关于Network Flow Monitor
AWS Network Flow Monitor 是 Amazon CloudWatch 的网络监控子服务。其核心组件 aws-network-sonar-agent(即 nfm-agent)是一个部署在每个计算节点上的轻量级 agent,通过 Linux eBPF 技术采集 TCP 连接的性能指标。镜像地址为602401143452.dkr.ecr.us-east-2.amazonaws.com/aws-network-sonar-agent:v1.1.3-eksbuild.3
通过对镜像的分析agent 主要逻辑为/usr/local/bin/nfm-agent。Agent 使用 Rust 的 aya 框架(v0.13.1)加载 eBPF 程序到内核:
- 程序类型:
nfm_sock_ops(sockops BPF 程序) - 挂载点:cgroupv2 需要 init container 预先挂载
- BPF Maps:
NFM_SK_PROPS(socket 属性)、NFM_SK_STATS(socket 统计)、NFM_COUNTERS、NFM_CONTROL - 采集的内核事件:
active_connect_events、established_events、state_change_events、rtt_events、retrans_events、rto_events
Agent 不会访问 TCP 连接的 payload 数据,只采集连接级别的元数据和性能指标。
数据处理层
每 500ms 聚合一次(aggregate_msecs 默认 500),每 30 秒 ± 5 秒抖动上报一次
- 通过 conntrack 还原 NAT 转换后的真实 IP
- 按
local_address + remote_address + 服务端口聚合,临时端口归零- 主动外连:
local_port=0,remote_port=目标端口 - 被动接收:
local_port=服务端口,remote_port=0
- 主动外连:
上报层
上报格式为OTLP(OpenTelemetry Protocol),protobuf 编码,gzip 压缩,发送到端点https://networkflowmonitorreports.{region}.api.aws/publish
每次上报最多 500 个流(top_k 默认 500)
实际指标日志
通过实际运行 agent 并开启日志输出(-l on),获取到的完整报告结构:
流级别指标(network_stats):
json
{
"flow": {
"protocol": "TCP",
"local_address": "172.31.14.46",
"remote_address": "169.254.169.254",
"local_port": 0,
"remote_port": 80
},
"stats": {
"sockets_connecting": 0,
"sockets_established": 0,
"sockets_completed": 5,
"severed_connect": 0,
"severed_establish": 0,
"connect_attempts": 5,
"bytes_received": 1302,
"bytes_delivered": 1626,
"segments_received": 5,
"segments_delivered": 5,
"retrans_syn": 0,
"retrans_est": 0,
"retrans_close": 0,
"rtos_syn": 0,
"rtos_est": 0,
"rtos_close": 0,
"connect_us": {"count": 5, "min": 102, "max": 199, "sum": 696},
"rtt_us": {"count": 5, "min": 61, "max": 91, "sum": 380},
"rtt_smoothed_us": {"count": 5, "min": 92, "max": 131, "sum": 536}
}
}网卡限额指标(host_stats):
json
{
"interface_id": "eni-030xxxx06fd2",
"stats": {
"bw_in_allowance_exceeded": 0,
"bw_out_allowance_exceeded": 0,
"conntrack_allowance_exceeded": 0,
"linklocal_allowance_exceeded": 0,
"pps_allowance_exceeded": 0,
"conntrack_allowance_available": 119972
}
}OpenMetrics 端口(:9090/metrics):仅暴露 5 个网卡限额指标,与 host_stats 重复,无额外数据。
通过分析 entrypoint.sh 和二进制中的 partition 数据确认
entrypoint.sh中默认端点为https://networkflowmonitorreports.$region.api.aws/publish,而中国区的 DNS 后缀应为api.amazonwebservices.com.cn- Network Flow Monitor 服务本身未在 cn-north-1 / cn-northwest-1 部署
- 虽然支持自定义端点(
CUSTOM_INGESTION_ENDPOINT环境变量),但没有后端服务可用
实现思路
核心思路绕过 AWS Network Flow Monitor 后端,利用 agent 的 eBPF 采集能力,通过 EMF(Embedded Metric Format)将指标写入 CloudWatch。
