医疗问诊AI大模型从0到1实战手册
前言
欢迎来到医疗问诊 AI 大模型的实战之旅!
在人工智能飞速发展的今天,**大语言模型(Large Language Model, LLM)**已经从实验室走向了我们的日常生活。从 ChatGPT 到各种行业大模型,AI 正在深刻改变着我们获取信息、解决问题的方式。而医疗问诊,作为一个与每个人健康息息相关的领域,更是 AI 技术落地的重要场景。
你是否曾经好奇:
-
什么是大模型?它和我们以前学的深度学习模型有什么不同?
-
预训练、微调这些词到底是什么意思?
-
为什么别人能做出一个会看病的 AI 助手?
-
我自己能不能从 0 开始,亲手写出一个这样的项目?
如果你有这些疑问,那么这本手册就是为你准备的。
本手册将带你从零开始,一步一步构建一个完整的医疗问诊 AI 大模型对话系统。我们不会只讲枯燥的理论,也不会只给你一堆看不懂的代码。我们会把理论和实践完美结合,从最基础的概念讲起,带你逐行分析每一行代码的含义,让你彻底搞懂:
-
大模型的核心概念:大模型、基础模型、预训练、训练、归一化、测试、模型加载
-
医疗大模型项目的完整开发流程
-
每一行代码是如何编写出来的,为什么要这么写
-
如何在普通的消费级显卡上(比如 GTX 1650)训练大模型
-
如何把训练好的模型部署成 Web 服务,让别人可以在线使用
无论你是 AI 零基础的初学者,还是有一定深度学习基础想要入门大模型的开发者,这本手册都能帮你彻底搞懂大模型项目的开发全过程。
准备好了吗?让我们开始这段从 0 到 1 的 AI 大模型开发之旅吧!
第一章:大模型基础概念篇
在开始写代码之前,我们首先要搞懂那些经常听到的大模型概念。很多初学者一听到 "预训练"、"微调"、"归一化" 这些词就头大,其实这些概念一点都不复杂,我们用通俗易懂的方式来解释它们。
1.1 什么是大模型?
当我们说 "大模型" 的时候,我们到底在说什么?
简单来说,大模型就是参数规模非常庞大、训练数据量非常巨大的深度学习模型。
在传统的深度学习时代,我们做一个图像分类模型,可能只有几百万参数;做一个简单的文本分类,可能也就几千万参数。但是大模型不一样,它的参数规模通常是数十亿、甚至上万亿。
比如我们这个项目中使用的 GPT2 模型,虽然在现在看来已经算是 "小" 模型了,但它也有上亿的参数。而现在的 GPT-4,参数规模更是达到了万亿级别。
这么多参数有什么用呢?
参数就像是模型的 "记忆细胞"。参数越多,模型能记住的知识就越多,能捕捉到的语言规律就越复杂。就像人脑一样,神经元越多,我们的思考能力就越强。
大模型通常都是基于 Transformer 架构构建的。Transformer 是 Google 在 2017 年提出的一种神经网络架构,它的核心是自注意力机制(Self-Attention),能够让模型在处理文本的时候,关注到文本中不同词之间的关系。
比如当我们说 "他头痛发烧了,应该吃什么药?",模型能够通过自注意力机制,知道 "他" 指的是那个头痛发烧的人,而不是别的什么人。
这就是大模型能够理解语言、生成流畅对话的基础。
1.2 基础模型:大模型的 "骨架"
基础模型(Foundation Model)就是大模型的 "骨架"。
你可以把基础模型理解成一个通用的、什么都懂一点的 "通才"。它在海量的通用数据上进行训练,学会了语言的规律,也学到了大量的世界知识。
比如 GPT2、BERT、LLaMA 这些,都是基础模型。它们就像是刚从大学毕业的学生,什么都学过一点,数理化文史哲都懂,但是还没有具体的专业技能。
在我们这个项目中,我们使用的基础模型就是 GPT2。我们会基于这个基础模型,用医疗问诊的数据来训练它,让它从一个 "通才" 变成一个 "医疗专家"。
1.3 预训练:模型的 "基础教育"
预训练(Pre-training)就是基础模型的 "基础教育阶段"。
在这个阶段,模型会在海量的无标注数据上进行学习。比如 GPT2 的预训练数据,包含了互联网上的大量文本:书籍、网页、文章等等。
在预训练阶段,模型的任务非常简单:根据前面的词,预测下一个词是什么。
比如给模型输入:"我头痛发烧了,应该",模型就要预测下一个词最可能是 "吃"。
通过这样的预测任务,模型就能自动学习到语言的规律:
-
语法:中文里 "的地得" 怎么用
-
语义:"头痛" 和 "发烧" 都是生病的症状
-
知识:发烧了通常要吃药、要休息
预训练就像是我们上学的时候,从小学到大学,学习各种基础知识。这个阶段结束后,模型就具备了通用的语言理解和生成能力。
但是,这时候的模型还不会做医疗问诊,就像一个大学生虽然知识很丰富,但还不会给人看病一样。这时候就需要下一步了。
1.4 微调:模型的 "专业培训"
微调(Fine-tuning)就是模型的 "专业培训阶段"。
预训练好的基础模型,已经有了很强的通用能力。但是如果我们想要让它做特定的任务,比如医疗问诊,我们就需要用特定领域的数据,对它进行进一步的训练。
这个过程就像是大学生毕业后,去医学院读研究生,学习专业的医学知识,最后成为一名医生。
在微调阶段,我们会把预训练好的模型的参数作为初始值,然后用我们的医疗问答数据来训练它。这时候,模型就会在保持通用语言能力的基础上,学习医疗领域的专业知识,学会医生是怎么问诊、怎么回答患者问题的。
这就是我们这个项目的核心:我们基于 GPT2 这个基础模型,用医疗问答数据对它进行微调,最终得到一个会做医疗问诊的 AI 助手。
这就是大模型最经典的 "预训练 + 微调" 两阶段范式:
-
预训练:海量通用数据,学习通用能力
-
微调:领域特定数据,学习专业技能
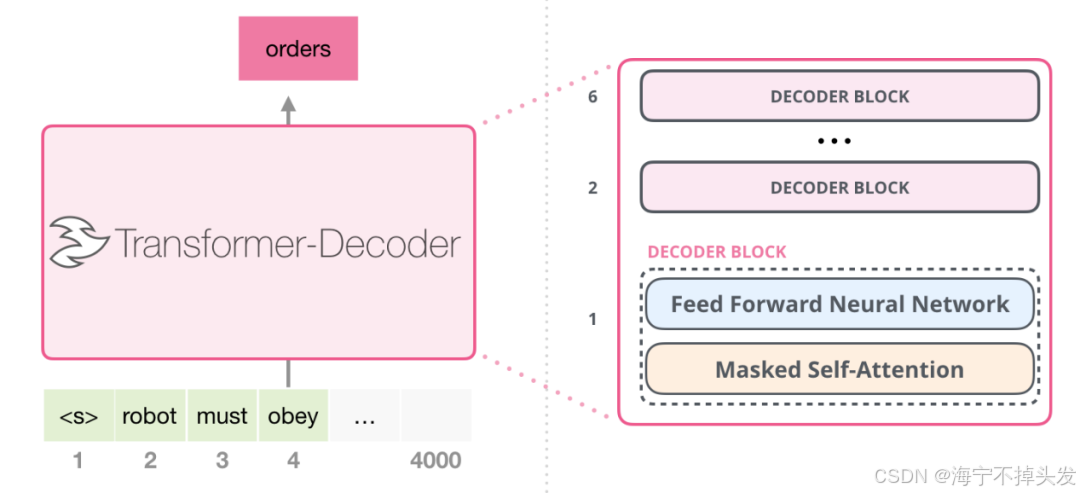
1.5 归一化:让训练更稳定的 "调节器"
归一化(Normalization)是深度学习中非常重要的一个技术,它的作用是让数据的分布变得更加稳定,从而让模型训练得更快、更稳定。
你可以把它理解成:我们在考试的时候,会把不同科目的分数转换成标准分,这样不同科目的分数就可以放在一起比较了。归一化做的就是类似的事情。
在大模型中,最常用的归一化技术是Layer Normalization(层归一化,简称 LN)。
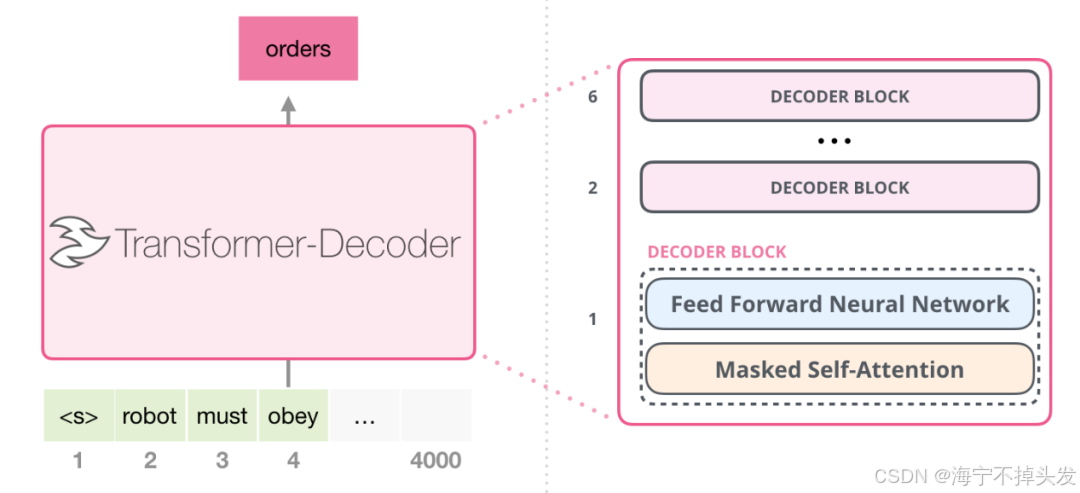
LayerNorm 的原理很简单:
-
对于每一个样本,计算它所有特征的均值和方差
-
然后用这个均值和方差,把样本的特征转换成均值为 0、方差为 1 的标准分布
-
最后再通过两个可学习的参数,对数据进行缩放和平移,让模型可以自己调整数据的分布
为什么要这么做呢?
