文档源
概述
操作系统使用处理器分页来隔离其进程的地址空间并高效利用物理内存。分页是将进程特定的线性地址转换为系统物理地址的过程。当处理器处于分页模式时(现代操作系统即如此),分页涉及每次数据和指令访问。x86 处理器利用各种硬件设施来降低与分页相关的开销。然而,在虚拟化环境下,客户机对物理内存的视图与系统对物理内存的视图不同,因此需要第二级地址转换来将客户机物理地址转换为机器地址。为了启用这一额外的转换级别,虚拟机监控器(hypervisor)必须虚拟化处理器分页。当前基于软件的分页虚拟化技术(如影子分页)会产生显著的开销,导致虚拟化性能下降、CPU 利用率增加和内存消耗增加。
延续在虚拟化架构和性能方面的领导地位,AMD64 四核处理器是首批引入硬件支持第二级(即嵌套级)地址转换的 x86 处理器。该功能是 AMD 虚拟化技术(AMD-V™)的组成部分,被称为快速虚拟化索引(Rapid Virtualization Indexing, RVI)或嵌套分页(Nested Paging)。在嵌套分页下,处理器利用由虚拟机监控器设置的嵌套页表来执行第二级地址转换。嵌套分页减少了等效影子分页实现中的开销。
本白皮书讨论了现有的基于软件的分页虚拟化解决方案及其相关的性能开销,然后介绍了 AMD-V™ 快速虚拟化索引技术(在本出版物中称为嵌套分页),重点介绍了其优势,并展示了嵌套分页可能带来的性能提升。
目录
- 引言
- 系统虚拟化基础
- [x86 地址转换基础](#x86 地址转换基础)
- [虚拟化 x86 分页](#虚拟化 x86 分页)
- 4.1 虚拟化地址转换的软件技术
- 4.2 [AMD-V™ 嵌套页表 (NPT)](#AMD-V™ 嵌套页表 (NPT))
- 4.2.1 详细说明
- 4.2.2 嵌套分页下页遍历的开销
- 4.2.3 使用嵌套分页
- 4.2.4 [NPT 的内存节省](#NPT 的内存节省)
- 4.2.5 页大小对嵌套分页性能的影响
- 4.2.6 提升嵌套分页性能的微架构支持
- 4.2.7 [地址空间 ID](#地址空间 ID)
- 4.2.8 嵌套分页基准测试
- 结论
1. 引言
系统虚拟化是对平台上资源的抽象和池化。这种抽象将软件和硬件解耦,使多个操作系统映像能够在单个物理平台上并发运行而不相互干扰。虚拟化可以通过将运行在多台物理机器上的工作负载整合到运行在单台物理机器上的虚拟机中,来提高计算资源的利用率。这种整合可以显著降低数据中心的功耗和空间需求。虚拟机可以通过集中管理接口按需配置、复制和迁移。
