导读
风电叶片长期暴露在高空环境中,裂纹、烧蚀、剥落、锈蚀等表面缺陷不仅影响发电效率,严重时还会导致叶片断裂。无人机巡检替代了人工高空作业,但拍回来的图像仍然需要高效的检测模型来自动识别缺陷。问题在于:叶片缺陷尺度差异大、边缘信息模糊、背景纹理复杂,通用检测模型往往精度不足。
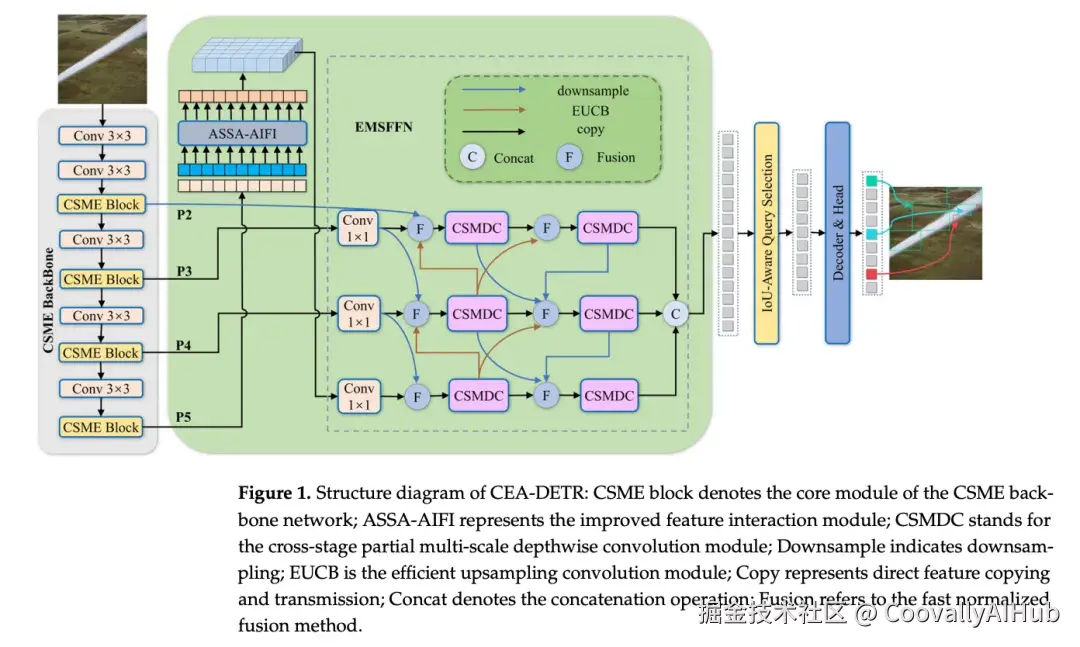
郑州大学联合嵩山实验室的研究团队提出了 CEA-DETR,以 RT-DETR-r18为基线,从骨干网络、特征融合和注意力机制三个环节进行针对性改进。骨干网络引入CSME 模块(多尺度池化 + 边缘增强 + 双域特征选择),特征融合采用 EMSFFN(BiFPN 加权融合 + 高效上采样 + 跨阶段深度卷积),编码器中的自注意力替换为ASSA(自适应稀疏自注意力,密集与稀疏双分支动态融合)。在自建的 4468 张风电叶片缺陷数据集上,CEA-DETR 的 mAP50 达到 89.4%,比基线提+3.1%;mAP50:95 达到 68.9%(+6.5%);同时参数量减少20%(19.9MB→15.9MB),GFLOPs 降低约 8%(57.0→52.4),实现了精度提升与计算开销下降的双重改进。
论文信息
- 标题:CEA-DETR: A Multi-Scale Feature Fusion-Based Method for Wind Turbine Blade Surface Defect Detection
- 作者:Xudong Luo, Ruimin Wang, Jianhui Zhang, Junjie Zeng, Xiaohang Cai
- 机构:郑州大学 网络空间安全学院、郑州大学 计算机与人工智能学院、嵩山实验室
- 期刊:Sensors 2026, 26(7), 2115
- 发表日期:2026年3月28日
一、风电叶片缺陷检测:尺度差异大、边缘模糊、背景复杂
风电叶片长度通常在数十米以上,无人机拍摄的图像中缺陷类型多样:裂纹(crack)细长且边缘不规则,烧蚀(burning)面积较大但与正常区域过渡模糊,剥落(peel)和变形(deformity)的形态各异,锈蚀(rusty)和污垢(dirt)则可能与叶片表面纹理混淆。
这些特点给检测模型带来三个核心难题:
- 多尺度问题:不同缺陷尺寸跨度大,细小裂纹和大面积剥落需要模型同时捕捉细粒度和全局特征。
- 边缘信息丢失:叶片表面缺陷的边界往往不清晰,多次下采样后边缘细节容易被模糊化,影响定位精度。
- 背景干扰:叶片表面的自然纹理、光照反射等与缺陷特征相似,容易导致误检。
论文以 RT-DETR-r18为基线模型。RT-DETR 本身是一个高效的实时检测Transformer,但直接应用于风电叶片场景时,其 mAP50 为 86.3%,mAP50:95 为 62.4%,在多尺度特征提取和边缘细节保留上存在改进空间。
二、CEA-DETR:三个模块改进骨干、融合和注意力
CEA-DETR 的改进集中在三个模块上,分别对应特征提取、特征融合和编码器注意力三个环节。
2.1 CSME骨干网络:多尺度边缘增强特征提取
CSME(Cross-Scale Multi-Edge feature Extraction) 替换原有的 ResNet18 骨干网络,包含三个子组件:
- 多尺度池化:使用 3x3、6x6、9x9、12x12 四种尺度的池化操作,捕捉不同大小的缺陷特征。
- EIEM(Edge Information Enhancement Module)边缘增强模块:专门强化缺陷边缘信息,缓解下采样过程中边缘细节丢失的问题。
- DSM(Dual-domain Selection Module)双域特征选择:包含空间域 SSM 和频率域 FSM 两个分支,分别在空间维度和频率维度进行特征筛选,综合两种域的互补信息。
2.2 EMSFFN:高效多尺度特征融合网络
EMSFFN(Efficient Multi-Scale Feature Fusion Network) 替换 RT-DETR 原有的 CCFM 特征融合模块,同样包含三个子组件:
- BiFPN 自适应加权融合:为不同尺度的特征分配可学习的权重,自适应地平衡浅层(高分辨率定位信息)和深层(高语义信息)特征的融合比例。
- EUCB(Efficient Up-sampling Convolution Block)高效上采样模块:在上采样过程中保留更多细节信息。
- CSMDC(Cross-Stage Multi-scale Depthwise Convolution)跨阶段多尺度深度卷积:跨阶段连接不同层级特征,使用深度可分离卷积降低计算量。
2.3 ASSA-AIFI:自适应稀疏自注意力编码器
ASSA(Adaptive Sparse Self-Attention) 替换 RT-DETR 编码器中原有的标准自注意力(AIFI),设计了双分支结构:
- Dense Self-Attention 分支:对所有 token 计算全局注意力,保留完整的上下文信息。
- Sparse Self-Attention 分支:使用 squared ReLU 激活函数替代 Softmax,自动将低相关性 token 对的注意力权重压为零,从而在保留高响应交互的同时降低计算复杂度。
- 可学习权重融合:两个分支的输出通过可学习的权重参数动态融合,让模型自适应地在全局上下文和局部聚焦之间取得平衡。
图片来源于原论文
三、实验结果:mAP50达89.4%,参数量和计算量同步下降
数据集
论文使用自建的风电叶片缺陷数据集,基本信息如下:
| 项目 | 参数 |
|---|---|
| 图像数量 | 4468 张 |
| 图像分辨率 | 640×640 |
| 缺陷类别 | 6类(crack, burning, peel, deformity, rusty, dirt) |
| 标注工具 | LabelImg |
| 数据划分 | 训练:验证:测试 = 7:2:1 |
训练环境:Ubuntu 22.04,Intel Xeon 8255C,NVIDIA RTX 3090,PyTorch 2.1.2,batch size 16,AdamW 优化器,学习率 1e-4,weight decay 1e-4,训练 200 epochs。

图片来源于原论文
最终模型与基线对比
| 指标 | RT-DETR-r18 基线 | CEA-DETR | 变化 |
|---|---|---|---|
| mAP50 | 86.3% | 89.4% | +3.1% |
| mAP50:95 | 62.4% | 68.9% | +6.5% |
| Params | 19.9MB | 15.9MB | -20.1% |
| GFLOPs | 57.0 | 52.4 | -8.1% |
CEA-DETR 不仅在精度上实现了提升,同时参数量从 19.9MB 降至 15.9MB,GFLOPs 从 57.0 降至 52.4。
骨干网络对比
论文将 CSME 与六种骨干网络在相同框架下进行了对比:
| 骨干网络 | P/% | R/% | Params/MB | mAP50/% |
|---|---|---|---|---|
| ResNet18 | 87.3 | 83.4 | 19.9 | 86.3 |
| ResNet50 | 88.0 | 83.8 | 43.1 | 86.9 |
| FasterNet | 87.1 | 82.6 | 14.6 | 85.7 |
| ManbaOut | 86.4 | 82.2 | 15.9 | 83.4 |
| SwinTransformer | 87.9 | 84.0 | 36.5 | 86.4 |
| EfficientViT | 86.8 | 83.5 | 14.1 | 86.6 |
| CSME | 89.5 | 85.9 | 15.8 | 88.2 |
CSME 以 15.8MB 参数量取得了 88.2% 的 mAP50,高于所有对比方案。相比 ResNet18 基线,mAP50 提升 +1.9%,同时参数量从 19.9MB 降至 15.8MB。相比参数量最大的 ResNet50(43.1MB),CSME 的 mAP50 仍高出 +1.3%,但参数量仅为其 36.7%。在轻量化骨干中,CSME 也优于 FasterNet(+2.5%)、ManbaOut(+4.8%)和 EfficientViT(+1.6%)。