因为在深层神经网络中,每一层的输入数据的分布都可能发生变化,这会导致训练变得很不稳定。LayerNorm 就像是一个调节器,把每一层的输入都调整到一个稳定的分布,这样梯度就不会爆炸也不会消失,模型就能稳定地训练下去。
在我们的 GPT2 模型中,每一个 Transformer 层里面都有 LayerNorm 层,这就是为什么我们的模型能够训练到 12 层这么深还能稳定收敛的原因。
1.6 模型训练:让模型 "学会" 知识
训练(Training)就是让模型从数据中学习知识的过程。
你可以把它理解成:我们给模型看很多很多的例子,然后告诉它,你应该怎么预测才是对的。然后模型就会不断调整自己的参数,让自己的预测越来越准确。
具体来说,训练的过程是这样的:
-
我们把数据输入给模型
-
模型根据当前的参数,做出预测
-
我们计算预测结果和真实答案之间的差距,这个差距叫做损失(Loss)
-
然后我们通过反向传播算法,把这个损失传回给模型,告诉模型哪些参数错了
-
模型调整自己的参数,让损失变小
-
不断重复这个过程,直到损失足够小,模型的预测足够准确
在我们的医疗问诊项目中,训练的过程就是:我们给模型看很多很多的 "患者提问 - 医生回答" 的例子,让模型学会,当患者问一个问题的时候,医生应该怎么回答。
1.7 模型测试:检验模型学的好不好
测试(Testing)就是检验模型学的好不好的过程。
就像我们上学的时候,学完了知识要考试一样。模型训练完了,我们也要用一些它没见过的数据来考一考它,看看它到底学的怎么样。
在医疗大模型中,测试的指标有很多:
-
准确率:模型回答对了多少问题
-
困惑度:模型对文本的预测有多准确,困惑度越低越好
-
BLEU/ROUGE:衡量模型生成的文本和标准答案的相似度
-
医疗实体 F1:衡量模型能不能正确识别医疗术语
在我们的项目中,我们在训练的时候,会每隔一段时间就用验证集来测试一下模型的损失,看看模型有没有过拟合,然后保存效果最好的那个模型。
1.8 模型加载:把模型 "请" 出来工作
模型加载(Model Loading)就是把训练好的模型从硬盘里读出来,放到内存里,让它可以开始工作。
你可以把它理解成:我们训练模型的时候,就像是在学校里培养学生。训练完了,我们要把这个学生请到公司来上班。模型加载就是把这个学生从学校接到公司的过程。
当我们加载模型的时候,我们会:
-
读取模型的配置文件,知道这个模型的结构是什么样的
-
读取模型的参数文件,把训练好的参数加载进来
-
把模型放到我们指定的设备上(CPU 或者 GPU)
-
把模型设置成评估模式,这样它就可以开始预测了
加载完模型之后,我们就可以用它来回答用户的问题了。
第二章:开发环境准备篇
搞懂了基础概念之后,我们就要开始准备开发环境了。工欲善其事,必先利其器,我们需要先把开发需要的软件和库都装好。
2.1 硬件要求:你的电脑够不够用?
很多人一听到大模型,就觉得必须要有很贵的显卡才能玩。其实不是的,我们这个项目,用普通的消费级显卡就可以跑起来。
我们的项目针对 GTX 1650 这种 4G 显存的显卡做了专门的优化,所以:
-
最低配置 :4G 显存的 NVIDIA 显卡,比如 GTX 1650、GTX 1050Ti
-
推荐配置 :8G 以上显存的显卡,比如 RTX 3060、RTX 3070
-
CPU:i5 以上的处理器,内存 16G 以上
当然,如果你没有 NVIDIA 显卡也没关系,用 CPU 也可以跑,就是速度会慢一点。
2.2 软件安装:从 Python 开始
首先,我们需要安装 Python。推荐使用 Python 3.8 或者 3.9 版本,这两个版本和 PyTorch 的兼容性最好。
你可以从 Python 官网下载:https://www.python.org/
安装完 Python 之后,我们需要安装 PyTorch。PyTorch 是 Facebook 开源的深度学习框架,我们整个项目都是基于它来开发的。
如果你有 NVIDIA 显卡,建议安装 CUDA 版本的 PyTorch,这样可以用 GPU 来加速训练。
安装命令:
bash
# CUDA 11.7版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
# 或者CPU版本
pip3 install torch torchvision torchaudio2.3 依赖库安装
除了 PyTorch,我们还需要安装一些其他的依赖库:
bash
# Transformers:HuggingFace的Transformers库,提供了GPT2等模型的实现
pip install transformers
# tqdm:进度条库,让我们可以看到训练的进度
pip install tqdm
# Flask:Web框架,用于把模型部署成Web服务
pip install flask
# scikit-learn:机器学习工具库
pip install scikit-learn这些就是我们项目需要的所有依赖了,是不是很简单?
2.4 项目目录结构
我们的项目目录结构是这样的:
Plain
medical_chatbot/
├── config/ # 模型配置文件
│ └── config.json # GPT2模型的配置文件
├── data/ # 数据文件
│ ├── medical_train.txt # 原始训练数据
│ ├── medical_valid.txt # 原始验证数据
│ ├── medical_train.pkl # 预处理后的训练数据
│ └── medical_valid.pkl # 预处理后的验证数据
├── vocab/ # 词表文件
│ └── vocab.txt # BERT的中文词表
├── save_model1/ # 训练好的模型保存目录
├── templates/ # Web前端页面
│ └── index.html # 聊天界面
├── parameter_config.py # 参数配置文件
├── preprocess.py # 数据预处理脚本
├── dataset.py # 自定义数据集
├── dataloader.py # 数据加载器
├── create_model.py # 模型创建脚本
├── functions_tools.py # 工具函数
├── my_train.py # 训练脚本
├── interact.py # 交互推理脚本
└── app.py # Web部署脚本这个目录结构非常清晰,每个文件都有自己的职责,我们后面会一个一个来讲解。
第三章:医疗数据处理篇
数据是 AI 的燃料,没有好的数据,再好的模型也没用。所以我们第一步,就是要处理我们的医疗数据。
3.1 原始医疗数据长什么样?
我们的原始数据是医疗问答对,存放在medical\_train\.txt文件里。
我们来看一下数据的格式:
Plain
帕金森叠加综合征的辅助治疗有些什么?
综合治疗;康复训练;生活护理指导;低频重复经颅磁刺激治疗
卵巢癌肉瘤的影像学检查有些什么?
超声漏诊;声像图;MR检查;肿物超声;术前超声;CT检查
...每一个问答对都是两行:
-
第一行:患者的问题
-
第二行:医生的回答
问答对之间用空行隔开。整个训练集有 3 万多条这样的问答对,涵盖了内科、外科、妇科、儿科等各个科室的常见问题。
但是,模型是看不懂文本的,模型只能看懂数字。所以我们需要把这些文本转换成模型能够理解的数字,这个过程就叫做数据预处理。
3.2 分词:把文本切成小片段
首先,我们需要把文本切成一个个的小片段,这个过程叫做分词(Tokenization)。
为什么要分词呢?因为中文的句子是连续的字符,我们需要把它拆分成一个个的词,这样模型才能理解。
比如句子:"我头痛发烧了",分词之后就变成:\"我\", \"头\", \"痛\", \"发\", \"烧\", \"了\"
哦,不对,我们用的是 BERT 的中文分词,它是按字分词的,也就是把每个汉字都当成一个 token。这样做的好处是可以解决未登录词的问题,不管是什么生僻的医学术语,都可以处理。
分词之后,我们还要把这些词转换成数字 ID,因为模型只能处理数字。我们有一个词表(vocab.txt),里面记录了每个词对应的 ID。
比如:
-
"CLS" 对应的 ID 是 101
-
"SEP" 对应的 ID 是 102
-
"我" 对应的 ID 是 2769
-
"头" 对应的 ID 是 1962
-
...
这样,我们的文本就转换成了一串数字。
3.3 特殊符号:告诉模型哪里是开头哪里是结尾
在处理问答对的时候,我们还需要加入一些特殊符号,来告诉模型文本的结构:
-
\[CLS\]:句子的开头符号,放在整个问答对的最前面 -
\[SEP\]:分隔符,用来分隔问题和答案
所以,一个问答对:
Plain
问题:感冒了怎么办?
答案:多喝水,多休息。处理完之后,就变成了:
Plain
[CLS] 感冒了怎么办? [SEP] 多喝水,多休息。 [SEP]然后转换成 ID 就是:
Plain
[101, 2697, 1088, 749, ..., 102, 1391, 5890, ..., 102]这样模型就能看出来,哪些是问题,哪些是答案了。
3.4 preprocess.py(preprocess.py) 代码逐行解析
好了,理论讲完了,我们来看具体的代码。这就是我们的preprocess\.py文件,它负责把原始的 txt 文件转换成处理好的 pkl 文件。
python
# 1.导包
from transformers import BertTokenizerFast # 分词工具
from tqdm import tqdm # 显示进度条
import pickle # 保存pkl文件首先是导入需要的库:
-
BertTokenizerFast:这是 HuggingFace 提供的快速分词工具,我们用它来做分词 -
tqdm:进度条工具,处理大量数据的时候,我们可以看到处理的进度 -
pickle:Python 的序列化工具,我们用它来把处理好的数据保存成 pkl 文件
python
# 2.1需求提前定义一个数据处理的函数
def data_preprocess(input_txt_path, output_pkl_path):
"""
:param input_txt_path: 原始中文数据文件路径
:param output_pkl_path: 转换为词表id后的数据文件路径
:return: 没有返回值,直接在data目录下生成pkl文件
示例
数据: 问题: 感冒了 答案: 吃药吧
id : 问题: 2697 1088 749 答案: 1391 5890 1416
然后把一个问答id拼接为: [CLS]感冒了[SEP]吃药吧[SEP]...
