本文的目标:带你从"用锁的朴素队列"一步步演进到一个生产级的 SPSC 无锁队列。
目录
- [SPSC 到底是什么,它有什么用](#SPSC 到底是什么,它有什么用)
- [基准版本:用 mutex 的朴素队列](#基准版本:用 mutex 的朴素队列)
- 理解环形缓冲区
- [第一版无锁 SPSC:朴素原子版](#第一版无锁 SPSC:朴素原子版)
- 内存序:最容易翻车的地方
- 伪共享:看不见的性能杀手
- 缓存索引:再榨一把性能
- 生产级实现
- 正确性测试与性能基准
- 常见陷阱与注意事项
1. SPSC 到底是什么,它有什么用
SPSC = Single Producer, Single Consumer,单生产者单消费者队列。它是所有无锁队列里最简单、性能也最高的一种。
为什么简单?因为只有一个线程写、一个线程读:
- 写入端不需要和其他写入端竞争
- 读取端不需要和其他读取端竞争
- 只需要协调"写入端"和"读取端"之间的可见性
这意味着很多实现甚至不需要 CAS(compare-and-swap),只需要普通的原子读写加上正确的内存屏障就够了。
典型用途:
- 音频线程 ↔ UI 线程之间传递音频块
- 网卡接收线程 ↔ 数据包处理线程
- 日志线程的单个写入者 ↔ 刷盘线程
- 游戏逻辑线程 ↔ 渲染线程的命令队列
- FPGA/硬件 DMA 的数据搬运
只要你的场景能描述成"一个线程产生数据,另一个线程消费数据",SPSC 就是最合适的选择。永远不要用 MPMC 去做 SPSC 能搞定的事------那是白白浪费性能。
2. 基准版本:用 mutex 的朴素队列
先从最无脑的实现开始,建立一个性能参照;因为std::queue是线程不安全的,所以要加锁:
cpp
#include <mutex>
#include <queue>
template <typename T>
class MutexQueue {
public:
void push(T value) {
std::lock_guard<std::mutex> lock(mu_);
q_.push(std::move(value));
}
bool try_pop(T& out) {
std::lock_guard<std::mutex> lock(mu_);
if (q_.empty()) return false;
out = std::move(q_.front());
q_.pop();
return true;
}
private:
std::mutex mu_;
std::queue<T> q_;
};这段代码当然是正确的,但有几个明显的问题:
- 每次操作都要加锁/解锁,涉及原子操作、可能的系统调用、上下文切换。
- 生产者和消费者会互相阻塞,明明它们操作的是队列的不同端,即锁的粒度不够细,明明操作不一定是同一个节点,但是每次操作都是把整个队列锁住。
- 堆分配 :
std::queue默认底层是std::deque,入队出队会触发堆分配与释放,对缓存极不友好。 - mutex 本身会导致缓存行抖动:锁变量在两个核心之间来回弹。
在一个典型的桌面 CPU 上,这种实现每次 push/pop 大约需要 100--300ns 。我们的目标是做到 10ns 级别。
3. 理解环形缓冲区
无锁队列几乎总是基于环形缓冲区(ring buffer) 或者链表。SPSC 我们选环形缓冲区,因为它:
- 内存预分配,无动态分配
- cache 友好,数据连续
- 代码简单,只有两个索引需要维护
3.1 基本结构
用一个定长数组加上两个索引:write_idx(生产者的写入位置)和 read_idx(消费者的读取位置)。
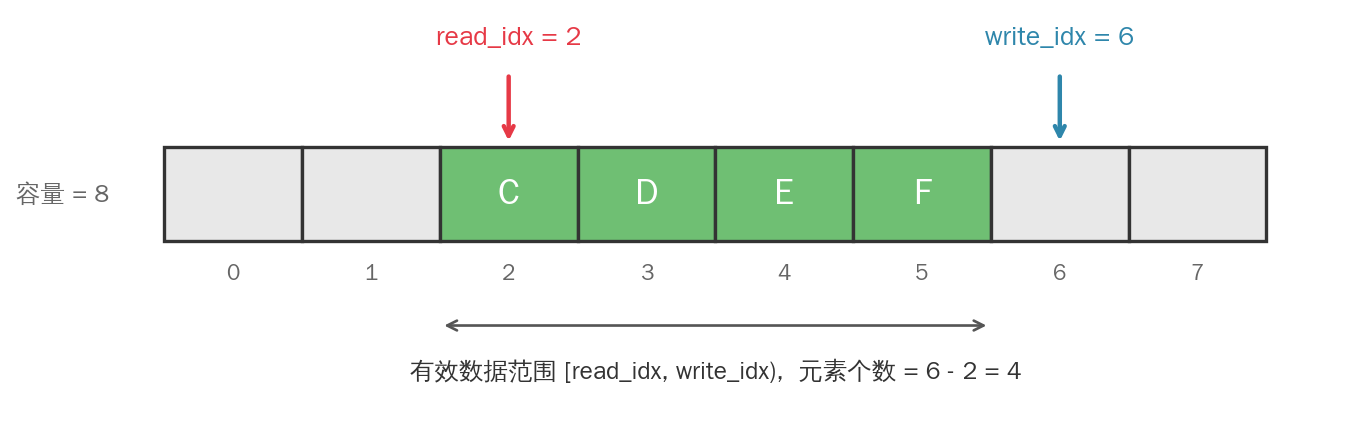
3.2 空与满的判断