eBPF 内核采集 → nfm-agent 日志输出 → EMF 转换 → CloudWatch Agent → CloudWatch Metrics关键参数:
-p off:关闭向 AWS 后端上报(避免报错)-l on:开启日志报告(完整 JSON 输出到 stdout)-n on:启用 NAT 解析--open-metrics on:启用 Prometheus 端口(可选)
文件结构
nfm-compose/
├── docker-compose.yml
├── cwagent-config.json
└── scripts/
├── start-nfm.sh
├── start-emf.sh
└── nfm_to_emf.pydocker-compose.yml
yaml
services:
nfm-agent:
image: 602401143452.dkr.ecr.us-east-2.amazonaws.com/aws-network-sonar-agent:v1.1.3-eksbuild.3
container_name: nfm-agent
entrypoint: ["/bin/sh", "/scripts/start-nfm.sh"]
privileged: true # eBPF 需要特权模式
network_mode: host # 采集宿主机网络
pid: host # 访问宿主机进程
restart: unless-stopped
logging:
driver: json-file
options:
max-size: "10m"
max-file: "3"
volumes:
- ./scripts:/scripts:ro
- shared-logs:/shared-logs
- /sys/fs/cgroup:/host-cgroup:rw # 挂载宿主机 cgroup,eBPF 才能采集所有流量
emf-converter:
image: python:3.11-slim
container_name: emf-converter
entrypoint: ["/bin/sh", "/scripts/start-emf.sh"]
depends_on:
- nfm-agent
restart: unless-stopped
logging:
driver: json-file
options:
max-size: "10m"
max-file: "3"
volumes:
- ./scripts:/scripts:ro
- shared-logs:/shared-logs
- emf-logs:/emf-logs
cloudwatch-agent:
image: public.ecr.aws/cloudwatch-agent/cloudwatch-agent:latest
container_name: cloudwatch-agent
depends_on:
- emf-converter
restart: unless-stopped
logging:
driver: json-file
options:
max-size: "10m"
max-file: "3"
volumes:
- ./cwagent-config.json:/etc/cwagentconfig/cwagent.json:ro
- emf-logs:/emf-logs
environment:
- AWS_REGION=cn-north-1
network_mode: host # 访问 IMDS 获取 IAM 凭证
log-rotator:
image: alpine:3
container_name: log-rotator
restart: unless-stopped
entrypoint: ["/bin/sh", "-c"]
command:
- |
while true; do
sleep 3600
for f in /shared-logs/nfm.log /emf-logs/emf.log; do
if [ -f "$$f" ]; then
size=$$(stat -c%s "$$f" 2>/dev/null || echo 0)
if [ "$$size" -gt 52428800 ]; then
: > "$$f"
echo "$$(date) Truncated $$f (was $${size} bytes)"
fi
fi
done
done
volumes:
- shared-logs:/shared-logs
- emf-logs:/emf-logs
volumes:
shared-logs:
emf-logs:start-nfm.sh Agent 启动脚本
bash
#!/bin/sh
set -e
# 挂载宿主机的根 cgroupv2,这样 eBPF 能捕获所有进程的 TCP 连接
CGROUP_PATH="/host-cgroup"
exec /usr/local/bin/nfm-agent \
--cgroup /cgroup-mount/cgroup-nfm-agent \
--endpoint-region "$region" \
--endpoint "" \
-p off \ # 关闭向 AWS 后端上报
-l on \ # 开启日志报告输出
-k off \ # 关闭 K8s 元数据(EC2 单机无需)
-n on \ # 启用 NAT 解析
--publish-secs 30 \
--jitter-secs 5 \
--open-metrics on \
--open-metrics-port 9090 \
--open-metrics-address 0.0.0.0 \
2>&1 | tee /shared-logs/nfm.logstart-emf.sh EMF 转换器启动脚本
bash
#!/bin/sh
echo "Waiting for nfm-agent logs..."
