130万对像素级对齐:SOMA-1M如何打通遥感多模态数据的"最后一公里"
副标题:SOMA-1M: A Large-Scale SAR-Optical Multi-resolution Alignment Dataset for Multi-Task Remote Sensing 深度解读
"数据对齐精度,决定了多模态遥感模型能力的天花板。"
导语:这篇论文为什么值得关注?
在遥感领域,光学影像和合成孔径雷达(SAR)影像就像一对性格迥异的搭档:光学影像色彩丰富、纹理清晰,但一遇到云层遮挡就"失明";SAR则能全天候穿透云雾,靠的是微波散射的几何结构信息。两者的互补性让"SAR-光学协同处理"成为遥感智能化的核心方向之一。
然而,想把这对搭档真正撮合在一起,远比想象中困难。现有公开数据集普遍存在三大硬伤:分辨率单一 (大多是10米级中低分辨率)、数据规模不足 (通常只有几万对样本)、对齐精度不够(地理坐标级粗对齐导致像素错位)。对于图像融合、跨模态翻译这类像素级敏感任务,哪怕只有几个像素的偏差,模型学出来的也是"带噪声的幻觉"。
武汉大学遥感信息工程学院团队推出的 SOMA-1M ,正是冲着这个瓶颈来的。这个名字代表 SAR-Optical Multi-resolution Alignment ,它带来了遥感领域首个百万级规模、像素级精度、显式多分辨率覆盖(0.5m / 3m / 10m)的SAR-光学对齐数据集。更重要的是,作者不仅造了数据集,还用四大主流视觉任务(图像匹配、图像融合、SAR辅助去云、SAR-光学图像翻译)的系统评测,验证了"高质量对齐数据"对模型泛化能力的决定性作用。
读完本文,你会带走什么?
- 理解为什么"像素级对齐"是多模态遥感模型的隐形天花板
- 掌握SOMA-1M从数据采集到粗精对齐的完整工程 pipeline
- 看清不同空间分辨率对几何任务、像素任务、生成任务的差异化影响
核心速览:1分钟get论文全貌
| 维度 | 内容 |
|---|---|
| 论文标题 | SOMA-1M: A Large-Scale SAR-Optical Multi-resolution Alignment Dataset for Multi-Task Remote Sensing |
| 作者团队 | Peihao Wu, Yongxiang Yao, Yi Wan, Wenfei Zhang, Ruipeng Zhao, Jiayuan Li, Yongjun Zhang(武汉大学) |
| 发表信息 | arXiv:2602.05480 (2026) |
| 核心问题 | 现有SAR-光学数据集在规模、分辨率多样性、对齐精度上无法支撑多尺度基础模型训练 |
| 核心方法 | 融合Sentinel-1/PIESAT-1/Capella Space/Google Earth数据,设计基于MapGlue的粗到精自动配准框架 |
| 关键结果 | 仅用10%数据(SOMA-0.1M)微调,即可在图像匹配任务上达到SOTA,且多任务性能显著提升 |
| 适合读者 | 遥感AI研究者、多模态学习工程师、地球科学基础模型开发者 |
正文解读
01|问题:前人到底卡在了哪里?
背景铺垫
SAR和光学的协同处理,本质上是在做一件"跨模态翻译"的工作:把SAR的散射语义和光学的光谱语义,映射到同一个可计算的空间里。这件事的应用场景非常广泛------
- 图像匹配:给SAR和光学影像找对应点,是三维重建、变化检测的第一步;
- 图像融合:把SAR的结构信息和光学的颜色信息合成到一张图里;
- SAR辅助去云:光学影像被云遮住时,用SAR作为结构先验恢复地面信息;
- SAR-光学翻译:直接用生成模型把SAR"画"成光学影像。
这些任务看起来方向不同,但它们有一个共同的前提:输入的SAR和光学影像必须在像素级别上严格对齐。一旦对齐有偏差,匹配点会飘移、融合结果会出现鬼影、去云和翻译会在错误的位置补出错误的纹理。
现有方法的瓶颈
作者把现有公开数据集的问题归纳为**"规模-分辨率-对齐精度"不可能三角**:
- 低中分辨率数据集:以 SEN12MS、SEN12MS-CR、SSL4EO-S12 为代表,基于Sentinel-1/2构建,分辨率约10米,规模可达十万甚至百万级。但10米分辨率无法分辨建筑物轮廓、车辆、道路标线等细粒度目标;更重要的是,它们大多只做了地理坐标级粗对齐,SAR侧视成像在非平坦地形区域会造成严重的局部像素错位。
- 高分辨率数据集:以 SpaceNet 6(0.5m)、OSdataset(1m)、UBCv2(0.5m)、EarthMiss(0.6m)为代表,像素级对齐精度较好,但规模通常只有1-2万对。样本量和地理多样性不足,导致模型容易过拟合,泛化到新场景时性能骤降。
- 新兴多分辨率/基础模型数据集:以 SkySense、Globe230k 为代表,虽然规模巨大(SkySense达2150万对),但高分辨率光学和低分辨率SAR之间只是地理坐标级配对,没有像素级精细配准;MultiResSAR 虽然覆盖了0.16m-10m多分辨率,但仅有1.1万对样本,无法支撑大模型预训练。
💡 关键洞察 :遥感多模态模型性能的上限,越来越不取决于网络架构,而取决于训练数据的"对齐纯度"。现有数据集要么够大但不精,要么够精但不大,同时满足"百万级+像素级对齐+多分辨率"的数据集一直缺位。
02|破局:作者的核心思路是什么?
