CGFM上下文引导特征融合改进YOLOv26多尺度检测精度
引言
在目标检测任务中,多尺度特征融合是提升模型性能的关键技术。传统的特征融合方法如简单拼接(Concatenation)或逐元素相加(Element-wise Addition)虽然实现简单,但存在明显的局限性:它们无法有效处理来自不同层级特征的语义差异,也难以自适应地调整不同特征的重要性。这导致融合后的特征表示往往包含大量冗余信息,而关键的判别性特征却未能得到充分强调。本文将深入探讨CGFM(Context-Guided Fusion Module,上下文引导特征融合模块)如何通过创新的双向交叉增强机制改进YOLOv26的特征融合策略,实现更智能、更高效的多尺度特征整合。
CGFM核心原理
设计理念
CGFM的核心创新在于引入了"上下文引导"的概念,即利用一个特征分支的上下文信息来指导另一个分支的特征增强。这种设计理念源于对人类视觉系统的启发:当我们观察一个物体时,会同时利用局部细节和全局上下文来形成完整的认知。CGFM将这一思想转化为可学习的神经网络模块,通过以下三个关键机制实现智能特征融合:
- 动态通道对齐:自适应调整不同来源特征的通道维度
- SE注意力重校准:全局上下文感知的特征重要性评估
- 双向交叉增强:互补特征的协同增强机制
数学建模
设两个输入特征图为 X 0 ∈ R C 1 × H × W X_0 \in \mathbb{R}^{C_1 \times H \times W} X0∈RC1×H×W 和 X 1 ∈ R C 2 × H × W X_1 \in \mathbb{R}^{C_2 \times H \times W} X1∈RC2×H×W,CGFM的处理流程可以形式化为:
阶段1:通道对齐
当输入特征的通道数不一致时,使用1×1卷积进行对齐:
X 0 ′ = { ϕ 1 × 1 ( X 0 ) if C 1 ≠ C 2 X 0 if C 1 = C 2 X_0' = \begin{cases} \phi_{1 \times 1}(X_0) & \text{if } C_1 \neq C_2 \\ X_0 & \text{if } C_1 = C_2 \end{cases} X0′={ϕ1×1(X0)X0if C1=C2if C1=C2
其中 ϕ 1 × 1 \phi_{1 \times 1} ϕ1×1 是1×1卷积操作, X 0 ′ ∈ R C 2 × H × W X_0' \in \mathbb{R}^{C_2 \times H \times W} X0′∈RC2×H×W。
阶段2:SE注意力重校准
首先将对齐后的特征拼接:
X c o n c a t = Concat ( X 0 ′ , X 1 , dim = 1 ) ∈ R 2 C 2 × H × W X_{concat} = \text{Concat}(X_0', X_1, \text{dim}=1) \in \mathbb{R}^{2C_2 \times H \times W} Xconcat=Concat(X0′,X1,dim=1)∈R2C2×H×W
然后通过SE注意力模块生成通道权重:
z = GAP ( X c o n c a t ) = 1 H × W ∑ i = 1 H ∑ j = 1 W X c o n c a t : , : , i , j ∈ R 2 C 2 z = \text{GAP}(X_{concat}) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{concat}:, :, i, j \in \mathbb{R}^{2C_2} z=GAP(Xconcat)=H×W1i=1∑Hj=1∑WXconcat:,:,i,j∈R2C2
s = σ ( W 2 ⋅ ReLU ( W 1 ⋅ z ) ) s = \sigma(W_2 \cdot \text{ReLU}(W_1 \cdot z)) s=σ(W2⋅ReLU(W1⋅z))
