目录
- [一次 AI 调用 15 万 Token 只花了 0.058?彻底搞懂 Token、缓存读、补全计费机制!(附完整架构图)](#一次 AI 调用 15 万 Token 只花了 0.058?彻底搞懂 Token、缓存读、补全计费机制!(附完整架构图))
- [一、什么是 Token?](#一、什么是 Token?)
- [二、AI API 的三种 Token 计费方式](#二、AI API 的三种 Token 计费方式)
- 三、真实价格解析
- [四、AI API 调用架构图](#四、AI API 调用架构图)
- 五、真实费用计算
-
-
- [1 缓存读费用](#1 缓存读费用)
- [2 输出 Token 费用](#2 输出 Token 费用)
- [3 输入 Token 费用](#3 输入 Token 费用)
- [4 总费用](#4 总费用)
-
- [六、Token 计费结构图](#六、Token 计费结构图)
- 七、为什么缓存读这么重要?
- [八、缓存机制对 AI 产品的意义](#八、缓存机制对 AI 产品的意义)
-
-
- [AI Agent](#AI Agent)
- [RAG 系统](#RAG 系统)
- [AI API 网关](#AI API 网关)
-
- [九、AI 成本优化图](#九、AI 成本优化图)
-
-
- [1 控制上下文长度](#1 控制上下文长度)
- [2 使用 Prompt 压缩](#2 使用 Prompt 压缩)
- [3 提高缓存命中率](#3 提高缓存命中率)
- [4 控制输出 Token](#4 控制输出 Token)
- [5 选择合适模型](#5 选择合适模型)
-
- [十、为什么 /v1/responses 更先进?](#十、为什么 /v1/responses 更先进?)
- 十一、总结
一次 AI 调用 15 万 Token 只花了 $0.058?彻底搞懂 Token、缓存读、补全计费机制!(附完整架构图)
最近很多开发者在调用 AI API 时都会遇到一个疑惑:
为什么一次调用用了十几万 Token,结果只花了几美分?
来看一条真实调用记录:
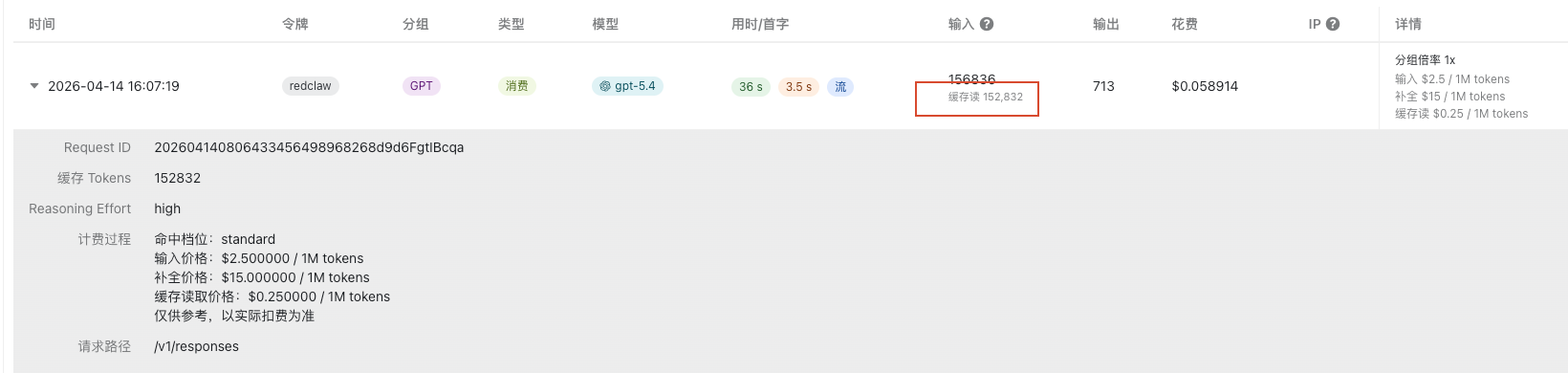
时间:2026-04-14 16:07:19
总 Tokens:156836
缓存读:152832
补全:713
费用:$0.058914
价格:
输入 $2.5 / 1M tokens
补全 $15 / 1M tokens
缓存读 $0.25 / 1M tokens
接口:
/v1/responses第一眼很多人会觉得:
15 万 Token 才 0.058 美元?