上述示例转换后的效果为: [101 2697 1088 749 102 1391 5890 1416 102]
最终多个问答就是列表套列表: [[101 2697 1088 749 102 1391 5890 1416 102],[...],...]
"""这是我们定义的数据处理函数,输入是原始的 txt 文件路径,输出是处理好的 pkl 文件路径。注释里已经写的很清楚了,我们要做的就是把问答对转换成 ID 序列。
python
# 1.初始化分词工具
# 默认从预训练模型加载bert-base-chinese的词表,本次项目从本地加载词表
# tokenizer = BertTokenizerFast.from_pretrained('../data/bert-base-chinese')
tokenizer = BertTokenizerFast(
vocab_file='../vocab/vocab.txt',
pad_token="[PAD]",
sep_token="[SEP]",
cls_token="[CLS]"
)这一步是初始化分词工具。我们从本地加载词表文件,而不是从 HuggingFace 下载,这样可以离线使用。我们指定了三个特殊符号:
-
pad\_token:填充符号,后面我们会用到 -
sep\_token:分隔符 -
cls\_token:开头符
python
# 获取起始符[CLS]和[SEP]的token ID
cls_id = tokenizer.cls_token_id
sep_id = tokenizer.sep_token_id
# 测试代码
print(f'词表的大小:-->{tokenizer.vocab_size}')
print(f'起始符[CLS]的token ID:-->{cls_id}')
print(f'结束符[SEP]的token ID:-->{sep_id}')然后我们获取这两个特殊符号的 ID,打印出来看看。词表的大小是 13317,这是我们这个项目用的词表的大小,比标准的 BERT 词表小一点,因为我们只保留了常用的字。
python
# 2.加载原始数据
with open(input_txt_path, 'rb') as f:
data = f.read().decode("utf-8")
# 根据换行符进行整个文件数据切分获得到每个问答对,但是注意: window是\r\n,linux是\n
if "\r\n" in data:
qa_data_list = data.split("\r\n\r\n")
else:
qa_data_list = data.split("\n\n")
# 测试代码
print(f'打印原始问答对列表--->{qa_data_list[:1]}')
print(f'打印原始问答对列表的个数--->{len(qa_data_list)}')接下来加载原始数据。这里有个很重要的细节:Windows 系统的换行符是\\r\\n,而 Linux 和 Mac 系统的换行符是\\n。所以我们要先判断一下,然后用对应的分隔符来切分数据,把整个文件切成一个个的问答对。
这就是为什么我们的代码在 Windows 和 Linux 上都能运行的原因,这个细节很多初学者都会忽略,导致在不同系统上运行出问题。
python
# 3.遍历原始数据问答对列表并转换为id,[[CLS] + 问题 + [SEP] + 答案 + [SEP]]
# 提前定义空列表存储转换后的对话id
qa_ids_list = []
# 开始把问答对列表中每个问答切分并转为对应的id,并拼接为: [CLS] + 问题 + [SEP] + 答案 + [SEP]
# qa_data_list = [...,'家族性腺瘤性息肉病会转化成什么?\n大肠癌',...]
for index, qa_data in enumerate(tqdm(qa_data_list)):
# 拆分每个问答数据: '家族性腺瘤性息肉病会转化成什么?\n大肠癌' -> ['家族性腺瘤性息肉病会转化成什么?', '大肠癌']
if "\r\n" in qa_data:
qas = qa_data.split("\r\n")
else:
qas = qa_data.split("\n")然后我们遍历所有的问答对。这里用了tqdm,这样处理的时候就能看到进度条了,不会干等着。同样,我们也要处理换行符的问题,把每个问答对拆分成问题和答案两部分。
python
# 开始拼接为[CLS] + 问题 + [SEP] + 答案 + [SEP]
# 定时初始input_ids依次拼接每个问答id
input_ids = [cls_id]
# 便利每个问答小列表,依次获取问题和答案的id,并拼接到input_ids中
for qa in qas:
id = tokenizer.encode(qa, add_special_tokens=False)
input_ids += id
# 每个seq之后添加[SEP]
input_ids.append(sep_id)这是核心的处理逻辑:
-
首先,我们初始化
input\_ids,第一个元素就是\[CLS\]的 ID,因为整个问答对的开头是\[CLS\] -
然后,我们遍历问题和答案,把它们分别转换成 ID
-
每处理完一个部分(问题或者答案),我们就添加一个
\[SEP\]分隔符
这样,我们就得到了我们想要的格式:\[CLS\] 问题 \[SEP\] 答案 \[SEP\]
python
# TODO 把每个问答对input_ids添加到大列表qa_ids_list中
qa_ids_list.append(input_ids)然后,我们把处理好的这个问答对的 ID 序列,添加到总的列表里。
python
# 4.最终把转换后的对话id保存到pkl文件中
with open(output_pkl_path, "wb") as f:
pickle.dump(qa_ids_list, f)最后,我们用pickle把整个列表保存成 pkl 文件。pkl 文件是 Python 的二进制文件,保存和加载都非常快,比 txt 文件方便多了。
python
if __name__ == '__main__':
# TODO 2.数据转为词表中的id,并存储到pkl文件中
# 2.1需求提前定义一个数据处理的函数
# 2.2调用函数传入原始数据
data_preprocess('../data/medical_train.txt', '../data/medical_train.pkl')
data_preprocess('../data/medical_valid.txt', '../data/medical_valid.pkl')这是程序的入口,我们分别处理训练数据和验证数据,生成对应的 pkl 文件。
你看,这就是数据预处理的全部代码了,是不是很简单?但是这里面有很多细节,比如换行符的处理、特殊符号的添加,这些都是我们在实际开发中需要注意的。
第四章:自定义数据集与数据加载篇
数据预处理完了,接下来我们就要把这些数据加载到模型里去训练了。在 PyTorch 中,我们通常用Dataset和DataLoader来管理数据。
4.1 为什么需要 Dataset 和 DataLoader?
你可能会问,我直接把数据读进内存,然后传给模型不行吗?
当然可以,但是如果数据量很大的话,一次性把所有数据都读进内存,内存就爆了。而且,我们训练的时候是按批次(batch)来训练的,不是一次把所有数据都喂给模型。
所以,PyTorch 提供了Dataset和DataLoader这两个工具:
-
Dataset:负责定义数据集,告诉程序怎么根据索引获取数据 -
DataLoader:负责把数据分成批次,帮我们做打乱、填充等操作
这样,我们就可以高效地处理大量数据了。
4.2 自定义 Dataset 类
首先,我们来自定义一个 Dataset 类,这就是dataset\.py文件。
python
# 1.导包
from torch.utils.data import Dataset # 自定义数据集
import torch # 处理张量
import pickle # 加载处理过的pkl文件数据首先导入需要的库:
-
Dataset:PyTorch 的数据集基类,我们要继承它 -
torch:PyTorch 的核心库,用来处理张量 -
pickle:用来加载我们之前保存的 pkl 文件
python
# 2.自定义类
class MyDataset(Dataset):
"""
自定义数据集类,继承自Dataset
重写__init__,__len__,__getitem__魔法方法
"""
def __init__(self, qa_ids_list, max_len):
"""
初始化函数,用于设置数据集的属性
:param qa_ids_list: 从pkl文件中加载出来的id问答列表
:param max_len: 最大长度,用于对输入的问答列表截断或者填充
"""
super().__init__()
self.qa_ids_list = qa_ids_list
self.max_len = max_len这是我们的自定义数据集类,继承自 PyTorch 的Dataset基类。我们需要重写三个方法:\_\_init\_\_、\_\_len\_\_、\_\_getitem\_\_。
\_\_init\_\_是初始化函数,我们在这里接收两个参数:
-
qa\_ids\_list:就是我们之前预处理好的 ID 列表 -
max\_len:样本的最大长度,超过这个长度的我们要截断
python
def __len__(self):
"""
返回数据集的长度
:return: 数据集的长度
"""
return len(self.qa_ids_list)\_\_len\_\_方法很简单,就是返回数据集的总长度。这样,当我们调用len\(dataset\)的时候,就能得到数据集有多少个样本了。
python
def __getitem__(self, index):
"""
根据指定索引返回数据集的对应的那一个样本
:param index: 样本的索引
:return: 索引对应的问答id张量
"""
print(f'用户传入的索引-->{index}')
# 根据索引获取问答id张量
qa_ids = self.qa_ids_list[index]
# 根据最大长度对输入的数据进行截断或者填充
qa_ids = qa_ids[:self.max_len]
# 将输入的序列转换为张量long类型
qa_ids = torch.tensor(qa_ids, dtype=torch.long)
# 返回问答id张量
return qa_ids\_\_getitem\_\_是最核心的方法,它的作用是:根据索引,返回对应的样本。
当我们调用dataset\[index\]的时候,就会调用这个方法。它做了三件事:
-
根据索引,从列表里取出对应的 ID 序列
-
截断:如果这个序列太长了,超过了
max\_len,我们就把后面的截断掉 -
转换:把 Python 的列表转换成 PyTorch 的张量,而且是
long类型,因为 ID 都是整数
这样,我们的自定义数据集就完成了。是不是很简单?