特征融合模块对比
| 融合模块 | P/% | R/% | Params/MB | mAP50/% |
|---|---|---|---|---|
| CCFM(基线) | 87.3 | 83.4 | 19.9 | 86.3 |
| SlimNeck | 86.4 | 83.2 | 19.4 | 86.1 |
| BiFPN | 87.1 | 83.5 | 20.6 | 86.2 |
| GDNeck | 87.6 | 85.8 | 22.3 | 86.6 |
| MAFPN | 87.8 | 86.0 | 22.9 | 87.1 |
| EMSFFN | 88.4 | 86.3 | 20.1 | 87.6 |
EMSFFN 的 mAP50 达到 87.6%,比基线 CCFM 提升 +1.3%,比性能第二的 MAFPN 高出 +0.5%。参数量为 20.1MB,低于 GDNeck(22.3MB)和 MAFPN(22.9MB)。值得注意的是,单独使用 BiFPN 的效果仅为 86.2%(与基线接近),但 EMSFFN 将 BiFPN 与 EUCB 和 CSMDC 组合后实现了更大的提升,说明三个子组件之间存在互补效应。
四、消融实验:三个模块各贡献多少?
从骨干对比和融合对比的数据,可以分析各模块的独立贡献:
| 改进模块 | 关键提升 | 改进环节 |
|---|---|---|
| CSME | mAP50 从 86.3% 提升至 88.2%(+1.9%) | 骨干网络 |
| EMSFFN | mAP50 从 86.3% 提升至 87.6%(+1.3%) | 特征融合 |
| ASSA-AIFI | 与 CSME/EMSFFN 联合后最终 mAP50 达 89.4% | 编码器注意力 |
从实验数据中可以观察到几个值得关注的点:
CSME 骨干是精度提升的核心驱动力。在单独替换骨干的对比实验中,CSME 取得了最高的 mAP50(88.2%),Recall 也最高(85.9%),同时参数量保持在 15.8MB 的较低水平。多尺度池化(4种尺度)+ 边缘增强 + 双域特征选择的组合设计,使其在捕捉多尺度缺陷特征和保留边缘信息两方面均优于对比方案。
EMSFFN 的组合效应优于单一 BiFPN。单独使用 BiFPN 时 mAP50 仅为 86.2%,但 EMSFFN 将其与高效上采样(EUCB)和跨阶段深度卷积(CSMDC)整合后达到 87.6%,说明特征融合环节中上采样质量和跨阶段连接同样重要。
三模块联合实现了参数量和计算量的同步下降。最终模型的参数量(15.9MB)低于基线 ResNet18 骨干的参数量(19.9MB),GFLOPs 从 57.0 降至 52.4。这主要得益于 CSME 用轻量化设计替换了 ResNet18,以及 ASSA 中稀疏注意力分支减少了编码器的计算开销。

图片来源于原论文
五、总结与思考
本文提出的 CEA-DETR 以 RT-DETR-r18 为基线,通过 CSME 骨干网络、EMSFFN 特征融合网络和 ASSA 自适应稀疏自注意力三个模块的改进,在自建的 4468 张风电叶片缺陷数据集上将 mAP50 从 86.3% 提升至 89.4%(+3.1%),mAP50:95 从 62.4% 提升至 68.9%(+6.5%),同时参数量从 19.9MB 降至 15.9MB(-20.1%),GFLOPs 从 57.0 降至 52.4(-8.1%)。
模型轻量化为边缘部署提供了基础 。15.9MB 参数量和 52.4 GFLOPs 的计算开销,相比基线均有下降,对于无人机机载推理或风电场边缘计算节点部署较为友好。论文报告 CEA-DETR 的推理速度为 63.2 FPS(基线 RT-DETR-r18 为 65.5 FPS),速度略有下降但仍保持了良好的实时性,说明精度提升并未以大幅牺牲推理效率为代价。