)。可以说Servlet 是 Java Web 开发的 "底层标准",所有 Java Web 框架(包括 Spring)底层都必须基于 Servlet 运行。也就是说,Spring是基于Servlet之上的一个框架,帮助你简化开发,提供IOC、AOP、事务管理以及整合各种中间件的上层框架,但它最底层处理HTTP请求,仍然是基于Servlet。
核心理念
IOC(控制反转)
就是把对象创建的控制权交给容器了,由容器来管理对象的创建、依赖、以及生命周期。不再由开发者自己new,这是一种思想理念。
好处就是统一管理,对象单例、多例、初始化、销毁都由容器控制,便于测试,可以轻松替换 mock 对象。
DI(依赖注入)
依赖注入(DI)就是:类不再自己 new 依赖对象,而是由 IOC 容器根据配置自动创建并传入;类只负责使用,不关心依赖如何创建、如何配置。DI 是实现 IOC 控制反转思想最核心、最常用的方式。比如,我们经常在Service层使用的@Autowired
java
public class UserService {
@Autowired
private UserDao userDao;
}UserService类根本不关心UserDao是怎么来的,它连的哪个数据库,交由容器帮我们按自定义配置来创建或者从它的缓存中获取。UserService只关心userDao的使用即可。这么做的好处显而易见,开发者只需要告诉容器,UserDao创建的配置,容器依据这个配置创建完,容器自己管理它的生命周期,销毁了就依据我的配置重新创建,这样容器自己可以统一管理整个应用中对象的生命周期,想按什么策略来可以统一的实现,开发者使用时,也不需要分出精力管依赖对象的创建和传入,只需给容器提供统一的配置即可。
AOP(面向切面编程)
在不修改原有业务代码的前提下,对方法进行统一增强,把通用逻辑抽离成 "切面",动态织入到程序中。
AOP的本质
Spring AOP 底层是动态代理:
- 目标类有接口 → JDK 动态代理
- 没有接口 → CGLIB 生成子类代理
最终效果:调用方法时,实际调用的是代理对象,代理对象在原方法的前后加逻辑。
可以这么说,AOP正是IOC思想下的产物,因为容器假如不集中控制Bean的创建,那就没有办法做到针对所有Bean的统一切面和动态代理,没有IOC,那Bean都是开发者自己造,对象创建到处分散,也就没办法统一的创建对象的代理了,正是IOC的思想,才产生了这么便利的AOP。
三者的关系,IOC是种思想,靠DI实现了这个思想,AOP是IOC下产生的便利能力
常用注解的区别
@Autowired和@Resource区别?
- @Autowired是spring提供的注解,@Resource是Java提供的注解
- @Autowired默认先找类型匹配的Bean,假如类型有多个实现类,直接报错,必须结合@Qualifier 指定类的具体名称;
@Resource默认先找变量名匹配的Bean,如果指定了name属性,则先找name属性匹配的Bean。找不到再按类型匹配Bean - @Autowired可以修饰构造器,并自动注入参数,如果一个类上只有一个构造器,还可以省略@Autowired,有多个构造器时,则需指定@Autowired到其中一个来告诉srping使用这个进行构造Bean
java
@Service
public class UserService {
private final UserDao userDao;
// Spring 会用这个
@Autowired
public UserService(UserDao userDao) {
this.userDao = userDao;
}
// 这个不会被 Spring 使用
public UserService() {
}
}@ConfigurationProperties 和 @Configuration的区别
这两个是完全不同的含义,@ConfigurationProperties是表示当前类将从application.yml / application.properties 读取配置,而@Configuration标识当前类是一个提供Bean的配置类。
例如:
@ConfigurationProperties获取yaml里的配置
yaml
my:
app:
name: demo
version: 1.0.0
java
@Component
@ConfigurationProperties(prefix = "my.app")
public class MyAppProperties {
private String name;
private String version;
}@Configuration表示,当前类用来提供Bean对象的,假如要RedisTemplate那就来调dataSource()方法
java
@Configuration
public class MyConfig {
@Bean
public RedisTemplate dataSource() {
return new RedisTemplate();
}
}@Service和 @Component的区别