python
if __name__ == '__main__':
# 3.加载数据
# 先获取qa_ids_list数据
with open('../data/medical_train.pkl', 'rb') as f:
qa_ids_list = pickle.load(f)
# 测试自定义数据集对象
dataset = MyDataset(qa_ids_list, max_len=300) # 此时会自动调用__init__方法
print(f'打印数据集的长度-->{len(dataset)}') # 此时会自动调用__len__方法
print(f'打印数据集的索引0对应的数据-->{dataset[0]}') # 此时会自动调用__getitem__方法
print(f'打印数据集的索引1对应的数据-->{dataset[1]}') # 此时会自动调用__getitem__方法这是测试代码,我们加载 pkl 文件,创建数据集,然后测试一下,看看能不能正常获取数据。
4.3 DataLoader 与批处理
有了 Dataset 之后,我们就可以用 DataLoader 来加载数据了。但是,不同的样本长度不一样啊,有的问答对短,只有几十个 token,有的很长,有几百个。我们要把它们放到一个批次里,就需要把它们填充到一样的长度。
这个填充的操作,就是在collate\_fn里做的。这就是我们的dataloader\.py文件。
python
# 1.导包
import torch.nn.utils.rnn as rnn_utils # 用于处理可变长度的序列的填充和排序
from torch.utils.data import DataLoader # 用于加载数据
from dataset import * # 导入自定义类中所有功能首先导入库:
-
rnn\_utils:PyTorch 提供的序列处理工具,里面有填充的函数 -
DataLoader:数据加载器 -
然后导入我们刚才写的 Dataset
python
# 2.定义加载数据的方法
def load_dataset(train_pkl_path, valid_pkl_path, max_len=300):
# 先分别获取训练和验证的qa_ids_list数据
with open(train_pkl_path, 'rb') as f:
train_qa_ids_list = pickle.load(f)
with open(valid_pkl_path, 'rb') as f:
valid_qa_ids_list = pickle.load(f)
# 分别创建训练和验证数据集对象
train_dataset = MyDataset(train_qa_ids_list, max_len=max_len)
valid_dataset = MyDataset(valid_qa_ids_list, max_len=max_len)
# 返回数据集对象 默认放到元组中返回
return train_dataset, valid_dataset这个函数负责加载数据集,它加载 pkl 文件,然后创建我们的 MyDataset 对象,返回训练和验证的数据集。
python
# 3.定义对齐数据的方法
def collate_fn(batch):
"""
用于将数据集中的样本进行批处理
:param batch: 样本列表
:return: 经过填充的输入序列张量和标签序列张量
"""
print(f'打印batch的长度-->{len(batch)}')
print(f'打印batch的第一个样本的长度-->{batch[0].shape}')
print(f'打印batch的第二个样本的长度-->{batch[1].shape}')
print('--------------------------------------------------')这就是我们的collate\_fn函数,它的作用是处理一个批次的样本。因为每个样本的长度不一样,所以我们要把它们填充到一样长。
python
# 利用rnn_utils工具对数据进行填充,使得输入序列的长度一致
# TODO 根据input_ids来生成对应的logits(每个位置上token的得分)
input_ids = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=0)
print(f'pad_sequence进行了补齐操作...')
print('--------------------------------------------------')
print(f'打印input_ids的第一个样本的长度-->{input_ids[0].shape}')
print(f'打印input_ids的第二个样本的长度-->{input_ids[1].shape}')
print('--------------------------------------------------')首先,我们用pad\_sequence来填充输入。pad\_sequence会把批次里所有的样本,都填充到最长的那个样本的长度。填充的值是 0,因为 0 就是我们的\[PAD\]符号的 ID。
比如,批次里有两个样本,一个长度是 10,一个长度是 20,那么填充之后,两个样本的长度都是 20,短的那个样本后面会补 10 个 0。
python
# 利用rnn_utils工具对数据进行填充,使得标签序列的长度一致
# TODO labels中-100在后续训练模型的时候,计算损失-100会被忽略
"""
如果input_ids是医生的问题:你哪里不舒服? 患者:我头痛 ,那么labels可以认为就是标准答案,就是我头痛对应的tokenids
模型训练过程中,模型的输出logits会与lable计算交叉熵损失,不断指导模型更新参数...
criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
"""
labels = rnn_utils.pad_sequence(batch, batch_first=True, padding_value=-100)
# 返回填充后的输入序列张量和标签序列张量
return input_ids, labels然后,我们处理标签。这里有个非常重要的细节:标签的填充值我们用的是\-100,而不是 0!
为什么呢?因为 PyTorch 的交叉熵损失函数CrossEntropyLoss,有一个参数叫做ignore\_index,默认值就是 - 100。也就是说,当标签的值是 - 100 的时候,计算损失的时候会忽略这个位置,不会计算它的梯度。
这太重要了!因为我们填充的那些位置,是没有意义的,我们不希望模型去学习那些填充的符号。所以我们把填充的标签设为 - 100,这样计算损失的时候就会自动忽略它们。
这就是为什么我们的模型不会被填充的噪声影响的原因,这个细节很多初学者都搞不懂,现在你明白了吧?
python
# 4.定义获取数据加载器的方法
def get_dataloader(train_pkl_path, valid_pkl_path, max_len=300):
"""
获取训练数据集和验证集的dataloader对象
:param train_pkl_path: 训练集路径
:param valid_pkl_path: 验证集路径
:return: 训练数据集的dataloader对象和验证数据集的dataloder对象
"""
train_dataset, valid_dataset = load_dataset(train_pkl_path, valid_pkl_path, max_len)
# print(f'train_dataset-->{len(train_dataset)}') # 30177
# print(f'valid_dataset-->{len(valid_dataset)}') # 413
# 创建对象
train_dataloader = DataLoader(train_dataset,
batch_size=8,
shuffle=True,
collate_fn=collate_fn,
drop_last=True
)
validate_dataloader = DataLoader(valid_dataset,
batch_size=8,
shuffle=True,
collate_fn=collate_fn,
drop_last=True
)
# 返回数据集对象
return train_dataloader, validate_dataloader然后,我们创建 DataLoader。这里的参数:
-
batch\_size=8:每个批次 8 个样本,这个大小很适合小显存的显卡 -
shuffle=True:训练的时候打乱数据,让模型不会过拟合 -
collate\_fn=collate\_fn:指定我们刚才写的填充函数,用它来处理每个批次 -
drop\_last=True:如果最后一个批次不够 8 个样本,就扔掉它,避免影响训练
这样,我们的 DataLoader 就创建好了。现在,我们就可以用它来迭代数据了,每次迭代都会返回一个批次的input\_ids和labels,直接就可以喂给模型了。
第五章:模型构建篇
数据准备好了,接下来我们就要创建模型了。我们的模型是基于 GPT2 的,我们来看看它是怎么构建的。
5.1 GPT2 模型架构
GPT2 是 OpenAI 在 2019 年提出的语言模型,它的架构非常简单,就是纯 Decoder 的 Transformer。
我们这个项目用的是 small 版本的 GPT2,它的配置是:
-
12 层 Transformer 层
-
12 个注意力头
-
隐藏层维度 768
-
上下文长度 1024
-
总参数大约 1.2 亿
虽然这个模型现在看来不大,但是对于医疗问诊这个任务来说,已经完全够用了。
5.2 模型配置文件
在创建模型之前,我们先来看一下模型的配置文件config\.json:
json
{
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"gradient_checkpointing": false,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_inner": null,
"n_layer": 12,
"n_positions": 1024,
"output_past": true,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 400
}
},
"tokenizer_class": "BertTokenizer",
"transformers_version": "4.2.0",
"use_cache": true,
"vocab_size": 13317
}这个配置文件定义了模型的所有参数:
-
n\_layer=12:12 层 Transformer -
n\_head=12:12 个注意力头 -
n\_embd=768:隐藏层维度 768 -
n\_ctx=1024:上下文长度 1024 -
vocab\_size=13317:词表大小 13317 -
layer\_norm\_epsilon=1e\-05:LayerNorm 的 epsilon,就是我们之前讲的防止除零的那个小常数
这些参数决定了我们的模型长什么样。
5.3 create \\\[_model.py(_model.py)](\_model.py(_model.py)) 代码解析
好了,我们来看创建模型的代码,就是create\_model\.py:
python
# 1.导包
from transformers import GPT2LMHeadModel, GPT2Config
import parameter_config首先导入库:
-
GPT2LMHeadModel:这是 HuggingFace 提供的带语言模型头的 GPT2 模型。什么是 LMHead 呢?就是在 GPT2 的最后,加了一个线性层,把隐藏层转换成词表大小的 logits,这样我们就可以做语言模型的预测了。 -
GPT2Config:GPT2 的配置类 -
parameter\_config:我们的参数配置文件
python
# 2.创建模型
def get_model():
# 先获取参数配置对象
params = parameter_config.ParameterConfig()
# 再判断模型参数并创建模型对象
# 非空即为True
if params.pretrained_model:
# 如果模型参数不为空,则创建基于预训练模型的模型
model = GPT2LMHeadModel.from_pretrained(params.pretrained_model)
else:
# TODO 如果模型参数为空,则手动创建基于配置参数的初始化模型
model_config = GPT2Config.from_json_file(params.config_json)
model = GPT2LMHeadModel(model_config)
# 返回模型对象
return model这是核心的创建模型的函数。它做了一个判断:
-
如果我们指定了预训练模型的路径,那就加载预训练模型
-
如果没有,那就从我们的配置文件创建一个空白的模型,随机初始化参数
在我们这个项目中,我们是从头开始训练的,所以我们用的是第二种方式,从配置文件创建模型。
python
if __name__ == '__main__':
model = get_model()
# 最终打印模型
print(model)然后我们就可以打印模型,看看它的结构了。
你看,创建模型是不是很简单?HuggingFace 的 Transformers 库已经帮我们把 GPT2 的复杂实现都封装好了,我们只需要一行代码就能创建模型。
5.4 模型到底有多大?
