小白入门大模型强化学习博客
大家好,我又来分享学习笔记啦!这次学了大模型里的强化学习,也就是大家常说的 RLHF,原来 ChatGPT、GPT-4 这么听话,能听懂人话、不会乱说话,都是靠这个技术!
我刚开始看的时候,一堆 Actor、Critic、PPO、DPO 的专业名词,直接看懵了,啃了好久才搞明白,干脆整理成这篇大白话博客,咱们一起学,一起搞懂大模型的核心技术!全程无晦涩公式,看完你也能搞懂 RLHF!
目录
-
先搞懂:强化学习到底是个啥?(#1-先搞懂强化学习到底是个啥)
-
大模型里的强化学习:RLHF 到底是啥?
-
RLHF 里的 4 个 "工具人",都是干嘛的?
-
传统 PPO 算法:为啥训练大模型这么贵?
-
砍成本第一步:能不能把 Critic 干掉?
-
砍成本第二步:能不能只靠 1 个模型搞定?
-
最后:这些算法,到底该选哪个?
1. 先搞懂:强化学习到底是个啥?
要学大模型的强化学习,咱们先从最基础的来,强化学习到底是个啥?
其实特别简单,就像你玩王者荣耀:
-
你就是智能体(Agent) ,游戏就是环境(Environment)
-
你做的操作,比如往左走、放技能,就是动作(Action)
-
你做完操作,游戏给你的反馈,比如拿到人头、加金币、赢了比赛,就是奖励(Reward)
你玩的多了,就学会了:什么样的操作能拿到更多奖励,能赢比赛,这个学习的过程,就是强化学习!
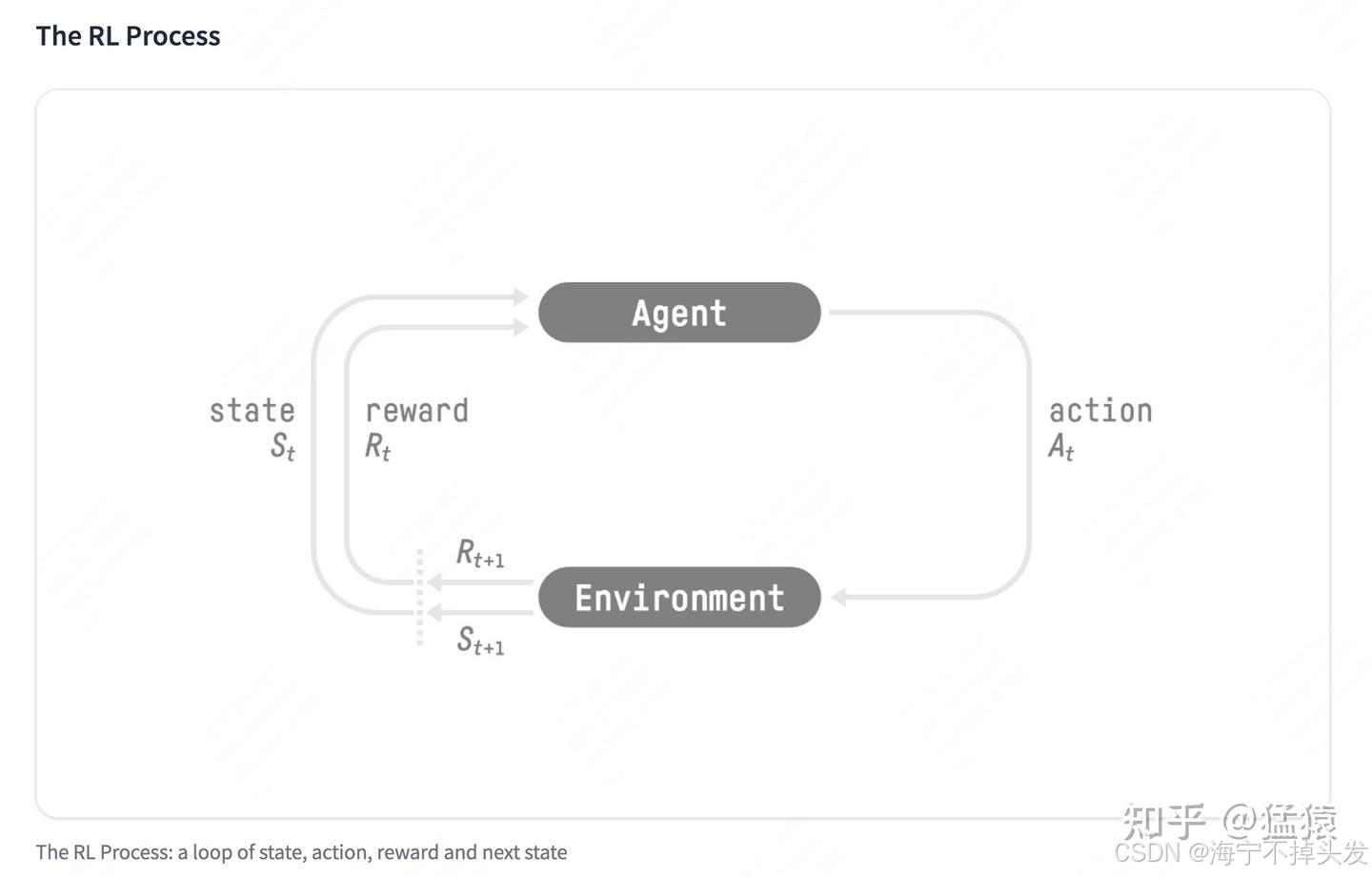
这里还有个小细节:不能只看眼前的奖励!比如你现在吃个小金币加 10 分,但是绕一下能吃个大金币加 100 分,那肯定选后者对吧?