面对上述瓶颈,SOMA-1M团队选择了一条"工程驱动+算法护航"的路线。他们没有发明一个 fancy 的新网络结构,而是花了10个月时间(2024年12月至2025年10月),动员20余名遥感专业人员,系统性地攻克了从多源数据获取到像素级对齐的每一个环节。
如果把作者的思路总结成三个关键词,它们是:
- 多源互补 :整合 Sentinel-1(免费全球覆盖)、PIESAT-1(中国3米级商业SAR)、Capella Space(美国0.5米级商业SAR)和 Google Earth 光学影像,在分辨率、覆盖范围、成本之间取得平衡。
- 粗到精对齐:设计了一套基于MapGlue的全自动两阶段配准 pipeline,用"全局粗配准→局部分块精配准→中心裁剪去黑边"的策略,将大规模SAR-光学数据的对齐精度提升到像素级。
- 多任务验证:不只是发布数据集,而是在图像匹配、融合、去云、翻译四个层级任务上,用30余种主流算法做了系统评测,证明"高质量对齐数据"能显著激活模型的跨模态表征学习能力。
一个形象的类比:如果把SAR-光学协同处理比作双语翻译,那么以往的数据集就像是"机翻对齐的语料"------句子大致对应,但词序混乱、语义错位。而 SOMA-1M 做的是"逐词对齐的双语词典",让模型能够真正学会两种"语言"之间的精确映射关系。
03|方法详解:SOMA-1M数据集是如何构建的?
3.1 整体架构一览
下图展示了SOMA-1M数据集的整体概览及其在四大下游任务上的应用示例:

图 1:SOMA-1M数据集概览与多任务应用示例。左两列为原始SAR和光学输入,右侧依次为图像匹配、图像融合、SAR辅助去云、SAR-光学翻译的代表性结果。
架构的四个关键阶段:
- 多源数据采集:覆盖全球1466个地理位置,整合三种SAR传感器和Google Earth光学影像;
- 自动化两阶段配准:基于MapGlue实现 coarse-to-fine 的像素级对齐;