是不是计费算错了?
其实完全没有问题。
真正的原因是:
AI API 的 Token 计费其实分三种类型:
1️⃣ 输入 Token
2️⃣ 输出 Token(补全)
3️⃣ 缓存读取 Token
而三者价格差距 最高能达到 60 倍。
很多 AI 产品能盈利,靠的就是 缓存机制。
今天这篇文章,我会带你彻底搞懂:
- Token 到底是什么
- 为什么缓存读这么便宜
- 为什么长对话成本不会爆炸
- 如何把 AI API 成本降低 10 倍
如果你在做:
- AI Agent
- RAG 系统
- AI API 网关
- OpenAI 兼容接口
这篇文章一定对你非常有价值。
一、什么是 Token?
首先必须理解一个核心概念:
Token 是大模型处理文本的最小单位
它既不是字符,也不是单词。
例如一句英文:
Hello world可能会被拆成:
Hello
world两个 Token。
但中文通常是:
你好世界可能被拆成:
你
好
世
界四个 Token。
所以通常可以粗略认为:
| 内容 | Token数量 |
|---|---|
| 英文100词 | ≈120 Token |
| 中文100字 | ≈100 Token |
因此:
Token ≈ 文本长度
二、AI API 的三种 Token 计费方式
这条调用记录:
总 Tokens:156836
缓存读:152832
补全:713Token 实际被拆成三部分:
| 类型 | 含义 |
|---|---|
| 输入 Token | 用户发送给模型 |
| 输出 Token | 模型生成内容 |
| 缓存读 Token | 命中历史上下文 |
注意:
缓存 Token 是最便宜的。
三、真实价格解析
这条记录的计费标准:
输入 $2.5 / 1M tokens
补全 $15 / 1M tokens
缓存读 $0.25 / 1M tokens换算成单 Token 价格:
| 类型 | 单价 |
|---|---|
| 输入 | $0.0000025 |