这里有个经典坑点:如果 write_idx == read_idx 同时代表"空"和"满",就没法区分了。
有两种常见解法:
方法 A:留一个空位(浪费一个槽)
- 空:
write_idx == read_idx - 满:
(write_idx + 1) % capacity == read_idx
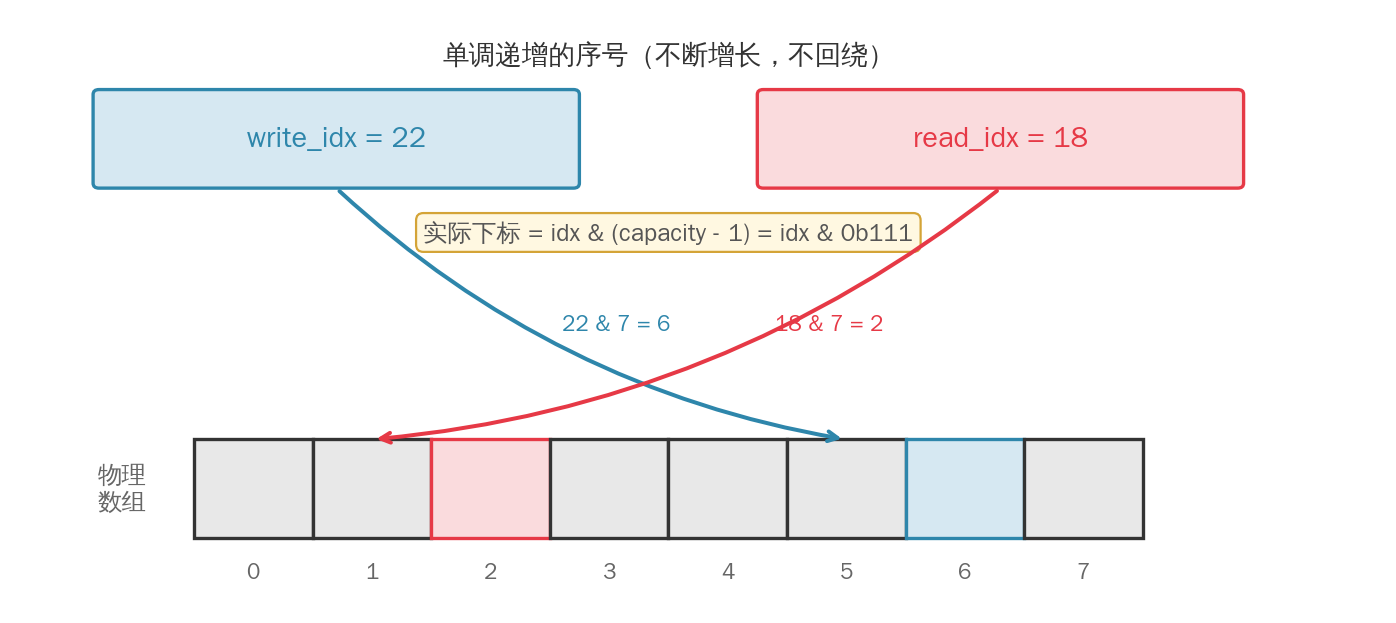
方法 B:使用单调递增的序号,用取模得到实际下标
- 空:
write_idx == read_idx - 满:
write_idx - read_idx == capacity - 数组下标:
idx & (capacity - 1)(容量必须是 2 的幂):
假设容量是8,那么对应下标有0、1、2、3、4、5、6、7共八个;8的二进制表示为00001000,07的二进制表示为0000000000000111;也就是说(capacity - 1) = 00000111,无论idx具体是多少,只要idx & (capacity - 1)就一定会映射到00000000~00000111,但这必须是建立在容量是2的幂的情况下。
同时这里使用**&操作相比求余操作**计算量更小(&操作单条 CPU 指令,1 个时钟周期完成;除法/取余是CPU最慢的整数运算之一,通常需要 20~90+个时钟周期)。
我们选方法 B,原因是:
- 不浪费槽位
- 空/满判断更直观
- 单调递增的序号对利用无符号整数溢出特性很友好(后面会用到)
示意图:
4. 第一版无锁 SPSC:朴素原子版
先写一版不考虑内存序、不考虑伪共享的"直觉版",看它哪里不对。
cpp
// ❌ 有问题的版本,仅用于演示
template <typename T, size_t Capacity>
class SpscQueueBad
{
// 00001000 & 00000111 = 00000000
static_assert((Capacity & (Capacity - 1)) == 0, "Capacity must be a power of 2");
public:
bool try_push(const T &value)
{
size_t w = write_idx_.load();
size_t r = read_idx_.load();
if (w - r >= Capacity)
return false; // 满
buffer_[w & (Capacity - 1)] = value;
write_idx_.store(w + 1);
return true;
}
bool try_pop(T &out)
{
size_t r = read_idx_.load();
size_t w = write_idx_.load();
if (r == w)
return false; // 空
out = buffer_[r & (Capacity - 1)];
read_idx_.store(r + 1);
return true;
}
private:
std::array<T, Capacity> buffer_; // 定长数组
std::atomic<size_t> write_idx_{0}; // 写下标--线性增长
std::atomic<size_t> read_idx_{0}; // 读下标--线性增长
};4.1 为什么 SPSC 不需要 CAS?
注意 try_push 只修改 write_idx_,try_pop 只修改 read_idx_。因为:
- 只有一个 生产者线程会碰
write_idx_ - 只有一个 消费者线程会碰
read_idx_
没有写入端之间的竞争,也就不需要 CAS。普通的 load + store 就够了。
4.2 这版代码有什么问题?