从 64 位 AMD Opteron™ Rev-F 处理器开始,AMD 提供了处理器扩展,以促进更高效、安全和健壮的系统虚拟化软件的开发。这些扩展统称为 AMD Virtualization™ 或 AMD-V™ 技术,消除了与纯软件虚拟化解决方案相关的开销,并试图缩小虚拟化系统与非虚拟化系统之间的性能差距。
2. 系统虚拟化基础
为了允许多个操作系统在同一物理平台上运行,一个以软件实现的平台层将操作系统与底层硬件解耦。这一层称为虚拟机监控器(hypervisor)。在系统虚拟化的语境中,被虚拟化的操作系统称为客户机(guest)。
为了正确地虚拟化和隔离客户机,虚拟机监控器必须控制或中介客户机执行的所有特权操作。虚拟机监控器可以使用多种技术来实现这一点。第一种技术称为半虚拟化(para-virtualization),其中客户机源代码被修改以在执行特权操作时与虚拟机监控器协作。第二种技术称为二进制翻译(binary translation),在运行时虚拟机监控器透明地替换客户机中的特权操作,使用允许虚拟机监控器控制和模拟这些操作的操作来替代。第三种方法是硬件辅助虚拟化,虚拟机监控器使用处理器扩展(如 AMD-V)来拦截和模拟客户机中的特权操作。在某些情况下,AMD-V 技术允许虚拟机监控器指定处理器应如何在客户机自身中处理特权操作,而无需将控制权转移给虚拟机监控器。
使用二进制翻译或硬件辅助虚拟化的虚拟机监控器必须向客户机提供客户机运行在物理硬件上的错觉。例如,当客户机使用处理器的分页支持进行地址转换时,虚拟机监控器必须确保客户机观察到与非虚拟化硬件上等效的行为。
3. x86 地址转换基础
虚拟地址是程序用来访问数据和指令的地址。虚拟地址由段和偏移字段组成。段信息用于确定保护信息和段的起始地址。段转换无法禁用,但操作系统通常使用平坦分段(flat segmentation),其中所有段都映射到整个物理地址空间。在平坦分段下,虚拟地址实际上就是线性地址。在本白皮书中,我们将线性地址和虚拟地址互换使用。
如果启用了分页,线性地址使用处理器分页硬件转换为物理地址。为了使用分页,操作系统创建并管理一组页表(见图 1)。页表遍历器(page table walker)或简称页遍历器,由处理器硬件实现,使用这些页表和线性地址中的各种位字段执行地址转换。图 2 显示了页遍历器用于地址转换的高层算法。
