
vLLM安装
一、集群环境
| 机器 | IP | 作用 | 显卡 |
|---|---|---|---|
| master | 10.132.47.60 | Head 节点 | Tesla T4 16G |
| node1 | 10.132.47.61 | Worker 节点 | Tesla T4 16G |
| node2 | 10.132.47.62 | Worker 节点 | Tesla T4 16G |
| windows 10 | 10.132.47.50 | open claw | Tesla T4 16G |
1.配置hosts
bash
#master节点执行
hostnamectl set-hostname master
#Node1 节点执行
hostnamectl set-hostname node1
#Node2 节点执行
hostnamectl set-hostname node2
cat >> /etc/hosts << EOF
10.132.47.60 master
10.132.47.61 node1
10.132.47.62 node2
EOF2.配置免密登录
在master(10.132.47.60)执行
bash
ssh-keygen -t rsa
#一路回车
# 把公钥传到服务器
ssh-copy-id root@master
ssh-copy-id root@node1
ssh-copy-id root@node2
#验证
for ip in master node1 node2; do ssh $ip "echo ✅ 主机 $ip 免密登录成功"; done二、驱动安装
1. 安装NVIDIA驱动
bash
# Ubuntu系统安装驱动
# 添加NVIDIA官方仓库
sudo apt update
sudo apt install -y software-properties-common
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt install -y alsa-utils
sudo apt update
sudo apt install ubuntu-drivers-common
# 查看推荐的驱动版本
ubuntu-drivers devices
# 安装推荐的驱动
sudo apt install -y nvidia-driver-580
# 重启系统使驱动生效
sudo reboot
# 重启后验证驱动安装
nvidia-smi
# 预期输出:显示GPU信息、驱动版本、CUDA版本
Thu Jan 22 14:19:34 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:0A.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+1. 安装 CUDA
bash
# 卸载旧的CUDA工具包
sudo apt-get purge nvidia-cuda-toolkit
sudo apt-get autoremove
sudo apt-get clean添加 NVIDIA 官方源
bash
# 添加GPG密钥
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
# 更新源列表
sudo apt-get update安装 CUDA Toolkit
bash
# 安装CUDA 13.0(和你的驱动版本匹配)
sudo apt-get install -y cuda-13-0配置环境变量
bash
# 编辑~/.bashrc文件
vim ~/.bashrc
# 在文件末尾添加以下内容
export PATH=/usr/local/cuda-13.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH
# 保存并退出后,生效配置
source ~/.bashrc验证安装
bash
# 检查CUDA版本
nvcc -V
# 预期输出应该包含:
# nvcc: NVIDIA (R) Cuda compiler driver
# Copyright (c) 2005-2024 NVIDIA Corporation
# Built on ...
# Cuda compilation tools, release 13.0, V13.0.xxx3. 安装 NVIDIA Container Toolkit
安装 NVIDIA Container Toolkit,参考Installing the NVIDIA Container Toolkit(
bash
#中科大源安装
#拉取中科大 GPG 密钥并写入
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
#配置适配 Ubuntu 22.04 的 nvidia 源列表
# 生成源列表并添加签名验证(适配 jammy 版本)
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 关键:替换源中的系统版本为 jammy(Ubuntu 22.04),避免源适配错误
sudo sed -i 's/focal/jammy/g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 把源列表里的 nvidia.github.io 替换为 mirrors.ustc.edu.cn
sudo sed -i 's#nvidia.github.io/libnvidia-container#mirrors.ustc.edu.cn/libnvidia-container#g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
#更新 apt 缓存
sudo apt update -y
#安装 nvidia-container-toolkit
sudo apt install -y nvidia-container-toolkit4. 安装docker
bash
# 1. 安装依赖
sudo apt install -y apt-transport-https ca-certificates curl gnupg lsb-release
# 2. 配置阿里云yum源
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 3. 修改 Docker 软件源为阿里云