- 质量过滤与切块:剔除黑边占比超过50%的图像块,最终输出512×512像素的标准样本;
- VLM自动分类标注:利用Qwen3-VL-8B对大规模样本进行12类地物自动语义标注。
3.2 核心技术点 1:多源数据采集与分辨率分层
SOMA-1M将数据按分辨率分为三层,具体构成如下:
| 分辨率层级 | SAR数据源 | SAR分辨率 | 光学数据源 | 光学分辨率 | 原始场景数 | 有效样本数 |
|---|---|---|---|---|---|---|
| 低分辨率 | Sentinel-1 | 10m | Google Earth | 8m | 343 | 357,563 |
| 中分辨率 | PIESAT-1 | 3m | Google Earth | 4m | 628 | 834,265 |
| 高分辨率 | Capella Space | 0.5m | Google Earth | 1m | 495 | 109,126 |
| 总计 | --- | --- | --- | --- | 1,466 | 1,300,954 |
低分辨率和高分辨率样本在全球范围内分布较广,而中分辨率样本(PIESAT-1)主要集中在东亚地区。这种分层设计确保了数据集既能支持大尺度语义理解(低分辨率),又能支持细粒度结构分析(高分辨率)。
下图展示了SOMA-1M采样点的全球地理分布:
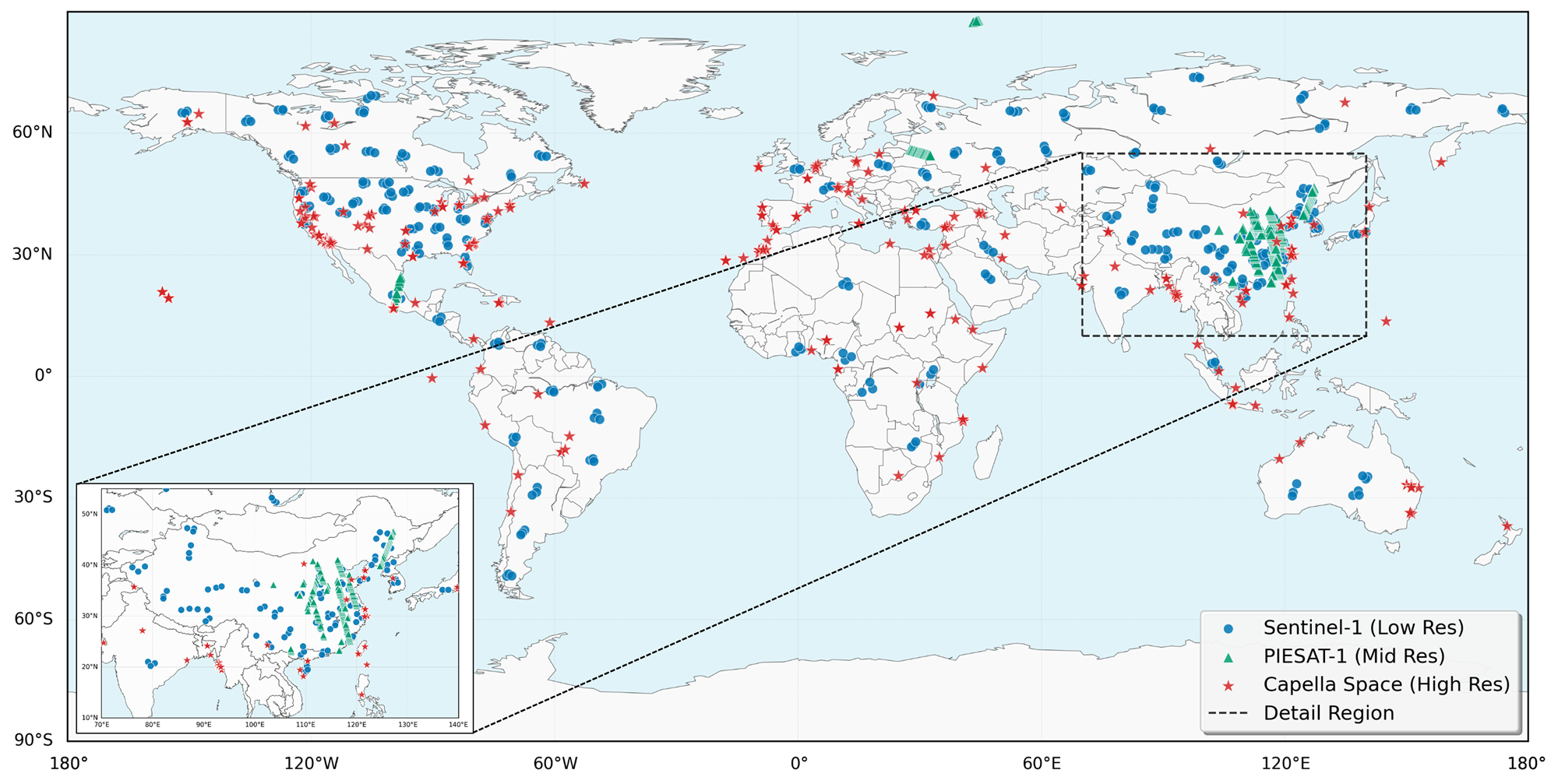
图 2:SOMA-1M采样点的全球地理分布。颜色或密度反映了不同区域的样本覆盖情况。
3.3 核心技术点 2:粗到精自动化配准框架
这是SOMA-1M dataset construction中最核心的算法创新。由于SAR和光学影像在成像机理上存在本质差异(SAR为侧视斜距投影,光学为透视/正射投影),直接地理坐标对齐在复杂地形区域往往存在数像素乃至数十像素的偏差。
作者设计的两阶段配准 pipeline 如下图所示:
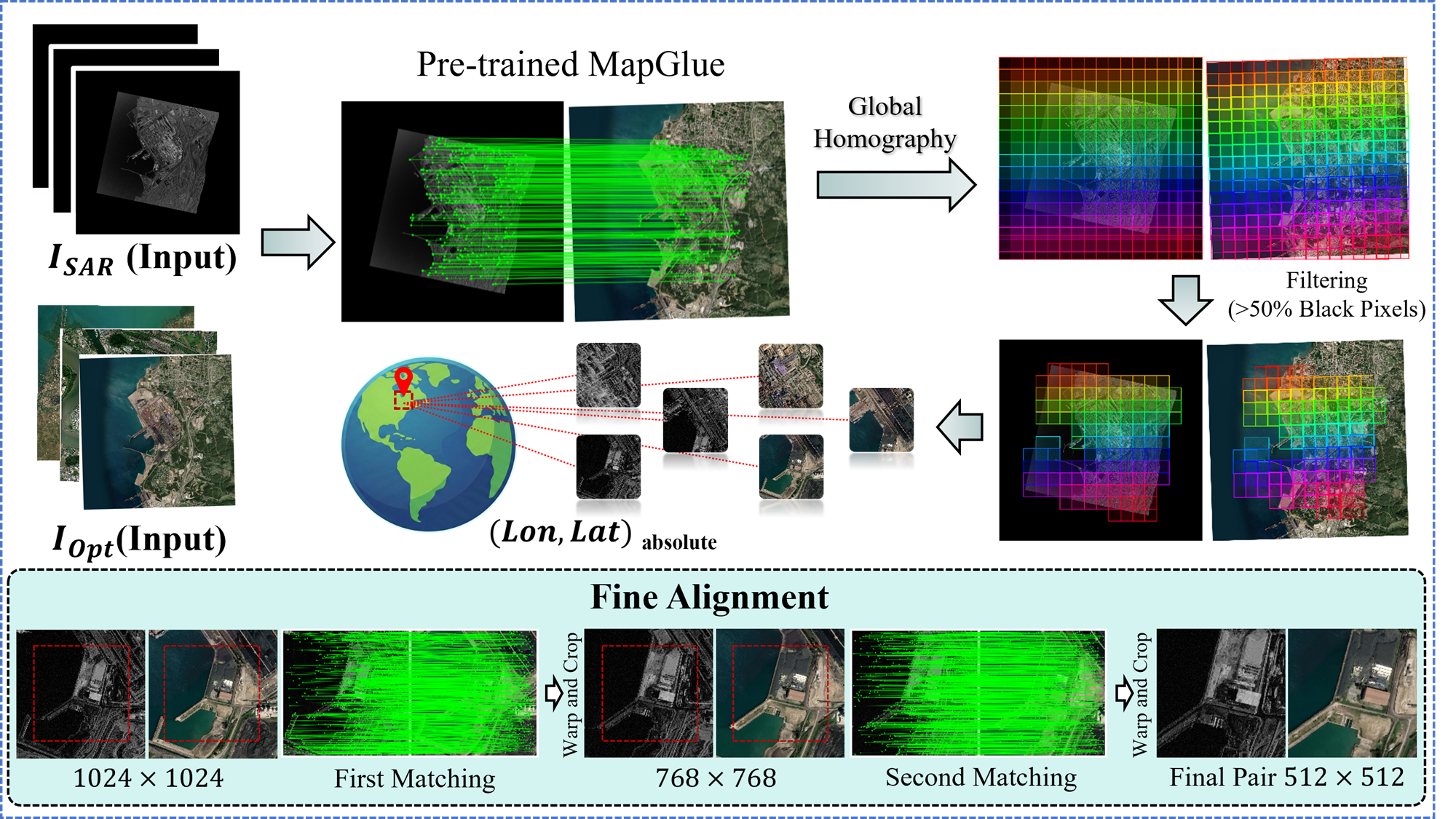