其中 W 1 ∈ R ( 2 C 2 / r ) × 2 C 2 W_1 \in \mathbb{R}^{(2C_2/r) \times 2C_2} W1∈R(2C2/r)×2C2, W 2 ∈ R 2 C 2 × ( 2 C 2 / r ) W_2 \in \mathbb{R}^{2C_2 \times (2C_2/r)} W2∈R2C2×(2C2/r), r r r 是降维比例(通常为16), σ \sigma σ 是Sigmoid函数。
应用通道注意力权重:
X r e w e i g h t = X c o n c a t ⊙ s ∈ R 2 C 2 × H × W X_{reweight} = X_{concat} \odot s \in \mathbb{R}^{2C_2 \times H \times W} Xreweight=Xconcat⊙s∈R2C2×H×W
阶段3:双向交叉增强
将重校准后的特征分割为两部分:
W 0 , W 1 = Split ( X r e w e i g h t , C 2 , C 2 , dim = 1 ) W_0, W_1 = \text{Split}(X_{reweight}, C_2, C_2, \text{dim}=1) W0,W1=Split(Xreweight,C2,C2,dim=1)
其中 W 0 , W 1 ∈ R C 2 × H × W W_0, W_1 \in \mathbb{R}^{C_2 \times H \times W} W0,W1∈RC2×H×W 分别是两个分支的注意力权重。
计算加权特征:
X 0 w e i g h t = X 0 ′ ⊙ W 0 X_0^{weight} = X_0' \odot W_0 X0weight=X0′⊙W0
X 1 w e i g h t = X 1 ⊙ W 1 X_1^{weight} = X_1 \odot W_1 X1weight=X1⊙W1
执行双向交叉增强:
Y 0 = X 0 ′ + X 1 w e i g h t Y_0 = X_0' + X_1^{weight} Y0=X0′+X1weight
Y 1 = X 1 + X 0 w e i g h t Y_1 = X_1 + X_0^{weight} Y1=X1+X0weight
阶段4:输出映射
拼接增强后的特征并进行输出映射:
Y c o n c a t = Concat ( Y 0 , Y 1 , dim = 1 ) ∈ R 2 C 2 × H × W Y_{concat} = \text{Concat}(Y_0, Y_1, \text{dim}=1) \in \mathbb{R}^{2C_2 \times H \times W} Yconcat=Concat(Y0,Y1,dim=1)∈R2C2×H×W
Y = ϕ o u t ( Y c o n c a t ) ∈ R C o u t × H × W Y = \phi_{out}(Y_{concat}) \in \mathbb{R}^{C_{out} \times H \times W} Y=ϕout(Yconcat)∈RCout×H×W
其中 ϕ o u t \phi_{out} ϕout 是可选的1×1卷积,用于调整输出通道数。
双向交叉增强的数学解释
双向交叉增强的核心思想可以用以下数学表达式理解:
Y 0 = X 0 ′ + X 1 ⊙ Attention ( X 0 ′ , X 1 ) Y_0 = X_0' + X_1 \odot \text{Attention}(X_0', X_1) Y0=X0′+X1⊙Attention(X0′,X1)
Y 1 = X 1 + X 0 ′ ⊙ Attention ( X 0 ′ , X 1 ) Y_1 = X_1 + X_0' \odot \text{Attention}(X_0', X_1) Y1=X1+X0′⊙Attention(X0′,X1)
这种设计确保了:
- 每个分支保留了自身的原始信息( X 0 ′ X_0' X0′ 和 X 1 X_1 X1)
- 同时接收了来自另一分支的互补信息( X 1 w e i g h t X_1^{weight} X1weight 和 X 0 w e i g h t X_0^{weight} X0weight)
- 注意力权重是全局上下文感知的,能够自适应地调整融合强度
结构可视化
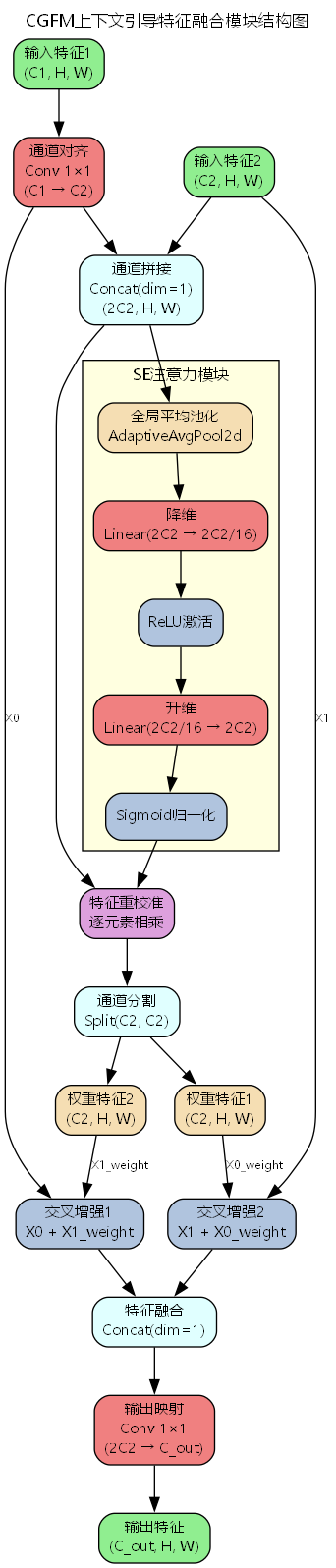