它们两在功能上无任何区别,Spring都会把它们当作Bean转载到容器中,进行依赖注入初始化。
唯一不同的就是前者标识这是个业务代码层的Service类,专注实现业务逻辑,后者是通用注解不是一个业务Service类,仅此而已。
@Controller和@RestController的区别
假如做的不是前后端分离项目,后端需要返回页面,那@Controller就可以实现。而@RestController注解的Controller,只能返回字符串或者JSON。
@RestController = @Controller + @ResponseBody
java
// 传统控制器
@Controller
public class PageController {
// 返回页面(如 index.html)
@GetMapping("/index")
public String index() {
return "index";
}
// 返回 JSON 数据 → 必须加 @ResponseBody
@GetMapping("/user")
@ResponseBody
public User getUser() {
return new User("张三", 20);
}
}
// REST 接口控制器,自带 @ResponseBody
@RestController
public class ApiController {
// 直接返回 JSON,无需额外注解
@GetMapping("/user")
public User getUser() {
return new User("张三", 20);
}
}本地事务
@Transaction 默认只对RuntimeException和Error回滚,普通Exception不会回滚,需增加:
@Transactional(rollbackFor = Exception.class)
事务的传播机制
- REQUIRED(外部有事务就继承,没有就开新事物)
- REQUIRES_NEW(永远都开新事物,和外部事务隔离)
- NESTED(外部回滚,内部也回滚;内部异常,只回滚内部,不影响外部)
- SUPPORTS(有事务就继承,没有则非事务执行)
- NOT_SUPPORTED(不开事务执行)
- MANDATORY(必须在事务内运行,否则报错)
- NEVER(必须在非事务内运行,否则报错)
事务并发引起的三个问题
- 脏读
读到了别的事务还没提交的数据,别的事务回滚了,数据没提交,那读到的就是脏数据 - 不可重复读
同一个事务里,不同时刻读取同一行数据,结果不一样。原因是中间其他事务修改了这一行数据
个人理解,不可重复读严格来说并不是一个问题,既然数据已经提交到数据库了,那重新读读到最新的才是正常的机制。只能说要求可重复读是某些场景下的需求,但并不能说不可重复读是个问题,因为大部分的场景下,读到当前正确的数据才是对的机制,所以很多企业现在都用RC场景。 - 幻读
同一个事务里,按相同条件查询,结果行数变多或变少了。原因是中间其他事务插入或者删除了数据。
同理,幻读也是某些场景下的需求,但并不能说幻读是个一定要解决的问题,幻读是否需要解决,完全取决于业务是否要求事务期间结果集稳定不变。
扩展:什么情况下需要可重复读,且没有幻读的场景呢,换句话说,什么时候需要保持事务窗口内的数据一致?
比如银行金融体系,需要对所有用户发起当天余额的派息操作,那利息的计算,可能是以某个时刻用户的余额为基础进行计息,用户在计息事务执行期间,他存钱或者取钱,余额的变化都不能影响到派息,这种场景下,RR就比较合适,因为事务一开始就生成快照,后续事务内都已这个快照为基准。
换句话说,需要以某一时刻作为结算点,结算数据不依赖最新数据,就以该时刻平账,希望结算期间不受实时数据影响的业务,就可以用RR来解决不可重复读、幻读问题。
事务的隔离级别
- READ_UNCOMMITTED(读未提交)
可以读到其他事务未提交的数据
问题:脏读、不可重复读、幻读 - READ_COMMITTED(读已提交)
只能读到其他事务已提交的数据
实现 :每次查询都会生成新的快照,MVCC+语句级快照
解决:脏读(其他事务没提交,读不到,不存在脏数据了) - REPEATABLE_READ(可重复读)
同一个事务内多次读取同一数据,保证结果一致
实现 :事务开始时生成一次快照,整个事务复用
解决:脏读、不可重复读、99%场景下的幻读 - SERIALIZABLE(串行化)
所有命令串行执行,不存在脏读、不可重复读、幻读
RR隔离级别,什么情况下会产生幻读?
首先,RR隔离级别通过快照读,解决普通查询下的幻读问题,但是mysql有个硬性规矩,当查询加锁时(SELECT FOR UPDATE)会强制更新当前的Read View(也就是必须强制当前读)。这就导致RR下,如果先执行快照读(普通查询),再执行当前读(加锁查询),再执行快照读时,如果第一次快照读和当前读期间,有数据插进来了,那第二次快照读的时候,就会读到这条数据,因为当前读更新了Read View。
因此,这种极端场景下,无法做到解决幻读。
RR隔离级别,什么情况下会产生间隙锁?