图 3:自动化数据标注 pipeline 流程图。展示了从原始大尺度影像到最终512×512像素对齐样本的粗到精处理过程。
第一阶段:粗对齐(Coarse Alignment)
- 将原始大尺度影像降采样到1024×1024;
- 使用预训练于12万对地图-光学数据的 MapGlue 模型提取4096个关键点进行全局匹配;
- RANSAC阈值设为10像素,估计全局单应性矩阵,将光学影像 warping 到SAR坐标系;
- 将配准后的大图切分为1024×1024的图像块,步长612;
- 过滤:若图像块中黑边像素超过50%,则直接丢弃。
第二阶段:精对齐(Fine Alignment)
- 第一级精修 :在1024×1024块上再次运行MapGlue匹配,RANSAC阈值收紧至1.5像素,估计局部单应矩阵 H\boldsymbol{H}H 并二次 warping;
- 从中心区域裁剪出768×768块,消除边缘畸变和黑边;
- 第二级精修:对768×768块重复上述匹配和warping操作;
- 最终从中心裁剪出 512×512 的 definitive sample,相邻样本最大重叠100像素。
通过这种多级精修策略,作者实现了像素级对齐精度。他们在10万对随机样本上做了人工质检,合格率超过 99.8%。对齐效果的可视化如下图所示:

图 4:对齐结果可视化。展示了城市街道、农田、河流、桥梁等多样化场景下的像素级对齐效果。
3.4 数据特性分析
SOMA-1M包含12个典型地物类别,分为三个语义层级:高价值目标 (飞机、舰船、桥梁、油罐)、人工聚落 (城市、乡村、工业区)、自然背景(山地、植被、农田、水体、沙漠)。下图展示了12类典型场景的对齐样本:

图 5:SOMA-1M中12类典型地物的SAR-光学对齐样本可视化。每行展示同一类别的SAR(左)和光学(右)影像对。