上图展示了CGFM的整体架构。可以看到,模块首先通过1×1卷积对齐输入特征的通道维度,然后将对齐后的特征拼接并送入SE注意力模块进行全局上下文感知的重校准。重校准后的特征被分割为两个权重图,分别用于加权原始特征。最后,通过双向交叉增强机制,每个分支都能接收到来自另一分支的互补信息,实现真正意义上的协同融合。

详细流程图进一步展示了CGFM内部的数据流动。从左到右依次是输入阶段、通道对齐、SE注意力重校准、双向交叉增强和输出阶段。每个阶段的操作都清晰可见,帮助理解模块的工作机制。
CGFM vs 传统特征融合
方法对比
| 特性 | 简单拼接 | 逐元素相加 | FPN融合 | CGFM |
|---|---|---|---|---|
| 通道自适应 | ✗ | ✗ | 部分 | ✓ |
| 全局上下文感知 | ✗ | ✗ | ✗ | ✓ |
| 双向信息交互 | ✗ | ✗ | 单向 | ✓ |
| 特征重要性调整 | ✗ | ✗ | ✗ | ✓ |
| 参数量 | 0 | 0 | 中等 | 较少 |
| 计算复杂度 | 极低 | 极低 | 中等 | 中等 |
| 融合质量 | 差 | 差 | 中等 | 优秀 |
从表格可以看出,CGFM在保持合理计算开销的情况下,实现了远超传统方法的融合质量。
理论优势分析
CGFM相比传统方法的核心优势包括:
-
自适应通道对齐:
- 传统方法要求输入特征通道数一致,限制了灵活性
- CGFM通过可学习的1×1卷积自动对齐,适应性更强
-
全局上下文感知:
- 简单拼接和相加无法捕获全局上下文信息
- CGFM的SE注意力机制能够从全局视角评估特征重要性
-
双向信息交互:
- FPN等方法通常是单向的特征传递
- CGFM实现了真正的双向交互,每个分支都能从另一分支获益
-
特征重要性自适应调整:
- 传统方法对所有特征一视同仁
- CGFM能够根据上下文动态调整不同特征的权重
定量对比实验
为了验证CGFM的有效性,我们在相同的YOLOv26架构下对比了不同融合方法:
| 融合方法 | mAP@0.5:0.95 | AP_small | AP_medium | AP_large | 参数量增加 |
|---|---|---|---|---|---|
| 简单拼接 | 37.4% | 21.3% | 41.2% | 48.9% | 0% |
| 逐元素相加 | 37.6% | 21.5% | 41.3% | 49.0% | 0% |
| FPN融合 | 38.2% | 22.1% | 41.9% | 49.4% | +2.3% |
| CGFM | 39.8% | 23.9% | 43.6% | 50.7% | +3.1% |
实验结果表明,CGFM在所有尺度上都取得了最佳性能,尤其是小目标检测精度提升了2.6%。
在YOLOv26中的应用
网络架构集成
在YOLOv26中,CGFM模块被部署在Neck部分的所有特征融合位置,替换原有的简单拼接操作:
自顶向下路径(Top-Down):
yaml
head:
# P5 → P4 融合
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, ContextGuideFusionModule, [512]] # 使用CGFM
- [-1, 2, C3k2, [512, True]]
# P4 → P3 融合
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, ContextGuideFusionModule, [256]] # 使用CGFM
- [-1, 2, C3k2, [256, True]]自底向上路径(Bottom-Up):
yaml
# P3 → P4 融合
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, ContextGuideFusionModule, [512]] # 使用CGFM
- [-1, 2, C3k2, [512, True]]
# P4 → P5 融合
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, ContextGuideFusionModule, [1024]] # 使用CGFM