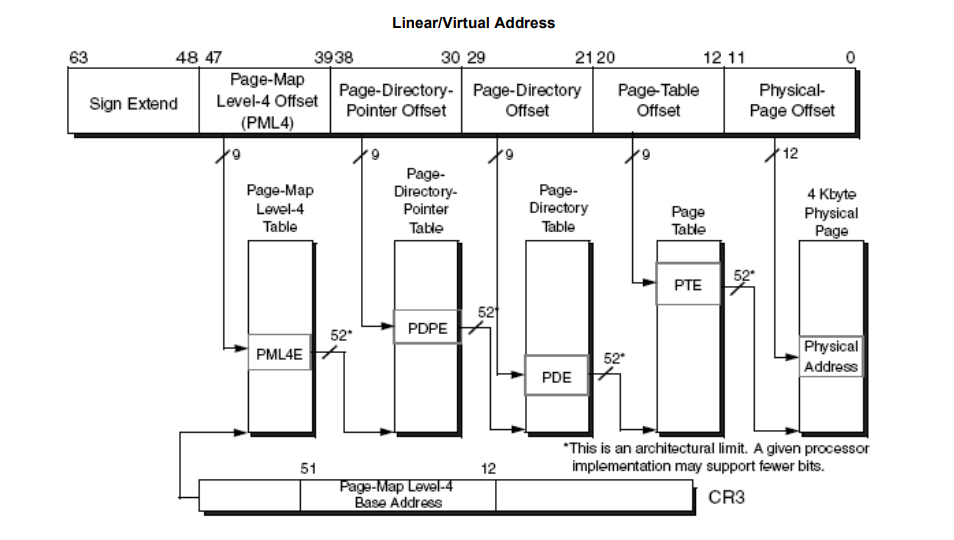
图 1:长模式下的 4KB 页表
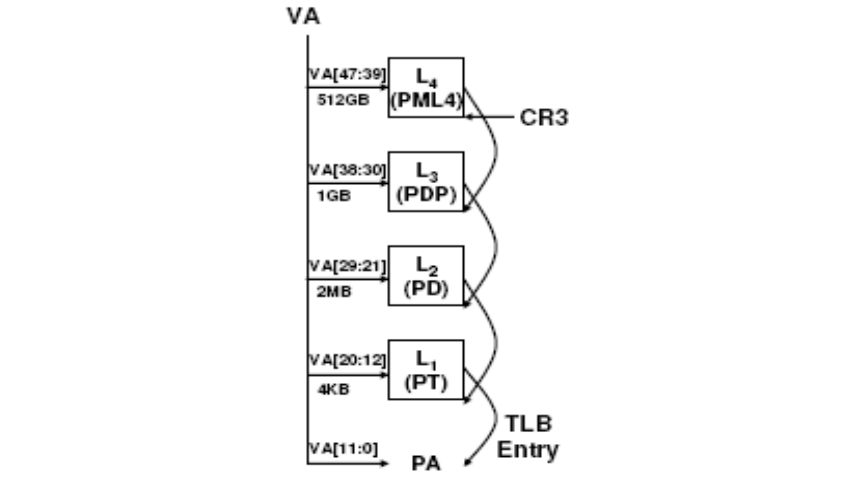
图 2:线性/虚拟地址到物理地址转换算法
在页遍历期间,页遍历器遇到 CR3 寄存器和页表项中的物理地址,这些地址指向下一级遍历。当到达数据页或叶子页时,页遍历结束。
地址转换是一个非常内存密集型的操作,因为页遍历器必须多次访问内存层次结构。为了降低这种开销,AMD 处理器自动将最近的转换存储在内部转换后备缓冲器(TLB)中。在每次内存引用时,处理器首先检查 TLB 以确定所需的转换是否已被缓存;如果已缓存,处理器使用该转换;否则遍历页表,将结果转换保存到 TLB 中并执行指令。
操作系统需要与处理器协作,以保持 TLB 与内存中的页表一致。例如,当移除地址转换时,操作系统必须请求处理器使与该转换关联的 TLB 项无效。在 SMP 系统中,操作系统可能在运行于多个处理器上的进程之间共享页表,操作系统必须确保所有处理器上的 TLB 项保持一致。当移除共享转换时,操作系统软件应使所有处理器上相应的 TLB 项无效。
操作系统在上下文切换期间更新页表基指针(CR3)。CR3 的更改建立了一组新的转换,因此处理器自动使与先前上下文关联的 TLB 项无效。
处理器在内存访问期间设置页表中的访问位和脏位。当处理器使用该转换读取或写入内存时,在页表的所有级别设置"访问"位。当处理器写入由该 PTE 映射的内存页时,在 PTE 中设置"脏"位。
4. 虚拟化 x86 分页
为了在客户机和虚拟机监控器之间提供保护和隔离,虚拟机监控器必须通过在客户机活动时实质上强制执行另一级地址转换来控制处理器上的地址转换。这额外的转换级别将客户机对物理内存的视图映射到系统对物理内存的视图。
对于半虚拟化客户机,虚拟机监控器和客户机可以利用半虚拟化接口来降低虚拟化 x86 分页时虚拟机监控器的复杂性和开销。然而对于未修改的客户机,虚拟机监控器必须完全虚拟化 x86 地址转换。这可能产生显著的开销,我们将在以下章节中讨论。
4.1 虚拟化地址转换的软件技术
基于软件的技术维护一个从客户机页表(gPT)派生的页表影子版本。当客户机活动时,虚拟机监控器强制处理器使用影子页表(sPT)执行地址转换。sPT 对客户机不可见。
为了维护有效的 sPT,虚拟机监控器必须跟踪 gPT 的状态。这包括客户机对 gPT 添加或移除转换的修改、客户机与虚拟机监控器引起的缺页异常(定义如下)、sPT 中的访问位和脏位;以及对于 SMP 客户机,处理器上地址转换的一致性。