这个就是价值函数,它帮你算:当前的动作,加上未来能拿到的所有奖励,总共能拿多少,这样就不会只看眼前,目光短浅啦。
2. 大模型里的强化学习:RLHF 到底是个啥?
搞懂了基础的强化学习,那放到大模型里,它是怎么工作的?这就是我们常说的RLHF,全称是「基于人类反馈的强化学习」,说白了就是:
我们人类给 AI 反馈,告诉它什么是好的回答,什么是坏的,AI 就用强化学习,学会怎么说人话,怎么符合人类的喜好。
那在大模型里,之前说的智能体、动作、奖励,都是啥呢?
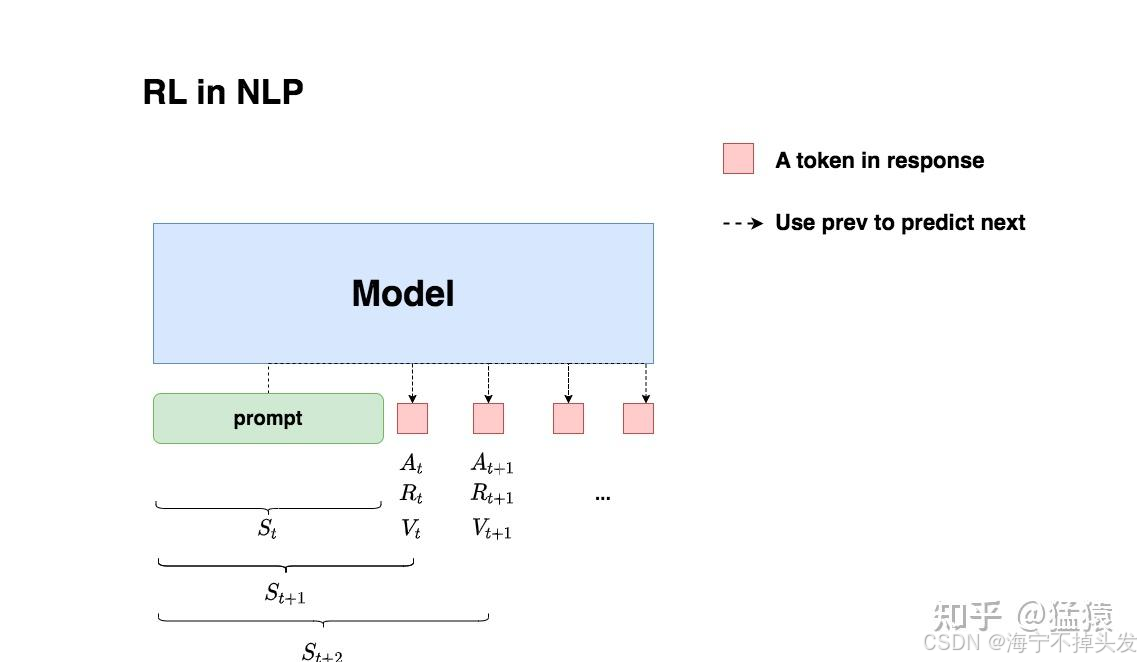
太好懂了:
-
AI 就是那个玩游戏的智能体!
-
它给你回答问题的时候,是一个字一个字往外蹦的对吧?每个字,就是它的一个动作!
-
我们给每个字打分:这个字说的好不好,有没有符合人类的喜好,这个就是奖励!
-
它就这么一个字一个字的学,慢慢就学会了:怎么说话,能拿到最高的奖励,也就是最符合人类的喜好!
是不是一下就懂了?原来这么简单!
