
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》
《个人在线OJ平台》《Linux网络编程》《CMake自动化构建工具》《Redis数据库》
🌸Yupureki🌸的简介:

目录
[1. IP报头格式](#1. IP报头格式)
[2. IP协议的传输工作](#2. IP协议的传输工作)
[2.1 寻址与路由](#2.1 寻址与路由)
[2.2 数据封装](#2.2 数据封装)
[2.3 分片与重组](#2.3 分片与重组)
[3. 网段划分](#3. 网段划分)
[3.1 子网的由来](#3.1 子网的由来)
[3.1.1 早期因特网的困境](#3.1.1 早期因特网的困境)
[3.1.2 初代方案:子网划分与子网掩码](#3.1.2 初代方案:子网划分与子网掩码)
[3.1.3 现代方案:CIDR 无类别域间路由](#3.1.3 现代方案:CIDR 无类别域间路由)
[3.2 公网与私网](#3.2 公网与私网)
[3.2.1 私有IP地址](#3.2.1 私有IP地址)
[3.2.2 NAT](#3.2.2 NAT)
[3.3 重点概念的重新认识](#3.3 重点概念的重新认识)
[3.3.1 以太网](#3.3.1 以太网)
[3.3.2 子网](#3.3.2 子网)
[3.3.3 私网](#3.3.3 私网)
[3.3.4 公网](#3.3.4 公网)
[3.3.5 因特网](#3.3.5 因特网)
[3.3.6 万维网](#3.3.6 万维网)
[4. 路由](#4. 路由)
[4.1 路由的概念](#4.1 路由的概念)
[4.2 公网和路由的关系](#4.2 公网和路由的关系)
[5. 一个数据包的"出国旅行"](#5. 一个数据包的“出国旅行”)
1. IP报头格式
IP协议(这里主要指IPv4 )的报头格式如下,通常为20~60字节,由固定部分和可选字段组成。
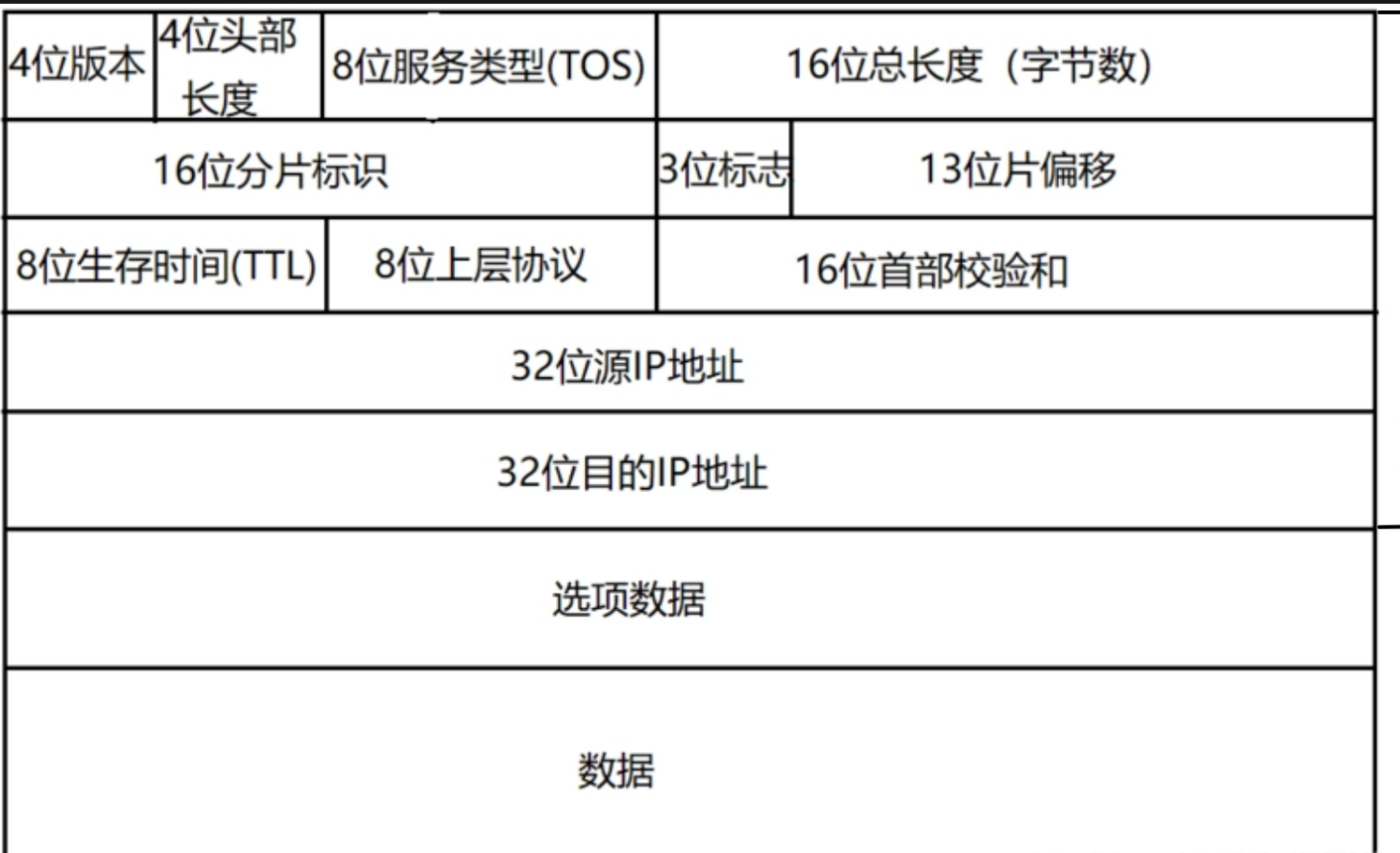
各字段含义
-
版本(4位)
IP协议版本号,IPv4的值为
4。 -
首部长度(4位)
表示IP报头的长度,以4字节 为单位。最小值为