类别统计与传感器分布如下图所示。数据集呈现明显的长尾分布:农田(31.7%)和乡村(26.2%)占比最高,而油罐、舰船、飞机等稀有目标虽然比例仅约0.1%,但绝对数量仍有数千对,足以支持深度学习模型的稀有目标特征学习。
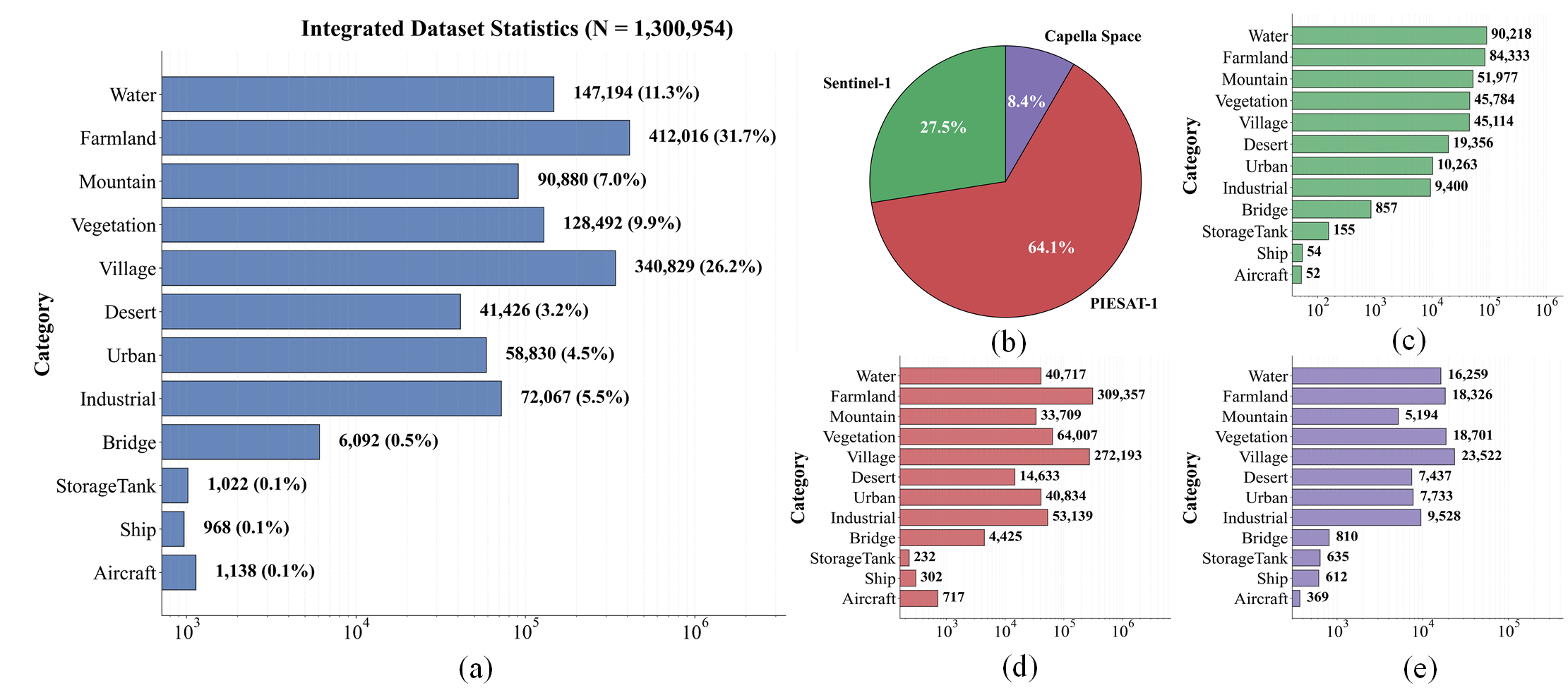
图 6:SOMA-1M类别统计与传感器分布比例。(a) 全部样本的类别分布;(b) 三个分辨率子集的占比;(c)-(e) Sentinel-1、PIESAT-1、Capella Space子集的详细类别统计。
作者还从物理复杂度和语义相似性两个维度对数据集做了深度分析:
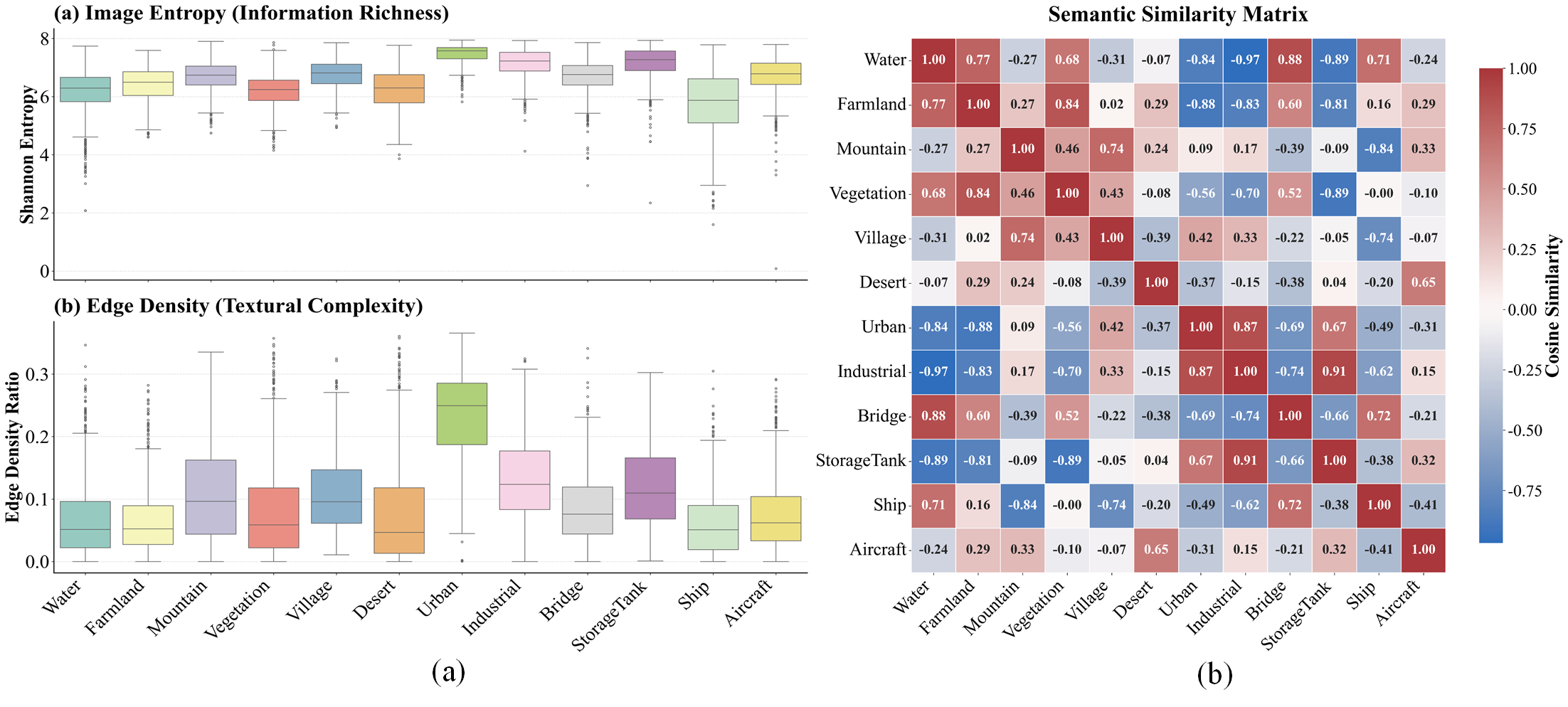
图 7:SOMA-1M的多维特性分析。(a) 场景的物理复杂度(信息熵与边缘密度);(b) 类别间的语义相似性矩阵。
分析结果显示,城市和工业区具有最高的信息熵(均值>7.2)和边缘密度,而水体和沙漠的结构性复杂度最低。语义相似性矩阵则揭示了人工地物(城市、工业区、油罐)之间存在强特征耦合(相似性>0.87),而水体与工业区呈强负相关(-0.96),说明数据集在特征空间上具有广泛的可分性梯度。
3.5 为什么这个方法有效?
SOMA-1M配准框架成功的关键在于三个设计选择:
- MapGlue的跨模态迁移能力:虽然MapGlue训练于地图-光学数据,但其学习到的"跨模态几何对应"能力可以泛化到SAR-光学领域。这说明地图(线条图)与SAR(散射结构)在"几何结构表示"上具有某种共享的底层特征空间。
- 逐级收缩的裁剪策略:从1024→768→512的三级收缩,每一级都通过中心裁剪消除边缘畸变。这相当于在配准过程中不断增加"有效区域的对齐置信度",最终保留的是几何变形最可控的核心区域。
- 大重叠步长的切块策略:步长612意味着相邻1024×1024块之间有412像素的重叠。即使某个块在边缘存在未对齐区域,下一块仍可能捕获到同一地物的更好对齐版本,从而提高整体数据质量。
04|实验验证:数字背后说明了什么?