软件可以使用多种技术来保持 sPT 和 gPT 一致。其中一种技术是写保护 gPT。在这种技术中,虚拟机监控器对构成 gPT 的所有物理页进行写保护。客户机添加转换的任何修改都会导致缺页异常。在缺页异常时,处理器控制权转移给虚拟机监控器,以便它可以适当地模拟该操作。类似地,当客户机编辑 gPT 以移除转换时,虚拟机监控器获得控制权;虚拟机监控器从 gPT 中移除转换并相应地更新 sPT。
另一种影子分页技术不对 gPT 进行写保护,而是依赖处理器的缺页行为和客户机遵循 TLB 一致性规则。在这种技术中(有时称为虚拟 TLB),虚拟机监控器允许客户机在不拦截这些操作的情况下向 gPT 添加新转换。然后当客户机访问导致处理器使用该转换引用内存的指令或数据时,处理器发生缺页,因为该转换尚不存在于 sPT 中。缺页允许虚拟机监控器介入;它检查 gPT 以在 sPT 中添加缺失的转换并执行导致缺页的指令。类似地,当客户机移除转换时,它执行 INVLPG 以使 TLB 中的该转换无效。虚拟机监控器拦截此操作;然后移除 sPT 中相应的转换并对移除的转换执行 INVLPG。
两种技术都导致大量的缺页异常。许多缺页是由正常的客户机行为引起的;例如访问被客户机操作系统换出到存储层次结构的页面。我们称此类缺页为客户机引起的缺页(guest-induced page faults),虚拟机监控器必须拦截、分析这些缺页,然后反射到客户机中,与原生分页相比这是显著的开销。由于影子分页引起的缺页称为虚拟机监控器引起的缺页(hypervisor-induced page faults)。为了区分这两种缺页,虚拟机监控器遍历客户机和影子页表,这会产生显著的软件开销。
当客户机活动时,页遍历器在 sPT 中设置访问位和脏位。但由于客户机可能依赖于 gPT 中这些位的正确设置,虚拟机监控器必须将它们反射回 gPT。例如,客户机可能使用这些位来确定哪些页面可以移动到硬盘以腾出空间给新页面。
当客户机尝试在处理器上调度新进程时,它更新处理器的 CR3 寄存器以建立与新进程对应的 gPT。虚拟机监控器必须拦截此操作,使与先前 CR3 值关联的 TLB 项无效,并根据新进程对应的 sPT 设置实际的 CR3 值。客户机内频繁的上下文切换可能导致显著的虚拟机监控器开销。