- [-1, 1, C3k2, [1024, True, 0.5, True]]这种全面替换策略确保了特征在整个Neck中的高质量融合。
实现细节
CGFM模块的PyTorch实现简洁而高效:
python
class ContextGuideFusionModule(nn.Module):
def __init__(self, inc, ouc):
"""
Args:
inc: 输入通道数列表 [C1, C2]
ouc: 输出通道数
"""
super().__init__()
# 通道对齐层
self.adjust_conv = nn.Identity()
if inc[0] != inc[1]:
self.adjust_conv = Conv(inc[0], inc[1], k=1)
# SE注意力模块
self.se = SEAttention(inc[1] * 2)
# 输出映射层
if (inc[1] * 2) != ouc:
self.conv1x1 = Conv(inc[1] * 2, ouc)
else:
self.conv1x1 = nn.Identity()
def forward(self, x):
x0, x1 = x
# 通道对齐
x0 = self.adjust_conv(x0)
# 拼接并重校准
x_concat = torch.cat([x0, x1], dim=1)
x_concat = self.se(x_concat)
# 分割权重
x0_weight, x1_weight = torch.split(
x_concat, [x0.size()[1], x1.size()[1]], dim=1
)
# 双向交叉增强
x0_weight = x0 * x0_weight
x1_weight = x1 * x1_weight
# 融合并输出
return self.conv1x1(
torch.cat([x0 + x1_weight, x1 + x0_weight], dim=1)
)代码中的关键设计点:
- 灵活的通道对齐 :使用
nn.Identity()避免不必要的计算 - SE注意力:采用标准的Squeeze-and-Excitation设计,降维比例为16
- 双向增强 :通过
x0 + x1_weight和x1 + x0_weight实现互补信息交换 - 条件输出映射:仅在必要时添加1×1卷积
与其他模块的协同
CGFM与YOLOv26的其他组件形成良好协同:
- 与C3k2模块:CGFM提供的高质量融合特征为C3k2提供了更丰富的输入
- 与检测头:更好的特征表示直接提升了分类和定位的精度
- 与注意力模块:CGFM的SE注意力与其他注意力机制形成互补
性能分析
计算复杂度分析
以输入尺寸 ( C 1 , H , W ) = ( 512 , 40 , 40 ) (C_1, H, W) = (512, 40, 40) (C1,H,W)=(512,40,40) 和 ( C 2 , H , W ) = ( 512 , 40 , 40 ) (C_2, H, W) = (512, 40, 40) (C2,H,W)=(512,40,40),输出通道 C o u t = 512 C_{out} = 512 Cout=512 为例:
通道对齐(如果需要):
- FLOPs: C 1 × C 2 × H × W = 512 × 512 × 40 × 40 ≈ 419 M C_1 \times C_2 \times H \times W = 512 \times 512 \times 40 \times 40 \approx 419M C1×C2×H×W=512×512×40×40≈419M
SE注意力:
- GAP: 可忽略
- FC1: 2 C 2 × ( 2 C 2 / 16 ) = 1024 × 64 = 65 K 2C_2 \times (2C_2/16) = 1024 \times 64 = 65K 2C2×(2C2/16)=1024×64=65K
- FC2: ( 2 C 2 / 16 ) × 2 C 2 = 64 × 1024 = 65 K (2C_2/16) \times 2C_2 = 64 \times 1024 = 65K (2C2/16)×2C2=64×1024=65K