我们的模型创建好之后,我们可以算一下它有多少参数:
python
num_parameters = sum(p.numel() for p in model.parameters())
print(f'模型参数数量为:{num_parameters}')运行这个代码,你会得到:模型参数数量为:124816896
也就是大约 1.25 亿参数。这个大小,即使是 4G 显存的显卡,也完全可以跑的起来,因为我们还有各种优化技术。
第六章:参数配置统一管理篇
在一个完整的项目中,我们会有很多很多的参数,比如路径参数、训练参数、推理参数等等。如果把这些参数散落在各个文件里,就会很难维护。所以我们把所有的参数都统一管理起来,这就是parameter\_config\.py文件。
6.1 为什么要统一管理参数?
统一管理参数有很多好处:
-
所有参数都在一个地方,修改起来很方便
-
不同的文件可以共享这些参数,不会出现不一致的情况
-
代码更清晰,别人一看就知道我们有哪些参数
我们来看一下这个文件:
python
# -*- coding: utf-8 -*-
import torch
class ParameterConfig():
def __init__(self):我们定义了一个 ParameterConfig 类,所有的参数都在它的初始化函数里。
python
# 判断是否使用GPU(1.电脑里必须有显卡;2.必须安装cuda版本的pytorch)
# 下载cuda版本的pytorch链接:https://pytorch.org/get-started/previous-versions/
# self.device = torch.device('mps')
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')首先是设备配置。我们自动检测 CUDA 是否可用,如果有 GPU 就用 GPU,没有就用 CPU。这样代码在不同的机器上都能自动适配。
python
# 词典路径:在vocab文件夹里面
self.vocab_path = '../vocab/vocab.txt'
# 训练文件路径
self.train_path = '../data/medical_train.pkl'
# 验证数据文件路径
self.valid_path = '../data/medical_valid.pkl'
# 模型配置文件 window建议需要使用绝对路径,linux,mac必须使用相对路径
self.config_json = r'../config/config.json'
# 模型保存路径
self.save_model_path = '../save_model1'
# 如果你有预训练模型就写上路径(我们本次没有直接运用GPT2它预训练好的模型,而是仅只用了该模型的框架)
self.pretrained_model = ''
# 保存对话语料
self.save_samples_path = 'sample'然后是路径配置:词表路径、数据路径、配置文件路径、模型保存路径等等。这些都是我们项目中用到的文件路径。
python
# 忽略一些字符:句子需要长度补齐,针对补的部分,没有意义,所以一般不进行梯度更新
self.ignore_index = -100这个就是我们之前讲的,忽略的标签索引,就是 - 100。
python
# 历史对话句子的长度
self.max_history_len = 3
# 每一个完整对话的句子最大长度
self.max_len = 300 # '每个utterance的最大长度,超过指定长度则进行截断,默认25'这是序列长度的配置:
-
max\_history\_len:推理的时候,最多保留 3 轮历史对话 -
max\_len:每个样本的最大长度,超过的截断
python
self.batch_size = 8 # 一个批次几个样本
self.epochs = 4 # 训练几轮
self.loss_step = 1 # 多少步汇报一次loss这是训练的基本参数:
-
batch\_size=8:批次大小 8,适合小显存 -
epochs=4:训练 4 轮,医疗数据不需要训练太多轮,太多会过拟合 -
loss\_step=1:每 1 步打印一次 loss
python
self.repetition_penalty = 10.0 # "重复惩罚参数,若生成的对话重复性较高,可适当提高该参数"
self.topk = 4 # '最高k选1。默认8'这是推理的参数:
-
repetition\_penalty:重复惩罚,防止模型重复输出 -
topk:topk 采样的 k 值
python
# TODO 初始化学习率,设置一个较小的学习率,确保梯度平滑的更新
self.lr = 2.6e-5
# TODO 为了增加数值计算的稳定性而加到分母里的项,其为了防止在实现中除以零
self.eps = 1.0e-09
# TODO 设置最大梯度范数,用于梯度裁剪防止梯度爆炸
self.max_grad_norm = 2.0
# TODO 设置梯度累积,即梯度累加的次数,用于多个小批次内累积梯度以模拟大批次训练的效果
self.gradient_accumulation_steps = 4这是优化器的参数:
-
lr=2\.6e\-5:学习率。微调的时候学习率不能太大,不然会把模型的知识冲掉,所以我们用了一个很小的学习率 -
eps=1e\-9:AdamW 优化器的 epsilon,防止除零 -
max\_grad\_norm=2\.0:梯度裁剪的最大范数,防止梯度爆炸 -
gradient\_accumulation\_steps=4:梯度累积的步数,这个我们后面训练的时候会讲
python
"""
TODO 默认.warmup_steps = 4000
TODO 使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,
直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),
采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
"""
self.warmup_steps = 100这是 warmup 的参数。warmup 就是在训练的前 100 步,学习率慢慢从小到大增加,这样可以让模型在训练初期更稳定。
你看,所有的参数都在这里了,一目了然。以后你要修改什么参数,直接改这个文件就可以了,非常方便。
第七章:模型训练核心流程篇
终于到了最核心的训练环节了!这部分是整个项目最复杂的部分,但是别担心,我们一步一步来拆解它。
7.1 训练的整体流程
训练的整体流程是这样的:
-
加载数据和模型
-
创建优化器和学习率调度器
-
遍历每一轮训练
-
遍历每个批次,前向传播计算损失
-
反向传播更新参数
-
定期验证模型,保存最优模型
但是,为了在小显存的显卡上训练大模型,我们还加入了很多优化技术:
-
混合精度训练
-
梯度累积
-
梯度裁剪
-
Warmup 学习率
我们一个个来看。
7.2 混合精度训练:省显存的神器
我们知道,通常的训练用的是 float32 精度,每个参数占 4 个字节。但是混合精度训练用的是 float16,每个参数只占 2 个字节,这样显存占用直接减半!
而且,NVIDIA 的显卡有 Tensor Core,对 float16 的计算有专门的加速,所以训练速度也会更快。
这就是为什么我们的项目能在 4G 显存的 GTX 1650 上跑起来的重要原因。
7.3 梯度累积:小批次模拟大批次
我们的批次大小是 8,但是如果我们想要用更大的批次,比如 32,但是显存不够怎么办?
梯度累积就是解决这个问题的。我们可以累积 4 个小批次的梯度,然后再更新一次参数。这样,效果就和我们用 32 的批次训练是一样的,但是显存占用却只有 8 的批次的大小。
这就是我们设置gradient\_accumulation\_steps=4的原因。
7.4 my \\\[_train.py(_train.py)](\_train.py(_train.py)) 代码逐行解析
好了,我们来看训练的代码,my\_train\.py:
python
# 1.导包
import os
import parameter_config
import dataloader
import create_model
from datetime import datetime
from tqdm import tqdm
import functions_tools
import torch
import transformers
import torch.optim as optim首先导入需要的库,各种我们之前写的模块都导入进来。
python
def train_epoch(model, train_dataloader, optimizer, scheduler, epoch, params, scaler):
model.train()
device = params.device
ignore_index = params.ignore_index
epoch_start_time = datetime.now()
total_loss = 0
epoch_correct_num, epoch_total_num = 0, 0这是训练一个 epoch 的函数。首先,我们把模型设置为训练模式,然后初始化一些变量。
python
for batch_idx, (input_ids, labels) in enumerate(tqdm(train_dataloader)):
# 非阻塞数据传输,配合 pin_memory 加速
input_ids = input_ids.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)然后我们遍历每个批次。把数据传到 GPU 上,用non\_blocking=True来加速数据传输。
python
# GTX 1650 专属:稳定 FP16 混合精度,省显存
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(input_ids, labels=labels)
logits = outputs.logits
loss = outputs.loss
# 梯度累积损失缩放
if params.gradient_accumulation_steps > 1:
loss = loss / params.gradient_accumulation_steps这是核心的前向传播。我们用torch\.amp\.autocast来开启混合精度,这样里面的计算都会用 float16 来做,省显存。
然后我们把数据喂给模型,模型会返回输出,里面包含了 logits 和 loss。我们不需要自己计算损失,模型已经帮我们算好了!