影子分页对于 SMP 客户机可能产生显著的额外内存和性能开销。在 SMP 客户机中,同一个 gPT 实例可用于多个处理器上的地址转换。在这种情况下,虚拟机监控器必须维护可在每个处理器上使用的 sPT 实例,或在多个虚拟处理器之间共享 sPT。前者导致高内存开销;后者可能导致高同步开销。
据估计,对于某些工作负载,影子分页可占虚拟机监控器总开销的 75%。
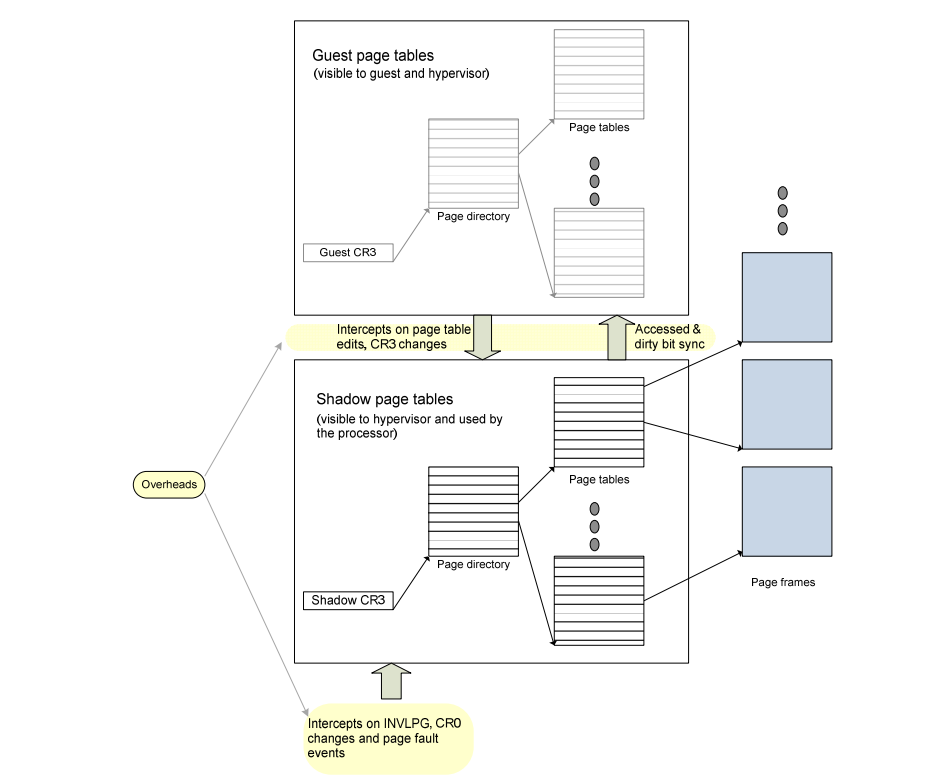
图 3:客户机和影子页表(显示两级分页)
4.2 AMD-V™ 嵌套页表 (NPT)
为了避免影子分页下的软件开销,AMD64 四核处理器将嵌套分页添加到硬件页遍历器中。嵌套分页使用额外的或嵌套的页表(NPT)来将客户机物理地址转换为系统物理地址,并让客户机完全控制其页表。与影子分页不同,一旦嵌套页表被填充,虚拟机监控器不需要拦截和模拟客户机对 gPT 的修改。嵌套分页消除了与影子分页相关的开销。然而,由于嵌套分页引入了额外的转换级别,TLB 缺失的开销可能更大。
4.2.1 详细说明
在嵌套分页下,客户机和虚拟机监控器各自拥有影响分页的处理器状态副本,如 CR0、CR3、CR4、EFER 和 PAT。
gPT 将客户机线性地址映射到客户机物理地址。嵌套页表(nPT)将客户机物理地址映射到系统物理地址。
客户机页表和嵌套页表分别由客户机和虚拟机监控器设置。当客户机尝试使用线性地址引用内存且启用了嵌套分页时,页遍历器使用 gPT 和 nPT 执行二维遍历,将客户机线性地址转换为系统物理地址。参见图 4。
当页遍历完成时,包含从客户机线性地址到系统物理地址转换的 TLB 项被缓存在 TLB 中,并在后续对该线性地址的访问中使用。
支持嵌套分页的 AMD 处理器使用相同的 TLB 设施来映射线性地址到系统物理地址,无论处理器处于客户机模式还是主机(或虚拟机监控器)模式。当处理器处于客户机模式时,TLB 将客户机线性地址映射到系统物理地址。当处理器处于主机模式时,TLB 将主机线性地址映射到系统物理地址。
此外,支持嵌套分页的 AMD 处理器维护一个嵌套 TLB,缓存客户机物理地址到系统物理地址的转换,以加速嵌套页表遍历。嵌套 TLB 利用客户机页表结构的高局部性,具有高命中率。
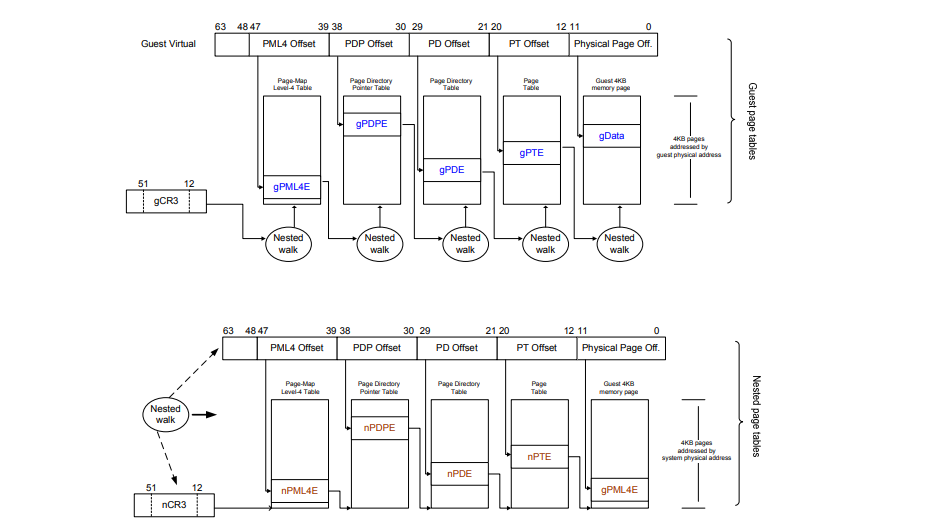
图 4:使用嵌套页表将客户机线性地址转换为系统物理地址
4.2.2 嵌套分页下页遍历的开销