看起来好像没啥问题对吧?但它有两个致命问题:
-
内存序不正确 :默认的
load/store是memory_order_seq_cst(顺序一致),虽然"能工作",但过于保守,在弱内存模型架构(如 ARM)上会插入不必要的屏障。更关键的是,即使用默认的 seq_cst 是对的,如果有人"优化"成memory_order_relaxed,代码就彻底错了------编译器和 CPU 可能把数据写入重排到索引更新之后,消费者会读到未完成写入的垃圾数据。 -
伪共享 :
write_idx_和read_idx_很可能落在同一条 cache line 上,生产者和消费者会不断抢这条线,性能损失可能高达 10 倍。
5. 选择合适的内存序
5.1 问题的本质
编译器和 CPU 都可能重排指令以提升性能。在单线程内没有问题,但在多线程间,一个线程看到的另一个线程操作的顺序可能和源码不一致。上面分析过,使用memory_order_seq_cst是正确的,但是过于保守,会有不必要的屏障;但也不能无脑替换成memory_order_relaxed,这样会因为重排导致错误,例如下面使用memory_order_relaxed之后会产生的后果:
考虑这段生产者代码:
cpp
buffer_[w & mask] = value; // (1) 写数据
write_idx_.store(w + 1,std::memory_order_acquire); // (2) 更新索引执行(1)(2)之前,如果队列空且这两步被重排成 (2) 在 (1) 之前执行,消费者看到 write_idx_ 已更新就会去读 buffer_,读到的是旧值或未初始化数据。
同样,消费者这段:
cpp
out = buffer_[r & mask]; // (3) 读数据
read_idx_.store(r + 1,std::memory_order_acquire); // (4) 更新索引执行(3)(4)之前,如果队列为满且这两步被重排成 (4) 在 (3) 之前执行,生产者看到 read_idx_ 更新就可能覆写 buffer_,消费者读的是被覆盖后的数据。
5.2 Release / Acquire 语义
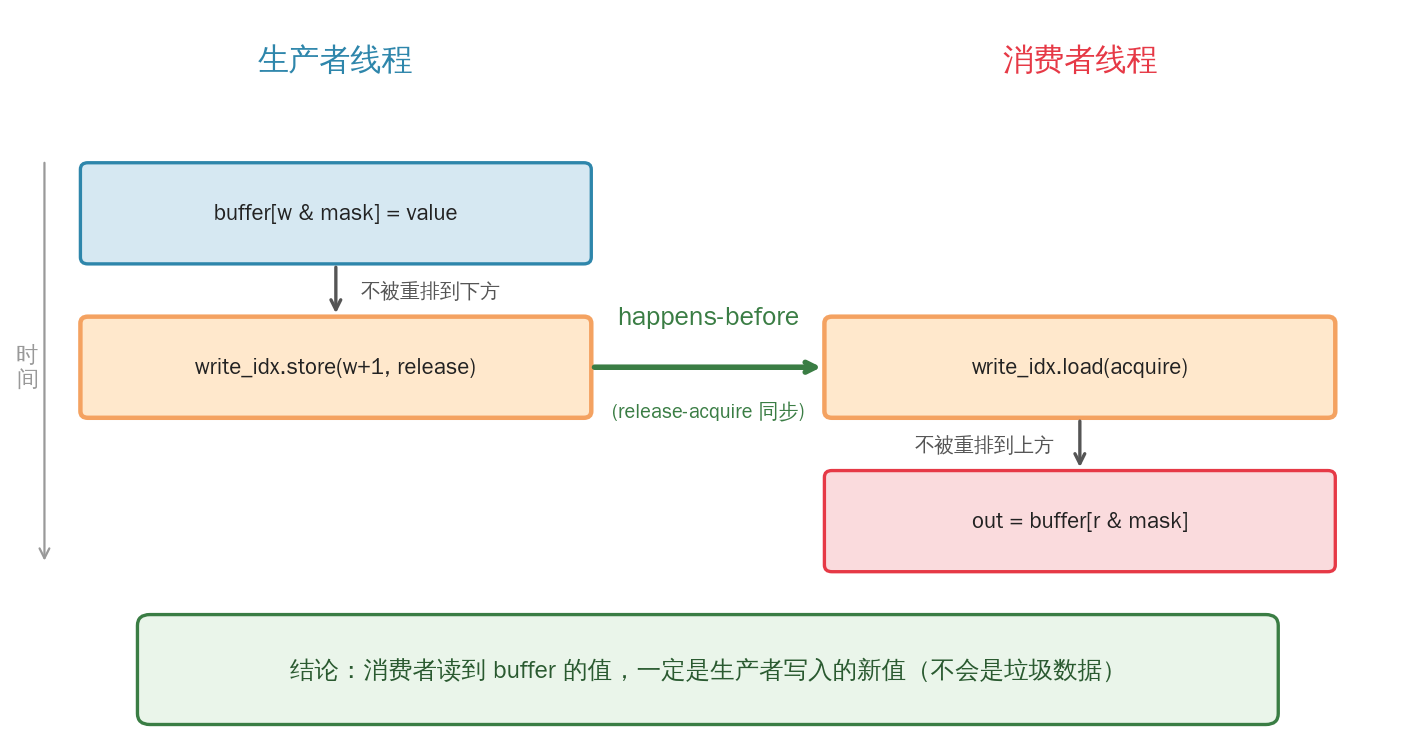
C++ 用 memory_order 描述同步关系。我们只需要两个:
release:在当前操作之前的所有读写,不会被重排到它之后。用于"发布"。acquire:在当前操作之后的所有读写,不会被重排到它之前。用于"获取"。
核心规则 :如果线程 A 的 release 写了某个变量,线程 B 以 acquire 读到了同一个变量 的那个值(或更新的值),那么 A 在 release 之前的所有写入对 B 在 acquire 之后都可见。
这形成了 happens-before 关系:
5.3 修正后的代码
cpp
bool try_push(const T& value) {
const size_t w = write_idx_.load(std::memory_order_relaxed); // relaxed
const size_t r = read_idx_.load(std::memory_order_acquire); // acquire ①
if (w - r >= Capacity) return false;
buffer_[w & (Capacity - 1)] = value; // ②
write_idx_.store(w + 1, std::memory_order_release); // release ③
return true;
}
bool try_pop(T& out) {
const size_t r = read_idx_.load(std::memory_order_relaxed); // relaxed
const size_t w = write_idx_.load(std::memory_order_acquire); // acquire ④
if (r == w) return false;
out = buffer_[r & (Capacity - 1)]; // ⑤
read_idx_.store(r + 1, std::memory_order_release); // release ⑥
return true;
}每一步的理由:
- 生产者加载自己 的
write_idx_用relaxed就行(对于write_idx_的写操作始终只有生产者一个线程进行写入,所以不会存在多线程的问题)。 - ① 生产者加载对方 的
read_idx_用acquire,是为了"观察"消费者的进度:消费者释放槽位(⑥ release)之后,生产者才能重用这些槽位(② 写入)。 - ③ 生产者发布
write_idx_用release,保证 ② 的数据写入对看到write_idx_更新的消费者可见。 - ④ 消费者加载
write_idx_用acquire,与 ③ 配对,保证看到数据。 - ⑤ 读数据。
- ⑥ 消费者发布
read_idx_用release,保证 ⑤ 的读取在释放槽位之前完成(否则生产者可能覆写数据,消费者读到新数据)。
5.4 一个直观的类比
把队列想象成一个信箱:
- 生产者写信(② 写数据),然后挂上"有新信"的牌子(③ release store)。
- 消费者先看牌子(④ acquire load)------看到了才去开信箱(⑤ 读数据)。
- 消费者读完后再挂上"已取走"的牌子(⑥ release store)。
- 生产者下次要投新信之前先看"已取走"的牌子(① acquire load)------确认旧信被取走了才复用槽位(② 写数据)。
release/acquire 保证了**"挂牌子"这个动作前后的操作不会跨越牌子**。
6. 伪共享:看不见的性能杀手
6.1 什么是伪共享(false sharing)