5(即5×4 = 20字节),最大为15(60字节)。因为可选项的存在,报头长度可变。
-
服务类型/区分服务(8位)
早期用于指定优先级、延迟、吞吐量等
-
总长度(16位)
整个IP数据报(报头+数据)的长度,以字节为单位。最大65535字节,但通常受链路层MTU限制(如以太网1500字节)。
-
标识(16位)
用于唯一标识一个数据报的所有分片。当数据报被分片后,同一原始数据报的所有分片具有相同的标识值,便于接收方重组。
-
标志(3位)
-
第0位:保留,必须为0。
-
第1位:DF,置1时禁止分片,若数据报超过MTU则丢弃并返回ICMP差错报文。
-
第2位:MF,置1表示后续还有分片;最后一个分片该位为0。
-
-
片偏移(13位)
表示该分片在原始数据报中的相对位置,以8字节为单位。用于接收方按序重组分片。
-
生存时间 TTL(8位)
限制数据报经过的最大跳数(路由器数)。每经过一个路由器TTL减1,减到0时丢弃数据报并回送ICMP超时消息。防止数据报无限循环。
-
协议(8位)
指明数据部分使用的上层协议,如
6(TCP)、17(UDP)、1(ICMP)等。用于到达目的地后交给正确的协议处理。 -
首部校验和(16位)
只对IP报头 计算校验和(不包括数据部分)。每经过一跳路由器,因TTL变化,校验和会被重新计算。
计算方式:将报头按16位分段,求反码和后再取反。
-
源IP地址(32位)
发送方的IPv4地址。
-
目的IP地址(32位)
接收方的IPv4地址。
-
可选字段(长度可变)
可选功能,如记录路由、时间戳、严格/宽松源路由等,很少使用。
长度以4字节为单位,不足时用全0的填充字节补全,使报头长度为4字节的整数倍。
-
填充
用于确保报头结束于32位边界。
2. IP协议的传输工作
首先,理解IP协议的两个基本设计哲学至关重要:
-
无连接:在发送数据包之前,IP协议不会像打电话那样先建立一个固定的端到端连接。每个数据包都是独立的个体,并可能走不同的路。
-
不可靠,但尽力而为 :IP协议不保证数据包一定能送达、不保证按序到达、也不保证数据不重复。它只承诺尽最大努力去投递,这种机制被称为"尽力而为的服务"(best-effort delivery)。端到端的可靠性,需要由它的"搭档"------TCP协议来保证。