嵌套分页下的 TLB 缺失可能比非嵌套分页下的 TLB 缺失开销更高。这是因为在嵌套分页下,页遍历器不仅必须遍历 gPT,还要同时遍历 nPT,以将客户机页表遍历期间遇到的客户机物理地址(如 gCR3 和 gPT 项)转换为系统物理地址。
例如,4 级客户机页表遍历可能调用嵌套页遍历器 5 次------每次为遇到的客户机物理地址调用一次,加上数据本身客户机物理地址的最终转换一次。每次嵌套页遍历最多需要 4 次可缓存内存访问来确定客户机物理地址到系统物理地址的映射,外加一次内存访问读取项本身。在这种情况下,TLB 缺失开销可能从非嵌套分页的 4 次内存引用增加到嵌套分页的 24 次(除非进行缓存)。图 5 显示了客户机和嵌套页表都有 4 级时页遍历器采取的步骤。
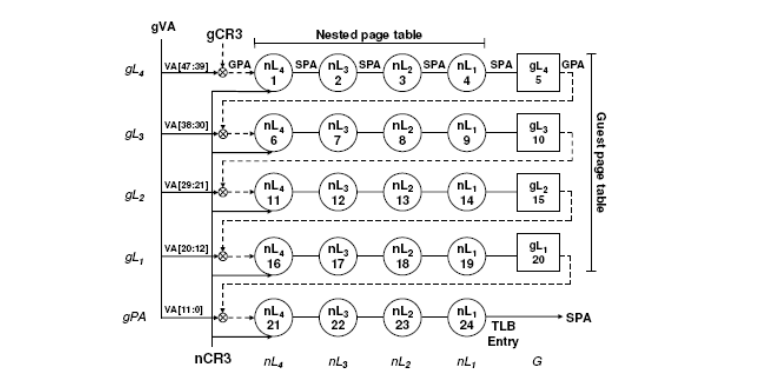
图 5:嵌套分页的地址转换。GPA 为客户机物理地址;SPA 为系统物理地址;nL 为嵌套级别;gL 为客户机级别
4.2.3 使用嵌套分页
嵌套分页是供虚拟机监控器使用的功能。客户机在使用嵌套分页的虚拟机监控器下运行时,不会观察到任何差异(性能除外)。嵌套分页不需要对客户机软件进行任何更改。
嵌套分页是一个可选功能,并非所有支持 AMD-V 技术的处理器实现都提供。软件可以使用 CPUID 指令来确定该处理器实现是否支持嵌套分页。
4.2.4 NPT 的内存节省
与影子分页不同(要求虚拟机监控器为每个 gPT 维护一个 sPT 实例),使用嵌套分页的虚拟机监控器可以设置单个 nPT 实例来映射整个客户机物理地址空间。由于客户机内存是紧凑的,nPT 通常应比等效的影子分页实现消耗少得多的内存。
使用嵌套分页,虚拟机监控器可以维护单个 nPT 实例,该实例可以在 SMP 客户机中的一个或多个处理器上同时使用。这比影子分页实现更高效,在影子分页中虚拟机监控器要么产生内存开销来维护每个虚拟处理器的 sPT,要么因使用共享 sPT 而产生同步开销。
4.2.5 页大小对嵌套分页性能的影响
除其他因素外,当 TLB 缺失开销增加时,地址转换性能会下降。在其他条件相同的情况下,TLB 缺失开销(在嵌套和非嵌套分页下)如果需要遍历的页数更少,则会降低。大页大小减少了地址转换所需的页级别数。
为了提高嵌套分页性能,虚拟机监控器可以选择用大页大小填充 nPT。嵌套页表大小对于每个客户机中的每页可以不同,并可以在客户机执行期间更改。AMD64 四核处理器支持 4KB、2MB 和 1GB 页大小。