1、更新/删除语句带范围条件时(update/delete ... where id>5 and id<10),加间隙锁
2、for update查询带范围条件时(select ... where id>5 and id<10 for update),加间隙锁
3、for update等值查询数据:
有唯一索引,查得到数据加行锁,但查不到这一行数据时,前后加间隙锁(select ... where id=8 for update)
非唯一索引,无论是查到0条、1条、多条数据,前后加间隙锁(select ... where age=8 for update)
分布式事务
分布式系统天然存在网络可能不可达的情况,在网络断开的情况下,怎么权衡每个服务之间的事务数据一致性就是分布式事务面临的难题。
先看一个理论CAP定理:分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance) 三者不可兼得,只能三选二。分布式场景下网络天然不可靠,所以P必定保证不了,因此只能在P保证不了的情况下,要么选择CP(强一致,牺牲可用性)或AP(高可用,牺牲强一致)。
其实就是个常识,A(主节点)、B(从节点)两个节点,当它们网络正常时,CAP能同时保证。当它们网络断开时,为了保证一致性,A就得停止写,就牺牲了可用性;为了保证可用性,不停止A的写的话,那就得容忍AB数据不一致。
由于这个理论衍生出了两种模型:CP模型(强一致模型)、AP模型(最终一致模型,优先保证可用)。
CP模型
保证强一致性模型,要么阻塞等待所有都成功,要么有一个失败,全回滚。
2PC(两阶段提交)
数据库原生支持的 CP 方案
- 角色:协调者(TM) + 多个参与者(RM,如数据库)
- 阶段 1(准备):
- 协调者向所有节点发 prepare
- 参与者执行本地事务、写 undo/redo、不提交,回复 yes/no
- 阶段 2(提交 / 回滚):
- 全 yes → 发 commit
- 任一 no / 超时 → 发 rollback
- CP 特性:强一致、性能很差,全程锁资源、网络异常时阻塞(牺牲可用性)
- 适用:金融、账务、订单支付等必须强一致场景
- 实现:MySQL XA、Seata XA 模式(Seata就是基于数据库XA实现的,使用注解方式对代码无侵入)
3PC(三阶段提交)
- 角色:协调者(TM) + 多个参与者(RM)
- 三个阶段执行
- CanCommit:询问是否可执行(不锁资源)
- PreCommit:执行、锁定、回复 yes/no
- DoCommit:真正提交 / 回滚
- CP 特性:强一致、只有在询问完可执行了才锁资源,解决了部分阻塞问题,但仍然会阻塞
- 适用:复杂度高,相比2PC还多了一个询问,实际几乎无落地
AP模型
保证事务的最终一致性,但是不强一致,优先高可用。
TCC(Try-Confirm-Cancel)
业务层实现的2PC两阶段提交,不依赖数据库
- 两个阶段 :
- Try:预留资源
- Confirm:所有资源预留成功,确认执行
- Cancel:某一个资源预留失败,回滚
- 缺点 :
- 所有的业务都得分成3个接口,一个预留资源(如冻结库存),一个提交资源(如扣减库存),一个回滚资源(如回滚冻结库存),这简直是工作量的灾难
- 代码侵入性高
- 表结构需要修改,必须增加冻结库存、预创建订单等概念来保证能预留资源和回滚资源
- 优点 :
锁资源只锁了冻结的部分,且时间短, 仅仅try阶段,无长事务,适合高并发,不依赖数据库XA - 实现:Seata TCC
- 注意事项 :
空回滚:Cancel 来了,但 Try 没来 → 别干事
幂等:重复调用不重复执行 → 保证安全
防悬挂:Cancel 跑完后,Try 不准再执行 → 防止资源永远锁住
SAGA
SAGA大概就是:一阶段直接提交本地事务,失败则通过补偿操作(反向操作)回滚所有已完成步骤,保证最终一致性
- 执行步骤 :
- 依次执行 T₁ → T₂ → T₃三个正向事务(订单创建T₁ →扣减库存 T₂ → 账户扣款T₃)
- 任何一步失败,倒序执行补偿:C₃ → C₂ → C₁(账户退款C₃ →加回库存 C₂ → 订单回滚C₁)
- 优点 :
- 代码侵入比 TCC 低,只需要写正向 + 补偿两个方法,不需要资源预留
- 每个步骤都是本地事务立即提交,不占用数据库连接
- 缺点 :
中间状态会短暂暴露(比如订单创建了但库存没扣成功) - 实现:Seata SAGA模式
AT
指的就是Seata的AT模式,可以在代码低侵入的情况下,实现分布式事务。
要求每个使用的数据库都必须创建一张UNDO_LOG表
- 原理 :
使用了AT模式的全局事务方法,seata会为方法里执行的每一条sql依据方向生成它的回滚语句,放到UNDO_LOG表里(比方新增订单,那回滚就是删除刚才新增的订单)。当全局事务都提交了,就删除UNDO_LOG里的这个回滚数据 - 优点 :
- 代码侵入低,只需要创建UNDO_LOG表,引入全局事务注解即可
- 缺点 :
- 涉及第三方事务,没有控制权,总不能要求别人创建一张UNDO_LOG表吧,因此这种场景不适用
- 有短暂不一致情况,订单事务提交了,订单创建了,此时库存事务还没提交,库存还在
本地消息表+MQ消息
比如创建订单 → 扣减库存 → 核销优惠券场景。
创建订单时同步接口调用扣库存和核销优惠券,加入库存扣减成功,但是优惠券核销失败,那就放一个回滚库存的消息到本地消息表,并立马发送消息到库存回滚,消息发送成功则本地消息表状态改为已发送,发不成功,则交由定时任务扫本地消息表发送消息。
这种方式,其实跟上面的SATA很类似了,只是一个依赖Seata,一个依赖消息中间件