2.1 寻址与路由
这是IP协议最核心的功能,它就像物流系统中的地址和导航:
-
IP地址 :是网络中每个设备的唯一逻辑地址,就像"xx省xx市xx区xx路xx号"。在IPv4中,它是一个32位的数字,通常写成4组,例如
192.168.1.1。 -
子网划分 :为了方便管理,IP地址被分为"网络号"(标识所在的网络区域)和"主机号"(标识区域内的具体设备)两部分。通过子网掩码 (如
255.255.255.0)来区分这两部分。 -
路由选择 :当数据包从A发往B时,沿途的路由器 会检查数据包的目的IP地址,然后查询自己的路由表,为数据包选择一条通往目的地的"下一跳"路径。这个过程是逐跳(hop-by-hop)进行的,直到数据包最终抵达目标网络。
2.2 数据封装
发送数据时,IP协议会从传输层(TCP/UDP)接收数据,然后在数据前面添加一个IP报头 ,形成一个IP数据包。这个报头就是物流"快递单",包含了所有关键信息:
-
源IP地址和目的IP地址:寄件人和收件人的全球唯一地址。
-
报文标识、标志、片偏移:用于后续的分片和重组。
-
TTL生存时间:数据包在网络中能经过的最大跳数(比如最多经过64个路由器),防止数据包在网络中无限循环。
-
上层协议:指明包裹里装的是哪种货物,比如是TCP(6)、UDP(17)还是ICMP(1)。
-
首部校验和:用于检查"快递单"本身是否在运输中损坏。
2.3 分片与重组
不同的物理网络有不同的最大传输单元(MTU),就像不同运输工具对包裹尺寸有限制。例如,以太网的MTU通常是1500字节。
如果一个IP数据包"超重",超过了链路的MTU,IP协议就会将其"化整为零":
-
分片Fragmentation:在发送端或中间路由器,将数据部分切成多个小片,以适配即将经过网络的MTU。
-
贴标签:每个分片都带有一个IP报头,其中:
-
标识 字段相同,表示它们属于同一个原始数据包。
-
标志(MF,More Fragments) 字段指示后面是否还有更多分片。
-
片偏移 字段记录了该分片在原始数据包中的位置。
-
-