与大的嵌套页大小类似,大的客户机页大小也减少了 TLB 缺失开销。许多工作负载(如数据库工作负载)通常使用大页,在嵌套分页下应该表现良好。
大页的一个间接好处是 TLB 效率。使用更大的页面,每个 TLB 项覆盖更大的线性到物理地址转换范围;有效增加了 TLB 容量并减少了页遍历频率。
4.2.6 提升嵌套分页性能的微架构支持
为了减少页遍历开销,AMD64 处理器为频繁使用的页表项引用的内存维护了一个快速内部页遍历缓存(Page Walk Cache, PWC)。PWC 项使用物理地址标记,防止页表项引用访问内存层次结构。
在嵌套分页下,PWC 的重要性更加突出。支持嵌套分页的 AMD 处理器可以缓存客户机页表和嵌套页表项。这将客户机和嵌套页表项引用的数据的无条件内存层次结构访问转换为可能的 PWC 命中。最顶层页级别的页表项重用率最高,而最低级别的重用率最低。PWC 在缓存项时会考虑这些特征。
如前所述,TLB 在减少地址转换开销方面起着重要作用。当 TLB 容量增加时,所需的昂贵页遍历次数减少。AMD "Barcelona" 系列处理器设计为在其 L1 数据 TLB 中可缓存多达 48 个 TLB 项(适用于任何页大小:4KB、2MB 或 1GB 页面);还可以在其 L2 TLB 中缓存 512 个 4KB TLB 项或 128 个 2MB 项。大容量 TLB 在嵌套分页和影子分页下都能提高性能。
与缓存线性地址到系统地址转换的常规 TLB 类似,支持嵌套分页的 AMD 处理器支持嵌套 TLB(NTLB)来缓存客户机物理地址到系统物理地址的转换。NTLB 的目标是减少嵌套遍历期间页表项引用的平均数量。
TLB、PWC 和 NTLB 协同工作,提高嵌套分页性能,而无需对客户机或虚拟机监控器进行任何软件更改。
4.2.7 地址空间 ID
从 64 位 AMD Opteron Rev-F 处理器开始,支持地址空间 ID(ASID)来动态划分 TLB。虚拟机监控器为每个调度在处理器上运行的客户机分配唯一的 ASID 值。在 TLB 查找期间,当前活动客户机的 ASID 值与 TLB 项中的 ASID 标记进行匹配,线性页帧号进行匹配以确定潜在的 TLB 命中。因此,属于不同客户机和虚拟机监控器的 TLB 项可以共存而不会导致错误的地址转换,并且这些 TLB 项可以在上下文切换期间持续存在。没有 ASID,所有 TLB 项必须在上下文切换前刷新并稍后重新填充。