源码分析
调试源码
要看懂源码,必须要先下载Spring Boot的源码,然后本地运行起来进行调试才行。
Spring Boot源码下载:https://github.com/spring-projects/spring-boot/tree/3.5.x
下载完后,导入IDEA,在根目录下运行命令gradlew.bat clean build -x test编译出SpringBoot的3.5.13版本
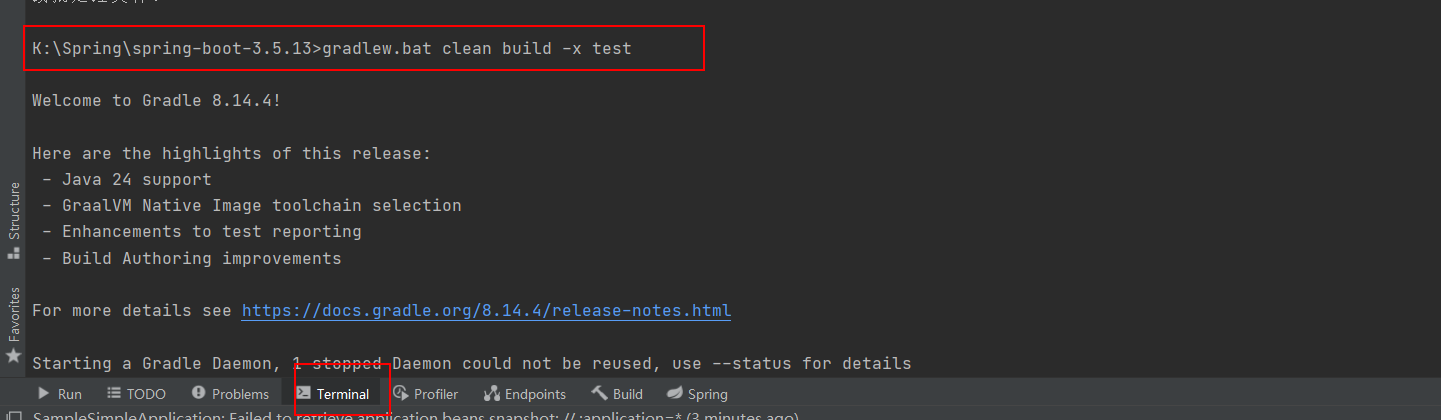
然后在工程下新建一个Module,运行我们的Application
pom.xml按下面的配置
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 上面步骤编译成功的话,这里的version 3.5.13就不会报红 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.13</version>
</parent>
<groupId>com.example</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- Additional lines to be added here... -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>最后运行我们自己的SampleSimpleApplication

跳转源码时,一开始没有关联本地代码,可以选右上角的choose source,然后关联本地的这个spring boot源码文件夹
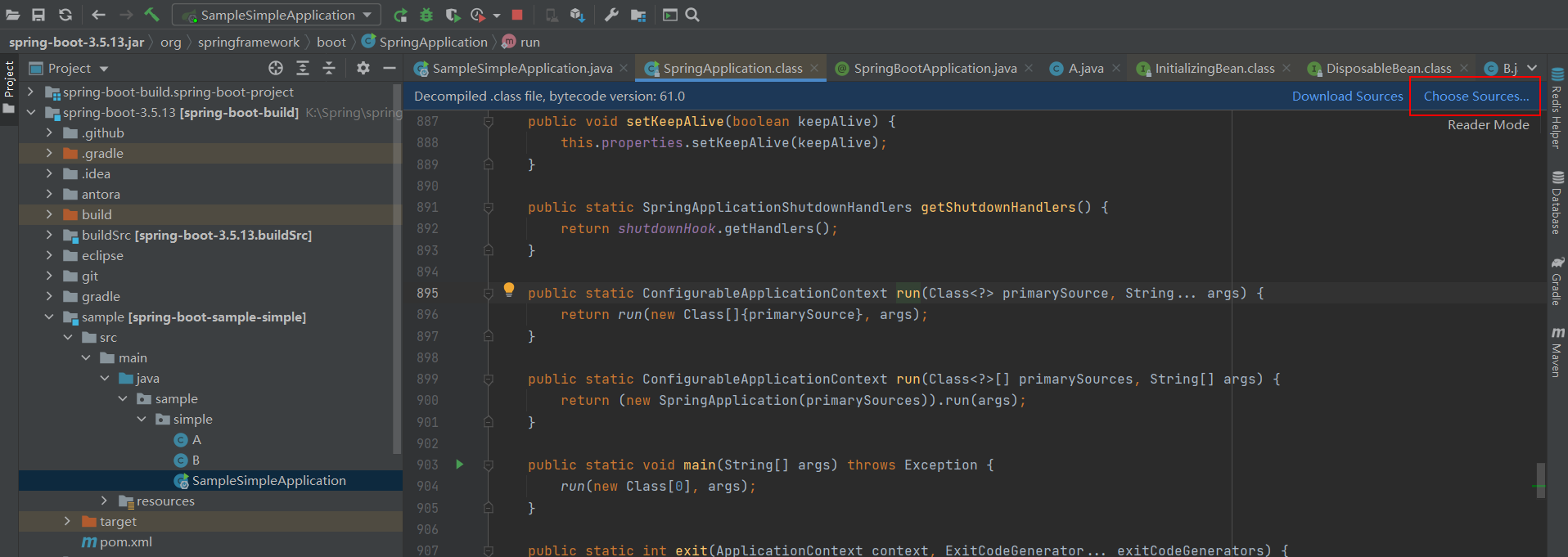
创建两个互相依赖的类A、B,用来调试我们的Bean创建
A.java:
java
package sample.simple;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.beans.factory.BeanFactoryAware;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
@Component
public class A implements BeanNameAware,
BeanFactoryAware,
ApplicationContextAware,
InitializingBean,
DisposableBean {
@Autowired
private B b;
// 实现BeanFactoryAware后,Spring在Bean属性注入阶段回调这个方法,给Bean感知到BeanFactory
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
System.out.println("setBeanFactory");
}
// 实现BeanNameAware后,Spring在Bean属性注入阶段回调这个方法,回调给Bean告诉它BeanName
@Override
public void setBeanName(String name) {
System.out.println("setBeanName:"+name);
}
// 实现DisposableBean后,Spring在Bean的摧毁的生命周期回调这个方法,回调给Bean告诉它要销毁了,执行自定义逻辑
@Override
public void destroy() throws Exception {
System.out.println("destroy");
}
// 实现InitializingBean后,Spring在Bean属性注入完成后回调这个方法,回调给Bean告诉它属性注入完成了,要执行这里的自定义逻辑
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("afterPropertiesSet");
}
// 实现ApplicationContextAware后,Spring在Bean属性注入阶段回调这个方法,回调给Bean告诉,让Bean感知到ApplicationContext这个容器对象
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
System.out.println("setApplicationContext");
}
}B.java:
java
package sample.simple;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class B {
@Autowired
private A a;
}拓展 :A、B两个类必须放在SampleSimpleApplication所在包或所在包的子包下,比如:SampleSimpleApplication放在com.sample包下,那A、B类必须放在com.sample.*下或者com.sample才可以,否则即使加了@Component,那也会扫描不到这两个类。
如果想要放到不同的包,那就得在Application上增加注解@ComponentScan
java
package com.example.demo;
@SpringBootApplication
// 手动添加需要扫描的包
@ComponentScan(basePackages = {"com.example.demo", "com.example.utils", "com.other.project"})