重组Reassembly :只有在最终目的地,才会进行重组。目的主机利用这些标签,将收到的所有分片重新拼接成完整的数据包。
为何要"避免分片"?
分片会带来性能损耗和丢包风险,因为一旦一个分片丢失,整个数据包就作废了。因此,现代网络通常会采用路径MTU发现等技术,在发送端就探测并避免分片。
3. 网段划分
要讲网段划分,我们就必须回顾互联网的发展史,为什么要网段划分?
3.1 子网的由来
3.1.1 早期因特网的困境
在互联网的雏形ARPANET时期,为了方便管理,IP地址被设计为"有类地址",即按规模大小分为A、B、C等类别:
| 类别 | 网络数 | 主机数 | 适用场景 | 问题 |
|---|---|---|---|---|
| A类 | 126个 | 超1670万台 | 国家级网络 | 地址空间巨大,几乎无法管理 |
| B类 | 约1.6万个 | 65534台 | 大型机构 | 对多数机构过多,造成浪费 |
| C类 | 约200万个 | 254台 | 小型公司 | 对多数机构过少,不够灵活 |
这种"一刀切"的方式导致两大严重问题:
-
IP地址严重浪费:一个仅有几十人的小公司若申请B类地址,会导致数万个IP被闲置。
-
路由表爆炸式增长:每个物理网络都需在互联网主干路由表中占一条记录,C类小型网络极多,导致路由表规模失控,严重影响路由器的效率和速度。
这就像给一个几十人的小公司分配了一栋能容纳数百人的办公楼,造成了资源的巨大闲置和浪费。
3.1.2 初代方案:子网划分与子网掩码
为了解决上述问题,工程师们在1985年左右提出了子网划分 和子网掩码的方案。
子网划分的思路
子网划分的核心是向主机位"借"位,来创建新的"子网位"。这相当于把一个大型的、难以管理的网络大院,内部分隔成多个独立的小院落(子网)。这一过程仅在机构内部可见,对外,整个机构仍表现为一个统一的网络。
子网划分将IP地址从"网络号 + 主机号"变成了"网络号 + 子网号 + 主机号"的三级结构。
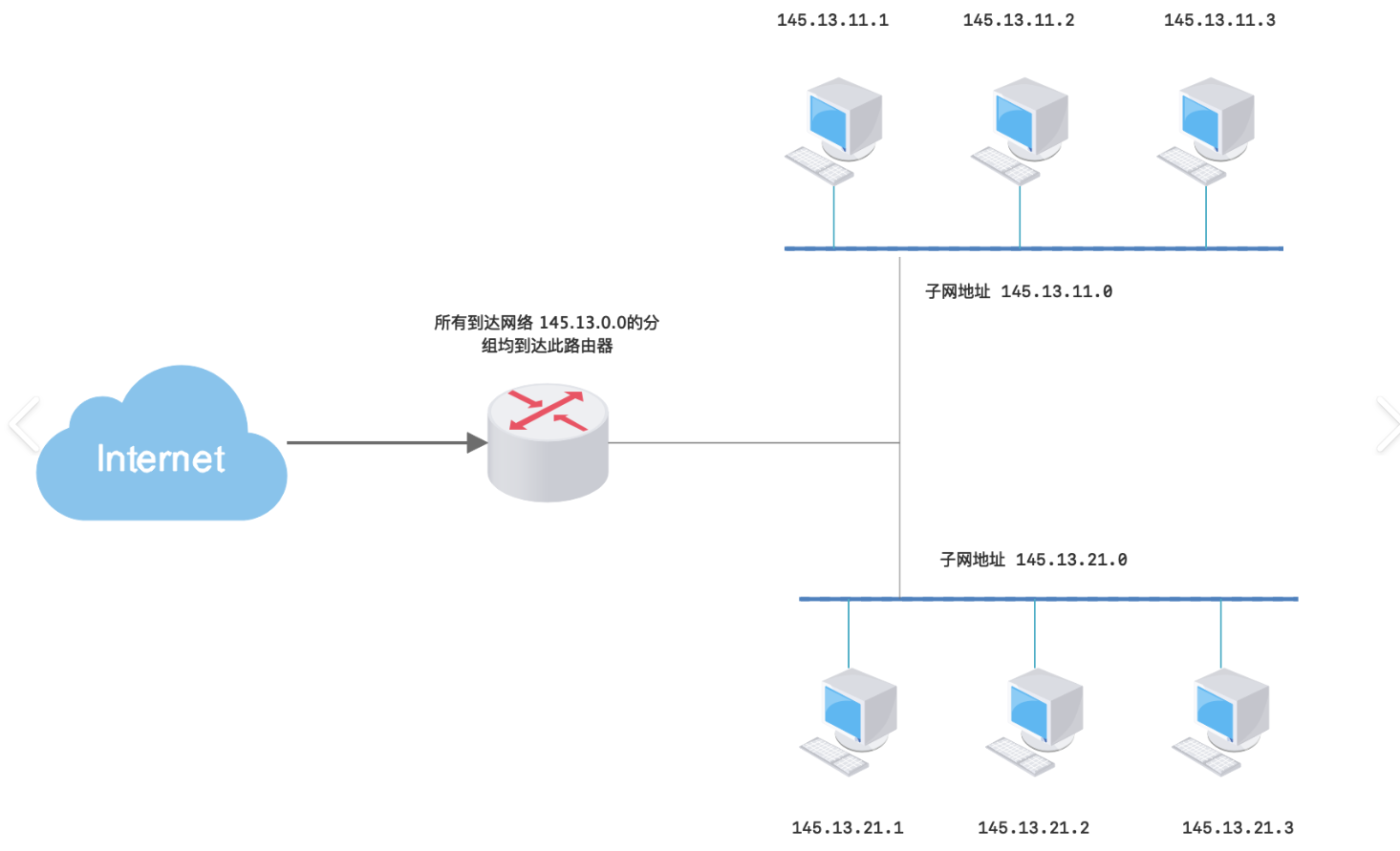
子网掩码扮演的角色
这就引出了一个关键问题:当一个数据包到达时,路由器如何知道它应该去往内部的哪个子网呢?