4.1 实验设置
考虑到完整数据集规模巨大(130万对),作者构建了两个子集用于实验:
- SOMA-0.1M:包含10万对代表性样本(Sentinel-1/PIESAT-1/Capella各占1/3),用于模型训练或微调;
- SOMA-Test:低/中/高分辨率各1000对,共3000对,用于公平评测。
此外还使用了两个外部测试集评估跨数据集泛化:
- OSdataset:662对高分三号SAR-光学影像(1m分辨率),测试跨传感器泛化;
- SRIF:1200对多模态影像(含SAR-光学、红外-光学、深度-光学等),测试跨模态零样本鲁棒性。
实验平台为NVIDIA A100(80GB)。
4.2 任务一:图像匹配
图像匹配是检验SOMA-1M对几何特征学习贡献的核心任务。作者对比了稀疏匹配(MSG, GLIFT, LightGlue, MambaGlue, DiffGlue, MapGlue等)、半密集匹配(XoFTR, ELoFTR)和密集匹配(RoMa)三大类方法。
定量结果(AUC@5px / @10px / @20px,单位:%)如下图所示:
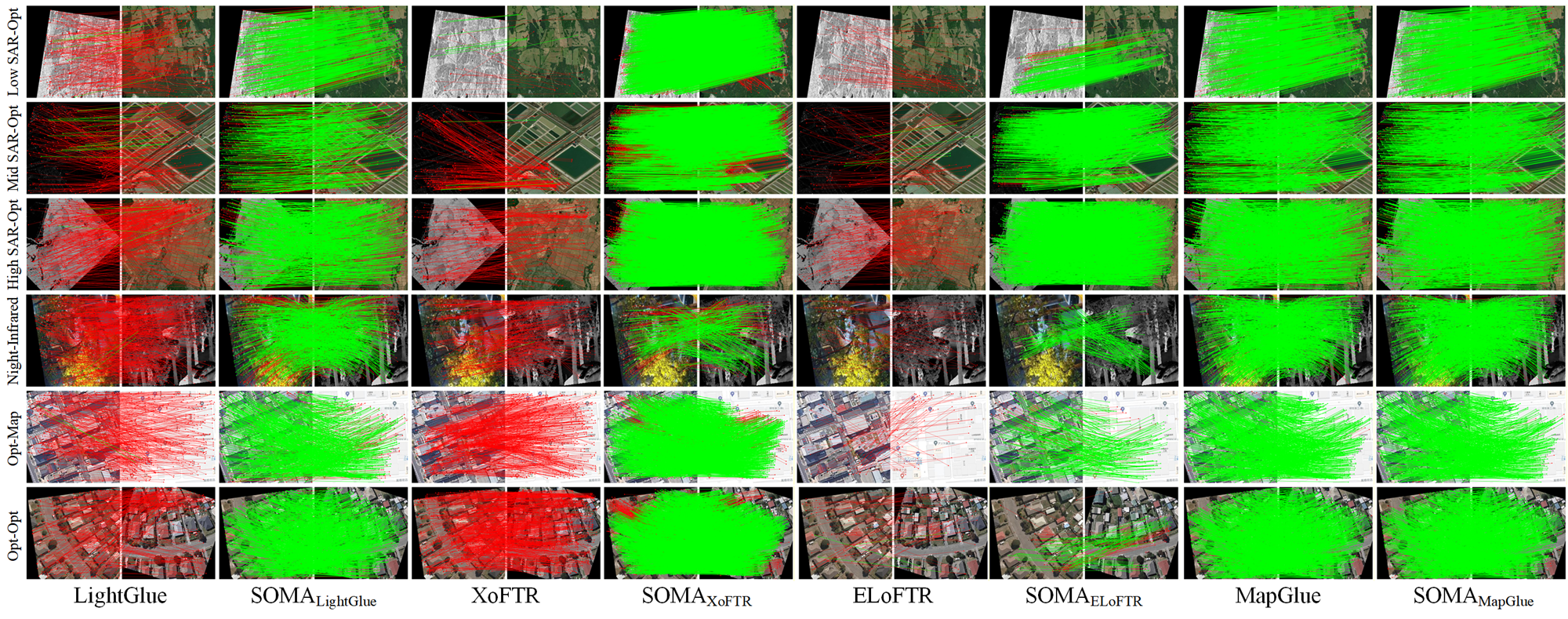
图 8:图像匹配的定性对比结果。展示了原始模型与SOMA微调模型在不同场景下的匹配效果差异。
核心发现:
- SOMA微调显著提升所有模型:以LightGlue为例,在SOMA-Test上AUC@5从0.50%提升到6.40%,AUC@20从2.57%提升到33.61%,提升幅度达一个数量级。
- 半密集匹配受益最大:XoFTR和ELoFTR在SOMA微调后AUC@20分别提升22.06%和33.70%。这说明半密集匹配模型对"像素级对齐精度"极为敏感------此前在SEN12MS等粗对齐数据上根本无法学习到精确的纹理映射关系。
- MapGlue表现最优:SOMA-MapGlue在SOMA-Test上达到AUC@5=18.63%, AUC@10=37.25%, AUC@20=55.42%,远超其他方法。这得益于其专门针对多模态遥感数据的架构设计和地图-光学预训练基础。
- 跨数据集泛化同样出色:在OSdataset和SRIF上,SOMA微调模型也普遍优于原始版本和MINIMA系列(在其他多模态数据集上重训练的版本),证明SOMA-1M学到的特征是跨传感器、跨模态可迁移的。
4.3 任务二:图像融合
融合任务采用跨分辨率训练-测试协议:所有模型仅在SOMA-0.1M低分辨率子集(33,334对)上训练,然后直接测试中/高分辨率子集和OSdataset,以评估跨分辨率泛化能力。
评估指标为非参考融合指标:FMI(特征互信息)、MI(互信息)、VIF(视觉信息保真度)、QAB/FQ^{AB/F}QAB/F(梯度融合质量)。

图 9:图像融合的定性对比结果。展示了SOMA微调前后不同融合方法在SAR几何结构与光学纹理保留上的差异。
核心发现:
- SOMA微调全面优于原始模型 :在低分辨率测试集上,所有SOMA系列模型在四项指标上均超越原始版本。SOMA-LUT-Fuse在FMI和MI上提升最为惊人(分别提升228%和98%),而SOMA-MMDRFuse在VIF和QAB/FQ^{AB/F}QAB/F上表现最佳。
- 跨分辨率泛化存在但有限 :在中/高分辨率测试集上,大多数微调模型仍优于原始版本,但优势幅度缩小。值得注意的是,传统方法BASHVS在中高分辨率VIF指标上超过深度学习模型,暴露了现有红外-光学融合模型在SAR-光学场景下的域迁移困难。
- 高分辨率下的 speckle 噪声抑制仍是瓶颈:定性结果显示,高分辨率融合结果中仍存在明显的SAR散斑噪声伪影。当前无监督融合框架难以在"去噪"和"保结构"之间取得平衡。
4.4 任务三:SAR辅助去云
作者采用合成云遮挡方案:在10万张无云光学影像上叠加模拟云和云掩膜,构建成对的SAR- cloudy optical - cloud-free 训练数据。

图 10:SOMA-0.1M数据集中不同分辨率的云遮挡图像对示例。(a) 低分辨率 (b) 中分辨率 (c) 高分辨率。
对比了6种主流去云方法(5种CNN-based:Dsen-CR, GLF-CR, Align-CR, ACA-CRNet, HPN-CR;1种扩散模型:EMRDM),并设置了单模态光学去云 vs SAR辅助多模态去云的对照实验。

图 11:SAR辅助去云的定性对比结果。展示了在浓密云覆盖区域,单模态方法与SAR辅助方法在几何结构和纹理连续性上的差异。
核心发现:
- SAR信息 universally 有益:所有方法的SAR辅助版本均优于单模态版本。GLF-CR提升最大(PSNR +6.09%, SSIM +6.06%, MAE -25%)。
- HPN-CR整体最强:HPN-CR_Multi在PSNR(28.849)和SSIM(0.885)上取得最佳,说明Transformer全局建模+异构并行网络的结构适合此任务。