| 输出 | $0.000015 |
| 缓存 | $0.00000025 |
重点来了:
缓存读价格只有输入的 1/10。
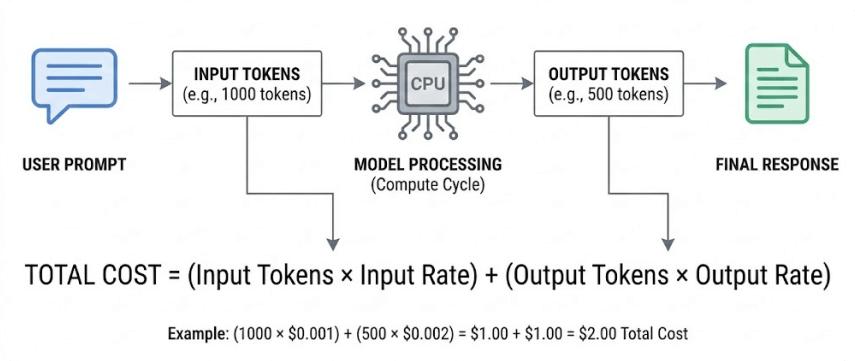
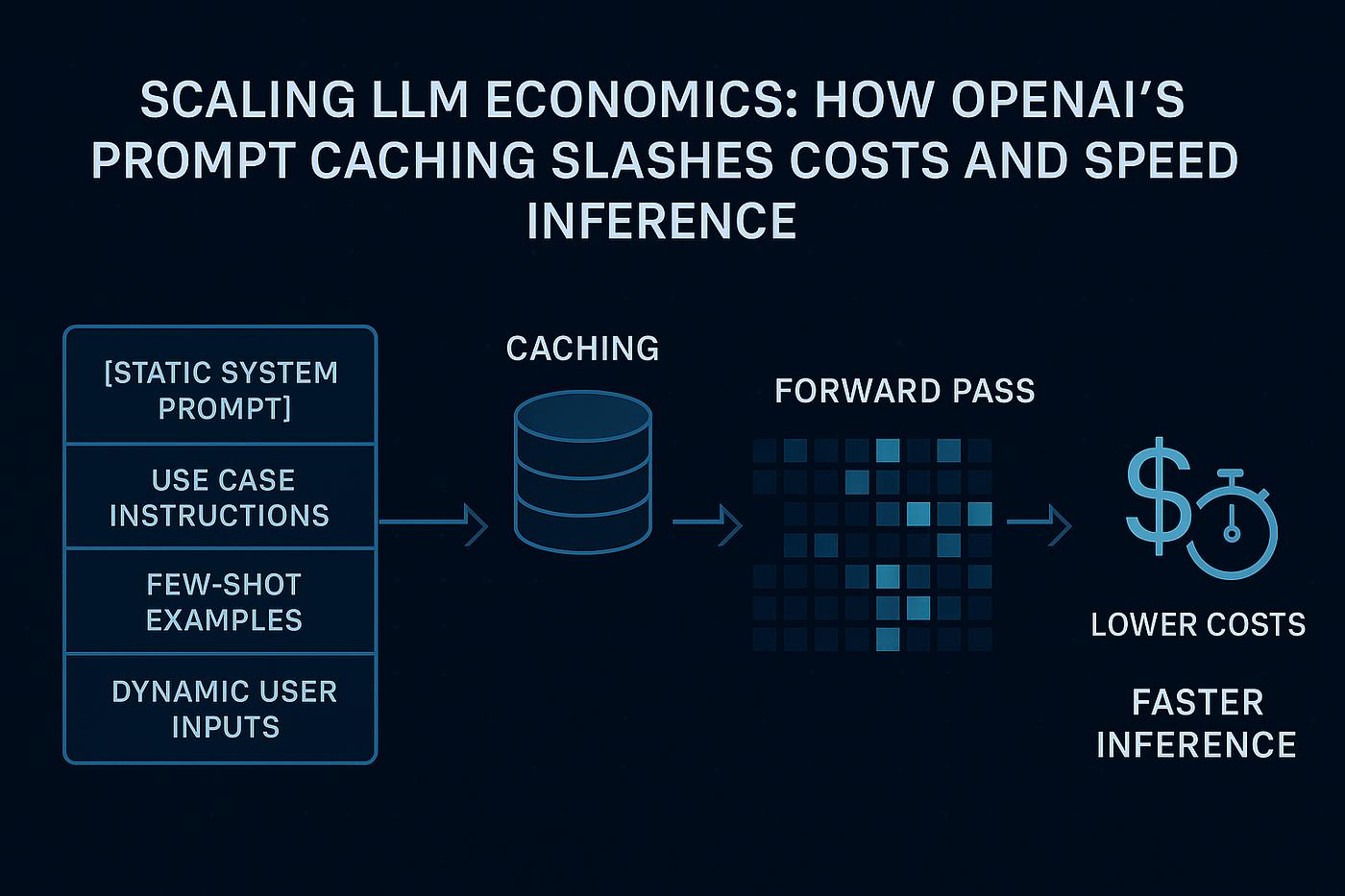
四、AI API 调用架构图
理解 Token 计费,必须先理解 AI 请求流程。
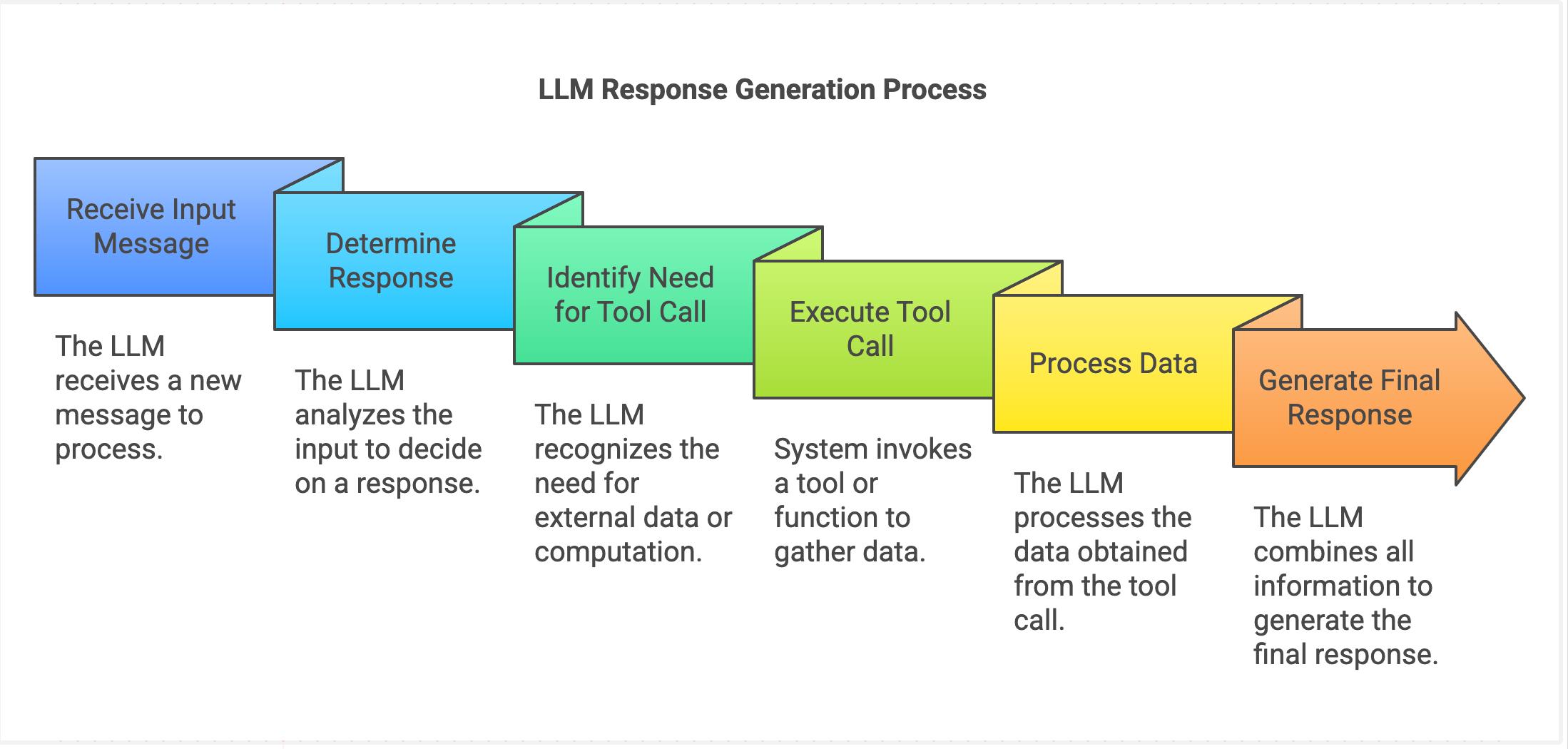
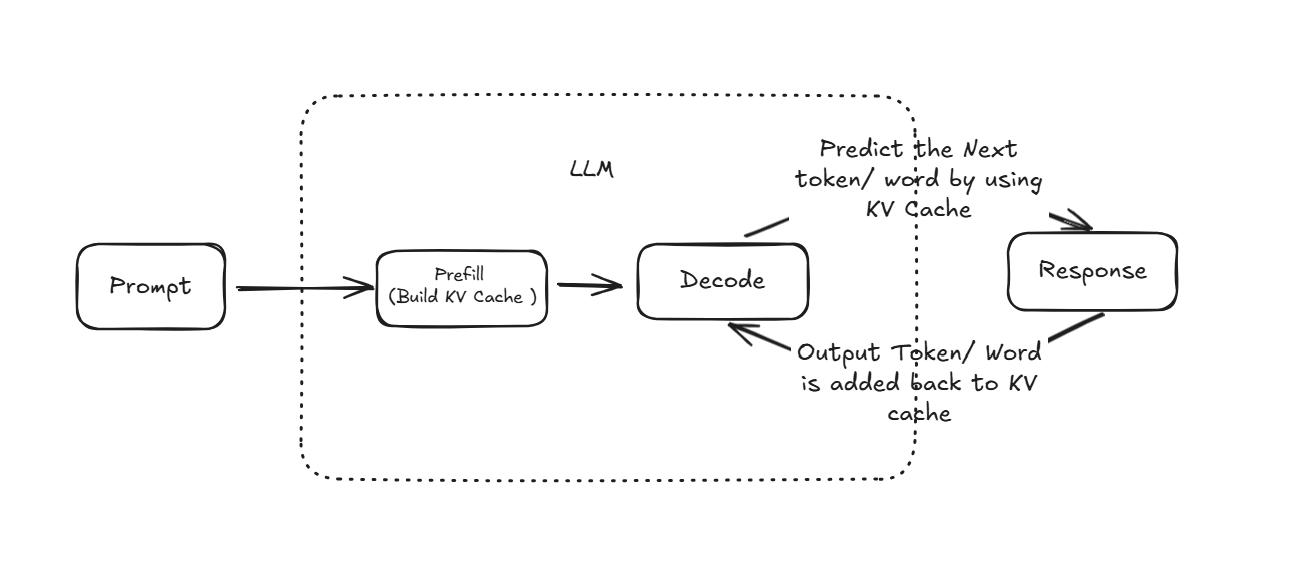
典型 AI 请求流程:
用户请求
│
▼
API 网关
│
▼
上下文构建
(系统Prompt + 历史对话)
│
▼
缓存检测
│
├── 命中缓存 → 直接读取
│
└── 未命中 → GPU推理
│
▼
模型生成结果
│
▼
返回用户在这个过程中:
缓存命中越高 → 成本越低。
五、真实费用计算
现在我们拆解刚才的调用记录。
1 缓存读费用
152832 tokens
价格:$0.25 / 1M计算:
152832 / 1,000,000 × 0.25
≈ $0.03822 输出 Token 费用
713 tokens
价格:$15 / 1M计算:
713 / 1,000,000 × 15
≈ $0.01073 输入 Token 费用
剩余部分属于输入:
3291 tokens计算:
3291 / 1,000,000 × 2.5
≈ $0.00824 总费用
最终费用:
0.0382
+0.0107
+0.0082
---------------
≈ $0.0589与账单:
$0.058914完全一致。
六、Token 计费结构图

Token 结构如下:
| 类型 | 数量 |
|---|---|
| 缓存读 | 152832 |
| 输入 | 3291 |
| 输出 | 713 |
可以看到:
97% Token 都来自缓存。
七、为什么缓存读这么重要?