答案就是子网掩码 。它是一把精密的标尺,定义了IP地址中哪些位是网络标识(包括子网位),哪些是主机标识。
-
规则 :掩码中连续的
1对应网络位,**连续的0**对应主机位。 -
工作方式 :网络设备将IP地址与子网掩码进行"逻辑与"运算,如果两个地址的运算结果相同,就说明它们属于同一个子网,可直接通信;如果不同,则需将数据包发送给网关,由路由器进行转发。
子网掩码就是为了配合子网划分而诞生,它告诉了网络设备如何去理解一个IP地址的内部结构。
3.1.3 现代方案:CIDR 无类别域间路由
子网划分非常成功,催生了更彻底的解决方案------无类别域间路由 (CIDR)。
CIDR于1993年被提出,它的核心思想是彻底打破A、B、C类的固定边界 。它采用"斜线记法"(如 /24)来直接指示网络前缀的长度。
CIDR带来了两大革命性优势:
-
灵活的地址分配 :允许网络管理员使用可变长子网掩码 (VLSM),根据实际需求精确分配任意大小的地址块,极大地提升了地址利用率。
-
路由聚合(超网):可以将多个连续的小地址块"打包"成一个大的路由通告,使全球路由表条目数从数万条骤降到数千条,有效遏制了路由表的爆炸式增长。
3.2 公网与私网
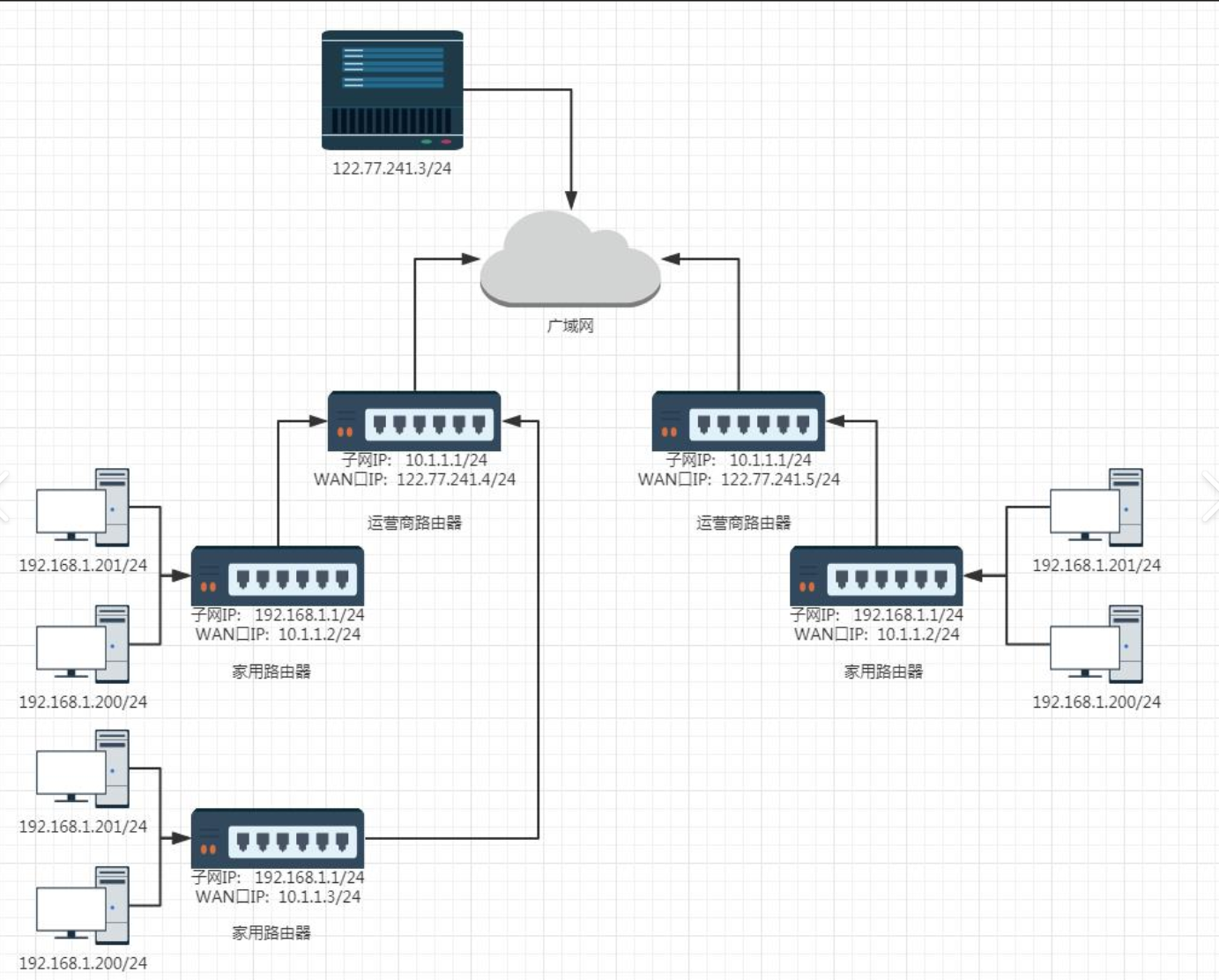
在技术演进的同时,另一场危机也在悄然降临:IPv4地址即将耗尽。子网划分和CIDR虽然提升了利用率,但无法改变42亿个绝对地址的上限。为应对此危机,催生了两个相互配合的关键技术:私有IP地址 和网络地址转换 (NAT)。
3.2.1 私有IP地址
1996年,IETF在RFC 1918中划定了几段专用地址,任何组织都可以无限制地重复使用:
| 类别 | IP地址范围 | 默认掩码 |
|---|---|---|
| A类私网 | 10.0.0.0 ~ 10.255.255.255 |
255.0.0.0 (/8) |
| B类私网 | 172.16.0.0 ~ 172.31.255.255 |
255.240.0.0 (/12) |
| C类私网 | 192.168.0.0 ~ 192.168.255.255 |
255.255.0.0 (/16) |
这些地址可以被世界上无数个家庭和企业同时在内部使用,极大地缓解了对公网地址的消耗。
3.2.2 NAT
NAT技术于1994年提出,它是连接使用私有IP地址的内部网络与使用公有IP地址的全球互联网的唯一桥梁。
它的核心工作机制如下:
-
建立映射:家中的路由器(NAT设备)会维护一个NAT转换表。
-
地址替换 :当内网设备向外网发起请求时,路由器会将数据包中的私有源IP地址替换为自己WAN口的公有IP地址,并分配一个唯一的端口号。
-
记录状态:转换记录("私有IP:端口"↔"公有IP:端口")会存入NAT表。
-
逆向转换:当外网数据返回时,路由器根据接收到的公有IP和端口号,查询NAT表,并将这个公网IP替换回原先的私有IP和端口,最终送达给发起请求的设备。
关键点 :需要明确,这个通信过程必须由内部主机首先发起。NAT技术像一个智能门卫,没有内部预先登记的外来者,无法直接访问内部主机,这在客观上也为内部网络提供了一定的安全防护
3.3 重点概念的重新认识
有很多"网":公网 私网 子网 以太网 因特网 万维网这些概念都有什么关系和区别?
一图理清:
bash
+-----------------------------------------------------------------------+
| 万 维 网 (WWW) |