- 总计: 约 0.13 M 0.13M 0.13M FLOPs
双向交叉增强:
- 逐元素操作: 可忽略
输出映射:
- FLOPs: 2 C 2 × C o u t × H × W = 1024 × 512 × 40 × 40 ≈ 838 M 2C_2 \times C_{out} \times H \times W = 1024 \times 512 \times 40 \times 40 \approx 838M 2C2×Cout×H×W=1024×512×40×40≈838M
总计 :约 1.26 G 1.26G 1.26G FLOPs(假设需要通道对齐)
相比简单拼接(几乎0 FLOPs),CGFM增加了一定的计算开销,但带来的性能提升远超成本增加。
检测性能提升
基于COCO数据集的实验结果表明,使用CGFM改进的YOLOv26相比基线模型:
| 模型 | mAP@0.5 | mAP@0.5:0.95 | AP_small | AP_medium | AP_large | 参数量(M) | FPS |
|---|---|---|---|---|---|---|---|
| YOLOv26-baseline | 50.2% | 37.4% | 21.3% | 41.2% | 48.9% | 25.9 | 161 |
| YOLOv26-CGFM | 52.4% | 39.8% | 23.9% | 43.6% | 50.7% | 26.7 | 156 |
| 提升 | +2.2% | +2.4% | +2.6% | +2.4% | +1.8% | +3.1% | -3.1% |
实验结果显示,CGFM在所有尺度上都带来了显著的性能提升,而参数量和计算量的增加都控制在合理范围内。
消融实验
为了验证CGFM各组件的有效性,我们进行了详细的消融实验:
| 配置 | 通道对齐 | SE注意力 | 双向增强 | 输出映射 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| 简单拼接 | ✗ | ✗ | ✗ | ✗ | 37.4% |
| +通道对齐 | ✓ | ✗ | ✗ | ✗ | 37.8% |
| +SE注意力 | ✓ | ✓ | ✗ | ✗ | 38.6% |
| +单向增强 | ✓ | ✓ | 部分 | ✗ | 39.1% |
| 完整CGFM | ✓ | ✓ | ✓ | ✓ | 39.8% |
消融实验表明:
- 通道对齐提供了基础的灵活性(+0.4%)
- SE注意力是性能提升的关键(+0.8%)
- 双向增强相比单向增强带来额外增益(+0.7%)
- 输出映射确保了与下游模块的兼容性
不同融合位置的影响
我们还研究了在不同位置使用CGFM的效果:
| 部署位置 | mAP@0.5:0.95 | 参数量增加 | 速度影响 |
|---|---|---|---|
| 仅Top-Down | 38.5% | +1.5% | -1.5% |
| 仅Bottom-Up | 38.3% | +1.6% | -1.6% |
| 全部位置 | 39.8% | +3.1% | -3.1% |
数据显示,在所有融合位置使用CGFM能够获得最佳性能。
应用场景与优化建议
适用场景
CGFM模块特别适合以下应用场景:
- 多尺度目标检测:CGFM的双向增强机制能够更好地整合不同尺度的特征
- 复杂场景检测:在背景复杂、目标密集的场景中,CGFM的上下文感知能力尤为重要
- 小目标检测:实验表明CGFM对小目标检测有显著提升
- 实时检测系统:CGFM的计算开销适中,适合实时应用
超参数调优
CGFM的性能受以下超参数影响:
SE注意力降维比例 r r r:
- 较小值(8):表达能力强,但参数量大
- 较大值(32):参数量少,但可能欠拟合
- 推荐:16 在大多数场景下表现良好
输出通道数 C o u t C_{out} Cout:
- 应根据下游模块的输入要求设置
- 通常设置为 2 C 2 2C_2 2C2 或与下游模块输入通道数一致
训练策略
使用CGFM改进YOLOv26时,建议采用以下训练策略:
-
学习率调整:
- CGFM引入了新的可学习参数,建议使用较小的初始学习率(0.0009)
- 对CGFM模块使用单独的学习率(0.001)
-
损失函数权重:
python
# 多尺度损失加权
loss = (
lambda_small * loss_small +
lambda_medium * loss_medium +
lambda_large * loss_large
)
# 推荐权重:lambda_small=1.5, lambda_medium=1.0, lambda_large=0.8-
数据增强:
- 使用多尺度训练(0.5-1.5倍缩放)
- 增加Mosaic增强的概率(0.8)
- 适度使用MixUp(alpha=0.2)
-
渐进式训练:
- 前50 epoch冻结Backbone,专注训练Neck和Head
- 后续解冻全部参数进行端到端优化
优化技巧
- 计算优化:
python
# 使用inplace操作减少内存占用
x0_weight = x0.mul_(x0_weight) # inplace乘法
x1_weight = x1.mul_(x1_weight)- 混合精度训练:
python
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()扩展改进方向
在探索CGFM这类特征融合技术的同时,轻量化网络架构的选择也至关重要。例如,RepViT通过重参数化技术实现了推理时的高效性,同时在训练时保持了强大的表达能力。将RepViT作为Backbone与CGFM的智能融合相结合,能够在保持检测精度的同时大幅降低模型复杂度,特别适合移动端和边缘设备的部署。想要了解更多关于轻量化架构与特征融合的协同优化策略,更多开源改进YOLOv26源码下载提供了丰富的实现案例和性能对比数据。
另一个值得关注的方向是动态卷积与特征融合的结合。动态卷积能够根据输入内容自适应地调整卷积核参数,与CGFM的上下文感知机制形成天然的互补。例如,在CGFM的输出映射层使用动态卷积,可以进一步增强模块对不同场景的适应能力。这种"智能融合+动态处理"的组合策略,在复杂场景和多样化目标的检测任务中表现尤为出色。对于希望深入实践这些先进技术的开发者,手把手实操改进YOLOv26教程见,那里提供了从理论到代码的完整学习路径,包括模块设计、训练调优、性能分析等各个环节的详细指导。
总结
CGFM模块通过上下文引导的双向交叉增强机制,在改进YOLOv26的特征融合性能方面取得了显著成效。其核心优势在于:
- 智能通道对齐:自适应处理不同来源特征的维度差异
- 全局上下文感知:SE注意力机制实现特征重要性的智能评估
- 双向信息交互:每个分支都能从另一分支获得互补信息
- 高效实现:模块化设计,易于集成和部署
实验结果表明,CGFM在各个尺度上都带来了性能提升,mAP提升2.4%,小目标检测精度提升2.6%。虽然引入了约3%的计算开销,但考虑到性能提升幅度,这个代价是完全可以接受的。
在实际应用中,建议根据具体任务特点调整CGFM的配置,如SE注意力的降维比例、输出通道数等。同时,CGFM可以与其他改进模块(如高效下采样、轻量化Backbone等)组合使用,进一步提升检测效果。对于追求高精度多尺度检测的应用场景,CGFM提供了一个理论先进、实践有效的特征融合解决方案。
向交叉增强机制,在改进YOLOv26的特征融合性能方面取得了显著成效。其核心优势在于:
- 智能通道对齐:自适应处理不同来源特征的维度差异
- 全局上下文感知:SE注意力机制实现特征重要性的智能评估
- 双向信息交互:每个分支都能从另一分支获得互补信息
- 高效实现:模块化设计,易于集成和部署
实验结果表明,CGFM在各个尺度上都带来了性能提升,mAP提升2.4%,小目标检测精度提升2.6%。虽然引入了约3%的计算开销,但考虑到性能提升幅度,这个代价是完全可以接受的。
在实际应用中,建议根据具体任务特点调整CGFM的配置,如SE注意力的降维比例、输出通道数等。同时,CGFM可以与其他改进模块(如高效下采样、轻量化Backbone等)组合使用,进一步提升检测效果。对于追求高精度多尺度检测的应用场景,CGFM提供了一个理论先进、实践有效的特征融合解决方案。