while [ ! -f /shared-logs/nfm.log ]; do
sleep 1
done
echo "Starting EMF converter, writing to /emf-logs/emf.log"
tail -F /shared-logs/nfm.log | python3 /scripts/nfm_to_emf.py >> /emf-logs/emf.lognfm_to_emf.py 日志转 EMF 格式
python
#!/usr/bin/env python3
"""nfm-agent JSON log -> CloudWatch EMF format (network_stats + host_stats)"""
import json, sys
def to_emf(entry):
report = entry["report"]
ts = entry["timestamp"]
env = dict(report.get("env_metadata", []))
k8s = report.get("k8s_metadata", {})
instance_id = env.get("instance-id", {}).get("String", "unknown")
node_name = k8s.get("node_name") or instance_id
# Part 1: 流级别指标
for item in report.get("network_stats", []):
flow = item["flow"]
stats = item["stats"]
rtt_count = stats["rtt_us"]["count"]
avg_rtt = stats["rtt_us"]["sum"] / max(rtt_count, 1)
seg_total = stats["segments_delivered"] + stats["segments_received"]
retrans_total = (stats["retrans_syn"] + stats["retrans_est"]
+ stats["retrans_close"])
emf = {
"_aws": {
"Timestamp": ts,
"CloudWatchMetrics": [{
"Namespace": "NFM/NetworkFlows",
"Dimensions": [
["NodeName", "LocalAddress", "RemoteAddress",
"RemotePort"],
["NodeName", "RemoteAddress", "RemotePort"],
["NodeName"],
],
"Metrics": [
{"Name": "AvgRttUs", "Unit": "Microseconds"},
{"Name": "MaxRttUs", "Unit": "Microseconds"},
{"Name": "AvgConnectUs", "Unit": "Microseconds"},
{"Name": "BytesReceived", "Unit": "Bytes"},
{"Name": "BytesDelivered", "Unit": "Bytes"},
{"Name": "Retransmissions", "Unit": "Count"},
{"Name": "RetransRate", "Unit": "None"},
{"Name": "SeveredConnect", "Unit": "Count"},
{"Name": "SocketsCompleted", "Unit": "Count"},
]
}]
},
"NodeName": node_name,
"InstanceId": instance_id,
"LocalAddress": flow["local_address"],
"RemoteAddress": flow["remote_address"],
"RemotePort": str(flow["remote_port"]),
"AvgRttUs": round(avg_rtt, 1),