现代 CPU 的缓存以 cache line (典型 64 字节)为最小单位。当两个核心分别频繁修改同一条 cache line 上的不同变量时,会触发缓存一致性协议(MESI 等)不断在核心间传递这条 line 的所有权,即使它们操作的是不同的变量。这就是伪共享。
对于上面的代码:

实测下来,伪共享能让性能下降 5--10 倍。这通常是无锁队列最大的性能瓶颈,比内存序还关键。
6.2 解决方案:cache line 对齐
C++17 以后有 std::hardware_destructive_interference_size,但许多编译器(比如 GCC 12 之前)支持不完整,实际项目里直接硬编码 64 字节最稳。
cpp
static constexpr size_t kCacheLine = 64;
alignas(kCacheLine) std::atomic<size_t> write_idx_{0};
alignas(kCacheLine) std::atomic<size_t> read_idx_{0};布局变成:
现在:
- 生产者修改
write_idx_只影响 line 1 - 消费者修改
read_idx_只影响 line 2 - 两个核心不再互相抢缓存行
6.3 容易忽略的细节:buffer 本身的位置
除了索引,buffer_ 数组也要注意。如果 buffer 紧贴着其中一个索引,可能和索引共享一条 cache line。建议也显式对齐,或者在 buffer 两侧加 padding。
另外,整个 SpscQueue 对象后面如果紧跟着别的变量,也可能产生伪共享(外部对象干扰队列末尾的变量)。生产级实现会在最后加一段 padding 保护。
7. 缓存索引:再榨一把性能
7.1 观察:原子 load 也不是免费的
即使没有伪共享,每次 try_push 都要 load(acquire) 一次 read_idx_,这个原子操作:
- 在 x86 上等价于普通 load(还好)
- 在 ARM 上需要
ldar指令,比普通 load 贵 - 更关键的是:这个 load 会让
read_idx_所在的 cache line 进入生产者核心的共享状态,而消费者要写这条 line 时又得把它从共享变成独占,触发一致性流量
7.2 核心观察
绝大多数情况下,队列不会满也不会空。也就是说:
- 生产者检查
read_idx_时,通常发现还有很多空位 - 消费者检查
write_idx_时,通常发现还有很多元素
那我们何必每次都去读对方的原子变量呢?
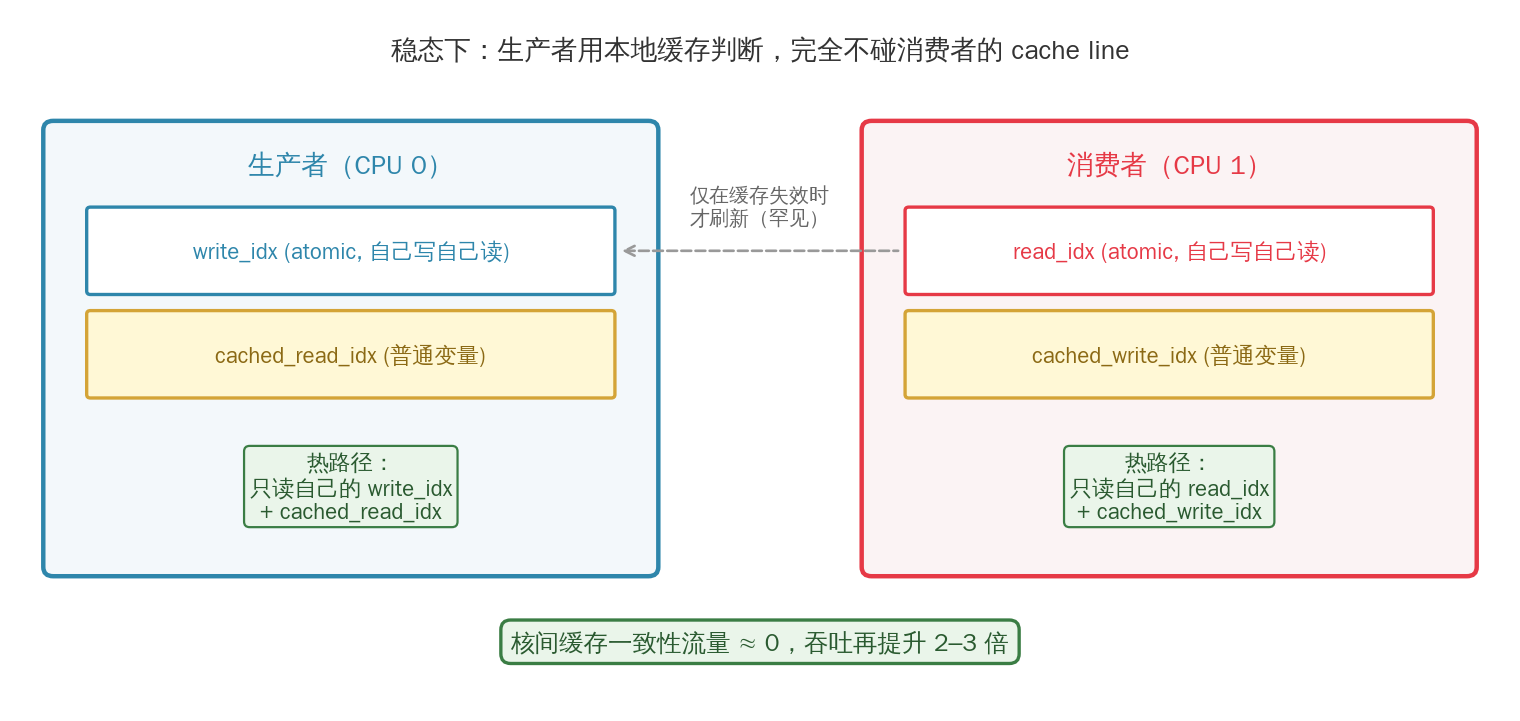
7.3 缓存索引的思路 -- 减少load操作
给生产者一个本地变量 cached_read_idx_,保存"上次看到的 read_idx_"。
- 检查队列是否满时,先用缓存判断:如果缓存显示还有空间,根本不用去碰原子变量
- 只有缓存显示可能满了,才真的去
load一次原子值(刷新缓存)
消费者同理,维护一个本地的 cached_write_idx_。
7.4 生产者的逻辑
cpp
bool try_push(const T& value) {
const size_t w = write_idx_.load(std::memory_order_relaxed);
// 先用缓存判断是否满
if (w - cached_read_idx_ >= Capacity) {
// 缓存显示满了,刷新一次
cached_read_idx_ = read_idx_.load(std::memory_order_acquire);
// 再判断一次
if (w - cached_read_idx_ >= Capacity) {
return false; // 真的满了
}
}
buffer_[w & (Capacity - 1)] = value;
write_idx_.store(w + 1, std::memory_order_release);
return true;
}正确性论证 :cached_read_idx_ 可能比真实的 read_idx_ 小(落后),但不会更大(因为消费者只会让 read_idx_ 变大)。所以:
- 如果
w - cached_read_idx_ < Capacity,那真实差值更小,肯定不满,安全写入。 - 如果
w - cached_read_idx_ >= Capacity,可能是真满,也可能缓存过时,所以要刷新后再判断。
7.5 效果
在稳态下(队列不满不空),生产者完全不访问 read_idx_ 这条 cache line,反之亦然。这把两个核心间的缓存一致性流量降到了几乎为零,通常能再提升 2--3 倍吞吐。
这个技巧在 LMAX Disruptor、moodycamel、boost::lockfree 里都有使用。
7.6 优化后的代码
cpp
#define START std::chrono::high_resolution_clock::now()
#define END std::chrono::high_resolution_clock::now()
#define DURATION(start, end) std::chrono::duration_cast<std::chrono::nanoseconds>(((end) - (start))).count()
#define QUERY 100000
#define CAPACITY 1024
static constexpr size_t kCacheLine = 64;
template <typename T, size_t Capacity>
class SpscQueue
{
// 00001000 & 00000111 = 00000000
static_assert((Capacity & (Capacity - 1)) == 0, "Capacity must be a power of 2");
public:
bool try_push(const T &value)
{
size_t w = write_idx_.load(std::memory_order_relaxed);