| HTTP / HTTPS 协议驱动的全球超媒体应用系统 |
| (你正在看的网页、视频、API 接口都在这里) |
+---▲-------------------------------------------------------------------+
| 依赖
+---▼-------------------------------------------------------------------+
| |
| 因 特 网 (Internet) |
| = 全球所有使用 TCP/IP 协议族互联的网络集合 |
| |
| +----- 核心寻址体系 ----------------------------------------------+ |
| | | |
| | +----- 公 网 (Public IP) -----------+ 你的运营商给你的地址 | |
| | | 全球唯一,可直接路由 | 比如 1.2.3.4 | |
| | | IANA 统一分配 | | |
| | | 如: 8.8.8.8, 203.0.113.0/24 | | |
| | +-----------------------------------+ | |
| | ▲ | |
| | | 通过 NAT 转换 | |
| | ▼ | |
| | +----- 私 网 (Private IP) ---------+ 你的家庭/公司内部地址 | |
| | | 不可在公网直接路由 | 比如 192.168.1.5 | |
| | | 可被无数组织重复使用 | | |
| | | 如: 192.168.x.x, 10.x.x.x | | |
| | +-----------------------------------+ | |
| | | |
| +------ 子网划分 (Subnetting) 贯穿其间 ---------------------------+ |
| | | |
| | 无论公网还是私网,都可以通过子网掩码进一步划分为更小的子网: | |
| | | |
| | ┌─ 公网 203.0.113.0/24 ─┐ ┌─ 私网 192.168.1.0/24 ────┐ | |
| | │ ├─ 203.0.113.0/25 │ │ ├─ 192.168.1.0/26 (客厅)│ | |
| | │ └─ 203.0.113.128/25 │ │ └─ 192.168.1.128/26(卧室)│ | |
| | └───────────────────────┘ └────────────────────────────┘ | |
| | | |
| +------------------------------------------------------------------+ |
| |
| 运转依赖:OSPF / BGP 路由协议、IP协议、NAT、DNS 等 |
+---▲-------------------------------------------------------------------+
| 依赖
+---▼-------------------------------------------------------------------+
| 以 太 网 (Ethernet) |
| 局域网物理/链路层标准,定义了帧格式、MAC地址、交换机规则 |
| 日常用的网线、Wi-Fi 骨干、交换机端口,都是以太网的范畴 |