然后,如果有梯度累积,我们把损失除以累积的步数,因为我们要累积梯度。
python
# 反向传播
scaler.scale(loss).backward()然后反向传播。这里用了scaler\.scale,这是混合精度训练的缩放,防止 float16 的梯度溢出。
python
# 参数更新
if (batch_idx + 1) % params.gradient_accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), params.max_grad_norm)
scaler.step(optimizer)
scaler.update()
scheduler.step()
optimizer.zero_grad(set_to_none=True) # 【优化】梯度清零更省显存这是参数更新的部分。我们每累积 4 个批次,才更新一次参数:
-
首先把梯度反缩放回来
-
然后做梯度裁剪,把梯度的范数限制在 2.0 以内,防止梯度爆炸
-
然后用 scaler 来更新优化器
-
然后更新学习率调度器
-
最后把梯度清零,用
set\_to\_none=True更省显存
你看,这就是梯度累积的实现。我们累积了 4 个批次的梯度,然后一起更新,这样就相当于用了 4 倍大的批次,但是显存却没增加。
python
# 【关键】只在指定步长打印,彻底解决 IO 拖慢
if (batch_idx + 1) % params.loss_step == 0:
# 【优化】准确率只在打印时计算,不用每个 batch 都算,省大量时间
batch_correct_num, batch_total_num = functions_tools.calculate_acc(logits, labels, ignore_index=ignore_index)
batch_acc = batch_correct_num / batch_total_num
epoch_correct_num += batch_correct_num
epoch_total_num += batch_total_num
print(
"batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(
batch_idx + 1,
epoch + 1,
loss.item() * params.gradient_accumulation_steps,
batch_acc,
scheduler.get_last_lr()
)
)然后,我们打印日志。这里有个优化:准确率我们只在打印的时候才计算,不是每个批次都算,因为计算准确率也很耗时,这样可以省很多时间。
这个准确率计算的函数,就是我们的functions\_tools\.py里的,我们后面来看。
python
# 【优化】损失只累加,不做额外计算
total_loss += loss.item()然后我们累加损失,这里只做简单的累加,不做其他计算,尽可能快。
python
epoch_mean_loss = total_loss / len(train_dataloader)
epoch_mean_acc = epoch_correct_num / epoch_total_num if epoch_total_num > 0 else 0
print(
"epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc)
)一个 epoch 训练完了,我们计算平均损失和平均准确率,打印出来。
python
if epoch % 10 == 0 or epoch == params.epochs - 1:
print('saving model for epoch {}'.format(epoch + 1))
if not os.path.exists(params.save_model_path):
os.mkdir(params.save_model_path)
model_path = os.path.join(params.save_model_path, f'binzi_model_epochs{epoch + 1}')
if not os.path.exists(model_path):
os.mkdir(model_path)
model.save_pretrained(model_path)
print(f'epoch {epoch + 1} finished')
epoch_finish_time = datetime.now()
print(f'time for {epoch + 1} epoch: {epoch_finish_time - epoch_start_time}')
return epoch_mean_loss然后,每 10 个 epoch,或者最后一个 epoch,我们保存一下当前的模型。
python
def validate_epoch(model, validate_dataloader, epoch, params):
print('--------------------------开始验证--------------------------')
model.eval()
device = params.device
epoch_start_time = datetime.now()
total_loss = 0
with torch.no_grad():
for batch_idx, (input_ids, labels) in enumerate(tqdm(validate_dataloader)):
input_ids = input_ids.to(device, non_blocking=True)
labels = labels.to(device, non_blocking=True)
# 验证也用混合精度
with torch.amp.autocast(device_type='cuda', dtype=torch.float16):
outputs = model.forward(input_ids, labels=labels)
loss = outputs.loss
loss = loss.mean()
total_loss += loss.item()
epoch_mean_loss = total_loss / len(validate_dataloader)
print(
"validate epoch {}: loss {}".format(epoch + 1, epoch_mean_loss)
)
epoch_finish_time = datetime.now()
print('time for validating one epoch: {}'.format(epoch_finish_time - epoch_start_time))
return epoch_mean_loss这是验证的函数。验证的时候,我们把模型设置为 eval 模式,然后用torch\.no\_grad\(\)来关闭梯度,这样省显存。验证也用混合精度,速度更快。
我们只计算验证集的损失,不计算准确率,因为验证只是为了看模型有没有过拟合。
python
def train(params, train_dataloader, validate_dataloader, model):
optimizer = optim.AdamW(model.parameters(), lr=params.lr, eps=params.eps)
t_total = len(train_dataloader) // params.gradient_accumulation_steps * params.epochs
scheduler = transformers.get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=params.warmup_steps, num_training_steps=t_total
)
# 新版稳定 GradScaler
scaler = torch.amp.GradScaler('cuda')这是训练的主函数。首先创建优化器,我们用的是 AdamW 优化器,这是现在大模型训练最常用的优化器。
然后创建学习率调度器,用的是线性 warmup,前 100 步学习率慢慢上升,然后慢慢下降。
然后创建 GradScaler,这是混合精度训练的缩放器。
python
print('-----------------------------开始训练------------------------------')
train_losses, validate_losses = [], []
best_val_loss = 10000
for epoch in range(params.epochs):
print("================= TODO 训练=================")
train_loss = train_epoch(
model=model, train_dataloader=train_dataloader,
optimizer=optimizer, scheduler=scheduler,
epoch=epoch, params=params, scaler=scaler
)
train_losses.append(train_loss)
# 【优化】每 2 个 epoch 验证一次,不用每个 epoch 都验证,省大量时间
if (epoch + 1) % 2 == 0:
print("================= TODO 验证=================")
validate_loss = validate_epoch(
model=model, validate_dataloader=validate_dataloader,
epoch=epoch, params=params
)
validate_losses.append(validate_loss)
# 只在验证时保存最优模型
if validate_loss < best_val_loss:
best_val_loss = validate_loss
print('saving current best model for epoch {}'.format(epoch + 1))
model_path = os.path.join(params.save_model_path, f'binzi_model_min_ppl{epoch + 1}')
if not os.path.exists(model_path):
os.mkdir(model_path)
model.save_pretrained(model_path)然后我们遍历每个 epoch,训练,然后每 2 个 epoch 验证一次。为什么每 2 个 epoch 才验证?因为验证也很耗时,我们不需要每个 epoch 都验证,这样可以省很多时间。
验证完了,如果这个 epoch 的验证损失是最好的,我们就保存这个最优模型。这样,我们最后得到的就是效果最好的模型,而不是最后一个 epoch 的。
python
# 程序入口
if __name__ == '__main__':
# 【优化】训练前关掉不必要的显存占用
torch.cuda.empty_cache()
params = parameter_config.ParameterConfig()
train_dataloader, validate_dataloader = dataloader.get_dataloader(params.train_path, params.valid_path)
print(f'获取训练集长度:{len(train_dataloader)}')
print(f'获取验证集长度:{len(validate_dataloader)}')
model = create_model.get_model()
model = model.to(params.device)
print(f"模型已经移动到指定设备:{params.device}")
# 计算模型参数量
num_parameters = sum(p.numel() for p in model.parameters())
print(f'模型参数数量为:{num_parameters}')
# 开始训练
train(params, train_dataloader, validate_dataloader, model)这是程序的入口。首先清空 GPU 缓存,然后加载参数、数据、模型,把模型移到 GPU,然后开始训练。
你看,这就是整个训练的代码了。里面有很多针对小显存的优化,让我们在普通的显卡上也能训练大模型。
7.5 准确率计算函数
我们刚才提到了,计算准确率的函数在functions\_tools\.py里,我们来看一下:
python
# -*- coding: utf-8 -*-
import torch.nn.functional as F
def calculate_acc(logit, labels, ignore_index=-100):
"""
函数目的计算准确率,主要注意忽略特定索引的预测结果
参数:
logit (Tensor): 模型的输出结果,形状为(batch_size, seq_length, vocab_size)
labels (Tensor): 实际标签,形状为(batch_size, seq_length)
ignore_index (int): 需要忽略的索引,默认值为-100
返回:
正确预测的数量和总词数
"""
# 对模型输出结果进行预处理,移除最后一个时间步的输出,并调整形状为(-1, vocab_size)
# 示例:[4,95,13317]->[4,94,13317]->[376,13317]
logit = logit[:, :-1, :].contiguous().view(-1, logit.size(-1))首先,我们处理 logits。因为语言模型的任务是:用前 n 个词,预测第 n+1 个词。所以,输入的前 n 个词,对应的标签是后 n 个词。
所以,我们的 logits 要去掉最后一个时间步,因为最后一个词没有下一个词可以预测了。
python
# 对标签进行预处理,移除第一个时间步的标签,并调整形状为(-1)
# 示例:[4,95]->[4,94]->[376]
labels = labels[:, 1:].contiguous().view(-1)然后,标签要去掉第一个,因为第一个词没有前面的词来预测它。
这样,我们的 logits 和 labels 就对齐了。
python
# 对每个预测单词,取出最大概率值以及对应索引
_, logit = logit.max(dim=-1) # 对于每条数据,返回最大的index然后,我们对 logits 取 max,得到每个位置预测的 token。
python
'''
在 PyTorch 中,labels.ne(ignore_index) 表示将标签张量 labels 中的值不等于 ignore_index(-100)的位置标记为 True,
等于 ignore_index(-100) 的位置标记为 False。这个操作,以过滤掉 ignore_index 对损失的贡献,说白了就不能影响损失计算
'''
non_pad_mask = labels.ne(ignore_index)然后,我们生成一个 mask,把填充的位置去掉,我们不计算填充位置的准确率。
python
# TODO 以下计算正确预测的数量和总词数
'''
在 PyTorch 中,logit.eq(labels) 表示将模型的预测输出值 logit 中等于标签张量 labels 的位置标记为 True,
不等于标签张量 labels 的位置标记为 False。以标记出预测输出值和标签值相等的位置。
masked_select(non_pad_mask) 表示将张量中非填充标记的位置选出来。
'''
# masked_select(non_pad_mask) 使用non_pad_mask对上述布尔张量进行掩码操作,仅保留非填充位置的结果
# sum().item() 对保留的结果求和并转换为Python标量,得到正确预测的数量
# todo 只统计非填充位置的预测结果
n_correct = logit.eq(labels).masked_select(non_pad_mask).sum().item()
# non_pad_mask.sum().item() 对non_pad_mask求和并转换为Python标量,得到总词数(非填充位置的数量)
n_word = non_pad_mask.sum().item()
# 返回正确预测的数量和总词数
return n_correct, n_word最后,我们计算正确的预测数量,和总的词数,返回这两个值。这样我们就能算出准确率了。
第八章:模型推理与交互篇
模型训练好了,接下来我们就要用它来做推理了,也就是让它回答用户的问题。这部分就是interact\.py文件。
8.1 自回归生成:模型是怎么回答问题的?
大模型生成文本的方式,叫做自回归生成(Auto-regressive Generation)。
什么意思呢?就是模型一个词一个词地生成。比如:
-
用户输入:"我头痛发烧了怎么办?"