// size_t r = read_idx_.load(std::memory_order_acquire); // 这里读取到的r主要用于判断队列是否已满
// if (w - r >= Capacity)
// return false;
// 使用缓存,减少read_idx_的读取频率,提升性能
if(w - cached_read_idx_ >= Capacity)
{
cached_read_idx_ = read_idx_.load(std::memory_order_acquire);
if(w - cached_read_idx_ >= Capacity)
{
return false; // 满
}
}
buffer_[w & (Capacity - 1)] = value;
write_idx_.store(w + 1, std::memory_order_release);
return true;
}
bool try_pop(T &out)
{
size_t r = read_idx_.load(std::memory_order_relaxed);
// size_t w = write_idx_.load(std::memory_order_acquire); // 这里读取到的w主要用于判断队列是否为空
// if (r == w)
// return false; // 空
if(r == cached_write_idx_)
{
cached_write_idx_ = write_idx_.load(std::memory_order_acquire);
if(r == cached_write_idx_)
{
return false; // 空
}
}
out = buffer_[r & (Capacity - 1)];
read_idx_.store(r + 1, std::memory_order_release);
return true;
}
private:
std::array<T, Capacity> buffer_; // 定长数组
alignas(kCacheLine) std::atomic<size_t> write_idx_{0}; // 写下标--线性增长
size_t cached_read_idx_{0}; // 读下标缓存
alignas(kCacheLine) std::atomic<size_t> read_idx_{0}; // 读下标--线性增长
size_t cached_write_idx_{0}; // 写下标缓存
};
SpscQueue<int, CAPACITY> queue;
void producer()
{
for(int i = 0; i < QUERY; ++i)
{
while(!queue.try_push(i))
{
std::this_thread::yield();
}
}
}
void consumer()
{
std::vector<int> nums;
int num = 0;
for(int i = 0; i < QUERY; ++i)
{
while(!queue.try_pop(num))
{
std::this_thread::yield();
}
nums.emplace_back(num);
}
for(int i = 0; i < QUERY; ++i)
{
if(nums[i] != i)
{
std::cout << "false" << std::endl;
return;
}
}
std::cout << "true" << std::endl;
}
int main()
{
auto start = START;
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
auto end = END;
std::cout << "Duration: " << DURATION(start, end) << " ns" << std::endl;
return 0;
}实测优化效果是原来性能的3倍左右: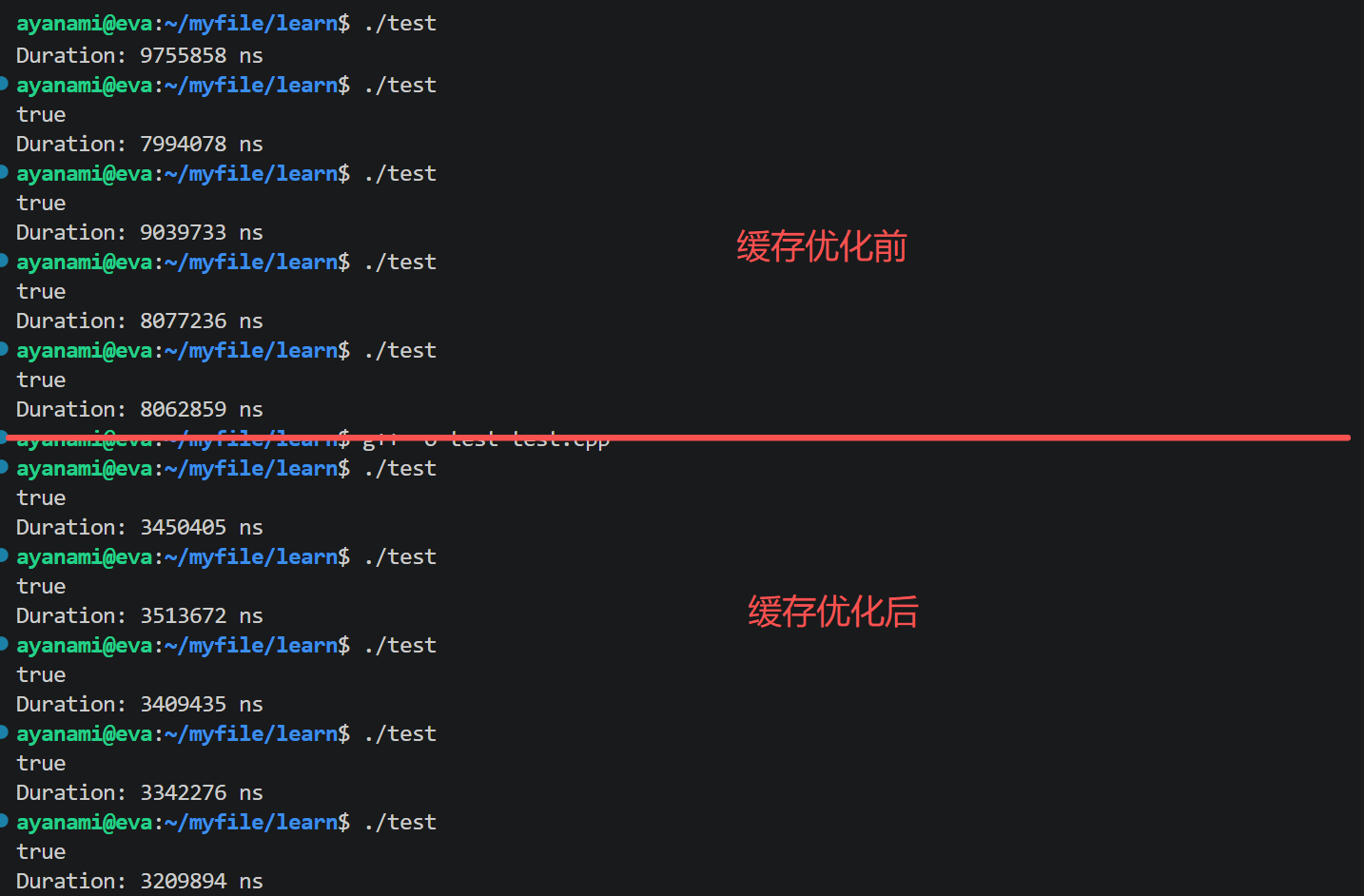
8. 生产级实现
把前面所有的优化整合起来。为了能支持不可默认构造的类型(如 std::unique_ptr<T>),我们用 placement new 手动管理对象生命周期。
cpp
#include <atomic>
#include <cstddef>
#include <cstdint>
#include <new> // placement new, std::launder
#include <type_traits>
#include <utility>
template <typename T, std::size_t Capacity>
class SpscQueue
{
static_assert(Capacity >= 2, "Capacity must be at least 2");
static_assert((Capacity & (Capacity - 1)) == 0, "Capacity must be a power of 2");
static constexpr std::size_t kCacheLine = 64;
static constexpr std::size_t kMask = Capacity - 1;
public:
SpscQueue() = default;
~SpscQueue()
{
// 析构残留元素
std::size_t r = read_idx_.load(std::memory_order_relaxed);
const std::size_t w = write_idx_.load(std::memory_order_relaxed);
while (r != w)
{
slot(r)->~T();
++r;
}
}
SpscQueue(const SpscQueue &) = delete;