+-----------------------------------------------------------------------+3.3.1 以太网
定义 :一种局域网(LAN)技术标准,定义了数据在物理线缆 (网线、光纤)和链路层上的传输规则。它规定了数据帧的格式和物理地址(MAC地址)的使用。
-
层次:物理层和数据链路层。
-
关键 :它是硬件基础,是我们日常插网线、连Wi-Fi(以以太网为骨干)所依赖的技术。你电脑的网卡、交换机端口都遵循以太网标准。
-
关系 :以太网是承载IP数据包的最主要物理和链路层技术。你可以把它理解为"货车"和"本地马路"。
3.3.2 子网
定义 :一个逻辑概念,是网络管理员在IP网络(网络层)上,通过子网掩码把一个大的IP地址空间划分成的独立小网络。
-
层次:网络层。
-
关键 :它是一个逻辑规划工具,用于隔离广播域、提高安全性和便于管理。子网的划分完全由管理员通过修改子网掩码来决定,与物理位置没有绝对关系。
-
关系 :无论是公网还是私网地址,都可以在其中进一步规划子网。子网定义了一个IP网段内主机可以直接通信的范围。
3.3.3 私网
定义 :根据RFC 1918规定,预留出三块在互联网上不可直接路由、供内部自由重复使用的IP地址范围。
-
层次:网络层(地址范畴)。
-
关键 :它是解决公网IPv4地址不足的核心手段。地址块包括:
-
10.0.0.0/8 -
172.16.0.0/12 -
192.168.0.0/16
-
-
关系 :你家里的Wi-Fi路由器给手机、电脑分配的就是私网IP。这些设备要上网,必须通过NAT技术 ,把私网IP转换成路由器的公网IP。在一个私网内部,又可以继续划分出更多子网。
3.3.4 公网
定义 :由IANA(互联网号码分配局)统一分配,在全球互联网上唯一且可直接路由的IP地址。
-
层次:网络层(地址范畴)。
-
关键 :它是互联网通信的唯一"身份证"。全球的骨干路由器上,路由表里记录的全是公网IP段。公网IP非常稀缺,需要向ISP(互联网服务提供商)申请购买或租用。
3.3.5 因特网
定义:指全球范围内,通过TCP/IP协议族互相连接起来的庞大计算机网络集合。它的名字Internet就是"互联的网络"之意。
-
层次:网络层及以上(整个网络实体)。
-
关键 :它是一个物理与逻辑交织的全球网络实体 。它将无数以太网、光纤网、无线网连接起来,底层依赖公网IP进行全球寻址和路由,让世界各地的公网设备都能互相找到。
-
关系 :因特网是"网络"本身。
3.3.6 万维网
定义 :构建在因特网之上的一种分布式应用服务系统。通过HTTP/HTTPS协议,将无数的网页、图片、视频等超媒体资源链接在一起。
-
层次:应用层。
-
关键 :它是应用服务 ,不是网络本身。我们通过浏览器输入
www.example.com访问的就是万维网。 -
关系 :万维网是因特网上最流行、最广泛使用的信息服务。除了万维网,因特网上还运行着电子邮件(SMTP)、文件传输(FTP)等无数其他应用。我们常说的"上网",很多时候指的就是使用万维网。
4. 路由
4.1 路由的概念
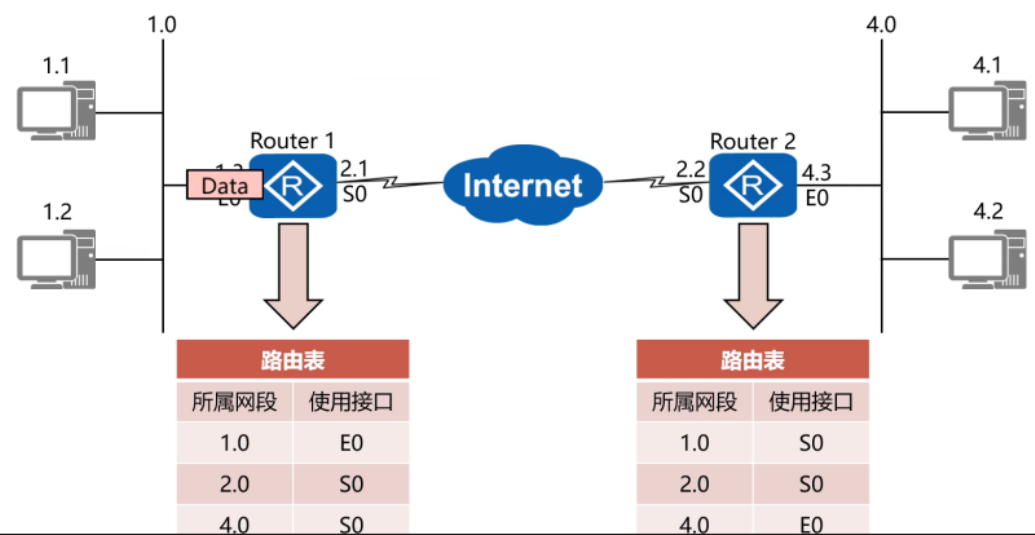
路由,简单来说,就是数据包在网络中寻找最佳路径,从源地址一跳一跳地最终抵达目的地址的过程。它由无数台路由器协作完成,就像全球邮政系统的分拣中心一样。
每个路由器内部都维护着一张路由表 ,它记录了"去往某个网络,下一跳应该交给谁"。一个数据包到达路由器后,路由器会检查它的目的IP地址,在路由表里查找匹配的条目,然后把它从相应的接口转发出去。如果路由表里没有匹配的条目,包就会被丢弃。