-
模型根据这个输入,预测第一个词应该是 "建"
-
然后把 "建" 加到输入里,模型根据新的输入,预测第二个词 "议"
-
然后把 "议" 也加进去,预测第三个词 "你"
-
就这样一直下去,直到生成结束符
\[SEP\],或者达到最大长度
这样,模型就一点点把整个回答生成出来了。
8.2 Top-K 采样:让生成的内容更丰富
但是,如果我们每次都选概率最大的那个词,那模型生成的内容就会很死板,每次都一样。所以我们用采样的方式。
Top-K 采样就是:我们从概率最高的 K 个词里,随机选一个。这样既保证了生成的质量,又有一定的随机性,让回答更丰富。
我们的项目里 K=4,也就是从最好的 4 个词里选一个。
我们来看一下 topk 的代码,就是我们之前的topk应用\.py:
python
import torch
# 设置随机种子以确保结果可重现
torch.manual_seed(1)
# 创建一个包含logits值的张量
logits = torch.tensor([1.2, 3.6, 2.4, 4.8])
print(logits) # tensor([1.2000, 3.6000, 2.4000, 4.8000])
# 获取logits中最大的两个值及其对应的索引
# a是内容值,c是索引值
a, c = torch.topk(logits, k=2)
print(a) # tensor([4.8000, 3.6000])
print(torch.topk(logits, k=2)[0]) # tensor([4.8000, 3.6000, 2.4000])
print('--------------------------------------')
# 获取第二大值,用于后续的阈值比较
print(a[..., -1, None]) # 3.6
print('--------------------------------------')
# TODO 完整格式
# 创建一个布尔掩码,标识需要移除的元素(小于第二大值的所有元素)
indices_to_remove = logits < torch.topk(logits, 2)[0][..., -1, None]
print(indices_to_remove) # tensor([ True, False, True, False])
# 将需要移除的元素设置为负无穷大
logits[indices_to_remove] = -float('Inf')
print(logits) # tensor([ -inf, 3.6000, -inf, 4.8000])这个例子很清楚:我们有 4 个 logits,topk=2 的话,我们保留最大的两个,把其他的都设为负无穷。这样,采样的时候就只会从这两个里面选了。
8.3 重复惩罚:防止模型复读机
有时候,模型会重复输出同样的词,比如 "建议患者患者患者...",变成复读机。
为了解决这个问题,我们加入了重复惩罚。就是对于已经生成过的词,我们降低它的概率,让模型不太可能再选它。
我们的重复惩罚系数是 10.0,也就是已经生成过的词,我们把它的 logits 除以 10,这样它的概率就会变小很多。
8.4 Multinomial 采样:按概率抽样
选好了候选词之后,我们就要按概率来抽样了。我们用的是torch\.multinomial函数,它会根据概率分布来随机抽样,概率越高的词,被抽到的几率越大。
我们来看一下这个函数的例子,就是torch中的multinomial函数\.py:
python
import torch
import torch.nn.functional as F
# 示例1:基本用法
weights = torch.tensor([0, 10, 3, 0], dtype=torch.float)
# 无放回抽样1个样本
result = torch.multinomial(weights, 1)
print(f"抽样结果索引: {result}") # 可能输出: tensor([1])比如,权重是 0, 10, 3, 0,那么第二个元素的概率最高,所以最可能抽到它。
python
# 示例3:在您的代码中的实际应用
# 假设filtered_logits是经过top-k过滤后的logits
filtered_logits = torch.tensor([float('-inf'), 3.6, float('-inf'), 4.8])
# 先通过softmax转换为概率分布
probabilities = F.softmax(filtered_logits, dim=-1)
print(f"概率分布: {probabilities}") # tensor([0.0000, 0.2314, 0.0000, 0.7686])
# 从概率分布中抽样1个样本
next_token = torch.multinomial(probabilities, num_samples=1)
print(f"抽样得到的token索引: {next_token}") # 更可能抽到索引3(概率0.7686)在我们的代码里,过滤后的 logits 是 -inf, 3.6, -inf, 4.8,转换成概率就是 0, 0.23, 0, 0.77。所以,抽到索引 3 的概率是 77%,抽到索引 1 的概率是 23%。这样既有随机性,又保证了质量。
8.5 interact.py(interact.py) 代码逐行解析
好了,我们来看完整的交互代码:
python
# 导包
import os
from transformers import BertTokenizerFast
from transformers import GPT2LMHeadModel
import torch
from parameter_config import ParameterConfig
import torch.nn.functional as F
# 创建参数对象
params = ParameterConfig()
# 提前定义好填充笔记,用于文本处理中表示填充位置
PAD = '[PAD]'
# 提前定义好填充ID,用于数值化中表示填充位置
pad_id = 0
# 获取到训练设备
device = params.device
# 打印当前使用的设备
print(f"当前使用的设备:{device}")
# 指定使用GPU设备id为0,默认电脑就一个的话,可以省略
os.environ['CUDA_VISIBLE_DEVICES'] = '0'首先导入库,加载参数,设置设备。
python
# 初始化分词工具
# 默认从预训练模型加载bert-base-chinese的词表,本次项目从本地加载词表
# tokenizer = BertTokenizerFast.from_pretrained('../data/bert-base-chinese')
tokenizer = BertTokenizerFast(
vocab_file=params.vocab_path,
pad_token="[PAD]",
sep_token="[SEP]",
cls_token="[CLS]"
)初始化分词器,和我们预处理的时候用的是同一个。
python
# TODO 加载预训练的GPT2LMHeadModel模型,指定模型路径
model = GPT2LMHeadModel.from_pretrained('../save_my_model1/binzi_model_epochs')
# 将模型移动到指定设备上
model = model.to(device)
# TODO 将模型设置为评估模式,达到禁用dropout等特性
model.eval()加载我们训练好的模型,把它移到 GPU,然后设置为 eval 模式,这样 dropout 就会关闭,预测更稳定。
python
def top_k_top_p_filtering(logits, top_k, filter_value=-float('Inf')):
"""
使用top-k/或者top-p筛选过滤logits的分布
top-k > 0 : 保留概率最高的top k个标记
"""
assert logits.dim() == 1
top_k = min(top_k, logits.size(-1)) # 确保top_k不超过logits的最后一个维度大小
# 判断topk
if top_k > 0:
# indices_to_remove获取的是一个布尔张量列表,用于获取logits中概率值小于top_k的标记为True
# 小于topk值默认设置为True,大于是False 示例: [ True, False, True, False]
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
# 对于topk之外的数据将logits值(True)设置为负无穷 示例: [ -inf, 3.6000, -inf, 4.8000]
logits[indices_to_remove] = filter_value
return logits这就是我们的 topk 过滤函数,和我们之前讲的一样。
python
# 定义一个模型预测,并保存聊天日志的函数
def model_predict(text):
"""
根据用户传入的文本进行预测
:param text: 输入文本
:return: 模型响应答案
"""
# 可以提前设置保存聊天日志文件对象,目的是当前函数任意位置可以访问
sample_file = ''
# 检查是否设置了保存日志文件的路径
if params.save_samples_path:
# 如果存储日志目录不存在,就创建对应目录
if not os.path.exists(params.save_samples_path):
os.mkdir(params.save_samples_path)
# 创建一个my_model_chat.txt,用于追加存储聊天记录
sample_file = open(params.save_samples_path + '/my_model_chat.txt', 'a', encoding='utf8')这是预测函数,首先我们创建日志文件,把聊天记录保存下来。
python
# 在文件中写入当前用户的问题
sample_file.write(f"用户问题:{text}\n")
# 定义空列表,存储聊天记录,用于后续转化为id操作
history = []
# tokenizer将文本转换为模型可以识别的id序列
text_id = tokenizer.encode(text, add_special_tokens=False)
# 将转换后的文本id序列添加到历史对话中
history.append(text_id)然后,我们把用户的问题转换成 ID,加到历史对话里。
python
# TODO 初始化输入id序列,以[CLS]开始
input_ids = [tokenizer.cls_token_id] # 举例input_ids = [101 ]
print(f"input_ids:{input_ids}")
# TODO 遍历历史对话记录,提取输入id序列
# history内容举例:[[872,1962],[872,342,123]...] -->history[-10:]
for history_id, history_utr in enumerate(history[-params.max_history_len:]):
# 将历史对话记录的输入id,扩展到input_ids中 [101,872,1962]
input_ids.extend(history_utr)
# 在每个历史对话记录后添加分隔符id,用于区分不同的对话
input_ids.append(tokenizer.sep_token_id) # 举例input_ids = [101 872 1962 102]然后,我们构建输入序列,和我们训练的时候一样:\[CLS\] \+ 历史对话 \+ \[SEP\]。我们最多保留最近的 3 轮历史对话,这样我们的模型也可以做多轮对话。
python
print(f"input_ids:{input_ids}")
# 将输入的tokenid列表转换为pytorch张量,同时指定long类型和device设备
input_ids = torch.tensor(input_ids, dtype=torch.long, device=device)
# TODO 在维度0上增加一个维度,用于匹配后续模型输入的期望形状 [[101 872 1962 102]]
input_ids = input_ids.unsqueeze(0)
print(f"input_ids:{input_ids}")然后转换成张量,加上 batch 维度,因为模型要求输入是 batch_first 的。
python
# TODO 初始化一个空列表,用于存储后续生成的响应数据
response = []
for _ in range(params.max_len):
# TODO 调用模型 也可以用model(input_ids=input_ids)
outputs = model.forward(input_ids=input_ids)
# TODO 将模型输出的logits值赋值给变量logits
logits = outputs.logits
# print(f"logits:{logits.shape}")
# TODO 获取下一个单词的概率值
next_token_logits = logits[0, -1, :]
# print(f"下一个单词的概率值:{next_token_logits.shape}")然后,我们开始循环生成词。每次调用模型,得到最后一个位置的 logits,也就是下一个词的预测。
python
# TODO 对reponse已经生成的结果中每个token添加一个重复惩罚,防止模型重复输出已经生成的结果
for id in set(response):
next_token_logits[id] = next_token_logits[id] / params.repetition_penalty
# TODO 对于[UNK]的概率设置为无穷小,也就是说模型的输出中不能出现[UNK]
next_token_logits[tokenizer.convert_tokens_to_ids('[UNK]')] = -float('Inf')然后,我们做重复惩罚,把已经生成过的词的 logits 除以 10。同时,我们把未知词\[UNK\]的概率设为负无穷,不让模型生成这个词。
python
# TODO 自定义一个函数,使用top-k和top-p过滤策略,对logits进行过滤,提升生成质量
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=params.topk)
# filtered_logits 示例结果: [ -inf, 3.6000, -inf, 4.8000]
# 先用torch中multinomial表示从候选的集合中无放回的抽取num_sample个元素
# 权重越高,抽到的几率越高,返回元素的下标
next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1,replacement=False)然后,我们用 topk 过滤 logits,然后用 multinomial 采样,得到下一个词。
python
# 如果下一个标记遇到[SEP]则表明response生成结束,停止循环
if next_token.item() == tokenizer.sep_token_id:
break
# 将下一个标记的id添加到响应列表中
response.append(next_token.item())
# TODO 沿着列维度将下一个标记与输入id拼接,更新输入序列
input_ids = torch.cat((input_ids, next_token.unsqueeze(0)), dim=1)如果遇到了结束符\[SEP\],我们就停止生成。否则,我们把这个词加到响应里,然后把它加到输入序列里,准备生成下一个词。
python
# 将机器人的响应添加到对话历史中
# print(response) # [872, 1962, 8024, 2456, 6379, 2642, 5442, 6206, 1914, 7608, 4289]
history.append(response)
# 将响应从id序列转换文本
res = tokenizer.convert_ids_to_tokens(response)
# print(res) # ['你', '好', ',', '建', '议', '患', '者', '要', '多', '食', '物']
ai_res = "".join(res)
# 把模型结果也保存到chat.txt文件中
sample_file.write(f"AI回复内容:{ai_res}\n")
# 返回响应结果
return ai_res最后,我们把响应的 ID 转换成文本,保存到日志里,然后返回给用户。
python
if __name__ == '__main__':
print('您好,我是你的健康助手小黑~')
while True:
user_input = input('请您输入您的问题(q退出):')
if user_input == 'q':
print('欢迎下次再来')
break
# 模型预测获取结果
my_model_res = model_predict(user_input)
print(f"AI助手回复:{my_model_res}")这是交互的入口,我们循环等待用户输入,然后调用模型预测,打印回复。
现在,你运行这个文件,就可以和你的医疗 AI 助手对话了!