SpscQueue &operator=(const SpscQueue &) = delete;
SpscQueue(SpscQueue &&) = delete;
SpscQueue &operator=(SpscQueue &&) = delete;
// --- 生产者接口(只能被一个线程调用)---
template <typename... Args>
bool try_emplace(Args &&...args)
{
const std::size_t w = write_idx_.load(std::memory_order_relaxed);
if (w - cached_read_idx_ >= Capacity)
{
cached_read_idx_ = read_idx_.load(std::memory_order_acquire);
if (w - cached_read_idx_ >= Capacity)
{
return false;
}
}
::new (raw_slot(w)) T(std::forward<Args>(args)...);
write_idx_.store(w + 1, std::memory_order_release);
return true;
}
bool try_push(const T &value)
{
return try_emplace(value);
}
bool try_push(T &&value)
{
return try_emplace(std::move(value));
}
// --- 消费者接口(只能被一个线程调用)---
bool try_pop(T &out)
{
const std::size_t r = read_idx_.load(std::memory_order_relaxed);
if (r == cached_write_idx_)
{
cached_write_idx_ = write_idx_.load(std::memory_order_acquire);
if (r == cached_write_idx_)
{
return false;
}
}
T *p = slot(r);
out = std::move(*p);
p->~T(); // 对象被析构了(~T()),但队列的内存没有被释放
read_idx_.store(r + 1, std::memory_order_release);
return true;
}
// --- 查询接口(近似值,仅供参考)---
std::size_t size_approx() const noexcept
{
const std::size_t w = write_idx_.load(std::memory_order_acquire);
const std::size_t r = read_idx_.load(std::memory_order_acquire);
return w - r;
}
bool empty_approx() const noexcept
{
return size_approx() == 0;
}
static constexpr std::size_t capacity() noexcept
{
return Capacity;
}
private:
// 原始存储槽的地址
void *raw_slot(std::size_t idx) noexcept
{
return &storage_[(idx & kMask) * sizeof(T)];
}
// 已构造的 T* 视角(用 launder 规避严格别名问题,不能通过一种类型的指针,去访问另一种类型的对象。)
// 内存里存的实际是std::byte,但用T* 去访问,编译器认为这是未定义行为,所以需要 std::launder 来告诉编译器,这个指针是合法的,可以用来访问 T 对象。
// std::launder(p):保证这块内存里真的有一个 T 对象,把这个指针变成合法可用的指针。
T *slot(std::size_t idx) noexcept
{
// reinterpret_cast<T*>:只是强行改变指针类型,但不合法。
// std::launder:让这个指针变得合法、安全、符合标准。
return std::launder(reinterpret_cast<T *>(raw_slot(idx)));
}
private:
// 存储区:未初始化的字节数组,按 T 对齐
// std::byte 是 C++17 专门用来表示「纯原始内存 / 字节」的类型,它不参与任何类型运算、不隐式转整数
// std::byte 作用是提供未初始化的原始内存,申请一块足够大、对齐正确、但还没有构造任何 T 对象的内存区域。
// std::byte 只代表1 字节原始内存,没有任何语义,不会自动调用任何构造 / 析构函数,不会被当成整数、字符使用,完全是"空白画布",方便后续用 placement new 在上面构造对象;这正是无锁队列需要的:预先分配内存,延迟构造对象。
// 为什么不用T[]:
// 1、会立刻构造 Capacity 个 T 对象(队列还没使用就构造了,浪费、错误、可能有副作用)
// 2、无锁队列需要手动控制对象构造 / 析构
// 3、会导致重复构造、重复析构,引发崩溃
// 而 std::byte 完全没有这个问题,它只是字节,不是对象。
// 为什么不用void*?因为void* 无法直接定义数组,无法计算偏移,无法分配栈 / 静态内存,不适合做固定大小的存储区。
alignas(T) std::byte storage_[Capacity * sizeof(T)];
// --- 生产者 cache line ---
alignas(kCacheLine) std::atomic<std::size_t> write_idx_{0};
std::size_t cached_read_idx_{0};