ASID 的使用允许虚拟机监控器高效利用处理器的 TLB 容量,以提高嵌套分页下的客户机性能。
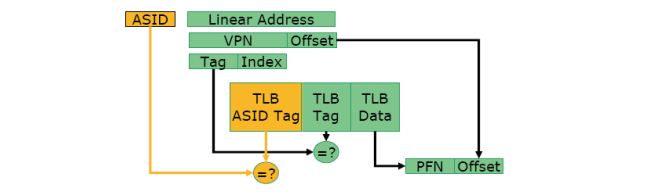
图 6:地址空间 ID (ASID)
4.2.8 嵌套分页基准测试
本白皮书包含从 AMD "Barcelona" 系列处理器早期版本和早期虚拟机监控器实现收集的基准测试结果。随着虚拟机监控器针对嵌套分页的优化,整体性能可能会提高。此外,微架构的增强也可能提升性能。当 AMD64 四核处理器后续版本和后续虚拟机监控器版本的基准测试结果可用时,将添加或链接到本文档。
此处讨论的基准测试是在以下配置的系统上收集的:
- 处理器:2 插槽,2.0GHz/1800MHz-NB Barcelona(型号 2350),95W。
- 内存:32GB 4GB DDR2-667MHz。
- HBA:QLA2432(双端口 PCIe 2Gb 光纤)HBA:使用 1 个端口。
- 磁盘阵列:MSA1500,1 个控制器,1 个光纤连接,512MB 缓存。15 块 15K rpm SCSI 73GB 磁盘。
图 7 显示了使用 VMware ESX 实验版本在有无嵌套分页情况下收集的基准测试数据。使用嵌套分页,SQL DB Hammer 和 MS Terminal Services 工作负载的性能分别提高了约 14% 和 58%。
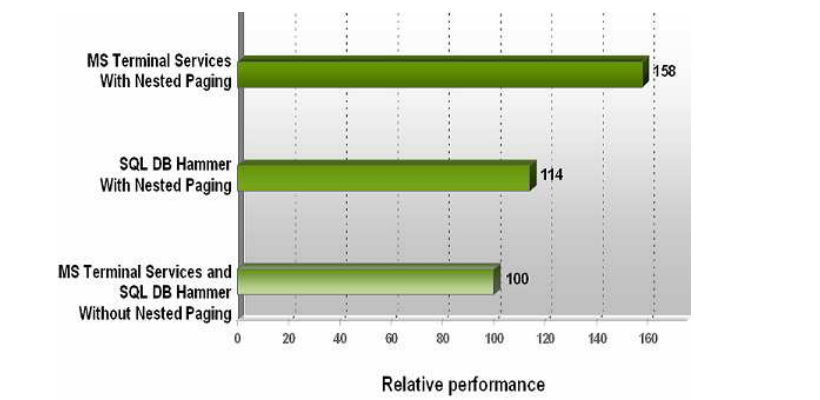
图 7:在 AMD64 四核型号 2350 上使用 VMware ESX 虚拟机监控器实验版本有无嵌套分页的性能对比
图 8 显示了在 RHEL 4.4 上运行于 Xen 3.1 下的 Oracle 10G OLTP 有无嵌套分页的情况。使用嵌套分页,性能提高了约 94%。使用半虚拟化(PV)NIC 和存储驱动程序,性能提高了 249%。
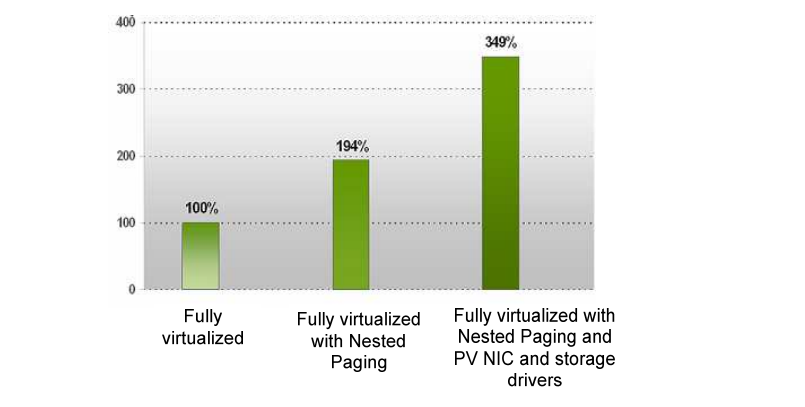
图 8:在 AMD64 四核型号 2350 上 RHEL 5.5 下 Xen 中有无嵌套分页的 Oracle 10G OLTP 性能对比
5. 结论
嵌套分页消除了与传统基于软件的影子分页算法相关的虚拟化开销。结合 AMD64 四核处理器中的其他架构和微架构增强,嵌套分页有助于提供性能改进,特别是对于具有高上下文切换频率的内存密集型工作负载。基于这些处理器的服务器可以提供出色的可扩展性、领先的每瓦性能、高整合率和服务器工作负载的充足余量。