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] http://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 4. 更新
sudo apt update
# 5. 安装 Docker 最新版本
sudo apt install -y docker-ce docker-ce-cli containerd.io
#验证 Docker 是否安装成功
docker --version
# 3. 配置Docker镜像加速和cgroup驱动、GPU使用
mkdir -p /etc/docker && cat > /etc/docker/daemon.json << 'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://mirror.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://docker.m.daocloud.io"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"storage-driver": "overlay2"
}
EOF
# 4. 启动Docker
systemctl daemon-reload && systemctl start docker && systemctl enable docker
# 5. 配置Docker运行时(如果使用Docker)
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# 安装指定版本 如20.10.24
sudo apt install -y docker-ce=5:20.10.24~3-0~ubuntu-jammy docker-ce-cli=5:20.10.24~3-0~ubuntu-jammy containerd.io5. 验证docker可以使用GPU
bash
#拉取镜像
docker pull nvidia/cuda:11.8.0-base-ubuntu22.04
#运行
docker run --rm --gpus all nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04
#运行
docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
#一键验证
for host in master node1 node2; do echo -e "\n==================== $host Docker GPU 测试 ===================="; ssh $host "docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi"; done
# 预期输出:容器内能看到GPU信息
root@k8s-master:~# docker run --rm --gpus all swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:11.8.0-base-ubuntu22.04 nvidia-smi
Thu Jan 22 06:33:02 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:0A.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+三、 配置虚拟环境和模型文件
bash
# 安装基础依赖
sudo apt install -y build-essential gcc g++ cmake git wget curl python3 python3-pip python3-venv
# 配置pip国内镜像(加速安装)
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip3 config set global.trusted-host pypi.tuna.tsinghua.edu.cn1. 创建 Python 虚拟环境
bash
# 创建虚拟环境
python3 -m venv vllm-env
# 激活环境,(注意:后续所有操作都需在此环境中执行)
source vllm-env/bin/activate
# 升级pip
pip install --upgrade pip
#注意:机器重启后需要重新激活虚拟环境
source vllm-env/bin/activate2. 下载模型
bash
# 安装modelscope
pip install modelscope
# 创建 /models/ 目录(-p 表示自动递归创建,不存在就新建)
sudo mkdir -p /models/
# 将文件夹权限赋予当前用户
sudo chown -R $USER:$USER /models
# 只在10.132.47.60下载模型到文件夹内
modelscope download --model Qwen/Qwen3.5-4B --local_dir /models/Qwen3.5-4B3. 创建NFS服务共享模型
安装 NFS 服务
bash
sudo apt update
sudo apt install -y nfs-kernel-server配置 NFS 共享目录,编辑 /etc/exports 文件,添加共享规则:
bash
sudo vim /etc/exports
#在文件末尾添加以下内容(根据需求调整):
/models *(rw,sync,no_root_squash,no_subtree_check)使配置生效
bash
sudo exportfs -arv动 NFS 服务并设置开机自启
bash
sudo systemctl start nfs-kernel-server
sudo systemctl enable nfs-kernel-server客户端挂载
bash
sudo apt install -y nfs-common创建本地挂载目录
bash
sudo mkdir -p /models临时挂载 NFS 到 /models
bash
sudo mount -t nfs 10.132.47.60:/models /models永久挂载,编辑 /etc/fstab 文件:
bash
sudo vim /etc/fstab
#添加以下内容(或修改之前的挂载配置):
10.132.47.60:/models /models nfs defaults 0 0执行挂载验证
bash
sudo mount -a
#验证挂载
df -h | grep /models
#进入 /models 目录,应该能看到和服务端一样的内容(如 Qwen3.5-4B 文件夹)。四、安装核心依赖
在虚拟环境中安装 vLLM 和 Ray:
bash
# 安装 vLLM (会自动安装匹配的 PyTorch 和 CUDA 依赖)
pip install vllm
# 安装 Ray (包含 Dashboard 和必要的集群组件)
pip install "ray[default]"验证安装
bash
# 检查 vLLM 版本
python3 -c "import vllm; print(f'vLLM version: {vllm.__version__}')"
# 检查 Ray 版本
ray --version五、启动Ray 集群
在 Head 节点(10.132.32.60)启动 Ray Head
bash
# 确保在虚拟环境中
source ~/vllm-env/bin/activate
# 启动 Ray Head
# --dashboard-host=0.0.0.0 允许外部访问 Dashboard (端口 8265)
ray start --head --port=6379 --dashboard-host=0.0.0.0在 Worker 节点启动并加入集群
Next steps
To add another node to this Ray cluster, run
ray start --address='10.132.47.60:6379'
#请记录下这个地址。
# 确保在虚拟环境中
# 加入集群 (请替换为 Head 节点的实际 IP)
ray start --address='10.132.47.60:6379'
# 输出提示:Local node IP: xxx.xxx.xxx.xxx 表示成功加入。验证集群状态
# 在 Head 节点 运行:
ray status
#显示集群的信息
(vllm-env) root@ubuntu:~# ray status
======== Autoscaler status: 2026-04-13 05:59:47.050278 ========
Node status
---------------------------------------------------------------
Active:
1 node_e9634775437fe647a43ba0f13a5afeaeb5e0369c906c11832c7f5bd9
1 node_88efd0d4ed2a70bada2f267b2695f67c43c909767a866cbdca7d1c9f
1 node_3812bbc61a51d34f71968dcc8f4722bbaf1649eb48fd8a29d10a8af3
Pending:
(no pending nodes)
Recent failures:
(no failures)
Resources
---------------------------------------------------------------
Total Usage:
0.0/96.0 CPU
0.0/3.0 GPU
0B/259.87GiB memory
0B/111.37GiB object_store_memory
From request_resources:
(none)
Pending Demands:
(no resource demands)六、测试启动vLLM服务
在 Head 节点 的终端执行(如果是以太网而非 InfiniBand,建议设置):
bash
# 强制使用以太网 (如果没有 IB 设备)
export NCCL_IB_DISABLE=1
# 设置 NCCL 日志级别 (方便排错,测试完可设为 INFO)
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ens3 # 如果网卡名不是 ens3 请用 ip a 查看并替换启动 vLLM API 服务 (前台测试)
在 Head 节点 的虚拟环境中执行:
注意:
- 这里以
Qwen/Qwen-4B为例(Qwen 3.5 发布后请替换名称)。--pipeline-parallel-size=3对应 3 台机器。- 需从 ModelScope 下载,需提前配置
export VLLM_USE_MODELSCOPE=True。
bash
vllm serve /models/Qwen3.5-4B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--pipeline-parallel-size 3 \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--distributed-executor-backend ray \
--max-model-len 8192部署完成之后测试(前台部署,需要新开一个终端或者在其他机器上测试)
bash
curl http://10.132.47.60:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/models/Qwen3.5-4B",
"messages": [
{"role": "user", "content": "你好,介绍一下你自己"}
],
"temperature": 0.7,
"max_tokens": 2048
}'有时会出现 vLLM 0.19.0 的 V1 新引擎 在配合 Pipeline Parallel (PP=3) 和 Qwen3.5 特殊注意力结构 时出现的兼容性 Bug (KeyError: 'linear_attn')。
日志显示 Hidden layers were unevenly partitioned: [11,11,10],报错发生在第 12 和 24 层。我们可以尝试手动强制分层,避开这个断层
bash
export VLLM_PP_LAYER_PARTITION="10,11,11"