假设没有缓存:
152832 tokens按输入价格计算:
152832 / 1M × 2.5
≈ $0.38而实际只花:
$0.038直接:
便宜 10 倍。
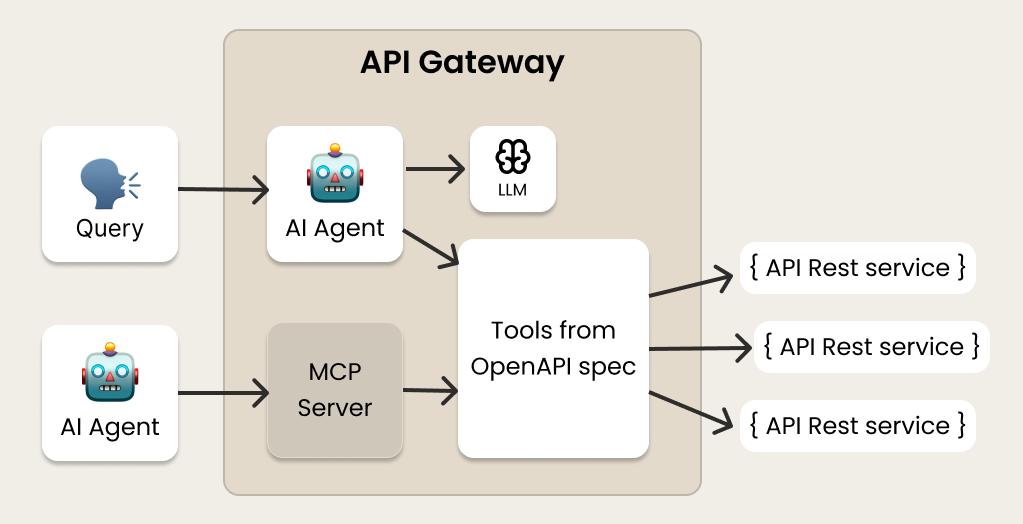
八、缓存机制对 AI 产品的意义
缓存机制对于 AI 产品来说极其重要。
例如这些场景:
AI Agent
Agent 通常带大量上下文:
系统Prompt
工具描述
历史对话如果每次重新推理:
成本会非常高。
RAG 系统
RAG 请求通常包含:
用户问题
历史对话
知识库片段很多上下文是重复的。
缓存可以节省大量 GPU 计算。
AI API 网关
如果你做:
- OpenAI API 代理
- AI 聚合平台
- AI SaaS
缓存策略甚至会决定:
你的产品是盈利还是亏钱。
九、AI 成本优化图
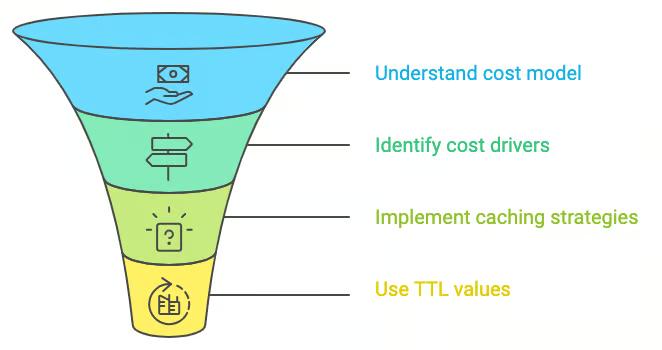

常见 AI 成本优化方式:
1 控制上下文长度
建议:
只保留最近 10 轮对话2 使用 Prompt 压缩
例如:
摘要历史对话减少 Token。
3 提高缓存命中率
例如:
系统Prompt缓存
知识库缓存
工具描述缓存4 控制输出 Token
输出 Token 是最贵的:
$15 / 1M tokens比输入贵 6倍。
5 选择合适模型
很多轻量模型价格更低:
- DeepSeek
- Qwen
- Doubao
适合高并发调用。
十、为什么 /v1/responses 更先进?
这条调用记录使用接口:
/v1/responses而不是传统:
/v1/chat/completions原因是:
responses API 支持:
- 多模态输入
- 推理模型
- streaming
- 工具调用
- reasoning
示例:
json
POST /v1/responses
{
"model": "xxx",
"input": "你好",
"stream": true
}未来很多 AI 平台都会逐步迁移到这个接口。
十一、总结
这次调用:
156836 tokens只花了:
$0.0589核心原因:
绝大部分 Token 命中了缓存。
Token 结构:
| 类型 | 数量 |
|---|---|
| 缓存 | 152832 |
| 输入 | 3291 |
| 输出 | 713 |
价格差异:
| 类型 | 单价 |
|---|---|
| 缓存 | $0.25 / 1M |
| 输入 | $2.5 / 1M |
| 输出 | $15 / 1M |
所以 AI 成本控制的核心其实只有三点:
Token数量
模型单价
缓存命中率未来 AI 工程能力的重要指标之一就是:
如何用更少 Token 做更多事情。