public class SampleSimpleApplication{
}Bean的生命周期
Spring Bean的生命周期,大的流程遵循:实例化 → 属性填充 → 初始化 → 销毁
细的流程按顺序遵循以下步骤:
- SpringApplication#prepareContext() 加载第一层扫描入口
- SpringApplication#refreshContext()
- obtainFreshBeanFactory() 递归扫描入口,扫出所有BeanDefinition
- finishBeanFactoryInitialization() → preInstantiateSingleton() → doCreateBean()
- → createBeanInstance(),根据BeanDefinition调用反射生成Bean的实例(属性为null)
- → populateBean(),填充Bean的属性
- → initializeBean(),初始化
- → invokeAwareMethods() 执行Aware接口
- → postProcessBeforeInitialization() 执行 BeanPostProcessor 前置处理
- → invokeInitMethods() 执行自定义初始化方法
- → postProcessAfterInitialization() 执行 BeanPostProcessor 后置处理
- 容器销毁时
- 执行监听DisposableBean.destroy()
- 执行自定义销毁方法(@PreDestroy /destroy-method)
以下为详细的过程以及解释:
-
加载BeanDefinition
- 目的:解析XML/注解,把类信息封装成BeanDifinition对象(类定义对象)
- 源码入口:
AbstractApplicationContext#refresh() → obtainFreshBeanFactory() XmlBeanDefinitionReader/ConfigurationClassPostProcessor - 首先根配置源会通过BeanDefinitionLoader.load()加载到容器中,根配置源是所有扫描的入口,比方启动类SpringBootApplication、手动传的Xml ,如以下代码:
SpringApplication.run(DemoApplication.class, "classpath:spring-beans.xml")
通过BeanDefinitionLoader.load()加载的BeanDefinition只会有第一层(即DemoApplication加载出来的BeanDefinition、spring-beans.xml加载出来的BeanDefinition)。
而真正递归扫描这些入口里的Bean的是通过AbstractApplicationContext.refresh()方法来的,比方启动类上加的@ComponentScan注解,就会通过refresh方法,去扫描包下面的所有Bean,或者XML里import的XML也会在refresh方法里递归扫描成BeanDefinition。
需要注意的是refresh内部也是调用的BeanDefinitionLoader.load()去加载的,load方法会根据传入的source来区分是用XmlBeanDefinitionReader还是AnnotatedBeanDefinitionReader等。
-
实例化 Bean(调用构造方法)
- 目的:调用构造方法创建对象(属性还都是默认值 null)
- 源码入口:
AbstractAutowireCapableBeanFactory#createBean() → doCreateBean() → createBeanInstance() - 当构造完所有的BeanDefinition后,在`AbstractApplicationContext.refresh()的finishBeanFactoryInitialization()方法里,就会依据所有的beanNames去获取他们的实例,最终调用createBeanInstance(),里面会调用反射创建类的实例,创建出来的Bean里面的属性都是null
-
属性填充(依赖注入 DI)
- 目的:@Autowired、@Value、setter 注入,给对象赋值
- 源码入口:
AbstractAutowireCapableBeanFactory#createBean() → doCreateBean() → populateBean() - createBeanInstance()方法实例化出一个半成品Bean(属性值为null)后,会调用在populateBean()给Bean进行@Autowired、@Value、setter 注入值
-
执行 Aware 接口
- 目的:通过Aware接口,标识当前对象类,spring会在执行到特定阶段时,调用实现了特定Aware接口的类方法(比如实现了ApplicationContextAware接口的类,spring 会在这个类的Bean实例之后,调用
setApplicationContext(ApplicationContext ctx)方法将ctx传给这个Bean。
类似的还有其他各种Aware(InitializingBean、BeanFactoryAware等),帮助Bean感知Spring的生命周期或者获取Spring的容器对象) - 源码入口:
AbstractAutowireCapableBeanFactory#createBean() → doCreateBean() → initializeBean() → invokeAwareMethods() - populateBean()后会调用initializeBean(),这个初始化方法一进来,就会调用写死的3个Aware接口(第一类Aware,BeanNameAware、BeanClassLoaderAware、BeanFactoryAware),后面会调第二类Aware接口(ApplicationContextAware等)
- 目的:通过Aware接口,标识当前对象类,spring会在执行到特定阶段时,调用实现了特定Aware接口的类方法(比如实现了ApplicationContextAware接口的类,spring 会在这个类的Bean实例之后,调用
-
初始化前处理(@PostConstructor在这执行)
- 目的:初始化前的前置处理(AOP 早期代理、包装、修改对象)
- 实现监听接口:
BeanPostProcessor#postProcessBeforeInitialization(Object bean, String beanName)。
也就是说Bean类实现了这个接口BeanPostProcessor后,spring就会在执行初始化前,调用postProcessBeforeInitialization这个方法,开发者就可以在Bean初始化前,对这个bean进行某些属性的修改等。 - 源码入口:
AbstractAutowireCapableBeanFactory#initializeBean() → applyBeanPostProcessorsBeforeInitialization()
-
执行自定义初始化方法
- 目的:用户自定义初始化
- 注解:@Bean (initMethod)定义的方法、XML:init-method定义的方法
- 源码入口:
AbstractAutowireCapableBeanFactory#initializeBean() → invokeInitMethods() → 反射调用自定义方法
-
初始化完成后处理
- 目的:初始化完成 → AOP 动态代理创建核心位置
- 源码入口:
AbstractAutowireCapableBeanFactory#initializeBean() → applyBeanPostProcessorsAfterInitialization()
-
Bean 就绪(放入单例池)
- 目的:初始化完成的 Bean 放入 singletonObjects 单例池
- 源码入口:
DefaultSingletonBeanRegistry#addSingleton()
-
执行对象销毁逻辑
- 目的:容器关闭时的销毁逻辑
- 实现监听接口:
DisposableBean#destroy() - 源码入口:
AbstractAutowireCapableBeanFactory#destroyBean() → invokeDestroyMethods()
-
执行自定义销毁方法(@PreDestroy /destroy-method)
- 目的:用户自定义销毁逻辑
- 注解:@PreDestroy、XML:destroy-method
- 源码入口:
AbstractAutowireCapableBeanFactory#destroyBean() → invokeCustomDestroyMethod()
结合上面Bean的生命周期,动态代理对象是在什么时候生成的
- 正常情况下,没有出现循环依赖时,当Bean走完创建实例 → 注入属性 → 执行Aware → 前置处理 → 初始化 → 后置处理 整个生命周期后,Bean就正常创建出来了,但是这时候是原始对象,此时会在后置处理里面
applyBeanPostProcessorsAfterInitialization()生成原始对象的代理对象,真正干活的是:AbstractAutoProxyCreator#postProcessAfterInitialization(),里面会判断是否需要切面(实现了@Transaction、@Async等注解),需要切面则判断是否强制了cglib(@EnableAspectJAutoProxy(proxyTargetClass = true)),没有强制则判断目标类有没有接口,有接口则默认jdk,否则都走cglib。 - 假如出现了循环依赖,A依赖B,B又依赖A的情况,A注入属性的时候,会去先初始化B,B初始化的时候,会拿A三级缓存里的BeanFactory去创建A的早期对象,此时如果A是需要切面的,就直接生成的代理对象了,然后把代理对象丢给B赋值,因为如果不生成代理对象,那B里引用的就是原始对象,后面使用时是会出问题的。
结合上面Bean的生命周期,来看下Bean的一、二、三级缓存分别在哪一步生成的
调用createBeanInstance时,会反射把Bean实例化出来(但此时属性都为null),实例化完就会将这个原始Bean对象(属性为null)封装到ObjectFactory里,放到三级缓存。
当发生循环依赖时,B对象依赖当前这个对象,那就会去三级缓存里调用这个ObjectFactory的getObject方法,getObject方法会判断,当前对象需不需要切面,需要的话,就会生成代理对象丢给B对象赋值,否则就将原始对象丢给B对象赋值,getObject方法返回的代理对象或者原始对象就会存到二级缓存中,同时删除三级缓存里的ObjectFactory对象。