char pad_producer_[kCacheLine - sizeof(std::atomic<std::size_t>) - sizeof(std::size_t)]{};
// --- 消费者 cache line ---
alignas(kCacheLine) std::atomic<std::size_t> read_idx_{0};
std::size_t cached_write_idx_{0};
char pad_consumer_[kCacheLine - sizeof(std::atomic<std::size_t>) - sizeof(std::size_t)]{};
// 尾部 padding:防止外部对象污染消费者 cache line
char pad_end_[kCacheLine]{};
};8.1 设计要点回顾
- 容量限制:2 的幂且至少为 2。
- 对齐 :
write_idx_和read_idx_各占独立 cache line,cached_*放在各自一侧,末尾加 padding。 - 内存序:写端 release、读端 acquire;自己的索引用 relaxed load。
- 缓存索引 :
cached_read_idx_只被生产者读写,cached_write_idx_只被消费者读写,不是原子的。 - 元素生命周期 :使用
alignas(T)字节数组做存储,placement new构造,手动析构。std::launder是 C++17 引入的,为了在严格别名规则下合法访问 placement new 后的对象。 - 禁用拷贝与移动:队列包含原子变量和内部指针相关状态,跨线程搬运无意义且容易出错。
8.2 关于 size_t 溢出
write_idx_ 和 read_idx_ 单调递增,最终会溢出 size_t。在 64 位系统上,size_t 是 2⁶⁴,即使每纳秒自增一次也要 500 多年才溢出,完全不用担心。
更妙的是,w - r 这类无符号减法在溢出发生时也能正确工作------因为无符号整数的减法是定义良好的模算术,只要真实的队列长度不超过 2⁶³ 就不会出错(而真实长度 ≤ Capacity,远小于这个数)。
在 32 位系统上,每秒千万级操作可能几分钟就溢出一次。虽然数学上仍然正确,但要做额外验证。大多数现代系统都是 64 位,可以安心用。
9. 正确性测试与性能基准
9.1 正确性测试:序列号验证
最可靠的测试是让生产者发送单调递增的序列号,消费者验证收到的序列号严格递增且无遗漏。
cpp
// test_spsc.cpp
#include "spsc_queue.hpp"
#include <atomic>
#include <cassert>
#include <chrono>
#include <cstdint>
#include <iostream>
#include <thread>
int main() {
constexpr std::size_t kCap = 1024;
constexpr std::uint64_t kN = 10'000'000;
SpscQueue<std::uint64_t, kCap> q;
std::thread producer([&] {
for (std::uint64_t i = 0; i < kN; ) {
if (q.try_push(i)) {
++i;
}
// 满了就自旋;实际项目里可以挂起或让出 CPU
}
});
std::thread consumer([&] {
std::uint64_t expected = 0;
std::uint64_t value;
while (expected < kN) {
if (q.try_pop(value)) {
assert(value == expected && "序列号不连续,队列有 bug!");
++expected;
}
}
});
producer.join();
consumer.join();
std::cout << "Passed: " << kN << " items in order.\n";
return 0;
}9.2 吞吐量基准
cpp
// bench_spsc.cpp
#include "spsc_queue.hpp"
#include <chrono>
#include <cstdint>
#include <iostream>
#include <thread>
int main() {
constexpr std::size_t kCap = 1024;
constexpr std::uint64_t kCount = 100'000'000;
SpscQueue<std::uint64_t, kCap> q;
auto t0 = std::chrono::steady_clock::now();
std::thread producer([&] {
for (std::uint64_t i = 0; i < kCount; ) {
if (q.try_push(i)) ++i;
}
});
std::thread consumer([&] {
std::uint64_t v;
std::uint64_t n = 0;
while (n < kCount) {
if (q.try_pop(v)) ++n;
}
});
producer.join();
consumer.join();
auto t1 = std::chrono::steady_clock::now();
auto ns = std::chrono::duration_cast<std::chrono::nanoseconds>(t1 - t0).count();
std::cout << "Total: " << kCount << " items\n"
<< "Elapsed: " << ns / 1'000'000 << " ms\n"
<< "Throughput: " << (kCount * 1'000'000'000.0 / ns)