3. RLHF 里的 4 个 "工具人",都是干嘛的?
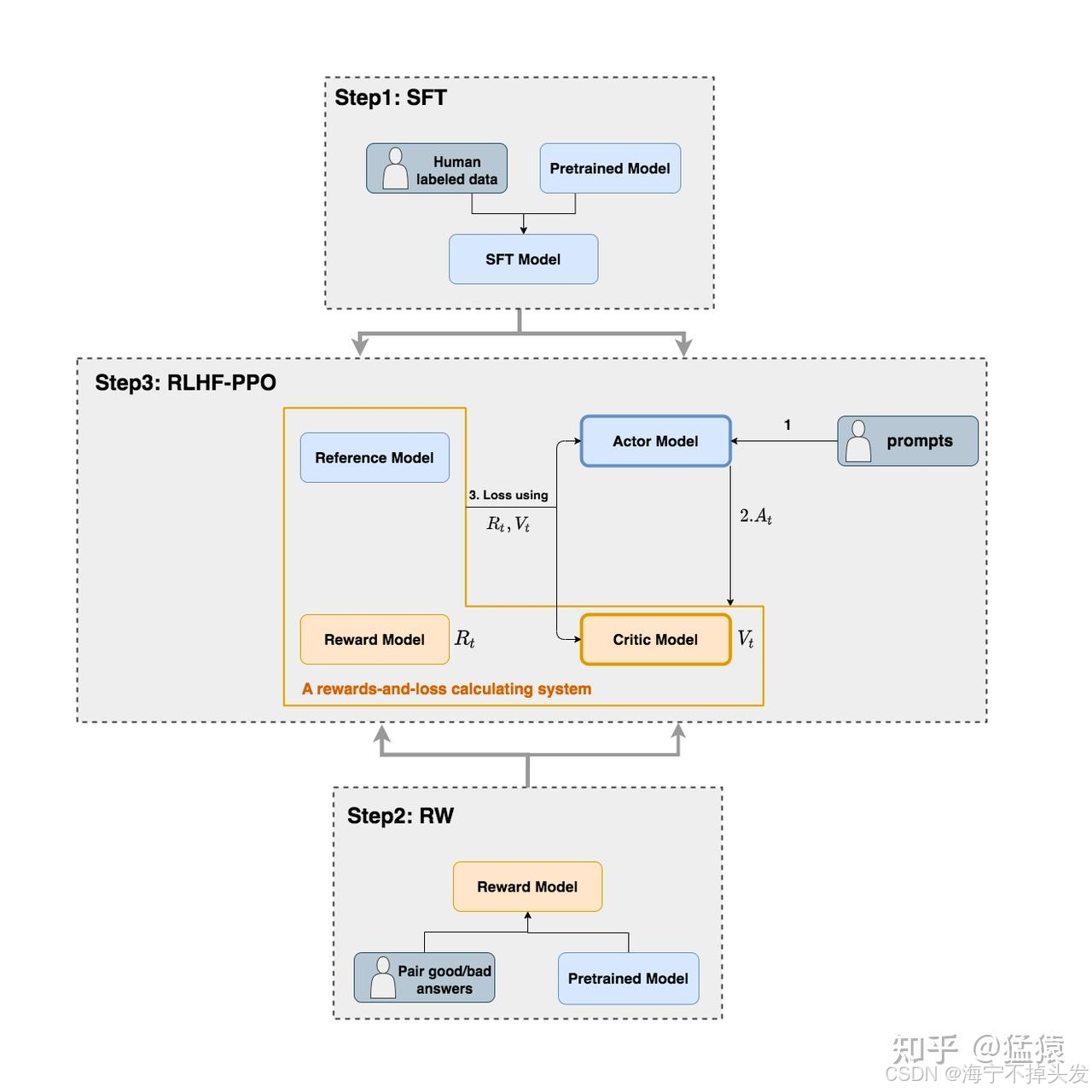
刚学 RLHF 的时候,我看到说要 4 个模型,直接懵了:搞个 AI 还要 4 个模型?都是干嘛的?
其实这四个就是分工不同的 "工具人",我给你翻译成大白话:
-
Actor Model(演员模型) :就是我们要教的学生!我们最终要的就是它,把它教的会说人话,就搞定了。
-
Reference Model(参考模型) :就是班长!它是学生原来的水平,防止学生学歪了 ------ 比如学生为了拿高分,乱说话,越学越离谱,班长就看着它:你不能和原来差太多哦!
-
Reward Model(奖励模型) :就是裁判!给学生写的答案打分,这个答案写的好不好,符不符合人类的喜好,它说了算。
-
Critic Model(评论家模型) :就是监考老师!帮学生预估一下:我现在写的这个字,最后整个答案能拿多少分?帮学生调整自己的动作。
你看,是不是就是一个老师教学生的场景?太形象了!
4. 传统 PPO 算法:为啥训练大模型这么贵?