第九章:Web 服务部署篇
现在,我们有了可以交互的模型了,但是只有你自己在命令行里能用。能不能做一个网页,别人也能通过浏览器来用呢?
当然可以!这就是我们的app\.py文件,用 Flask 把模型部署成 Web 服务。
9.1 Flask:轻量级 Web 框架
Flask 是 Python 的一个轻量级 Web 框架,用它我们可以很容易地把 Python 代码包装成 Web 服务。
我们来看代码:
python
from flask import Flask, request, jsonify, render_template
# TODO 导入自己的模型预测模块
import interact
# TODO 注意: Flask默认扫描的页面路径是 templates,如果要改路径,就需要使用template_folder
app = Flask(__name__, template_folder='templates')首先导入 Flask,还有我们的 interact 模块,这样我们就能调用模型预测了。然后创建 Flask 应用。
python
# 定义路由,处理根路径请求
@app.route('/')
def home():
"""
首页:展示简单的Web界面
"""
return render_template(['index.html'])这是根路径的路由,当用户访问网站的首页的时候,我们返回前端的页面index\.html。这个页面是一个简单的聊天界面,用户可以在里面输入问题,看到回复。
python
# 定义路由,处理用户提问
@app.route('/api/predict', methods=['POST'])
def predict():
"""
API接口:接收用户输入的医疗问题,返回模型预测结果
"""
# 从请求中获取JSON数据
data = request.get_json()
# 检验数据是否存在且包含'question'键
if not data or 'question' not in data:
# 如果数据无效,返回错误响应
return jsonify({'error': 'Invalid input'}), 400
# 从数据中提取问题文本
question = data['question']
# TODO 调用自己的模型预测方法
# 调用模型预测方法获取问题的答案
answer = interact.model_predict(question)
# 返回包含问题和答案的响应
return jsonify({
'question': question,
'answer': answer
})这是 API 接口,前端会把用户的问题通过 POST 请求发送到这个接口,然后我们调用interact\.model\_predict来得到答案,然后返回给前端。
python
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8888, debug=True)最后,启动 Flask 服务,监听 8888 端口。host=\&\#39;0\.0\.0\.0\&\#39;表示允许外部的机器访问,这样别人也能通过你的 IP 来访问这个服务了。
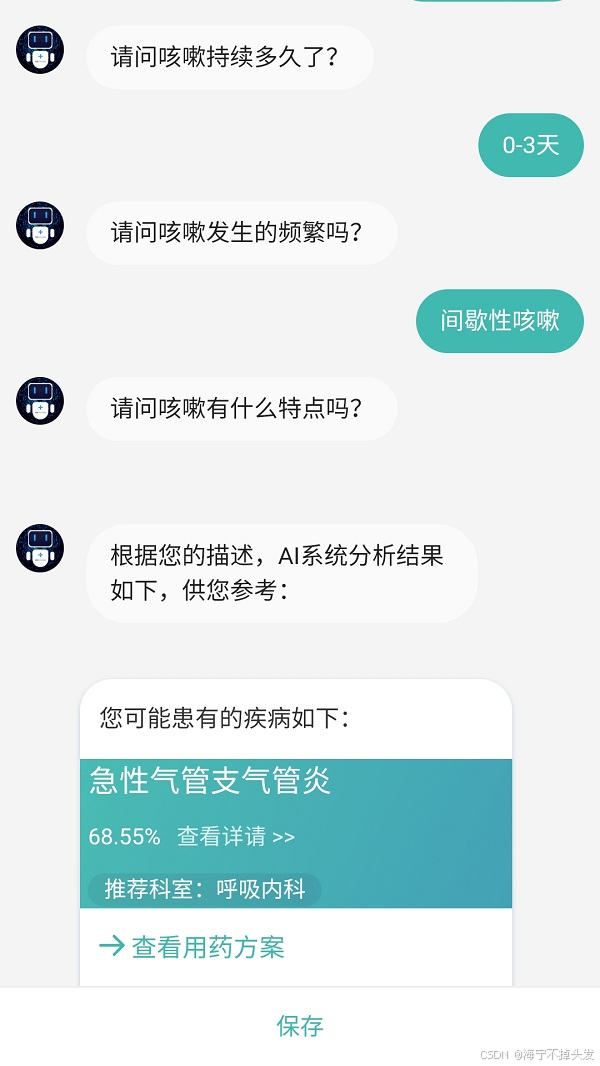
现在,你运行这个 app.py(app.py),然后打开浏览器,访问http://localhost:8888,你就能看到一个漂亮的聊天界面了,你可以在里面和你的 AI 助手对话,就像真正的问诊一样!
第十章:项目完整运行实战
好了,所有的代码我们都讲完了。现在,我们来从头到尾,一步步运行整个项目,让你亲手把它跑起来。
10.1 第一步:准备环境
首先,按照我们第二章讲的,安装好 Python、PyTorch 和各种依赖库。
bash
pip install torch transformers tqdm flask10.2 第二步:数据预处理
首先,我们要处理原始数据,把 txt 文件转换成 pkl 文件。
运行preprocess\.py:
bash
python preprocess.py这个脚本会处理medical\_train\.txt和medical\_valid\.txt,生成medical\_train\.pkl和medical\_valid\.pkl。
运行完之后,你会看到打印的信息:
Plain
词表的大小:-->13317
起始符[CLS]的token ID:-->101
结束符[SEP]的token ID:-->102
打印原始问答对列表--->['帕金森叠加综合征的辅助治疗有些什么?\n综合治疗;康复训练;生活护理指导;低频重复经颅磁刺激治疗']
打印原始问答对列表的个数-->30177
100%|██████████| 30177/30177 [00:05<00:00, 5632.12it/s]
...这说明数据预处理完成了。
10.3 第三步:训练模型
然后,我们开始训练模型。
运行my\_train\.py:
bash
python my_train.py这个脚本会加载数据,创建模型,然后开始训练。
你会看到类似这样的输出:
Plain
获取训练集长度:3772
获取验证集长度:51
模型已经移动到指定设备:cuda
模型参数数量为:124816896
-----------------------------开始训练------------------------------
================= TODO 训练=================
1%| | 29/3772 [00:01<02:02, 30.59it/s]
batch 1 of epoch 1, loss 10.2345, batch_acc 0.023, lr [2.6e-05]
...然后训练就开始了。如果你用的是 GTX 1650,整个训练过程大概需要几个小时。训练完之后,模型会保存在save\_model1文件夹里。
10.4 第四步:命令行交互
训练完了,你可以先在命令行里测试一下。
修改interact\.py里的模型路径,改成你训练好的模型的路径。然后运行:
bash
python interact.py你会看到:
Plain
当前使用的设备:cuda
您好,我是你的健康助手小黑~
请您输入您的问题(q退出):然后你就可以输入问题了,比如:
Plain
请您输入您的问题(q退出):感冒了怎么办?
AI助手回复:建议患者多喝水,多休息,注意保暖。是不是很棒?
10.5 第五步:Web 部署
如果你想做一个网页版的,那就运行app\.py:
bash
python app.py然后打开浏览器,访问http://localhost:8888,你就可以在网页里和 AI 助手对话了!
结语
恭喜你!你已经完成了整个医疗问诊 AI 大模型项目的学习!
现在,你已经彻底搞懂了:
-
大模型的核心概念:大模型、基础模型、预训练、微调、归一化、训练、测试、模型加载
-
大模型项目的完整开发流程:从数据处理,到数据集构建,到模型创建,到训练,到推理,到部署
-
每一行代码是怎么写出来的,为什么要这么写
-
如何在普通的消费级显卡上训练大模型
这只是一个开始,大模型的世界还有很多很多有趣的东西等着你去探索。你可以尝试:
-
用更大的数据集来训练模型
-
用更大的模型,比如 GPT2-medium,甚至 LLaMA
-
加入多轮对话的功能
-
加入知识库,让模型可以引用医学文献来回答问题
希望这本手册能够帮助你入门大模型的开发,开启你的 AI 之旅!
祝你学习愉快!