vllm serve /models/Qwen3.5-4B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--pipeline-parallel-size 3 \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--distributed-executor-backend ray \
--max-model-len 131072七、后台启动
bash
export VLLM_PP_LAYER_PARTITION="10,11,11"
nohup vllm serve /models/Qwen3.5-4B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--pipeline-parallel-size 3 \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--distributed-executor-backend ray \
--max-model-len 131072 > vllm.log 2>&1 &
### 命令说明
- `nohup`:关闭终端也不会停止程序
- `> vllm.log 2>&1 &`:把日志写入 vllm.log,完全后台运行
- **你的所有参数保持不变**,直接就能用查看日志(实时看输出)
bash
tail -f vllm.log停止后台服务
bash
pkill -f vllm检查是否在运行
bash
ps aux | grep vllm八、开机自启
创建开机自启服务文件
bash
vim /etc/systemd/system/vllm-qwen4b.service
bash
[Unit]
Description=vLLM Qwen3.5-4B 128K PP=3 Service
After=network.target network-online.target
[Service]
Type=simple
User=root
WorkingDirectory=/root
Environment="VLLM_PP_LAYER_PARTITION=10,11,11"
ExecStart=/root/vllm-env/bin/vllm serve /models/Qwen3.5-4B \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 1 \
--pipeline-parallel-size 3 \
--gpu-memory-utilization 0.9 \
--trust-remote-code \
--distributed-executor-backend ray \
--max-model-len 131072
Restart=on-failure
RestartSec=10
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target启用开机自启
bash
systemctl daemon-reload
systemctl enable vllm-qwen4b常用管理命令
bash
#启动服务
systemctl start vllm-qwen4b
#停止服务
systemctl stop vllm-qwen4b
#查看实时日志
journalctl -u vllm-qwen4b -f
#查看状态
systemctl status vllm-qwen4b
#禁止开机自启
systemctl disable vllm-qwen4b集群监控入口
- Ray 集群资源监控面板:
http://10.132.47.60:8265,可实时查看 3 台机器的 GPU/CPU 负载、任务调度状态
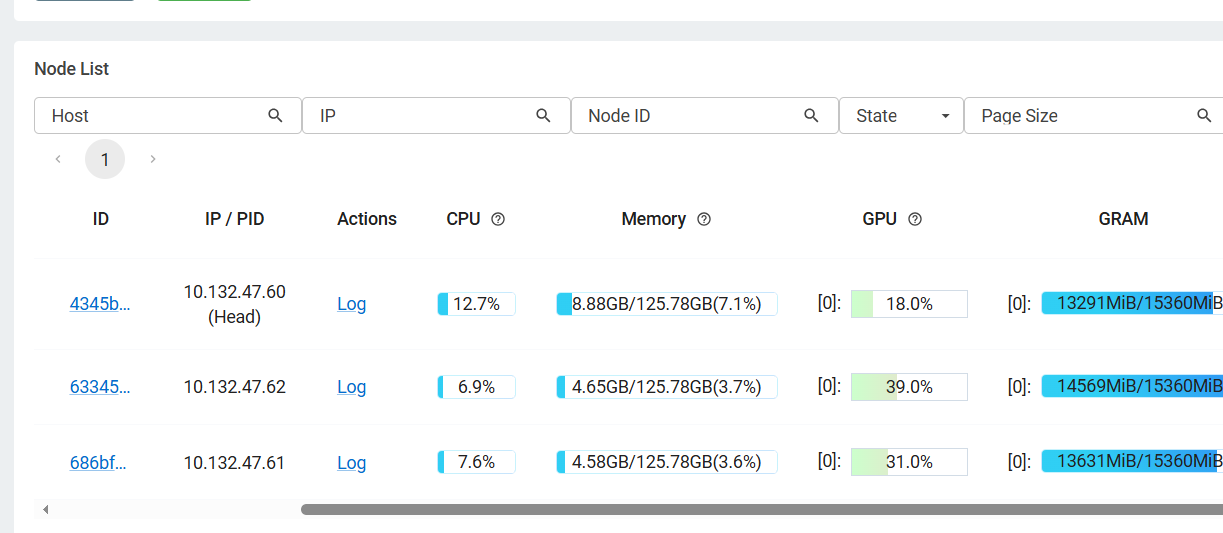
- vLLM 健康检查:
curl http://10.132.47.60:8000/health,返回 200 即服务正常 - Prometheus 性能指标:
http://10.132.47.60:8000/metrics,可接入监控系统做长期告警和趋势分析
open claw安装(windows 10)
一、准备工作
1. 确认显卡型号与系统信息
- 方法 1(设备管理器):
- 按
Win+X→ 选择 设备管理器 - 展开 显示适配器,记下显卡全称(如 NVIDIA GeForce RTX 4060、AMD Radeon RX 7900 XT、Intel UHD Graphics 770)
- 按
- 方法 2(DirectX 诊断):
- 按
Win+R→ 输入dxdiag→ 回车 - 切换到 显示 选项卡,查看显卡名称与系统版本
- 按
- 确认系统:Windows 10 64 位(主流)/32 位
2. 关闭干扰(推荐)
- 关闭所有游戏、视频、直播软件
- 临时关闭杀毒 / 防火墙(避免拦截安装)
- 备份重要文件(以防异常)
二、安装显卡驱动
下载 NVIDIA vGPU 驱动
访问 NVIDIA 官方驱动下载网站。
安装完成之后重启机器
PowerShell查看
powershell
nvidia-smiPS C:\Users\win> nvidia-smi
Wed Mar 18 15:14:33 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 582.16 Driver Version: 582.16 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 TCC | 00000000:00:0B.0 Off | 0 |
| N/A 47C P8 10W / 70W | 9MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+下载CUDA工具包
CUDA Toolkit 13.2 Downloads | NVIDIA Developer
验证
powershell
nvcc --version三、安装openclaw
PowerShell 执行策略限制了 .ps1 脚本的运行,执行以下命令,输入 A 确认:
powershell
Set-ExecutionPolicy RemoteSigned -Scope LocalMachine自动安装
powershell