"MaxRttUs": stats["rtt_us"]["max"],
"AvgConnectUs": round(
stats["connect_us"]["sum"]
/ max(stats["connect_us"]["count"], 1), 1),
"BytesReceived": stats["bytes_received"],
"BytesDelivered": stats["bytes_delivered"],
"Retransmissions": retrans_total,
"RetransRate": round(
retrans_total / max(seg_total, 1), 6),
"SeveredConnect": stats["severed_connect"],
"SocketsCompleted": stats["sockets_completed"],
}
print(json.dumps(emf), flush=True)
# Part 2: 网卡限额指标
for iface in report.get("host_stats", {}).get("interface_stats", []):
s = iface.get("stats", {})
emf = {
"_aws": {
"Timestamp": ts,
"CloudWatchMetrics": [{
"Namespace": "NFM/HostStats",
"Dimensions": [
["NodeName", "InterfaceId"],
["NodeName"],
],
"Metrics": [
{"Name": "BwInAllowanceExceeded", "Unit": "Count"},
{"Name": "BwOutAllowanceExceeded", "Unit": "Count"},
{"Name": "PpsAllowanceExceeded", "Unit": "Count"},
{"Name": "ConntrackAllowanceExceeded", "Unit": "Count"},
{"Name": "ConntrackAllowanceAvailable", "Unit": "Count"},
{"Name": "LinklocalAllowanceExceeded", "Unit": "Count"},
]
}]
},
"NodeName": node_name,
"InstanceId": instance_id,
"InterfaceId": iface.get("interface_id", "unknown"),
"BwInAllowanceExceeded": s.get("bw_in_allowance_exceeded", 0),
"BwOutAllowanceExceeded": s.get("bw_out_allowance_exceeded", 0),
"PpsAllowanceExceeded": s.get("pps_allowance_exceeded", 0),
"ConntrackAllowanceExceeded": s.get(
"conntrack_allowance_exceeded", 0),
"ConntrackAllowanceAvailable": s.get(
"conntrack_allowance_available", 0),
"LinklocalAllowanceExceeded": s.get(
"linklocal_allowance_exceeded", 0),
}
print(json.dumps(emf), flush=True)
for line in sys.stdin:
try:
entry = json.loads(line.strip())
if entry.get("message") == "Publishing report":
to_emf(entry)
except Exception:
passcwagent-config.json CloudWatch Agent 配置
json
{
"agent": {
"region": "cn-north-1",
"debug": false