最早的 RLHF,用的是 PPO 算法,也就是我们上面说的,四个模型一起跑,但是这个方法有个大问题:太贵了!
四个模型同时在显卡上跑,对显存的要求太高了,普通人根本玩不起,比如你要训个 7B 的模型,没个好点的显卡根本跑不动,这也是为啥原来大模型只有大公司能玩的原因。
那大家就想了:能不能把这些模型砍一砍?能不能少几个,降低训练成本?
于是就有了一堆新的算法,我们一个个来看!
5. 砍成本第一步:能不能把 Critic 干掉?
第一个想到的就是:监考老师(Critic)能不能不要?毕竟它也是个模型,占了不少显存,能不能把它砍了,省点钱?
还真可以!就有了两个新算法:ReMax 和 GRPO。
ReMax:用最优答案当 baseline
ReMax 的思路特别简单:
原来 Critic 是帮我们算一个 baseline(基准分),用来降低训练的方差,那我不用 Critic,用学生自己的最优答案当 baseline 行不行?
比如,给学生一个问题,让它先写一个最标准的答案(greedy 采样,就是它认为最好的答案),然后让它再探索一个新的答案,如果新的答案比这个标准分高,那我就鼓励它,不然就不鼓励。
这样就把 Critic 干掉了!效果有多好?
原来 PPO 跑不起来的 Llama-7B,用 ReMax,4 张 A800 显卡就能跑起来,不用任何额外的操作,而且训练速度还更快!
GRPO:用多个答案的平均分当 baseline
GRPO 的思路也差不多:还是砍 Critic,那我给同一个问题,让学生写好几个答案,把这几个答案的平均分当 baseline 行不行?
比如,我让学生写 5 个答案,这 5 个答案的平均分就是基准分,哪个答案比平均分高,我就鼓励它,比平均分低,我就惩罚它。
这样也不用 Critic 了,而且效果也很好!
6. 砍成本第二步:能不能只靠 1 个模型搞定?
把 Critic 干掉之后,还有三个模型:学生、班长、裁判,能不能再砍?能不能只靠一个模型,就像普通的训练一样简单?
还真可以!这就是 Offline 路线的算法,比如 DPO、ORPO 这些。
DPO:直接学好坏答案,不用别的模型
DPO 的思路更绝:我不用在线训练了,我直接拿一堆别人整理好的「好答案」和「坏答案」,让学生自己学行不行?
比如,同一个问题,有一个好的回答,一个坏的回答,我就让学生学:好的回答我要多学学,提高它出现的概率,坏的回答我要少学学,降低它出现的概率。
这样一来,我就不用裁判、不用监考老师了,只需要学生和班长两个模型,就搞定了!训练起来就和普通的 SFT 一样简单,普通人也能玩得起!
后来大家还在 DPO 的基础上做了很多优化,比如 DPOP 解决 DPO 训崩的问题,TDPO 加了 KL 惩罚防止学歪了。
ORPO:把班长也干掉,只留一个模型!
最狠的是 ORPO,它连班长(Reference Model)都干掉了!
它的思路是:我直接把 SFT 的 loss 和好坏答案的 loss 合在一起,一方面,我让学生学好答案,另一方面,我让它降低坏答案的概率,这样就不用班长了,只需要学生一个模型,就搞定了 RLHF!
我的天,原来要 4 个模型,现在直接砍到 1 个,训练起来和普通的微调一模一样,谁都能做了!
7. 最后:这些算法,到底该选哪个?
到这里,你已经搞懂了大模型里的强化学习,还有这些主流的算法,最后给大家总结一下,什么时候用哪个:
| 算法 | 需要的模型数量 | 特点 | 适用场景 |
|---|---|---|---|
| PPO | 4 个 | 最传统,效果稳定,但是成本高 | 大公司,有足够的算力 |
| ReMax/GRPO | 3 个 | 砍掉了 Critic,成本降了一半 | 中小团队,想训大一点的模型 |
| DPO/TDPO | 2 个 | 离线训练,简单方便 | 普通开发者,有好坏答案的数据 |
| ORPO | 1 个 | 只需要一个模型,和 SFT 一样简单 | 个人开发者,快速做对齐 |
是不是一下就清楚了?原来现在的 RLHF 已经这么亲民了,普通人也能玩得起了!
这部分内容我啃了好久,原来大模型的对齐技术已经发展这么快了,从原来的 4 个模型,砍到现在 1 个模型就能搞定,太厉害了!
整理成这篇博客,希望能帮到同样是小白的你,如果你跟着学遇到了问题,或者有什么想法,欢迎在评论区留言,咱们一起讨论,一起学习,一起进步!
如果你觉得这篇文章有用,别忘了点赞收藏关注哦,后续我还会分享更多大模型入门的内容,咱们一起打怪升级!