- 扩散模型光谱一致性更好:EMRDM_Multi的SAM最低(1.267),表明扩散模型在保持色彩一致性方面优于CNN方法,但像素级保真度(PSNR/SSIM)稍逊。
4.5 任务四:SAR-光学翻译
翻译任务对比了无监督方法(CycleGAN, CUT, UNSB)和监督方法(pix2pix, pix2pixHD, BBDM)。作者发现单一模型难以同时处理三种分辨率,因为高分辨率SAR中的layover、double-bounce等散射效应与低分辨率中的平滑强度分布差异巨大。因此为每个分辨率单独训练了模型。

图 12:SAR-光学图像翻译的定性对比结果。对比了无监督方法与监督方法在不同分辨率下的翻译质量差异。
核心发现:
- 监督方法全面碾压无监督方法:在SSIM和PSNR上,pix2pix/pix2pixHD/BBDM显著优于CycleGAN/CUT/UNSB。这说明像素级对齐监督对约束生成过程中的几何一致性至关重要。
- pix2pixHD感知质量最佳:在中高分辨率子集上,pix2pixHD的FID和LPIPS最低,得益于其多尺度生成器设计。
- 分辨率越高,生成难度越大:高分辨率子集的FID普遍高于低分辨率,反映了复杂几何散射效应给生成模型带来的挑战。
4.6 分辨率影响的深度分析
作者补充了不同分辨率子集上的匹配和去云结果,揭示了任务对分辨率的敏感度梯度:
| 任务 | 分辨率敏感度 | 关键现象 |
|---|---|---|
| 图像匹配 | 最高 | MapGlue AUC@20从低分辨率69.99%骤降至中分辨率45.45%,高分辨率50.91%。高分辨率SAR的layover和speckle噪声引入复杂非线性几何变形,严重阻碍特征对齐。 |
| 图像翻译 | 高 | pix2pixHD FID从低分辨率58.27波动至中分辨率67.44,生成质量在尺度过渡时明显下降。 |
| 图像融合 | 中等 | MMDRFuse的VIF从低分辨率0.751降至高分辨率0.507,高分辨率物理复杂度限制了视觉指标上限。 |
| SAR辅助去云 | 最低 | HPN-CR的SSIM在三个分辨率上稳定在0.88-0.89之间。SAR结构先验的稳定性使该任务对分辨率变化最不敏感。 |
这一发现直接验证了SOMA-1M多分辨率分层设计的必要性:单尺度模型无法同时捕获细粒度几何细节和全局语义上下文。
05|深度讨论:超越论文本身的思考
5.1 这篇论文的真正价值
SOMA-1M的价值远不止于"又多了一个数据集"。它实际上在解决遥感AI领域一个被长期忽视但至关重要的问题:数据对齐精度对模型能力的隐性约束。
在计算机视觉领域,ImageNet级别的标注精度(类别标签)足以支撑CNN的崛起;但在遥感多模态领域,像素级对齐的精度要求远高于自然图像。SOMA-1M通过系统性的工程投入和算法创新,首次证明了当对齐精度被提升到像素级、数据规模达到百万级、分辨率覆盖从0.5m到10m时,现有主流模型(包括在自然图像上训练的SuperGlue、LoFTR、RoMa等)在遥感跨模态任务上的潜力可以被完全释放出来。
更重要的是,SOMA-1M为"遥感基础模型"的构建提供了关键基础设施。作者提到未来可以利用数据集中保存的绝对经纬度坐标,开展地理位置编码与跨模态特征深度融合的研究------这或许是通向具备全球空间感知能力的遥感大模型的重要一步。
5.2 容易被忽略的细节
- MapGlue的跨模态迁移能力:作者并没有重新训练一个SAR-光学匹配模型来做配准,而是直接使用了在地图-光学数据上预训练的MapGlue。这个选择非常聪明------地图和SAR在"线条/边缘结构表示"上具有共性,避免了为配准任务单独收集标注数据的成本。
- 合成云的设计:去云任务中的云是模拟生成的,而不是真实云。虽然这保证了训练数据的可控性和规模,但真实云的物理特性(如阴影、厚度变化、光谱吸收)可能与合成云存在差距,这是应用时需要留意的。
- VLM自动分类的层级规则:使用Qwen3-VL-8B做自动标注时,作者设计了一套优先级规则------高价值目标 > 人工聚落 > 自然背景。这套规则确保了混合地物场景(如农村建筑和农田共存)的语义一致性。
5.3 局限性与质疑
- 局限 1:高分辨率样本的地理覆盖偏集中。PIESAT-1中分辨率样本主要集中在东亚,Capella高分辨率样本的全球分布虽然较广但绝对数量(10.9万对)仍远低于中低分辨率。模型在高分辨率上的泛化能力是否能覆盖全球多样化地形,还需要更多验证。
- 局限 2:配准算法的边界情况未详细讨论。虽然99.8%的合格率很高,但对于山地、城市峡谷等极端地形,MapGlue是否仍然可靠?论文中只给出了成功的可视化案例,失败案例和错误分布分析较少。
- 局限 3:翻译任务的FID指标整体偏高。即使是最佳方法pix2pixHD,低分辨率FID也达到58.27,说明SAR-光学翻译在感知质量上仍有很大提升空间。这是否说明当前的生成模型架构对SAR散射特征的理解还不够深入?