当前对象完成初始化(Aware → BeanPostProcessor#before → init → BeanPostProcessor#after)后,就会从二级缓存删掉,丢到一级缓存中,此时假如对象需要切面,那一级缓存里存的一定是代理对象。
值得注意的是,假如没有发生循环依赖,对象是不会调用三级缓存里的ObjectFactory.getObject()方法的,也就是说一直都会存在三级缓存中,直到对象初始化时(Aware → BeanPostProcessor#before → init → BeanPostProcessor#after),在BeanPostProcessor#after中生成代理对象(需要AOP)或者拿到原始对象(不需要AOP),直接把代理对象放到一级缓存中,所以正常没有循环依赖的情况下,二级缓存是不会有值的。
JDK动态代理 和 Cglib动态代理的区别
- jdk动态代理通过反射生成一个实现了目标类所有接口的新代理类,代理类和目标类都继承相同的接口。
cglib通过ASM 字节码框架生成目标类的子类,重写目标类的非 final 方法,代理类是目标类的子类。 - jdk代理必须实现接口才行,没有接口,就代理不了,且没有在接口定义内的方法是无法生成代理方法的,因此在这些方法上的注解都会失效,比方A类实现了接口,但是A类有个方法不在接口定义内,但是这个方法上标注了@Transactional,如果用jdk动态代理,那事务将失效
cglib代理不存在这个问题,因为它是目标类的子类,也就是除了final、private、static,子类不能重写的方法之外其他方法都代理了。 - JDK 1.8+ jdk动态代理更快,低版本cglib略快
- Spring AOP 默认策略:
目标类实现了接口 → 自动用 JDK 动态代理
目标类没有实现接口 → 自动用 Cglib 动态代理
可以强制全局使用 Cglib:proxy-target-class="true"
FactoryBean和BeanFactory的区别
FactoryBean是一个Bean,用于生成原始Bean的对象,可以调用getObject来懒加载原始对象。
BeanFactory是IOC容器,生产和管理所有的Bean。
AOP和拦截器链,在源码中的实现体现
AOP是基于动态代理的,而创建代理对象的时机上面已经说过了,循环依赖时是在B对象拿三级缓存里的A的ObjectFactory调用它的getObject()方法时创建的;没有循环依赖时,正常就是在Bean初始化完成的后置处理方法里BeanPostProcessor#postProcessAfterInitialization() 里,这个方法是动态代理的关键,除了构造代理对象出来,还会去找出所有能切这个Bean的Advisors(切点+通知),把它们以List<Advisors>的形式存到代理对象里,这里不区分方法,只区分能切这个类的所有Advisor。
真正构造拦截器链的,是在方法调用时,会从这个已经构造好的List<Advisor>里拿和这个方法相关的Advisor(入口JdkDynamicAopProxy.invoke() / CglibAopProxy.intercept()),把它们转成 MethodInterceptor,然后构造拦截器链,每个拦截器就代表一个切面,调用方式如下:
java
interceptor1.invoke()
interceptor2.invoke()
interceptor3.invoke()
target.method() // 你的业务方法
interceptor3 返回
interceptor2 返回
interceptor1 返回所以AOP并不是给方法生成了增强的方法,本质上是通过调用拦截器链在目标方法的前后执行所有切面逻辑
事务失效的场景
1、本地方法直接调用,通过this.method(),this不是代理对象导致失效
2、事务方法里,起了其他线程,新的线程无事务
3、private、final、static方法,无法生成代理方法
4、事务回滚异常,rollback默认是RuntimeException和Error,抛出了其他异常,没有重写rollback属性,导致事务失效
Spring Boot 自动装配
SPI机制
SpringBoot 通过 SPI 机制收集所有自动配置类,再通过条件注解按需加载,相当于框架提前帮我们写好了大量 @Configuration,让我们只引依赖就能自动装配 Bean。
SpringBoot 会扫描项目中所有依赖 jar 包内部的META-INF/spring/xxx.imports 文件,把所有自动配置类全部收集合并,再通过条件注解按需加载,这就是自动配置的 "动态可扩展" 原理。
也就是说,引入一个新的依赖,那在这个新的jar包下,就会有这么一个META-INF/spring/xxx.imports 文件,规定哪些Bean是这个jar包必须配置的
没有了SPI,那开发者自己就得手动写一堆的@Configuration配置,做不到开箱即用,引入一个依赖后,配置几个必须的yaml参数就可以使用这个依赖了。
Starter
为什么在pom.xml里加了这个依赖,spring就可以直接使用redis的相关能力了呢,不需要开发者手动配置RedisTemplate等对象
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>原因就是因为每个starter中,包含了四个核心:
- 必需的依赖 jar(如 redis 客户端、jackson、jdbc 等)
- 自动配置类(XXXAutoConfiguration)
- 配置属性类(XXXProperties,对应 application.yml)