curl -fsSL https://openclaw.ai/install.cmd -o install.cmd && install.cmd --tag beta && del install.cmd
powershell
iwr -useb https://openclaw.ai/install.ps1 | iex手动安装
OpenClaw 依赖Git 与**Node.js**运行,先装好这两个基础环境。
安装 Git下载地址:https://git-scm.cn/install/windows
安装要点:全程默认下一步,无需修改配置。
安装 Node.js下载地址:https://nodejs.org/
或者
下载https://github.com/coreybutler/nvm-windows/releases/download/1.2.2/nvm-setup.exe
安装过程一路 Next 即可。安装成功后建议你用 管理员权限打开 PowerShell:
-
按 Win 键 + S
-
搜索 PowerShell
-
鼠标右键 → 以管理员身份运行
验证 NVM 命令
nvm version
安装 Node.js 24.14.0
nvm install 24.14.0
切换版本
nvm use 24.14.0
验证
node -v # 输出 v24.14.0
OpenClaw 要求 Node.js 版本必须 ≥ 22
验证环境以管理员身份打开 CMD,输入:
powershell
git --version
node -v
npm -v出现版本号即环境正常。
安装pnpm
powershell
npm install -g pnpm
pnpm --version
pnpm setup
关闭powershell重新打开安装
powershell
# 全局安装 OpenClaw
pnpm add -g openclaw@latest验证安装
powershell
openclaw --version
# 1. 启动配置向导(自动安装守护进程,无需额外参数)
openclaw onboard --install-daemon
# 2. 检查环境是否正常(排查配置/依赖问题)
openclaw doctor
# 3. 启动 OpenClaw 网关(指定端口,方便访问)
openclaw gateway --port 18789 --verbose
# 4. 启动 Openclaw
openclaw gateway startopen claw安装(ubuntu)
更新软件:
bash
# 1. 更新系统包列表
sudo apt update && sudo apt upgrade -y
# 2. 安装编译工具和基础依赖(Node 编译必需)
sudo apt install -y gcc g++ make cmake python3 git curl1.脚本部署
macOS / Linux / WSL2
bash
curl -fsSL https://clawdbot.org.cn/install.sh | bash
curl -sSL https://openclaw.ai/install.sh | bash脚本会自动完成:
-
检测并安装 Node 22+
-
全局安装 OpenClaw CLI
-
启动引导配置向导(脚本执行完成后会进入引导配置,先ctrl+c退出,稍后进入配置)
2.安装 Node 22+ 并自行管理安装过程
更新系统并安装基础依赖
bash
# 1. 更新系统包列表
sudo apt update && sudo apt upgrade -y
# 2. 安装编译工具和基础依赖(Node 编译必需)
sudo apt install -y gcc g++ make cmake python3 git curl安装 Node.js 22+(OpenClaw 要求版本)
bash
# 1. 添加 NodeSource 22 源(自动适配 Ubuntu 版本)
curl -o- https://gitee.com/RubyMetric/nvm-cn/raw/main/install.sh | bash
source ~/.bashrc
# 2. 安装 Node.js 22(自动包含 npm)
nvm install 22
# 3. 验证版本(需显示 v22.x.x,否则安装失败)
node -v
npm -v全局安装 OpenClaw(核心步骤)
bash
# 1. 全局安装 OpenClaw 最新版(加 sudo 避免权限问题)
sudo npm install -g openclaw@latest
# 2. 验证安装(显示版本号即成功)
openclaw -v#### 1.脚本部署
##### macOS / Linux / WSL2
```bash
curl -fsSL https://clawdbot.org.cn/install.sh | bash
curl -sSL https://openclaw.ai/install.sh | bash脚本会自动完成:
-
检测并安装 Node 22+
-
全局安装 OpenClaw CLI
-
启动引导配置向导(脚本执行完成后会进入引导配置,先ctrl+c退出,稍后进入配置)
2.安装 Node 22+ 并自行管理安装过程
更新系统并安装基础依赖
bash
# 1. 更新系统包列表
sudo apt update && sudo apt upgrade -y
# 2. 安装编译工具和基础依赖(Node 编译必需)
sudo apt install -y gcc g++ make cmake python3 git curl安装 Node.js 22+(OpenClaw 要求版本)
bash
# 1. 添加 NodeSource 22 源(自动适配 Ubuntu 版本)
curl -o- https://gitee.com/RubyMetric/nvm-cn/raw/main/install.sh | bash
source ~/.bashrc
# 2. 安装 Node.js 22(自动包含 npm)
nvm install 22
# 3. 验证版本(需显示 v22.x.x,否则安装失败)
node -v
npm -v全局安装 OpenClaw(核心步骤)
bash
# 1. 全局安装 OpenClaw 最新版(加 sudo 避免权限问题)
sudo npm install -g openclaw@latest
# 2. 验证安装(显示版本号即成功)
openclaw -v