5.4 对实际工作的启发
- 如果你在做研究:SOMA-1M为SAR-光学图像匹配、半密集/密集匹配在遥感领域的应用打开了大门。此前由于数据集对齐精度不足,LoFTR、RoMa等模型的潜力在遥感领域几乎未被发掘。现在可以系统性地研究这些模型在SOMA-1M上的微调策略和泛化行为。
- 如果你在做工程:如果你的应用场景涉及SAR-光学融合或去云,SOMA-1M提供了一个高质量的训练数据源。但需要特别注意,高分辨率融合结果中的speckle噪声问题仍未完全解决,工程部署时可能需要额外的后处理。
- 如果你在关注行业趋势:遥感基础模型的发展路径正在从"单模态大模型"向"多模态协同大模型"演进。SOMA-1M的出现意味着,未来1-2年内,我们可能会看到在SOMA-1M上预训练的、具备跨模态理解和生成能力的遥感基础模型涌现。
06|常见误解 FAQ
Q1:SOMA-1M只是一个更大的SEN12MS吗?
A1:不是。SEN12MS的核心价值在于规模大(18万对)和全球覆盖,但它的分辨率固定在10米,且对齐精度只有地理坐标级。SOMA-1M同时实现了百万级规模、像素级对齐、显式多分辨率覆盖这三个维度,这是SEN12MS和其他现有数据集都不具备的。对于图像匹配、融合、翻译这类像素级敏感任务,SOMA-1M的意义远大于单纯的规模扩展。
Q2:为什么说"像素级对齐"那么重要?模型不能自己学会对齐吗?
A2:模型确实可以通过数据驱动学习一定的鲁棒性,但如果训练数据本身存在系统性像素错位,模型学到的就会是"带偏差的映射"。特别是在图像融合和翻译任务中,几个像素的偏差就会导致鬼影、边缘模糊等伪影。SOMA-1M的像素级对齐相当于给模型提供了"干净的教科书",让它能够学习到精确的SAR-光学对应关系,而不是在噪声中猜测。
Q3:SOMA-1M能直接用于所有遥感任务吗?
A3:不能。SOMA-1M主要面向SAR-光学协同的几何对齐、像素级处理和跨模态生成任务。对于纯单模态任务(如单独的光学分类或SAR目标检测),它的价值相对有限。此外,虽然数据集包含12类地物标注,但这些标注是场景级标签,不是像素级语义分割掩膜,因此不能直接用于分割任务。
附录
关键图表索引
- 图 1:SOMA-1M数据集概览与多任务应用示例 --- 展示了数据集在匹配、融合、去云、翻译四个任务上的代表性结果
- 图 2:全球采样点分布 --- 说明数据集的地理覆盖范围和分辨率分布
- 图 3:自动化标注 pipeline --- 解释粗到精配准的核心流程
- 图 4:对齐结果可视化 --- 验证像素级对齐在不同场景下的效果
- 图 5:12类典型地物示例 --- 展示数据集的场景多样性和对齐质量
- 图 6:类别统计与传感器分布 --- 分析数据集的类别长尾分布和分辨率构成
- 图 7:多维特性分析 --- 从信息熵、边缘密度、语义相似性等维度刻画数据集
- 图 8:图像匹配定性对比 --- 展示SOMA微调前后匹配效果的差异
- 图 9:图像融合定性对比 --- 展示不同融合方法在SAR结构注入和光学纹理保留上的表现
- 图 10:不同分辨率云遮挡样本 --- 说明SAR辅助去云任务的合成数据设计
- 图 11:去云定性对比 --- 对比单模态与SAR辅助去云的效果
- 图 12:图像翻译定性对比 --- 对比无监督与监督SAR-光学翻译的质量
术语速查
| 术语 | 解释 |
|---|---|
| SAR | 合成孔径雷达(Synthetic Aperture Radar),一种主动式微波遥感传感器,具有全天候、全天时成像能力 |
| GSD | 地面采样距离(Ground Sampling Distance),即影像中一个像素对应的地面实际尺寸 |
| Pixel-level Alignment | 像素级对齐,指两幅影像中同一地物点对应的像素坐标完全一致 |
| MapGlue | 一种专为多模态遥感图像匹配设计的深度学习模型,在地图-光学数据上预训练 |
| AUC@5px / @10px / @20px | 图像匹配评估指标,表示匹配误差小于5/10/20像素的样本比例曲线下面积 |
| FID | 弗雷歇 inception 距离(Fréchet Inception Distance),评估生成图像感知质量的指标,越低越好 |
| SAM | 光谱角映射(Spectral Angle Mapper),衡量重建图像光谱失真的指标,越低越好 |
| Layover / Double-bounce | SAR成像中的典型散射效应:前者指高层地物顶部投影到近坡脚,后者指角反射器的二次散射 |
资源链接
- 论文主页:https://arxiv.org/abs/2602.05480
- 官方代码:https://github.com/PeihaoWu/SOMA-1M
- 相关基线工作 :
- MapGlue: https://github.com/PeihaoWu/MapGlue
- LightGlue: https://github.com/cvg/LightGlue
- LoFTR: https://github.com/zju3dv/LoFTR
解读日期:2026-04-16
本文由 AI 辅助生成,观点仅供参考,建议结合原论文阅读