- SPI 配置文件(告诉 Spring Boot 去哪里加载自动配置)
其中自动配置类长这样:
java
@AutoConfiguration
@ConditionalOnClass(RedisTemplate.class) // classpath 有这个类才生效
@EnableConfigurationProperties(RedisProperties.class) // 读取配置文件
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean // 你没自己定义 RedisTemplate 才自动创建
public RedisTemplate<String, Object> redisTemplate() {
// 创建 RedisTemplate Bean
}
}也就是说,开发者自己没有配置,那starter里其实就已经包含redis使用的必要类了,开发者需要做的,仅仅是在yaml或properties里配置自己的redis服务器连接串而已。
实现原理
@SpringBootApplication注解包含了@EnableAutoConfiguration, @EnableAutoConfiguration又包含了@Import(AutoConfigurationImportSelector.class),@Import注解告诉spring容器,需要加载AutoConfigurationImportSelector这个类到容器中,而AutoConfigurationImportSelector这个类实现了ImportSelector这个接口,spring会在refreshContext解析类定义BeanDefinition阶段,发现这个类实现了ImportSelector这个接口,于是会调它的selectImports ()方法,调AutoConfigurationImportSelector.selectImports ()这个方法里面,就会去jar包的SPI配置文件读配置文件里的配置类,然后以String\[\]的数组形式返回所有的类名,spring拿到这些类名后,就会把它们封装成BeanDefinition加载到容器中。
案例:Tomcat是怎么集成到Spring Boot中的*
首先必须引入依赖starter
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>它内部自动依赖了tomcat-starter
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</dependency>tomcat-starter的pom.xml里就包含了tomcat核心包、tomcat websocket支持包、EL表达式支持包等
引入依赖后,项目启动,@SpringBootApplication → @EnableAutoConfiguration → @Import(AutoConfigurationImportSelector.class),会加载AutoConfigurationImportSelector这个类到容器中,而AutoConfigurationImportSelector这个类实现了ImportSelector这个接口,spring会在refreshContext解析类定义BeanDefinition阶段,发现这个类实现了ImportSelector这个接口,于是会调它的selectImports()方法,这个方法里,就会去解析tomcat-starter引入的spring-boot-autoconfigure.jar 包下的META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports,这个imports文件就有一行
org.springframework.boot.autoconfigure.web.servlet.ServletWebServerFactoryAutoConfiguration,把这个ServletWebServerFactoryAutoConfiguration加载成BeanDefinition转载到容器中。后面会在源码refreshContext() → onRefresh() → createWebServer(),通过这个配置类创建出ServletWebServerFactory,从工厂创建出TomcatWebServer调用initialize() 触发 tomcat.start()。
Spring请求处理流程
-
浏览器请求
-
Tomcat
- 封装 HttpServletRequest(请求对象)
- 封装 HttpServletResponse(响应对象)
-
Tomcat 把请求转发给 Spring 的核心:DispatcherServlet
- DispatcherServlet 是 Spring MVC 的唯一入口,所有请求都必须经过它。
-
DispatcherServlet 里会去查找能处理这个请求的Controller的方法,映射封装成一个对象HandlerMapping
-
执行前置拦截器逻辑
-
HandlerMapping再交由HandlerAdapter统一调方法
- Spring 中 Controller 方法写法非常灵活,有的返回String,有的返回JSON,有的参数是 @RequestParam,有的参数是 @RequestBody,为了统一调用Spring 使用 HandlerAdapter 适配器
-
执行后置拦截器逻辑