<< " ops/sec\n"
<< "Per op: " << double(ns) / kCount << " ns\n";
return 0;
}编译命令:
bash
g++ -O3 -std=c++17 -pthread bench_spsc.cpp -o bench_spsc在一台典型的桌面 CPU(Intel i7 / AMD Ryzen)上,单条路径大约 5--15 ns/op 。对比 mutex 版本的 ~200 ns/op,提升是 一到两个数量级。
9.3 推荐的其他测试
实战中还应该加上:
- ASan / TSan :用
-fsanitize=thread跑一遍,确认没有数据竞争。 - 随机停顿 :在生产者和消费者的循环里随机
sleep,模拟不均衡速度,验证队列能正确处理满/空。 - 不同类型测试 :
std::string、std::unique_ptr、自定义 move-only 类型。 - 析构测试:在没清空的队列上析构,用带统计的类型(RAII 计数器)验证没有泄漏、没有重复析构。
10. 常见陷阱与注意事项
10.1 "单生产者"到底意味着什么
SPSC 的"单"指的是整个程序运行期间 ,始终 只有一个固定的线程 调用 try_push。消费者同理。
不合法的用法:
- 线程池里随便挑一个线程调用
try_push(即使保证同一时刻只有一个在调用)------因为换线程调用时,前一个线程的写入对新线程来说不一定可见,除非你自己加同步。 - 主线程初始化阶段 push 了一些数据,然后把队列交给工作线程 push ------这种"切换生产者"的模式需要一次显式同步(比如
std::thread构造本身提供的 happens-before 就够了)。
如果你需要多个线程轮流当生产者,请改用 MPSC 或 MPMC。
10.2 不要在同一个线程里既 push 又 pop
不是绝对禁止,但很容易写出 bug。比如:
cpp
// 危险:如果队列满了就死循环
while (!q.try_push(x)) {} // 等不到有人 pop如果当前线程同时负责消费,自旋等待 push 成功会导致死锁。正确做法:
- 区分生产者线程和消费者线程
- 如果真的单线程就不需要无锁队列
10.3 try_pop 的 out 参数要 movable 或 copyable
上面实现用 out = std::move(*p),要求 T 至少可以 move-assign。如果 T 只有 move 构造(常见于某些资源类),可以改成:
cpp
bool try_pop(T& out) {
// ...
T* p = slot(r);
out = std::move(*p); // 若 T 无 move-assign 会编译失败
p->~T();
// ...
}对于更通用的接口,可以提供 T consume() 或者传 lambda:
cpp
template <typename F>
bool try_consume(F&& f); // f 接受 T&&10.4 队列满了怎么办?
SPSC 队列通常有界。满了的常见策略:
- 丢弃:最新数据最重要,丢历史。适合行情、传感器采样。
- 阻塞等待 :用 condition variable 或
std::this_thread::yield()。失去无锁的优势,但语义上是无损的。 - 自旋 + 回退:先短自旋,再 yield,再 sleep。适合低延迟系统。
- 反压:让生产者变慢。适合流处理。
- 扩容:SPSC 下非常难做对,一般不做。需要扩容就改链表实现。
10.5 不要把队列作为临时对象跨线程传递
SpscQueue 被设计成长期存在的对象,通常是全局、成员或堆分配后共享指针持有。把它作为函数参数在栈上构造再传给另一个线程是自找麻烦:栈对象随函数返回销毁,另一边正在读写就是 UAF。
10.6 数据结构和控制结构不要混在一条 cache line
如果 T 很大(比如一个 1KB 的音频块),buffer 本身就占多条 cache line,不会和索引冲突;
如果 T 很小(比如 int),capacity 又小,buffer 可能几十字节,容易和相邻字段落在一起。用 alignas(kCacheLine) 给 buffer 前加对齐也是好习惯。
上面的生产级实现已经为索引做了对齐,而 storage_ 在索引之前,加上索引各自 64 字节对齐,实际布局是安全的------但如果你改动成员顺序,务必手动验证 sizeof 和 offsetof。
10.7 relaxed 用在哪里,什么时候不能用
- 自己的索引自己读 :用
relaxed,因为没有跨线程同步需求。 - 对方的索引 :必须
acquire(读)/release(写),用来同步数据本身。 - 初始化阶段 :构造函数里把索引置 0,不需要原子操作(对象还没被其他线程看到)。但要保证构造完成之前 对象地址没被其他线程观察到,通常靠
std::thread构造的 happens-before 自然满足。
10.8 要不要用 std::hardware_destructive_interference_size
C++17 提供了这个常量表示 cache line 大小,但实际坑:
- GCC 12 之前默认不启用(链接错误)
- 不同编译器报告的值不同(有的是 64,有的是 128)
- 同一程序跨架构编译时可能不一致
推荐做法:直接硬编码 64,并在架构特殊时(如 Apple M1 的 128 字节)加宏处理。工业界更倾向于硬编码 + 注释。
11.总结
一个生产级 SPSC 队列,核心要点就四个:
- 环形缓冲区 + 2 的幂容量,用位与代替取模;
- 生产者和消费者的索引分别放在独立 cache line,消除伪共享;
- release / acquire 配对,保证数据可见性;
- 缓存对方索引,让稳态下的热路径不触碰对方的 cache line。
每一步都对应一个具体的硬件/语言行为:
- 缓存行、缓存一致性协议 → 伪共享
- CPU 重排、编译器重排 → 内存序
- 核间缓存一致性流量 → 缓存索引