},
"logs": {
"metrics_collected": {
"emf": {}
},
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/emf-logs/emf.log",
"log_group_name": "/nfm/emf-metrics",
"log_stream_name": "{instance_id}",
"timezone": "UTC"
}
]
}
},
"force_flush_interval": 5
}
}关键配置说明:
metrics_collected.emf: {}:开启 EMF 解析,CW Agent 发现日志中包含_aws.CloudWatchMetrics字段时自动提取指标file_path:监听 emf-converter 输出的 EMF 日志文件log_group_name:EMF 日志同时存入 CloudWatch Logs,可用 Logs Insights 查询明细force_flush_interval: 5:每 5 秒刷新一次
CloudWatch 中的指标
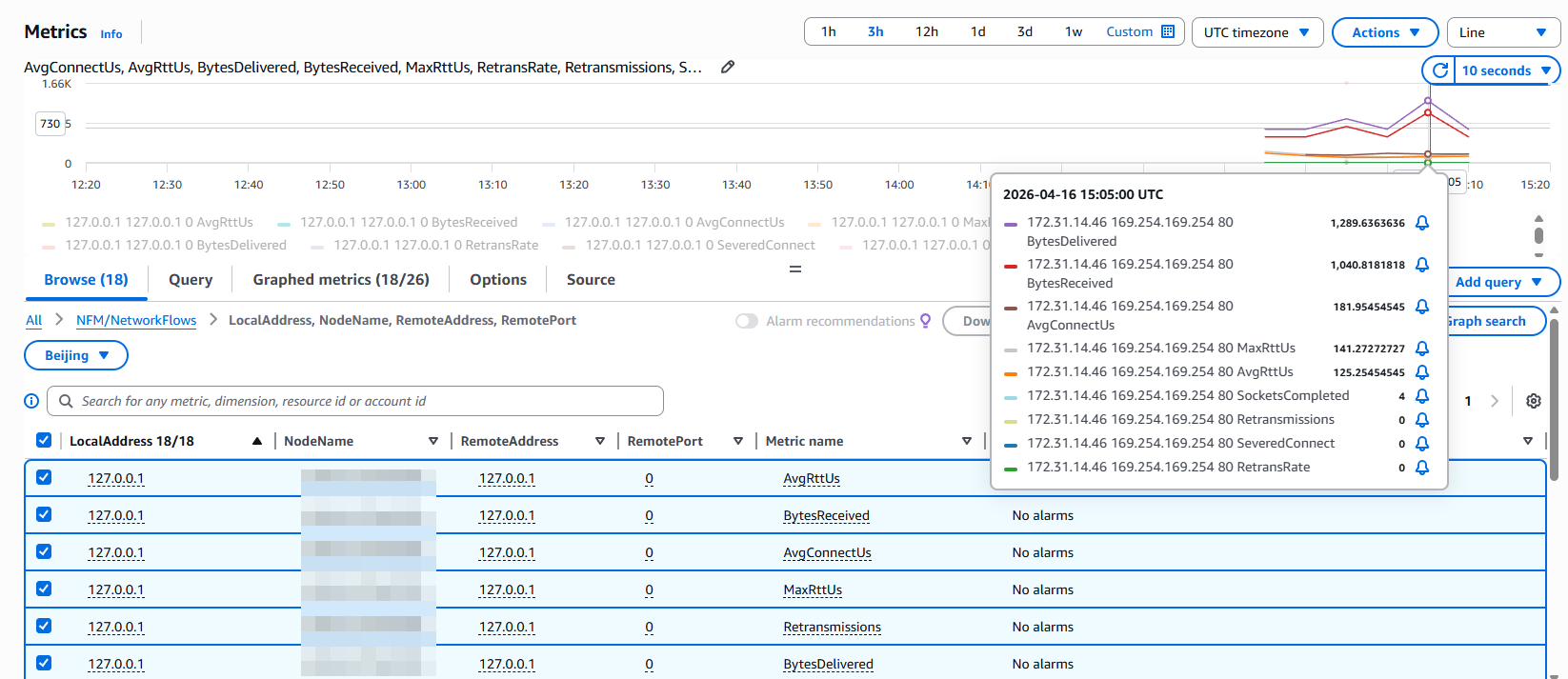
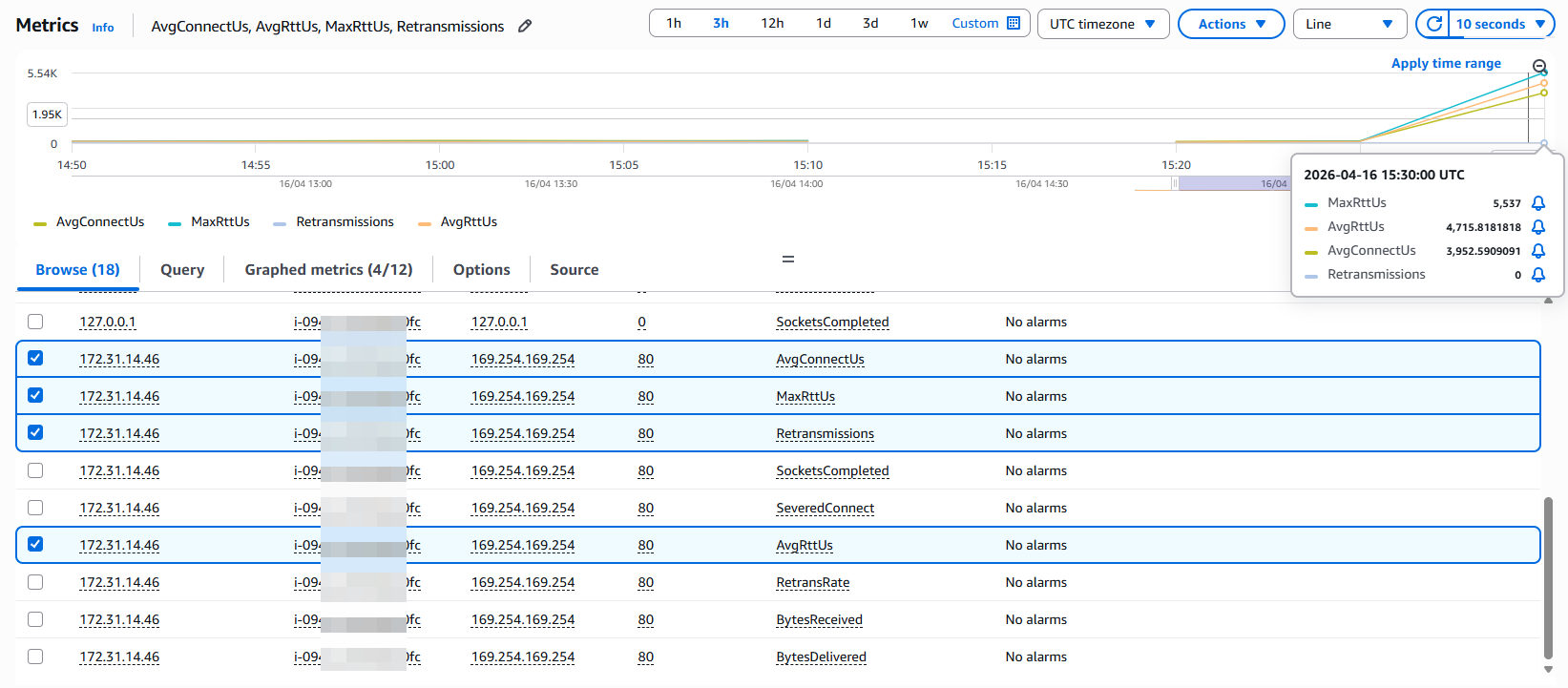
部署后,CloudWatch 中自动出现两个命名空间:
NFM/NetworkFlows
维度组合:
NodeName:节点级汇总NodeName + RemoteAddress + RemotePort:按目标查看NodeName + LocalAddress + RemoteAddress + RemotePort:完整视图
| 指标 | 单位 | 说明 |
|---|---|---|
| AvgRttUs | Microseconds | 平均 TCP 往返时间 |
| MaxRttUs | Microseconds | 最大 RTT |
| AvgConnectUs | Microseconds | 平均 TCP 连接建立耗时 |
| BytesReceived | Bytes | 接收字节数 |
| BytesDelivered | Bytes | 发送字节数 |
| Retransmissions | Count | TCP 重传次数 |
| RetransRate | None | 重传率 |
| SeveredConnect | Count | 异常断开的连接数 |
| SocketsCompleted | Count | 正常完成的连接数 |
NFM/HostStats
| 指标 | 说明 |
|---|---|
| BwInAllowanceExceeded | 入站带宽超限丢包数 |
| BwOutAllowanceExceeded | 出站带宽超限丢包数 |
| PpsAllowanceExceeded | PPS 超限丢包数 |
| ConntrackAllowanceExceeded | 连接跟踪超限丢包数 |
| ConntrackAllowanceAvailable | 剩余可用连接跟踪数 |
| LinklocalAllowanceExceeded | 本地代理 PPS 超限丢包数 |
RTT 异常检测思路
静态阈值
AvgRttUs > 2000(2ms)→ WARNING
AvgRttUs > 5000(5ms)且 Retransmissions > 0 → CRITICAL综合判断
RTT 突增 + 重传正常 → 对端处理慢,应用层问题
RTT 突增 + 重传增加 → 网络拥塞或链路问题
RTT 正常 + 重传增加 → 丢包,可能是网卡/交换机问题
RTT 突增 + SeveredConnect 增加 → 严重网络故障长连接场景下RTT 数据来自内核每次 ACK 的采样,长连接每 30 秒窗口都有持续的 rtt_us {count, min, max, sum}。检测方法为
- 突变:
cur_avg / prev_avg > 3 - 抖动:
max / avg > 10(间歇性问题,如 GC、网络瞬断)
模拟高 RTT 验证
使用 tc(traffic control)给网卡注入延迟,验证采集和告警链路。