这个过程是逐跳的,每个路由器只负责把包送到下一个离目标更近的节点,而不需要知道完整的路径。
4.2 公网和路由的关系
这两者的关系,可以从三个层面来理解:
1. 公网地址是"可被路由"的,私网地址不是
这是最根本的区别。全球互联网中的骨干路由器,它们路由表里存放的全部是公网IP网段的条目 。比如你的运营商拥有 1.2.0.0/16 这个公网地址块,它就会通过BGP这样的路由协议,向全世界宣告"这些地址在我这里,请把去往它们的数据包都送给我"。
而 10.x.x.x、192.168.x.x 这类私有地址段,是永远不会被写入公共路由表的。任何一个骨干路由器,如果遇到了目标是私有地址的数据包,它会直接丢弃,因为这在地球上不是唯一的地址,无法确定到底要投递到哪个"192.168.1.1"。所以,私网地址天生就是不可以在公网上直接路由的。
2. 公网路由系统是地址聚合(CIDR)的最大受益者
早期的有类路由表,有几十万条杂乱的小网络条目。正是CIDR的引入,让全球的路由器可以把连续的公网地址块"打包"成一条大的路由条目。比如,谷歌拥有 8.8.0.0/16 这个公网段,全球的路由器只需要记住一条"去 8.8.0.0/16 找某条路"即可,而不用记256条C类路由。如果没有公网地址的层次化分配和路由聚合,今天的全球路由表早已大到任何设备都无法承载。
3. 私网通过NAT"借用"公网身份接入路由系统
那么,我们用私网地址的设备,是如何上网的呢?关键就在于NAT网络地址转换。当你的电脑(192.168.1.100)访问一个网站时,数据包会先到达家庭路由器。路由器把私网源IP换成自己WAN口上的公网IP 1.2.3.4,并记下一个转换记录,然后再把这个包发出去。
从互联网上这个网站的回包,其目的地址就是公网IP 1.2.3.4。全球的路由系统会通力合作,根据路由表把包一级一级地送到你的运营商,最终送到你的路由器上。路由器拿到这个包,查询自己的NAT转换表,发现这是属于 192.168.1.100 的,就把目的地址替换回去,最终将数据交付给你。
整个过程,你的私有地址对外是不可见的,互联网上其他主机看到、并实际与之通信的,始终是你的那个唯一的公网IP。
5. 一个数据包的"出国旅行"
举个例子完整串联一下:
-
假设你家的公网IP是运营商的
1.2.3.4,你在家用电脑(私网IP192.168.1.5)访问某个网站(公网IP8.8.8.8)。 -
你发出的包,源地址是
192.168.1.5,目的地址是8.8.8.8。 -
数据包到达你的路由器,NAT将其源地址改为
1.2.3.4:12345(加了个端口号)。现在,这个包变成了源地址1.2.3.4,目的地址8.8.8.8。 -
你的路由器把包送入互联网。和你家路由器直连的运营商路由器,查路由表发现去
8.8.0.0/16的下一跳应该发往另一个城市的节点,于是转发出去。 -
经过十几跳,沿途所有路由器都用这条聚合的路由条目(
8.8.0.0/16),一步步把包送到了谷歌服务器。 -
谷歌服务器收到后,回复一个包,源地址写
8.8.8.8,目的地址写你的公网IP1.2.3.4。 -
回程依然依赖于全球路由系统:沿途路由器都认识
1.2.0.0/16这个公网前缀,知道它归属于你的运营商。它们再次接力,把包送回你的路由器。 -
你的路由器收到回包,看到目的端口
12345,查NAT表,确定这是发给192.168.1.5的,于是将地址还原,最终把数据交给你。
可以看到,整个旅程中,全球路由系统只认公网IP,用公网IP来寻址、转发。而私网IP只在你的家庭内部有意义。NAT则是这两套寻址系统之间的转换界面。